1.1 语言的基本组成要素------词汇
1.1.1 语言的组成要素
无论是人类学习语言,还是让机器学习人类语言,在面对一门语言时,我们总是先记住一些常用词,然后是语法和基本句型,再然后结合到具体的篇章、对话的语境中学习。可以说,语言是由字符、词汇、语法、语义、语境等多个元素相互作用的结果。如果聚焦到某个语言下的句子中,它的分析粒度就可以到字符、词汇、句法这几个级别。
不同语言的词汇之间往往也是可以互相翻译的,这就是为什么我们会有不同语言之间的互译词典。通过词典,可以把不同的单词对换过来,但不同语言下同一个句子不同词汇的出现顺序是有要求的。比如一个很经典的笑话:"How old are you"如果按照词典逐个单词直译过来,它的中文叫什么,叫"怎么老是你"。所以,在翻译的过程中,还需要按照目标语言的语法约束,对词汇的出现进行重新组合。
语法约束使得一个句子中不同成分的出现次序有一定规律,这也是统计机器翻译(SMT)的来源。早在人工智能这个概念诞生之前,自动控制之父维纳就在和友人的信件中提及机器翻译这个概念。他认为,通过一定规模的词典,加上形式化表达的规则约束可以实现一部分语句的机器翻译。果不其然,理论在后来不久得到证实,IBM开发了早期的一个英语-俄语翻译工具,能对常见的700多个俄语句子进行翻译。而后来,随着机器学习、深度学习的发展,这些人工智能模型也被用于机器翻译中来。想研究机器翻译,就要理解某个语言下的词汇、句法、语法吧,这就需要对文本信息进行基本处理。而在处理以后,又要理解语义下的一些内容,比如事件、对象、关系、主题,这是进一步深层次的处理。再进一步,对篇章语义的理解、问答、对话,进而到写作、生成、推理,这些是机器真正对文章的理解和智能所在。
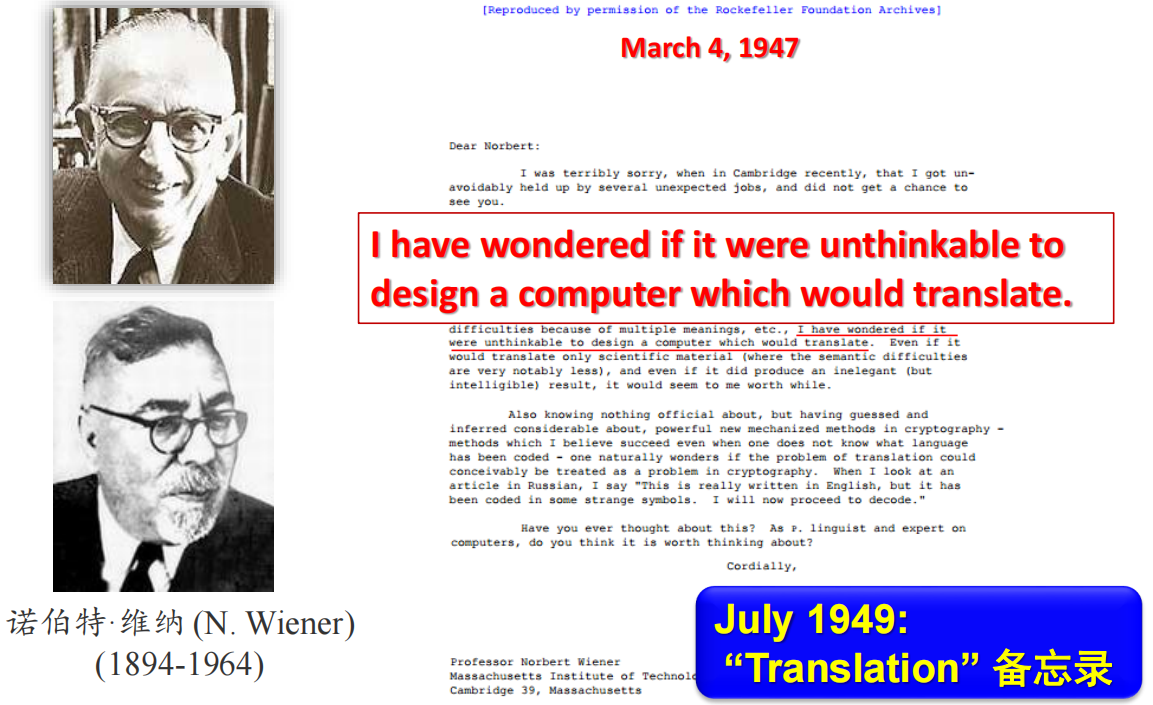
探索之初,我们在第一章想和同学们聊一聊机器如何理解语言。
1.1.2 词法分析
自然语言处理中的词法分析
自然语言处理(NLP)中的词法分析是理解文本的基础步骤,其核心目标是将原始文本分解为有意义的语言单元,并提取关键信息。例如,面对句子"I love studying NLP!",词法分析需要将其切分为单词(如"I""love""studying""NLP"),标注词性(如动词、名词),并识别可能的变化形式(如将"studying"还原为"study")。这一过程的意义在于,只有将文本拆解为结构化单元,机器才能进一步分析语法、语义或情感。词法分析通常包括分词、词性标注、词形还原、命名实体识别等任务。例如,中文句子"他买了一部苹果手机"中,若未正确分词(如误拆为"苹果/手机"而非"苹果/手机"),可能导致语义误解。因此,词法分析为后续处理提供了规范的输入,是NLP任务不可或缺的起点。
词形还原与词干提取的早期实现
在早期自然语言处理中,词形还原(Lemmatization)和词干提取(Stemming)主要依赖规则和简单算法。例如,词干提取通过删减词缀来获取词干,如将"running"变为"run",但这一过程可能不够精确(如"better"被简化为"bet")。20世纪70年代的Porter算法是典型的基于规则的词干提取方法,通过多步骤规则(如删除"-ing"后缀)处理英文词汇。词形还原则更复杂,需结合词典和形态学规则,例如通过查表将"ate"还原为"eat"。早期工具如Snowball Stemmer和WordNet词典库,通过预定义的规则和词形映射表实现这些操作。尽管这些方法在效率上表现优异,但对不规则变化(如"go→went")和多义词(如"leaves"可能指树叶或离开)的处理能力有限,依赖人工规则也导致泛化性不足。
停用词的定义与处理
停用词(Stop Words)是文本中频繁出现但信息量低的词汇,如"的""是""the""and"等。这些词在大多数任务(如搜索、分类)中会引入噪声,例如在搜索引擎中,查询"如何学习编程"若包含停用词"如何",可能返回大量无关结果。去除停用词能显著提升模型效率和准确性。具体操作通常基于预定义的停用词列表,例如NLTK库中的英文停用词表或哈工大中文停用词表。处理时,系统遍历文本中的每个词,若其存在于停用词表中则直接过滤。但需注意,某些场景(如情感分析中的"not")可能需要保留部分停用词,因此需根据任务动态调整词表。
正则表达式的定义与编写
正则表达式(Regular Expression)是一种用于描述字符串模式的工具,通过特定语法规则匹配、查找或替换文本中的字符序列。例如,表达式\b[A-Za-z]+\b可匹配英文单词,而\d{3}-\d{4}可匹配"123-4567"格式的电话号码。编写正则表达式时,需结合元字符(如.匹配任意字符,*表示重复)和字符类(如[A-Z]匹配大写字母)。例如,要提取文本中的日期"2023-08-28",可使用\d{4}-\d{2}-\d{2}。正则表达式在词法分析中广泛应用,如识别邮箱、URL或特定术语。但需注意,复杂表达式可能导致性能问题,且需处理转义字符(如\.匹配句点)。
命名实体识别及其概念
命名实体(Named Entity)指文本中具有特定意义的专有名称,包括人名(如"张三")、地名(如"北京")、组织名(如"联合国")、日期(如"2023年")、货币与数字(如"100美元")等。命名实体识别(NER)的任务是自动识别这些实体并分类,例如从"马云创立了阿里巴巴"中提取"马云(人名)"和"阿里巴巴(组织)"。NER技术早期依赖规则(如关键词列表),后逐渐转向统计模型(如隐马尔可夫链)和深度学习(如BiLSTM-CRF)。其应用涵盖信息抽取、问答系统等场景,例如从新闻中自动提取事件主体,或为知识图谱构建实体节点。
1.1.3 中文分词问题
中文和其他语言有很大不同。在西欧地区的一些语言中(比如英语、法语、意大利语),组成句子的最小单位是词汇。词汇与词汇之间,必须用空格分隔开来,单个的字符(也就是字母)往往没有很大的语义信息。而组成中文的最小元素是汉字,由汉字组成词汇,再通过词汇组成一个完整的句子。因此,在亚洲这些地方的语言(汉语、日语、韩语、泰语等)中,词汇与词汇之间并没有明显的分隔。熟悉这些语言的人能很容易分出来哪个词在什么位置,而这对于一个完全没有学习过中文的老外而言会显得很困难,更别说机器了。
这样的语言现象对于计算机来说往往会造成一些问题。比如,大家看看下面这个句子:

如果把它直接给大模型来分词,我们以不带深度思考的普通deepseek模型为例(不使用R1),它的结果我原封不动给大家看看:
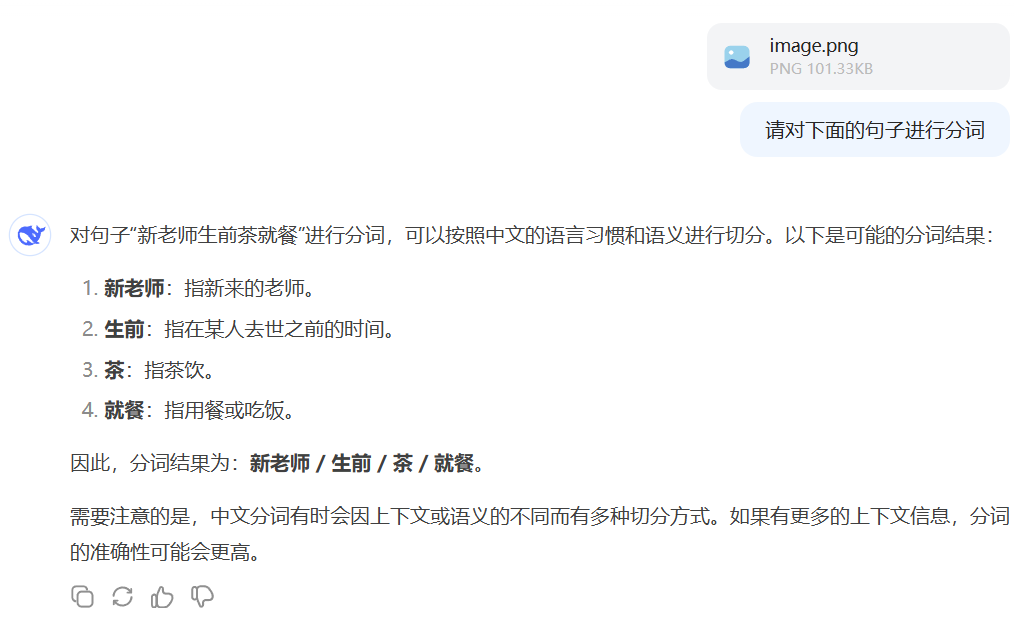
