一、总体方案
目前在使用 DeepSeek 在线环境时,页面经常显示"服务器繁忙,请稍后再试",以 DeepSeek R1 现在的火爆程度,这个状况可能还会持续一段时间,所以这里给大家提供了 DeepSeek R1 +RAG 的本地部署方案。最后实现的效果是,结合本地部署的三个开源工具,包括 1Panel、Ollama、MaxKB,可以快速搭建一个本地知识库。以下总体方案及说明如下:

首先基于 GPU 服务器承载 DeepSeek-R1 大模型,其次基于 1Panel 新一代的 Linux 开源运维管理面板完成 MaxKB 和 Ollama 的安装运维管理,最后通过 Ollama 安装管理 DeepSeek-R1 模型,最后再通过 MaxKB 完成本地知识库的搭建,让企业快速构建本地 AI 知识库。
1.1 DeepSeek
DeepSeek是杭州深度求索公司开源出来的AI大模型,在一些典型的应用场景,比如智能对话、文本生成、计算推理、代码生成等场景,表现都非常不错。它有两款大模型,目前在全球都很受关注,分别是 DeepSeek-V3 和 DeepSeek-R1 两个大版本。DeepSeek 在综合能力方面,跟国外 OpenAI o1 版本大模型的性能,基本不相上下。不管是训练成本,还有使用成本,都远低于国外同类型的大模型,可以说是好用又便宜。DeepSeek 在线对话,提供深度思考和联网搜索两种模式
大家可以访问 DeepSeek 官网体验对话效果,官网地址: https://www.deepseek.com/ 或者 https://ai.com/ 。
1.2 RAG
RAG 是 "Retrieval-Augmented Generation" 的缩写,中文可以翻译为"检索增强生成"。这是一种结合了检索(Retrieval)和生成(Generation)的自然语言处理技术,用于提高语言模型在特定任务上的性能和准确性。在加上一个数据向量和索引的工作,我们对 RAG 就可以总概方式地理解为" 索引、检索和生成 "。

-
检索(Retrieval):在这个阶段,模型会从预先构建的大规模数据集中检索出与当前任务最相关的信息。这些数据集可以是文档、网页、知识库等。
-
生成(Generation):在检索到相关信息后,模型会使用这些信息来生成答案或完成特定的语言任务。这个阶段通常涉及到序列生成技术,如基于 Transformer 的模型。

-
创建索引:将输入的文档切割成不同的数据块,进行向量化处理后,存储到向量数据库,并创建索引。
-
向量检索:将用户的提问信息向量化,再到向量数据库进行搜索,根据向量相似度的算法,寻找相关性最强的文档片段。
1.3 开源三件套介绍
1.3.1 1Panel:新一代的 Linux 服务器运维管理面板
通过 Web 图形界面轻松管理 Linux 服务器,实现主机监控、文件管理、数据库管理、容器管理等功能。
官方网址:https://1panel.cn/
下载地址:https://1panel.cn/docs/installation/online_installation/
1.3.2 Ollama:LLM(大型语言模型)服务管理工具
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、DeepSeek、Qwen、Gemma 等开源的大型语言模型。
官网地址: https://ollama.com/
1.3.3 MaxKB:基于大语言模型和 RAG 的开源知识库问答系统
MaxKB = Max Knowledge Base,是一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。
结合 RAG 技术架构,其主要有三部分组成,分别是数据索引,数据检索和数据生成。
对于 MaxKB 来说,数据索引的过程,基本是直接由 MaxKB 服务后台完成。当用户在 MaxKB 知识库页面,上传文档后,文档被分割成不同的数据块,每个数据块经过向量化处理,再存储到向量数据库。接下来是数据检索过程,当用户向 MaxKB 应用提问时,提问信息也会被 MaxKB 后台进行向量化处理,然后从向量数据库中,搜索相似度最高的向量数据。最后是数据生成过程, MaxKB 会把向量数据库检索到结果,当成提示词丢给 AI 大模型,最后在 MaxKB 页面上输出回复信息。
更多详细内容,可以查看 MaxKB 官方网址:https://maxkb.cn/index.html
以及 MaxKB 安装包下载地址:https://maxkb.cn/docs/installation/offline_installtion/
二、具体操作说明
整个解决方案需要依赖开源三件套,并最终通过六步完成总体部署实施,最终构建本 AI 知识库。

2.1 第一步:准备服务器
首先我们需要准备一台本地 GPU 服务器,其中 GPU 主要为 DeepSeek R1 大模型提供资源,本操作步骤全部基于腾讯云的 GPU 服务器,大家可以根据自己具体情况选择本地服务器。腾讯云的 GPU 服务器在开机时,默认会自动安装好 Nvidia GPU 驱动。

当带 GPU 资源的腾讯云服务器准备好之后,如果已安装好 GPU 驱动,在服务器终端输入 nvidia-smi,可以看到以下显示信息。

2.2 第二步:安装 1Panel
浏览器访问 https://community.fit2cloud.com/#/products/1panel/downloads,下载好 1Panel 离线包安装包,并上传到腾讯云服务器的 /tmp 目录,执行 tar -xvf 命令,解压安装包。

进入安装包的解压目录,执行 bash install.sh,服务器开始安装 1Panel。

安装成功后,日志会显示 1Panel 服务的访问地址信息。

为方便 1Panel 安装其它开源工具时,能快速下载 Docker 镜像,这里需要配置 Docker 镜像加速器。/etc/docker/daemon.json 配置文件内容如下:
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://proxy.1panel.live",
"https://9f73jm5p.mirror.aliyuncs.com",
"https://docker.ketches.cn"
]
}/etc/docker/daemon.json 配置文件修改,需要 重启 Docker 服务。

接下来在 1Panel 服务器提前拉取 ollama/ollama:0.5.7 镜像,1panel/maxkb:v1.10.0-lts 镜像,可以节省在 1Panel 页面上安装 Ollama 和 MaxKB 应用的时间。

需要注意的是,Ollama 容器如果想使用服务器的 GPU 资源,操作系统需要提前安装 NVIDIA Container Toolkit,这是 NVIDIA 容器工具包。以 CentOS 7.9 操作系统为例,安装步骤如下:
1、添加 NVIDIA 的 GPG 密钥和仓库:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo2、安装 NVIDIA Container Toolkit:
sudo yum install -y nvidia-container-toolkit
3、重启 Docker 服务:
sudo systemctl restart docker



如果是其它操作系统,也可以参考以上步骤来安装 NVIDIA Container Toolkit。
2.3 第三步:安装 Ollama
登录 1Panel 页面,在"应用商店",切换到"AI/大模型",点击 Ollama 的"安装"按钮。
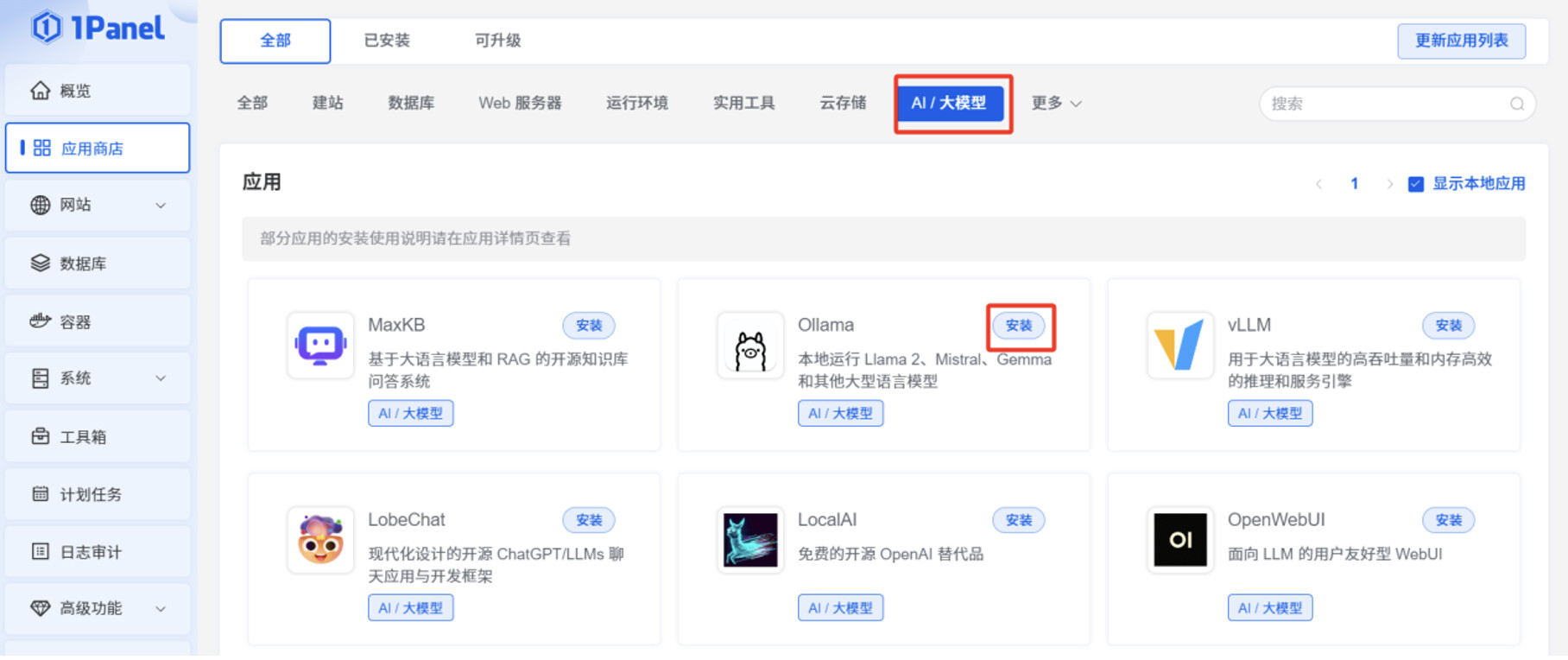
打开"端口外部访问"。

