PanWeiDB2.0异构数据库访问测试
异构数据库访问兼容性测试一览表
| No | 访问路径 | 多维度结果 | 备注 |
|---|---|---|---|
| 1 | PanWeiDB(集中式)---访问---PanWeiDB(集中式) | √ | 支持复杂SQL |
| 2 | PanWeiDB(集中式)---访问---Oracle | √ | 支持 |
| 3 | Oracle---访问---PanWeiDB(集中式) | √ | 受Oracle默认大写影响,dblink涉及磐维的对象及字段,需要用双引号""括起来。不支持求平均值,偶发性出现链接错误,重新登录正常 |
| 4 | PanWeiDB(集中式)---访问---PanWeiDB(分布式) | × | 基础select不支持,缺少get_typmod_with_unit系统基础函数 |
| 5 | PanWeiDB(分布式)---访问---PanWeiDB(集中式) | × | 不支持database link语法,厂商反馈:不支持database link访问磐维集中式 |
| 6 | PanWeiDB(集中式)---访问---GoldenDB(分布式) | √ | 支持简单SQL,需注意与GoldenDB数据交互或者修改时,外部表定义的数据类型可能会出现转换异常的情况 |
| 7 | PanWeiDB(集中式)---访问---AntDB(集中式) | × | 认证交互错误:DETAIL: expected authentication request from server, but received v |
| 8 | AntDB(集中式)---访问---PanWeiDB(集中式) | × | 外部表映射错误,ERROR: user mapping not found for "antdb" |
测试过程
1、PanWeiDB访问PanWeiDB
测试结果
| 序号 | 复杂度 | 具体操作 | 结果 |
|---|---|---|---|
| 1 | 基本SQL操作 | 查询远程数据(SELECT) | 验证通过 |
| 2 | 插入数据到本地表(INSERT) | 验证通过 | |
| 3 | 更新本地表数据(UPDATE) | 验证通过 | |
| 4 | 删除数据(DELETE) | 验证通过 | |
| 5 | 复杂SQL操作 | 多表关联(4表JOIN) | 验证通过 |
| 6 | 笛卡尔积与过滤条件 | 验证通过 | |
| 7 | 嵌套循环(NESTED LOOP) | 验证通过 | |
| 8 | 哈希连接(HASH JOIN) | 验证通过 | |
| 9 | 聚合函数与GROUP BY | 验证通过 | |
| 10 | 子查询与EXISTS | 验证通过 | |
| 11 | 窗口函数与RANK | 验证通过 | |
| 12 | 复杂条件与函数 | 验证通过 |
2、PanWeiDB访问Oracle
3、Oracle访问PanWeiDB
3.1 多表关联(4表JOIN)
-- 左连接 + 右连接 + 窗口函数
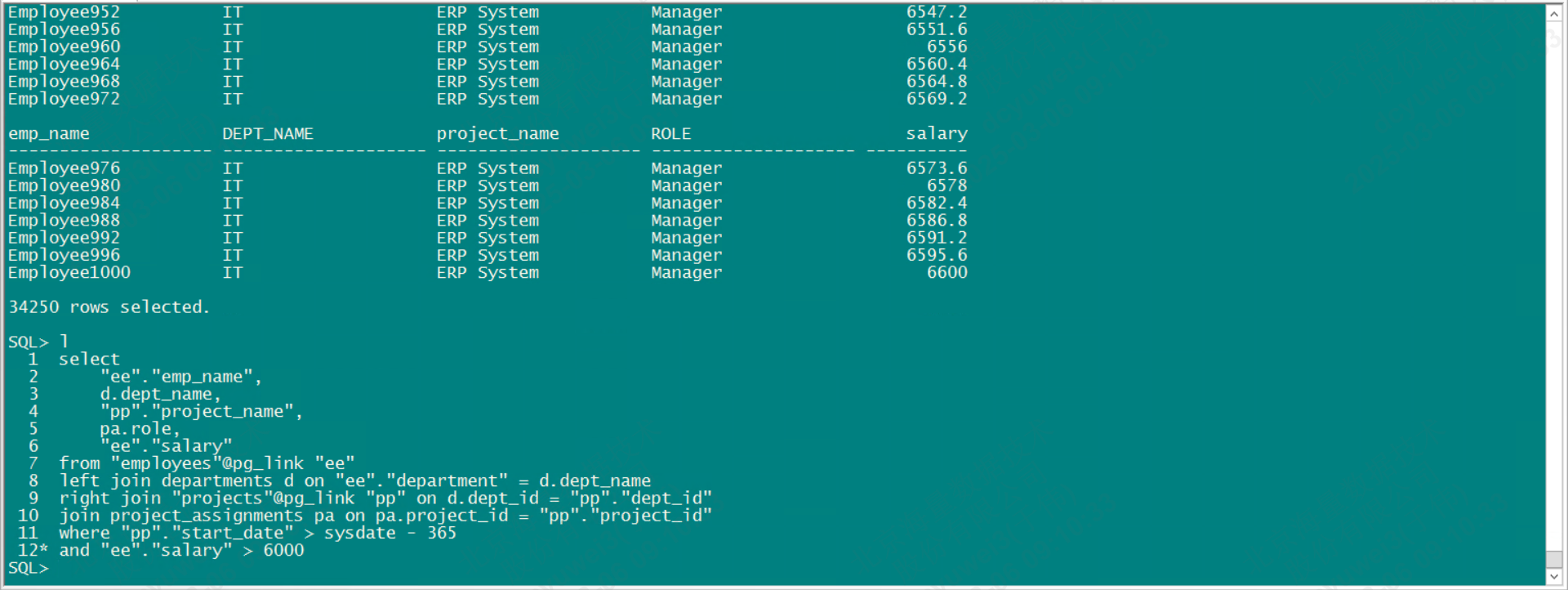
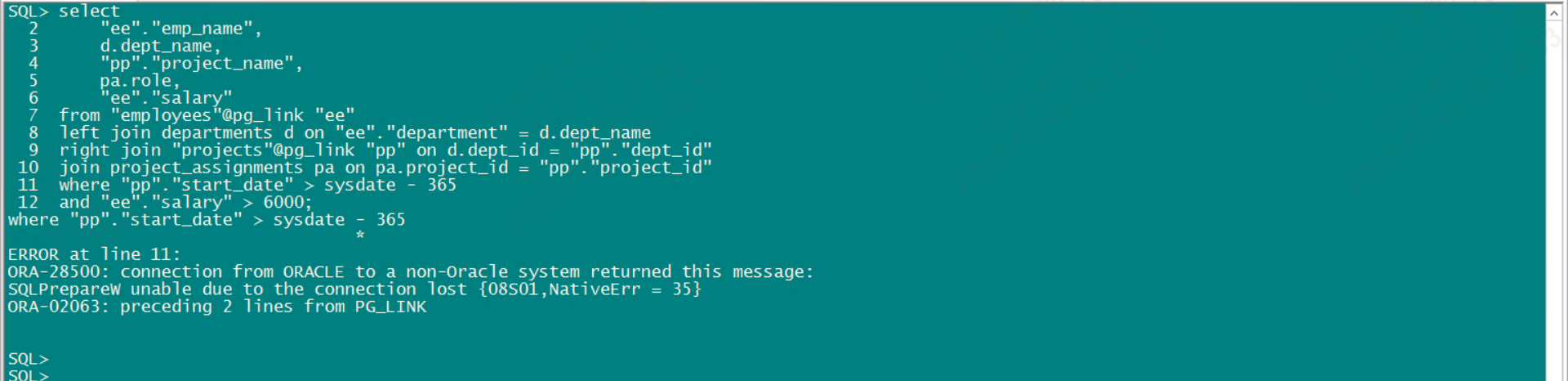
select
"ee"."emp_name",
d.dept_name,
"pp"."project_name",
pa.role,
"ee"."salary"
from "employees"@pg_link "ee"
left join departments d on "ee"."department" = d.dept_name
right join "projects"@pg_link "pp" on d.dept_id = "pp"."dept_id"
join project_assignments pa on pa.project_id = "pp"."project_id"
where "pp"."start_date" > sysdate - 365
and "ee"."salary" > 6000;database link涉及磐维对象及字段,需要用双引号""括起来,这受Oracle默认大写影响
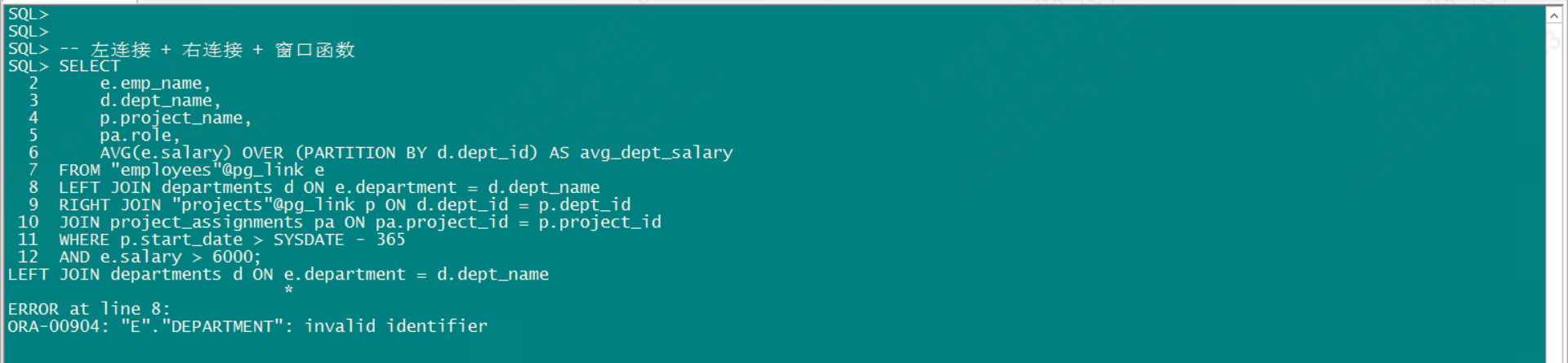
不支持求平均值
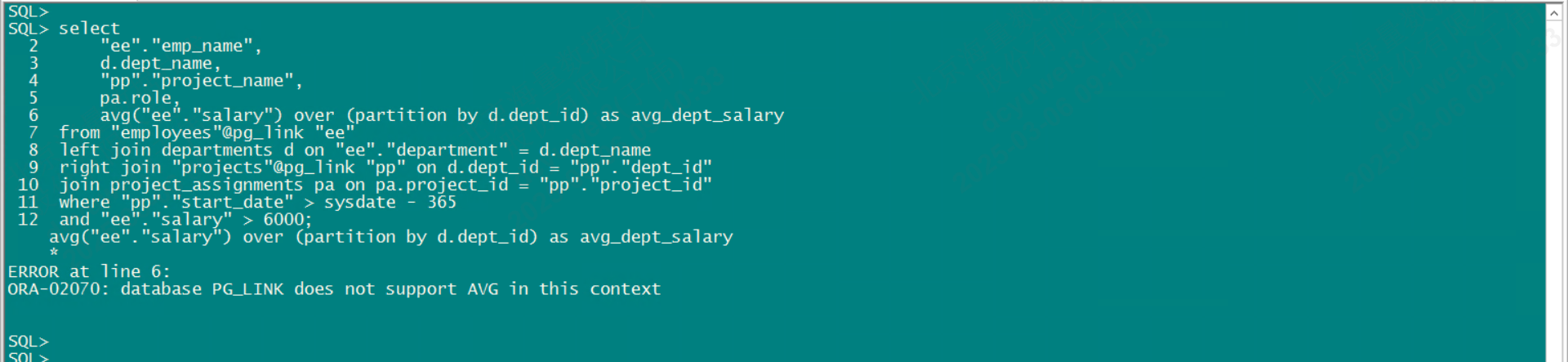
可以查询

偶发性出现链接错误
3.2 笛卡尔积与过滤条件
-- 笛卡尔积 + CASE判断
SELECT
"ee"."emp_name",
p.project_name,
CASE
WHEN "ee"."salary" > 10000 THEN 'High'
WHEN "ee"."salary" BETWEEN 5000 AND 10000 THEN 'Medium'
ELSE 'Low'
