从RNN、LSTM到NTM、MANN------神经网络的记忆与推理进化
一、前言:为什么要研究记忆?
(温馨提示:在阅读本文之前,请确保你已经对深度学习中最基本的概念有一定的了解,例如:激活函数、多层感知机、前向传播、反向传播等)
本文的侧重点是神经网络的记忆功能。
深度学习的科学家们总是喜欢从人脑 中汲取灵感。通过大脑神经元的结构,人们提出了神经网络图 ;通过人脑对重要事物的聚焦(注意力),人们提出了注意力机制(Attention is all you need );
显而易见,深度学习的科学家是不会放过记忆力 这个大脑的重要能力的。尤其是大模型时代,注意力机制 极大的加速了人工智能的发展,催生出了GPT4.0 、deepseek 之类的强悍模型,然而这些大模型无一例外的患有**"健忘症"**。大模型的参数虽然很多,但是它们的"记忆"能力是有限的,甚至是极其有限的。
为什么大模型会得健忘症?答案可能很幽默:正是由于大模型的自注意力机制,才导致了大模型无法实现长上下文处理。(什么是注意力机制?这个我们在后面会提到。现在不会也没关系)
自注意力机制的计算复杂度为 \(O(n^2)\),其中 n 是输入序列的长度。这意味着随着上下文的长度增加,计算所需的资源(时间和内存)也会平方级别增加 。这对一个普通的小程序来说当然不是问题,问题是那可是大模型啊,参数的数量会随着上下文长度急剧增加。一个千位长度的文字就能带来几百万个参数,还有大量的矩阵运算。所以,为了使计算时间没有那么长,我们不得不限制上下文的长度,代价就是大模型的**"健忘"**。
二、记忆力在深度学习中的作用
如何提升模型的记忆力?这显然是一个重要的课题。对于我们人类而言,记忆力显然是智力的重要组成部分。好的记忆力甚至可以大幅提升我们的推理能力和学习能力。
让我们首先类比身边的一个例子:学霸们记得都很多,而且学霸记得越多,学霸的学习速度也就越快,这就是所谓的**"记忆增强"** 。让我们拆分一下学霸的优点:*1、学霸可以快速学习新知识点;2、学霸自学能力极强;3、学霸不需要靠刷题就能取得高分。*现在让我们类比回深度学习的领域:
- 快速学习一个新知识,在深度学习领域一般称作 "一次学习(One-shot learning)";
- 通过以前的学习经验学习新的知识,在深度学习领域一般称作"元学习(Meta-Learning)";
- 通过少量样本素材进行学习,在深度学习领域一般称作"小样本学习"。
现在我们正处于**"大模型"**时代,各个公司的模型都是靠超级庞大的参数量来取胜,模型都是靠疯狂的"题海战术"来进行训练。然而,模型真的有必要这么大吗?小模型能不能起到和大模型同等的作用?能不能让我们的模型像一个学霸一样,不怎么刷题靠自学就可以成才?
综上,可以看出元学习、一次学习、少样本学习等领域仍然有非常重要的科研价值。而这些领域中的其中一个热门方向,就是使用外部记忆 来**"增强"**我们的神经网络模型。
这种思维模式由来已久,笔者难以考证最初的灵感来自于何时。但是,RNN是第一个备受人们关注的带有一定记忆功能的神经网络模型,所以让我们从RNN神经网络开始讲起。
最后,笔者不得不提到,外部记忆模块是否能像注意力机制一样大放光彩,还有待时间去验证。但是不得不说这是一个积极的探索,并且有迹可循。
三、循环神经网络RNN
"如果这个世界上的所有东西都毫无关联,那要记忆有何用呢?"------沃兹基硕德
希望在看到此处时,你已经知道了多层感知机和卷积神经网络 CNN 的基本概念。并且在此时我就要指出这两个模型的弱点:它们不擅长处理具有序列特性的信息。此时你一定会有两个问题:
- 什么是序列特性?
- 为什么CNN不擅长处理呢?