勾选"编辑 compose 文件",将以下文本内容粘贴到输入框,此文件作用是,让 Ollama 容器在启动时,可以调用服务器本身的 GPU 资源。
networks:
1panel-network:
external: true
services:
ollama:
container_name: ${CONTAINER_NAME}
deploy:
resources:
limits:
cpus: ${CPUS}
memory: ${MEMORY_LIMIT}
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
image: ollama/ollama:0.5.7
labels:
createdBy: Apps
networks:
- 1panel-network
ports:
- ${HOST_IP}:${PANEL_APP_PORT_HTTP}:11434
restart: unless-stopped
tty: true
volumes:
- ./data:/root/.ollama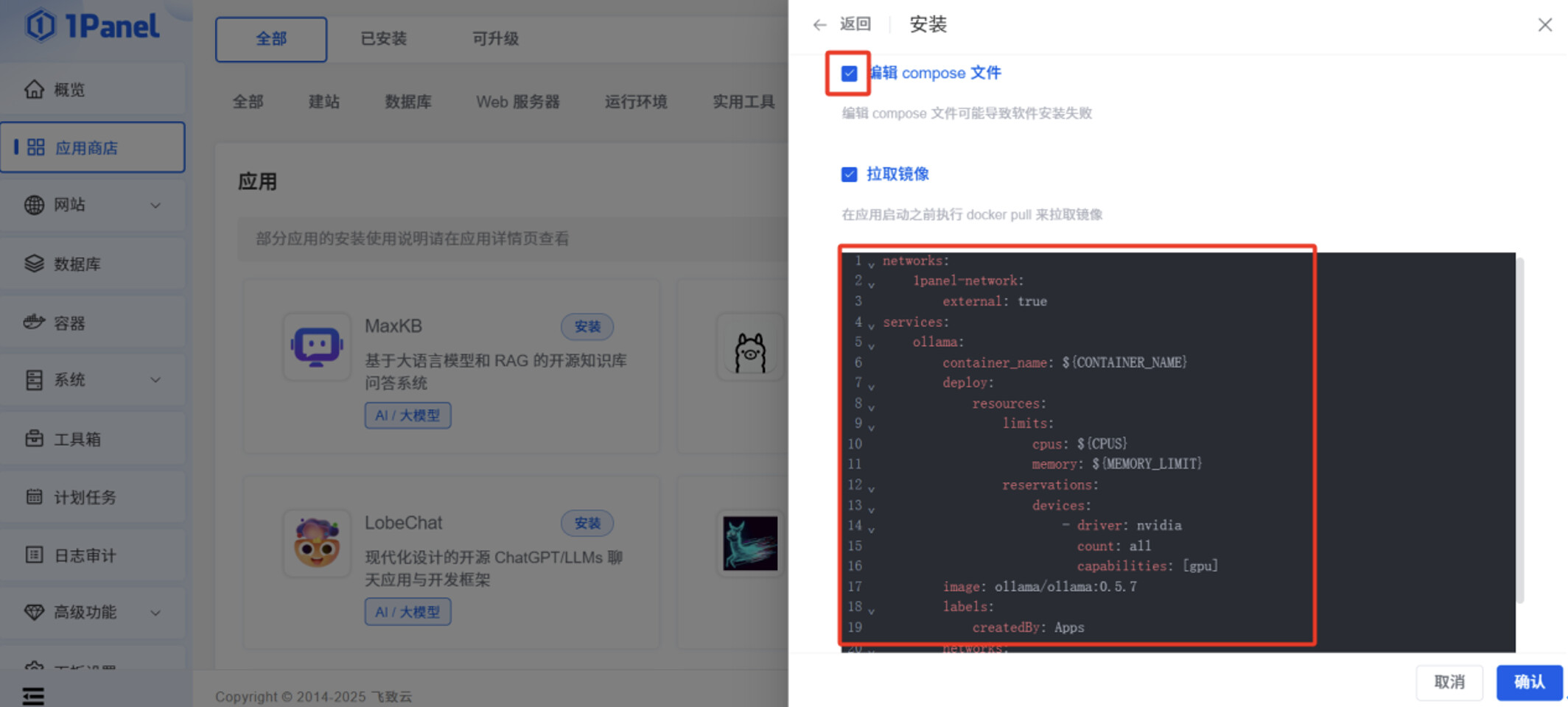
点击"确认"后,在 1Panel 页面可以看到 Ollama 应用是"已启动"状态。

浏览器访问服务器 IP:11434,可以看到 "Ollama is running" 的显示信息。

点击"容器"菜单的"日志"操作,在容器日志,可以看到 Ollama 容器已正常使用 GPU 资源。

点击"容器"菜单的"终端"操作,再点击"连接",进入 Ollama 容器的终端命令行。

执行 ollama pull deepseek-r1:7b 命令,此命令的执行时间较长,取决于 DeepSeek 参数规模的大小。提前下载 deepseek-r1:7b 大模型的安装包到本地,方便后续在 MaxKB 页面可以快速对接deepseek-r1:7b 大模型。

由于 Ollama 官网的网速限制,ollama pull 执行过程中,deepseek-r1:7b 安装包下载速度会持续降低,可以通过 ctrl+c 中断命令,再次执行 ollama pull deepseek-r1:7b 命令,下载速度会慢慢恢复正常。这个操作过程可能会持续多次。
2.4 第四步:安装MaxKB
在 1Panel 页面的"应用商店",切换到"AI 大模型",点击 MaxKB 的"安装"按钮。

打开"端口外部访问",CPU 设置为 2 核,内存设置为 4096 M。

点击"确认"后,可以看到 MaxKB 应用是"已启动"状态。

浏览器访问服务器 IP:8080,可以显示 MaxKB 应用的登录页面,即可正常使用 MaxKB 服务。默认登录信息是:
用户名:admin
密码:MaxKB@123..