END AS salary_level
FROM "employees"@pg_link "ee", projects p
WHERE p.dept_id = 1
AND "ee"."department" = 'IT';执行计划
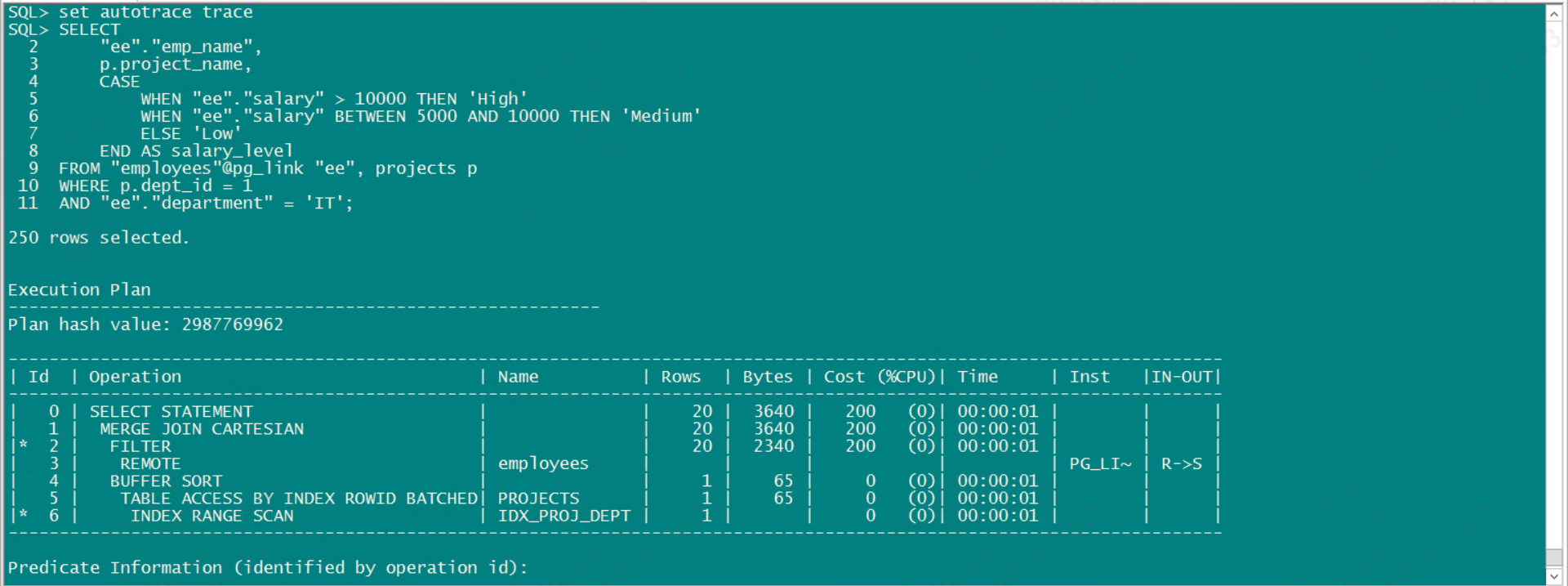
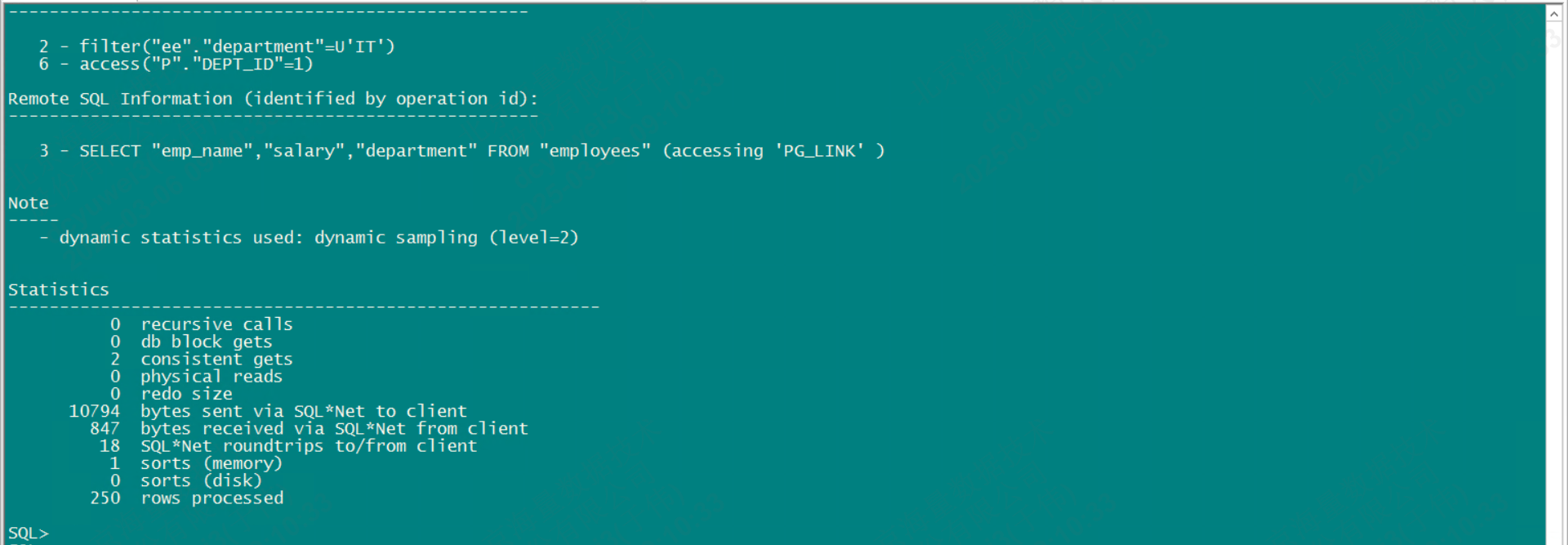
3.3 嵌套循环(NESTED LOOP)
-- 强制使用NESTED LOOP(提示方式)
SELECT /*+ USE_NL(e "dd") */
e.emp_id,
"dd"."dept_name"
FROM employees e
JOIN "departments"@pg_link "dd" ON e.department = "dd"."dept_name"
WHERE "dd"."budget" > 500000;3.4 哈希连接(HASH JOIN)
-- 强制使用HASH JOIN
SELECT /*+ USE_HASH(pa "pp") */
pa.assignment_id,
"pp"."project_name"
FROM project_assignments pa
JOIN "projects"@pg_link "pp" ON pa.project_id = "pp"."project_id" WHERE "pp"."end_date" > SYSDATE; 3.5 聚合函数与GROUP BY
-- 聚合函数 + HAVING
SELECT
"dd"."dept_name",
COUNT(e.emp_id) AS total_employees,
SUM(e.salary) AS total_salary FROM "departments"@pg_link "dd" LEFT JOIN employees e ON "dd"."dept_name" = e.department GROUP BY "dd"."dept_name" HAVING SUM(e.salary) > 100000; 3.6 子查询与EXISTS
-- EXISTS子查询
SELECT
e.emp_name
FROM employees e
WHERE EXISTS ( SELECT 1 FROM "project_assignments"@pg_link "pa" WHERE "pa"."emp_id" = e.emp_id AND "pa"."role" = 'Manager' ); 3.7 窗口函数与RANK
-- RANK()窗口函数
SELECT
"emp_name",
"salary",
RANK() OVER (ORDER BY "salary" DESC) AS salary_rank FROM "employees"@pg_link WHERE "department" = 'IT'; 3.8 复杂条件与函数
-- 字符串函数 + 日期计算
SELECT
"ee"."emp_name",
UPPER(d.dept_name) AS dept_upper,
ADD_MONTHS("ee"."hire_date", 12) AS hire_anniversary FROM "employees"@pg_link "ee" JOIN departments d ON "ee"."department" = d.dept_name WHERE TO_CHAR("ee"."hire_date", 'YYYY') = '2023' AND LENGTH("ee"."emp_name") > 5; 4、集中式PanWeiDB访问分布式PanWeiDB
PanWeiDB(PanWeiDB版本升级测试库),访问,PanWeiDB分布式(计费系统)
测试结果
| 序号 | 复杂度 | 具体操作 | 结果 |
|---|---|---|---|
| 1 | 基本SQL操作 | 查询远程数据(SELECT) | 测试未通过 |
测试账户
create user testuser2 with sysadmin password '3GahEH271';
create database testdb1 owner testuser2;
\q
gsql -r -p 17700 -d testdb1 -U testuser2 -W 3GahEH2711.1 创建dblink
create database link dblink_jfjsxt19098 connect to testuser2 identified by '3GahEH271' using postgres_fdw(host '10.183.190.98',port '17700',dbname 'testdb1');2.1 基本SQL操作
testdb1=> SELECT * FROM employees@dblink_jfjsxt19098 WHERE department = 'IT';
