一文读懂知识蒸馏
一句话解释:知识蒸馏是一种模型压缩技术(model compression technique),通过让小模型(学生模型)学习大模型(教师模型)的输出或中间表示,以在保持精度的同时减少计算量和存储需求。
传统意义上的知识蒸馏
背景知识及总览
- Bucilua等人(2006年)首次提出了模型压缩,将信息从大型模型或模型集合转移到训练小型模型中,而不会显著降低准确性。
- 后来Hinton等人(2015年)正式提出为知识蒸馏,小模型从大模型中学习。
- 知识蒸馏对象由传统深度神经网络(DNNs)到如今的通用大语言模型(LLMs)。
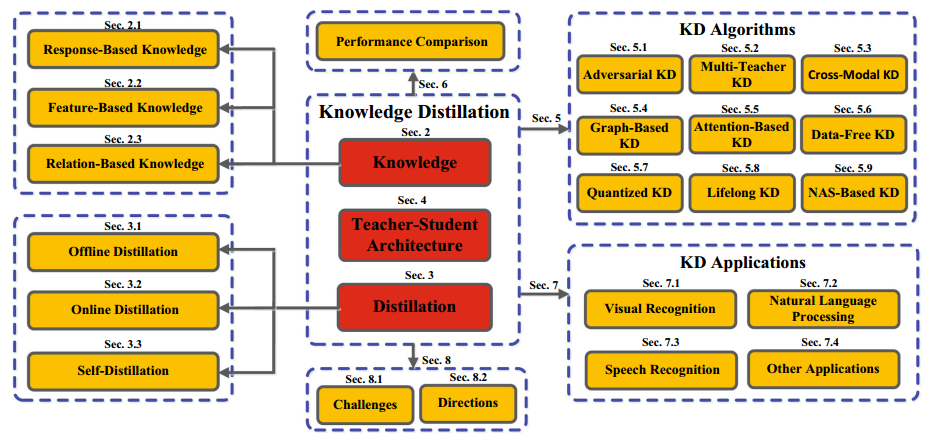
传统知识蒸馏主要从下面几个角度下手:知识类型、蒸馏方案、师生架构、蒸馏算法和蒸馏应用。
知识类型(knowledge types)
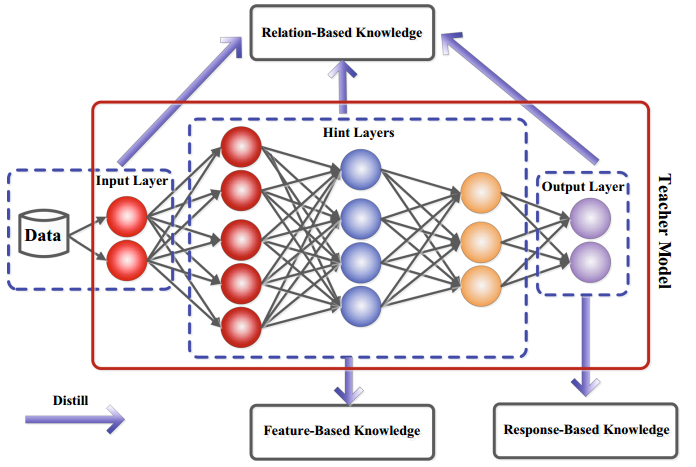
知识分为三种类型:基于响应(response) 的知识、基于特征(feature) 的知识和基于关系(relation) 的知识。
由上图可以清晰的看出:
1.基于响应的知识依赖于从教师模型的输出层 来获取知识(通过监督微调学习教师模型输出概率分布)。
2.基于特征的知识依赖于匹配学生模型和教师模型隐藏层 中的特征表示(例如CV中不同卷积层代表图片不同特征:边缘、纹理和形状等)。
3.基于关系的知识依赖于 <输入x,特征网络n、输入y> 类似这种三元组内部的关系(考虑样本之间的关系,如数据分布模式、隐空间结构和样本之间相似性等)。
蒸馏方案(Distillation Schemes)
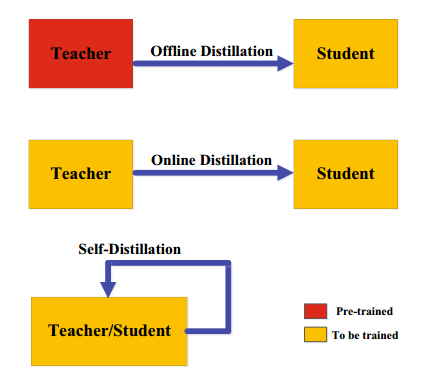
1.离线蒸馏(Offline Distllation)
两步走:
①.先用一组数据样本训练大型教师模型。
②.提取教师模型的logits或中间特征形式的知识,用于指导学生模型训练。
logits:模型在softmax或sigmoid前的输出值,本身不是概率分布。
优点:简单易行
缺点:训练大模型开销大。学生模型依赖于教师模型,且差距依然存在。
2.在线蒸馏(Online Distllation)
教师模型和学生模型同步 更新,整个知识蒸馏框架式端到端可训练 的。
优点:高效、并行计算、端到端。
缺点:很难适用于高容量的教师模型
3.自我蒸馏(Self-Distllation)
在自我蒸馏中,教师和学生使用相同的网络,自我蒸馏可看成在线蒸馏的一个特例。
总结
离线蒸馏是指知识渊博的老师教给学生知识;在线蒸馏意味着教师和学生共同学习;自我蒸馏是指学生自学知识。
这三种蒸馏方案可以相互结合。
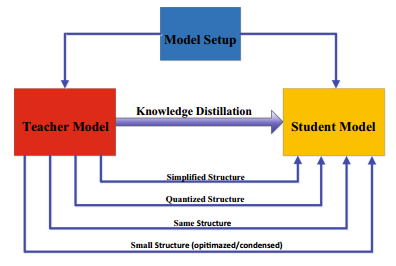
师生模型架构(Teacher-Student Architecture)
深度神经网络主要受两方面影响:深度和宽度(Depth and width) 。
学生网络的选择:
①.教师网络的简化(quantized)版本,每层具有更少的层和更少的通道。
②.教师网络的量化(quantized)版本,其中保留了网络的结构。
③.具有高效基本操作的小型网络。
④.具有优化的全局网络结构的小型网络。
