技术背景
想必最近有在部署DeepSeek大模型的人,看标题就知道这篇文章在做什么事情了。由于Ollama对于IP的监听缺乏安全防护,并且内网部署的Ollama模型对于外网来说也是不可见的,而如果使用一些公网API,又存在隐私数据泄露的风险。这里提供一个方案:使用端到端加密的通讯软件,将消息内容转为token传输给Ollama本地部署的模型,然后接收token作为消息,通过加密通讯返回给用户。但是考虑到加密通讯软件的用户群体并不是很大,这里仅仅使用Slack作为一个演示。需要注意的是,Slack公司也有自己的AI模型SlackAI,在用户数据安全防护这一块有多大的可靠性,留给大家自行判断。
Slack应用注册流程
我们先假定你已经有一个Slack账号和相应的Slack工作区了,那么可以进入到app界面去创建一个自己的应用:
我选择的是scratch创建模式:
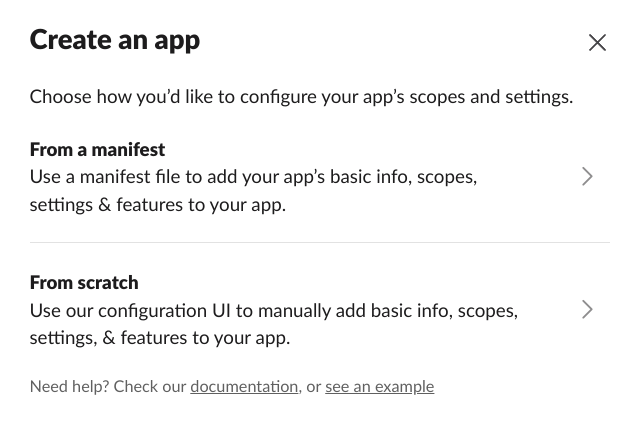
这样就能在网页界面上进行配置。选择好自己的工作区,配置该机器人在工作区中的名字:
创建完成后大概是这样的:
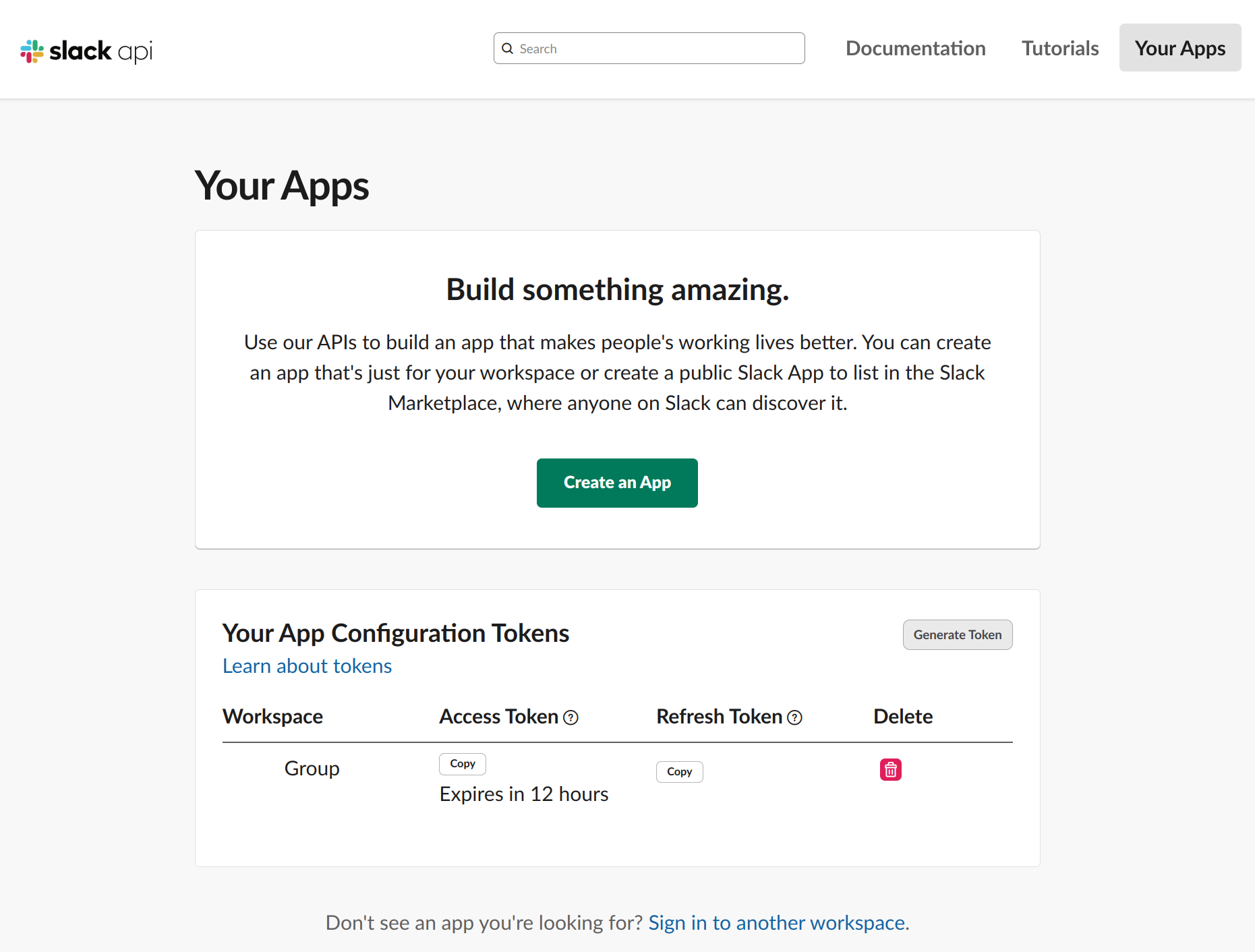
然后可以进入到APP的设置界面:
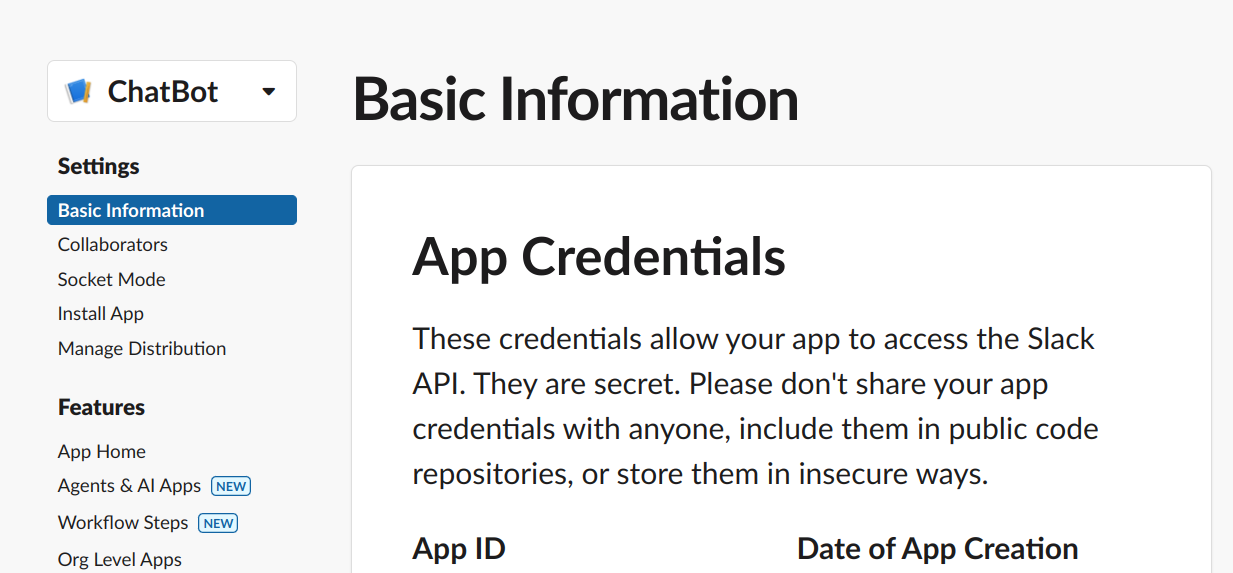
要打开Socket模式:
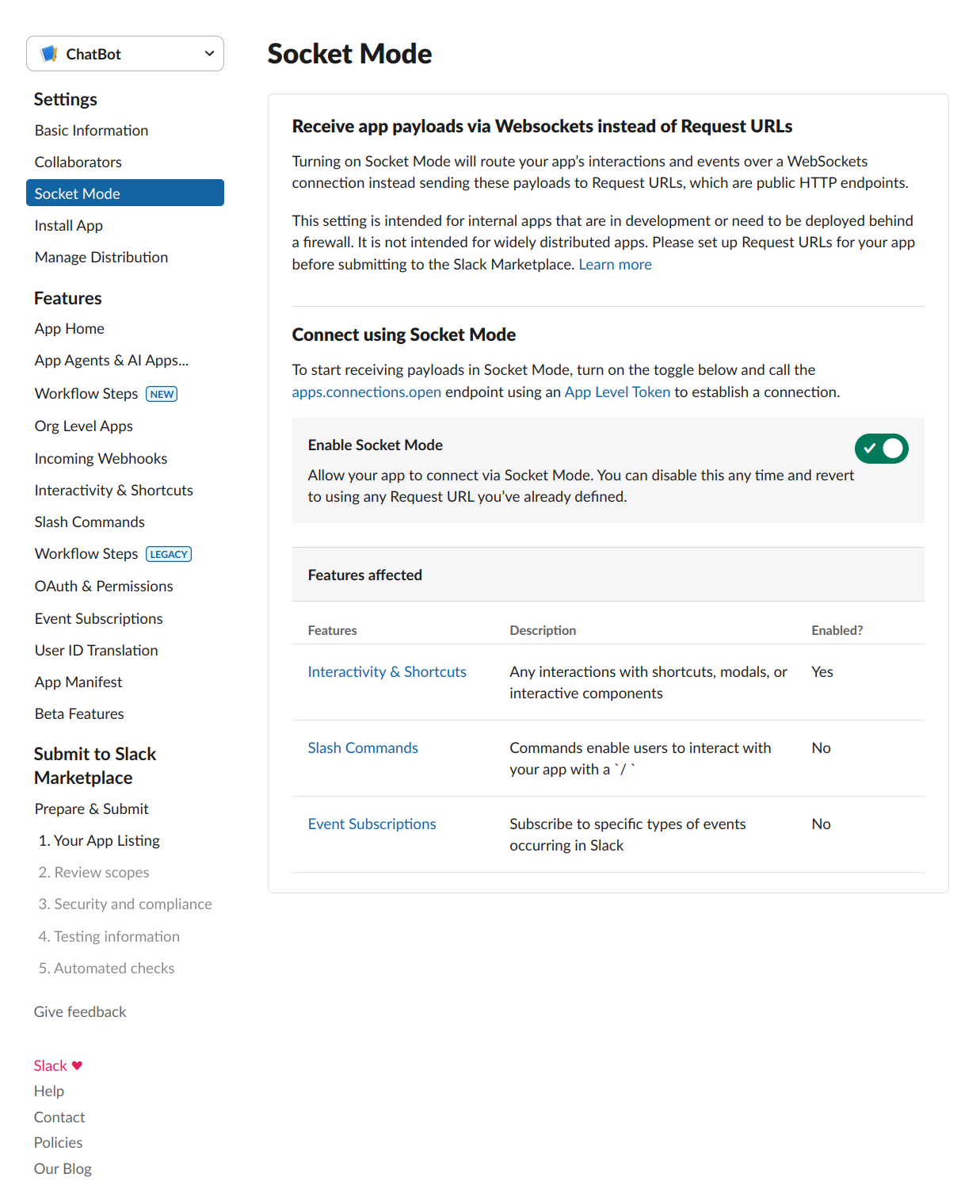
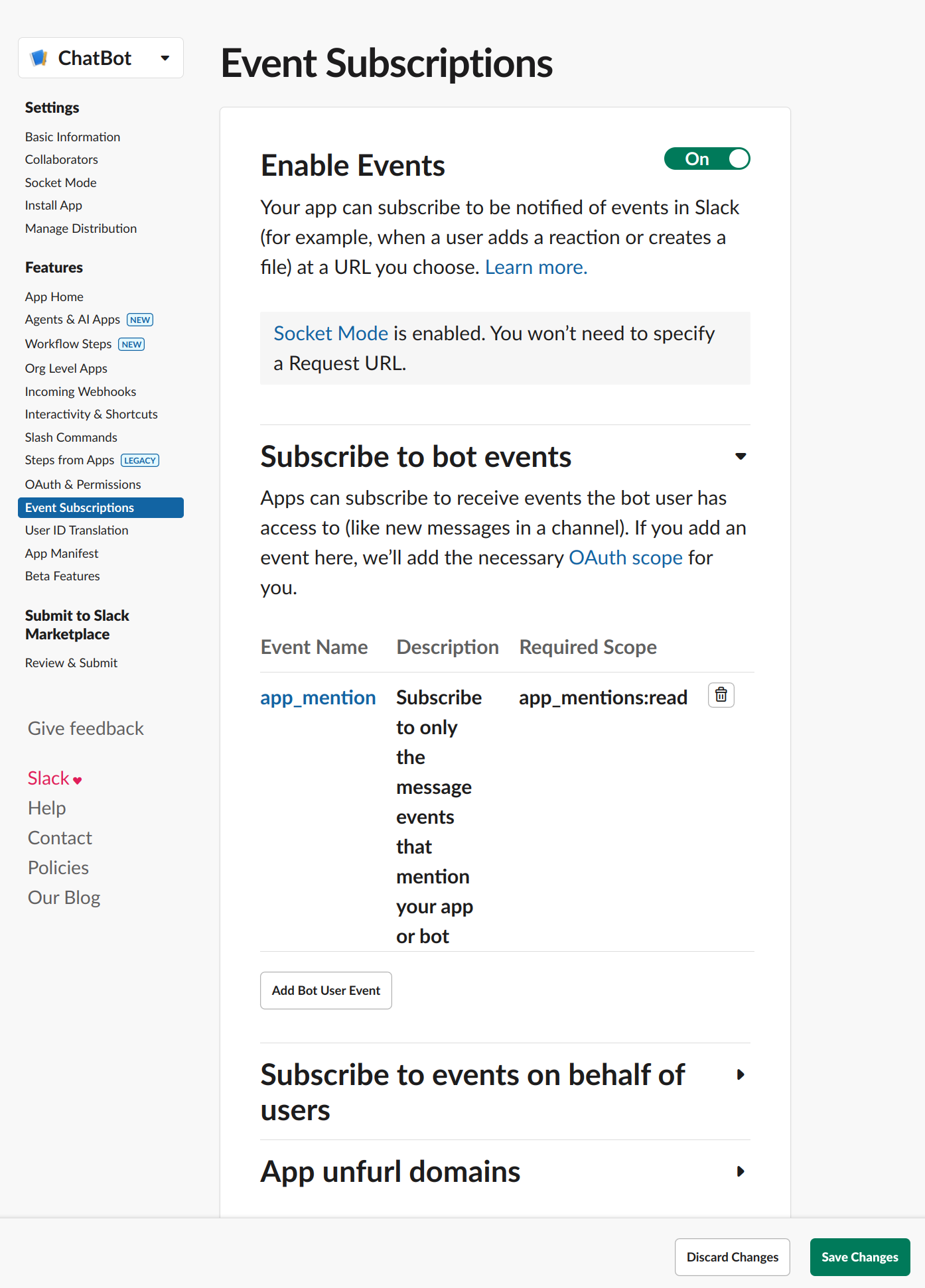
权限配置在Event Subscriptions和OAuth & Permissions中:
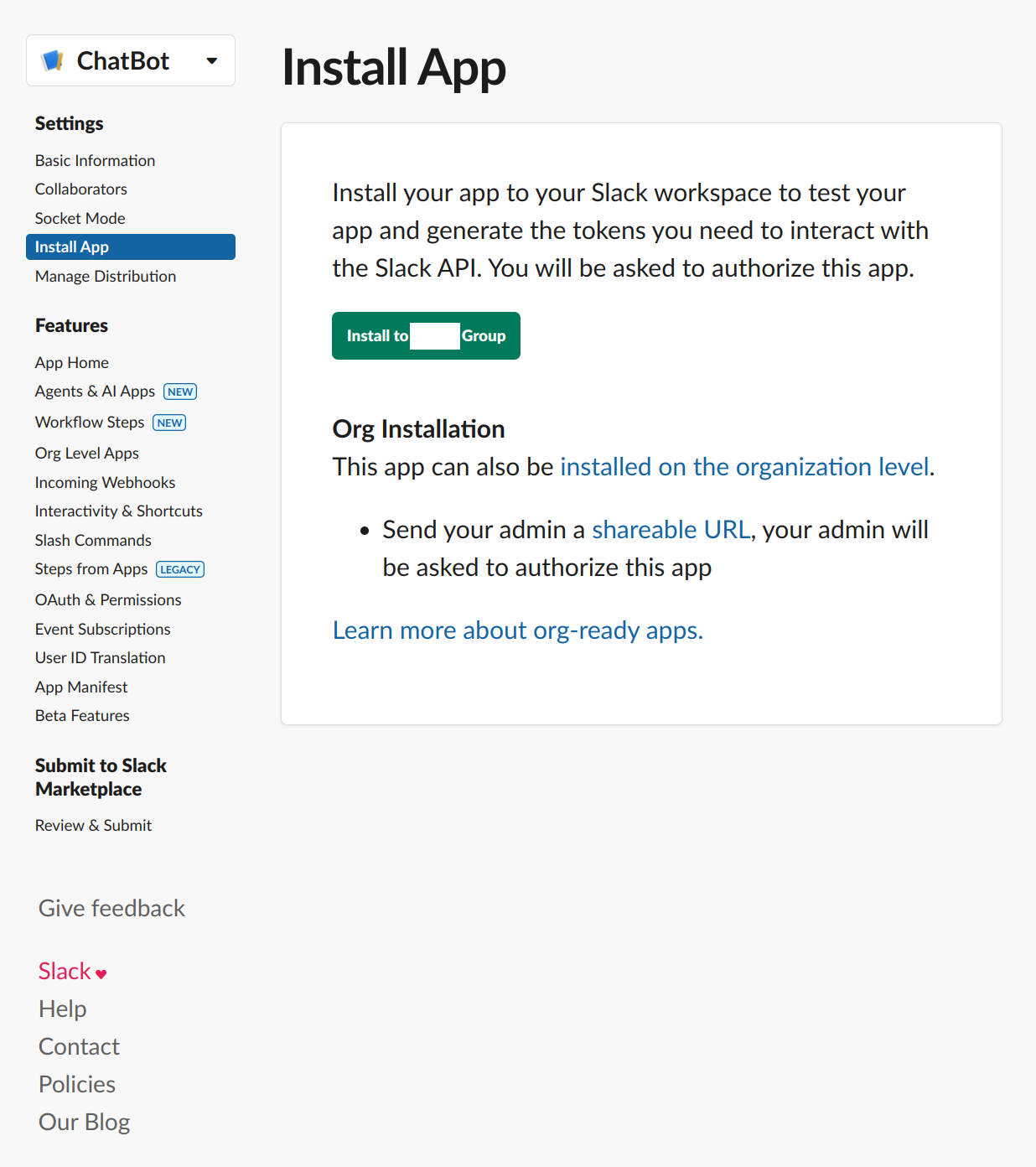
但是权限配置这一块需要后面单独开一个章节,请继续往下看。配置完成后,可以把应用安装到自己的工作区:
安装完成后,打开本地的Slack客户端,找到应用-添加应用,在列表中属于该工作区的应用会排在最前面,可以直接将其加入工作区:

这样以后就可以在应用列表看到自己定义的应用了。
关键信息
Slack应用创建之后,有几个关键的tokens信息(可以自己在Slack APP网页找到相关的字符串)需要保存到本地:
SLACK_BOT_TOKEN,是一串xoxb-开头的字符串,用QAuth&Permissions里面的Bot User OAuth Token;SLACK_APP_TOKEN,是一串xapp-开头的字符串,从Basic Information里面的APP Level Tokens里面找,注意权限配置;SLACK_SIGNING_SECRET,是一串普通的随机字符串,从Basic Information里面找。
关键配置
想要正常的使用SlackBot,有几个关键的权限配置,如果权限配置错误,会导致SlackBot无法正确的读取消息或者正确地对消息进行反应。
首先是APP Level Tokens的配置(参考这里的ChatBotApp里面的配置):
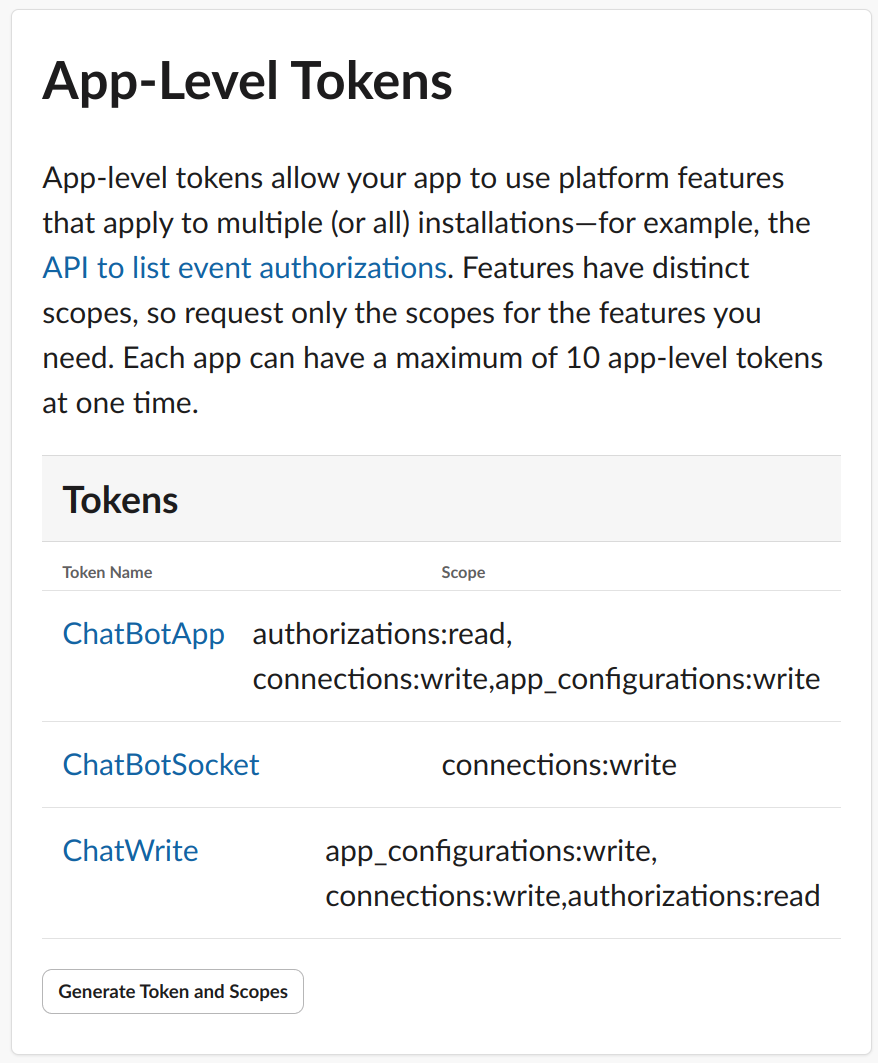
然后是Event Subscriptions中的配置信息:

最后是两个QAuth&Permissions的配置参数:
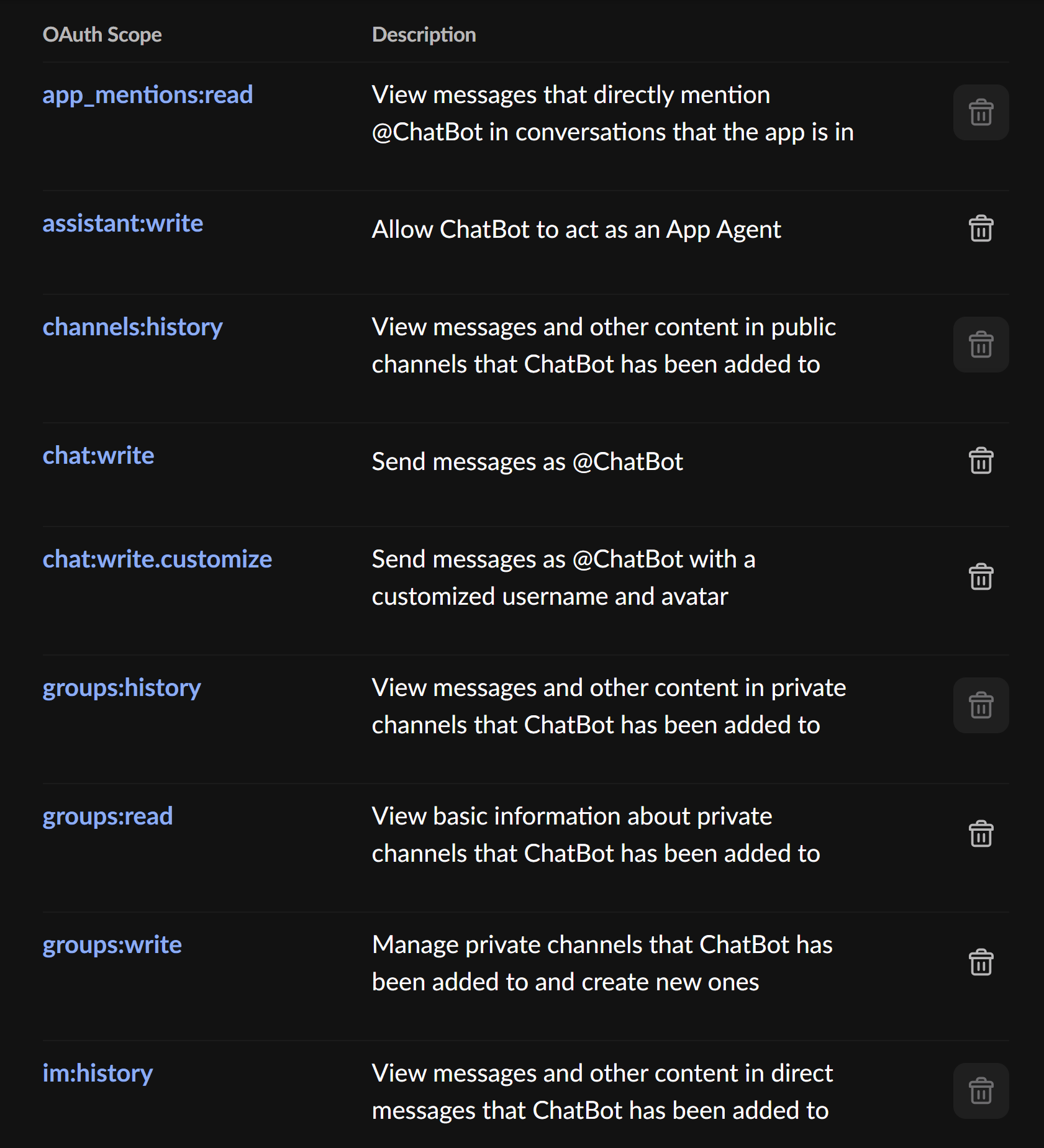
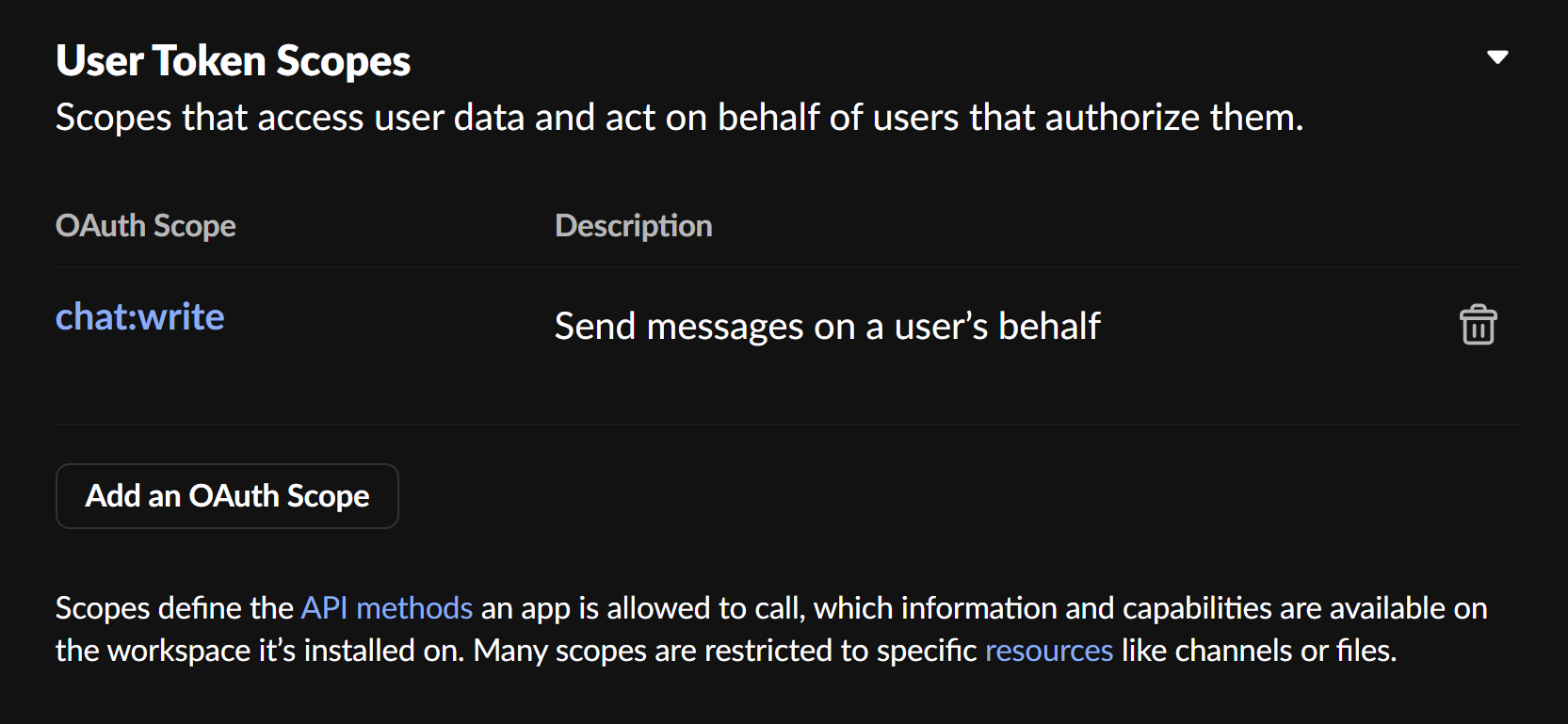
需要注意的是,这些都是个人配置信息,仅供参考。
slack_bolt环境配置
slack_bolt可以允许你从本地Python启动服务,调用SlackBot的API,监听Slack应用程序中的对话,并且可以按照不同的权限跟用户进行对话。可以使用pip安装slack_bolt:
bash
$ python3 -m pip install slack_bolt
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting slack_bolt
