概述:VaanaAI
缘起
使用 AI 生成 SQL 的原因
- 数据仓库和数据湖在企业中广泛应用,但能够精通 SQL 并理解企业数据结构的人很少。AI 可以帮助商业用户使用自然语言查询数据库,生成 SQL 查询,从而提高数据利用率。
简介
- Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,专注于 SQL 生成和相关功能。
它允许用户在自己的数据上训练一个 RAG "模型",然后通过自然语言提问,生成在数据库上运行的 SQL 查询语句,并将查询结果以表格和图表的方式展示给用户。
Vanna 的核心目标是简化数据库交互,让用户无需精通 SQL 即可从数据库中提取有价值的信息。

- URL
20250228 1.2k fork / 13.5k star
-
开源协议: MIT
-
Demo
探索过程
- 在官方文档中,讲述了他们探索如何利用不同的上下文策略和大型语言模型(LLM)来提高 SQL 生成的准确性。
从实验中表明,提供合适的上下文信息可以显著提高 LLM 生成 SQL 查询的准确性,从约3%提升到约80%。
文章比较了多种 LLM,包括 Google Bison、GPT 3.5、GPT 4 ,并展示了结合模式定义、文档和先前 SQL 查询的相关性搜索策略。
| Accuracy | Bison | GPT3.5 | GPT 4 | Avg |
|---|---|---|---|---|
| Schema | 0% | 0% | 10% | 3% |
| Static | 34% | 61% | 74% | 56% |
| Contextual | 91% | 69% | 88% | 83% |
主要发现
- 提供适当的上下文至关重要,可以显著提高 LLM 生成 SQL 的准确性。
- GPT 4 是生成 SQL 的最佳 LLM,但在提供足够上下文时,Google 的 Bison 表现同样优异。
- 三种上下文策略中,结合模式定义、文档和先前 SQL 查询的相关性搜索策略表现最佳。

原文 :《 AI SQL 准确性:测试不同的 LLMs + 上下文策略以最大限度地提高 SQL 生成准确性》
https://vanna.ai/blog/ai-sql-accuracy.html
VannaAI 的优势
- 高准确性:通过 RAG 模型的语义检索和上下文增强,大幅提高了 SQL 生成的准确性,尤其在复杂数据集上表现优异。
- 安全性与隐私:用户的数据库内容不会发送到 LLM 或向量数据库,SQL 执行完全在本地环境中进行,确保数据安全。
- 自我学习:Vanna 可以在成功执行的查询上自动训练,用户也可以通过提供反馈优化模型,逐步提高准确性。
- 支持任何 SQL 数据库:Vanna 允许连接任何支持 Python 连接的 SQL 数据库,极大提高了兼容性。
- 灵活的前端选择:用户可以选择使用 Jupyter Notebook、Slackbot、Web 应用、Streamlit 应用或自定义前端与 Vanna 进行交互。
原理与架构
交互模式:Vanna + LLM/SQL Database/Vector Storage/Front-End
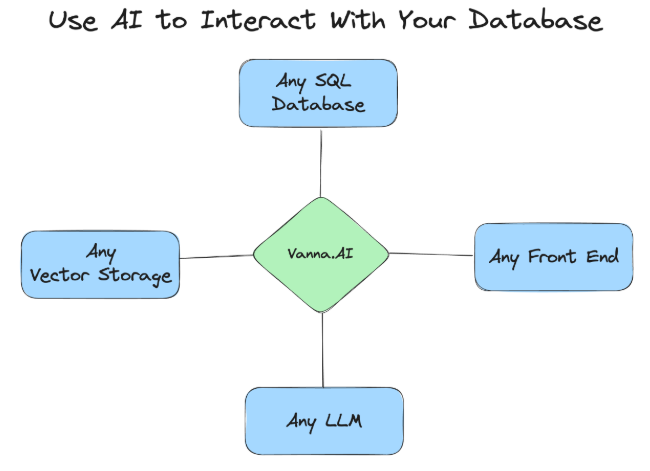
工作原理
How Vanna works
- Vanna的工作分为两个简单的步骤:
- 在你的数据上训练一个RAG"模型",(Train a RAG "model" on your data.)
- 然后问一些问题,这些问题将返回SQL查询,这些查询可以设置为自动在你的数据库上运行。(Ask questions.)