⑤.与教师相同的网络。
蒸馏算法(Distillation Algorithms)
1.对抗式蒸馏(Adversarial Distillation)
挑战:知识蒸馏中,教师模型很难从真实的数据分布中完美地学习。同时,学生模型的容量很小,无法准确模仿教师模型。
生成式对抗网络GAN(generative adversarial networks)的出现缓解了这一问题。
GAN中的鉴别器(discriminator)估计样本来自训练数据分布的概率,也就是找出数据中的假数据,而生成器(generator)试图使用生成的数据样本欺骗鉴别器,也就是生成更逼真于数据集的数据。
GAN的使用可以总结出三个要点:
①.GAN是通过教师知识转移增强学生学习能力的有效工具。
②.联合GAN和KD可以为提高KD性能生成有价值的数据并且克服数据不可用和无法获取的局限性。
③.KD可用于压缩GAN。
2.多教师蒸馏(Multi-teacher Distillation)
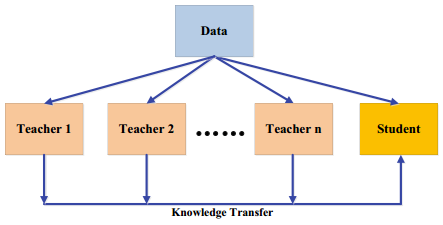
最简单的方法就是用所有教师的平均响应作为监督信号,此外还有许多不同的方法,例如给教师添加不同类型的噪声、使用具有特征集合的多个教师模型等。
3.其他蒸馏方式
此外,其他蒸馏方式例如跨模态蒸馏 (在不同模态之间传递知识)、基于图蒸馏 (将图作为教师知识的载体或者使用图形来控制教师知识的消息传递)、基于注意力蒸馏 (注意力可以很好地反映卷积神经网络的神经元激活)、无数据蒸馏 (利用GAN生成数据)、定量蒸馏 、终身(lifelong)蒸馏 (旨在以与人类相似的方式学习)、基于神经结构搜索(NAS)蒸馏(旨在自动识别深度神经模型并自适应地学习适当的深度神经结构)。
基于大语言模型的知识蒸馏
问题提出
1.尽管例如GPT-4和Gemini这种转悠模型能力强大,但是通常伴随着高额的使用费和受限的访问权限。
2.使用这些模型可能涉及数据隐私和数据安全问题。
3.可能并不总是适用于一些横向领域的应用。

KD在LLM中起到三个关键作用:1)主要是增强能力 ;2)提供传统的压缩 效率;3)通过自我生成的知识进行自我改进的新型趋势;
基于LLM的知识蒸馏总览
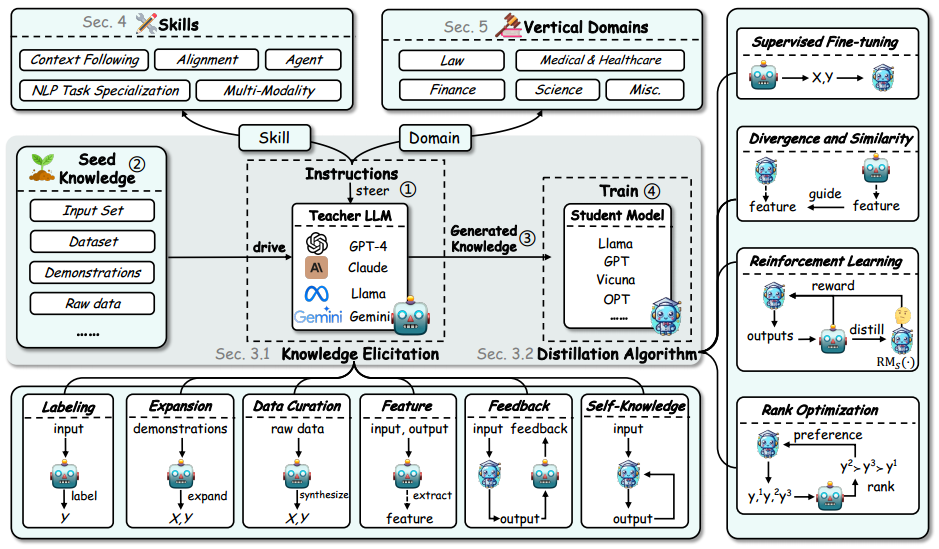
传统意义上的知识蒸馏主要集中在将知识从复杂、繁琐的神经网络转移到更紧凑的架构上,而LLM拥有巨大参数量导致当前的知识蒸馏重点从单纯的架构压缩转移到知识启发和转移。
当前的知识蒸馏也强调了更抽象的品质转移,例如推理模型 (reasoning patterns)、偏好一致性 (preference alignment)和价值一致性(value alignment)。
数据增强(data augmentation)也称为不可或缺的一部分,旨在以某种方式去扩展训练数据集,例如通过提示词(prompt)指导LLM生成高质量目标数据集。
蒸馏算法可以分为以下几种:监督微调 (Supervised fine-tuning)、发散最小化 (divergence minimization)、强化学习 技术(reinforcement learning techniques)和排名优化策略(rank optimization strategies)。

