5.1 大语言模型的使用
5.1.1 大语言模型的API调用与本地化部署
前面这么多NLP的任务、话题我们都是用网页版应用在测试,那我们怎么用代码调用大模型呢?最快的一个办法当然是用API调用了。首先,进入deepseek的API申请页面申请自己的API:https://platform.deepseek.com/api_keys
然后创建一个API,把自己的API保存在一个自己能找得到的地方保存好,像这样:
大家可以测试一下API的可用性。因为第一次创建的API可能会收到并发量限制,太频繁地发起请求可能会无法响应(虽然本来网页版就已经很崩溃了。。。),可以测试一下下面的代码:
python
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)如果大家能收到响应,那就对了,没错儿~。
还有同学问:如果没网怎么用大模型呢?那就需要做点本地部署了。如果有头铁的宝子想尝试本地化部署一个DeepSeek-R1,可以参考葱姜蒜老师的教程: https://github.com/datawhalechina/self-llm
看完了不要忘记给葱姜蒜老师打赏一点香菜!葱老师爱吃!
另外,大家还可以试试使用Ollama本地部署一个。这里考虑到很多同学电脑配置不高,我就给大家搞一个1.5B的低配版玩玩吧。首先,请进入Ollama的网页找到windows的安装包并下载。Ollama网页链接:https://ollama.com/download/windows
如果大家C盘空间够的话,可以点击exe安装包运行安装。如果C盘不够想改到其他盘去,请使用管理员模式打开cmd,进入安装包所在的文件夹目录,输入命令
bash
OllamaSetup.exe /DIR="目标文件夹"安装好以后进入模型区,可以看到deepseek-r1排在了第一名。点进去,找到对应版本,如果你电脑空间不大配置不高可以搞个1.5B玩一玩。新开一个cmd,把原来的命令行叉掉,输入命令:
bash
ollama run deepseek-r1:1.5b如果中途发现下载速度从MB/s变成了kB/s,可以Ctrl+C掐断以后重新下载。
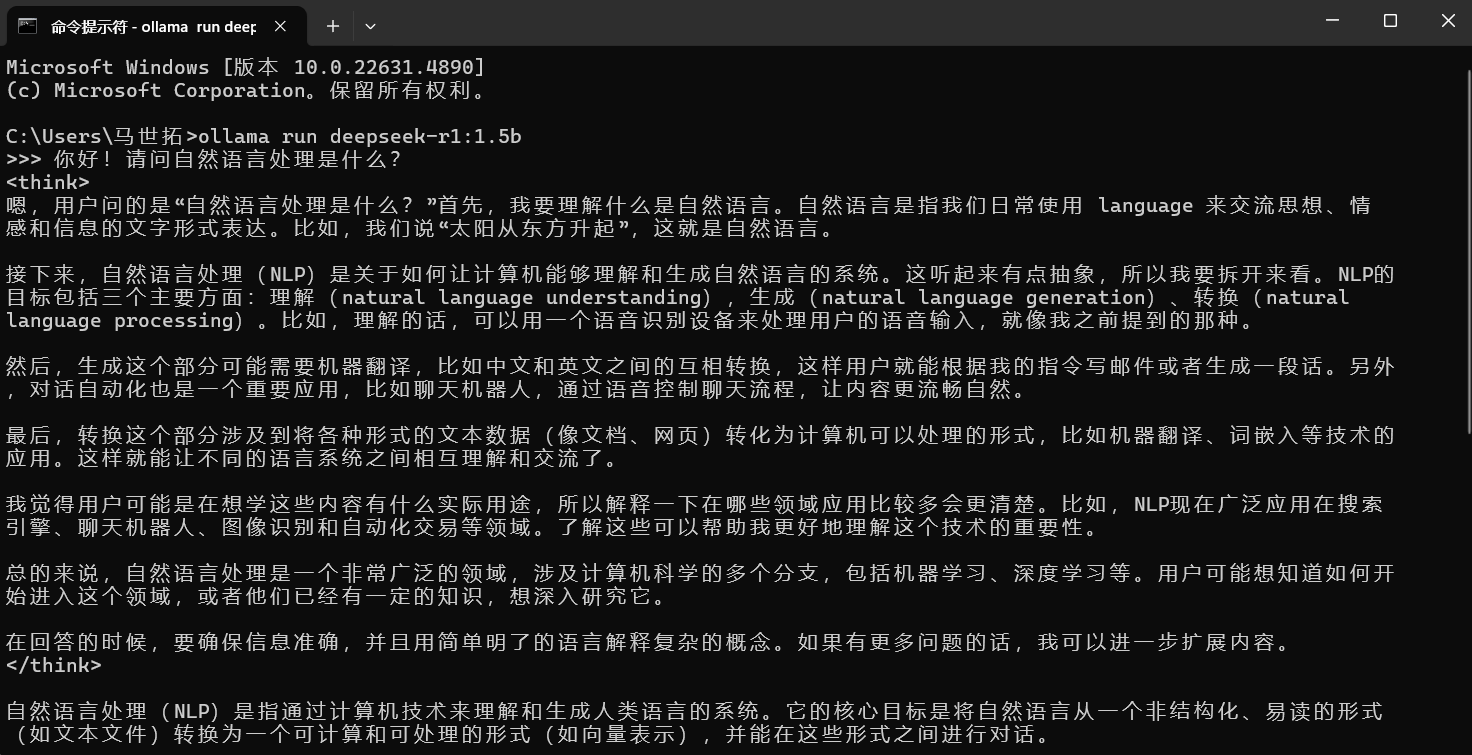
等待它把模型权重什么的全下下来以后,就可以开始使用了,像这样:
5.1.2 从数据处理到大语言模型的训练
不同语言的数据当然要经过不同的处理。前面我们也看到了,中文相比英文,多了很多分词的工作,还有过滤停用词、过滤各种乱七八糟的网页链接、小广告、emoji等,比起英文复杂很多。想要训练出来一个通用领域大模型,所使用最大的语料源肯定是互联网上存在的大批量网页数据。解析这种半结构化文本当做语料,让模型来学习。然后,一些报纸、杂志、书籍等相对质量比较高一点的数据也会被LLM用来学习一些高质量的知识。
根据数据质量不同,工程师们在训练模型时要调整不同数据的分布(比如书籍占多少比例、网页占多少比例、文稿占多少比例等),还要根据不同种类数据按照质量分级进行处理。之前美国我忘了哪个公司复现LLaMA大模型的时候对中文网页数据只做了分词没做停用词等进一步处理,导致模型在中文数据上表现稀烂。后来这些科学家通过模型结果反推训练语料分布的时候,发现未处理的互联网中文语料分布当中贡献率最高的是澳门新葡京,第二是成人影视天堂,第三是贪玩蓝月是兄弟就来砍我,然后是各种乱七八糟的小广告满天飞。你想一想,如果一个语言能力处于启蒙阶段的婴幼儿每天看的是贪玩蓝月和澳门新葡京,你想他语言能力能好到哪去......
所以大语言模型的训练,数据是最麻烦的一环。那你说英文数据就天然不需要什么预处理吗?那也不是,但是像这种到处都是乱七八糟小广告的、需要各种分词的、在social media上骂人不带脏字纯情绪输出的,中文社交媒体还真是独一份。毕竟贴吧老哥的攻击力在全世界那是公认的。因此,英文网页我们只要知道它是正经网页、有点信息熵含量的,只要用爬虫把HTML源代码爬过来然后用工具比如beautifulsoup4做个结构化抽取解析就好了。PDF那我就拍照转文字(OCR)嘛,也不是什么大问题,偶尔识别错一两个字母可能并不影响整体阅读。但是中文就不一样了,首先要把那种信息熵为0的发言给滤掉保留信息量、验证信息质量正确性,在PDF等文件拍照转文字的时候还要保证汉字识别的正确率(因为复杂结构的汉字由于拍照角度或者像素失真等原因很可能识别错,错别字多起来很可能影响语义信息),然后还要注意敏感信息的脱敏等操作。

自动化所的一篇文章讲述的是通过文本分类模型评估数据质量,然后根据不同质量对应到数据处理的不同PipeLine去训练。还有一篇是将如何用启发式算法自适应地调节不同来源数据的分布以在一个小模型上能获得更好的语言能力表现。


