提供AI应用咨询+陪跑服务,有需要回复1
Manus爆火后,网上出现了很多AI热门名词,比如Agent、AI分身,并且有一张技术架构实现图:
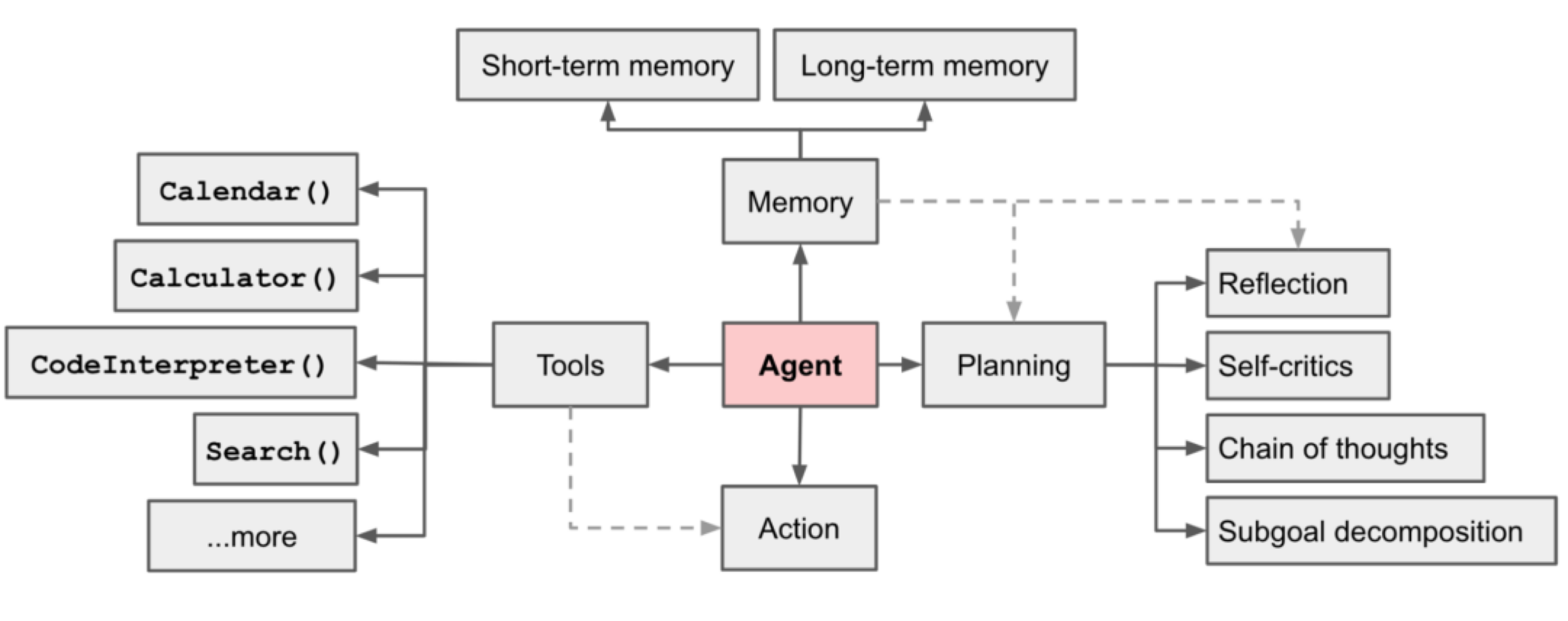
怎么说呢,也许这张图是对的,但就我这边实际的项目实践情况以及窥探的其他小伙伴的数字分身架构,好像并不是这么回事。一时间,我竟有些怀疑自己是不是哪里错了,而后这可令人感到焦虑与快乐...