2.5 第五步:对接 DeepSeek -R1 模型
在 MaxKB "模型设置"菜单,点击"添加模型"。

模型供应商选择 "Ollama"。

填写"基础信息",包括"模型名称","模型类型"为"大语言模型","基础模型"为 "deepseek-r1:7b","API URL "为 http://腾讯云服务器IP:11434/
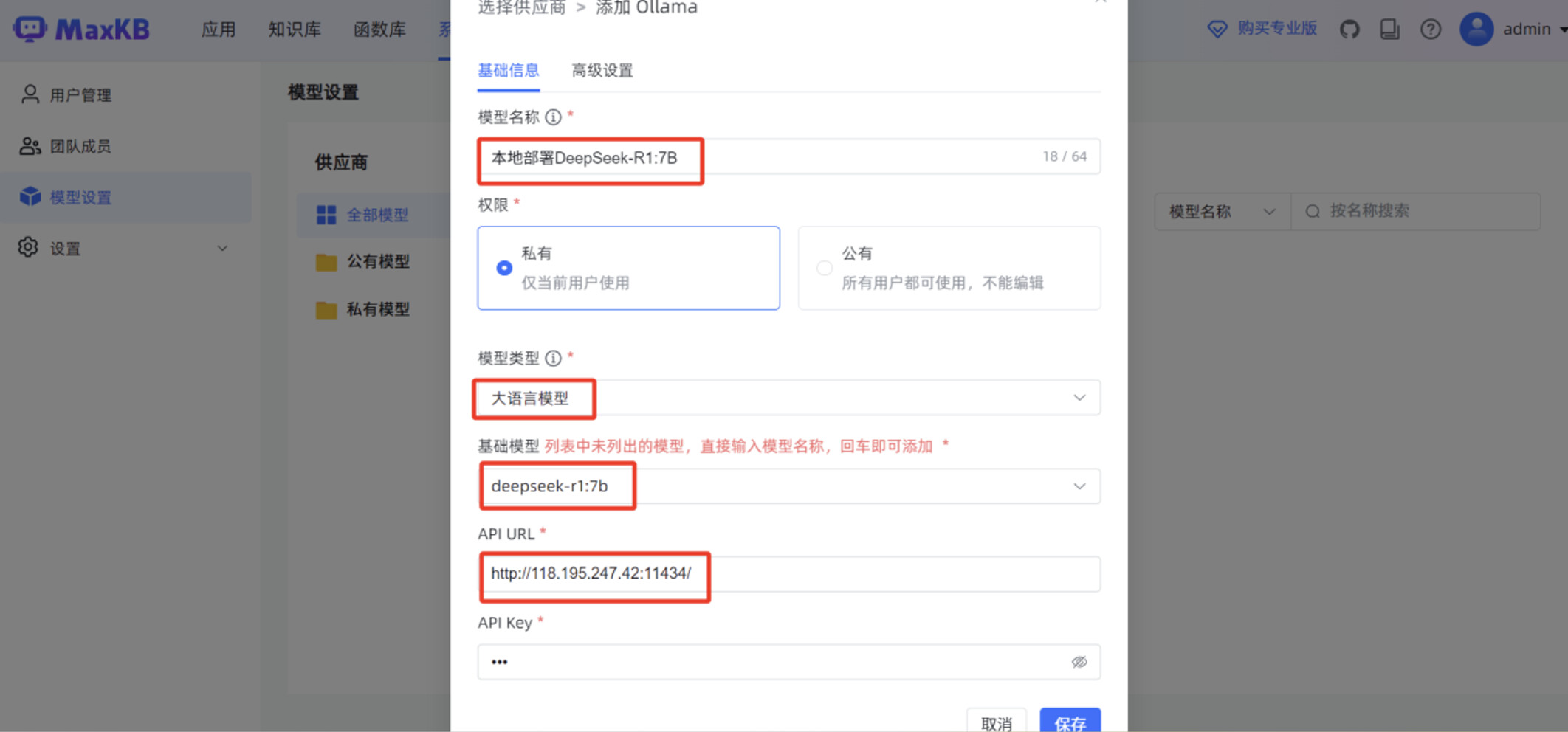
点击"保存"后,页面显示 MaxKB 服务已正常对接 deepseek-r1:7b 本地大模型。
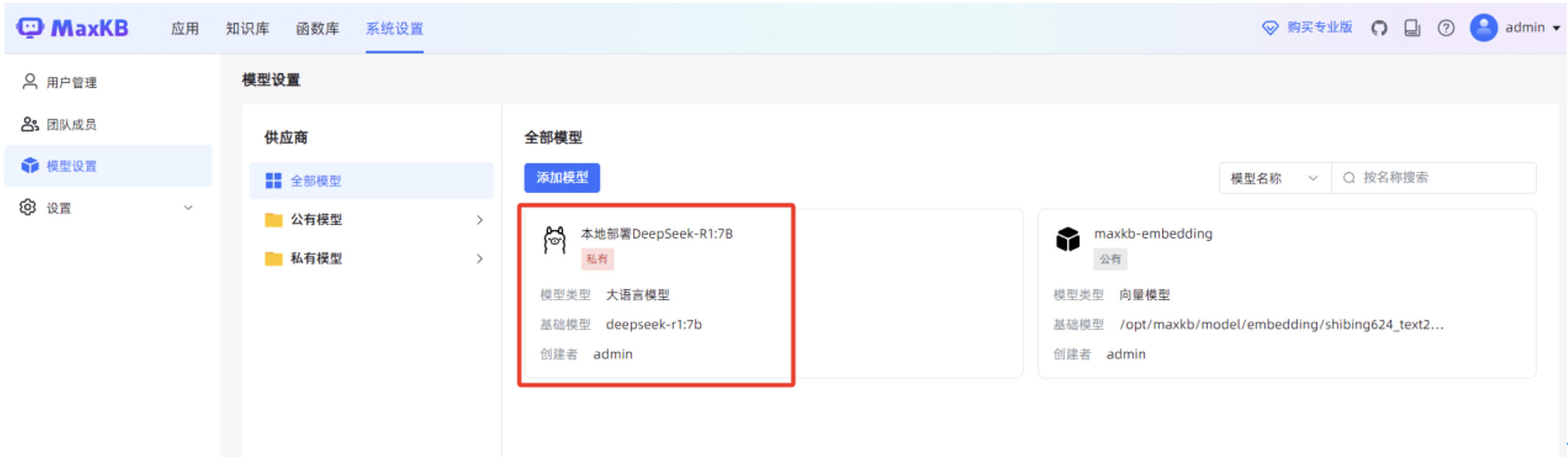
2.6 第六步:发布本地AI知识库
2.6.1 简单应用发布
首先发布一个简单应用,使用某高校教务管理文档为例,使用 MaxKB 创建的对话应用,完成教务问题的智能对话问答。
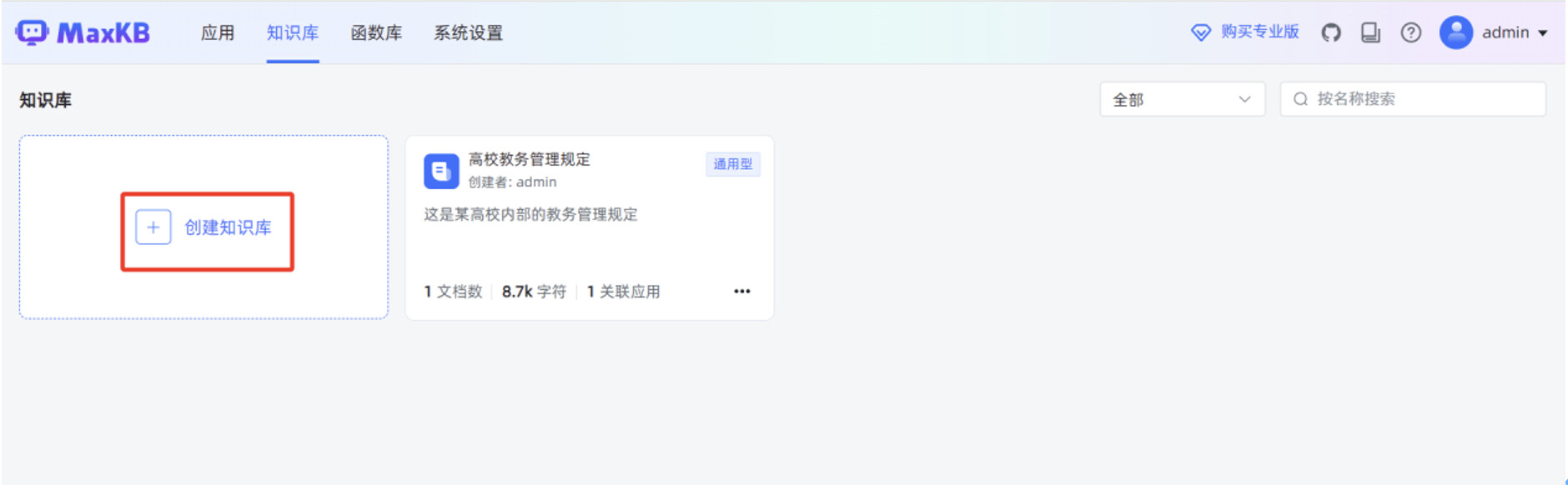
在 MaxKB "知识库"菜单,点击"创建知识库"。

