数组专用工具类指的是 java.util.Arrays 类,基本上常见的数组操作,这个类都提供了静态方法可供直接调用。毕竟数组本身想完成这些操作还是挺麻烦的,有了这层封装,就方便多了。
java
package java.util;
/**
* @author Josh Bloch
* @author Neal Gafter
* @author John Rose
* @since 1.2
*/
public class Arrays {}方法一览
| 方法名 | 简要描述 |
|---|---|
| asList() | 返回由指定数组支持的固定大小的列表。 |
| sort() | 将数组排序(升序) |
| parallelSort() | 将指定的数组按升序排序 |
| binarySearch() | 使用二分搜索法快速查找指定的值(前提是数组必须是有序的) |
| compare() | 按字典顺序比较两个数组 |
| compareUnsigned() | 按字典顺序比较两个数组,将数字元素处理为无符号 |
| copyOf() | 填充复制数组 |
| copyOfRange() | 将数组的指定范围复制到新数组 |
| fill() | 将指定元素填充给数组每一个元素 |
| equals() | 比较两个数组 |
| deepEquals() | 比较两个数组深度 |
| toString() | 将数组转换为字符串 |
| deepToString() | 将一个多维数组转换为字符串 |
| mismatch() | 查找并返回两个数组之间第一个不匹配的索引,如果未找到则返回-1 |
| parallelPrefix() | 使用提供的函数对数组元素进行操作 |
| parallelSetAll() | 使用提供的生成器函数并行设置指定数组的所有元素以计算每个元素 |
| setAll() | 使用提供的生成器函数设置指定数组的所有元素以计算每个元素 |
asList()
- 功能:返回由指定数组支持的固定大小的列表
- 参数:asList(T... a)
- 返回值:一个列表
java
List < String > ss = Arrays.asList("hello", "world");
// List<String> ss1 = Arrays.asList("hello", "world",1); 报错,类型必须一致(泛型)
System.out.println(ss); //[hello, world]
// ss.add("java"); //UnsupportedOperationException 会报错
// ss.remove(1); //UnsupportedOperationException 会报错
System.out.println(ss.get(0)); //hello
ss.set(0, "java");
System.out.println(ss); //[java, world]需要注意的是,add方法和remove会报错。
这是因为asList() 返回的是Arrays类的内部类:
java
public static < T > List < T > asList(T...a) {
return new ArrayList < > (a);
}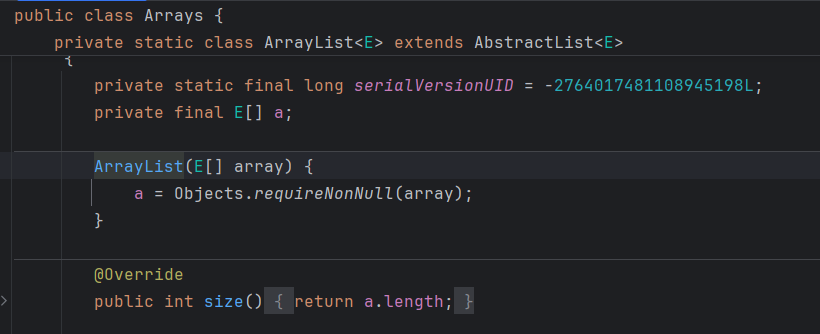
这个内部类也继承了 java.util.AbstractList 类,重写了很多方法,比如contains方法、set方法,但是却没有重写add方法,最终是调用了父类的add(int, E)方法,所以在调用add方法时才会抛出java.lang.UnsupportedOperationException异常。
关于这一点,在《阿里巴巴Java开发手册》中,也有提及:使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。

所以大家在使用Arrays.asList时还是要注意下,避免踩坑。
toString() 和 deepToString()
- 功能:将数组转换为字符串
- 参数:待转化数组
- 返回值:转化后的字符串
代码示例:
java
public void toStringTest() {
String[] str = {"java", "hello", "javascript"};
String[][] strs = {{"a", "b"}, {"c"}, {"d", "e"}};
System.out.println(Arrays.toString(str));