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/5d/2d/fb23c998c43ff8398d7fa1e58bb82e7e735fbdaa0bd4ddaac04b3865bd4c/slack_bolt-1.22.0-py2.py3-none-any.whl (229 kB)
Collecting slack_sdk<4,>=3.33.5 (from slack_bolt)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/25/2d/8724ef191cb64907de1e4e4436462955501e00f859a53d0aa794d0d060ff/slack_sdk-3.34.0-py2.py3-none-any.whl (292 kB)
Installing collected packages: slack_sdk, slack_bolt
Successfully installed slack_bolt-1.22.0 slack_sdk-3.34.0然后根据前面重要配置信息中提到的,配置Token:
bash
# export SLACK_BOT_TOKEN=xxx
# export SLACK_APP_TOKEN=xxx
# export SLACK_SIGNING_SECRET=xxx先测试一个简单的Python脚本:
python
import os
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
# Install the Slack app and get xoxb- token in advance
app = App(token=os.environ["SLACK_BOT_TOKEN"])
if __name__ == "__main__":
SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"]).start()运行效果:
bash
$ python3 slack_chatbot.py
⚡️ Bolt app is running!这就表示本地SlackBot安装成功了,当然,这个程序本身没有附带任何的功能。可以稍微升级一下SlackBot的测试功能:
python
import os
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
# Initializes your app with your bot token and socket mode handler
app = App(token=os.environ.get("SLACK_BOT_TOKEN"), signing_secret=os.environ.get("SLACK_SIGNING_SECRET"))
# Listens to incoming messages that contain "hello"
# To learn available listener arguments,
# visit https://tools.slack.dev/bolt-python/api-docs/slack_bolt/kwargs_injection/args.html
@app.message("hello")
def message_hello(message, say):
# say() sends a message to the channel where the event was triggered
say(f"Hey there <@{message['user']}>!")
@app.event("app_mention")
def handle_mentions(event, say):
say(text="Hello!", channel=event["channel"])
# Start your app
if __name__ == "__main__":