这个结果有什么问题?第一,在从图片识别文字(OCR)这一步的时候就出了问题,"来"字被识别成了"茶",这显然影响了后续分析;第二,在分词的过程中,"生前"被划到一个词里面去了,闹了个笑话。我们大家看到这张图当然知道怎么分词,对吧,因为横幅张贴的位置是在学校里,这种视觉信息与常识(common sense)为我们提供了更多的上下文语义知识。
高质量的中文分词,是中文信息处理的第一步操作。少了这一步,大模型的表现就是渣渣。
基于词典的分词模型
1. 基于词典的分词思想与基本原理
在机器学习技术兴起之前,中文分词的核心思想是依赖预先构建的词典。其基本原理是:通过词典中存储的词汇列表,按照一定的匹配规则将句子切分为词典中存在的词语。词典通常包含常见词汇及其词频信息,分词时优先匹配长词(最大匹配原则),以避免短词组合带来的歧义。例如,给定词典包含"研究"和"研究生",句子"研究生命的起源"会被切分为"研究生/命/起源"或"研究/生命/起源",具体结果取决于匹配方向与词典设计。这种方法简单高效,但高度依赖词典的覆盖度和匹配策略的合理性。
2. 正向最大匹配与逆向最大匹配算法
正向最大匹配(FMM) :从句子左端开始,每次取当前最大可能长度的候选词进行匹配。若词典中存在该词则切分,否则缩短候选词长度继续匹配。
逆向最大匹配(RMM):从句子右端开始,反向选取最大长度的候选词进行匹配,匹配逻辑与正向类似。
Python代码实现
python
# 示例词典(按词长倒序排列)
word_dict = {
"研究生", "研究", "生命", "起源", "南京", "市长", "长江大桥", "长江"
}
max_word_len = max(len(word) for word in word_dict)
def fmm_segment(sentence):
tokens = []
start = 0
while start < len(sentence):
end = min(start + max_word_len, len(sentence))
for size in range(end - start, 0, -1): # 从长到短尝试
candidate = sentence[start:start+size]
if candidate in word_dict:
tokens.append(candidate)
start += size
break
else: # 未匹配到词,切分单字
tokens.append(sentence[start])
start +=1
return tokens
def rmm_segment(sentence):
tokens = []
end = len(sentence)
while end > 0:
start = max(0, end - max_word_len)
for size in range(end - start, 0, -1):
candidate = sentence[start:start+size]
if candidate in word_dict:
tokens.insert(0, candidate)
end = start
break
else:
tokens.insert(0, sentence[end-1])
end -=1
return tokens
# 测试案例
sentence = "研究生命的起源"
print("FMM:", fmm_segment(sentence)) # 输出:['研究生', '命', '的', '起源']
print("RMM:", rmm_segment(sentence)) # 输出:['研究', '生命', '的', '起源']3. 双向匹配结合方法
单纯使用正向或逆向最大匹配可能导致错误切分。例如,句子"南京市长江大桥"的两种分词结果:
- FMM :
["南京", "市", "长江大桥"](正确) - RMM :
["南京市", "长江", "大桥"](错误)
双向匹配通过对比两种分词结果,选择更合理的一种。规则通常包括:
- 若分词数量不同,选数量少的(更倾向长词)。
- 若数量相同,选单字更少的。
- 仍相同则按预设优先级(如选逆向结果)。
Python代码扩展
python
def bidirectional_segment(sentence):
fmm_tokens = fmm_segment(sentence)
rmm_tokens = rmm_segment(sentence)
# 选择规则
if len(fmm_tokens) != len(rmm_tokens):
return fmm_tokens if len(fmm_tokens) < len(rmm_tokens) else rmm_tokens
else:
fmm_single = sum(1 for w in fmm_tokens if len(w)==1)
rmm_single = sum(1 for w in rmm_tokens if len(w)==1)
return fmm_tokens if fmm_single < rmm_single else rmm_tokens
print("Bidirectional:", bidirectional_segment("南京市长江大桥"))
# 输出:['南京', '市', '长江大桥']基于机器学习的分词模型
随着机器学习算法的发展,一些机器学习与深度学习方法被应用到中文分词模型中来。事实上,中文分词的核心逻辑就是我得知道在一长串汉字组成的序列中在哪里打分隔符的问题。也就是给定一串序列,我要判断这个字符后面是否需要打上分隔符的一个序列标注问题。对于每个汉字字符,它可以是一个词的词首(B),可以是一个词的词尾(E),可以是一个词的中间(I),也可以单字成词(O),这种标记方法叫BIO标记法。比如:
例子:我爱自然语言处理,因为它可以解决很多实际问题
标注:我-O,爱-O,自-B,然-E,语-B,言-E,处-I,理-E,因-B,为-E,它-O,可-B,以-E,解-B,决-E,很-B,多-E,实-B,际-E,问-B,题-E
那么这也就是对序列里面每个元素做四分类,并且每个字符的标记与前面的序列信息有关。上文的序列信息影响了下一个字的标注。对于序列标注模型,我们常常使用HMM、CRF等机器学习模型,或者配合RNN、LSTM等神经网络结构进行标注。例如,我们可以用CRF训练一个中文分词模型实现功能。
1. CRF的基本原理通俗解释
条件随机场(CRF)是一种用于序列标注的统计模型,其核心思想是**"通过上下文特征预测标签"** 。与HMM等生成式模型不同,CRF直接建模标签之间的依赖关系,能灵活融合多种特征(如当前字、前后字、词性等)。