//[java, hello, javascript]
System.out.println(Arrays.toString(strs));
//[[Ljava.lang.String;@4563e9ab, [Ljava.lang.String;@11531931, [Ljava.lang.String;@5e025e70]
//普通的toString()方法只转化一层,内层还是地址值
System.out.println(Arrays.deepToString(strs));
//可以深度转换
//[[a, b], [c], [d, e]]
}方法源码:
java
public static String toString(Object[] a) {
// 先判断 null,是的话,直接返回"null"字符串;
if (a == null)
return "null";
//获取数组的长度
int iMax = a.length - 1;
//如果数组的长度为 0( 等价于 length - 1 为 -1),返回中括号"[]",表示数组为空的;
if (iMax == -1)
return "[]";
//如果数组既不是 null,长度也不为 0,就声明 StringBuilder 对象,
StringBuilder b = new StringBuilder();
//添加一个数组的开始标记"["
b.append('[');
//遍历数组,把每个元素添加进去
for (int i = 0; ; i++) {
b.append(String.valueOf(a[i]));
//当遇到末尾元素的时候(i == iMax),不再添加逗号和空格", ",而是添加数组的闭合标记"]"。
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}sort() 和 parallelSort()
- 功能:都是将数组排序(默认升序,支持lambda,泛型),默认的排序算法是 Dual-Pivot Quicksort
- 参数:
sort(Object[] a[, int fromIndex, int toIndex]) 或者 sort(T[] a[, int fromIndex, int toIndex,] Comparator<? super T> c)
parallelSort(Object[] a[, int fromIndex, int toIndex]) 或者 parallelSort(T[] a[, int fromIndex, int toIndex,] Comparator<? super T> c)
代码示例:
java
public void sortTest() {
String[] str = {
"abc", "add", "java", "hello", "javascript"
};
int[] ii = {
1, 8, 99, 222, 35
};
//单参数情况
Arrays.sort(str); //默认全排,字母会按照字母表顺序
Arrays.sort(ii);
System.out.println(Arrays.toString(str)); //[abc, add, hello, java, javascript]
System.out.println(Arrays.toString(ii)); //[1, 8, 35, 99, 222]
//多参数情况
Arrays.sort(str,2,4); //只排列指定范围内的
Arrays.sort(ii,2,4);
System.out.println(Arrays.toString(str)); //[abc, add, hello, java, javascript]
System.out.println(Arrays.toString(ii)); //[1, 8, 99, 222, 35]
//可传入lambda表达式,指定排序比较器(多参数情况可指定开始结束位置)
Arrays.sort(str, (a, b) -> b.compareTo(a)); //降序
System.out.println(Arrays.toString(str)); //[javascript, java, hello, add, abc]
//parallelSort()方法目前我实验感觉与sort()相差无几,基本相似
Arrays.parallelSort(str);
System.out.println(Arrays.toString(str)); //[abc, add, hello, java, javascript]