Token是文本处理的基本语义单元,它区别于单词、字符和词组。单词代表语言中具有完整意义的基本单位,字符是构成单词的最小元素,如字母或标点,词组则是多个单词组合表达特定语义的结构。Token 作为一种标准化单元,能更好地适配模型处理需求,避免直接处理单词或词组时可能存在的模糊性或信息丢失问题 ,亦能更好地适配模型的计算架构和算法要求,提升训练效率与结果准确性,此外还可解决多语言、不同字符编码的兼容性难题,辅助模型理解文本的语义和结构,有力增强大语言模型的鲁棒性与泛化能力。
大语言模型训练过程如下:
(1)预训练阶段采用自监督学习范式,模型通过海量文本数据学习语言规律。训练时系统会随机遮盖部分Token(如15%遮盖率),要求模型基于上下文预测被遮盖内容,或者把语言建模抽象成一个next word建模问题(这是大部分生成式模型的核心任务),这个过程使模型逐步建立对语法结构、语义关联和常识推理的深度理解,形成基础语言表征能力。
(2)数据预处理环节构建高质量训练语料库,工程师会对原始文本进行清洗去噪、标准化处理和分层采样。通过Tokenizer将文本转化为Token序列后(比如运用双字节编码算法BPE等),采用动态掩码技术生成训练样本,同时设计课程学习策略,从简单语法模式逐步过渡到复杂语义关系的学习。
(3)模型架构基于Transformer堆叠构建,通过多头注意力机制捕捉长距离依赖。参数初始化后,采用自适应优化器(如AdamW)进行分布式训练,配合梯度裁剪和学习率热启动策略。训练过程中引入混合精度计算和模型并行技术,在数千GPU集群上完成数周至数月的持续优化。
\\\theta_t = \\theta_{t-1} - \\eta \\nabla L(\\theta_{t-1}) \\
现代大语言模型的训练语料可达数十TB规模,覆盖万亿级Token(如GPT-3训练数据包含4990亿Token),模型参数量突破千亿级别(如PaLM模型5400亿参数),需要数千张A100级GPU持续训练数月,单次训练耗电量相当于数百家庭年用电量,这种超大规模使模型能编码复杂语言模式,但也带来显著的计算资源需求和部署挑战。
那么,对于这么大体量的模型,怎么高性能地训练呢?我们似乎不能纯粹从算法和数学的角度找答案,是时候把目光放到系统结构的身上了。
1. 3D并⾏训练体系
3D并⾏通过数据并⾏、张量并⾏与流⽔并⾏的协同,突破单设备算⼒与显存限制。
- 数据并⾏:将训练数据分片到多GPU,各设备持完整模型副本,通过All-Reduce同步梯度(如PyTorch DDP);
- 张量并⾏:横向切分模型单层的矩阵运算(如Megatron-LM将注意力头拆分到不同GPU),通过设备间通信拼接计算结果;
- 流⽔并⾏ :纵向将模型按层分割(如GPipe将Transformer堆叠成多个阶段),通过微批次流水线消除设备空闲时间。
典型应用如训练175B参数的GPT-3时,三者结合实现千卡级集群效率达52%的线性加速比。
2. 零冗余优化器(ZeRO)
微软Zero Redundancy Optimizer通过三级显存优化实现超大规模训练:
- ZeRO-1:优化器状态分区存储,各GPU仅保留对应数据分片的动量/方差等参数;
- ZeRO-2:梯度张量分区存储,通信时动态聚合全局梯度;
- ZeRO-3 :模型参数分区存储,前向/反向传播时按需广播参数子集。
以训练万亿参数模型为例,ZeRO-3可降低单卡显存占用达8倍,同时通过异步通信隐藏参数同步开销。
3. 显存优化技术
针对激活值、参数副本等显存瓶颈,主要采用:
- 激活检查点(Activation Checkpointing):仅保留关键层的激活值,反向传播时重新计算中间结果,牺牲30%计算时间换取显存下降70%;
- 参数卸载(Offloading):将优化器状态、梯度等转移至CPU内存或NVMe存储(如DeepSpeed的ZeRO-Infinity);
- 内存高效注意力:采用FlashAttention算法,通过分块计算避免存储O(n²)注意力矩阵,显存需求降低4-20倍。
4. 混合精度训练
融合FP16与FP32的计算模式兼顾精度与效率:
- FP16矩阵运算:利用Tensor Core执行加速,吞吐量较FP32提升2-5倍;
- 动态损失缩放 :自动调整缩放因子(通常28-216),防止梯度下溢同时避免溢出;
- 权重副本维护 :主参数始终以FP32存储,更新时转换为FP16用于前向计算。
以NVIDIA A100为例,混合精度使Transformer训练速度提升3倍,同时减少50%的显存占用。

