主要介绍在CV中常用的Backbone原理 简易代码(代码以及原理经常更新 ),参考论文中的表格,对不同的任务所使用的backbone如下:
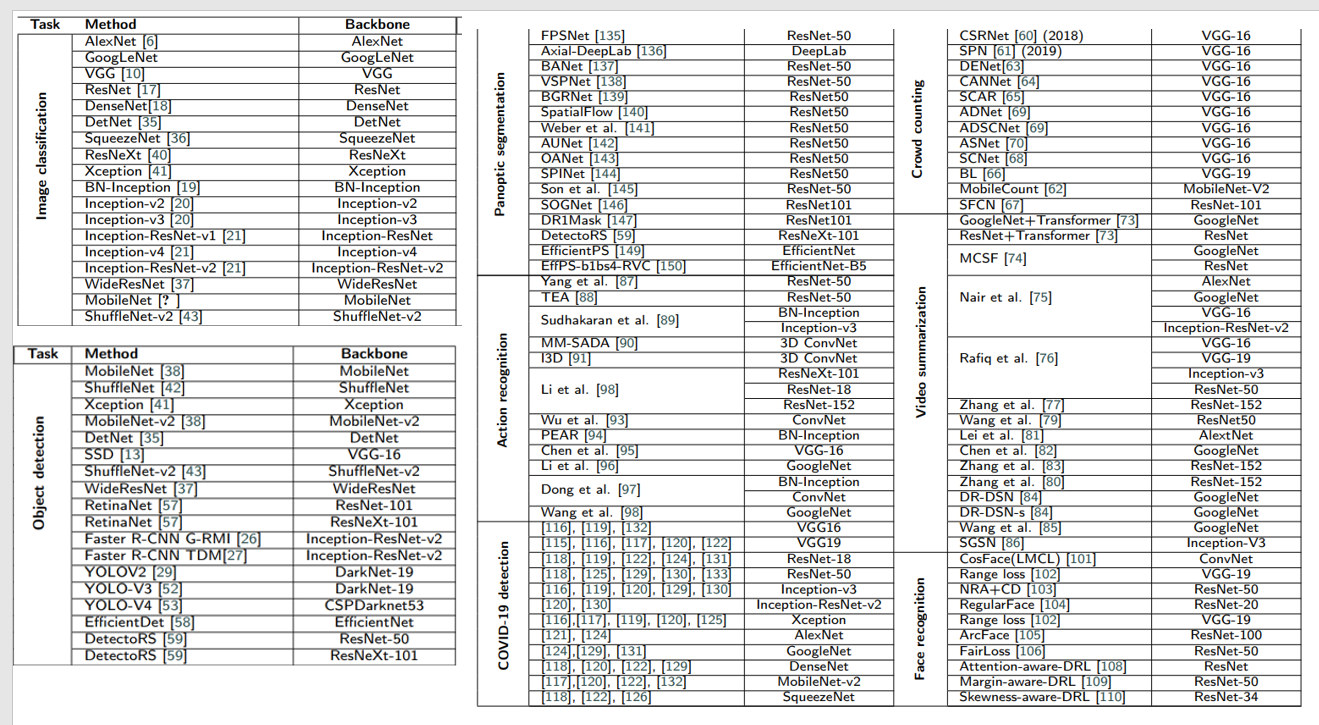
针对上面内容分为两块内容:1、基于卷积神经网络的CV Backbone:1.Resnet系列;2.Unet系列等;2、基于Transformer的 CV Backbone:1.Vit系列等;3、在多模态中常用的backbone如:SAM/Clip等
FROM:https://www.big-yellow-j.top/posts/2025/01/18/CV-Backbone.html
一、基于卷积神经网络的CV Backbone:
1. Resnet系列
主要有何凯明大佬提出,主要有resnet18,resnet34,resnet50,resnet101,resnet152,这几种区别主要就在于卷积层数上存在差异(18:18个卷积后面依次类推),对于Resnet论文中最重要的一个就是残差连接:
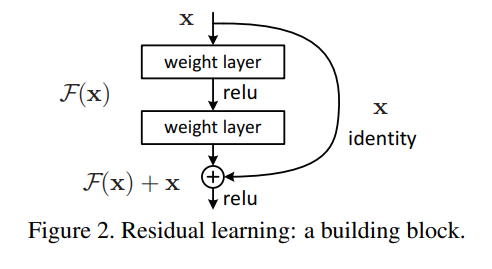
因为随着不断的叠加卷积层数,那么就容易导致 梯度消失 以及 退化问题,残差连接就是通过跳跃连接(skip connection),允许输入信息绕过若干层直接传递到后面的层:
\h\^{l+1} = h\^l + F(h\^l, W\^l) \\
其中\(x\)表示我们输入,\(h^l\)第\(l\)层的输入,\(F(h^l, W^l)\)残差分支的非线性变换。对于上面提到的两个问题,残差连接之所以能够缓解,是因为:
1、对于梯度消失问题 (对于一个神经网络结构,由于反向传播时梯度不断地被链式法则的多个小梯度乘积缩小,最终在靠近输入层的地方梯度变得接近于零,导致参数无法有效更新),残差连接在反向传播时引入了一个 恒等映射(identity mapping) ,使得梯度可以沿着跳跃路径直接传递给前层。这避免了梯度完全依赖深层网络中的权重进行传播。数学上表述就是,对于残差网络连接而言梯度传递为:
\\\frac{\\partial h\^{L}}{\\partial h\^{l}} = I + \\sum_{k=l}\^{L-1} \\prod_{j=k+1}\^{L-1} \\frac{\\partial F(h\^j, W\^j)}{\\partial h\^j} \\
\(I\): 恒等映射项,确保梯度具有直接路径传播至浅层。\(\sum_{k=l}^{L-1}\): 累积的非线性变换贡献。对于前馈神经网络而言梯度传递为:
\\\frac{\\partial h\^L}{\\partial h\^l} = \\prod_{k=l}\^{L-1} \\frac{\\partial F(h\^k, W\^k)}{\\partial h\^k} \\
对比很容易发现,如果某一层出现梯度值很大/小问题,那么就会导致这个效果被不断的扩大,但是残差连接就可以较好的避免这个问题,从另外一种角度而言,对于第\(l+1\)层的输入不仅仅只考虑\(l\)层的信息,还要去结合输入\(l\)层的信息\(x\) (就好比:传递口号,在A这里错了,后面(B,C)可能就都是错了,但是A传递正确给B,B如果传递错误给C但是C还要听一下A怎么给B讲的,这样就可以很好的保证后面口令都不错误)