Arrays.parallelSort(str, (a, b) - > b.compareTo(a));
System.out.println(Arrays.toString(str)); //[javascript, java, hello, add, abc]
}sort源码
java
public static void sort(int[] a) { //整体排序
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
public static void sort(int[] a, int fromIndex, int toIndex) { //部分排序
rangeCheck(a.length, fromIndex, toIndex);
DualPivotQuicksort.sort(a, fromIndex, toIndex - 1, null, 0, 0);
}从源码上看整体排序并不是调用的部分排序的方法,Arrays.sort(int\[\] a)和Arrays.sort(int\[\] a, int fromIndex, int toIndex)只是个入口,它们都会去调用DualPivotQuicksort.sort方法,都会传入排序部分的起终点,不过整体排序传入的起终点为0和length - 1。
从数组元素的类型来看,可以将Arrays.sort分为对基本数据类型的排序和对泛型及Object数组的排序。进入源码我们可以发现:对于基本数据类型数组的排序,Arrays.sort都将调用DualPivotQuicksort.sort方法,而泛型及Object数组的排序实现则与之不同。
对基本数据类型数组的排序
对于基本数据类型数组的排序,Arrays.sort都将调用DualPivotQuicksort.sort方法,来看看这个方法的部分源码(感兴趣可自行阅读,或可直接往后看结论):
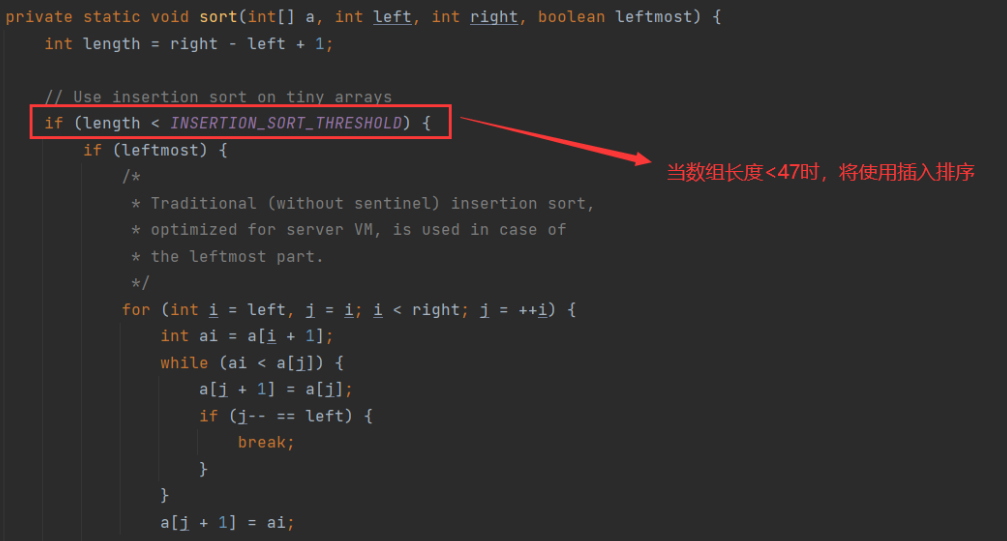
java
static void sort(int[] a, int left, int right,
int[] work, int workBase, int workLen) {
// 若数组长度<286,将调用sort(a, left, right, true)
if (right - left < QUICKSORT_THRESHOLD) {
sort(a, left, right, true);
return;
}
/*
* Index run[i] is the start of i-th run
* (ascending or descending sequence).
*/
int[] run = new int[MAX_RUN_COUNT + 1];
int count = 0;
run[0] = left;
// Check if the array is nearly sorted
for (int k = left; k < right; run[count] = k) {
if (a[k] < a[k + 1]) { // ascending
while (++k <= right && a[k - 1] <= a[k]);
} else if (a[k] > a[k + 1]) { // descending
while (++k <= right && a[k - 1] >= a[k]);
for (int lo = run[count] - 1, hi = k; ++lo < --hi;) {
int t = a[lo];
a[lo] = a[hi];
a[hi] = t;
}
} else { // equal
for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k];) {
if (--m == 0) {
sort(a, left, right, true);
return;
}
}
}
/*
* The array is not highly structured,
* use Quicksort instead of merge sort.
*/
if (++count == MAX_RUN_COUNT) {
sort(a, left, right, true);
return;
}
}
// Check special cases
// Implementation note: variable "right" is increased by 1.
