SQL Server数据库中,我们都清楚统计信息对于优化器来说非常重要。一般情况下,我们会开启"自动更新统计信息"(Auto Update Statistics)这个选项,以便数据库能自动更新过期/过时的统计信息,因为过期/过时的统计信息可能会导致数据库生成一个糟糕的执行计划,SQL性能将会大打折扣,举一个例子,我们大脑做一些决策的时候,严重依赖所获取做决策信息的真实性与准确性,如果你所获得的信息是错误的,那么十有八九你会做出一个严重错误的决定。例如,如果当下环境中,你获取的信息:"买房稳赚不赔;买房会抗通胀......"是过时/错误的信息,那么你就会为当下的决策付出惨痛代价。
"自动更新统计信息"固然是不错的一个功能,但是很多人对它内部的原理知之甚少。对于"自动更新统计信息"是否开启也是有一些争论的。如果你监控发现一个SQL的执行计划经常出现变化,除了参数嗅探外等因素外,那么你要考虑一下可能是因为SQL语句中所涉及的表的统计信息自动更新导致。个人曾遇到一个案例,SQL语句的执行计划在凌晨2点变了,而且是性能变差,具体原因是在这个时间段,有一个作业会归档清理数据,导致触发自动统计信息更新,而它使用的是自动采样比例,而由于采样比例过低,导致优化器生成了一个较差的执行计划。如果你不用扩展事件去跟踪、分析的话,那么真的很难搞清楚为什么出现这种玄幻的现象。
下面是一个SQL执行计划经常出现变化的例子的截图,来自SolarWinds的DPA。 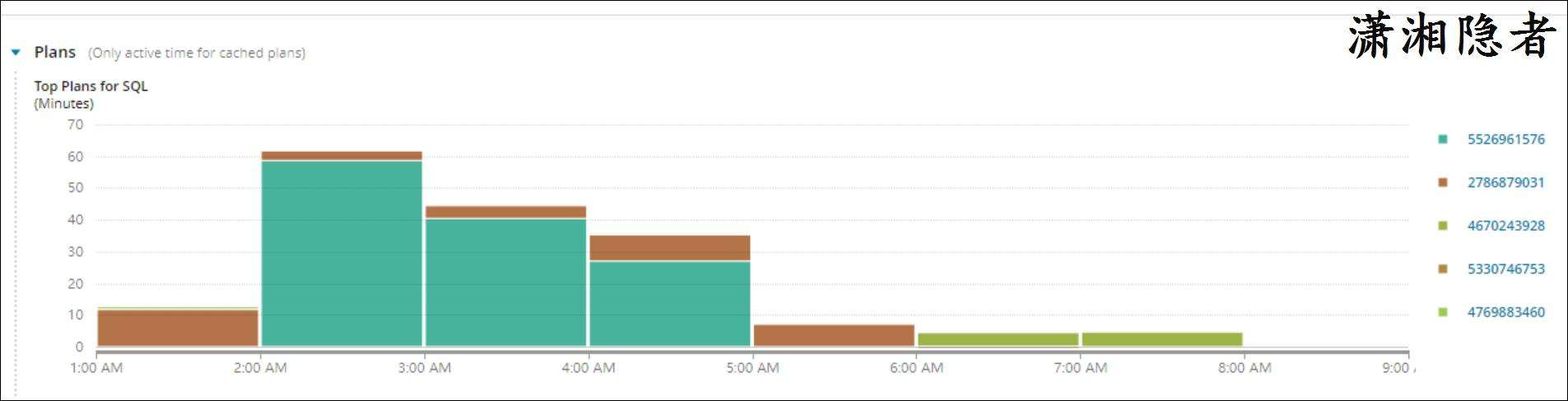
下面介绍一下,如何使用扩展事件跟踪统计信息自动更新。可以在做一些深入分析时用到。
创建扩展事件stat_auto_update_event
CREATE EVENT SESSION [stat_auto_update_event] ON SERVER
ADD EVENT sqlserver.auto_stats(
ACTION(sqlserver.sql_text,sqlserver.username,sqlserver.database_name))
ADD TARGET package0.event_file(SET filename=N'E:\extevntlog\stat_auto_update_event',max_rollover_files=(60)),
ADD TARGET package0.ring_buffer
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO启动会话,扩展事件就能捕获数据库中"自动更新统计信息"的一些事件了。
ALTER EVENT SESSION [stat_auto_update_event] ON SERVER
STATE = START;此时,你就可以用下面SQL查看/分析"自动更新统计信息"的一些详细信息了。
IF OBJECT_ID('tempdb..#stat_auto_update_event') IS NOT NULL
DROP TABLE #stat_auto_update_event;
CREATE TABLE #stat_auto_update_event
(
[ID] INT IDENTITY(1, 1)
NOT NULL ,
[stat_update_dtl] XML ,
CONSTRAINT [pk_stat_auto_update_event] PRIMARY KEY CLUSTERED ( [ID] )
);
INSERT #stat_auto_update_event
( [stat_update_dtl] )
SELECT CONVERT(XML, [event_data]) AS [stat_update_dtl]
FROM [sys].[fn_xe_file_target_read_file]('E:\extevntlog\stat_update_event*.xel', NULL, NULL, NULL)
CREATE PRIMARY XML INDEX [xml_idx_stat_dtl] ON #stat_auto_update_event([stat_update_dtl]);