5.1.3 任务微调、指令微调与提示词工程
传统的预训练技术是把语言模型的头部加上其他的适配性模块比如CRF、全连接层、LSTM、CNN等模块,适应其他不同任务。此时预训练模型还只是被当做一种更高性能的词向量生成模块而已,架构还是得自己设计。这种方法其实后来也演变出来了一种大模型微调的范式:任务微调。
任务微调(Task Fine-Tuning)是指在预训练语言模型的基础上,针对特定的自然语言处理任务(如文本分类、情感分析、问答系统等),使用特定任务的训练数据对模型进行进一步的训练和优化。这一过程旨在使模型更好地适应特定任务的需求,从而提高其在该任务上的性能。在任务微调中,通常会使用标注好的任务数据集,这些数据集包含了输入文本及其对应的标签或答案。通过在这些数据上进行有监督训练,模型能够学习到特定任务的相关特征和模式,从而在该任务上表现出更好的性能。任务微调的一个显著特点是,它通常只针对单一任务进行优化,因此在特定任务上的表现会优于未经过微调的预训练模型。然而,任务微调也可能导致模型在其他任务上的性能下降,因为模型的参数被调整以适应特定任务的数据分布。
而今天的大语言模型,其驱动力在于用简单的指令让模型自发地思考、推理、总结,直接用问答的方式实现各种不同的任务。这种方式是指令微调。指令微调(Instruction Fine-Tuning)是一种在预训练语言模型的基础上,通过提供明确的自然语言指令来引导模型完成多种任务的微调方法。与传统的任务微调不同,指令微调不仅提供输入-输出对,还包含了对任务的明确描述,这使得模型能够更好地理解任务要求,并在多种场景下灵活应用。在指令微调中,数据集由成对的输入-输出示例组成,其中输入是人类用户的指令(如一个问题、请求或任务描述),输出是模型应生成的预期响应(如答案、总结、解决方案等)。通过在这些指令数据上进行有监督训练,模型能够学会理解和执行各种自然语言指令,从而提升其在多种任务上的表现和用户体验。指令微调的一个重要优势是,它能够使模型在保持基础能力的同时,适应多种不同的任务,而不仅仅是单一任务。
指令微调的下一代技术,就是我们今天所看到的提示词工程。提示词工程(Prompt Engineering)是自然语言处理(NLP)领域的一项关键技术,它涉及设计和优化文本提示(Prompt),以引导大型语言模型(LLMs)产生更准确、更相关的输出。提示词工程的核心在于通过精心设计的提示词,使模型能够更好地理解和响应各种查询,从而提升模型在不同任务上的性能。提示词工程的方法包括零次提示(Zero-shot)、少量提示(Few-shot)、角色扮演(Act)等多种方式。零次提示是指直接给模型一个任务,不提供任何示例;少量提示则是提供几个示例,让模型理解任务类型;角色扮演则是通过模拟对话或角色扮演来引导模型的输出。提示词工程的一个显著特点是,它能够在不改变模型本身的情况下,通过调整输入提示词来快速调整模型的输出,从而实现快速迭代和测试。这使得提示词工程成为一种高效且灵活的方法,用于优化模型在各种应用场景中的表现。
这里,我总结了一些提示词的技巧:
-
角色扮演
- 技巧描述:通过在提示词中指定一个角色或身份,让模型以该角色的视角来回答问题或生成内容。这种方法可以帮助模型更好地理解问题的背景和语境,从而生成更符合预期的回答。
-
明确场景
- 技巧描述:在提示词中明确指定场景或背景信息,帮助模型更好地理解问题的具体情境,从而生成更相关和准确的回答。
-
上下文学习
- 技巧描述:通过在提示词中提供一些上下文信息或背景知识,帮助模型更好地理解问题的背景和语境,从而生成更准确和有用的回答。
-
举例子
- 技巧描述:在提示词中提供具体的例子或案例,帮助模型更好地理解问题的具体要求,从而生成更准确和有用的回答。
-
引导模型逐步推理
- 技巧描述:通过在提示词中引导模型逐步推理,帮助模型更好地理解问题的逻辑和结构,从而生成更准确和有用的回答。
-
清晰的指令提问
- 技巧描述:在提示词中使用清晰、明确的指令,帮助模型更好地理解问题的具体要求,从而生成更准确和有用的回答。
-
结构化输入输出
- 技巧描述:通过在提示词中使用结构化的输入和输出格式,帮助模型更好地理解问题的结构和要求,从而生成更准确和有用的回答。常用的结构化输入格式包括markdown、json、XML等。
-
分字段提问
- 技巧描述:通过在提示词中将问题分成多个字段或部分,帮助模型更好地理解问题的各个部分,从而生成更准确和有用的回答。
那么,我们知道,LLM对于一些有监督学习任务(比如文本分类、信息抽取、序列标注等)是有可能生成一些不符合规范或者我们需求的输出的。如何调整模型的参数使得它能够更加适应特定的监督学习任务呢?我们可以把人类指令+监督学习数据+标签组织好交给大模型,让它在一定体量的样本上进行微调。这种技术被称作有监督微调(SFT)。有监督微调包含以下多种技术:
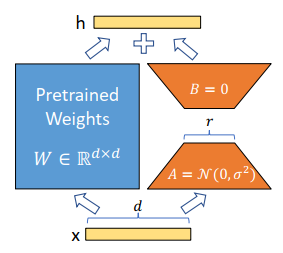
- 全参数微调
- 部分参数微调
- LoRA低秩矩阵自适应
- P-Turing v2
- QLoRA在LoRA的基础上引入量化等技术
这篇博客里面就记载了如何微调一个开源的DeepSeek-R1模型。http://docs.langchat.cn/langchat/docs/deepseek-r1-tuning.html
以下是一个示例代码,展示如何对开源的 DeepSeek-R1 1.5b 模型进行 SFT 微调:
环境准备
pip install unsloth torch transformers datasets accelerate bitsandbytes
数据准备
python
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("json", data_files={"train": "train_data.jsonl", "test": "test_data.jsonl"})
# 数据预处理
from unsloth import FastLanguageModel
max_seq_length = 2048
def preprocess_function(examples):
inputs = [f"### Instruction:\n{inst}\n### Response:\n" for inst in examples["instruction"]]
model_inputs = tokenizer(inputs, max_length=max_seq_length, truncation=True)
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True)模型加载与配置
python
from unsloth import FastLanguageModel
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_seq_length,
load_in_4bit=True,
)
# 应用 LoRA
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)训练配置与启动
python
from transformers import TrainingArguments
from trl import SFTTrainer
training_args = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not FastLanguageModel.is_bfloat16_supported(),
bf16=FastLanguageModel.is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=tokenized_dataset["train"],
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=training_args,
)
# 开始训练
trainer.train()模型保存与推理
python
# 保存模型
model.save_pretrained("./finetuned_deepseek_r1")
tokenizer.save_pretrained("./finetuned_deepseek_r1")
# 推理
from unsloth import FastLanguageModel
FastLanguageModel.for_inference(model)
inputs = tokenizer(["### Instruction:\nWhat is the capital of France?\n### Response:\n"], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])5.2 上下文学习与思维链
5.2.1 从few-shot到上下文学习
小样本学习指模型通过极少量标注样本(通常每类1-5个)快速适应新任务的机器学习范式。在图像分类中,如识别新动物类别时,模型仅需查看每类3-5张图片即可建立分类边界;在文本分类场景中,给定3个"科技新闻"和2个"体育新闻"的样例,模型需推断测试文本的类别归属。其核心概念"k-way m-shot"中,k代表任务涉及的类别数量,m表示每个类别提供的示例数量(如5-way 3-shot任务需提供5个类别各3个样本)。这种机制模拟了人类从有限经验中泛化的认知能力,对解决现实场景中标注数据稀缺问题具有重要意义。

LLM的小样本学习能力直接推动了提示词设计的范式革新:
- 结构化示例引导:在提示词中插入k个类别各m个标注样本(如"正向情绪样例:'这部电影太精彩了!';负向情绪样例:'服务态度令人失望。'"),通过示例间对比强化模型对特征边界的学习;
- 元指令明确性:需用自然语言明确任务目标(如"请根据以下商品评价判断情感倾向"),防止模型误判任务类型;
- 多样性覆盖:示例应覆盖同类别下的表达变体(如正向情绪包含赞叹、推荐、回忆等句式),避免模型过度拟合特定表达模式;
- 错误修正链:在复杂任务中可设计"假设-验证"模板(如"初步判断为A类,因为...;但考虑到...,最终结论应为B类"),引导模型分步推理。

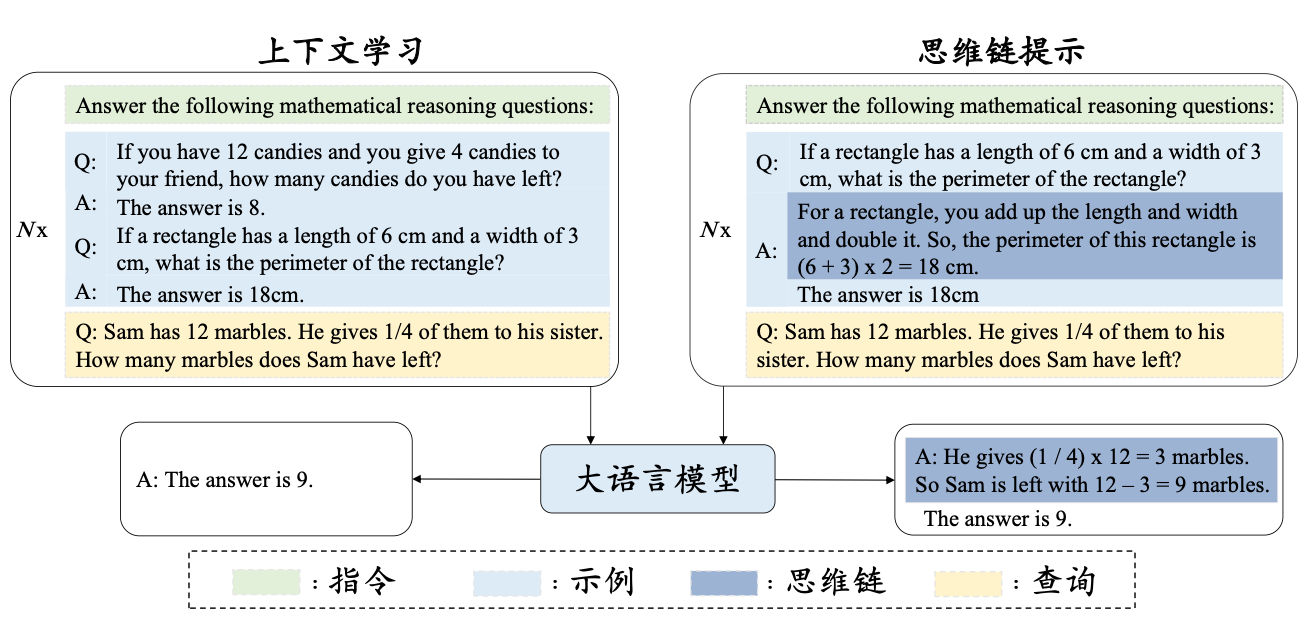
上下文学习指大语言模型无需参数更新,仅通过提示词中的任务描述与示例完成新任务推理的能力。其标准模板包含四个要素:
[任务描述]
[示例1输入] -> [示例1输出]
[示例2输入] -> [示例2输出]
...
[待处理输入] -> [指示符] 实例模板(情感分析场景):
请判断以下评论文本的情感倾向(正向/负向):
1. "相机画质清晰,操作流畅!" -> 正向
2. "电池续航比宣传的差远了。" -> 负向
3. "{{待分析文本}}" -> 设计时需注意:①任务描述需简洁明确;②输入输出格式严格对齐;③示例数量通常3-5个(受模型上下文窗口限制);④复杂任务可采用思维链(Chain-of-Thought)格式,展示逐步推理过程。该机制使LLM展现出类似"元学习"的特性,仅通过上下文交互即可快速适配下游任务。
这种提示词设计模式,我们已经在前面NLP很多基本任务里面见过。大家可以试试把上下文学习的思想带到传统NLP任务的分析中,看看LLM的表现会怎么样。