2、对于 退化问题 :网络深度增加时,传统深层网络会因优化难度增大而导致训练误差不降反升。残差连接引入恒等映射,使网络每层只需学习输入与目标之间的 差值(residual),降低了优化的难度:
- 如果某层优化失败,跳跃连接仍能保留输入特征,从而避免性能下降。
- 在极端情况下,残差网络等价于浅层网络(当 \(F(x) = 0\)时)。
简易代码Demo(直接用torch):
python
import torch
import torchvision.models as models
model = models.resnet50(pretrained=False) # true就会下载权重具体修改某一层参数,可以先将模型print出来然后直接进行修改。比如说修改resnet50中最后的线性层:
# 原始结构:(fc): Linear(in_features=2048, out_features=1000, bias=True)
model.fc = nn.Linear(2048, 10) # 预测10个类别总结一下上面提到的Resnet的输出,假设输入图片为:\(1 \times 3 \times 512 \times 512\)
| 模型 | Layer1 (blocks) |
Layer2 (blocks) |
Layer3 (blocks) |
Layer4 (blocks) |
总 block 数量 |
|---|---|---|---|---|---|
| ResNet-50 | 3:1, 256, 128, 128 |
4:1, 512, 64, 64 |
6:1, 1024, 32, 32 |
3:1, 2048, 16, 16 |
16 (Bottleneck) |
| ResNet-101 | 3:1, 256, 128, 128 |
4:1, 512, 64, 64 |
23:1, 1024, 32, 32 |
3:1, 2048, 16, 16 |
33 (Bottleneck) |
| ResNet-152 | 3:1, 256, 128, 128 |
8:1, 512, 64, 64 |
36:1, 1024, 32, 32 |
3:1, 2048, 16, 16 |
50 (Bottleneck) |
| ResNet-18 | 2:1, 64, 256, 256 |
2:1, 128, 128, 128 |
2:1, 256, 64, 64 |
2:1, 512, 32, 32 |
8 |
| ResNet-34 | 3:1, 64, 256, 256 |
4:1, 128, 128, 128 |
6:1, 256, 64, 64 |
3:1, 512, 32, 32 |
16 |
Bottleneck 层的具体结构:
假设我们有一个输入张量 ( X ),其通道数为 ( C_{in} ),输出通道数为 ( C_{out} ),通过 Bottleneck 结构后,网络的计算可以分为以下几个步骤:
-
第一层卷积(瓶颈):( 1 \times 1 ) 卷积,将输入通道数从 ( C_{in} ) 降低到一个较小的中间通道数 ( C_{mid} )(通常 ( C_{mid} < C_{in} ))。
- 输出形状: H \\times W \\times C_{mid}