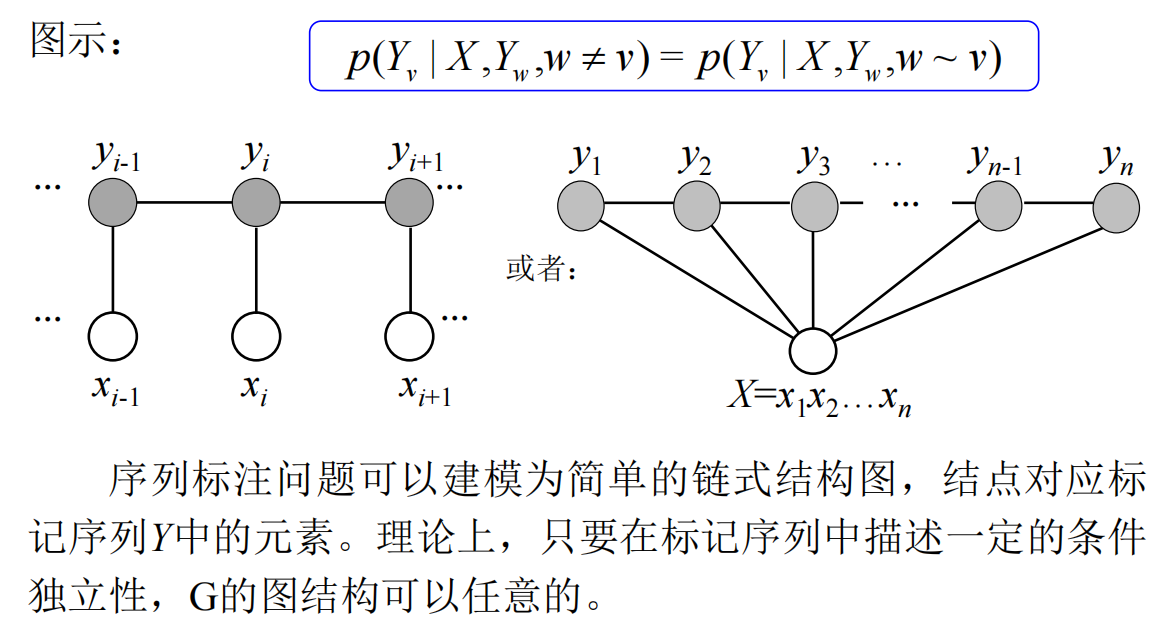
通俗理解 :
假设我们要给句子中的每个字打标签(如B/I/E/S),CRF会考虑以下问题:
- 当前字的特征(例如是否是数字、是否出现在词典中);
- 前一个字和后一个字的标签(例如前一个标签是B,当前标签更可能是I或E);
- 整个句子的全局特征(例如标签序列的合理性)。
数学简化 :
CRF通过以下公式计算标签序列的概率:
\P(y\|x) = \\frac{1}{Z(x)} \\exp\\left( \\sum_{i} \\sum_{k} \\lambda_k f_k(y_{i-1}, y_i, x, i) \\right) \\
- \(Z(x)\) 是归一化因子;
- \(f_k\) 是特征函数(例如"当前字是'的'且标签是E");
- \(\lambda_k\) 是模型学习的权重。
CRF的优势:
- 能处理长距离依赖(例如"南京市长江大桥"中的标签连贯性);
- 避免HMM的独立性假设限制。
2. CRF中文分词的完整代码实现
环境准备
安装依赖库:
bash
pip install sklearn-crfsuite python-crfsuite数据准备(示例)
假设原始数据格式为已分词的句子:
我-O,爱-O,自-B,然-E,语-B,言-E,处-I,理-E,因-B,为-E,它-O,可-B,以-E,解-B,决-E,很-B,多-E,实-B,际-E,问-B,题-E预处理函数将文本转换为CRF所需的特征和标签序列:
python
def load_data(file_path):
sentences = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
words = line.strip().split()
chars, labels = [], []
for word in words:
if len(word) == 1:
labels.append('S') # 单字词
else:
labels += ['B'] + ['I']*(len(word)-2) + ['E']
chars += list(word)
sentences.append((chars, labels))
return sentences
# 示例数据文件:data.txt(内容为"我-O,爱-O,自-B,然-E,语-B,言-E,处-I,理-E,因-B,为-E,它-O,可-B,以-E,解-B,决-E,很-B,多-E,实-B,际-E,问-B,题-E")
sentences = load_data('data.txt')特征提取
定义特征模板,提取每个字的上下文特征:
python
def word2features(sent, i):
word = sent[i]
features = {
'bias': 1.0,
'word': word,
'word.isdigit()': word.isdigit(),
'word[-2:]': word[-2:] if i>0 else '##',
'word[-1:]': word[-1:] if i>0 else '##',
'word[+1:]': sent[i+1][0] if i<len(sent)-1 else '##',
}
return features
def prepare_features(sentences):
X, y = [], []
for sent, labels in sentences:
X_sent = [word2features(sent, i) for i in range(len(sent))]
X.append(X_sent)
y.append(labels)
return X, y
X_train, y_train = prepare_features(sentences)模型训练与预测
使用sklearn-crfsuite库训练CRF模型:
python
import sklearn_crfsuite
from sklearn_crfsuite import metrics
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
crf.fit(X_train, y_train)
# 测试样例
test_sentence = ['我', '爱', '自', '然', '语', '言', '处', '理']
X_test = [word2features(test_sentence, i) for i in range(len(test_sentence))]
labels = crf.predict_single(X_test)
# 合并标签为分词结果
result = []
current_word = []
for char, label in zip(test_sentence, labels):
if label == 'B':
current_word = [char]
elif label == 'I':
current_word.append(char)
elif label == 'E':
current_word.append(char)
result.append(''.join(current_word))
current_word = []
elif label == 'S':
result.append(char)
print("分词结果:", result) # 输出:['我', '爱', '自然', '语言', '处理']随着深度学习技术的兴起,中文分词逐渐从依赖人工特征(如CRF中的模板设计)转向端到端的自动学习。早期的深度学习模型(如BiLSTM、CNN)通过捕捉字符序列的上下文信息,结合CRF层建模标签依赖关系(如BiLSTM-CRF架构),显著提升了分词的鲁棒性。这类模型能够自动学习汉字的分布式表示(Embedding)和长距离语义模式,解决了传统方法对新词和歧义结构的处理瓶颈。例如,BiLSTM的双向结构可同时利用前后文信息,而CRF层则确保标签序列的全局合理性,使得模型在面对"南京市长江大桥"等复杂分词场景时表现更优。比如,LSTM由于其出色的序列建模能力,往往与CRF组合在一起来提升中文分词的准确率。再后来,有了预训练语言模型(PLM)以后,BERT-BiLSTM-CRF被组合起来形成中文分词的骨干架构(backbone)。
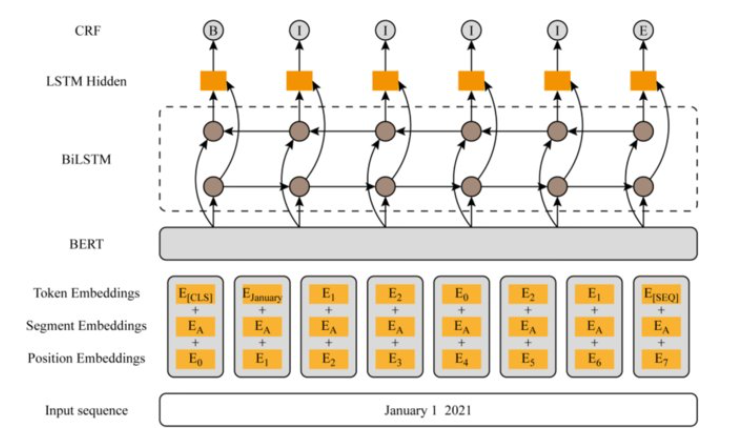