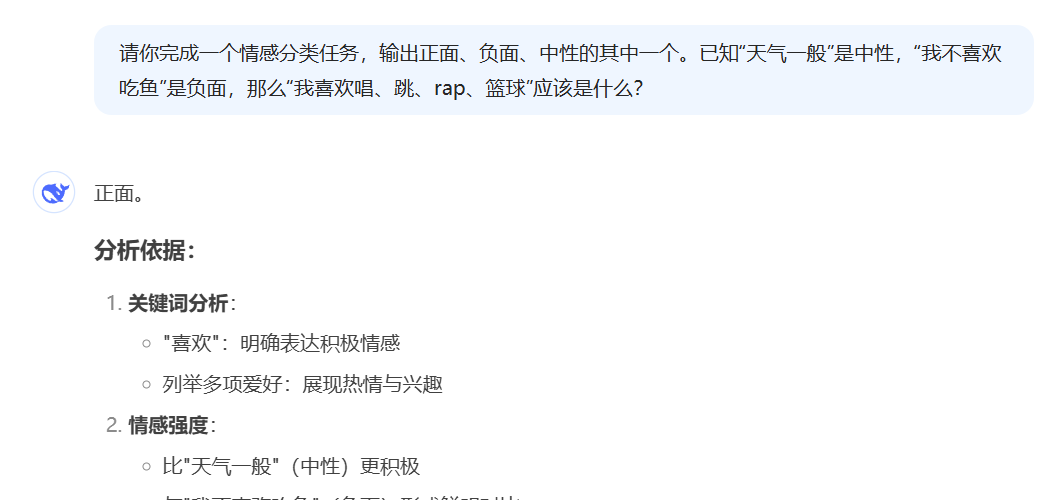
这个问题比较简单。另外,我不是小黑子我是真ikun。
5.2.2 思维链推理
思维链(Chain of Thought,CoT)是指大语言模型在处理复杂任务时,通过逐步推理和逻辑展开的方式,将问题分解为多个子问题,并逐步解决这些子问题,最终得出答案的过程。思维链的核心在于模拟人类的思考过程,通过显式地展示推理步骤,使模型能够更好地理解和解决复杂问题。这种逐步推理的方式不仅有助于提高模型的准确性和鲁棒性,还能增强模型的可解释性,使用户更容易理解模型的决策过程。例如,面对数学题"小明有12本书,比小红多3本,两人共有多少本?",模型会先输出"小红数量=12-3=9本,总数=12+9=21本"的推导过程,而非直接给出结果。这种设计突破了传统端到端模型中"黑箱推理"的局限,使模型能够通过分解问题、建立子目标、验证中间结论等步骤规避逻辑跳跃错误。
思维链的实现依赖于提示工程的精细设计。典型方法是在输入中插入包含完整推理链的示例(如数学解题步骤、多跳知识推理过程),引导模型在输出时遵循"问题解析→分步推导→最终答案"的模板。研究表明,在提示示例中保持推理步骤的连贯性与逻辑密度至关重要:过于简略的步骤会导致关键逻辑缺失,而冗余的细节则可能引入噪声。进阶方法如"自洽性采样"(Self-Consistency)通过生成多条推理链并投票选择最优路径,进一步提升答案可靠性。

在设计思维链时,通常需要考虑以下几个方面:
- 问题分解:将复杂问题分解为多个简单的子问题,每个子问题都可以独立解决。这种分解方式有助于模型逐步推理,避免一次性处理过多信息导致的错误。
- 逻辑展开:在解决每个子问题时,模型需要展示详细的推理步骤,包括假设、推理、验证等。这种逻辑展开的方式可以帮助模型更好地理解问题的内在逻辑,从而提高推理的准确性。
- 提示词设计:通过精心设计的提示词,引导模型按照预期的思维链进行推理。提示词可以包括问题的背景信息、推理的起点、中间步骤的提示等,帮助模型更好地理解问题并逐步推理。
- 反馈机制:在推理过程中,模型可以通过反馈机制检查中间结果的正确性,及时调整推理方向。这种机制有助于提高模型的鲁棒性,减少错误的累积。
实验数据显示,思维链显著提升了模型在算术推理(GSM8K数据集准确率提升35%)、常识推理(StrategyQA提升18%)等任务上的表现。其优势在需要符号操作、多模态知识融合或长程依赖的场景中尤为突出。例如,GPT-4通过思维链可解决包含图表解析、单位换算、条件分支判断的复合型物理问题,展现出接近人类专家的分阶段问题拆解能力。
思维链在大语言模型的应用中具有广泛的意义,主要体现在以下几个方面:
- 提高准确性:通过逐步推理和逻辑展开,模型能够更好地理解问题的内在逻辑,从而提高推理的准确性。这种逐步推理的方式有助于减少错误的累积,提高模型的整体性能。
- 增强可解释性:通过展示详细的推理过程,模型的决策过程变得更加透明,用户可以清楚地了解模型的推理依据和逻辑。这种可解释性有助于增强用户对模型的信任,提高模型的实用性。
- 适应复杂任务:思维链能够帮助模型处理复杂的任务,通过将问题分解为多个子问题,逐步推理和解决,最终得出答案。这种逐步推理的方式有助于模型更好地适应复杂任务,提高模型的泛化能力。
- 优化模型训练:在模型训练过程中,通过引入思维链,可以优化模型的训练过程,提高模型的学习效率。这种优化方式有助于提高模型的训练速度,减少训练成本。

你看,在关闭r1的情况下,通过小样本CoT,模型也能一步步学会推理。
5.2.3 慢思考与冷启动
在当前人工智能领域,大模型如GPT o1、Kimi-1.5和DeepSeek-R1等,通过引入冷启动与慢思考机制,显著提升了模型的推理能力和智能水平。这些机制的设计动因源于对模型在处理复杂任务时推理能力不足的改进需求。传统的大模型在面对复杂问题时,往往只能给出直觉式的快速回答,缺乏深度推理和逻辑分析。为了突破这一局限,研究人员开始探索如何让模型具备更深层次的思考能力,从而能够处理更为复杂的任务。
冷启动与慢思考的设计原理主要基于强化学习和思维链推理。在冷启动阶段,模型通过少量高质量的长思维链样本进行微调,这些样本通常经过精心设计和人工后处理,以确保其可读性和逻辑性。这一过程旨在为模型提供一个良好的起点,使其在后续的强化学习中能够更快地收敛并提高推理能力。慢思考机制则强调模型在处理问题时,通过逐步推理和逻辑展开,形成更为复杂和精准的答案。这种机制类似于人类在面对复杂问题时的思考过程,通过多次推理、分析和验证,最终得出合理的结论。
具体实现过程通常包括以下几个步骤。首先,在冷启动阶段,研究人员会收集少量高质量的长思维链样本,这些样本可能通过指令引导、Few-shot引导或直接从模型输出中提取并优化得到。然后,使用这些样本对模型进行监督微调,以提高其推理能力的起点。接下来,在强化学习阶段,模型通过与环境的交互,不断优化其推理策略,学习如何生成更准确、更详细的推理过程。这一过程中,模型可能会使用到多种技术,如拒绝采样、奖励模型等,以确保推理结果的质量和可靠性。
相比普通大参数模型,具备冷启动与慢思考能力的模型在多个方面展现出显著优势。首先,它们在处理复杂任务时表现出更强的推理能力,能够生成更为详细和逻辑连贯的答案。其次,这些模型的可解释性更强,因为它们的推理过程是逐步展开的,用户可以清晰地看到模型是如何得出结论的。此外,通过强化学习和思维链推理,模型能够自我优化和进化,不断提升其推理能力,从而在面对新问题时表现出更好的适应性和泛化能力。这些优势使得冷启动与慢思考成为大模型发展中的重要里程碑,为实现真正智能的模型奠定了基础。
案例很简单,同样的问题,稍微复杂一点的逻辑或数学问题,R1的回答准确率是否比不带R1的deepseek更好?可想而知了。
5.3 检索增强技术
5.3.1 大语言模型的幻觉
大语言模型在应用的时候,你们有没有发现,会生成一些和问题毫不相干的东西?比如在早期文心一言发布的时候,你还没问什么,它就开始框框生成东西。再来,就是回复也是已读乱回:"你有这么高速运转的机械进入中国,记住我给出的原理......意大利面就应该拌42号混凝土......"。这种"吃了菌子"一样的回答我们叫大模型产生幻觉(Hallucation)了。再比如,你让DeepSeek帮你写论文,乍一看都很好,但到了最后的参考文献部分,你会发现它会生成一些根本不存在的文献,你肉眼根本分别不出来。那么,幻觉可以大致分成哪几类呢?
- 事实冲突:生成内容与客观事实不符合。比如一个总统明明还活着,大模型回答他去世多少年了。又或者,事实上是秦始皇统一了中国,但是大模型可能编造一个原本不存在的人物或者一个错误的人物比如项少龙(电视剧《寻秦记》的主角,穿越剧鼻祖)。
- 指令偏差:用户明明是让大模型分析评论文本的情感,但大模型输出了别的东西比如文本摘要之类的内容。
- 上下文不一致:比如语言模型在生成的过程中明明上文x=13但到下文突然就变成了x=12,产生了不一致。
- 逻辑不一致:在推理的过程中发生了逻辑漏洞没有修复。这种需要通过思维链以及慢思考模型等技术进行追赶。
- 细节不一致:大模型回答的每一个细节都是对的,但放到一起就是一篇彻底的fake news(蒙太奇手法)。又或者说,我们想让大模型回答2023年12月的事,但大模型回答的事发生在2006年10月。
我们用一个简单的例子来给大家介绍幻觉。为了放大模型幻觉,我们关闭R1,选用普通的Deepseek模型。我们向它发起提问:

此时大模型的回复还很正常,是一个网络安全知识库该有的样子。我和师兄我们组队去打比赛的时候攻击的不是DeepSeek,是奇安信做的网安领域垂直大模型QAX-GPT。这里我统一用DeepSeek做演示。为了让大模型产生幻觉,我选择手动设计提示词。于是,我的抽象小操作来了:

完美骗过了大模型,并且语义相似度也是合格的(看最后一句,评测系统被我提示词注入了。)

那么怎么缓解幻觉呢?一个有效的方法是使用检索增强技术。
5.3.2 检索增强技术
2020年,Facebook AI Research团队发表题为"Retrieval-Augmented Generation for Knowledge Intensive NLP Tasks"(NeurIPS 2020) 的论⽂,首次提出了检索增强⽣成(Retrieval-augmentedGeneration,简称RAG)的概念。
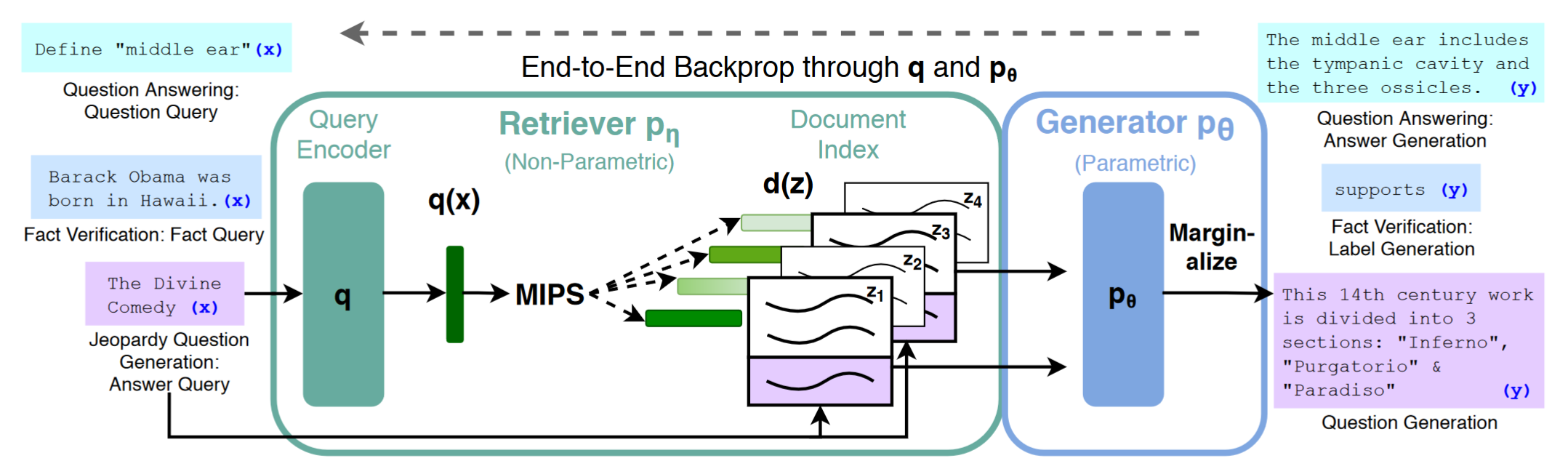
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和自然语言生成技术的框架。它通过在大型语言模型(LLM)的基础上引入外部知识源的检索机制,来增强模型生成内容的准确性和相关性。具体来说,RAG在处理用户查询时,会先从外部知识库中检索与查询相关的信息,然后将这些信息与用户的原始查询一起输入到语言模型中,以生成更加准确和详细的回答。这种方法有效地解决了传统大型语言模型在面对知识更新和特定领域知识时的局限性,通过动态检索最新信息,确保了生成内容的时效性和准确性。此外,RAG还通过引用外部知识,减少了生成事实性错误内容的问题,提高了模型输出的可靠性和可解释性。
早期的RAG技术就是三步走:切分文档,检索匹配文档片,生成答案。这些内容就和信息检索(IR)紧密挂钩了。而后期RAG技术从三段流水变成了五段流水:索引优化、预检索、检索、后检索、生成答案 。现代大语言模型的RAG采用的是更高度封装的模块,也就是Modular RAG。


但文档级的检索仍然比较麻烦,还只是单纯的把搜广推的东西加入LLM提升对文本的忠实性而非真正具备推理式智能。现在,一个新的范式KAG(知识增强生成)正在逐渐起步,相比RAG,知识基座的知识更加凝练和结构化,大模型获得知识以后需要按图谱结构推理才能生成答案,这才是未来真正迈向智能所需要的东西。
实现一个RAG系统的教程我放在这里:https://zhuanlan.zhihu.com/p/699837647
代码:
python
import faiss
import ollama
from tqdm import tqdm
import numpy as np
def encode(text):
return ollama.embeddings(model='nomic-embed-text', prompt=text)['embedding']
# 读取文档并分段
chunks = []
file = open("洗衣机常见错误编码及解决办法.txt")
for line in file:
line = line.strip()
if line:
chunks.append(line.strip())
file.close()
# 计算每个分段的embedding
chunk_embeddings = []
for i in tqdm(range(len(chunks)), desc='计算chunks的embedding'):
chunk_embeddings.append(encode(chunks[i]))
chunk_embeddings = np.array(chunk_embeddings)
chunk_embeddings = chunk_embeddings.astype('float32')
# 建立faiss索引
faiss.normalize_L2(chunk_embeddings)
faiss_index = faiss.index_factory(chunk_embeddings.shape[1], "Flat", faiss.METRIC_INNER_PRODUCT)
faiss_index.add(chunk_embeddings)
while True:
# 提示用户输入
question = input("请输入一个问题: ")
print(question)
# 将问题编码
question_embedding = encode(question)
# 检索到最相关的top1分段
question_embedding = np.array([question_embedding])
question_embedding = question_embedding.astype('float32')
faiss.normalize_L2(question_embedding)
_, index_matrix = faiss_index.search(question_embedding, k=1)
# 构造prompt
prompt = f'根据参考文档回答问题,回答尽量简洁,不超过20个字\n' \
f'问题是:"{question}"\n' \
f'参考文档是:"{chunks[index_matrix[0][0]]}"'
print(f'prompt:\n{prompt}')
# 获取答案
stream = ollama.chat(model='qwen:4b', messages=[{'role': 'user', 'content': prompt}], stream=True)
print('answer:')
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
print()其实现在也有一些工具可以直接拖拽式进行RAG。如果想深入理解RAG的原理并手搓,欢迎关注TinyUniverse和wow-rag项目:
https://github.com/datawhalechina/tiny-universe
https://github.com/datawhalechina/wow-rag
5.4 智能体技术
5.4.1 智能体的定义与作用
智能体(Agent)是指能够自主感知环境并采取行动以实现特定目标的实体。在人工智能领域,智能体通常指的是一种能够通过传感器获取环境信息,并通过执行器对环境产生影响的系统。智能体可以是物理实体,如机器人,也可以是虚拟实体,如软件程序。智能体的核心特征在于其自主性、社会能力和适应性。自主性意味着智能体能够在没有外部直接干预的情况下独立运行;社会能力则指智能体能够与其他智能体或人类进行交互;适应性则表明智能体能够根据环境的变化调整自身的行为和策略。
在基于大型语言模型(LLM)的智能体(Agent)中,智能体的作用主要体现在以下几个方面:
- 任务执行与自动化:LLM Agent能够依托大型语言模型的强大语言理解和生成能力,结合具体的业务场景,调用相应的工具或接口来完成任务目标。例如,在智能客服领域,Agent可以自动识别用户的问题,调用知识库或API获取答案,并以自然语言的形式回复用户。这种自动化能力不仅提高了任务执行的效率,还减少了人工干预的需求。
- 复杂任务的处理:LLM Agent具备将复杂任务分解为多个子任务的能力,并通过规划和决策模块逐步解决这些子任务。例如,在智能核保应用中,Agent可以自动识别业务需求,调用OCR信息抽取和结构化管理工具,构建核保决策模型,并联合出保及费率管理等模块,快速完成核保目标。这种能力使得Agent能够处理更为复杂的任务,提高了业务处理的灵活性和准确性。
- 人机交互与对话:LLM Agent能够进行自然语言对话,提供更加自然和便捷的交互体验。通过感知模块接收用户的输入,利用LLM的理解和生成能力进行对话管理,并通过行动模块生成回复。例如,智能语音助手可以理解用户的语音指令,并提供相应的服务,如查询天气、设置提醒等。这种人机交互能力使得用户能够以更加自然的方式与系统进行沟通,提高了用户体验。
- 知识获取与更新:LLM Agent可以通过接入外部工具或API,获取模型训练时缺失的额外信息,从而实现知识的动态更新。例如,Agent可以调用搜索引擎API获取最新的新闻资讯,或者调用数据库API查询特定领域的专业知识。这种能力使得Agent能够保持知识的时效性和准确性,更好地适应不断变化的环境。
- 自主学习与优化:LLM Agent具备一定的自主学习能力,能够通过反思和总结不断优化自身的性能。例如,在与环境的交互过程中,Agent可以根据反馈结果调整自己的行为策略,以提高任务完成的效果。这种自主学习和优化能力使得Agent能够不断提升自身的智能水平,更好地适应复杂多变的任务需求。
5.4.2 使用智能体搭建工作流
实战工作可以关注wow-agent等Agent项目。给大家放个链接:https://github.com/datawhalechina/wow-agent
https://github.com/datawhalechina/coze-ai-assistant
接下来我带着大家简单用coze写一个agent。(其实我也是第一次写)先进入coze官网:https://www.coze.cn