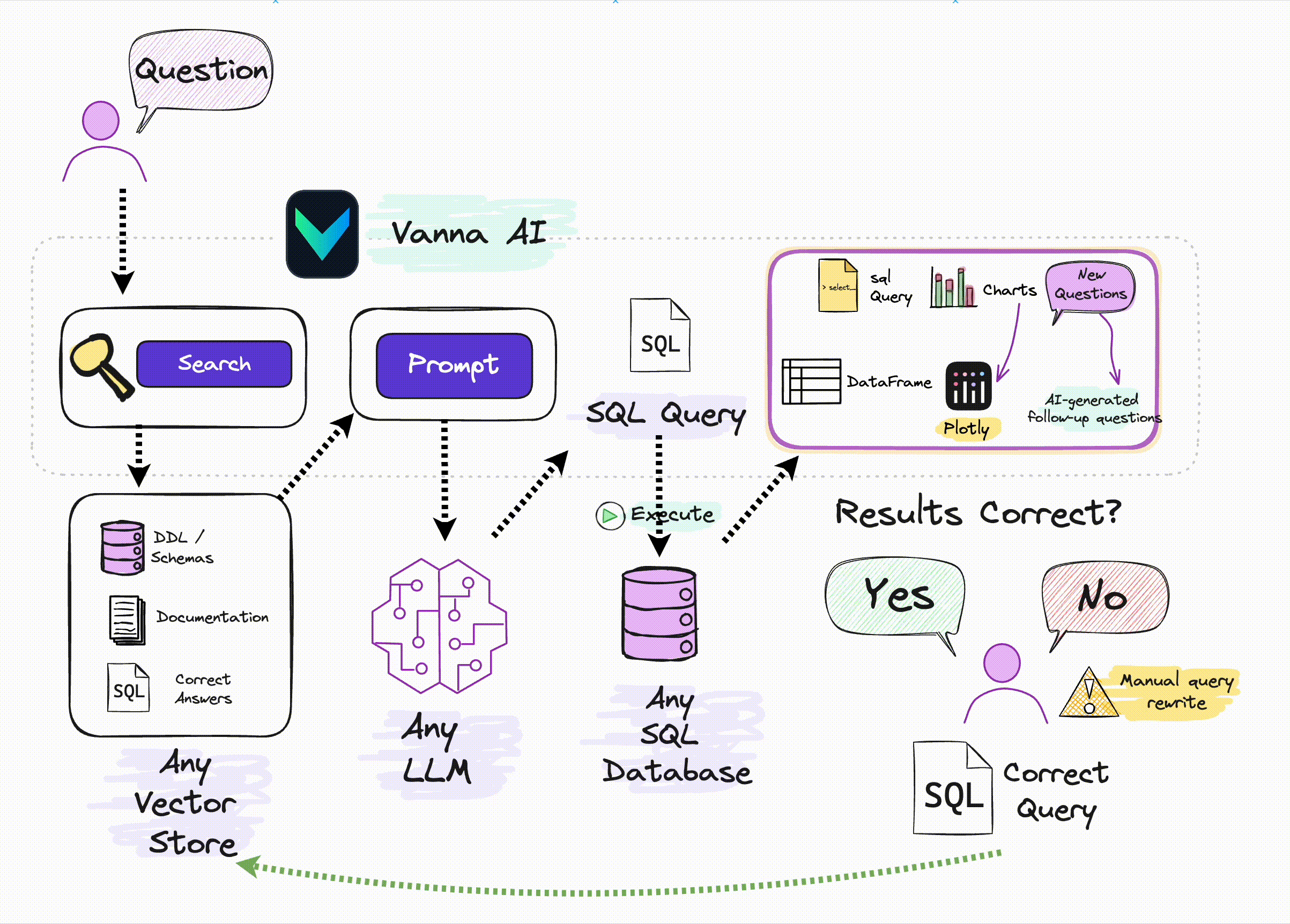

训练RAG模型
- 训练 RAG 模型的关键在于收集并提供足够的上下文信息,包括数据库的结构、列描述、样例查询等。
Vanna 会将这些信息存储在向量库中,并在用户提问时进行语义检索,生成 SQL 语句。
训练建议
主要因素
系统输出准确性的主要决定因素是训练数据的质量。最重要的训练数据是已知正确的问题到 SQL 对。这些对包含了大量嵌入信息,有助于系统理解问题的上下文,特别是在问题模糊时。
使用 Jupyter Notebook
初次使用系统时,建议在 Jupyter Notebook 中进行,以便最大限度地控制训练数据,并执行如提取数据库模式等批量操作。
提示词
- 初次运行时,在提问时尝试提供一些"提示"以帮助系统理解问题的上下文。
例如,如果问题涉及特定表,可以在问题中包含表名。
SQL 语句
避免使用过于通用的 SQL 语句(如 SELECT * FROM my_table)。
最好使用包含列名的具体 SQL 语句(如 SELECT id, name, email FROM my_table)。
vn.train
vn.train 是一个包装函数,允许你训练系统(即 LLM 之上的检索增强层)。可以通过以下方式调用:
DDL 语句
这些语句让系统了解有哪些表、列和数据类型。
python
vn.train(ddl="CREATE TABLE my_table (id INT, name TEXT)")文档字符串(documention)
这些可以是任何关于数据库、业务或行业的文档,有助于 LLM 理解用户问题的上下文。
text
vn.train(documentation="Our business defines XYZ as ABC")SQL 语句
系统理解常用 SQL 查询非常有帮助,有助于理解问题的上下文。
text
vn.train(sql="SELECT col1, col2, col3 FROM my_table")问题-SQL 对
这是训练系统最直接、最有帮助的方式,特别是当用户提问含糊不清时。
text
vn.train(
question="What is the average age of our customers?",
sql="SELECT AVG(age) FROM customers"
)问题-SQL 对包含大量嵌入信息,系统可以使用这些信息来理解问题的上下文。当用户倾向于提出具有很多歧义的问题时,尤其如此。
训练计划
text
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
vn.train(plan=plan)训练计划基本上就是将数据库信息架构分解成可供 LLM 参考的小块。这是一种快速使用大量数据训练系统的好方法。
- **更多详细信息,请访问 Vanna.AI 文档
生成 SQL 并返回结果
- 在用户提问时,Vanna 通过
RAG模型 检索相关信息,生成Prompt并交给LLM生成SQL查询。
生成的 SQL 查询会在数据库中执行,并将结果返回给用户,以表格和图表的形式展示。
例如:
text
vn.ask("What are the top 10 albums by sales?")生成的Prompt部分内容如下:
text
You are a SQLite expert. Please help to generate a SQL query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
Response Guidelines
1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question.
2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql
3. If the provided context is insufficient, please explain why it can't be generated.
4. Please use the most relevant table(s).
5. If the question has been asked and answered before, please repeat the answer exactly as it was given before.生成的sql如下:
text
SELECT
a.AlbumId, a.Title, SUM(il.Quantity) AS TotalSales
FROM Album a
JOIN Track t ON a.AlbumId = t.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY a.AlbumId, a.Title
ORDER BY TotalSales DESC
LIMIT 10;查询出来的结果如下:
绘制的图表


核心模块
RAG 模型
- RAG(Retrieval-Augmented Generation)模型是 Vanna 的核心技术,通过结合检索和生成技术,提高 SQL 生成的准确性。
RAG 模型的训练数据包括数据库的 DDL 语句、表结构、元数据、样例查询和相关文档。这些信息被嵌入到向量库中,在生成 SQL 时提供上下文支持。
一句话总结:RAG(中文为检索增强生成) = 检索技术 + LLM 提示。
例如,我们向 LLM 提问一个问题(answer),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
工作流程
下面这张图片展示了大概的工作流程。
基本上,主要思路就是利用LLM来生成多个查询,期望能够通过这些查询让问题的各个方面在上下文中显现出来。
之后你可以使用生成的查询进行向量搜索(如本系列之前的部分所述),并且基于其在结果集中的显示方式来对内容进行重新排序。

RAG架构
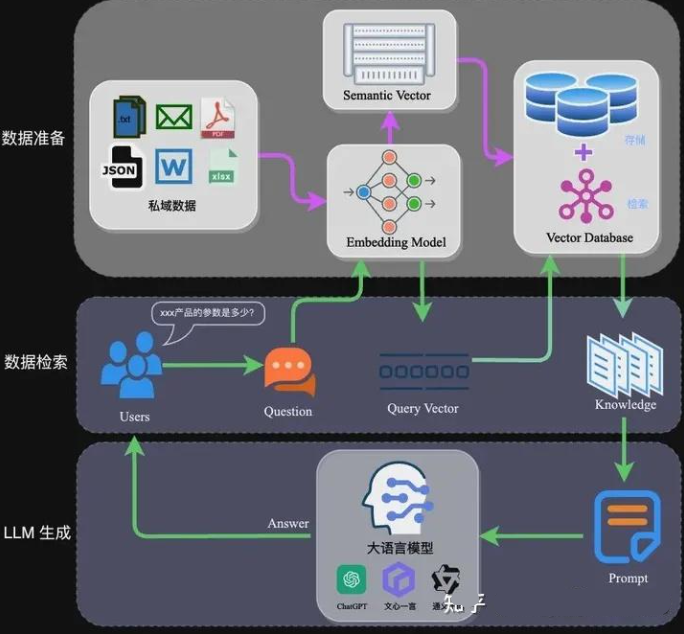
完整的RAG应用流程主要包含两个阶段:
-
数据准备阶段:数据提取------>文本分割------>向量化(embedding)------>数据入库
-
应用阶段:用户提问------>数据检索(召回)------>注入Prompt------>LLM生成答案
关于RAG详细内容请看链接(《一文读懂:大模型RAG(检索增强生成)》)
向量库
- 向量库存储了从训练数据中提取的向量表示,这些向量表示用于在生成 SQL 查询时进行语义检索。