近年来,基于预训练语言模型(如BERT、GPT)的分词方法进一步推动了性能突破。通过大规模语料预训练,模型能够生成深层次的上下文表征,直接支持分词任务。例如,BERT通过掩码语言建模学习汉字的多义性,在下游任务微调后,即使面对专业领域或网络新词(如"绝绝子"),也能实现高精度切分。同时,无监督或弱监督方法(如基于对比学习)开始探索如何降低对标注数据的依赖。然而,这类模型的计算成本较高,且仍需解决领域适应性和标签稀疏性问题。深度学习的引入,标志着中文分词从"规则驱动"迈向"数据驱动",为多模态、多语言场景的扩展奠定了基础。
尝试让大语言模型来分词
让我们来测试一下用大语言模型来分词的效果吧。这个提示词一般不需要很复杂就可以实现,因为这是个简单任务。比如,还是拿deepseek为例:
prompt:请对下面的新闻文本进行中文分词:
比亚迪和鸿蒙智行,一个靠规模摊薄成本,一个用生态重构溢价,智能驾驶赛道允许两种甚至更多生存模式。就在比亚迪把智驾车型打到10万以内的同时,问界M9系列宣布连续10个月登顶50万元级豪华车销量第一。

结果:比亚迪/和/鸿蒙智行/,/一个/靠/规模/摊薄/成本/,/一个/用/生态/重构/溢价/,/智能驾驶/赛道/允许/两种/甚至/更多/生存/模式/。/在/比亚迪/把/智驾/车型/打到/10万/以内/的/同时/,/问界M9/系列/宣布/连续/10个月/登顶/50万元级/豪华车/销量/第一/。
不过日常进行分词工作其实用不上LLM,别啥啥都找LLM就不怕把别人服务器搞崩溃吗?我们用jieba分词就可以了。
python
import jieba
# 待分词的文档
document = "比亚迪和鸿蒙智行,一个靠规模摊薄成本,一个用生态重构溢价,智能驾驶赛道允许两种甚至更多生存模式。就在比亚迪把智驾车型打到10万以内的同时,问界M9系列宣布连续10个月登顶50万元级豪华车销量第一。"
# 使用 jieba 进行分词
words = jieba.cut(document)
# 将分词结果转换为列表
words_list = list(words)
# 打印分词结果
print("分词结果:")
print("/".join(words_list))【备注】:看到那种不管是什么研究方向都想蹭一手大模型(如果你没用LLM他就问你为什么不用LLM)的这种论文审稿人我真的会很想问候他全家并把它打回大一年级去回炉重造。
1.1.4 词性标注问题
在语言学中,词性是对单词进行分类的一种方式,常见的词性包括名词、动词、形容词、副词、介词、连词、代词、数词、量词、叹词等。例如,"我"是代词,"吃"是动词,"苹果"是名词,"非常"是副词,"红色"是形容词。词性标注(Part-of-Speech Tagging,POS)是自然语言处理中的一个重要任务。在机器学习的视角下,词性标注通常被视为一个序列标注问题,其核心思想是为句子中每个单词分配一个正确的词性标签,这类似于在给定输入序列(单词序列)的情况下预测输出序列(词性序列)。
HMM(隐马尔可夫模型)是早期应用较为广泛的词性标注模型之一。它假设词性序列是一个马尔可夫链,当前词的词性仅依赖于前一个词的词性,并且根据发射概率矩阵来确定单词与词性的对应关系。不过,HMM 的假设较为严格,可能会导致某些复杂情况下的标注不够准确。CRF(条件随机场)模型是目前词性标注中更常用的方法。与 HMM 不同,CRF 是判别式模型,直接对观测序列(单词序列)和标签序列(词性序列)之间的条件概率进行建模,可以更灵活地考虑上下文特征,包括前驱词、后继词以及当前词与其上下文的关系等。CRF 模型通过全局训练,使得标注结果更准确,能够更好地捕捉到词性之间的依存关系。
近年来,随着深度学习的发展,基于神经网络的词性标注模型逐渐兴起。例如,LSTM(长短时记忆网络)和 BiLSTM(双向 LSTM)结构能够很好地捕捉序列中的长期依赖关系,被广泛应用于词性标注任务中。此外,自注意力机制(Transformer)也在词性标注等领域取得了一定的成效,能够更好地处理长距离的上下文信息。
在自然语言处理领域,有许多现成的工具可以进行高效的词性标注,以下是一些常用的工具及对应的 Python 代码示例:
示例一:使用 NLTK(Natural Language Toolkit)
NLTK 是一个强大的自然语言处理工具包,提供了众多语言处理功能,包括词性标注。
python
import nltk
# 下载 NLTK 数据集(只需要运行一次)
nltk.download('averaged_perceptron_tagger')
# 待标注的句子
sentence = "我爱自然语言处理,因为它可以解决很多实际问题。"
# 进行词性标注
words = nltk.word_tokenize(sentence)
pos_tags = nltk.pos_tag(words)
# 打印结果
print("NLTK 词性标注结果:")
for word, tag in pos_tags:
print(f"{word}: {tag}")运行结果:
NLTK 词性标注结果:
我: NN
爱: VB
自然语言处理: NN
,: ,
它: NN
可以: MD
解决: VB
很多: JJ
实际: JJ
问题: NN
。: .注意:NLTK 的中文处理支持有限,上述代码适用于英文词性标注,中文词性标注需额外处理。
示例二:使用 Spacy
Spacy 是一个用于工业级自然语言处理的高效工具,提供了多语言的支持,包括中文词性标注。
代码示例:
python
import spacy
# 加载中文模型
nlp = spacy.load('zh_core_web_sm')
# 待标注的句子
sentence = "我爱自然语言处理,因为它可以解决很多实际问题。"
# 进行词性标注
doc = nlp(sentence)
# 打印结果
print("Spacy 词性标注结果:")
for token in doc:
print(f"{token.text}: {token.pos_}")运行结果:
复制
Spacy 词性标注结果:
我: PRON
爱: VERB
自然语言处理: NOUN
,: PUNCT
它: PRON
可以: AUX
解决: VERB
很多: ADV
实际: ADJ
问题: NOUN
。: PUNCT注意事项:在使用这些工具之前,通常需要下载相应的语言模型或数据集。不同工具的词性标注结果可能略有差异,具体结果取决于所在模型的训练数据和标注风格。对于一些特殊的领域或语料,可能需要进行自定义训练以提高标注准确性。
1.2 词汇的组织形式------句法
1.2.1 句法分析