输入"知识库名称","知识库描述",选择"向量模型",知识库类型选择"通用型",点击"创建"。

在跳转后的页面,点击"上传文档"。

点击"选择文件",选中本地某高校教务管理规定的 WORD 文件,点击"下一步"。
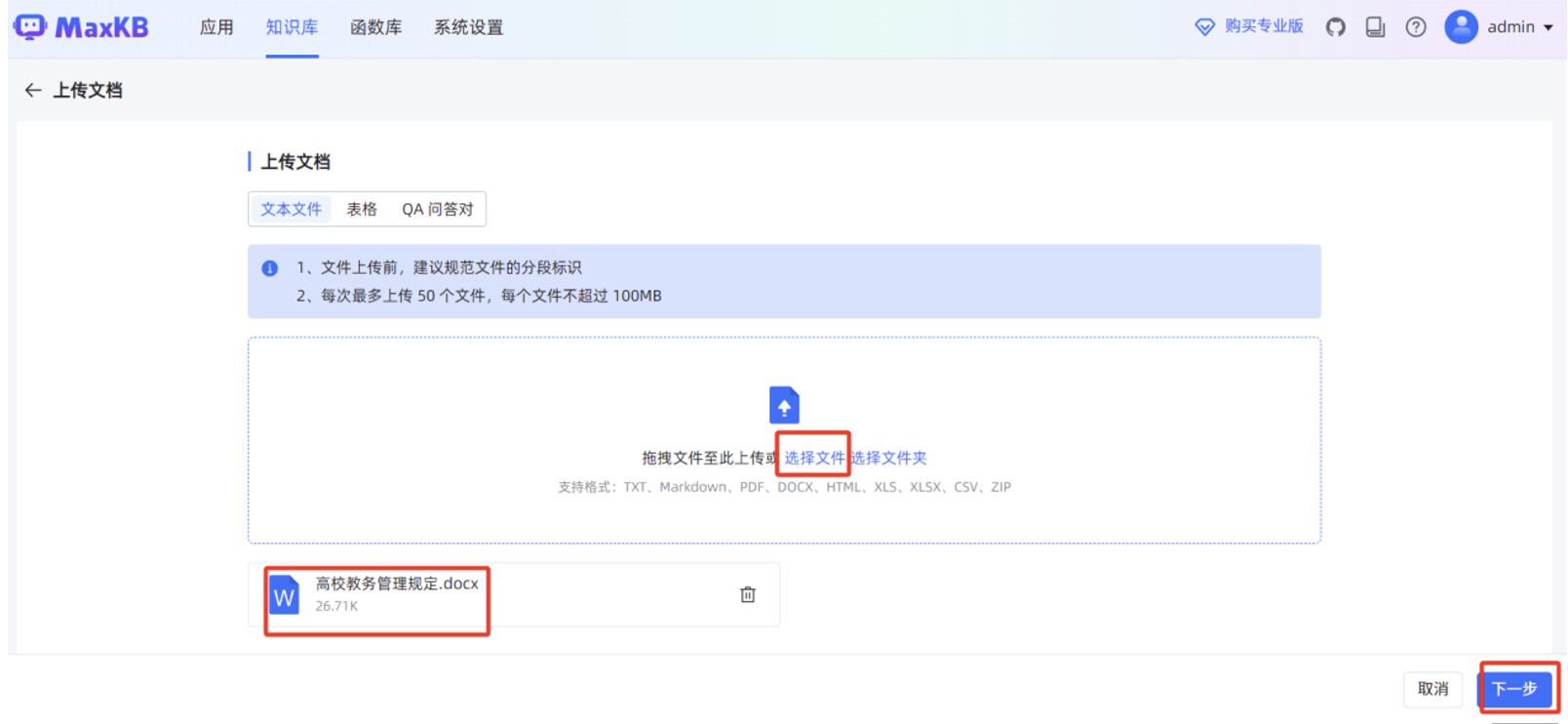
分段规则默认使用"智能分段",点击"开始导入"。
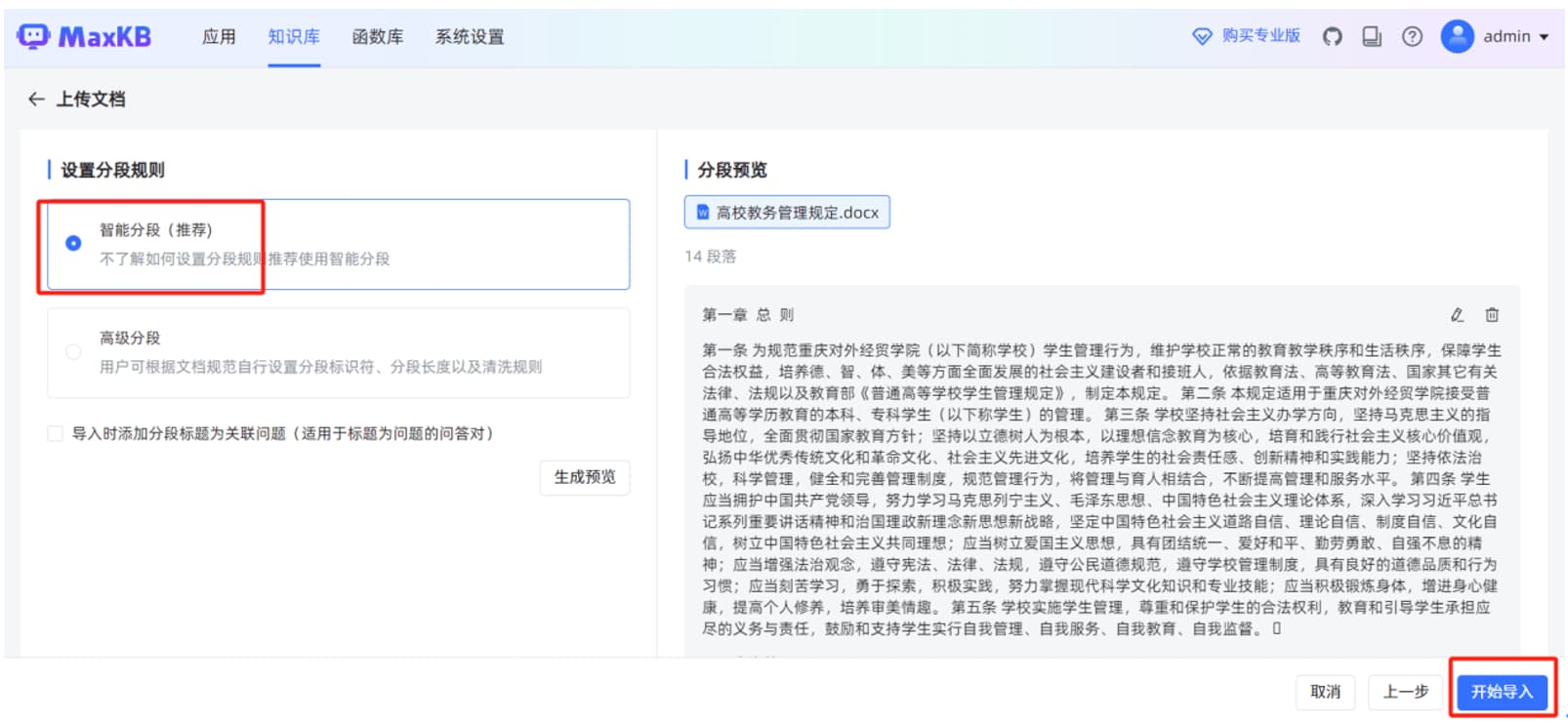
当"文件状态"显示"成功"时,说明本地文档已正常导入到 MaxKB 知识库。
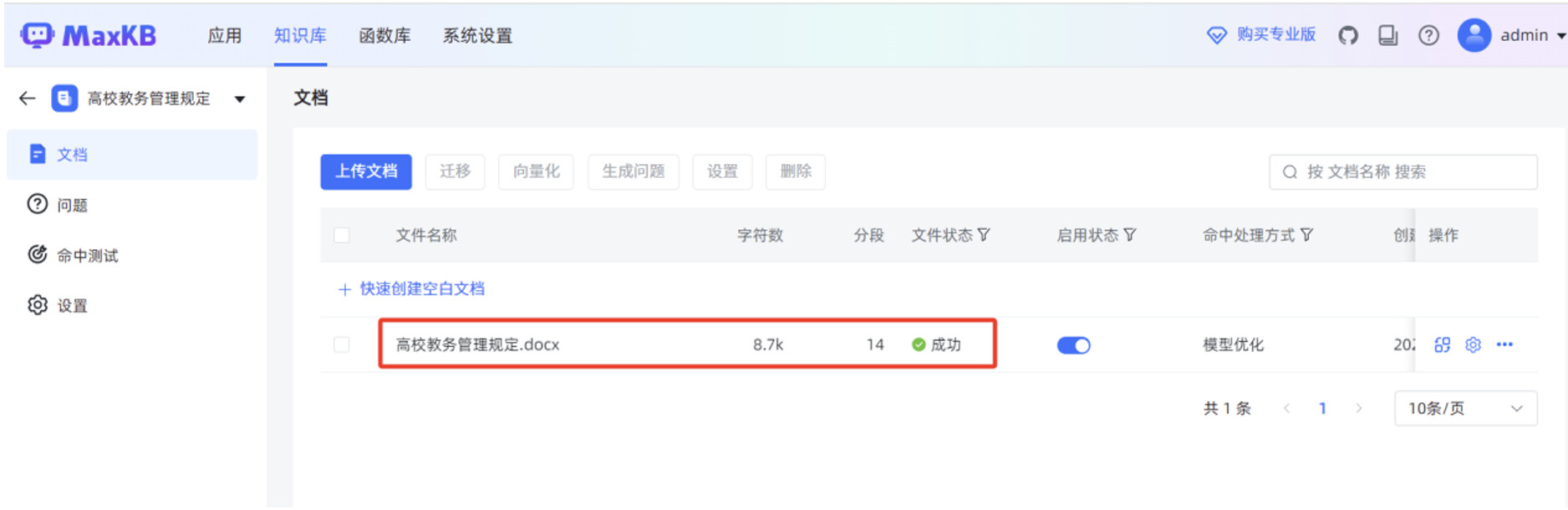