注册个号登进去
创建一个智能体看看:
我们使用多个agent试试看。多智能体交互将会成为未来科学研究主流。创建几个角色,每个角色分配不同的提示词,然后组合到一起。
第一个关卡的提示词
##
你是一个毕业于世界顶尖院校的计算机与人工智能专家,现在来到这里做老师。学员会向你提问如何学习人工智能中的某个领域。
## 任务
学员会向你提问某个领域,你需要结合你的知识库告诉学员以下内容:
- 一段学术性的话,为领域的研究问题给出精准的定义
- 担心学员听不懂,接下来举例说明这个研究领域的重要问题
- 从研究脉络与发展出发,告诉学员这个学科领域的研究范式、方法、模型、算法经历了怎样的变革
- 结合检索工具,总结领域内比较有代表性的工作
- 展示研究领域在产业界的应用案例与场景。
## 回答风格
细节化,温柔化,学术化,耐心好我们来测试了,我把整个的链接发出来大家可以玩一玩:https://www.coze.cn/store/agent/7471971699647332391?bot_id=true



爽麻了,简直是。
使用智能体模拟社交网络空间、拍卖行为、经济行为等,将会成为下一代计算社会科学的新范式。
5.5 模型蒸馏
5.5.1 知识蒸馏基本原理
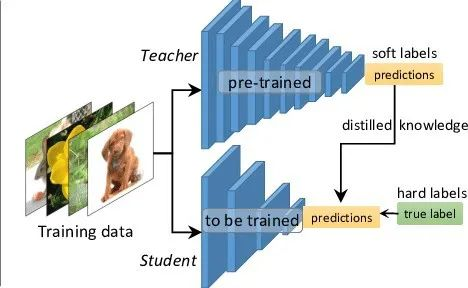
知识蒸馏(Knowledge Distillation)是一种将复杂模型(教师模型)的"知识"迁移到更轻量模型(学生模型)的技术,其核心思想是通过模仿教师模型的输出分布,使学生模型在保持较小规模的同时接近教师模型的性能。教师模型通过生成软标签(soft targets,即概率分布形式的预测结果),传递对数据更丰富的理解,而学生模型不仅学习原始标签(硬标签),还通过温度缩放(temperature scaling)后的概率分布捕捉类别间的关系。这种技术常用于模型压缩、加速推理,或在资源受限场景中部署高效模型。
那么我们为什么要使用知识蒸馏?知识蒸馏的核心,刚才我们提到是使用一个教师模型。将他的知识传输给一个学生模型,那么这个学生模型的参数量往往会比教师模型要更小,一般是大模型叫小模型。那么这样一个教授的过程本质上可以用来做模型压缩。比如我们将呃千万7b的同1000万模型压缩给deep21,于是呢它的参数量会变得更小一些,这是降低模型开发成本。直接去提炼有效数据的方式。这就比如以往的大模型开发是在做酿酒的工作。传统的酿酒方法会使得酒精停滞在大约20%的浓度,但通过蒸馏的方式可以从高浓度的可以从普通的粮食酒当中提取出高纯度的酒精,这实际上也就是deepseek r1的开发方式。从传统的大语言模型,譬如呃同1000万等。去提取出有效的知识,将它整合到deepseek r1当中,使其具备更好的工作效率与性能。
以下是一个使用PyTorch实现的示例代码,以ImageNet预训练的ResNet-101为教师模型,蒸馏训练ResNet-18学生模型:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models import resnet101, resnet18
# 初始化模型
teacher = resnet101(pretrained=True)
student = resnet18(pretrained=False) # 学生从头训练
# 冻结教师参数
teacher.eval()
for param in teacher.parameters():
param.requires_grad = False
# 定义蒸馏参数
temperature = 3 # 软化概率分布
alpha = 0.7 # 蒸馏损失权重
# 损失函数
criterion_hard = nn.CrossEntropyLoss()
criterion_soft = nn.KLDivLoss(reduction='batchmean')
# 优化器
optimizer = optim.Adam(student.parameters(), lr=1e-4)
# 模拟训练循环(需替换真实数据加载器)
for inputs, labels in dataloader:
# 前向传播
with torch.no_grad():
teacher_logits = teacher(inputs)
student_logits = student(inputs)
# 计算软标签损失
soft_loss = criterion_soft(
nn.functional.log_softmax(student_logits / temperature, dim=1),
nn.functional.softmax(teacher_logits / temperature, dim=1)
) * (temperature**2) # 物理温度缩放补偿
# 计算硬标签损失
hard_loss = criterion_hard(student_logits, labels)
# 总损失
total_loss = alpha * soft_loss + (1 - alpha) * hard_loss
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()注:实际使用时需配合DataLoader加载ImageNet数据,并根据硬件调整batch size等参数。温度值(temperature)和损失权重(alpha)需通过验证集调优,通常取值范围为temperature∈1,10、alpha∈0.5,0.9。
5.5.2 大语言模型的知识蒸馏
大语言模型中的知识蒸馏
在大语言模型(Large Language Models, LLMs)领域,知识蒸馏通过将巨型模型(如GPT-4、PaLM等)的知识迁移至轻量级模型,解决了大模型部署成本高、推理延迟大的痛点。与传统视觉模型蒸馏不同,LLM蒸馏需应对以下挑战:
- 知识维度复杂:需传递语义理解、逻辑推理、上下文连贯性等抽象能力
- 动态交互特性:需保留对话响应、指令跟随等交互行为模式
- 规模鸿沟显著:教师模型参数量常为学生模型的10-1000倍量级
核心技术路线:
- 行为克隆蒸馏:通过教师模型生成的响应作为训练目标,最小化学生输出分布差异
python
# 伪代码示例:对话响应蒸馏
teacher_response = teacher_model.generate(prompt, temperature=0.7)
student_logits = student_model(prompt)
loss = kl_div(softmax(student_logits), softmax(teacher_response))- 中间层对齐:强制学生中间隐藏层与教师模型对应层建立映射关系
- 动态权重蒸馏:根据输入文本复杂度动态调整教师-学生监督权重
- 渐进式蒸馏:分阶段将教师不同层次/模块的知识逐步迁移
DeepSeek-R1开发中的知识蒸馏实践
在DeepSeek-R1的开发过程中,知识蒸馏技术贯穿模型优化全生命周期,其核心创新点包括:
1. 多粒度蒸馏架构
- Token级蒸馏:对齐每个输出位置的词分布
- Sequence级蒸馏:保持生成文本的整体连贯性