在上一节当中我们已经接触了词法分析的一些基本内容。不同词出现的次序是不同的,比如名词后面很多会接着动词,而动词后面接的更多的是名词或副词等。这是由于不同词性往往在句子中承担不同的语法结构导致的,因为英语句子往往只有一个"主------谓------宾"结构,而主语往往是名词,谓语往往是动词或者系表结构,宾语往往也是名词或者从句居多。我相信在高中英语的课堂上,老师都会带着大家对阅读中的长难句进行一个长难句分析,标注:哪里是主谓宾、哪里是定状补、哪里是从句、从句的主谓宾等等,以及谁修饰谁、谁动作谁,形成一种层级结构。这种层级结构的划定规则其实就是一个语言的句法。
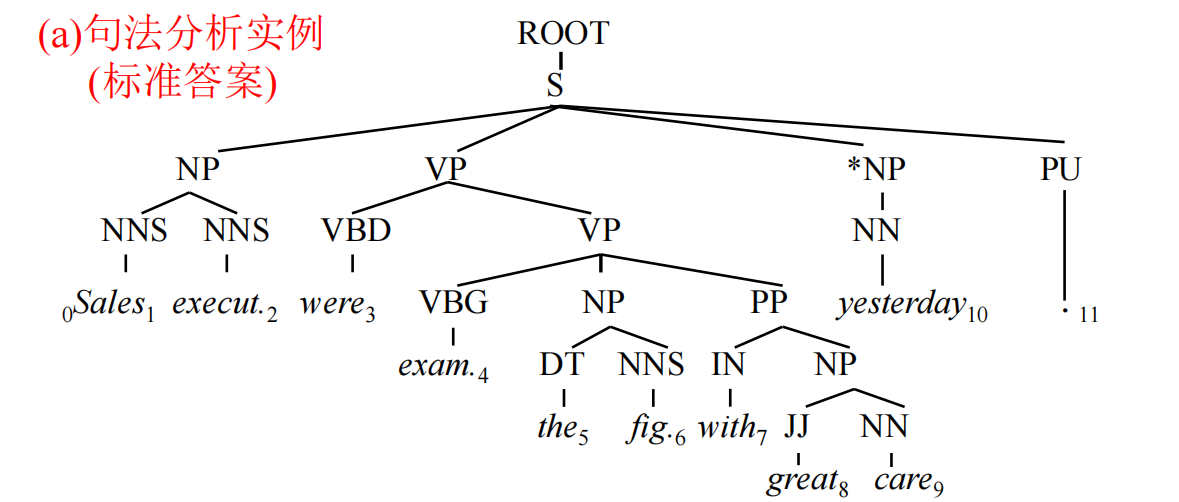
上图是一个句法分析树。
1. 句法的定义与语法元素
句法(Syntax)是语言学中研究句子结构的规则体系,其核心目标是揭示词汇如何通过特定规则组合成合法且有意义的句子。句法的基本单位包括短语 (如名词短语、动词短语)和句子成分(主、谓、宾、定、状、补等)。例如,在句子"聪明的学生认真阅读了图书馆的书籍"中:
- 主语:"学生"(动作的发出者);
- 谓语:"阅读"(核心动作);
- 宾语:"书籍"(动作的承受者);
- 定语:"聪明的"修饰主语,"图书馆的"修饰宾语;
- 状语:"认真"修饰谓语,说明动作的方式;
- 补语:补充说明动作的结果或状态(如"他跑得很快"中的"很快")。
句法规则通过层级结构(如树形结构)描述成分间的依存或并列关系,例如"主谓结构""动宾结构"等。
2. 句法分析的任务与方法
句法分析(Syntactic Parsing)是指从句子中提取语法结构的过程,目标是生成句子的形式化表示(如依存树或短语结构树)。主要方法包括:
- 基于规则的方法:依赖人工设计的语法规则(如上下文无关文法),通过模式匹配推导结构,适用于结构规整的句子,但对复杂语言现象泛化能力差。
- 统计方法:利用标注语料库(如宾州树库)训练概率模型(如PCFG概率上下文无关文法),通过最大似然估计选择最优结构。
- 深度学习方法:基于神经网络(如Transformer、图神经网络)直接建模句子的全局依赖关系,典型模型包括BERT+CRF、依存解析器(如Biaffine Parser),能够自动捕捉长距离依赖和上下文特征。
例如,句子"他送老师一束花"的依存分析结果可能为:
- "送"为核心动词,依存关系为"主谓"(他→送)和"动宾"(送→花);
- "老师"为间接宾语(送→老师),修饰关系为"介宾"(送→老师);
- "一束"为数量修饰(花→一束)。
如果我们用大语言模型进行句法分析,我们可以观察一下句法分析出来的一个语法结构树(AST):
prompt: 请对下面的中文句子进行句法分析,给出语法结构树(AST):
鼠疫是由鼠疫耶尔森菌引起的一种自然疫源性烈性传染病
分析结果:

S
/ \
NP VP
| / \
鼠疫 V NP
| |
是 NP
/ \
AdvP NP
/ \
由鼠疫耶尔森菌引起 NP
/ \
一种 NP
/ \
自然疫源性 NP
/ \
烈性 传染病3. 语义角色与语义角色标注
语义角色(Semantic Role)指句子中成分在动作或事件中承担的功能意义,例如:
- 施事(Agent):动作的发起者(如"猫抓老鼠"中的"猫");
- 受事(Patient):动作的承受者(如"老鼠");
- 工具(Instrument):动作使用的工具(如"用钥匙开门"中的"钥匙");
- 时间/地点(Time/Location):事件发生的时空背景(如"在公园散步"中的"公园");
- 目标(Goal):动作的终点(如"跑向终点"中的"终点")。
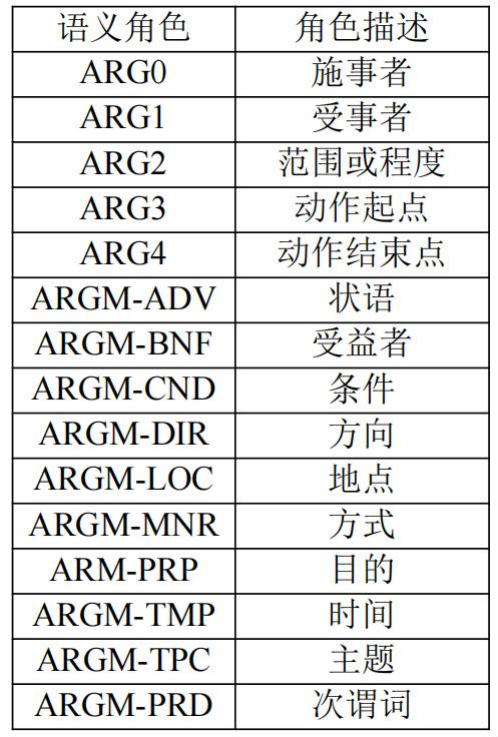
语义角色标注(Semantic Role Labeling, SRL) 的任务是识别句子中每个成分的语义角色,并标注其类型。例如,在句子"小明用手机给朋友发送了生日祝福"中:
- "小明"标注为施事(Agent);
- "手机"标注为工具(Instrument);
- "朋友"标注为目标(Goal);
- "生日祝福"标注为受事(Patient)。
SRL的实现通常结合句法分析与语义模型(如PropBank框架),通过特征模板或深度学习(如LSTM+CRF)预测角色标签,为问答系统、信息抽取等任务提供深层语义理解。
比如说,如果还是针对上面的句子案例,让大模型帮我们标注句子中的语义角色,结果形如:
主题(Theme):鼠疫
├─ 动作(Action):是
└─ 属性(Attribute):一种自然疫源性烈性传染病
├─ 数量修饰(Modifier):一种
├─ 类别修饰(Modifier):自然疫源性
├─ 性质修饰(Modifier):烈性
└─ 中心语(Head):传染病
└─ 施事(Agent):鼠疫耶尔森菌
└─ 动作(Action):引起句法分析是连接表层语言与深层语义的桥梁,其发展从规则驱动到数据驱动,逐步实现了对复杂语言现象的更精准建模。语义角色标注则进一步将句法结构映射到事件逻辑,为机器理解人类语言提供了结构化语义框架。
1.2.2 早期句法分析方法
早期句法分析方法
1. 基于规则的句法分析方法
基于规则的句法分析是自然语言处理中最早期的技术之一,其核心思想是通过人工设计的语法规则解析句子结构。主要方法包括:
- 上下文无关文法(Context-Free Grammar, CFG):定义一组规则描述句子的层次结构,例如"S → NP VP"表示句子由名词短语和动词短语组成。CFG通过递归推导生成句子的语法树,适用于结构规整的句子。
- 依存文法(Dependency Grammar):直接描述词语间的依存关系(如主谓、动宾),形成依存树而非短语结构树。例如,"喜欢→小明"表示"喜欢"是核心词,"小明"是其依赖项。
- 转移系统(Transition-Based Parsing):通过状态转移动作(如移进、规约)逐步构建句法树,结合栈和缓冲区实现高效解析。
这些方法依赖语言学知识和人工规则设计,能够处理特定领域的语言现象,但对复杂句式和歧义结构的泛化能力有限。
2. 上下文无关文法与PCFG的Python实现
上下文无关文法(CFG)
以下是一个简单的CFG实现,用于解析句子"小明喜欢读书":
python
import nltk
# 定义CFG规则
cfg_rules = """
S -> NP VP
NP -> '小明'
VP -> V NP
V -> '喜欢'
NP -> '读书'
"""
# 创建CFG解析器
cfg_parser = nltk.CFG.fromstring(cfg_rules)