if (run[count] == right++) { // The last run contains one element
run[++count] = right;
} else if (count == 1) { // The array is already sorted
return;
}
// Determine alternation base for merge
byte odd = 0;
for (int n = 1;
(n <<= 1) < count; odd ^= 1);
// Use or create temporary array b for merging
int[] b; // temp array; alternates with a
int ao, bo; // array offsets from 'left'
int blen = right - left; // space needed for b
if (work == null || workLen < blen || workBase + blen > work.length) {
work = new int[blen];
workBase = 0;
}
if (odd == 0) {
System.arraycopy(a, left, work, workBase, blen);
b = a;
bo = 0;
a = work;
ao = workBase - left;
} else {
b = work;
ao = 0;
bo = workBase - left;
}
// Merging
for (int last; count > 1; count = last) {
for (int k = (last = 0) + 2; k <= count; k += 2) {
int hi = run[k], mi = run[k - 1];
for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) {
if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) {
b[i + bo] = a[p++ +ao];
} else {
b[i + bo] = a[q++ +ao];
}
}
run[++last] = hi;
}
if ((count & 1) != 0) {
for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao]);
run[++last] = right;
}
int[] t = a;
a = b;
b = t;
int o = ao;
ao = bo;
bo = o;
}
}
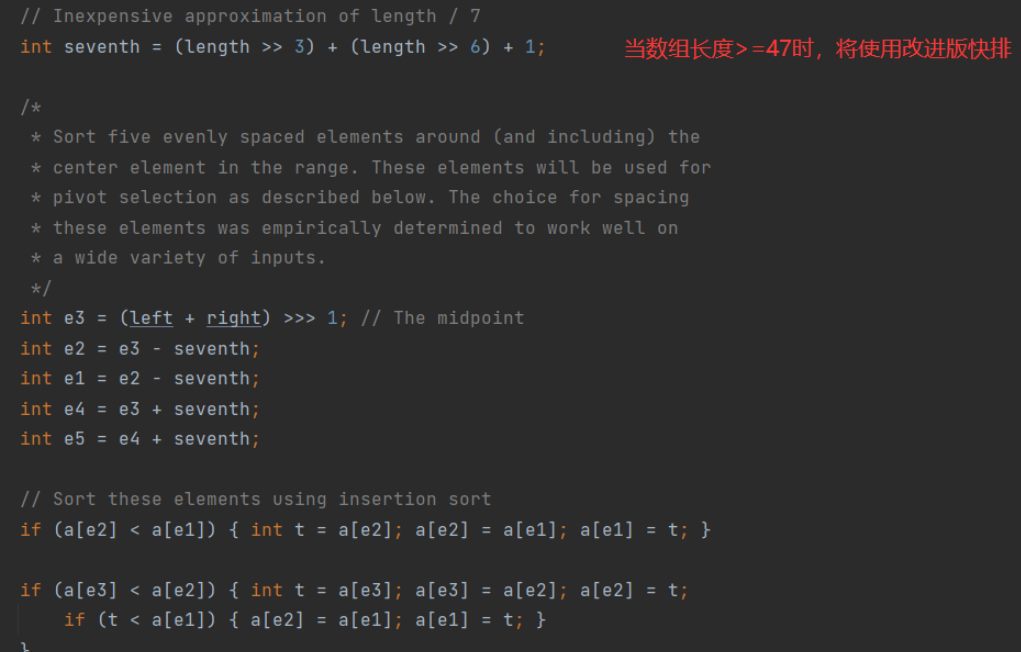
也就是说,若数组长度小于286,则会再次判断:
- 若数组长度较小,,长度<47,则使用插入排序
- 若数组长度>=47,将使用快速排序
这是由排序算法的特性决定的,因为在数组长度很小时,在大量测试的平均结果下,插入排序将快于快排。
那么当数组长度>=286时呢?重新回到DualPivotQuicksort.sort方法,发现会对数组的结构性进行判断:
- 若数组基本有序,则将使用归并排序
- 若数组的元素排列较为混乱,则调用sort(a, left, right, true)方法,由于数组长度>=286,也>=47,因此会进行快速排序。
为什么这样设计也是由排序算法的特性决定的,虽然快排和归并排序的(平均)时间复杂度是一样的,但对于基本有序的数组,归并排序的速度会比快速排序快,而对于近乎无序的数组,归并排序速度会比快速排序慢。
总结一下,对于基本数据类型数组的排序,排序算法的选择和数组长度的关系如下:
| 数组长度 | 所使用的排序算法 |
|---|---|
| length < 47 | 插入排序 |
| 47 <= length < 286 | 快速排序 |
| length >= 286 且数组基本有序 | 归并排序 |