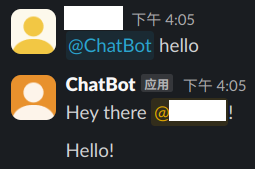
SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"]).start()在这个案例中,我们的程序会对一个事件和一个关键词起反应。例如我们只@slackbot的话,会返回一个hello:
如果@slackbot并且带上指定的字符串,那么就会做出相应的特别处理:
SlackBot对接Ollama模型
在上述章节中已经完成了本地通信的一些配置,接下来我们可以把SlackBot对接到Ollama模型中,原理也很简单:触发SlackBot之后,将消息作为token转发给Ollama的API,然后等待回复再回传给Slack聊天界面。这就是我做的一个简单的框架,接下来看看具体实施。
首先安装Ollama通信相关依赖:
bash
$ python3 -m pip install requests python-dotenv直接上D老师给的代码:
python
import os
import re
import requests
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 初始化 Slack 应用
app = App(
token=os.environ["SLACK_BOT_TOKEN"],
signing_secret=os.environ["SLACK_SIGNING_SECRET"]
)
# Ollama 配置(可通过环境变量覆盖)
OLLAMA_ENDPOINT = os.getenv("OLLAMA_ENDPOINT", "http://localhost:11434/api/generate")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "deepseek-r1:14b")
OLLAMA_PARAMS = {