蒸馏管道(pipeline )可以分为四个步骤:
①.选择特定领域或技能的教师LLM。
②.选择种子知识作为输入(种子知识通常包括与教师LLM的引出技能或领域知识相关的小数据集或特定数据线索)。
③.生成蒸馏知识(可以包含问答对话、自然语言解释、模型logits或hidden features等)
④.用特定学习目标训练学生模型。
获取知识
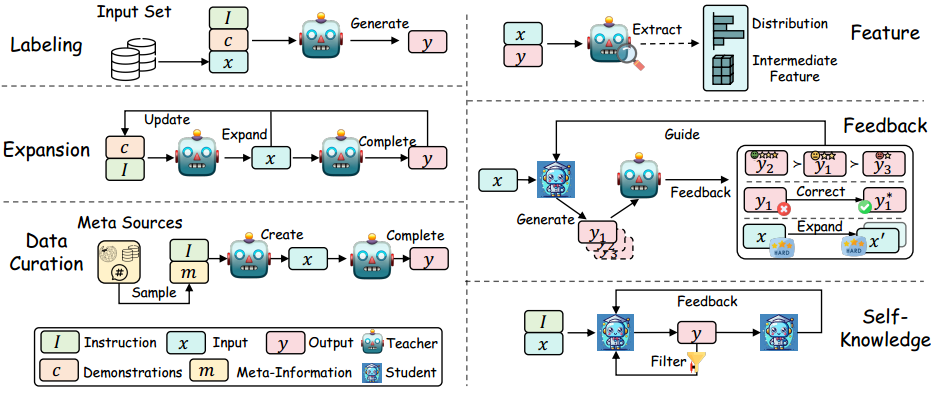
根据获取知识的方式可以分为下面几类:标签化 (labeling)、扩展 (expansion)、特征理解 (feature uderstanding)、反馈机制 (feedback mechanisms)和自我知识(self-knowledge)。
标签化(Labeling)
标记知识是指根据指令I或演示c,使用教师LLM将给定输入x的输出y标记为种子知识,目标是得到x对应输出的y ,其中c=(x1)\(c=(x_1,y_1),...,(x_n,y_n)\)。可以用如下公式表示:
\\\mathcal{D}\^{(\\text{lab})} = \\left\\{ x, y \\mid x \\sim \\mathcal{X}, y \\sim p_T(y \\mid \\mathbf{I} \\oplus c \\oplus x) \\right\\} \\
其中\(\oplus\)表示融合两段文本。
常用的指导标签生成的指令类型是思维链(chain-of-thought)
COT:一种提升大模型推理能力的方法,它通过让模型逐步拆解复杂问题,像人类思考一样分步骤推理,而不是直接给出答案,从而提高准确性和可解释性。
标签化缺点:受到输入数据的规模和种类的限制。
扩展(Expansion)
扩展和标签化不同的是,提供指令I和演示c,指导LLM生成输入x和输出y 。
可用如下公式表示:
\\\mathcal{D}\^{(\\text{exp})} = \\left\\{ (x, y) \\mid x \\sim p_T(x \\mid \\mathbf{I} \\oplus c), y \\sim p_T(y \\mid \\mathbf{I} \\oplus x) \\right\\} \\
缺点:1.生成的数据质量和多样性依赖于教师LLM和演示种子c,可能会导致数据集具有该LLM的固有偏差。2.扩展过程可能会无意中放大种子数据存在的偏差。
数据监管(Data Curation)
数据监管通过广泛的元信息作为种子只是来管理高质量或大规模的数据。
它是从头开始合成数据的方法,元信息如主题或知识点可以被纳入这个过程,以便生成可控的x和y,以产生不仅规模大且质量高的数据集。可用如下公式表示:
\\\mathcal{D}\^{(\\text{cur})} = \\left\\{ (x, y) \\mid x \\sim p_T(x \\mid \\mathbf{I} \\oplus m), y \\sim p_T(y \\mid \\mathbf{I} \\oplus x) \\right\\} \\
其中,m代表用于指导x合成的各种元信息。
特征(Feature)