ERROR: function get_typmod_with_unit(integer, text[]) does not exist
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
CONTEXT: Remote SQL command: SELECT a.attname,
(case pg_catalog.format_type(a.atttypid, get_typmod_with_unit(a.atttypmod, a.attoptions)) when 'oradate' then 'date' else pg_catalog.format_type(a.atttypid, get_typmod_with_unit(a.atttypmod, a.attoptions)) end)
FROM pg_catalog.pg_attribute a
WHERE a.attrelid = (select oid from pg_class where relname='employees' and relnamespace=(select oid from pg_namespace where nspname='testuser2'))
AND a.attnum > 0 AND NOT a.attisdropped AND a.attkvtype != 4 AND a.attname <> 'tableoid' AND a.attname <> 'tablebucketid'
ORDER BY a.attnum;
referenced column: format_type
testdb1=> 磐维集中式数据库-SQL执行正常
磐维分布式数据库-SQL无法执行
磐维分布式数据库缺少函数"get_typmod_with_unit",导致集中式数据库访问分布式数据库时,无法执行查询:
查询 pg_attribute 系统表,检索有关表 employees 的列信息,以获取列名和数据类型信息,
get_typmod_with_unit 是一个系统函数,用于从类型修饰符中提取单位信息。
它的作用是将类型修饰符转换为更易读的格式
手动创建函数get_typmod_with_unit
CREATE OR REPLACE FUNCTION get_typmod_with_unit(typmod integer, options text[])
RETURNS integer
AS $$
DECLARE
unit integer;
BEGIN
-- 从类型修饰符中提取单位信息
-- 这里是一个示例逻辑,实际逻辑可能需要根据你的数据库系统进行调整
unit := typmod % 1000; -- 假设单位信息存储在 typmod 的低三位
-- 返回提取的单位信息
RETURN unit;
END;
$$ LANGUAGE plpgsql;磐维集中式dblink访问
查询报错,依然缺少函数"get_typmod_with_unit"函数,暂无方案解决(20250305)。
5、分布式PanWeiDB访问集中式PanWeiDB
PanWeiDB分布式(结算系统(计费系统-计费云详单)),访问,PanWeiDB(PanWeiDB版本升级测试库)
分布式磐维数据库,暂不支持dblink
6、PanWeiDB访问GoldenDB
PanWeiDB(PanWeiDB版本升级测试库),访问,GoldenDB分布式(中台中心)
数据类型略微调整
create extension mysql_fdw;
grant usage on foreign data wrapper mysql_fdw to testuser1;
create server goldendb_fdw_server foreign data wrapper mysql_fdw options(HOST '10.183.200.193',PORT '8880');
create user mapping for testuser1 server goldendb_fdw_server options(username 'testuser1',password '3GahEH271!');
create foreign table employees_fdw_goldendb (
emp_id NUMBER(10) ,
emp_name VARCHAR2(50) NOT NULL,
hire_date DATE,
salary NUMBER(10, 2),
department VARCHAR2(50),
resume CLOB,
photo BLOB
) server goldendb_fdw_server options(DBNAME 'testdb1',table_name 'employees');