"num_ctx": int(os.getenv("OLLAMA_NUM_CTX", 4096)),
"num_gpu": int(os.getenv("OLLAMA_NUM_GPU", 64)),
"keep_alive": os.getenv("OLLAMA_KEEP_ALIVE", "2h")
}
def query_ollama(prompt: str) -> str:
"""向 Ollama 发送请求并获取完整响应"""
payload = {
"model": OLLAMA_MODEL,
"prompt": f"请先输出思考过程(用THINKING:开头),再输出最终答案(用ANSWER:开头):\n\n{prompt}",
"stream": False,
# "options": OLLAMA_PARAMS
}
try:
response = requests.post(OLLAMA_ENDPOINT, json=payload, timeout=6000)
response.raise_for_status()
return response.json()["response"]
except Exception as e:
return f"Ollama 请求失败: {str(e)}"
def format_slack_response(raw_response: str) -> str:
"""将原始响应分割为思考过程和最终答案"""
thinking_match = re.search(r"THINKING:(.*?)(ANSWER:|\Z)", raw_response, re.DOTALL)
answer_match = re.search(r"ANSWER:(.*)", raw_response, re.DOTALL)
thinking = thinking_match.group(1).strip() if thinking_match else "未提供思考过程"
answer = answer_match.group(1).strip() if answer_match else raw_response
return (
f"*🤔 思考过程*:\n```{thinking}```\n\n"
f"*💡 最终回答*:\n```{answer}```"
)
@app.event("app_mention")
def handle_ollama_query(event, say):
"""处理 Slack 提及事件"""
# 移除机器人提及标记
query = event["text"].replace(f'<@{app.client.auth_test()["user_id"]}>', '').strip()
# 获取原始响应
raw_response = query_ollama(query)
# 格式化响应
slack_message = format_slack_response(raw_response)
# 发送到 Slack 频道
say(text=slack_message, channel=event["channel"])
if __name__ == "__main__":
SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"]).start()只要运行这个Python脚本,就可以通过SlackBot启动Ollama本地对话服务。可以查看会话过程中Ollama的模型被调用(本地部署了多个模型,不要在意ModelName的差异):
bash
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:32b-q40 13c7c287f615 21 GB 30%/70% CPU/GPU 4 minutes from now成果展示
通过上一个章节部署完成,启动会话服务之后,可以测试一下本地DeepSeek蒸馏模型的回答。
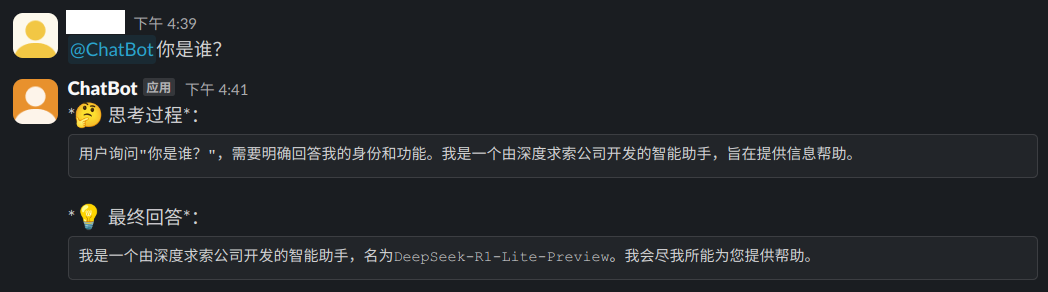