| length >= 286 且数组基本无序 | 快速排序 |
对Object数组和泛型数组的排序
对于泛型数组的排序,可以传入实现了Comparator接口的类的对象,也可以不传,实际上传和不传都是调用的同一个方法,只不过不传入时,对应的参数为null。我们来看看Arrays.sort对Object数组和泛型数组的排序源码:
java
public static void sort(Object[] a) {
// jdk1.7之前的排序用的就是归并排序,legacyMergeSort此方法就是1.7为了兼容之前版本的归并排序。
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}JDK8会默认选择TimSort作为排序算法。TimSort算法是一种起源于归并排序和插入排序的混合排序算法,原则上TimSort是归并排序,但小片段的合并中用了插入排序。对于泛型数组的排序,若不传入实现了Comparator接口的类的对象,将调用sort(Object\[\] a)方法
接下来看调用的ComparableTimSort.sort方法的部分源码:
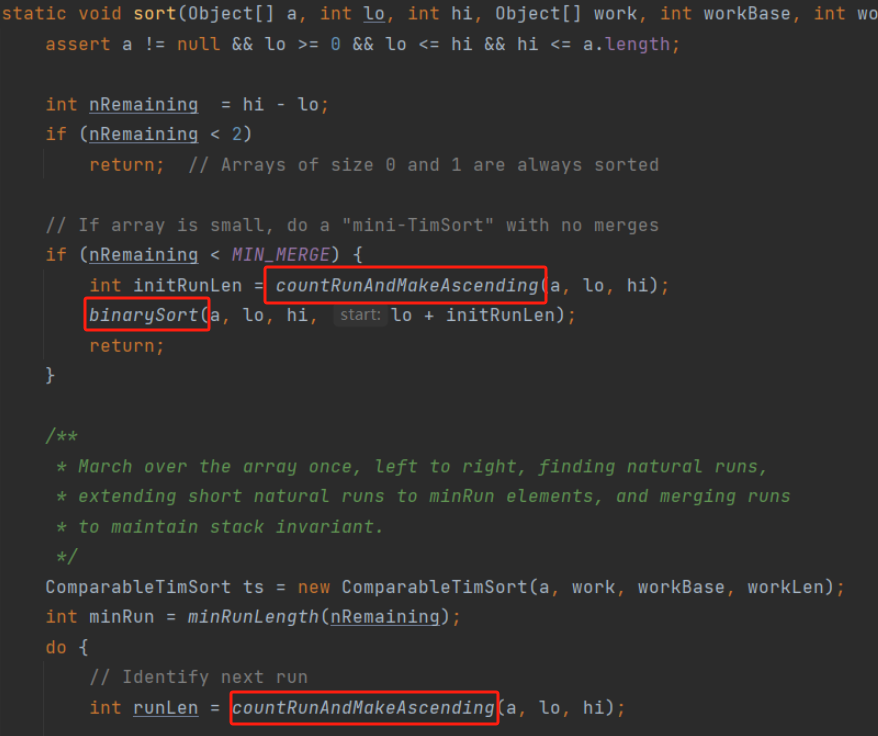
ComparableTimSort.sort 会调用countRunAndMakeAscending方法和binarySort方法,而这两个方法都有将数组元素强转为Comparable接口类型的操作,因为它需要调用Comparable接口中的compareTo方法进行元素间的比较,Comparable接口中只定义了一个方法,那就是compareTo。
java
private static int countRunAndMakeAscending(Object[] a, int lo, int hi) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
if (((Comparable) a[runHi++]).compareTo(a[lo]) < 0) { // Descending
//将数组元素强转为Comparable接口类型
while (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // Ascending
while (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
private static void binarySort(Object[] a, int lo, int hi, int start) {
assert lo <= start && start <= hi;
if (start == lo)
start++;
for (; start < hi; start++) {
//将数组元素强转为Comparable接口类型
Comparable pivot = (Comparable) a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
while (left < right) {
int mid = (left + right) >>> 1;
//compareTo方法
if (pivot.compareTo(a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2:
a[left + 2] = a[left + 1];
case 1:
a[left + 1] = a[left];
break;
default:
System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}因此,若调用Arrays.sort(Object\[\] o)对Object数组进行排序,但数组元素类型表示的类并没有实现Comparable接口,那么Java将认为该类的对象是无法比较的,那么就会抛出ClassCastException异常.