-
第二层卷积:( 3 \times 3 ) 卷积,进行特征提取。
- 输出形状: H \\times W \\times C_{mid}
-
第三层卷积:再次使用 ( 1 \times 1 ) 卷积,将中间通道数 ( C_{mid} ) 恢复到输出通道数 ( C_{out} )。
- 输出形状: H \\times W \\times C_{out}
最终,输入 ( X ) 和输出 ( Y ) 通过残差连接相加,形成一个新的输出。残差连接使得信息能够直接流经网络的不同层,从而避免梯度消失问题。
2.Unet系列
Unet主要介绍3种:Unet1,Unet++,Unet3,主要应用在医学影像分割(当然图像分割领域都适用)
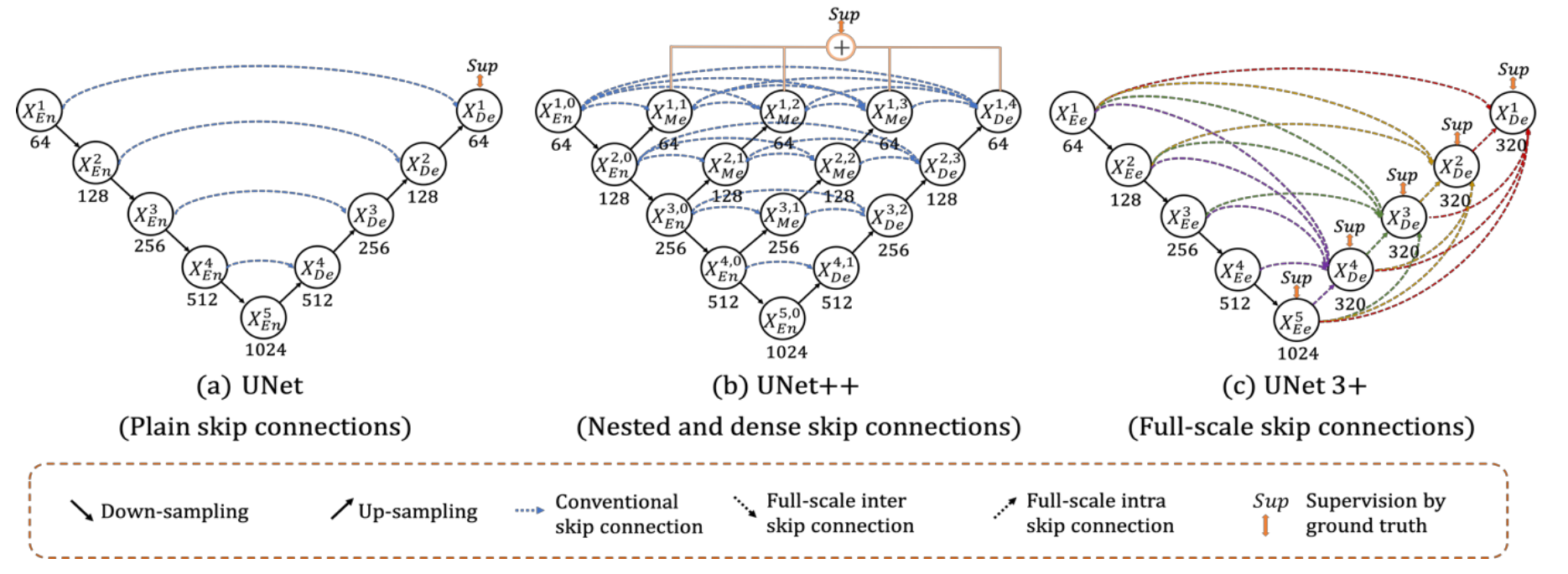
对比上面三种结构,主体结构上并无太大差异,都是首先通过下采样(左边),然后通过上采样(右边)+特征融合。主要差异就在于如何进行特征融合 。以Unet进行理解:
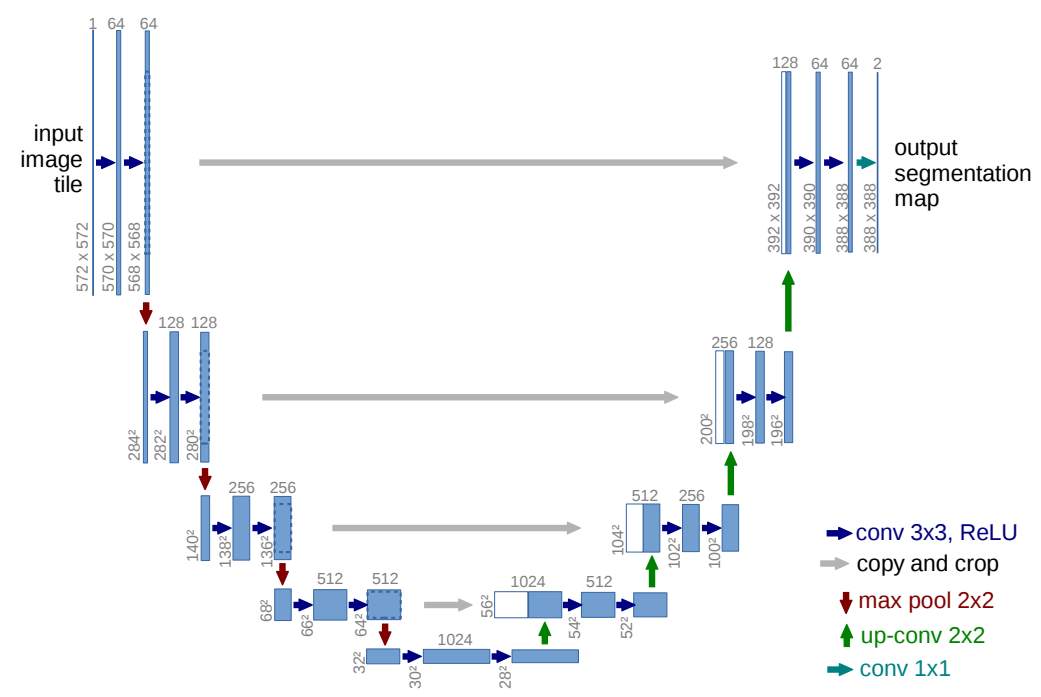
左侧encoder操作 :首先通过两层\(3 \times3\)卷积进行处理,然后通过一个 池化 处理
右侧decoder操作 :一个上采样的卷积层(去卷积层)+特征拼接concat(上图中白色部分就是要拼接的encoder内容)+两个3x3的卷积层(ReLU)反复构成。
Unet相比更早提出的FCN网络,使用拼接来作为特征图的融合方式。FCN是通过特征图对应像素值的相加 来融合特征的;U-net通过通道数的拼接 。
Unet好处就在于,因为是逐层的去累加卷积操作,随着卷积的"深入",越往下的卷积就拥有更加大的 感受野 ,但局部细节可能会逐渐丢失。为了解决这个问题,通过 上采样操作来恢复这些细节。上采样操作将低分辨率的特征图尺寸恢复到较高分辨率,从而保留更多的局部特征,弥补下采样过程中丢失的细节。最后将两部分内容继续融合(里面的skip-connection操作)相互进行弥补实现较好性能
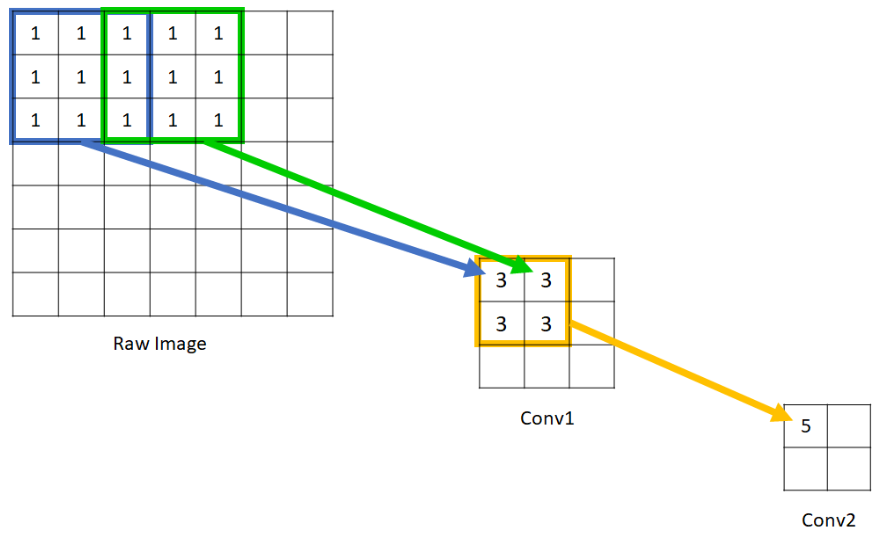
感受野 :可以简单理解:比如说一个512x512图像,最开始用卷积核(假设为3x3)去"扫",那么这个卷积核就会把其"扫"的内容"汇总"起来,比如说某一个值是汇聚了他周围其他的值,这样一来细节的感知就很多 ,但是随着网络层数叠加,这些细节内容就会越来越少,但是计算得到的每个值却是"了解"到了更加"全局"的内容,如下图展示一样
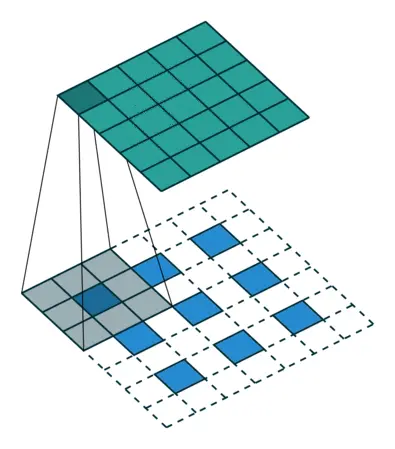
上采样 :可以简单理解为:将图片给"扩大",既然要扩大,那么就会需要对内容进行填补,因此就会有不同的插值方式:'nearest', 'linear', 'bilinear', 'bicubic'(
pytorch提供的)
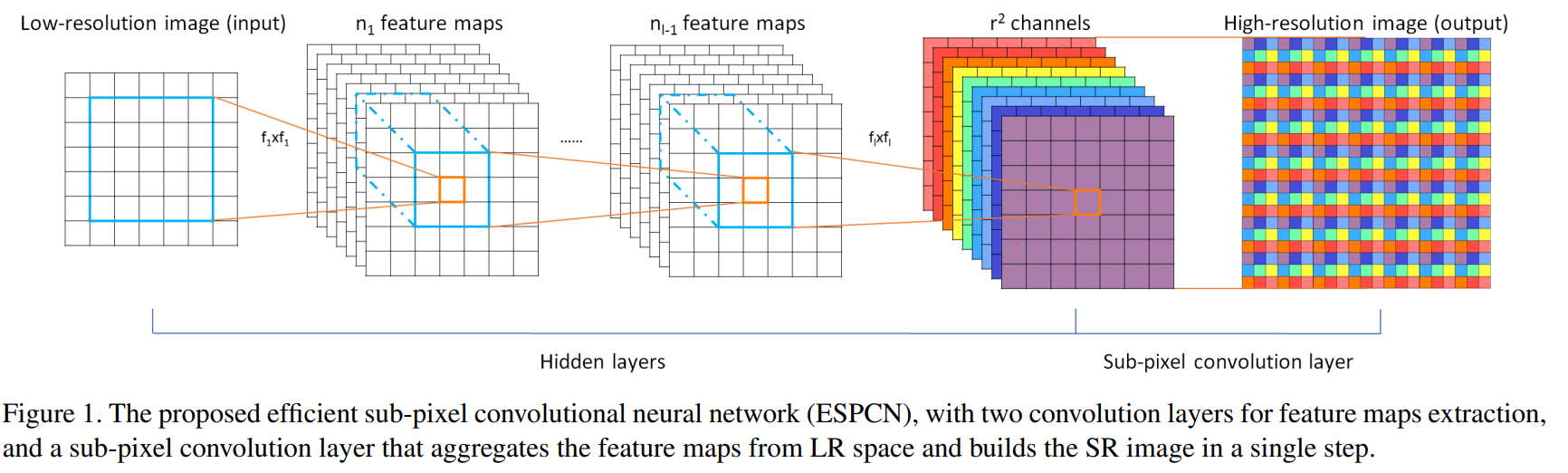
补充一点: 亚像素上采样 (Pixel Shuffle) :普通的上采样采用的临近像素填充算法,主要考虑空间因素,没有考虑channel因素,上采样的特征图人为修改痕迹明显,图像分割与GAN生成图像中效果不好。为了解决这个问题,ESPCN中提到了亚像素上采样方式。具体原理如下