# 解析句子
sentence = "小明 喜欢 读书".split()
for tree in cfg_parser.parse(sentence):
print(tree)概率上下文无关文法(PCFG)
PCFG在CFG基础上引入规则概率,以下是一个简单实现:
python
from nltk import PCFG, ViterbiParser
# 定义PCFG规则
pcfg_rules = """
S -> NP VP [1.0]
NP -> '小明' [0.6] | '读书' [0.4]
VP -> V NP [1.0]
V -> '喜欢' [1.0]
"""
# 创建PCFG解析器
pcfg_parser = ViterbiParser(PCFG.fromstring(pcfg_rules))
# 解析句子
sentence = "小明 喜欢 读书".split()
for tree in pcfg_parser.parse(sentence):
print(tree)代码说明
- CFG:通过规则描述句子的短语结构,生成所有可能的语法树;
- PCFG:引入概率选择最可能的语法树,适用于歧义句子的解析。
3. 早期句法分析方法的问题
尽管基于规则的方法在特定领域表现良好,但其局限性显著:
- 规则设计复杂:人工编写规则耗时费力,且难以覆盖所有语言现象;
- 泛化能力差:对未见过的新句式或复杂结构(如长距离依赖)处理能力有限;
- 歧义问题:同一句子可能对应多种语法树,规则方法难以选择最优解;
- 领域依赖性:规则通常针对特定领域设计,跨领域适应性差;
- 扩展性不足:随着语言变化(如网络新词、新兴句式),规则库需频繁更新。
这些问题促使研究者转向统计和深度学习方法,通过数据驱动提升模型的泛化能力和鲁棒性。
总结
基于规则的句法分析为自然语言处理奠定了重要基础,但其局限性推动了后续技术的演进。上下文无关文法和PCFG作为经典方法,仍在小规模、特定领域任务中发挥作用,而现代方法(如神经网络解析器)则通过端到端学习实现了更强大的语言理解能力。
1.2.3 依存句法分析
1. 依存句法与依存句法分析
依存句法(Dependency Syntax)是一种描述句子中词语间主从关系 的语法理论。其核心假设是:句子中的每个词(除根节点外)依存于且仅依存于一个中心词,形成非对称的二元关系。例如,在句子"小明喜欢读书"中:
- "喜欢"是核心动词(根节点);
- "小明"依存于"喜欢"作为主语(主谓关系);
- "读书"依存于"喜欢"作为宾语(动宾关系)。
依存句法分析(Dependency Parsing) 的任务是自动识别句子中所有词语间的依存关系,并构建依存树。与短语结构分析不同,依存树直接表示词与词之间的修饰、主谓、动宾等关系,更强调功能而非层次结构。
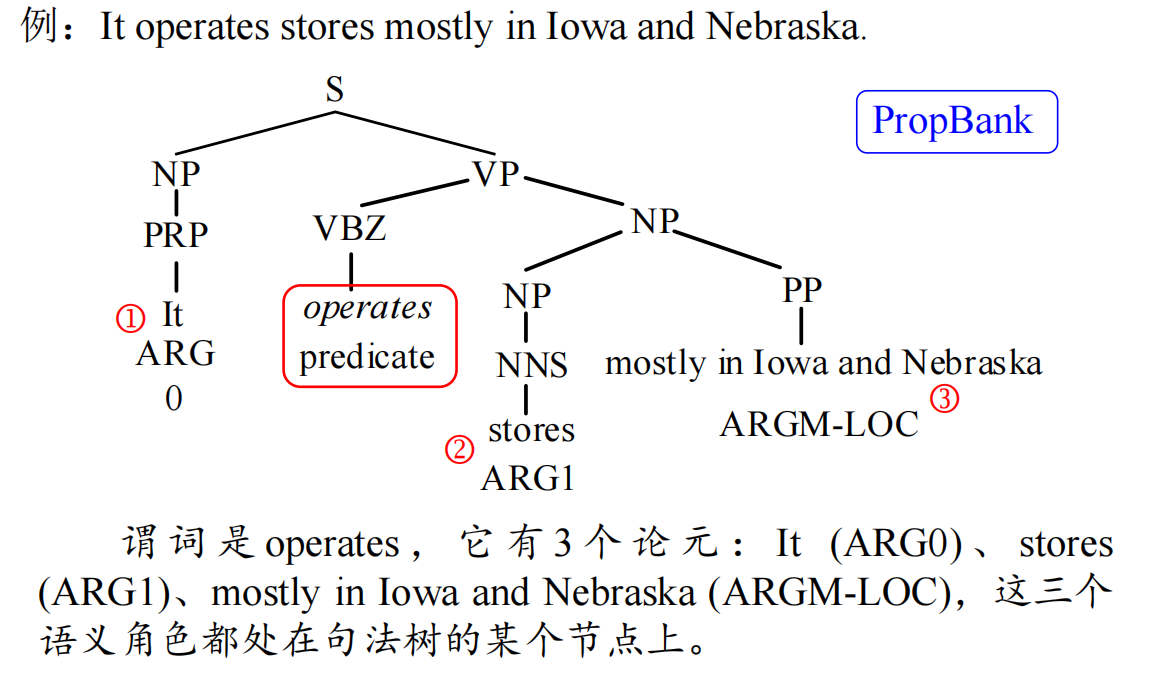
2. 依存句法分析模型的评价指标
评价依存句法分析模型性能的主要指标包括:
- 无标记准确率(UAS, Unlabeled Attachment Score):预测的依存关系是否正确(不考虑标签类型);
- 带标记准确率(LAS, Labeled Attachment Score):预测的依存关系及标签(如主谓、动宾)均正确;
- 根节点准确率(Root Accuracy):根节点是否被正确识别。
例如,若模型将"读书"错误地标注为"喜欢"的定语(应为宾语),则UAS和LAS均会扣分。此外,还需关注跨领域性能 (如新闻 vs. 社交媒体)、长距离依赖处理能力 (如嵌套从句)及计算效率(实时性要求)。
3. 机器学习与深度学习的依存句法分析发展
-
统计机器学习方法(2000s):
- 基于转移的方法(Transition-Based):通过状态转移动作(如移进、左/右规约)逐步构建依存树,结合支持向量机(SVM)或感知机进行动作预测。代表模型包括MaltParser。
- 基于图的方法(Graph-Based):将依存分析建模为图的最大生成树问题,通过动态规划或贪心算法求解。代表模型包括Eisner算法。
-
深度学习方法(2010s后):
- BiLSTM+MLP:利用双向LSTM编码上下文信息,通过多层感知机预测依存关系标签。
- Biaffine Attention:通过双仿射变换建模词对间的依存得分,显著提升长距离依赖处理能力。
- Transformer-Based:借助自注意力机制捕捉全局依赖,结合CRF层优化标签序列。
例如,Stanford Neural Dependency Parser采用BiLSTM和Biaffine机制,在多个语料库(如UD)上达到SOTA性能。
4. 基于大语言模型的依存句法分析发展
随着预训练语言模型(如BERT、GPT、T5)的崛起,依存句法分析进入新阶段:
- 隐式依存建模:大语言模型通过自监督预训练(如掩码语言建模)隐式学习句法知识,无需显式标注即可生成高质量依存树。例如,BERT的注意力头可自动捕获主谓一致等语法模式。
- 参数高效微调:通过Adapter或Prompt Tuning技术,在少量标注数据下适配大模型至依存分析任务。
- 多语言统一建模:XLM-R等跨语言模型通过共享参数,实现对多语言依存关系的联合解析。
挑战与趋势:
- 可解释性:大模型的"黑箱"特性使依存关系难以追溯;
- 领域迁移:通用预训练模型在医学、法律等垂直领域表现不稳定;
- 端到端联合学习:将依存分析与语义角色标注、共指消解等任务联合建模,提升整体语言理解能力。
总结
依存句法分析从早期的规则驱动到数据驱动,再到大模型时代的隐式学习,逐步实现了对复杂语言现象的更精准建模。未来,结合符号逻辑与神经网络的混合方法、轻量化部署技术及多任务协同优化,将是提升实用性和泛化能力的关键方向。
1.3 篇章内容的分析
1.3.1 篇章内容的表示
前面我们看完了词法,看完了句法,接下来该轮到整个的篇章了。篇章表示方法是自然语言处理和语言学研究中的一个重要领域,它旨在通过对篇章结构和内容的分析,揭示文本的内在逻辑和意义。篇章表示方法可以分为两大类:传统的语言学篇章表示理论和基于深度学习的篇章表示方法。
语言学篇章表示理论
语言学篇章表示理论主要关注篇章的结构和组织方式,通过分析篇章中的各种关系来理解其整体意义。其中,词汇链、事件链和话题链是三种重要的分析手段。
- 词汇链是指篇章中词汇之间的语义关联,通过词汇链可以揭示篇章中词汇的重复和替换关系,从而帮助理解篇章的主题和内容。事件链则关注篇章中事件的顺序和逻辑关系,通过事件链可以清晰地展示事件的发展过程和因果关系。话题链则是指篇章中话题的转换和延续,通过话题链可以把握篇章的结构和逻辑线索。