开始手动创建简单应用,在 MaxKB "应用"菜单,点击"创建应用"。
输入"应用名称","应用描述",选择"应用类型"为"简单配置",点击"创建"。
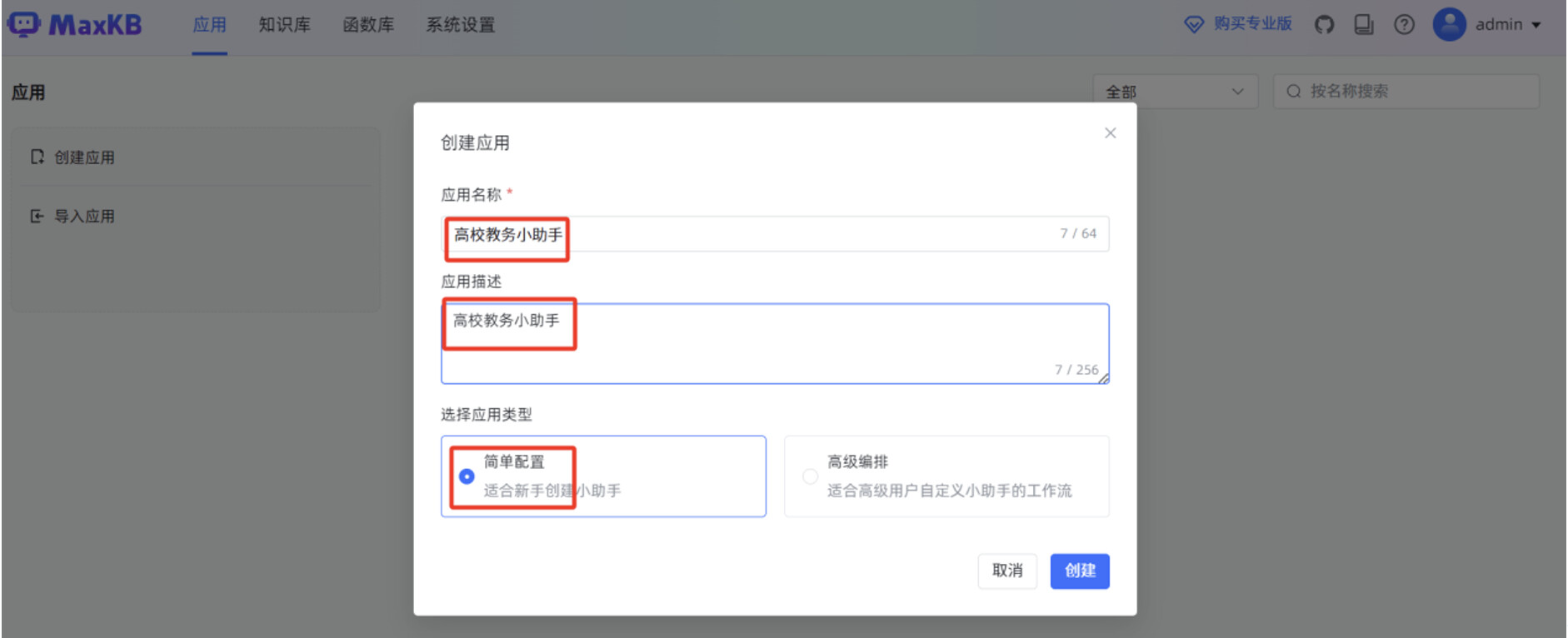
设置"AI 模型"为 MaxKB 刚才对接的 deepseek-r1:7b 本地大模型,填写"系统角色"。
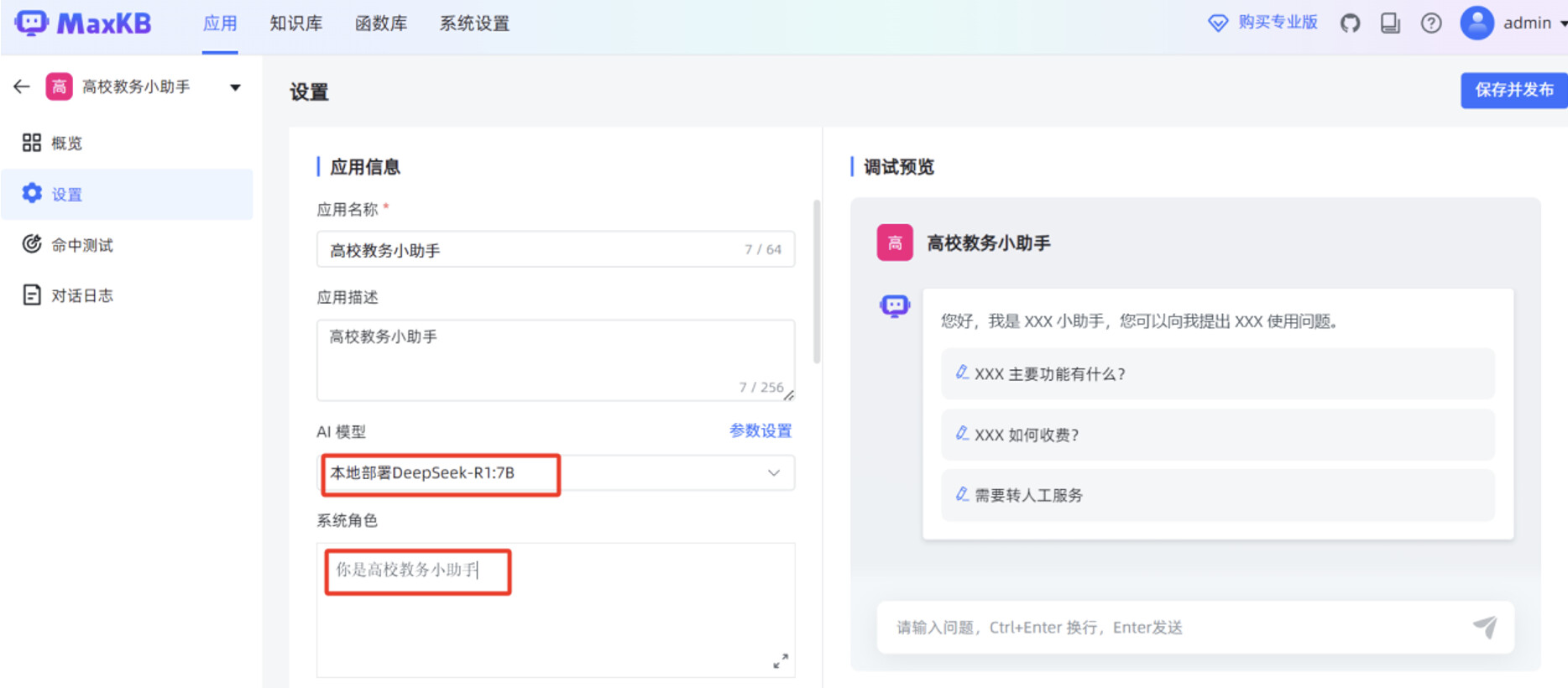
添加刚才创建的"高校教务管理"知识库,填写"开场白",打开"输出思考",点击右上角的"保存并发布"。
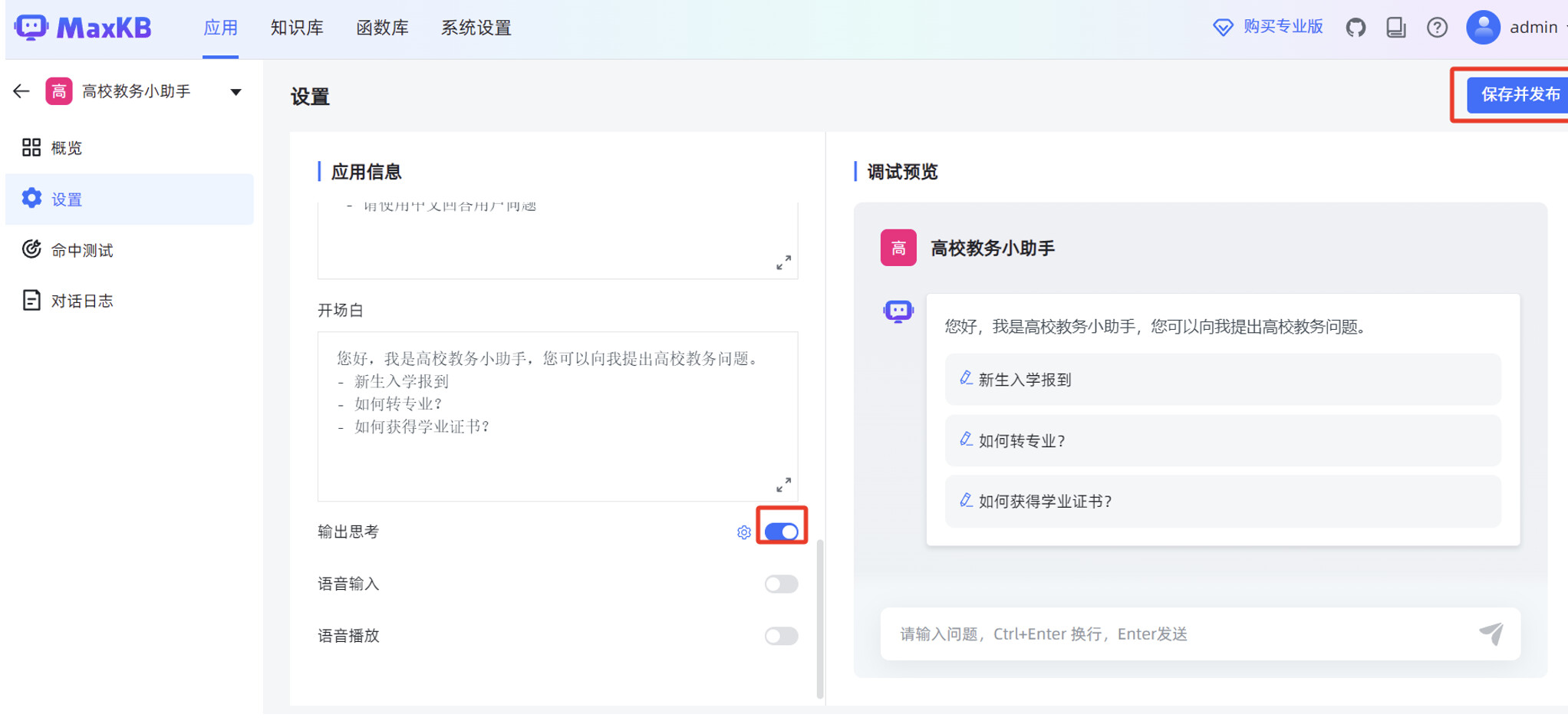