根据上图,可以得出将维度为\(B,C,H,W\)的 feature map 通过亚像素上采样的方式恢复到维度\(B,C,sH,sW\)的过程分为两步:
1.首先通过卷积进行特征提取,将\(B,C,H,W=>B,s\^2C,H,W\)
2.然后通过Pixel Shuffle 的操作,将\(B,s\^2C,H,W=>B,C,sH,sW\)
Pixel Shuffle的主要功能就是将这\(s^2\)个通道的特征图组合为新的\(B,C,sH,sW\)的上采样结果。具体来说,就是将原来一个低分辨的像素划分为\(s^2\)个更小的格子,利用\(s^2\)个特征图对应位置的值按照一定的规则来填充这些小格子。按照同样的规则将每个低分辨像素划分出的小格子填满就完成了重组过程。在这一过程中模型可以调整\(s^2\)个shuffle通道权重不断优化生成的结果。
python
class Net(nn.Module):
def __init__(self, upscale_factor):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(32, 1 * (upscale_factor ** 2), (3, 3), (1, 1), (1, 1)) # 最终将输入转换成 [32, 9, H, W]
self.pixel_shuffle = nn.PixelShuffle(upscale_factor) # 通过 Pixel Shuffle 来将 [32, 9, H, W] 重组为 [32, 1, 3H, 3W]
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = torch.tanh(self.conv2(x))
x = torch.sigmoid(self.pixel_shuffle(self.conv3(x)))
return x
if __name__ == "__main__":
model = Net(upscale_factor=3)
input = torch.arange(1, 10, dtype = torch.float32).view(1,1,3,3)
output = model(input)
print(output.size())
# 输出结果为:
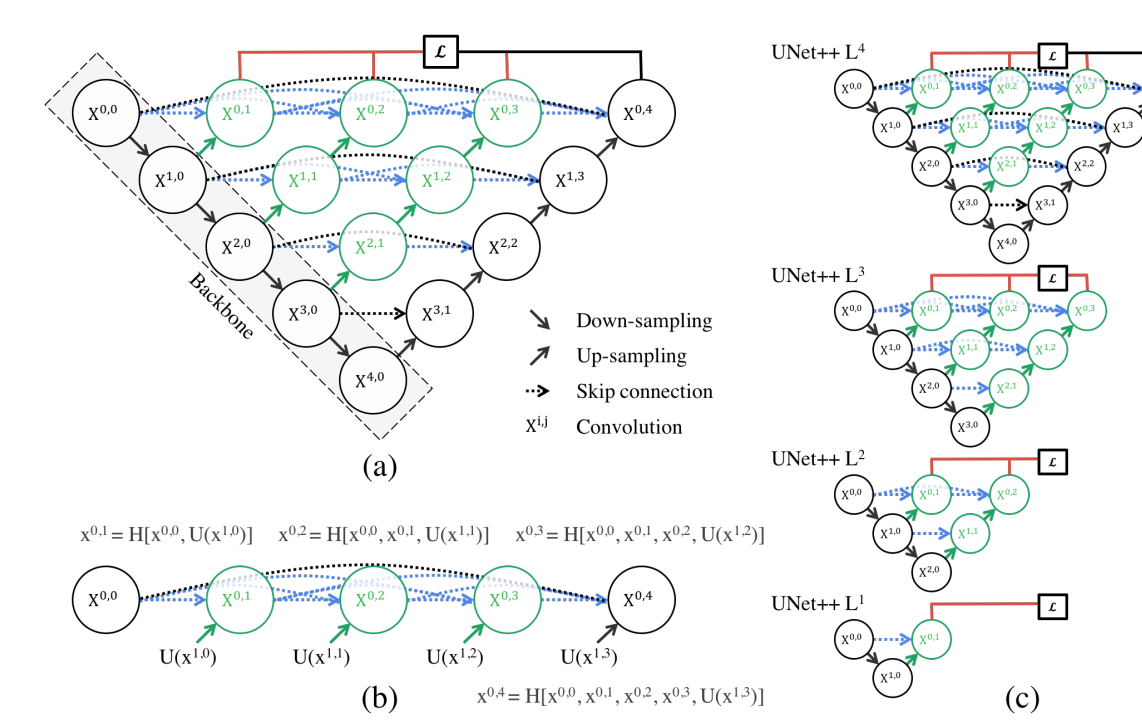
torch.Size([1, 1, 9, 9])对比三种UNet操作,从\(1\rightarrow 3\)进行特征融合的程度更加多,1:将同"水平" 的特征以及"下面"特征进行使用;3:将"左侧"所有的特征以及"下面"特征都进行使用;Unet++:不是直接使用简单的skip-connection而是回去结合 邻近水平 和 邻近水平下 的特征,比如说下面图c通过卷积操作结合\(X^{0,0}\text{和}X^{1,0}\)的特征。
总结上面三种网络结构改进在于:1、Skip-connection方式上区别(也就是如何进行特征连接过程)
Unet++网络结构
3.其他
对于传统的AlexNet,LeNet,GoogleNet可以去看之前写的内容:
1、https://www.big-yellow-j.top/code/AlexNet.html