小结
JDK中的Arrays.sort实际上采用的是设计模式中的模板模式,将排序算法的步骤封装了起来,而将如何比较两个数组元素交给了程序员来实现。
当排序自定义类时,可以让这个类实现Comparable接口,并重写其compareTo方法。也可以创建一个实现了Comparator接口的类,重写其compare方法。具体如何比较两个数组元素的逻辑就写在了需要重写的这两个方法中。
比较两个数组元素o1与o2的大小无非三种结果:o1>o2,o1=o2,o1<o2。因此compareTo方法和compare方法的返回值有三种情况,这是针对默认升序设计的:
- 当o1 > o2,返回一个正整数;
- 若o1 = o2,返回0;
- 若o1 < o2,返回一个负整数。
对于实现了Comparable接口的类,o1 即为this,表示当前类对象。若在重写方法的逻辑中按上述对应关系去返回对应值(即return o1 -o2),则调用Arrays.sort将会得到升序结果;若把对应关系写反((即return o2 -o1)),则会得到降序结果。
parallelSort()
parallelSort() 在功能上有所不同。与 sort() 使用单个线程对数据进行顺序排序不同,它使用 并行排序-合并排序 算法。它将数组分成子数组,这些子数组本身先进行排序然后合并。为了执行并行任务,它使用 ForkJoin 池。
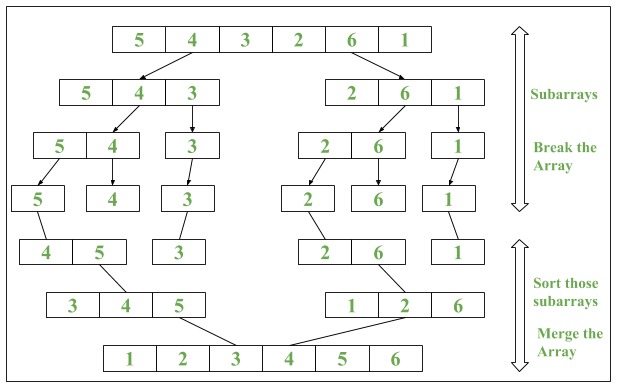
parallelSort源码:如果数组大小小于或等于 8192,或者处理器只有一个核心,则它将使用顺序的 Dual-Pivot Quicksort 算法。否则,它使用并行排序。
java
public static < T extends Comparable <? super T >> void parallelSort(T[] a) {
int n = a.length, p, g;
// MIN_ARRAY_SORT_GRAN = 1<<13,即8192
if (n <= MIN_ARRAY_SORT_GRAN ||
//或者处理器只有一个核心
(p = ForkJoinPool.getCommonPoolParallelism()) == 1)
//使用顺序的 Dual-Pivot Quicksort 算法
DualPivotQuicksort.sort(a, 0, n - 1, null, 0, 0);
else
new ArraysParallelSortHelpers.FJInt.Sorter
(null, a, new int[n], 0, n, 0,
((g = n / (p << 2)) <= MIN_ARRAY_SORT_GRAN) ?