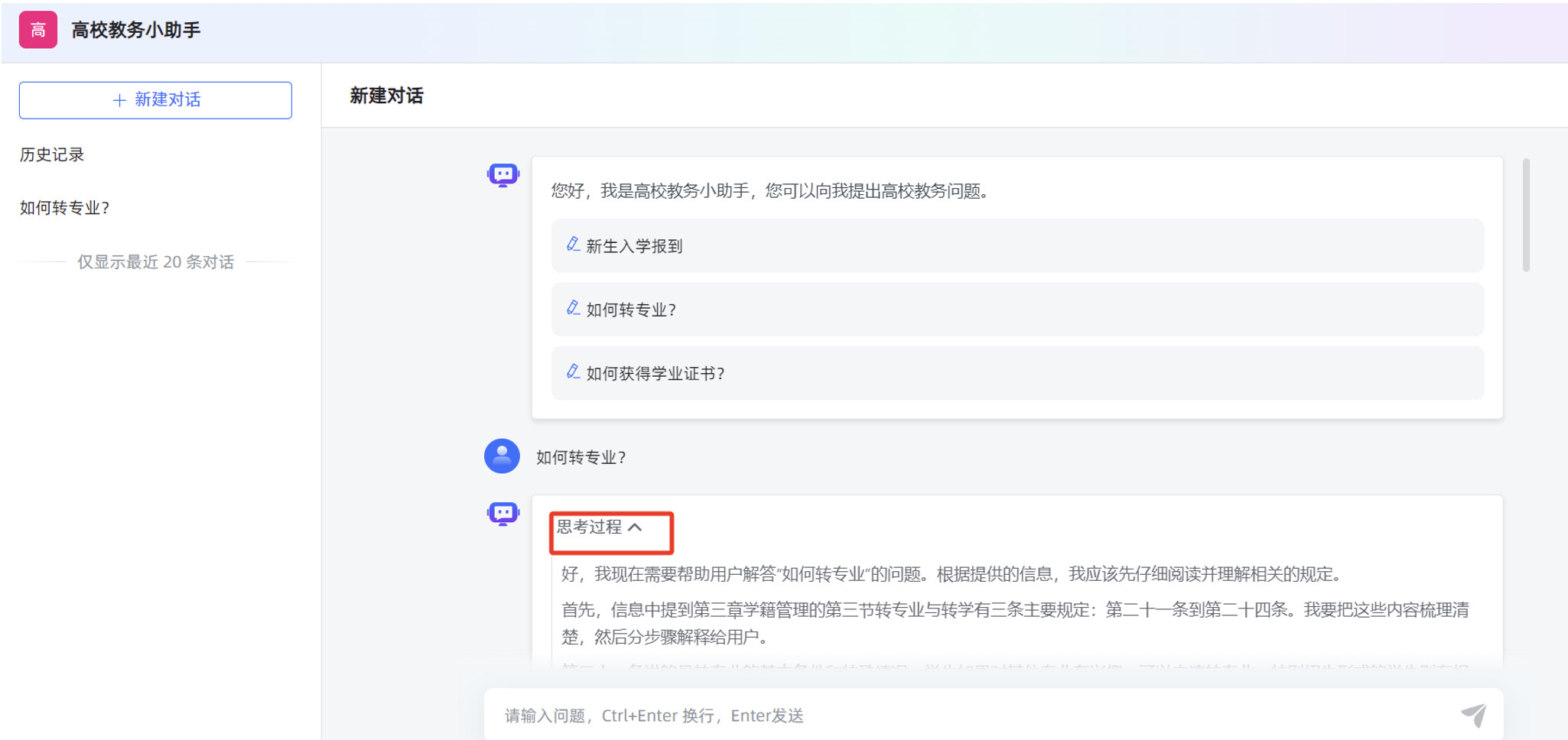
在 MaxKB "应用"菜单的概览页面,点击"演示",可以测试 MaxKB 创建的智能对话应用。
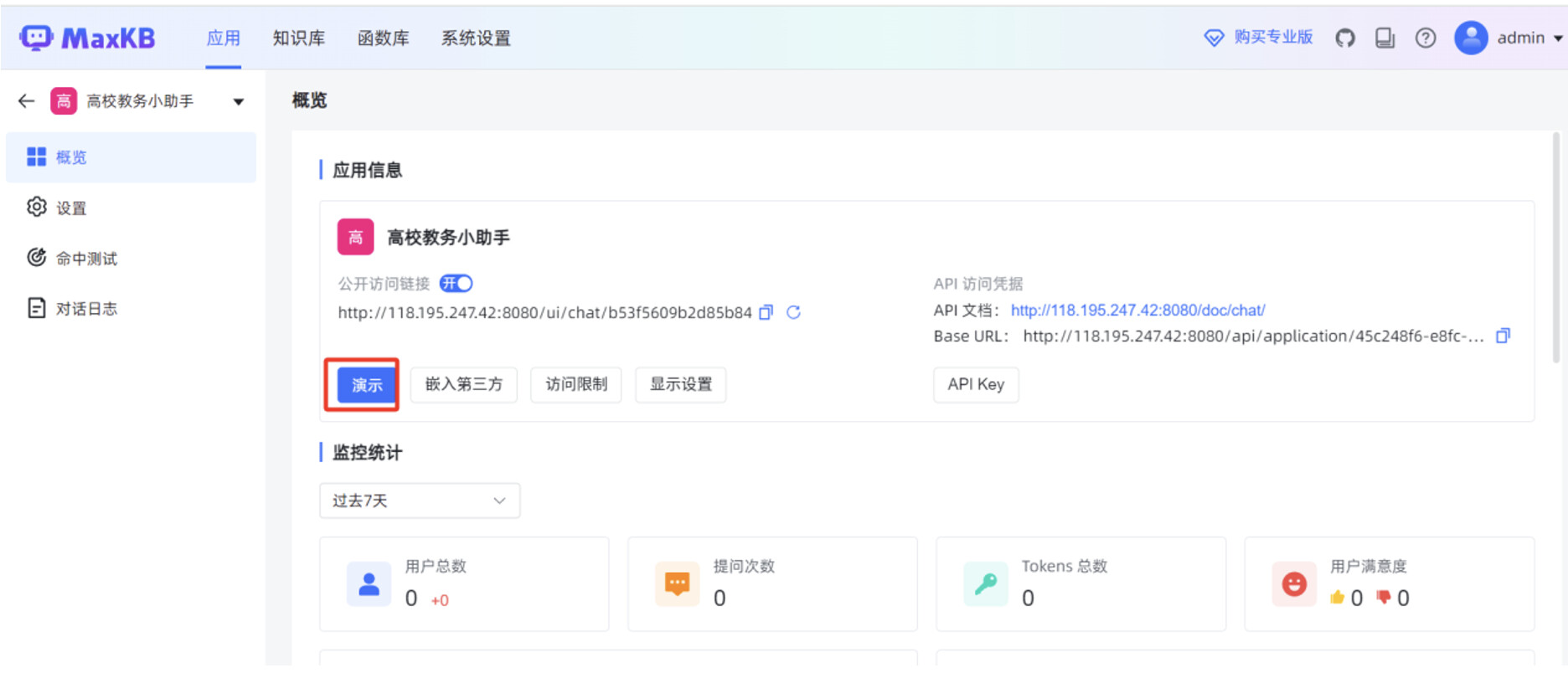
在对话应用的输入框,填写提问信息后,可以看到应用回复的内容是比较准确的。
2.6.2 高级编排应用发布
接下来,发布一个高级编排应用,使用 JumpServer 中文运维手册为例,使用 MaxKB 创建的高级应用,完成 JumpServer 运维的智能对话问答。当用户提问信息是英文时,高级应用可以将英文翻译成中文,结合 JumpServer 中文运维手册的数据,高级应用再将此中文数据自动翻译成英文,最后返回英文回复信息给用户。