- 修辞结构理论(Rhetorical Structure Theory, RST)是另一种重要的篇章表示方法,它关注篇章中的修辞关系,如因果、转折、并列等。修辞结构理论将篇章视为由多个修辞单元组成的结构,每个修辞单元之间存在特定的修辞关系。通过对这些修辞关系的分析,可以揭示篇章的逻辑结构和作者的写作意图。
- 汉语广义话题结构理论则关注汉语篇章中的话题结构,强调话题在篇章中的核心地位。该理论认为,汉语篇章通常以话题为中心展开,通过话题的转换和延续来组织篇章内容。通过对汉语广义话题结构的分析,可以更好地理解汉语篇章的结构特点和逻辑关系。
基于深度学习的篇章表示
随着深度学习技术的发展,基于深度学习的篇章表示方法逐渐成为研究的热点。深度学习模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等,能够自动学习篇章的语义表示,从而为篇章分析提供强大的工具。这些模型通过对大量文本数据的学习,能够捕捉到篇章中的语义和结构信息,从而实现对篇章的自动表示和分析。
基于深度学习的篇章表示方法具有很强的灵活性和适应性,能够处理复杂的篇章结构和语义关系。通过深度学习模型,可以实现篇章的自动分类、情感分析、主题提取等多种任务,为自然语言处理和文本分析提供了新的思路和方法。
1.3.2 篇章内容的分析
在篇章分析中,广泛存在着一系列亟待研究的问题,例如:

这些可都是自然语言处理领域实打实的难题。当然大家不知道这些东西是什么意思没关系,本教程只负责带大家了解一个基本概念入个门就好。更多的其实可以等大家看完本教程以后自行深入研究。
自然语言处理(NLP)中的篇章分析是对文本篇章(即较长的文本,如文章、故事、对话等)进行多层次、多角度的分析,旨在理解篇章的结构、语义、逻辑关系以及表达意图等。篇章分析通常包括以下几个方面:
- 篇章结构分析
篇章结构分析关注篇章的整体组织方式和层次结构,主要包括以下几个方面:
- 段落划分:识别篇章中的段落边界,理解段落之间的逻辑关系(如并列、递进、转折等)。
- 句子边界检测:识别句子的起始和结束位置,为后续的句法和语义分析提供基础。
- 层次结构分析:通过构建篇章的层次结构树(如基于修辞结构理论 RST),分析篇章中各个部分之间的关系。
- 篇章语义分析
篇章语义分析关注篇章中词语、句子以及段落的语义关系,主要包括以下几个方面:
词汇链分析:识别篇章中重复出现或语义相关的词汇,分析词汇之间的语义关联,帮助理解篇章的主题和内容。
- 事件链分析:识别篇章中描述的事件及其发展过程,分析事件之间的因果、时间、逻辑等关系。
- 话题链分析:识别篇章中的主要话题及其转换,分析话题的延续和切换,帮助理解篇章的逻辑线索。
- 篇章关系分析
篇章关系分析关注篇章中各个部分之间的逻辑和修辞关系,主要包括以下几个方面:
- 逻辑关系分析:识别篇章中句子或段落之间的逻辑关系,如因果、转折、并列、递进等。
- 修辞关系分析:识别篇章中的修辞手法,如比喻、夸张、对比等,分析其对篇章表达效果的影响。
- 引用和指代消解:识别篇章中的代词、名词短语等指代内容,分析其指代关系,帮助理解篇章的连贯性。
- 篇章风格分析
篇章风格分析关注篇章的语言风格和表达方式,主要包括以下几个方面:
- 词汇和句法风格:分析篇章中词汇的使用频率、句法结构的复杂性等,判断篇章的语言风格(如正式、口语、文学等)。
- 修辞风格:分析篇章中的修辞手法,判断其对篇章表达效果的影响。
- 情感和态度分析:识别篇章中的情感倾向和作者的态度,分析其对篇章主题的影响。
- 篇章主题和意图分析
篇章主题和意图分析关注篇章的核心内容和作者的表达意图,主要包括以下几个方面:
- 主题提取:识别篇章中的主要主题和关键词,帮助理解篇章的核心内容。
- 意图识别:分析作者的写作意图,如说明、论述、劝说、描述等,帮助理解篇章的表达目的。
- 摘要生成:根据篇章的主要内容和逻辑结构,生成篇章的摘要,帮助快速理解篇章的核心信息。
- 篇章连贯性和一致性分析
篇章连贯性和一致性分析关注篇章的整体连贯性和一致性,主要包括以下几个方面:
- 连贯性分析:分析篇章中句子和段落之间的衔接关系,判断篇章是否连贯。
- 一致性分析:分析篇章中的内容是否一致,是否存在矛盾或不一致的地方。
- 逻辑推理:通过逻辑推理,判断篇章中的内容是否合理,是否存在逻辑漏洞。
- 篇章生成
篇章生成是篇章分析的逆过程,关注如何根据给定的主题、意图和内容生成连贯、合理的篇章。主要包括以下几个方面:
- 规划和组织:根据给定的主题和意图,规划篇章的结构和内容,确定段落和句子的顺序。
- 内容生成:根据规划的结构和内容,生成具体的句子和段落,确保篇章的连贯性和一致性。
- 修辞和风格:根据篇章的风格要求,选择合适的词汇和句法结构,确保篇章的表达效果。
大家有考研的朋友吗?听过唐迟老师的课的举个手我看看。唐迟老师在课上反复强调------阅读的本质是逻辑,逻辑的本质是词汇,这个话并没有说错。下面,我以句间逻辑、段间逻辑、事件链分析三个篇章分析任务为例,让大模型帮我分析一篇英语阅读的逻辑。由于这个问题需要涉及逻辑理解和推理,我们要把长思考功能打开。大家可以使用kimi-1.5-长思考或者deepseek-r1推理模型。
prompt: 假如你是新高考的高三考生正在考场上写一份英语试卷,请帮我分析这篇英语文章不同段落之间的逻辑关系

大模型回答如下:
The six paragraphs in the passage are structured to tell a story of the author's evolving relationship with philosophy, from initial enthusiasm to disillusionment and then to a rekindled love. Here is a breakdown of the logical relationships between the paragraphs:
- Paragraph 1: Introduction to the Author's Early Engagement with Philosophy
- Content: The author describes how they were introduced to philosophy at the age of 13 through Jostein Gaarder's Sophie's World and spent the summer deeply engaged with the book.