create foreign table departments_fdw_goldendb (
dept_id NUMBER(10),
dept_name VARCHAR2(50) ,
manager_id NUMBER(10),
budget NUMBER(15, 2)
) server goldendb_fdw_server options(DBNAME 'testdb1',table_name 'departments');
create foreign table projects_fdw_goldendb (
project_id NUMBER(10),
project_name VARCHAR2(100),
start_date DATE,
end_date DATE,
dept_id NUMBER(10)
) server goldendb_fdw_server options(DBNAME 'testdb1',table_name 'projects');
create foreign table project_assignments_fdw_goldendb (
assignment_id NUMBER(10) ,
emp_id NUMBER(10),
project_id NUMBER(10),
role VARCHAR2(50)
) server goldendb_fdw_server options(DBNAME 'testdb1',table_name 'project_assignments');基本SQL操作
根据错误信息,问题出在数据类型转换上。具体来说,磐维无法将常量值的数据类型(1399)转换为GoldenDB 的数据类型。这通常发生在使用外部表(FDW,Foreign Data Wrapper)时,数据类型不匹配。
错误分析
-
数据类型不匹配
- 错误信息
cannot convert constant value to MySQL value表明,磐维 无法将某个常量值转换为 GoldenDB 的数据类型。 Constant value data type: 1399表示常量值的数据类型是 1399,这可能是 GoldenDB 中的DECIMAL类型。
- 错误信息
-
外部表定义问题
- 外部表
employees_fdw_goldendb的定义可能与GoldenDB 表的结构不完全匹配。
- 外部表
解决方案
-
检查外部表定义
- 确保外部表
employees_fdw_goldendb的定义与GoldenDB 表的结构完全匹配。 - 使用
SHOW CREATE TABLE或DESCRIBE命令检查 GoldenDB 表的结构。
- 确保外部表
-
修改外部表定义
- 如果数据类型不匹配,修改外部表的定义,使其与 GoldenDB 表的结构一致。
- 例如,如果 GoldenDB 表中的
emp_id是INT类型,确保外部表中的emp_id也是INT类型。
-
检查常量值的数据类型
- 确保插入或查询时使用的常量值的数据类型与外部表的定义匹配。
- 如果需要,使用显式类型转换。
MySQL_FDW功能描述
外部表,支持select查询、dml操作。
支持创建外部数据封装器mysql_fdw,连接MariaDB或MySQL或者GoldenDB数据库,并能在外部表上进行查询、插入、更新和删除操作。
mysql_fdw插件默认参与编译,用户可直接使用mysql_fdw,无须其他操作。
7、GoldenDB访问PanWeiDB
GoldenDB分布式(中台中心),访问,PanWeiDB(PanWeiDB版本升级测试库)
8、PanWeiDB访问AntDB
PanWeiDB(PanWeiDB版本升级测试库),访问,AntDB(财务系统)
创建扩展
-- 本地数据库创建表
-- 表1: employees (员工表)
CREATE TABLE employees (
emp_id int PRIMARY KEY,
emp_name VARCHAR(50) NOT NULL,
hire_date DATE,
salary int,
department VARCHAR(50),
resume text,
photo text
);
-- 表2: departments (部门表)
CREATE TABLE departments (
dept_id int PRIMARY KEY,
dept_name VARCHAR(50) UNIQUE,
manager_id int,
budget int,
CONSTRAINT fk_manager FOREIGN KEY (manager_id) REFERENCES employees(emp_id)
);
-- 表3: projects (项目表)
CREATE TABLE projects (
project_id int PRIMARY KEY,