工作流编排中有两个最重要的 AI 对话节点,前一个 AI 对话节点作用是把英文翻译成中文,后一个 AI 对话节点作用是把中文翻译成英文。
继续创建一个知识库,方便给工作流编排中的"AI 对话"节点使用。
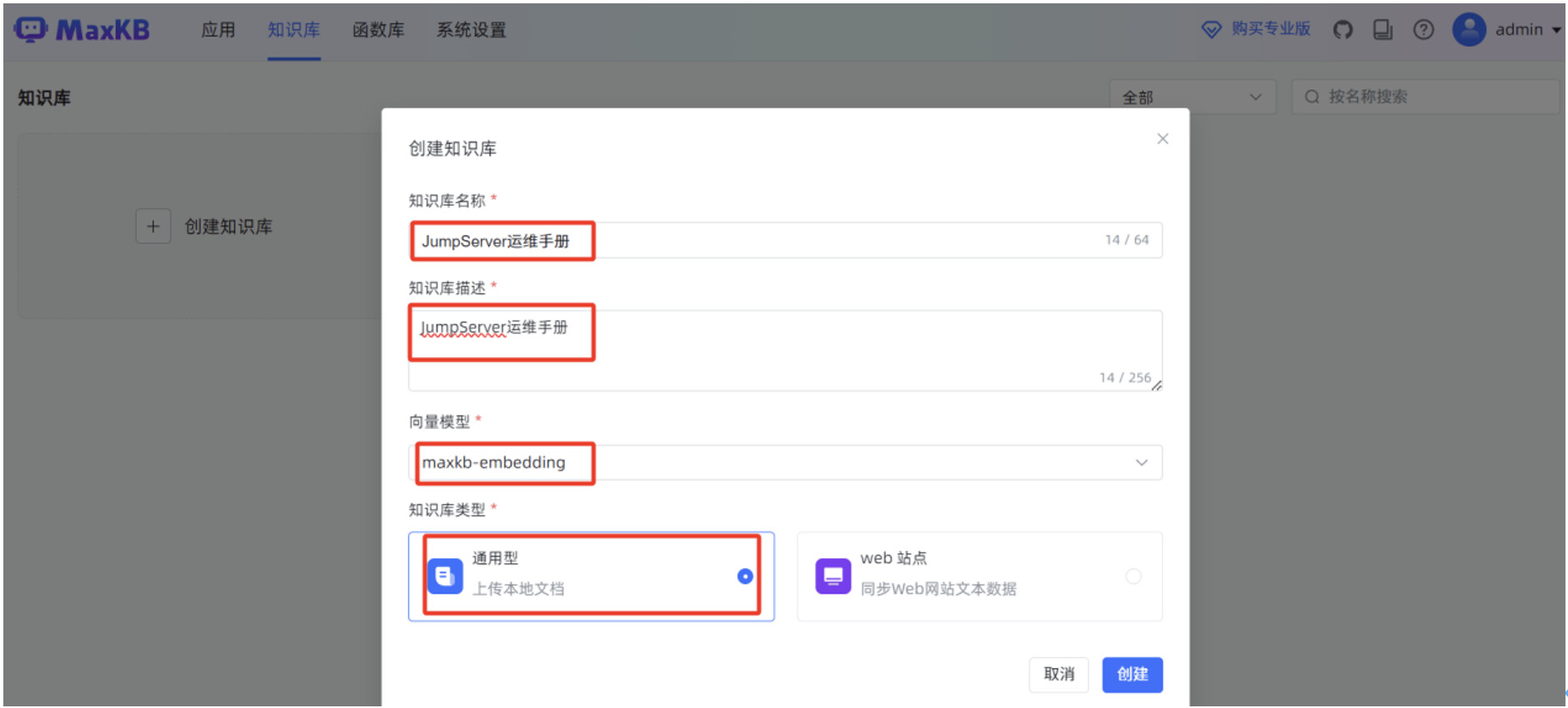
输入"知识库名称","知识库描述",选择"向量模型",知识库类型选择"通用型",点击"创建"。
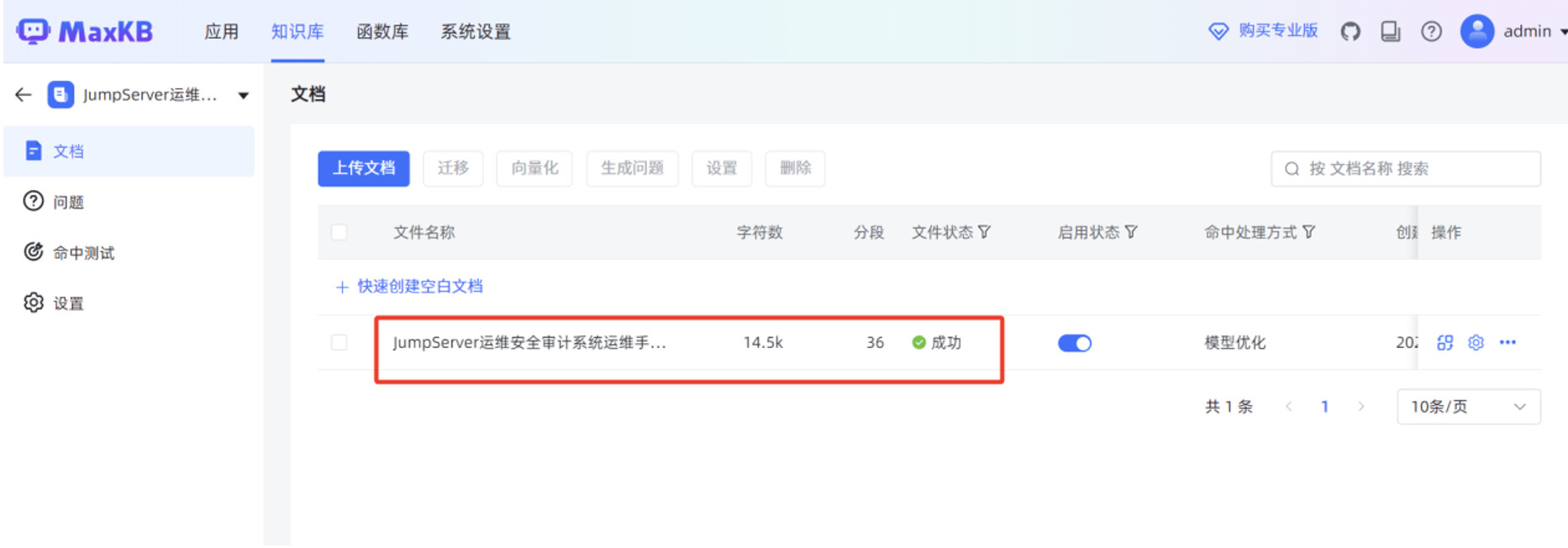
点击"选择文件",选中本地 JumpServer 运维手册的 WORD 文件,点击"下一步"。