2、https://www.big-yellow-j.top/code/LeNet.html
3、https://www.big-yellow-j.top/code/googlenet.html
二、基于Transformer的CV Backbone
主要介绍两种:Vit和MAE。Vit:核心思想是将图像划分为小块(Patch),将每个小块视为一个 "单词"(类似 NLP 中的 Token),然后通过标准的 Transformer 架构对这些 Patch 进行处理。
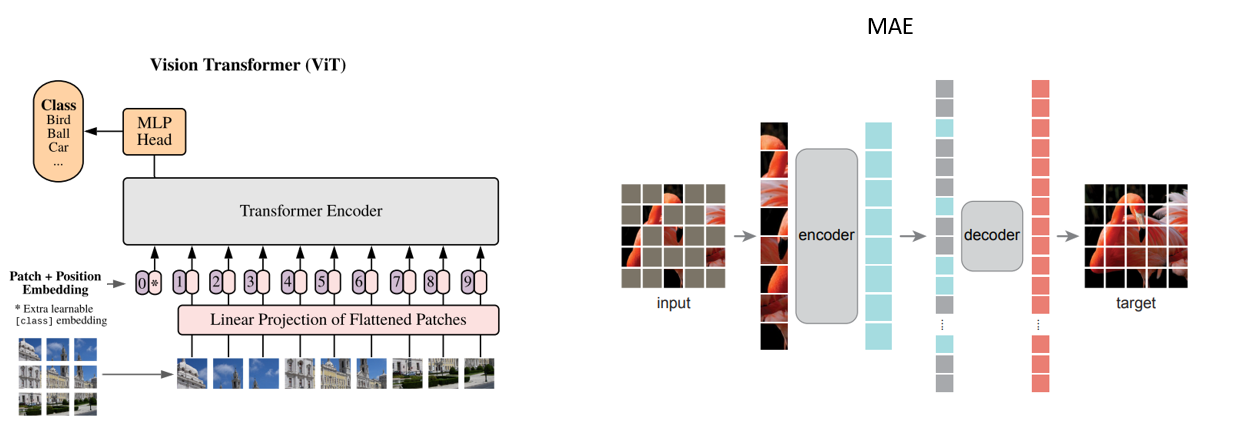
Vit主要操作流程:
- 1、
patch embedding和position embeeding:将图片进行切分为固定大小的patch,比如说输入一张224x224RGB图像,path=16x16。那么的话就会生成:\(\frac{224\times224}{16\times16}=196\)个patch,那么输入模型的序列数量:196 ,经过拉长处理之后得到的序列长度为:\(16\times 16\times 3=768\)。通过线性投射层处理之后维度为:\(196\times 768\)一共为 196 个token,然后补充一个位置编码,对于位置编码最简单的就是直接对每一个patch都生成一个1维的向量(类似one-hot,但是对于位置编码的方式有很多)然后去拼接起来(同时还需要补充一个CLS),最后维度就是:\(197\times768\)
值得注意的是 :正如上提到的**亚像素上采样 (Pixel Shuffle)**可以通过他的逆操作将token数量减少(其实就是将尺寸改变,比如b,c,w,h-->b,c/r\^2,w/2,h/2)
- 2、
transformer encoder:就是一个正常的transformer的encoder处理输入多少维度输出多少维度,依旧是\(197\times768\)
MAE 主要操作流程
- 1、
patch embedding和position embedding:前面操作和Vit操作差异不大,区别在于MAE进行 随机遮盖(Masking) ,例如遮盖 75% 的 Patch,只保留 25% 的 Token,用于后续的编码器输入。最终,编码器的输入维度变为:\(49 \times 768\)(假设保留的 Token 为 49)。与此同时,补充位置编码,最简单的方式是为每个 Patch Token 添加一个唯一的向量(类似于 One-Hot),拼接后维度保持不变。 - 2、
masked token reconstruction:将编码器的输出输入到解码器中,同时将被遮盖的 Token 填充为一个固定的嵌入(称为 Mask Token)。解码器的输入维度恢复为:\(196 \times 768\)解码器通过 Transformer 操作,将未遮盖的 Token 特征与 Mask Token 结合,并尝试重建完整图像。重建的目标是尽可能接近原始图像像素值。
值得注意的是:MAE 的优势在于编码器仅处理未遮盖的部分 Token,大大减少了计算成本。同时,解码器可以设计得更轻量,仅用于重建任务,最终可以通过重建损失(如 L2 损失)优化模型。
在MAE中是分与训练和微调的,与训练就是去预测mask内容,微调就是直接根据不同任务进行微调即可(换输出头/微调里面参数)