CREATE XML INDEX [xml_idx_stat_dtl_path] ON [#stat_auto_update_event]([stat_update_dtl])
USING XML INDEX [xml_idx_stat_dtl] FOR VALUE;
WITH cte_stat AS (
SELECT
[sw].[stat_update_dtl].[value]('(/event/data[@name="database_id"]/value)[1]', 'INT') AS [database_id],
[sw].[stat_update_dtl].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') AS [event_time],
[sw].[stat_update_dtl].[value]('(/event/@name)[1]', 'VARCHAR(MAX)') AS [event_name],
[sw].[stat_update_dtl].[value]('(/event/data[@name="index_id"]/value)[1]', 'BIGINT') AS [index_id],
[sw].[stat_update_dtl].[value]('(/event/data[@name="object_id"]/value)[1]', 'BIGINT') AS [object_id],
[sw].[stat_update_dtl].[value]('(/event/data[@name="job_type"]/text)[1]', 'VARCHAR(MAX)') AS [job_type],
[sw].[stat_update_dtl].[value]('(/event/data[@name="sample_percentage"]/value)[1]','INT') AS [sample_pct],
[sw].[stat_update_dtl].[value]('(/event/data[@name="status"]/text)[1]', 'VARCHAR(MAX)') AS [status],
[sw].[stat_update_dtl].[value]('(/event/data[@name="duration"]/value)[1]', 'BIGINT') / 1000000. AS [duration],
[sw].[stat_update_dtl].[value]('(/event/data[@name="statistics_list"]/value)[1]', 'VARCHAR(MAX)') AS [statistics_list]
FROM [#stat_auto_update_event] AS [sw]
)
SELECT
DB_NAME([cte_stat].[database_id]) AS [database_name] ,
DATEADD(HOUR, DATEDIFF(HOUR, GETUTCDATE(), GETDATE()), [cte_stat].[event_time]) AS [event_time] ,
[cte_stat].[event_name] ,
OBJECT_NAME([cte_stat].[object_id],[cte_stat].[database_id]) AS object_name,
[cte_stat].[index_id] ,
[cte_stat].[job_type] ,
[cte_stat].[status] ,
[cte_stat].[sample_pct],
[cte_stat].[duration] ,
[cte_stat].[statistics_list]
FROM cte_stat
ORDER BY [cte_stat].[event_time];上面扩展事件是跟踪整个数据库实例下的所有"自动更新统计信息"事件,会存在一定的开销,如果我只想跟踪某个对象,那么可以在创建扩展事件时进行过滤处理,如下所示,我只跟踪表test的"自动更新统计信息",那么就可以通过下面脚本添加扩展事件
CREATE EVENT SESSION [test_auto_update_event] ON SERVER