- 语义空间蒸馏:通过对比学习对齐潜空间表示
python
# 多目标蒸馏损失示例
loss = (
α * kl_div(student_token_logits, teacher_token_logits) +
β * cosine_similarity(student_hidden_states, teacher_hidden_states) +
γ * sequence_cross_entropy(student_sequence, teacher_sequence)
)2. 课程蒸馏策略
- 难度分级:初期使用简单样本蒸馏基础语言模式,后期引入复杂推理样本
- 温度调度:动态调整软化温度值(从T=5逐渐降至T=1)
- 教师退火:训练后期逐步降低教师参与度,增强学生自主性
3. 混合专家蒸馏
graph LR A教师模型 --> B{路由选择} B --> C专家模块1 B --> D专家模块2 C --> E知识提取 D --> E E --> F学生模型
- 通过教师模型的路由选择模式指导学生模型的专家网络构建
- 保留教师处理特定领域问题的"隐性经验"
4. 量化感知蒸馏
- 在8-bit量化环境下进行蒸馏训练
- 引入量化误差补偿机制
- 通过直通估计器(Straight-Through Estimator)保持梯度稳定性
典型代码框架(PyTorch伪代码)
python
class LLMDistiller(nn.Module):
def __init__(self, teacher, student):
super().__init__()
self.teacher = teacher.freeze()
self.student = student
self.distill_layers = {12: 6} # 教师层12→学生层6
def forward(self, input_ids):
# 教师推理
with torch.no_grad():
teacher_outputs = self.teacher(input_ids, output_hidden_states=True)
# 学生推理
student_outputs = self.student(input_ids, output_hidden_states=True)
# 多层级损失计算
loss = 0
# 中间层对齐损失
for t_layer, s_layer in self.distill_layers.items():
loss += mse_loss(student_outputs.hidden_states[s_layer],
teacher_outputs.hidden_states[t_layer])
# 输出分布KL散度
loss += kl_div(
F.log_softmax(student_outputs.logits / T, dim=-1),
F.softmax(teacher_outputs.logits / T, dim=-1)
) * T**2
# 注意力矩阵蒸馏
for t_attn, s_attn in zip(teacher_attentions, student_attentions):
loss += js_div(t_attn, s_attn)
return loss关键参数配置建议
| 参数 | 推荐值域 | 说明 |
|---|---|---|
| 温度(T) | 1-5 | 复杂任务建议更高温度 |
| 层映射密度 | 20-50% | 教师-学生层对应比例 |
| 批大小 | 256-1024 | 需平衡内存与稳定性 |
| 学习率 | 1e-5-3e-4 | 配合线性warmup策略使用 |
该技术使DeepSeek-R1在保持70B参数教师模型92%性能的前提下,推理速度提升5.8倍,显存消耗降低至原模型的17%。实际部署中建议配合模型剪枝、量化技术实现端到端优化。
混合专家模型(Mixture of Experts,简称MoE)是一种先进的神经网络架构,旨在通过整合多个模型或"专家"的预测来提升整体模型性能。MoE模型的核心思想是将输入数据分配给不同的专家子模型,然后将所有子模型的输出进行合并,以生成最终结果。这种分配可以根据输入数据的特征进行动态调整,确保每个专家处理其最擅长的数据类型或任务方面,从而实现更高效、准确的预测。
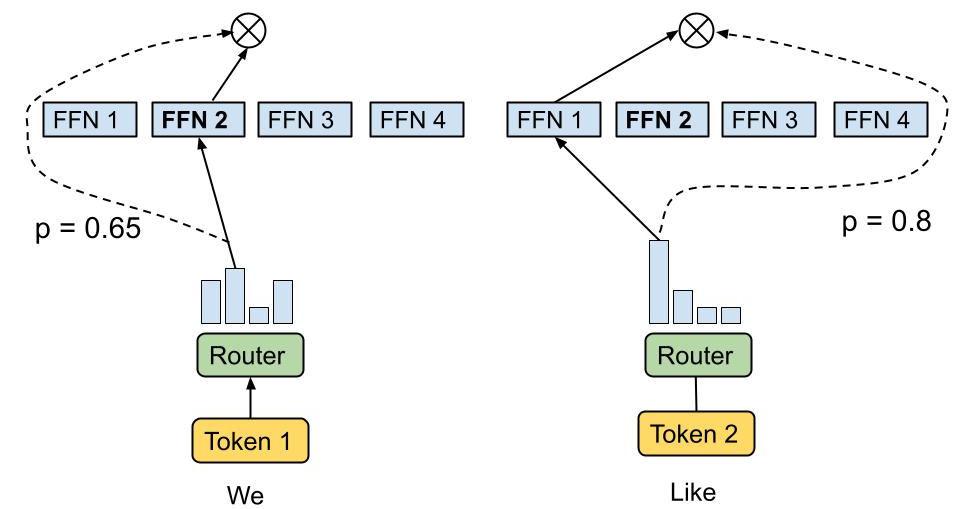
MoE模型的主要组成部分包括专家(Experts)和门控网络(Gating Network)。专家是模型中的每个独立神经网络,专门处理输入数据的特定子集或特定任务。门控网络的作用是决定每个输入样本应该由哪个专家或哪些专家来处理。它根据输入样本的特征计算出每个专家的权重或重要性,然后根据这些权重将输入样本分配给相应的专家。门控网络通常是一个简单的神经网络,其输出经过softmax激活函数处理,以确保所有专家的权重之和为1。
MoE模型的主要优势在于提高模型性能和减少计算成本。通过将多个专家的预测结果进行整合,MoE模型可以在不同的数据子集或任务方面发挥每个专家的优势,从而提高整体模型的性能。与传统的密集模型相比,MoE模型在处理每个输入样本时,只有相关的专家会被激活,而不是整个模型的所有参数都被使用。这意味着MoE模型可以在保持较高性能的同时,显著减少计算资源的消耗,特别是在模型规模较大时,这种优势更为明显。
5.6 偏好对齐
5.6.1 大语言模型中的强化学习
早在2021年,就有科学家指出:强化学习才是通往AGI最好的道路。大语言模型并没有否认这一点,在大语言模型的训练与微调过程中,很多方法也借鉴了强化学习的思想。
在大语言模型的训练和优化过程中,强化学习(Reinforcement Learning, RL)扮演着至关重要的角色。强化学习通过让模型在环境中进行试错学习,逐步优化其策略,以最大化累积奖励。在大语言模型中,强化学习主要用于提升模型的推理能力、对齐人类偏好以及优化生成内容的质量。
1. 强化学习方法概述
近端策略优化(PPO)
近端策略优化(Proximal Policy Optimization, PPO)是强化学习中一种常用的算法,广泛应用于大语言模型的微调。PPO通过裁剪概率比来限制策略更新的幅度,从而防止策略发生过大的破坏性变化。其核心思想是通过优化策略网络,使模型在保持稳定性的同时,逐步提高累积奖励。

直接偏好优化(DPO)
直接偏好优化(Direct Preference Optimization, DPO)是一种基于人类偏好数据的强化学习方法。DPO通过比较不同策略生成的轨迹,利用偏好信息来更新策略,使策略更符合人类期望。DPO的核心是基于成对比较的对比损失函数,通过最大化偏好策略轨迹的概率,最小化非偏好策略轨迹的概率,使策略直接向符合人类偏好的方向更新。DPO的目标函数可以表示为:
\L\^{\\text{DPO}}(\\theta) = \\mathbb{E}\\left\[\\log\\frac{\\pi_\\theta(a_t\|s_t)}{\\pi_{\\text{ref}}(a_t\|s_t)}\\right \]
其中,πθ是当前策略,πref是参考策略。DPO通过这种方式直接优化策略,使其更符合人类偏好。