python
class DetectionHead(nn.Module):
def __init__(self, embed_dim, num_classes):
super().__init__()
self.cls_head = nn.Linear(embed_dim, num_classes) # 分类头
self.reg_head = nn.Linear(embed_dim, 4) # 边框回归头
def forward(self, x):
cls_preds = self.cls_head(x) # [B, num_patches, num_classes]
reg_preds = self.reg_head(x) # [B, num_patches, 4]
return cls_preds, reg_preds然后将检测头补充到最后的decoder输出后面即可
补充
1、在Vit和MAE的代码中(两部分代码差异不大,以MAE为例)一般而言有如下参数:
img_size=224, patch_size=16, in_chans=3, embed_dim=768, encoder_layers=12, decoder_embed_dim=512, decoder_layers=4, mask_ratio=0.75
第一步 :对于一个输入图片首先 通过PatchEmbedding(用卷积(in_channels=3, out_channels=embed_dim=768)去"扫")然后拉平(x.flatten(2).transpose(1, 2) )输出维度为:[B, num_patches, embed_dim]然后与位置编码相加维度为:[B, num_patches, embed_dim]
第二步 :随机mask部分内容:x_masked, mask, keep = self.random_masking(x),x_masked为随机mask后内容,mask为mask掉的内容,keep为mask余下内容(比如1到100,其中x_maked,keep都为25)主要用来保证顺序,在输入decoder之前需要把之前mask内容补充进来
2、transformer框架模型一般而言需要较多的数据进行训练,如果数据少还是用卷积效果会好一点
Swin Transformer模型
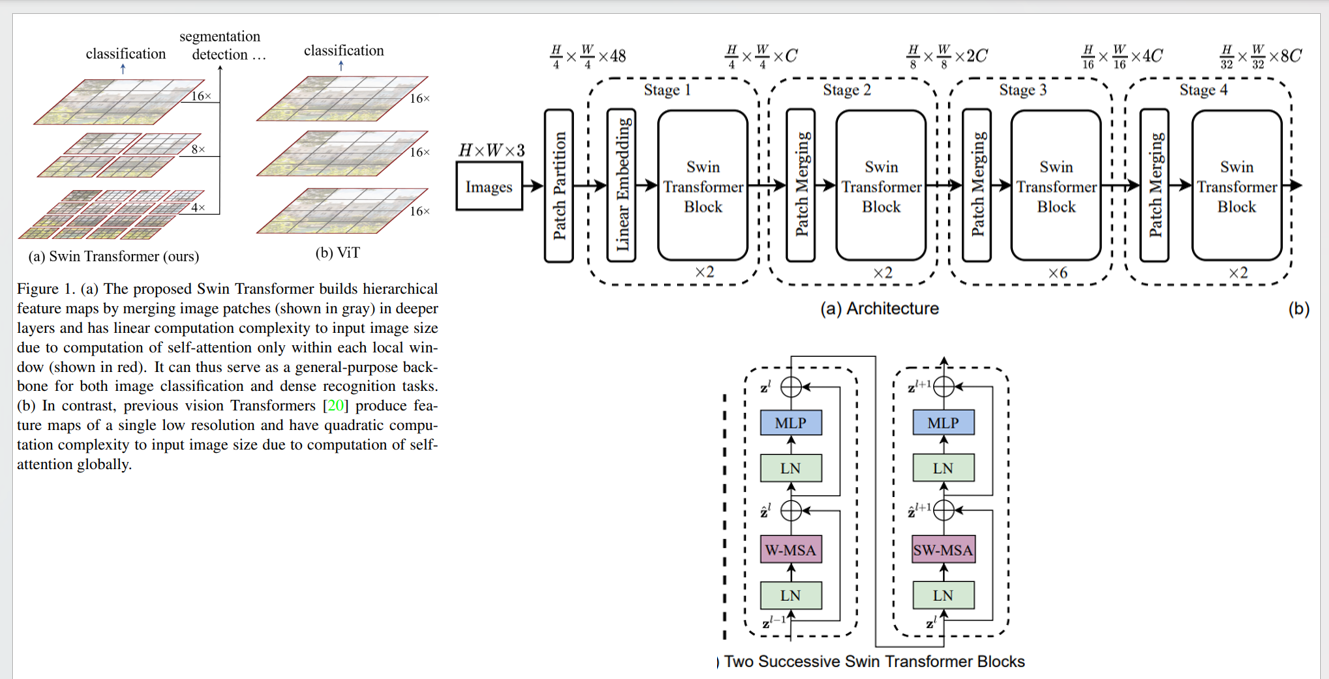
对比之前的Vit和MAE存在问题 在计算注意力的时候都是全局计算 的(每个token之间都是进行注意力计算)因此在Swin Transformer中作者认为这种操作不利于:高分辨率图像(像素点多计算量大)以及密集预测任务(全局的话可能对有些细节就会丢失)
The global computation leads to quadratic complexity with respect to the number of tokens, making it unsuitable for many vision problems requiring an immense set of tokens for dense prediction or to represent a high-resolution image.