简单提问:
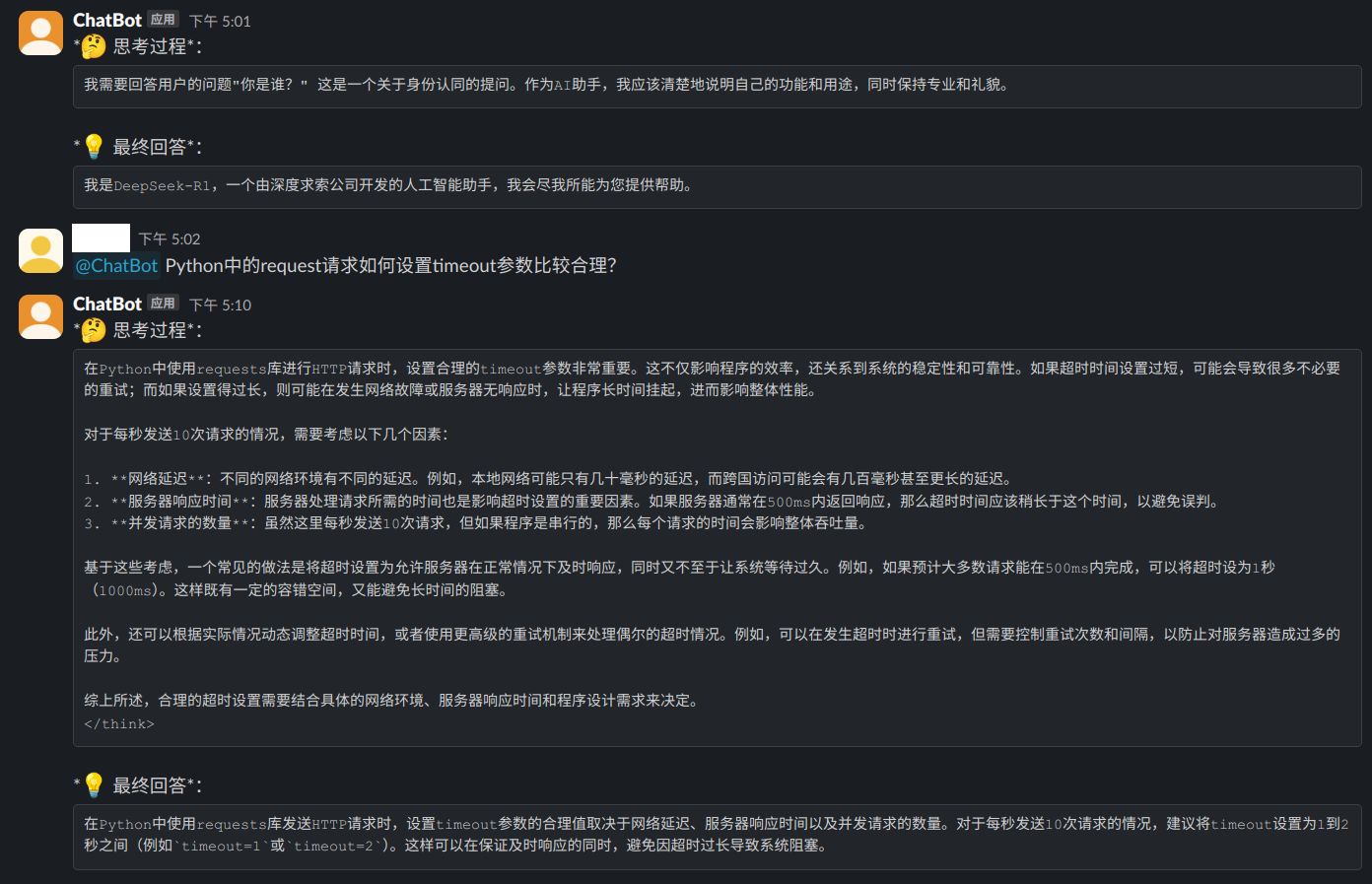
进一步提问:
因为每一次回复需要时间,不是流式的响应,因此我自己加了一个响应回复:
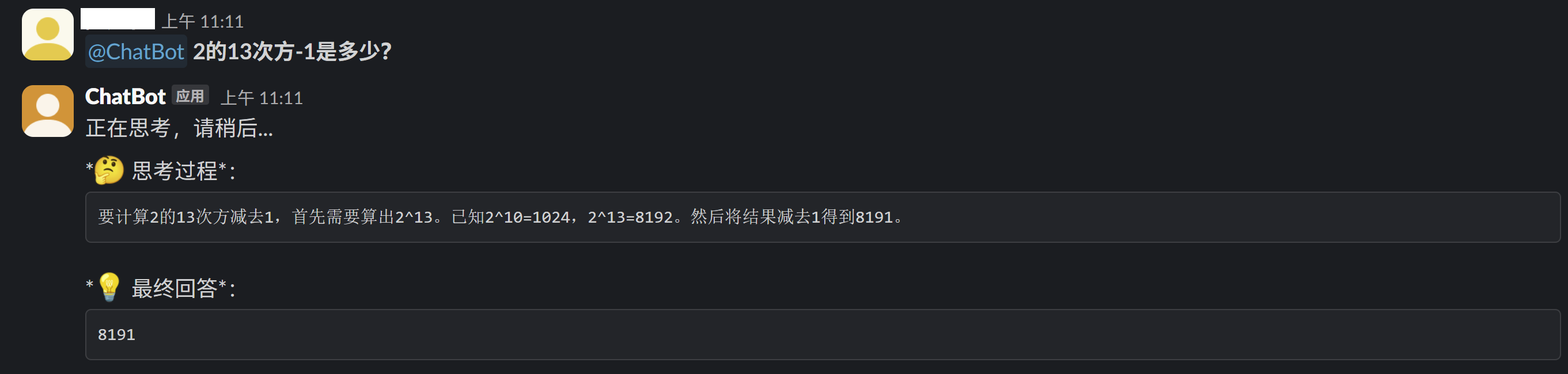
这样就会告知用户,你的提问已经被接收到了,服务正在正常运行,模型正在推理。
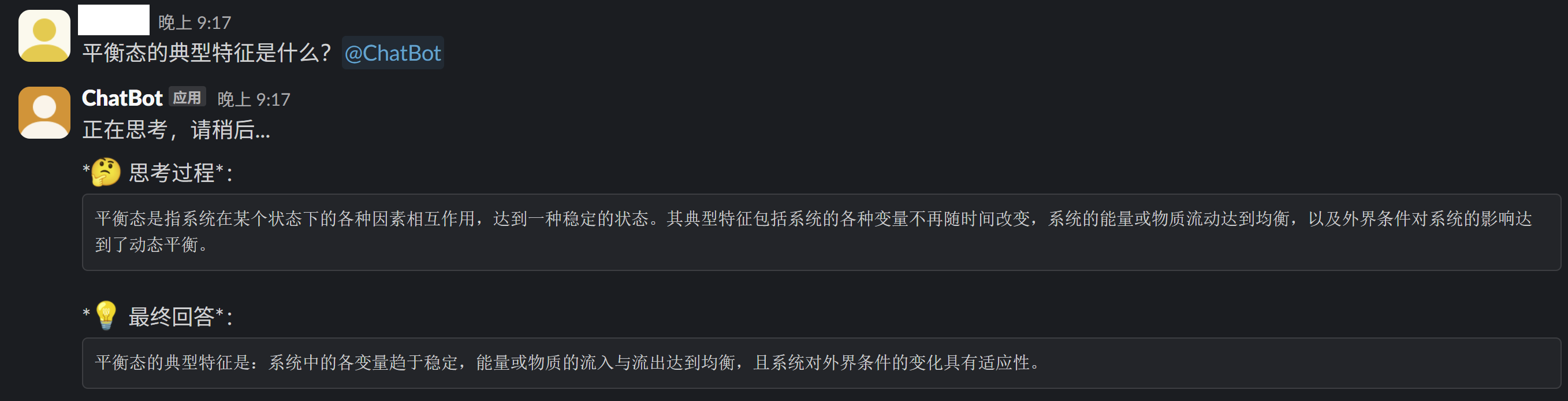
更多的示例就不一一展示了,跟之前介绍过的AnythingLLM和ChatBox、PageAssit等相比功能还是非常欠缺的,有兴趣的朋友可以考虑进一步去拓展。
方案选择
前一段时间有很多新闻在报道Ollama的安全漏洞,在公网上有众多开放Ollama端口的服务器可以被有心之人利用。这件事也引起了很多大模型本地用户的警觉,D老师对比了几种可能用到的方案并给出了建议:

D老师认为,使用自建的加密聊天工具+Ollama的安全加固,会是一个比较好用的方案。既可以满足用户的数据隐私需求,又可以很大程度上提高本地大模型使用的灵活度。而这篇文章中我们所使用到的是公共聊天工具+Ollama的方案,相比于使用公网API,数据隐私会稍好一些。但是这里面的数据隐私也很大程度上依赖于聊天工具对于用户隐私数据的保护程度,用户需要自己进行鉴别。
总结概要
本文介绍了一种使用Slack聊天工具中的机器人SlackBot的API接口,实现本地化部署Ollama的DeepSeek大模型的远程通讯方案。相比于调用公网的API接口,数据隐私稍微好一点点。最终的方案应该是自建加密聊天工具+Ollama本地化部署,但是这个时间成本有点高,用户可以自行尝试。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/slackbot.html
作者ID:DechinPhy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html