- 本程序的主要目的是对破损的快递盒进行分类检测,主要使用pytorch构建神经网络模型来解决这一问题。
- 本项目为本人第一个与深度学习有关的项目,有疏漏之处多多海涵,可以向我提出
- 有关于pytorch的内容请详见**官方文档** (PyTorch 文档 --- PyTorch 2.0 文档)。如果需要中文版的教程,可以参考**知乎谭庆波** (PyTorch中文版官方教程来啦(附下载) - 知乎 (zhihu.com))的文档。
- 推荐使用CUDA 来运行你的神经网络模型,这样可以使你的代码运行的更快。(CUDA的下载地址(CUDA | GeForce (nvidia.cn)))
- 本程序还额外包括快递盒边缘检测和色彩识别的功能,如果需要使用这些功能,需要下载**opencv** (首页 - OpenCV)。
- 本程序曾用于哈尔滨工业大学的大创项目。作者:魏轶轩、崔家铭、史子琦、李武。
- 项目github地址:https://github.com/weiyixuanxx/Stereo-vision
1.准备数据集
- 本次大创的数据集均存放于data中。
- data下属两个文件:train 和val。其中train为训练集,用于存放所有的训练数据;val为测试集,用于存放所有的测试数据。
- train和val各自下属两个文件a 和b,其含义是将图像分为两类:a类是正常完好包装的快递盒的图像,b类是有破损的快递盒的图像。
- 数据集中的图像通过双目识别摄像头 获取。有关于如何通过双目识别摄像头获取图像以及深度图是我们研究的另一个课题,此处不做阐述。
- (在中期实验阶段,数据集的内容并不是非常充分,有关于数据集的扩充我们打算放到结题部分去考虑。)
2.加载数据集
-
图像的数据预处理:
pythontrain_transformer=transforms.Compose([transforms.Resize(60), transforms.RandomCrop(48), transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])这段代码定义了一个数据预处理的变换序列
train_transformer,其包含四个变换操作:transforms.Resize(60):将输入的图像大小调整为60*60像素大小。transforms.RandomCrop(48):随机裁剪输入图像为48*48像素大小。transforms.ToTensor():将裁剪后的图像转换为张量形式,即将像素值转换为 0,1范围内的浮点数。transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)):对张量进行标准化操作,即减去均值 0.5,除以标准差 0.5。- 下面展示的
val_transformer同理。
pythonval_transformer=transforms.Compose([transforms.Resize(48), transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]) -
读取并载入数据:
pythontrain_dataset=datasets.ImageFolder(datatrain_dir,train_transformer) val_dataset=datasets.ImageFolder(dataval_dir,val_transformer) train_dataloader=torch.utils.data.DataLoader(train_dataset, batch_size=64,shuffle=False,num_workers=1) val_dataloader=torch.utils.data.DataLoader(val_dataset,batch_size=64 ,shuffle=False,num_workers=1)train_dataset和val_dataset分别代表训练集和验证集。train_dataloader和val_dataloader用于将数据集分为小批量,并在训练和验证期间用于加载数据。
3.创建神经网络
-
定义一个神经网络模型:
pythonclass CNN(nn.Module): def __init__(self,classes): super(CNN, self).__init__() self.conv1=nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1) self.conv2=nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1) self.conv3=nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1) self.fc1=nn.Linear(64*6*6,100) self.fc2=nn.Linear(100,classes) def forward(self,x): x=F.relu(self.conv1(x)) x=F.relu(self.conv2(x)) x=F.relu(self.conv3(x)) x=x.view(-1,64*6*6) x=F.relu(self.fc1(x)) x=self.fc2(x) return x如上所示,这段代码定义了一个卷积神经网络模型。
- 该模型包含三个卷积层
conv1、conv2、conv3和两个全连接层fc1、fc2。 - 卷积层
conv1、conv2、conv3分别包含16、32和64个输出通道,使用3*3的卷积核大小,步幅为2,填充为1。 - 全连接层
fc1的输入由卷积层计算得到,为64*6*6;全连接层fc2的输出为自定义classes,这样设计的好处是便于以后的改动。 - 模型的前向传递通过调用