要去避免全局计算,一个最简单的办法就是:我去从不同的patch中挑选出一部分内容组合起来,然后再组合的这一块内容中去计算注意力。
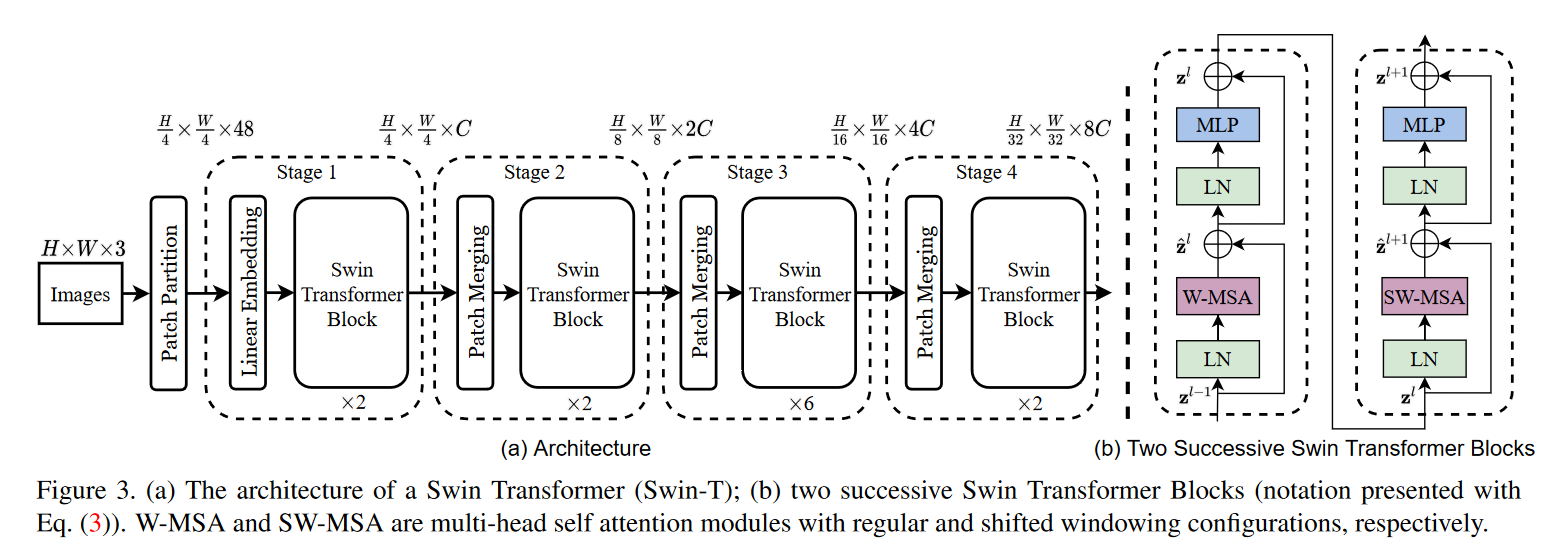
-
1、
Patch Merging操作,这部分操作就是进行 挑选组合 操作,对patch之间进行组合,作者论文中表示是:挑选2x2的邻居进行分组(这里操作和Unet中下采样很像,每个stage中都进行一次减小尺寸,这样一来就可以看到更加"全局")

-
2、
Swin Transformer Block:在将patch组合操作之后,输入到Transformer中,在这里作者将传统的注意力计算改为两种:W-MSA(Window-Multi-Head Self Attention)和SW-MSA(Shift-Window-Multi-Head Self Attention)之所以这样,作者还是在解决上面提到的问题:去避免全局计算。
W-MSA操作:对于传统的计算量大问题(\(MSA=4hwC^2+2(hw)^2C\))提出改进(\(W\text{-}MSA=4hwC^2+ 2M^2hwC\))这部分操作好理解,对于(H,W,C)划分为MxM的窗口得到:(N,MxM,C),然后就只需要对这部分计算Attention-Score即可
SW-MSA操作:弥补上面(W-MSA)存在问题,如果只是计算窗口内部的Attention-Score,就会导致不同窗口之间关系是不知道的,通过下面Shifted-Window来移动窗口位置

通过上面移动进而构成下面图像:
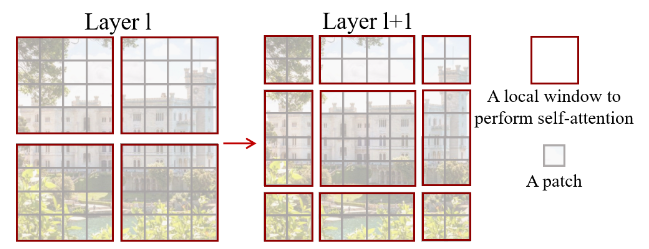
这里就会有9块,再W-MSA中是4块(都是4x4),无疑加大了计算量,因此只需要将9块重新进行拼接起来(保证最后为4x4即可)就可以,比如下面,
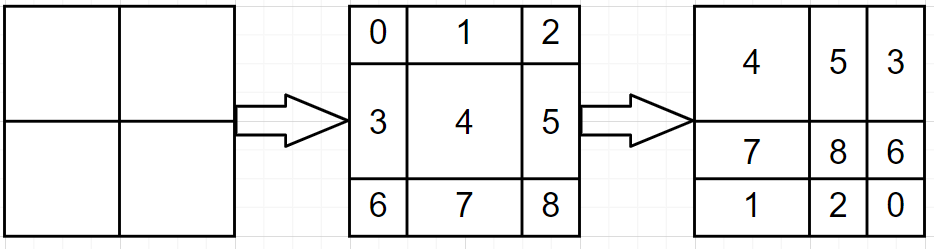
对于上面的操作,可以直接通过
torch.roll实现先左移动3然后上移动3 。torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
这样一来就都满足(4x4)还可以实现不同window之间进行交互(5,3为例,将他们视作整体,计算AttentionScore)不过值得注意的是,5和3之间像素都是有差异的,直接计算会引入误差,因此原文在计算注意力时,在执行softmax之前,分别将模块3像素对应的注意力值分别减去100,使得softmax后,权重都是0,从而实现模块3对模块5的影响。
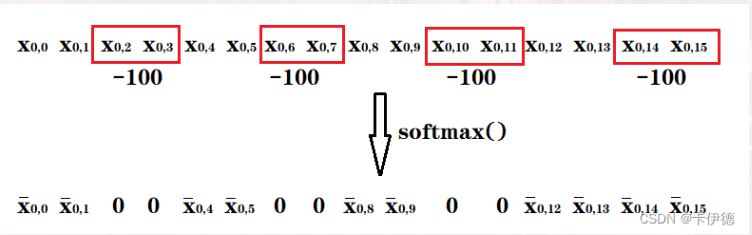
具体操作:
python
...
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
...
# con atten
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
...
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)上面操作很容易理解:对于注意力计算 :计算\(QK^T\)之后,得到各个点的权重 ,然后把这个权重加权到\(V\)上,上面操作通过加\(-100\)然后通过softmax处理,那么不属于分区内的"点"(比如53组合)权重就会被处理为0