- Logical Relationship: This paragraph sets the stage by establishing the author's initial enthusiasm for philosophy and the impact of Sophie's World on their intellectual development. It serves as the foundation for the rest of the passage.
- Paragraph 2: The Dampening Effect of College on the Author's Love for Philosophy
- Content: The author explains how their love for philosophy was diminished during college due to encounters with people who claimed to understand complex philosophers better than others and tried to explain them in a condescending manner.
- Logical Relationship: This paragraph introduces a negative experience that contrasts with the positive introduction to philosophy in the first paragraph. It explains why the author's interest in philosophy waned, creating a turning point in the narrative.
- Paragraph 3: Rekindling the Love for Philosophy through The Socrates Express
- Content: The author discusses how Eric Weiner's The Socrates Express reignited their passion for philosophy. The book is described as an invitation to think and experience philosophy rather than a mere explanation.
- Logical Relationship: This paragraph marks a new phase in the author's journey, contrasting the negative experience in college with the positive impact of Weiner's book. It sets up the detailed discussion of the book's content and impact in the following paragraphs.
- Paragraph 4: Detailed Analysis of The Socrates Express
- Content: The author provides a detailed analysis of The Socrates Express, explaining how Weiner structures each chapter around a train ride and frames each philosopher's work in the context of a specific life lesson. The book is described as a guide to improving life through philosophy.
- Logical Relationship: This paragraph builds upon the previous paragraph by providing a more in-depth look at the book, reinforcing the idea that it is a transformative and engaging work. It delves into the specifics of the book's structure and content.
- Paragraph 5: The Author's Personal Engagement with The Socrates Express
- Content: The author reflects on their personal experience with The Socrates Express, emphasizing how the book makes philosophical thought appealing and improves the quality of life. They also mention Weiner's humor and his ability to decode and interpret the messages of important philosophers.
- Logical Relationship: This paragraph connects the detailed analysis of the book's content with the author's personal experience, providing a subjective perspective that complements the objective analysis. It shows how the book has affected the author on a personal level.
- Paragraph 6: Conclusion and Recommendation
- Content: The author concludes by summarizing the impact of The Socrates Express and recommending it to readers. They highlight the book's ability to draw readers in with its simplicity and engage them in deeper thoughts on various life topics.
- Logical Relationship: This paragraph ties together the entire narrative, providing a final endorsement of The Socrates Express and leaving the reader with a clear call to action. It reinforces the author's positive assessment of the book and encourages readers to explore it.
- Summary of Logical Relationships
- Introduction: Establishes the author's initial enthusiasm for philosophy through Sophie's World.
- Negative Experience: Contrasts the initial enthusiasm with the dampening effect of college.
- Rekindling: Introduces The Socrates Express as the catalyst for renewed interest.
- Detailed Analysis: Provides an in-depth look at the book's structure and content.
- Personal Engagement: Reflects on the author's personal experience with the book.
- Conclusion and Recommendation: Summarizes the book's impact and recommends it to readers.
- The passage flows logically from the author's early experiences with philosophy, through a period of disillusionment, to the rekindling of their interest through The Socrates Express. Each paragraph builds upon the previous one, creating a coherent and engaging narrative.
其实到此,它对长文本的语义理解已经比较好的了。但我们还不满意,还希望它在此基础上进一步精简一点,直接告诉我段落之间的关系。于是,我们进一步提问,得到这样的回复:
Paragraph 1 and Paragraph 2: Contrast
Logical Relationship: The two paragraphs form a contrast, showing how the author's initial enthusiasm was followed by disillusionment.
Paragraph 2 and Paragraph 3: TransitionLogical Relationship: The two paragraphs mark a transition, moving from the negative experience to a positive reawakening of interest.
Paragraph 3 and Paragraph 4: ElaborationLogical Relationship: The two paragraphs are connected by elaboration, with the fourth paragraph expanding on the points made in the third.
Paragraph 4 and Paragraph 5: Personal ReflectionLogical Relationship: The two paragraphs are connected by personal reflection, with the fifth paragraph providing a subjective perspective on the book discussed in the fourth.
Paragraph 5 and Paragraph 6: ConclusionLogical Relationship: The two paragraphs are connected by conclusion, with the sixth paragraph summarizing the book's impact and encouraging readers to explore it.
只要把这个总结出来了,做主旨大意题不是手拿把掐?当然,提示词还可以进行进一步修改,我们会在后续章节讲讲提示词工程的技巧。我们继续探索一下事件链分析。直接提问,得到大模型的回复:
Event Chain and Summary
Event Chain:
- Introduction to Philosophy: The author was introduced to philosophy at the age of 13 through Jostein Gaarder's Sophie's World, which sparked a deep interest in the subject.
- Dampening Effect of College: The author's love for philosophy was diminished during college due to encounters with people who claimed to understand complex philosophers better than others and tried to explain them in a condescending manner.
- Rekindling Interest with The Socrates Express: Eric Weiner's The Socrates Express: In Search of Life Lessons from Dead Philosophers reignited the author's passion for philosophy by inviting them to think and experience philosophy rather than just explaining it.
- Detailed Analysis of The Socrates Express: The author provides a detailed analysis of the book's structure and content, explaining how each chapter is framed around a train ride and a specific life lesson from a philosopher.
- Personal Engagement with The Socrates Express: The author reflects on their personal experience with the book, emphasizing how it makes philosophical thought appealing and improves the quality of life.
- Conclusion and Recommendation: The author concludes by summarizing the impact of The Socrates Express and recommending it to readers, highlighting its ability to engage readers in deeper thoughts on various life topics.
Summary :
The passage follows the author's journey with philosophy, starting from their early introduction to the subject through Sophie's World, through a period of disillusionment during college, and then to a rekindled interest sparked by The Socrates Express. The author details how The Socrates Express reawakened their love for philosophy by providing a fresh and engaging perspective, and they recommend the book to others for its ability to improve the quality of life through philosophical thought.
这个逻辑关系,我想,应该比较清晰了吧。大语言模型,正是为了长篇章上下文语义和逻辑学习而发挥作用的。加上长时间思考的推理能力,对复杂语义逻辑的理解又上了一层楼。