此方法适用于白盒模型且参数小于1B的语言模型,类似传统方法匹配师生模型隐藏层的特征表示。
教师模型用其内部表示对输出序列y进行注释,然后使用KL散度等方法提取到学生模型中。可用如下公式表示:
\\\mathcal{D}\^{(\\text{feat})} = \\left\\{ (x, y, \\phi_{\\text{feat}}(x, y; \\theta_T)) \\mid x \\sim \\mathcal{X}, y \\sim \\mathcal{Y} \\right\\} \\
其中,\(\phi_{\text{feat}}(·; \theta_T)\)表示从教师LLM中提取特征知识(如输出分布)的操作。
缺点:可能不如黑箱模型(闭源的一般参数都很大,如GPT-4)。
反馈(Feedback)
通过教师模型给学生模型提供反馈,学生模型根据反馈来完善自己,来提高学生模型的学习效果(多轮迭代)。反馈如提供偏好(preferences)、评估(assessments)或者纠正信息(corrective information)。可用如下公式表示:
\\\mathcal{D}\^{(\\text{fb})} = \\left\\{ (x, y, \\phi_{\\text{fb}}(x, y; \\theta_T)) \\mid x \\sim \\mathcal{X}, y \\sim p_S(y \\mid x) \\right\\} \\
其中,\(\phi_{\text{fb}}(·; \theta_T)\)表示教师LLM的反馈。
自我知识(Self-Knowledge)
从学生模型本身引出知识,称为自我知识。同一个模型既充当教师又充当学生 ,通过提取和精炼自己先前生成的输出来迭代地改进自己。可用如下公式表示:
\\\mathcal{D}\^{(\\text{sk})} = \\left\\{ (x, y, \\phi_{\\text{sk}}(x, y)) \\mid x \\sim \\mathcal{S}, y \\sim p_S(y \\mid \\mathbf{I} \\oplus x) \\right\\} \\
其中,\(\phi_{\text{sk}}(·)\)是一个广义函数,表示自生成输出y的额外过程,可能包括但不限于过滤(filtering)、奖励(rewarding)或其他增强或评估y的机制。
蒸馏算法(Distillation algorithms)
大致包含以下四类:监督微调 (Supervised Fine-Tuning)、发散和相似性 (Divergence and Similarity)、强化学习 (Reinforcement Learning)和排名优化(Rank Optimization)。
监督微调(SFT)
将学生预测和教师预测对齐。根据从教师模型得到的(x,y)数据对来训练学生模型。可用如下公式表示:
\\\mathcal{L}_{\\text{SFT}} = \\mathbb{E}_{x \\sim \\mathcal{X}, y \\sim p_T(y \\mid x)} \\left\[ -\\log p_S(y \\mid x) \\right \]