project_name VARCHAR(100),
start_date DATE,
end_date DATE,
dept_id int,
CONSTRAINT fk_dept FOREIGN KEY (dept_id) REFERENCES departments(dept_id)
);
-- 表4: project_assignments (项目分配表)
CREATE TABLE project_assignments (
assignment_id int PRIMARY KEY,
emp_id int,
project_id int,
role VARCHAR(50),
CONSTRAINT fk_emp FOREIGN KEY (emp_id) REFERENCES employees(emp_id),
CONSTRAINT fk_project FOREIGN KEY (project_id) REFERENCES projects(project_id)
);
-- 创建索引
CREATE INDEX idx_emp_dept ON employees(department);
CREATE INDEX idx_proj_dept ON projects(dept_id);
CREATE INDEX idx_assign_role ON project_assignments(role);插入数据
-- 插入员工数据
DO $$
BEGIN
FOR i IN 1..1000 LOOP
INSERT INTO employees VALUES (
i,
'Employee' || i,
CURRENT_DATE - MOD(i, 365),
5000 + MOD(i, 10000),
CASE MOD(i, 4)
WHEN 0 THEN 'IT'
WHEN 1 THEN 'HR'
WHEN 2 THEN 'Finance'
ELSE 'Sales'
END,
'aaaaaaaaaa',
'bbbbbbbbbb'
);
END LOOP;
END;
$$;
-- 插入部门数据
INSERT INTO departments VALUES (1, 'IT', 100, 1000000);
INSERT INTO departments VALUES (2, 'HR', 200, 500000);
-- 插入项目数据
INSERT INTO projects VALUES (101, 'ERP System', CURRENT_DATE-100, CURRENT_DATE+200, 1);
INSERT INTO projects VALUES (102, 'HR Portal', CURRENT_DATE-50, CURRENT_DATE+100, 2);
-- 插入项目分配数据
DO $$
BEGIN
FOR i IN 1..500 LOOP
INSERT INTO project_assignments VALUES (
i,
MOD(i, 1000) + 1,
CASE MOD(i, 2) WHEN 0 THEN 101 ELSE 102 END,
CASE MOD(i, 3) WHEN 0 THEN 'Developer' WHEN 1 THEN 'Tester' ELSE 'Manager' END
);
END LOOP;
END;
$$;不支持使用dblink直接访问
testdb1=> SELECT * FROM employees@dblink_antdb WHERE department = 'IT';
ERROR: could not connect to server "dblink_antdb"
DETAIL: expected authentication request from server, but received v
testdb1=>认证错误
使用外部表的方式访问
create extension postgres_fdw;
grant usage on foreign data wrapper postgres_fdw to testuser1;
create server antdb_fdw_server foreign data wrapper postgres_fdw options(HOST '10.183.103.130',PORT '5432');
create user mapping for testuser1 server antdb_fdw_server options(user 'testuser1',password '3GahEH271!');
create foreign table employees_fdw_antdb (
emp_id NUMBER(10) ,
emp_name VARCHAR2(50) NOT NULL,
hire_date DATE,
salary NUMBER(10, 2),