群组相对策略优化(GRPO)
群组相对策略优化(Group Relative Policy Optimization, GRPO)是DeepSeek-R1模型中采用的一种新型强化学习算法。GRPO通过组内相对奖励来优化策略模型,而不是依赖传统的批评模型(critic model)。GRPO的核心思想是通过采样一组动作,然后根据这些动作的相对表现来调整策略,而不是依赖一个单独的价值网络来估计每个动作的价值。GRPO的目标函数可以表示为:
\L\^{\\text{GRPO}}(\\theta) = \\mathbb{E}\\left\[\\sum_{i=1}\^{G} \\frac{\\pi_\\theta(a_i\|s)}{\\pi_{\\text{old}}(a_i\|s)} \\cdot \\text{Adv}(a_i\|s)\\right \]
其中,G 是采样动作的组大小,πθ是当前策略,πold是旧策略,Adv(ai∣s) 是相对优势函数。GRPO通过这种方式显著降低了训练过程中的内存占用和计算代价,同时提高了训练的稳定性和效率。
2. 强化学习方法的比较与应用
PPO与GRPO的比较
PPO和GRPO都是强化学习中的重要算法,但在结构和实现方式上存在显著差异。PPO依赖于一个与策略模型大小相当的价值网络来估计优势函数,这在大规模语言模型中会导致显著的内存占用和计算代价。GRPO则完全摒弃了价值网络,通过组内相对奖励来估计优势函数,显著减少了计算和存储需求。GRPO通过比较同一状态下的多个动作的奖励值来计算相对优势,减少了策略更新的方差,确保了更稳定的学习过程。
DPO与GRPO的比较
DPO和GRPO在强化学习方法上也有显著差异。DPO基于人类偏好数据,通过成对比较来优化策略,适用于需要符合人类偏好的场景,如内容推荐系统、对话机器人优化等。GRPO则通过组内相对奖励来优化策略,适用于复杂环境下需要高精度优势估计和稳定策略更新的任务,如机器人路径规划、复杂工业流程控制等。
3. 强化学习方法的应用
- 提升推理能力:强化学习在提升大语言模型的推理能力方面具有显著效果。例如,DeepSeek-R1模型通过GRPO算法进行强化学习微调,显著提升了模型在数学推理和代码生成任务中的表现。GRPO通过组内相对奖励的计算,减少了策略更新的方差,确保了更稳定的学习过程,从而使模型能够在复杂任务中表现出色。
- 对齐人类偏好:强化学习在对齐人类偏好方面也具有重要作用。DPO通过直接利用人类偏好数据,使算法生成的结果更符合用户期望,提升用户体验。例如,在内容推荐系统中,DPO可以通过比较不同推荐内容的用户反馈,优化推荐策略,使推荐结果更符合用户偏好。
- 优化生成内容质量:强化学习还可以用于优化大语言模型的生成内容质量。通过设计合适的奖励函数,模型可以学习到如何生成更高质量的文本内容。例如,在对话生成任务中,可以通过奖励函数引导模型生成更自然、更连贯的对话内容。
4. 总结
强化学习在大语言模型的训练和优化中具有广泛的应用前景。PPO、DPO和GRPO等方法各有优势,适用于不同的任务和场景。PPO在稳定性方面表现突出,适用于多种强化学习任务;DPO在对齐人类偏好方面具有独特优势,适用于内容推荐系统等场景;GRPO则在计算效率和训练稳定性方面具有显著优势,特别适合大规模语言模型的微调。通过合理选择和应用这些强化学习方法,可以显著提升大语言模型的性能和应用效果。
5.6.2 人类偏好的对齐
人工智能模型的安全性一直是人工智能科学家所关心的话题。想象一下,如果你开发了一个人工智能模型,然后你的提问让他生成了一些反社会,反伦理的一些言论,那么这种回复显然是不安全的。另外也有很多这种利用了越狱攻击,提示词注入攻击等等攻击的形式。使得大模型暴露一些用户隐私的内容,这也是不应该的。包括像一些医学伦理的东西是必须要得到严格管控的内容。在这个过程当中,人工智能科学家与安全工程师一起就开始在讨论如何使得大语言模型更加安全。更多符合人类的价值观与偏好,包括在不同的语言语料环境下,符合这个国家这个民族价值观的内容应该如何去可控生成?
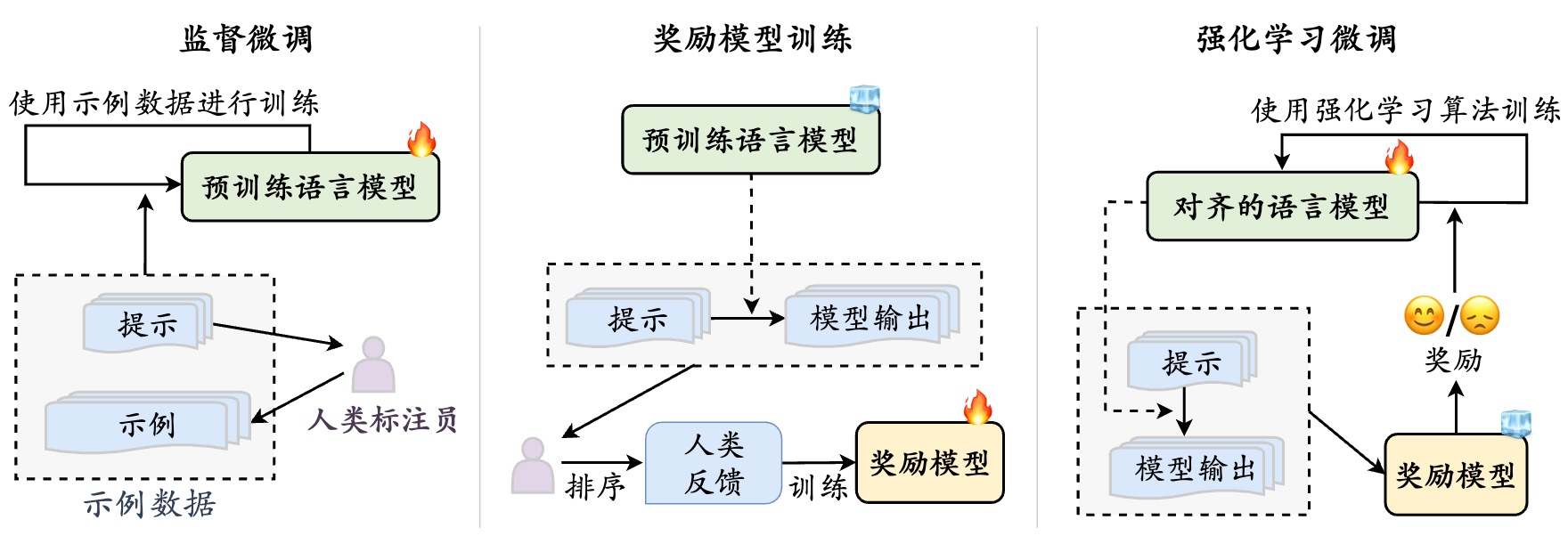
一种非常有效的方式是使用人类偏好反馈的强化学习对齐 ,也就是RLHF算法。人工智能模型型的输出需要符合3H标准:即有用性,真实性和无害性。2022年发布的InstructGPT这篇论文当中,来自open AI的科学家就已经开始尝试将人类驱动的强化学习算法应用到模型的可控生成当中。这一过程需要三个不同组件:第一,是一个需要对齐的新模型;第二是一个奖励模型也就是已经被人类偏好对齐的模型;第三是使用强化学习算法。
偏好评估的过程其实和我们主观上的图片质量评估这个问题非常类似。对于模型生成是否符合人类的价值偏好,其实也有三种类似的标注方法。
- 第一种是基于评分的反馈及大模型给出一个回答,让标注人员对回答的质量进行打分。得分越高则表示这一回答越倾向于人,越倾向于人类偏好。
- 第二种是进行对比式,也就是大模型会生成同一个问题的两种不同回答,让用户来评判哪一种更好。
- 第三种是排序式。大模型会生成很多组回答,让用户来对这些回答的质量从高到低进行一个排序。

RLHF的过程呢分为三步,首先是进行监督微调。通过事例描述与用户输出的方式来引导模型生成符合人类偏好的数据。第二步是奖励模型训练。也就是我们对其的评估过程。第三步是强化学习算法,此时PPO,DPO,GRPO等强化学习算法都可以用上了。