所谓序列特性的信息:就是和前面、后面的信息有关的信息。让我们把输入数据写作\((x_1,x_2,\dots,x_t,\dots,x_n)\),如果这些数据没有序列特性 ,就是指任一 \(x_i\) 和 \(x_j\) 都没有任何关系。
举个例子:
第一句话:冬天来了,能穿多少穿多少
第二句话:夏天来了,能穿多少穿多少
后面的输入(能穿多少穿多少)是完全相同的,但是语义却是完全不同的。这就是因为语言具有序列特性,前面的词语一换后面的意思就要发生变化。语言、声音、股票涨跌等信息都具有序列特性,待分类的图像则一般不具有序列特性。
为什么CNN不擅长处理带有序列特性的信息呢?不是说 CNN 不能处理这样的信息,但是 CNN 是通过卷积核进行特征提取的。卷积核的大小很有限,它只能非常局部地提取特征。
举个例子,看看下面这段文字:
李华 走进教室,发现所有的同学都在等待老师的到来。突然,门口传来了脚步声,++老师++ 走进了教室。大家立刻安静下来,专心听讲。++老师++开始布置作业,并提醒大家注意复习的重要性。通过这一天的努力, 他*相信自己能做好准备,迎接即将到来的考试。*
这是一个长序列特性 的文字。所谓长序列特性,就是它很长,又具有序列特性。比如上面这段文字,"他" 和**"李华"** 这两个词语之间是相关的(他=李华),但是这两个词语可谓是十万八千里,中间还有**"老师"**这个词的干扰。
如果交给CNN处理,CNN的卷积核只能注意到局部的特征。假设卷积核一次处理九个字(window_size=9):
李华走进教室发现所有的同学都在等待老师的到来。突然,门口传来了脚步声,++老师++ 走进了教室。大家立刻安静下来,专心听讲。++老师++ 开始布置作业,并提醒大家注意复习的重要性。通过这一天的努力,他相信自己能做好准备,迎接即将到来的考试。
李华 和他不可能在卷积核内同框,如果只进行一层卷积的话,显然不可能找到这两个词的关系。有一个办法是采用多个卷积层,但是这样做会加深神经网络的深度,及其容易出现梯度消失和过拟合的问题,计算时间也会大幅增长。
那么怎么办呢?这个时候需要我们的模型**"记住"** 之前的信息。在我们处理**"他"** 这个信息的时候,如果我们能**"记住""李华"**这个关键信息,那么一切就好办了。这就是 RNN 的思路。
这里还有一种可行的方式,就是**"他""注意到"了"李华"** 这个关键信息。这是 transformer 的思路。这篇文章就不主要讲解transformer了。
先上图:
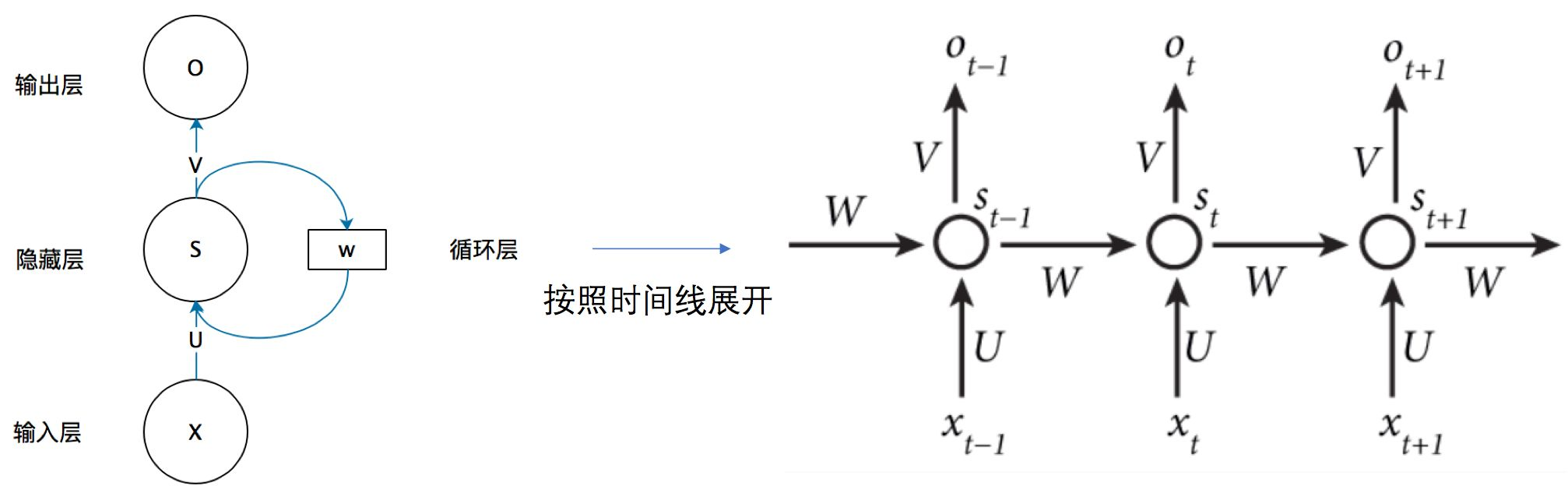
现在让我们假设一个神经元 \(s(t)\),这个神经元存着一个数字的信息,t 代表时刻。不难想到,\(s(t+1)\) 代表下一时刻的信息。\(input(x_t)\)代表这个神经元在 t 时刻的输入。
如果是普通的神经网络,那么只有:
\(s(t)=input(x_{t})\)
\(s(t+1)=input(x_{t+1})\)
显然这样的神经元的信息只和输入有关,每次都会被更新,根本没有记忆功能。那该如何具有记忆功能呢?很简单,我们只需要让上一时刻的信息 \(s(t)\) 也作为输入即可!
\(s(t+1)=input(x_{t+1})+s(t)\)
这样的神经元 s 不仅可以获得输入的信息 ,还能获得以前的状态信息。这个以前的状态信息是一个不断迭代后综合的信息,实际上是之前所有序列信息的一个综合。
但是,这样直接加还是有点太蠢了。万一输入太小,状态信息加大了怎么办?万一输入太大,直接把之前的状态信息盖掉了怎么办?++我们必须对 \(s(t)\) 进行调节,使其不能过大,也不能过小!++ 这个解决办法在神经网络中我们已经用过无数次,就是乘以一个权重,加上一个偏置值,使用激活函数。最后得到:
\(s(t+1)=f(i(x_{t+1})+w_s*s(t)+b)\)
恭喜你,RNN的基本思想你已经掌握了。由于我们的神经元往往一层多个,所以我们要用矩阵的形式来表示上述公式:
\(S_t=f(U\cdot X_t+W\cdot S_{t-1})\)
其他的部分和普通神经网络是相同的。
让我们回到这张图中:
(未完待续,联系我催更~~~)