MIN_ARRAY_SORT_GRAN : g).invoke();
}小结
当要排序的数据集很大时,parallelSort() 可能是更好的选择。但是,在数组较小的情况下,最好使用 sort(),因为它可以提供更好的性能。
binarySearch()
- 功能:使用二分搜索法快速查找指定的值(前提是数组必须是有序的,支持lambda表达式,泛型)
- 参数:binarySearch(Object\[\] a, int fromIndex, int toIndex, Object key)
- 返回值:有则返回对应下标,无则返回负值
代码示例:
java
public void binarySearchTest() {
int[] a = {
1, 5, 7, 4, 6, 7, 8, 4, 9, 0
};
Arrays.sort(a); //必须先排序
System.out.println(Arrays.toString(a));
//[0, 1, 4, 4, 5, 6, 7, 7, 8, 9]
System.out.println(Arrays.binarySearch(a, 4)); //2
System.out.println(Arrays.binarySearch(a, 11)); //-11
//也可指定范围查找,其查找机制是折半查找,每次缩小一半范围
}源码:
java
private static int binarySearch0(int[] a, int fromIndex, int toIndex, int key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}创建数组
使用 Arrays 类创建数组可以通过以下三个方法:
- copyOf,复制指定的数组,截取或用 null 填充
- copyOfRange,复制指定范围内的数组到一个新的数组
- fill,对数组进行填充
copyOf 和copyOfRange
- 功能:复制填充数组
- 参数 :
copyOf(int[] original, int newLength)
copyOf(T[] original, int newLength)
copyOfRange(int[] original, int from, int to)
copyOfRange(T[] original, int from, int to)
copyOfRange(U[] original, int from, int to, class <? extends T[]> newType) - 返回值:复制填充后的数组
- 区别 :
copyOf()是从原数组0位置开始拷贝指定长度到新数组;
copyOfRange()是从原数组中指定范围拷贝到新数组,如果指定长度或者范围超出原数组范围,则超出部分会补上此数据类型的默认值,如String类型会补null,int型会补0
代码示例
java
public void copyOfTest() {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
int[] arr1 = Arrays.copyOf(arr, 5); //拷贝长度为5,第二个参数为新数组的长度
int[] arr2 = Arrays.copyOf(arr, 15);
System.out.println(Arrays.toString(arr1)); //[1, 2, 3, 4, 5]
System.out.println(Arrays.toString(arr2)); //[1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 0, 0, 0, 0, 0]
arr[0] = 20; //改变原数组
System.out.println(Arrays.toString(arr)); //原数组改变
System.out.println(Arrays.toString(arr1)); //复制后的数组不变
String[] str = {"java", "hello", "world"};
String[] str1 = Arrays.copyOf(str, 2);
String[] str2 = Arrays.copyOf(str, 5);
System.out.println(Arrays.toString(str1)); //[java, hello]
System.out.println(Arrays.toString(str2)); //[java, hello, world, null, null]
//copyOfRange()
int[] arrs = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
int[] arr3 = Arrays.copyOfRange(arrs, 2, 8); //[3, 4, 5, 6, 7, 8]
int[] arr4 = Arrays.copyOfRange(arrs, 5, 15); //[6, 7, 8, 9, 0, 0, 0, 0, 0, 0]
System.out.println(Arrays.toString(arr3));
System.out.println(Arrays.toString(arr4));
arrs[6] = 99; //改变原数组
System.out.println(Arrays.toString(arrs)); //[1, 2, 3, 4, 5, 6, 99, 8, 9, 0] 原数组改变
System.out.println(Arrays.toString(arr3)); //[3, 4, 5, 6, 7, 8] 复制后的不会随着改变
}fill
- 功能:将指定元素填充给数组每一个元素
- 参数:fill(int\[\] a, 【int fromIndex, int toIndex】, int val)
- 返回值:无
代码示例:
java
String[] stutter = new String[4];
Arrays.fill(stutter, "seven");
System.out.println(Arrays.toString(stutter));//[seven, seven, seven, seven]源码如下:
java
public static void fill(Object[] a, int fromIndex, int toIndex, Object val) {
rangeCheck(a.length, fromIndex, toIndex);
//遍历填充
for (int i = fromIndex; i < toIndex; i++)
a[i] = val;
}setAll 和 parallelSetAll()
Java 8 新增了 setAll() 方法,它提供了一个函数式编程的入口,可以对数组的元素进行填充:
java
int[] array = new int[10];
// i 就相当于是数组的下标,值从 0 开始,到 9 结束,那么 `i * 10` 就意味着值从 0 * 10 开始,到 9 * 10 结束
Arrays.setAll(array, i -> i * 10);