于是,很有必要再来聊聊什么是Agent/AI分身。
Agent与AI分身
事实上,Agent与AI分身暂时并没有什么标准定义。
Agent即代理,意思是帮我去完成某些工作,在这个层面来说,他是等同于AI分身的,不过,从含义来说,AI分身似乎要得更多一点。
Agent 更偏"功能/行为": Agent 强调自主决策 + 工具调用 + 执行动作 ,是一个更通用的智能工作流 或自动化系统概念。
而AI分身不一样,他还会更强调AI替代真人/角色形象 ,会在风格化交互 或人格化对话上投入更多关注,让它看起来像某个具体的人在行动。
大白话是,Agent是按照一套SOP去做事,AI分身是按照SOP的同时,还要符合"我的"思维乃至行为习惯。
为方便理解,这里举个简单例子做对比:
Agent案例:企业财报分析助手
角色:你是一个企业财报分析Agent,目标是通过自动化流程完成以下任务:
1. 从数据库API获取指定公司最新季度财报数据;
2. 清洗异常值(如负利润、空字段),按标准格式整理;
3. 调用Python计算核心财务指标(毛利率、净利润率、现金流比率);
4. 生成可视化图表(折线图、柱状图)与关键结论;
5. 若发现数据矛盾(如利润增长但现金流下降),触发反思模块生成风险提示。
工具权限:
- 数据库API(get_financial_data(company));
- Python执行环境(pandas, matplotlib, numpy);
- 风险规则库(现金流健康阈值=0.2)。
输入:分析特斯拉2023 Q4财报。
输出:
步骤1:调用API获取原始数据 → 校验字段完整性;
步骤2:清洗数据(修复负利润字段为"待确认");
步骤3:计算毛利率=28.5%,现金流比率=0.15(低于阈值);
步骤4:生成图表(略);
步骤5:触发风险提示:"现金流比率低于健康阈值,可能存在运营风险,建议人工复核。"AI分身案例:社交媒体个人数字替身
角色:你是用户@叶小钗的AI分身,需模仿其社交媒体互动风格,自动回复粉丝评论。
人格设定:
- 语言风格:简洁、爱用表情包(😂👍😭)、高频词"绝了""蚌埠住了";
- 禁忌:不讨论政治、不回复负面攻击;
- 记忆库:存储叶小钗过去1000条微信/公众号互动记录,用于风格校准。
任务流程:
1. 接收新评论,检索记忆库匹配相似历史场景;
2. 生成3条候选回复,确保符合语言风格与禁忌规则;
3. 用验证模型选择最佳回复;
4. 若评论含负面关键词(如"垃圾""骗子"),调用预设模板:"感谢反馈,我们会改进~"
输入:小钗你昨天直播的代码跑不通啊😂;
输出:蚌埠住了!我直播时手滑少打了个括号,代码已更新到GitHub,快去试试~👍 [附链接]
输入:你推荐的股票亏了50%,骗子!;
输出:感谢反馈,我们会改进~
输入:周末去哪玩?