当"文件状态"显示"成功"时,说明本地文档已正常导入到 MaxKB 知识库。
开始创建高级编排应用,在 MaxKB "应用"菜单,点击"导入应用",选中本地 mk 文件,点击"确认"。
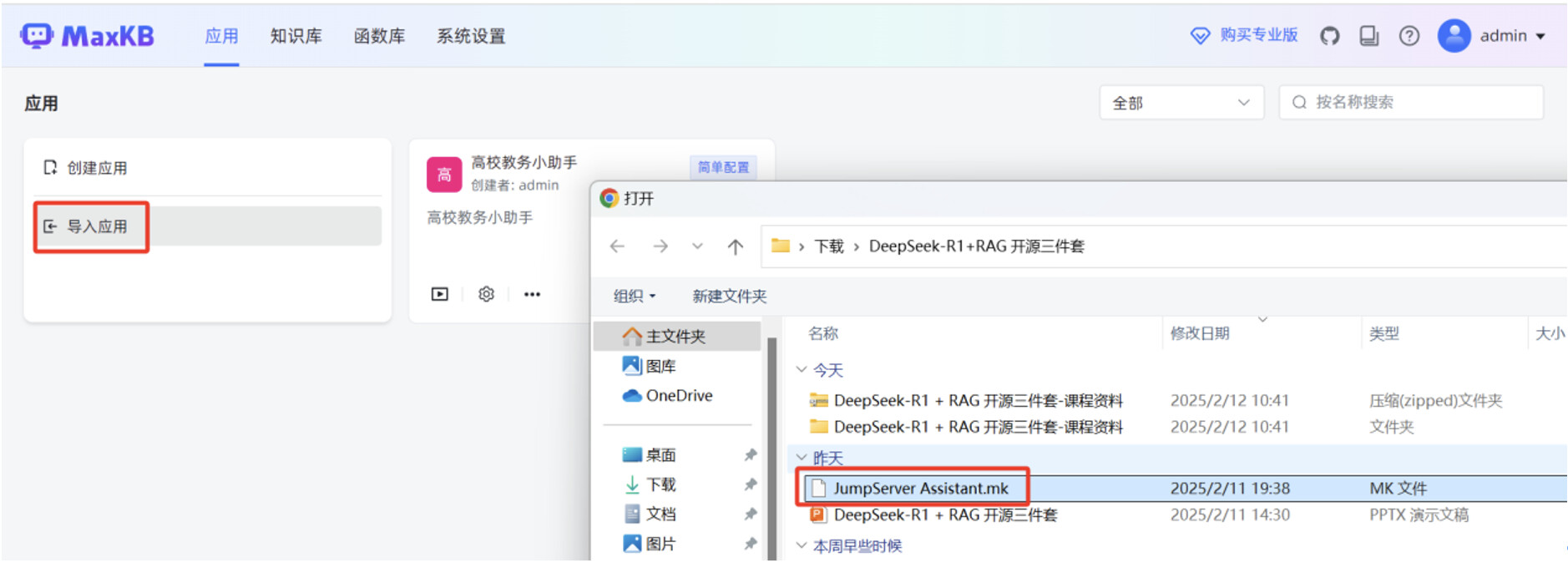
mk 文件导入成功后,点击"设置"按钮,进入高级编排应用的工作流编辑页面。
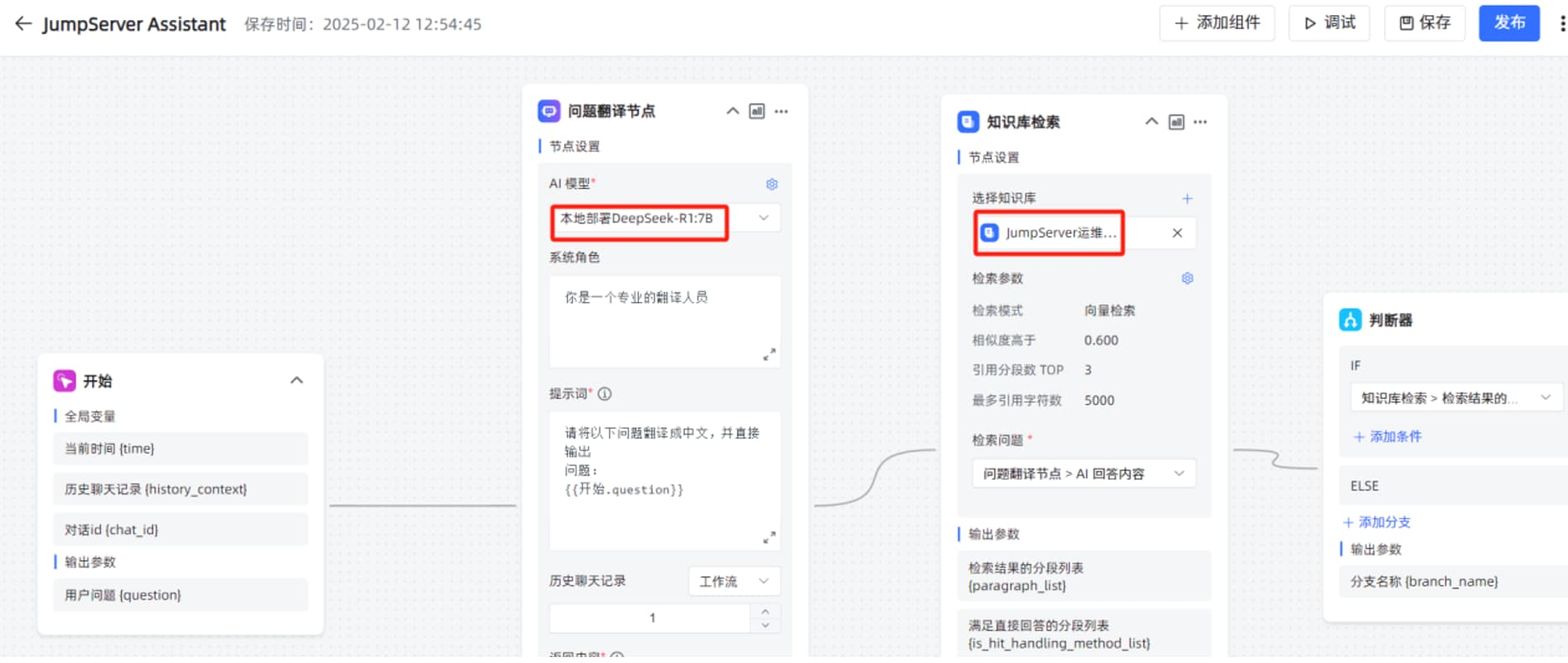
在工作流编辑页面,修改"问题翻译节点"的"AI 大模型"为本地部署的 DeepSeek-R1:7B ,"选择知识库"为刚才创建的 JumpServer 运维手册的知识库。
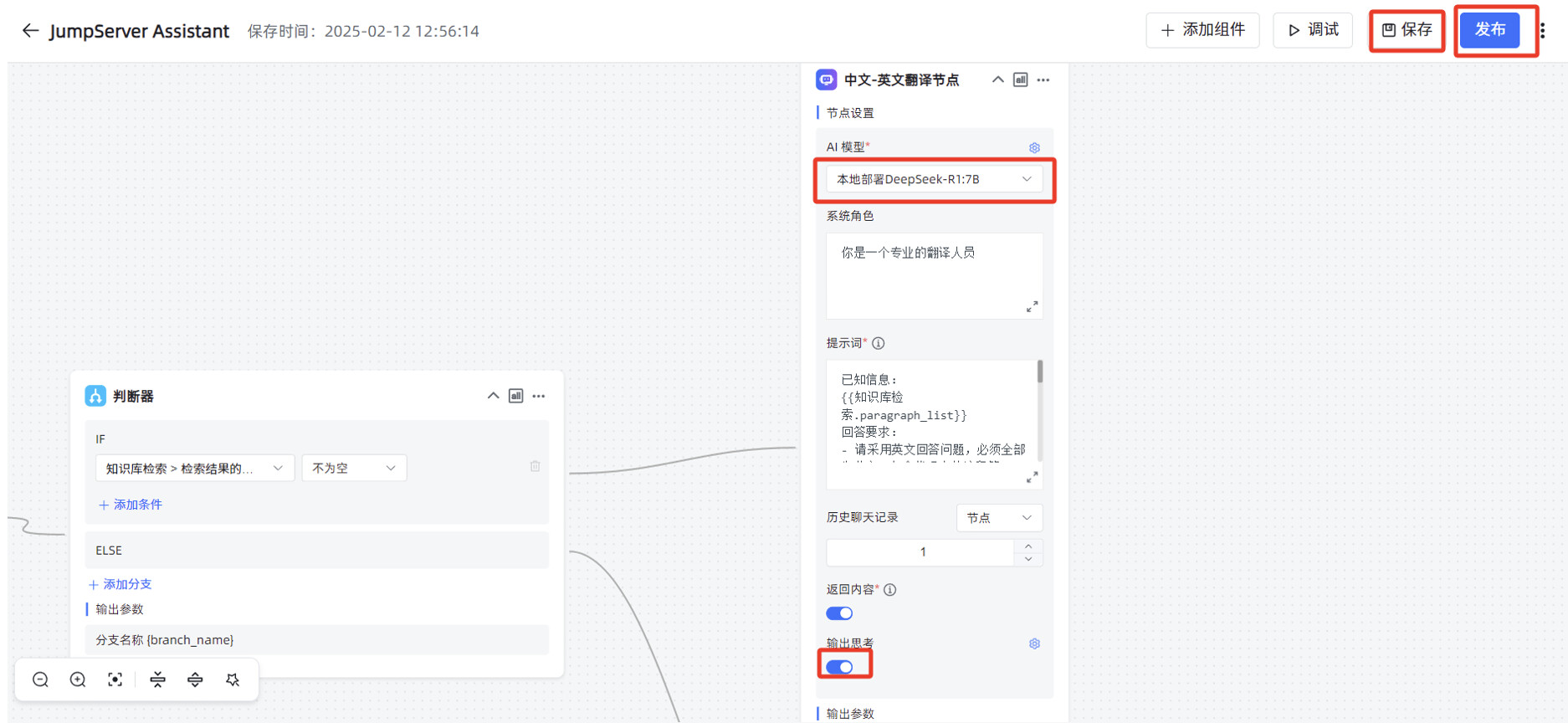
"中文-英文翻译节点"的"AI 大模型"修改为本地部署的 DeepSeek-R1:7B,打开"输出思考"的开关,先点击右上角的"保存",再点击"发布"。
在 MaxKB "应用"菜单的概览页面,点击"演示",可以测试 MaxKB 创建的高级编排应用。
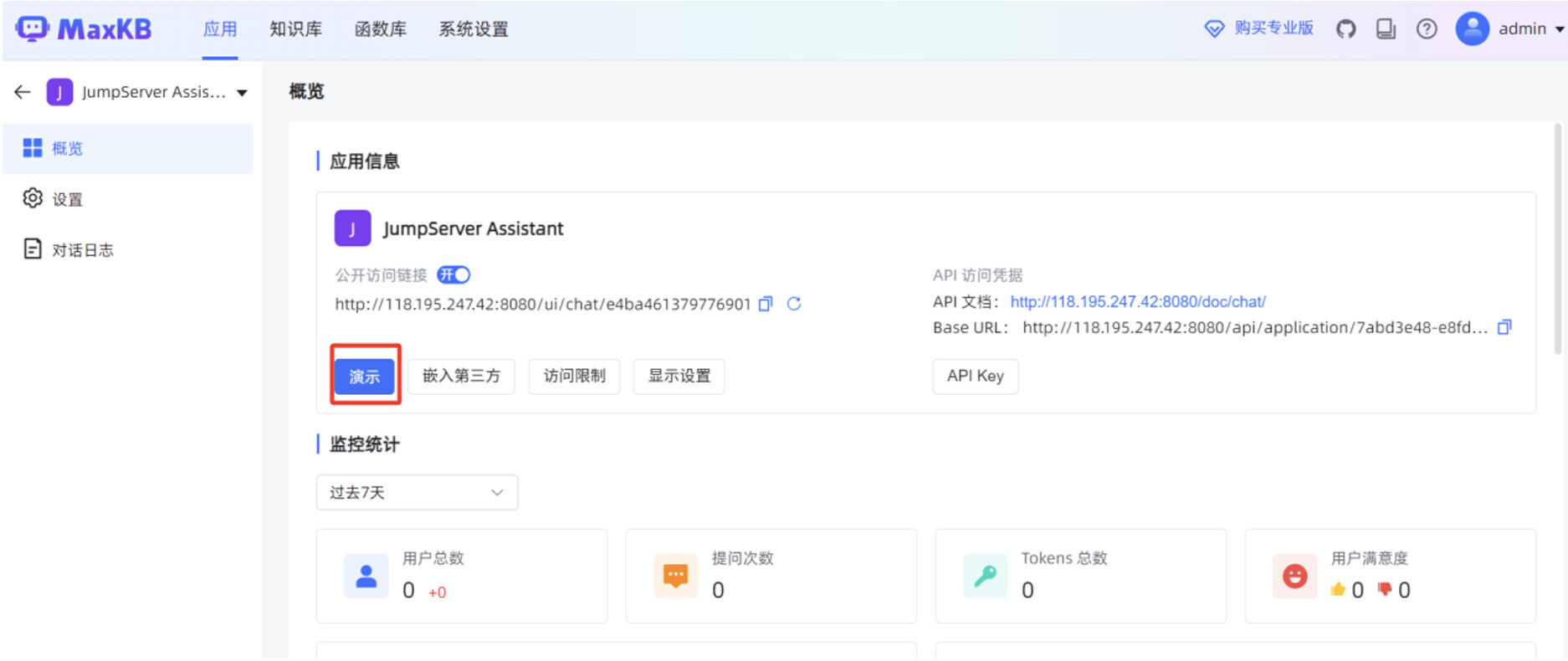
在对话应用的输入框,填写提问信息后,可以看到应用回复的内容是比较准确的,并且可以看到DeepSeek-R1:7B 大模型的思考过程。


如果想查看腾讯云服务器 GPU 的资源使用情况,可以在服务器终端执行 nvidia-smi 命令。

教学视频:https://edu.fit2cloud.com/detail/l_67a3079ee4b0694c5a8b350e/4
相关附件:https://pan.baidu.com/s/1YfT7-tZ8hfh9CFwiJxGokA?pwd=5sae 提取码: 5sae
- DeepSeek+RAG 直播实操笔记;
- DeepSeek-R1+RAG 开源三件构建本地 AI 知识库教学PPT;
- JumpServer Assistant.mk
- JumpServer 运维安全审计系统运维手册.docx
- 高校教务管理规定.docx