department VARCHAR2(50),
resume CLOB,
photo BLOB
) server antdb_fdw_server options(schema_name 'public',table_name 'employees');
create foreign table departments_fdw_antdb (
dept_id NUMBER(10),
dept_name VARCHAR2(50) ,
manager_id NUMBER(10),
budget NUMBER(15, 2)
) server antdb_fdw_server options(schema_name 'public',table_name 'departments');
create foreign table projects_fdw_antdb (
project_id NUMBER(10),
project_name VARCHAR2(100),
start_date DATE,
end_date DATE,
dept_id NUMBER(10)
) server antdb_fdw_server options(schema_name 'public',table_name 'projects');
create foreign table project_assignments_fdw_antdb (
assignment_id NUMBER(10) ,
emp_id NUMBER(10),
project_id NUMBER(10),
role VARCHAR2(50)
) server antdb_fdw_server options(schema_name 'public',table_name 'project_assignments');依然无法访问。
9、AntDB访问PanWeiDB
AntDB(财务系统、全面预算系统),访问,PanWeiDB(PanWeiDB版本升级测试库)
create extension postgres_fdw;
grant usage on foreign data wrapper postgres_fdw to testuser1;
create server panweidb_fdw_server foreign data wrapper postgres_fdw options(HOST '10.183.162.150',PORT '17700',dbname 'testdb1');
create user mapping for testuser1 server panweidb_fdw_server options(user 'testuser1',password '3GahEH271');
create foreign table employees_fdw_panweidb (
emp_id int ,
emp_name VARCHAR(50) NOT NULL,
hire_date DATE,
salary int,
department VARCHAR(50),
resume text,
photo text
) server panweidb_fdw_server options(schema_name 'public',table_name 'employees');不支持number、varchar2、clob、blob
无法访问外部表
测试用例
以下是一个基于Oracle数据库使用DBLink的详细案例,包含测试用例、完整SQL语句及复杂查询示例:
1. 测试用例设计
1.1 创建测试表及约束
-- 本地数据库创建表
-- 表1: employees (员工表)
CREATE TABLE employees (
emp_id NUMBER(10) PRIMARY KEY, emp_name VARCHAR2(50) NOT NULL, hire_date DATE, salary NUMBER(10, 2), department VARCHAR2(50), resume CLOB, photo BLOB ); -- 表2: departments (部门表) CREATE TABLE departments ( dept_id NUMBER(10) PRIMARY KEY, dept_name VARCHAR2(50) UNIQUE, manager_id NUMBER(10), budget NUMBER(15, 2), CONSTRAINT fk_manager FOREIGN KEY (manager_id) REFERENCES employees(emp_id) ); -- 表3: projects (项目表) CREATE TABLE projects ( project_id NUMBER(10) PRIMARY KEY, project_name