ADD EVENT sqlserver.auto_stats(
SET collect_database_name=(0)
ACTION
(
sqlserver.client_app_name
,sqlserver.sql_text
,sqlserver.tsql_stack
,sqlserver.username
,sqlserver.database_name
)
WHERE
[object_id] =45243216/* order of conditions matters - pick the most selective first */
AND [database_id] =5
AND [package0].[not_equal_uint64]([status], 'Loading stats without updating')
)
ADD TARGET package0.event_file(SET filename=N'E:\extevntlog\test_auto_update_event',max_rollover_files=(60)),
ADD TARGET package0.ring_buffer
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO注意:要根据实际情况调整相关值,例如database_id、object_id的值。
手动构造一些条件,触发表test自动更新统计信息,此时,你可以使用ssms工具查看扩展事件捕获的一些数据了,如下截图所示:
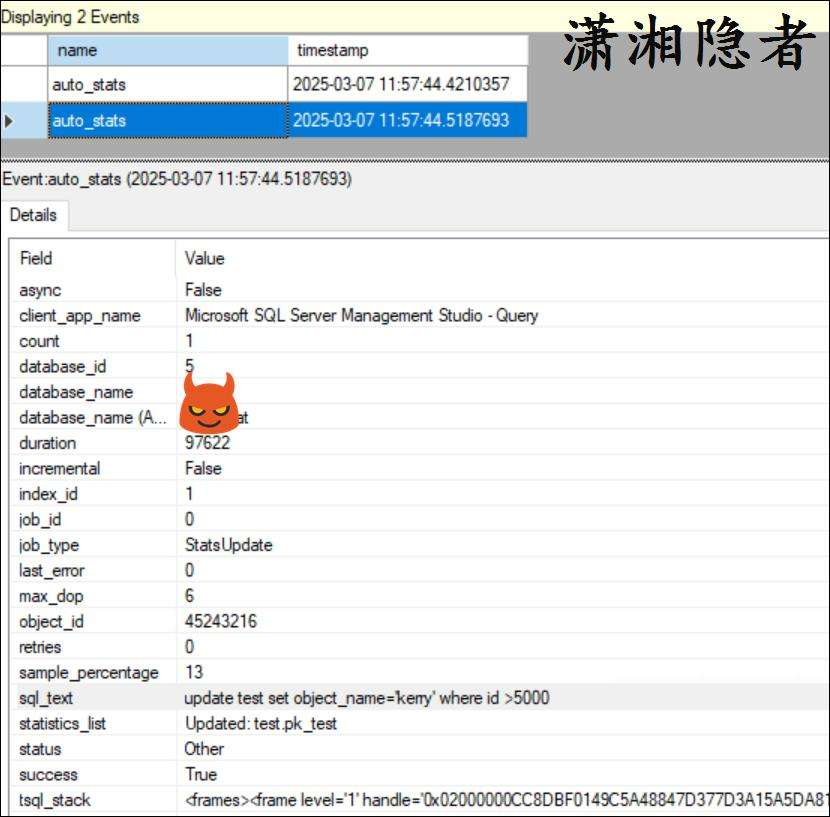
当然,你也可以使用下面SQL语句进行查询
IF OBJECT_ID('tempdb..#stat_auto_update_event') IS NOT NULL
DROP TABLE #stat_auto_update_event;
CREATE TABLE #stat_auto_update_event
(
[ID] INT IDENTITY(1, 1)
NOT NULL ,
[stat_update_dtl] XML ,
CONSTRAINT [pk_stat_auto_update_event] PRIMARY KEY CLUSTERED ( [ID] )
);
INSERT #stat_auto_update_event
( [stat_update_dtl] )
SELECT CONVERT(XML, [event_data]) AS [stat_update_dtl]
FROM [sys].[fn_xe_file_target_read_file]('E:\extevntlog\test_auto_update_event*.xel', NULL, NULL, NULL)
CREATE PRIMARY XML INDEX [xml_idx_stat_dtl] ON #stat_auto_update_event([stat_update_dtl]);
CREATE XML INDEX [xml_idx_stat_dtl_path] ON [#stat_auto_update_event]([stat_update_dtl])
USING XML INDEX [xml_idx_stat_dtl] FOR VALUE;
WITH cte_stat AS (
SELECT
[sw].[stat_update_dtl].[value]('(/event/data[@name="database_id"]/value)[1]', 'INT') AS [database_id],
[sw].[stat_update_dtl].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') AS [event_time],
[sw].[stat_update_dtl].[value]('(/event/@name)[1]', 'VARCHAR(MAX)') AS [event_name],