发散和相似(Divergence and Similarity)
适用于白盒模型,从教师LLM中提取特征知识,包括分布 和隐藏状态特征 ,然后与学生模型中的特征相匹配。大致可分为两类:最小化概率分布的发散 ;增强隐藏状态的相似性;
发散(Divergence)
目标是使教师模型和学生模型的概率分布之间的散度最小化。可用如下公式表示:
\L_{\\text{Div}} = \\mathbb{E}_{x \\sim \\mathcal{X}, y \\sim \\mathcal{Y}} \\left\[ D\\left( p_T(y \\mid x), p_S(y \\mid x) \\right) \\right \]
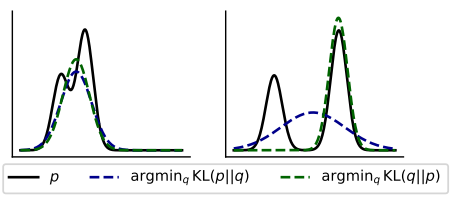
上图展示正向KL散度和反向KL散度的区别。正向KL散度倾向于覆盖目标分布的所有模式,但精度较低(模式覆盖 ),覆盖范围广。反向KL散度倾向于关注最突出的模型(模式寻求),有尖尖。
模式覆盖:可能导致幻觉和低质量的世代。更适用于机器翻译等任务,这些输出模式或变化较少。
模式寻求;可培养更准确的世代但牺牲了多样性。更适用于对话生成和指令调优等任务,这些任务涉及多种模式和更广泛的潜在响应。
相似(Similarity)
目标是将教师模型和学生模型的隐藏状态或特征进行对齐,确保学生模型不仅产生与教师相似的输出,而且以可比的方式处理信息。可用如下公式表示:
\\\mathcal{L}_{\\text{Sim}} = \\mathbb{E}_{x \\sim \\mathcal{X}, y \\sim \\mathcal{Y}} \\left\[ \\mathcal{L}_F \\left( \\Phi_T \\left( f_T(x, y) \\right), \\Phi_S \\left( f_S(x, y) \\right) \\right) \\right \]
在基于LLM的KD中,采用相似方法的很少(模型结构复杂,参数量大)。
强化学习(Reinforcement Learning)
适用于利用教师模型的反馈来训练学生模型,主要包含两个阶段:
1.训练蒸馏奖励模型
由输入输出对\((x,y_w,y_l)\)组成。在这里,\(y_w\)和\(y_l\)代表相对于教师偏好的"获胜"和"失败"输出,可用如下公式表示:
\\\mathcal{L}_{\\text{RM}}(r_{\\phi}, \\mathcal{D}\^{(\\text{fd})}) = - \\mathbb{E}_{(x, y_w, y_l) \\sim \\mathcal{D}\^{(\\text{fd})}} \\left\[ \\log \\sigma \\left( r_{\\phi}(x, y_w) - r_{\\phi}(x, y_l) \\right) \\right \]
2.强化学习优化
根据训练好的奖励模型,对由策略\(π_θ\)表示的学生模型进行优化,以最大化预期奖励。同时,它最小化了与参考策略\(π_ref\)的分歧,\(π_ref\)通常是由因子β控制的SFT训练的学生模型的初始策略。可由以下公式表示:
\\\max_{\\pi_{\\theta}} \\mathbb{E}_{x \\sim \\mathcal{X}, y \\sim \\pi_{\\theta}(y \\mid x)} \\left\[ r_{\\phi}(x, y) - \\beta D_{\\text{KL}} \\left\[ \\pi_{\\theta}(y \\mid x) \\\| \\pi_{\\text{ref}}(y \\mid x) \\right \right] \]
除了训练一个专门的奖励模型,也可以将教师模型直接作为奖励模型,在RL期间直接分配奖励。
排名优化(Ranking Optimization)
排名优化为RL提供了一种稳定且计算效率高的方案,用于将偏好反馈注入语言模型。这种对偏好的直接优化,不需要采样输出,使过程更加稳定和高效。
典型的算法有直接偏好优化DPO (Direct Preference Optimization)、排序响应以对齐人类反馈RRHF (Rank Responses to align Human Feedback)和偏好排序优化PRO(Preference Ranking OPtimization)。
技能蒸馏(Skill Distillation)
有如下几种技能:上下文跟踪 (Context Following)侧重于学生理解和有效回应输入信息的能力。对齐 (alignment)深入研究了学生将其输出与老师的回答对齐的能力。智能体 (Agent)强调了语言模型的自主性。NLP任务专业化 突出了LLM在各种自然语言处理任务方面的多功能性,展示了其适应性。多模态包括从教师LLM到多模态模型的知识转移。
这里简单介绍一下
上下文跟踪:1.用提示词prompt指导LLM处理上下文。2.使用多轮对话数据训练模型增强多轮对话能力。3.利用检索增强生成(RAG)等技术检索最新知识以提供给LLM。
对齐:1.不仅要模仿教师模型的输出,思考模式也要学会。2.偏好对齐。3.价值对齐。
智能体:1.让LLM学会使用工具。2.有类似COT的能力,将复杂问题拆解成一个个小问题逐个解决。
NLP任务专业化:1.自然语言理解NLU(Natural Language Understanding)。2.自然语言生成NLG(Natural Language Generation)。3.信息检索IR(Information Retrieval)。4.推荐系统(Recommender systems)。5.文本生成评估(Text Generation Evaluation)。6.代码(Code)。
多模态:1.视觉模型。2.多模式。3.其他等等。
参考文献
- Gou J, Yu B, Maybank S J, et al. Knowledge distillation: A surveyJ. International Journal of Computer Vision, 2021, 129(6): 1789-1819.
- Xu X, Li M, Tao C, et al. A survey on knowledge distillation of large language modelsJ. arXiv preprint arXiv:2402.13116, 2024.
- 【CSDN】一文搞懂知识蒸馏算法原理