VARCHAR2(100), start_date DATE, end_date DATE, dept_id NUMBER(10), CONSTRAINT fk_dept FOREIGN KEY (dept_id) REFERENCES departments(dept_id) ); -- 表4: project_assignments (项目分配表) CREATE TABLE project_assignments ( assignment_id NUMBER(10) PRIMARY KEY, emp_id NUMBER(10), project_id NUMBER(10), role VARCHAR2(50), CONSTRAINT fk_emp FOREIGN KEY (emp_id) REFERENCES employees(emp_id), CONSTRAINT fk_project FOREIGN KEY (project_id) REFERENCES projects(project_id) ); -- 创建索引 CREATE INDEX idx_emp_dept ON employees(department); CREATE INDEX idx_proj_dept ON projects(dept_id); CREATE INDEX idx_assign_role ON project_assignments(role); 1.2 插入测试数据(通过PL/SQL循环)
-- 插入员工数据
BEGIN
FOR i IN 1..1000 LOOP INSERT INTO employees VALUES ( i, 'Employee' || i, SYSDATE - MOD(i, 365), 5000 + MOD(i, 10000), CASE MOD(i, 4) WHEN 0 THEN 'IT' WHEN 1 THEN 'HR' WHEN 2 THEN 'Finance' ELSE 'Sales' END, EMPTY_CLOB(), EMPTY_BLOB() ); END LOOP; END; / -- 插入部门数据 INSERT INTO departments VALUES (1, 'IT', 100, 1000000); INSERT INTO departments VALUES (2, 'HR', 200, 500000); -- 插入项目数据 INSERT INTO projects VALUES (101, 'ERP System', SYSDATE-100, SYSDATE+200, 1); INSERT INTO projects VALUES (102, 'HR Portal', SYSDATE-50, SYSDATE+100, 2); -- 插入项目分配数据 BEGIN FOR i IN 1..500 LOOP INSERT INTO project_assignments VALUES ( i, MOD(i, 1000) + 1, CASE MOD(i, 2) WHEN 0 THEN 101 ELSE 102 END, CASE MOD(i, 3) WHEN 0 THEN 'Developer' WHEN 1 THEN 'Tester' ELSE 'Manager' END ); END LOOP; END; / 2. DBLink配置与基本SQL
2.1 创建DBLink
-- 创建到远程数据库的DBLink(假设远程数据库名为remote_db)
-- CREATE DATABASE LINK remote_db_link
-- CONNECT TO remote_user IDENTIFIED BY remote_password
-- USING 'remote_db';
grant all on database testdb1 to testuser1; create extension postgres_fdw; grant usage on foreign data wrapper postgres_fdw to testuser1; # 创建到oracle的映射,执行此语句需预先使用 gs_guc generate 命令生成 datasource 文件,此处以如下命令为例: gs_guc generate -S 'Gs@123456' -D $GAUSSHOME/bin -o usermapping create database link dblink_pwcrm149 connect to testuser1 identified by '3GahEH271' using postgres_fdw(host '10.183.162.149',port '17700',dbname 'testdb1'); 2.2 基本SQL操作
3. 复杂SQL示例
3.1 多表关联(4表JOIN)