向量库的质量直接影响 SQL 生成的准确性,因此在训练时尽可能提供丰富的上下文信息非常重要。
从前面的vanna工作流程图中我们可以看到,向量库的主要作用是:
-
将训练数据按照DDL,document,sql问答对分别创建了三个collection,也就是三类数据将分别存储和检索。对于sql/question会将数据变成{"question": question,"sql": sql}json字符串存储。
-
当用户询问的时候,问题会去向量库匹配关联度最高的DDL,document,sql问答对,形成prompt,发送给LLM,大语言模型会根据prompt的内容作为参考,生成对应的sql。
Vanna也是提供了多种向量库可以根据自身需求配置
大语言模型(LLM)
- 大语言模型(如 GPT-4)负责根据检索到的上下文生成 SQL 查询。
Vanna 默认使用 OpenAI 的在线 LLM 服务,但用户也可以配置自己的 LLM。
大语言模型通过解析用户的自然语言问题,结合向量库中检索到的上下文信息,生成准确的 SQL 查询。
- 在探索过程中,也讲到了在开发过程中,工程师们也对不同大语言模型在不同语境下准确生成sql的情况做了统计,可以看出提供适当的上下文至关重要,可以显著提高 LLM 生成 SQL 的准确性。
并且GPT 4 是生成 SQL 的最佳 LLM,所以在推荐中也是优先推荐OpenAI的GPT4.
Vanna也是提供了多种大语言模型可供选择
大语言模型的资料太多了,感兴趣的小伙伴可以自己去网上查阅
用户界面
User Interfaces
- Jupyter Notebook
- vanna-ai/vanna-streamlit
- vanna-ai/vanna-flask
- vanna-ai/vanna-slack
支持的LLM大模型
支持的向量存储
Supported VectorStores
支持的数据库
- PostgreSQL
- MySQL
- PrestoDB
- Apache Hive
- ClickHouse
- Snowflake
- Oracle
- Microsoft SQL Server
- BigQuery
- SQLite
- DuckDB
安装指南
安装 on Python pip
- 安装 python 环境
- 安装 python 虚拟环境管理器 : conda
- 创建 python 环境
shell
conda create --name python3.12-ai python=3.12- 安装 vanna
shell
pip install vanna总结
- Vanna 是一个强大且灵活的开源工具,通过 RAG 技术简化了与数据库的交互过程,使得用户无需掌握复杂的 SQL 语法,即可高效地从数据库中提取信息。
- 其高扩展性和灵活配置的特点,使其在各种应用场景中都能发挥重要作用。
- 未来,Vanna 有望成为创建 AI 数据分析师的首选工具,通过不断提高准确性、交互能力和自主性,进一步接近人类数据分析师的水平。
Y 推荐文献
- VannaAI
- Documentation : > https://vanna.ai/docs
- https://vanna.ai/docs/training-advice