三、多模态backbone
这部分内容主要介绍在多模态算法中常用的几类backbone,主要为代码(SAM/Clip等)
多模态算法涉及到的
backbone比较杂,传统卷积/Transformer都有
简短介绍:Clip:将文本和图像已经通过对齐;SAM:主要用来作分割(简单理解为:抠图)
python
# Clip
'''
预先下载/直接transformer下载:
config.json, preprocessor_config.json, tokenizer.json vocab.json pytorch_model.bin
'''
import transformers
import torch
import torch.nn as nn
from transformers import CLIPProcessor, CLIPModel
class ClipBackbone(nn.Module):
def __init__(self, ):
super(ClipBackbone, self).__init__()
self.clip_model = CLIPModel.from_pretrained('./clip/')
self.processor = CLIPProcessor.from_pretrained('./clip/')
...
# 加载llm
...
def forward(self, image, text):
# clip提取特征
inputs = self.processor(images= image, return_tensors= "pt")
with torch.no_grad():
image_embeddings = self.clip_model.get_image_features(**inputs)
...
# 将image_embeddings和llm尺寸对其
...
# llm处理
...
return image_embeddings输出为维度config.json中参数"projection_dim": 768
参考:
1、https://arxiv.org/pdf/2206.08016
2、https://arxiv.org/pdf/1512.03385
3、https://arxiv.org/pdf/2010.11929
4、https://arxiv.org/pdf/2111.06377
5、https://arxiv.org/pdf/1505.04597
6、https://arxiv.org/pdf/2311.17791
7、https://arxiv.org/pdf/2004.08790
8、https://pytorch.org/docs/stable/generated/torch.nn.Upsample.html
9、https://www.cnblogs.com/zhaozhibo/p/15024928.html
11、https://arxiv.org/pdf/1807.10165v1
12、https://arxiv.org/pdf/2103.14030
13、https://www.cnblogs.com/chentiao/p/18379629