forward方法实现,输入图像x通过三个卷积层和激活函数relu进行特征提取和非线性变换,然后通过view方法将特征展开成一维向量,最后通过两个全连接层和softmax函数输出分类结果。
- 该模型包含三个卷积层
-
使用创建好的神经网络模型:
pythonnet=CNN(2)
4.进行训练、测试
-
初始化损失函数、优化器、学习率、训练轮次:
pythonfrom torch.optim import SGD from torch.optim.lr_scheduler import StepLR optim = SGD(net.parameters(),0.01,0.9) criterion=torch.nn.CrossEntropyLoss() lr_step=StepLR(optim,step_size=50,gamma=0.1) epochs=200optim使用了随机梯度下降SGD优化算法,对模型的参数进行优化更新。SGD有三个参数,第一个参数net.parameters()表示要更新的模型参数,第二个参数lr=0.1表示学习率,第三个参数momentum=0.9表示动量,可以加速训练过程。criterion定义了损失函数,这里使用了交叉熵损失函数CrossEntropyLosslr_step使用了步长学习率调整StepLR策略,即每50个epoch将学习率降低为原来的0.1倍。根据训练情况的不同,应适当调整学习率。epochs表示训练模型的总轮数。
-
创建训练函数:
pythondef train(net,optim,criterion,train_dataloader): running_loss = 0.0 for data in train_dataloader: input,target=data output=net(input) loss=criterion(output,target) optim.zero_grad() loss.backward() optim.step() running_loss += loss.item() return running_loss / len(train_dataloader)如上所示,这段代码定义了一个训练函数
train,用于训练神经网络模型。train接受四个参数:net表示要训练的神经网络模型,optim表示优化器,criterion表示损失函数,train_dataloader表示训练集数据加载器。- 训练过程中,首先将
running_loss初始化为0.0,然后遍历训练集数据加载器train_dataloader中的每个小批量数据data。 - 对于每个小批量数据,首先将输入数据
input和目标标签数据target从data中提取出来,然后将输入数据input传入神经网络模型net中,得到输出output。 - 接下来,将输出
output和目标标签数据target传入损失函数criterion中,计算出当前小批量数据的损失值loss。 - 将优化器
optim的梯度缓存清零optim.zero_grad(),然后根据损失值loss计算梯度loss.backward()并进行参数更新optim.step()。 - 最后将当前小批量数据的损失值加到
running_loss中,计算训练集的平均损失值并返回。
-
创建测试函数:
pythondef test(net,loader,criterion): net.eval() running_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for data in loader: inputs, labels = data inputs, labels = inputs, labels outputs = net(inputs) loss = criterion(outputs, labels) running_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() return running_loss / len(loader), 100 * correct / total如上所示,这段代码定义了一个测试函数
test,用于测试训练好的神经网络模型在测试集上的表现。test接受三个参数:net表示要测试的神经网络模型,loader表示测试集数据加载器,criterion表示损失函数。- 测试过程中,首先将
net设置为评估模式eval,然后将running_loss、correct和total分别初始化为0。 - 接下来,使用
torch.no_grad()上下文管理器,该管理器可以在测试过程中不计算梯度,节省内存和时间。 - 遍历测试集数据加载器
loader中的每个小批量数据data:对于每个小批量数据,首先将输入数据inputs和目标标签数据labels从data中提取出来。 - 将输入数据
inputs传入神经网络模型net中,得到输出outputs。 - 接下来,将输出
outputs和目标标签数据labels传入损失函数criterion中,计算出当前小批量数据的损失值loss,然后将当前损失值加到running_loss中。 - 使用
torch.max函数找出输出outputs中概率最大的预测标签,并将其与目标标签labels进行比较,计算出正确分类的样本数correct和总样本数total。 - 最后,计算测试集的平均损失值和准确率,并返回。
-
使用训练函数和测试函数,进行训练、测试:
pythonfor epoch in range(0,epochs): train_loss=train(net,optim,criterion,train_dataloader) test_loss,test_acc=test(net,train_dataloader,criterion) print("train_loss: " +str(train_loss)+" test_loss: "+str(test_loss)+"test_acc"+str(test_acc)) -
保存训练结果:
pythontorch.save(net,'model.pth')
上述内容的代码均在文件cnn.py中。
5.验证测试结果
验证测试结果的方式有两种:一种是终端输出的结果;一种是编写额外的测试程序。
-
终端输出的结果:
刚开始训练时终端输出的结果,可以发现训练的正确率并不高:

训练300次以后的正确率已经有了显著的提升:
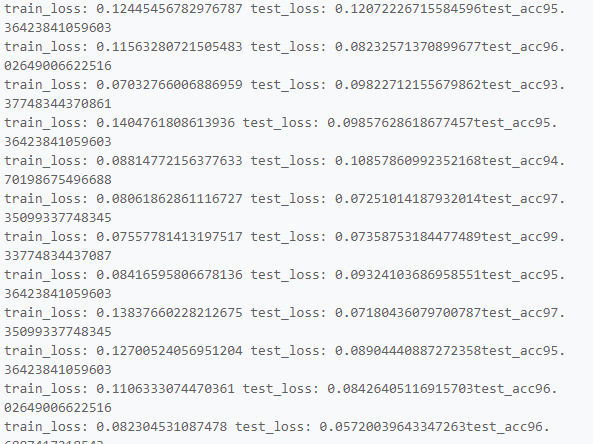
-
额外编写的测试程序:
pythonimport torch import torchvision.transforms as transforms from PIL import Image from cnn import CNN transformer = transforms.Compose([ transforms.Resize((48, 48)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) model = torch.load('model.pth') model.eval() classes = ['good_box', 'evil_box'] img = Image.open('test1.jpg') img_tensor = transformer(img).unsqueeze(0) with torch.no_grad(): output = model(img_tensor) _, predicted = torch.max(output.data, 1) print(classes[predicted.item()])torch.load加载事先训练好的神经网络模型model,然后将其设置为评估模式:model.eval()。classes定义了数据集中的类别,这里是好盒子good_box和坏盒子evil_box。- 本例中,待测试的图像文件是
'test1.jpg',通过img_tensor = transformer(img).unsqueeze(0)将其转换为张量形式。 - 使用
torch.max找出输出中概率最大的预测标签,并将其与类别列表classes进行对应,最后打印出预测结果。
6.基于opencv实现的其它功能
-
基于canny的边缘轮廓检测:
pythondef edge_detection(img,canny_a,canny_b): img0 = cv.GaussianBlur(img, (5, 5), 0) edges=cv.Canny(img0,canny_a,canny_b) _,edges=cv.threshold(edges,127,255,cv.THRESH_BINARY) contours,hierarchy=cv.findContours(edges,cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE) return contours,hierarchy,edges- 上述代码是一个可以实现边缘检测的函数,接受三个参数:原始图像
img,canny算子的两个参数canny_a和canny_b。 cv.GaussianBlur(img, (5, 5), 0):对原始图像进行高斯模糊,去除图像噪点。cv.Canny(img0,canny_a,canny_b):使用Canny算子进行边缘检测,得到二值化的边缘图像。cv.threshold(edges,127,255,cv.THRESH_BINARY):对二值化的边缘图像进行阈值处理,将所有大于等于127的像素值设为255,其余设为0。cv.findContours(edges,cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE):通过findContours函数找到二值化边缘图像中的所有轮廓。return contours,hierarchy,edges:返回轮廓列表、层级和二值化边缘图像。
- 上述代码是一个可以实现边缘检测的函数,接受三个参数:原始图像
-
颜色识别:
pythondef color_detection(img,l1,l2,l3,u1,u2,u3): lower_range=np.array([l1,l2,l3]) upper_range=np.array([u1,u2,u3]) hsv_img = cv.cvtColor(img, cv.COLOR_BGR2HSV) mask = cv.inRange(hsv_img, lower_range, upper_range) target=cv.bitwise_and(img,img,mask=mask) return target- 上述代码是一个可以实现颜色识别的函数,接受七个参数:原始图像
img,指定颜色区域的上下阈值l1、l2、l3、u1、u2、u3,以HSV空间表示。 cv.cvtColor(img, cv.COLOR_BGR2HSV):将输入图像img从BGR颜色空间转换为HSV颜色空间。cv.inRange(hsv_img, lower_range, upper_range):得到指定颜色区域的二值掩模mask,mask中指定颜色区域的像素值为255,其余为0。cv.bitwise_and(img,img,mask=mask):将输入图像img和二值掩模mask进行按位与操作,得到检测结果target。- 最后,函数返回检测结果
target。
- 上述代码是一个可以实现颜色识别的函数,接受七个参数:原始图像