[sw].[stat_update_dtl].[value]('(/event/data[@name="index_id"]/value)[1]', 'BIGINT') AS [index_id],
[sw].[stat_update_dtl].[value]('(/event/data[@name="object_id"]/value)[1]', 'BIGINT') AS [object_id],
[sw].[stat_update_dtl].[value]('(/event/data[@name="job_type"]/text)[1]', 'VARCHAR(MAX)') AS [job_type],
[sw].[stat_update_dtl].[value]('(/event/data[@name="sample_percentage"]/value)[1]','INT') AS [sample_pct],
[sw].[stat_update_dtl].[value]('(/event/data[@name="status"]/text)[1]', 'VARCHAR(MAX)') AS [status],
[sw].[stat_update_dtl].[value]('(/event/data[@name="duration"]/value)[1]', 'BIGINT') / 1000000. AS [duration],
[sw].[stat_update_dtl].[value]('(/event/data[@name="statistics_list"]/value)[1]', 'VARCHAR(MAX)') AS [statistics_list],
[sw].[stat_update_dtl].[value]('(/event/action[@name="sql_text"]/value)[1]','VARCHAR(MAX)') AS [sql_text],
[sw].[stat_update_dtl].[value]('(/event/action[@name="client_app_name"]/value)[1]','VARCHAR(MAX)') AS [client_app_name]
FROM [#stat_auto_update_event] AS [sw]
)
SELECT
DB_NAME([cte_stat].[database_id]) AS [database_name] ,
DATEADD(HOUR, DATEDIFF(HOUR, GETUTCDATE(), GETDATE()), [cte_stat].[event_time]) AS [event_time] ,
[cte_stat].[event_name] ,
OBJECT_NAME([cte_stat].[object_id],[cte_stat].[database_id]) AS object_name,
[cte_stat].[index_id] ,
[cte_stat].[job_type] ,
[cte_stat].[status] ,
[cte_stat].[sample_pct],
[cte_stat].[duration] ,
[cte_stat].[statistics_list],
[cte_stat].[sql_text],
[cte_stat].[client_app_name]
FROM cte_stat
ORDER BY [cte_stat].[event_time];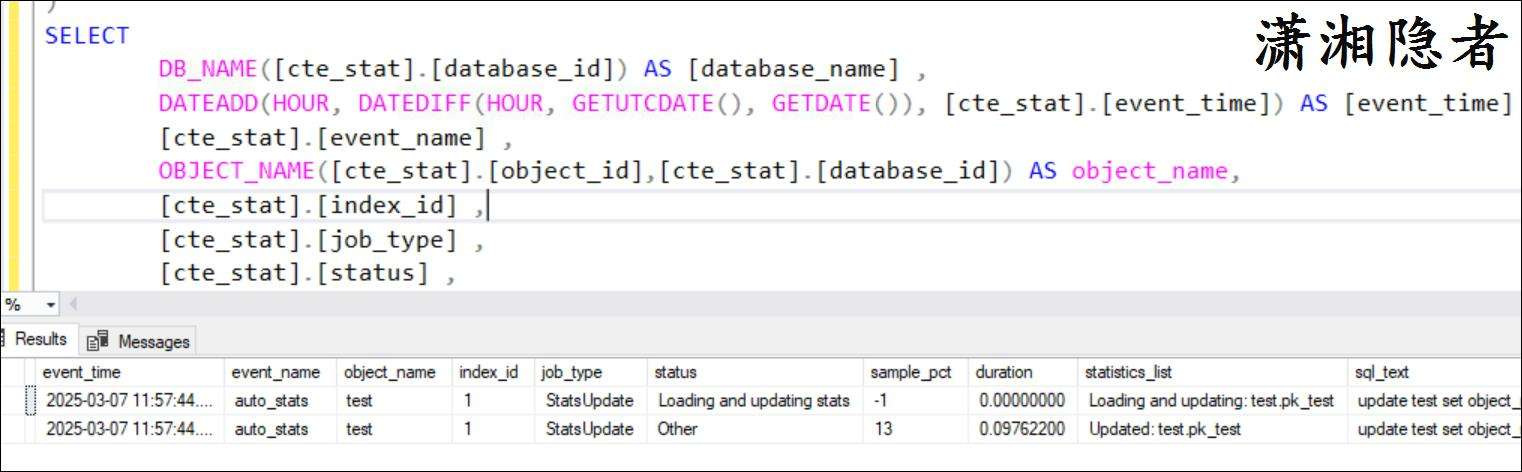
关于扩展信息捕获的aut_stat数据,status状态一般有下面一些值(状态),其中Loading stats without updating通常指的是加载统计信息而不进行更新操作
- Loading stats without updating
- Other
- Loading and updating stats
那么使用扩展事件追踪统计自动统计信息更新,有哪一些用途呢? 下面是我简单的一些总结,不仅仅局限于此,你也可以扩展其用途。
- 追踪分析自动统计信息的采样比例
- 分析SQL语句执行计划变化的原因。
- 为手工更新统计信息的频率与表对象提供数据支撑
- 研究自动统计信息更新触发的一些机制。