-- 左连接 + 右连接 + 窗口函数
SELECT
e.emp_name,
d.dept_name,
p.project_name,
pa.role,
AVG(e.salary) OVER (PARTITION BY d.dept_id) AS avg_dept_salary
FROM employees@dblink_pwcrm149 e
LEFT JOIN departments d ON e.department = d.dept_name
RIGHT JOIN projects@dblink_pwcrm149 p ON d.dept_id = p.dept_id
JOIN project_assignments pa ON pa.project_id = p.project_id
WHERE p.start_date > SYSDATE - 365
AND e.salary > 6000;3.2 笛卡尔积与过滤条件
-- 笛卡尔积 + CASE判断
SELECT
e.emp_name,
p.project_name,
CASE
WHEN e.salary > 10000 THEN 'High'
WHEN e.salary BETWEEN 5000 AND 10000 THEN 'Medium'
ELSE 'Low'
END AS salary_level
FROM employees@dblink_pwcrm149 e, projects p
WHERE p.dept_id = 1
AND e.department = 'IT';3.3 嵌套循环(NESTED LOOP)
-- 强制使用NESTED LOOP(提示方式)
SELECT /*+ USE_NL(e d) */
e.emp_id,
d.dept_name
FROM employees e
JOIN departments@dblink_pwcrm149 d ON e.department = d.dept_name
WHERE d.budget > 500000;3.4 哈希连接(HASH JOIN)
-- 强制使用HASH JOIN
SELECT /*+ USE_HASH(pa p) */
pa.assignment_id,
p.project_name
FROM project_assignments pa
JOIN projects@dblink_pwcrm149 p ON pa.project_id = p.project_id
WHERE p.end_date > SYSDATE;3.5 聚合函数与GROUP BY
-- 聚合函数 + HAVING
SELECT
d.dept_name,
COUNT(e.emp_id) AS total_employees,
SUM(e.salary) AS total_salary
FROM departments@dblink_pwcrm149 d
LEFT JOIN employees e ON d.dept_name = e.department
GROUP BY d.dept_name
HAVING SUM(e.salary) > 100000;3.6 子查询与EXISTS
-- EXISTS子查询
SELECT
e.emp_name
FROM employees e
WHERE EXISTS (
SELECT 1
FROM project_assignments@dblink_pwcrm149 pa
WHERE pa.emp_id = e.emp_id
AND pa.role = 'Manager'
);3.7 窗口函数与RANK
-- RANK()窗口函数
SELECT
emp_name,
salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank
FROM employees@dblink_pwcrm149
WHERE department = 'IT';3.8 复杂条件与函数
-- 字符串函数 + 日期计算
SELECT
e.emp_name,
UPPER(d.dept_name) AS dept_upper,
ADD_MONTHS(e.hire_date, 12) AS hire_anniversary
FROM employees@dblink_pwcrm149 e
JOIN departments d ON e.department = d.dept_name
WHERE TO_CHAR(e.hire_date, 'YYYY') = '2023'
AND LENGTH(e.emp_name) > 5;总结
- 测试用例:覆盖了多表结构、索引、约束及循环插入数据。
- DBLink操作:实现了跨数据库的增删改查。
- 复杂SQL:包含多表关联、窗口函数、不同连接算法及优化提示。
通过以上案例,可以从多个维度测试不同数据库DBLink的功能性和性能,同时满足复杂业务场景需求。