System.out.println(Arrays.toString(array));//[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]可以用来为新数组填充基于原来数组的新元素。
parallelSetAll() 就是 setAll 的并行版本,都是通过索引值去改变元素,改编后的值与索引有关
java
String[] str1 = {"a", "b", "c"};
Arrays.parallelSetAll(str1, (m) -> m + "haha");
System.out.println(Arrays.toString(str1)); //[0haha, 1haha, 2haha]equals() 和 deepEquals()
Arrays 类的 equals() 方法用来判断两个数组是否相等,来看下面这个例子:
java
String[] s1 = new String[] { "s", "e", "v", "e" };
System.out.println(Arrays.equals(new String[]{"s", "e", "v", "e"}, s1));//true
System.out.println(Arrays.equals(new String[]{"s", "e", "v", "n"}, s1));//false
String[][] s4 = {{"hello"}, {"java"}, {"c++"}, {"python"}};
String[][] s5 = {{"hello"}, {"java"}, {"c++"}, {"python"}};
System.out.println(Arrays.deepEquals(s4, s5)); //true
System.out.println(Arrays.equals(s4, s5)); //false
int[][] a = {{1,2},{3,4}};
int[][] b = {{1,2},{3,4}};
System.out.println(Arrays.deepEquals(a,b));// true区别在于:
- equals默认从头比较到尾,也可以指定范围,但是deepEquals不能指定范围
- deepEquals可以比较一维数组,也支持比较多维数组,而equals不能
- 当deepEquals比较一维数组时,不支持比较基本类型数组,如int\[\],但支持int\[\]\[\]
equals() 方法的源码:
java
public static boolean equals(Object[] a, Object[] a2) {
//数组是一个对象,所以先使用"=="操作符进行判断
if (a==a2)
return true;
//再判断是否为 null,其中一个为 null,返回 false
if (a==null || a2==null)
return false;
int length = a.length;
//判断 length,不等的话,返回 false
if (a2.length != length)
return false;
//否则的话,依次调用 Objects.equals() 比较相同位置上的元素是否相等
for (int i=0; i<length; i++) {
if (!Objects.equals(a[i], a2[i]))
return false;
}
return true;
}这里数组是一个对象的问题 可以看这篇文章 数组是不是对象,int\[\]数组是Object,但不是Object\[\],deepEquals支持的是Object\[\],int\[\]\[\]则属于Object\[\]
deepEquals() 方法的源码:
java
public static boolean deepEquals(Object[] a1, Object[] a2) {
//同equals
if (a1 == a2)
return true;
if (a1 == null || a2 == null)
return false;
int length = a1.length;
if (a2.length != length)
return false;
for (int i = 0; i < length; i++) {
Object e1 = a1[i];
Object e2 = a2[i];
if (e1 == e2)
continue;
if (e1 == null)
return false;
//如果是个多维数组,则递归比较
boolean eq = deepEquals0(e1, e2);
if (!eq)
return false;
}
return true;
}数组转流 stream()
Arrays 类的 stream() 方法可以将数组转换成流:
java
String[] intro = new String[] { "沉", "默", "王", "二" };
System.out.println(Arrays.stream(intro).count());还可以为 stream() 方法指定起始下标和结束下标:
java
System.out.println(Arrays.stream(intro, 1, 2).count());如果下标的范围有误的时候,比如说从 2 到 1 结束,则程序会抛出 ArrayIndexOutOfBoundsException 异常:
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: origin(2) > fence(1)
at java.base/java.util.Spliterators.checkFromToBounds(Spliterators.java:387)parallelPrefix
parallelPrefix 通过遍历数组中的元素,将当前下标位置上的元素与它之前下标的元素进行操作,然后将操作后的结果覆盖当前下标位置上的元素。
java
int[] arr = new int[] { 1, 2, 3, 4};
Arrays.parallelPrefix(arr, (left, right) -> left + right);
System.out.println(Arrays.toString(arr));上面代码中有一个 Lambda 表达式((left, right) -> left + right),是什么意思呢?上面这段代码等同于:
java
int[] arr = new int[]{1, 2, 3, 4};
Arrays.parallelPrefix(arr, (left, right) -> {
System.out.println(left + "," + right);
return left + right;
});
System.out.println(Arrays.toString(arr));来看一下输出结果就明白了:
1,2
3,3
6,4
[1, 3, 6, 10]也就是说, Lambda 表达式执行了三次:
- 第一次是 1 和 2 相加,结果是 3,替换下标为 1 的位置
- 第二次是 3 和 3 相加,结果是 6,也就是第一次的结果和下标为 2 的元素相加的结果
- 第三次是 6 和 4 相加,结果是 10,也就是第二次的结果和下标为 3 的元素相加的结果