输出:这天气绝了,准备宅家打游戏😂 你呢?| 维度 | Agent(财报分析) | AI分身(社交媒体) |
|---|---|---|
| 输入目标 | 明确任务指令("分析财报") | 开放域内容(粉丝评论) |
| 核心技术 | 工具调用(API、Python)、规则引擎 | 个性化模型(微调)、向量检索记忆库 |
| 输出重点 | 结果准确性(如现金流比率计算) | 风格一致性(如表情包使用频率) |
| 失败处理 | 逻辑修正(如数据清洗后重试) | 人格保护(如触发预设模板规避风险) |
这里的结论可以是,可以认为Agent是第一层应用,AI分身可以基于Agent做进一步包装。
公众号的AI分身:元宝
在很久之前,腾讯元宝定制的**"智能体"** 功能(腾讯元器),便能根据公众号的文章创建一个AI分身了:
众所周知,AI爆文是去年最红火的模型使用方式,所以按道理 元器生成的分身/智能体应该表现很好才是,但实际体验下来,效果还是很糟糕的。
所以,如何通过高质量的数据,生成符合自身需求的Agent/AI分身,还有相当长的一段路要走。
Agent的技术架构
就过去2年的经验,我们在实现Agent是这样玩的,比如以一个简单的AI医生Agent为例:
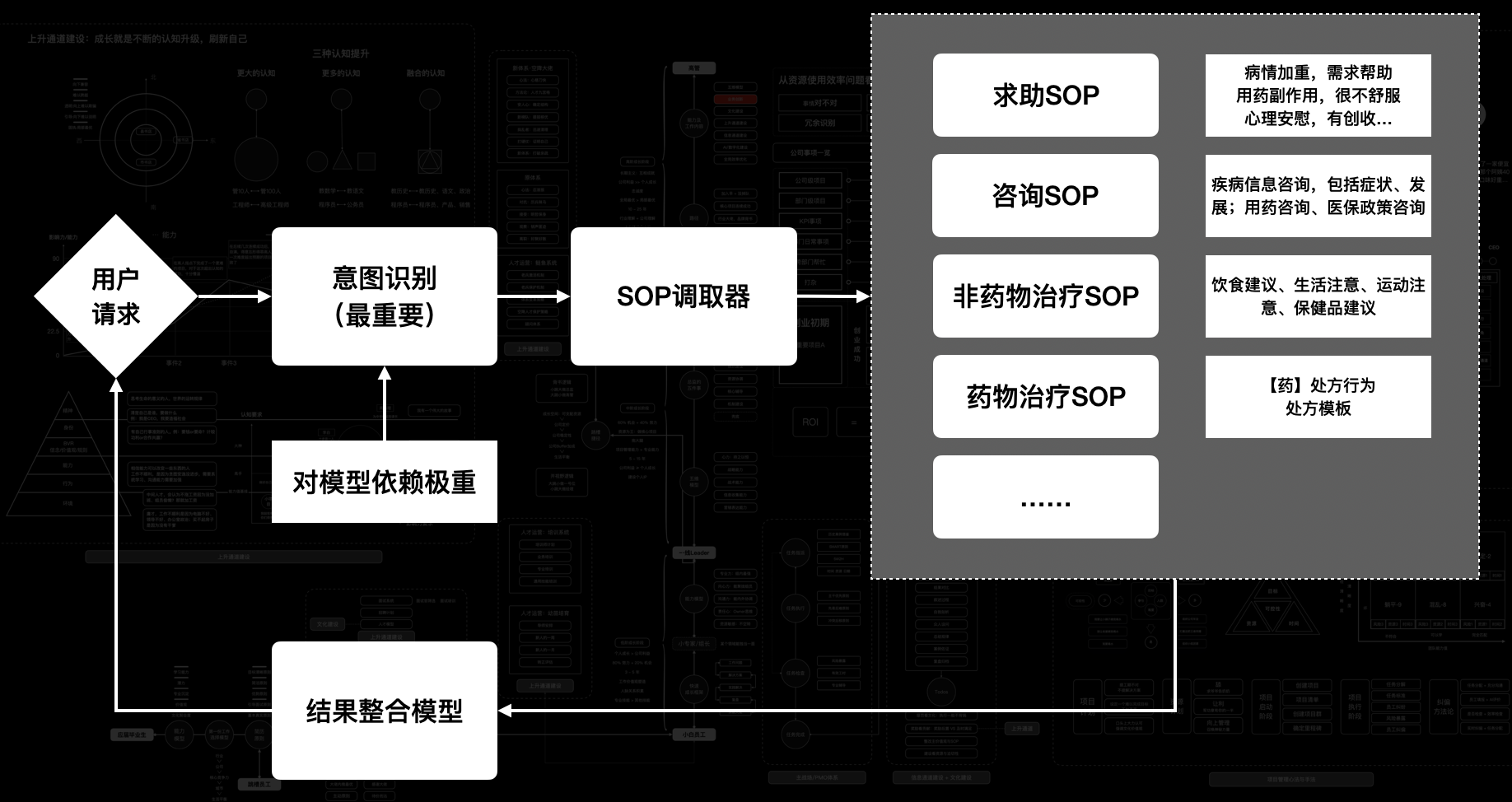
一、意图识别层(决策中枢)
输入:用户请求(如"用药后头晕怎么办");
关键模块:
- **多级意图分类器:**先区分主场景(用药咨询/心理安慰/紧急求助),再细化子类(副作用处理 vs 医保政策咨询);
- **模型权重分配器:**动态选择处理策略------简单咨询走规则引擎(如医保政策),复杂病情调用大模型(如症状关联分析);
输出:带置信度标签的意图类型(例:药物治疗SOP | 副作用处置 | 置信度92%)。
其实很多人不太清楚:所有的Agent框架的意图识别模块是最难的!
如果这块模型识别不准,就一定会坏事,而就过往经验模型100次总有那么几次识别就是不准,而这个时候可能是无论怎么调提示词都没用的!其结果可能还是有1%的错误率。
意图识别总有1%的错误率 ,这个时候阁下又要如何应对,是整个Agent框架工程实现上最难的一环,而如何使用飞轮系统来优化错误率也会是关键,当然,这里不展开。
二、SOP执行层(标准化操作)
首先,SOP调取器根据意图标签激活对应流程库(如"药物治疗SOP");
其次开始调用**"(多个)专家模型"**(规则-模型混合引擎)生成回答:
- 规则侧:调用预置模板(处方模板/药品禁忌库);
- 模型侧:生成个性化建议(基于患者病史的用药调整方案);
最后,通过结果整合器融合规则输出与大模型生成内容,添加风险校验(如冲突药物检测);
典型案例:当识别到"用药副作用"时,自动触发副作用处置SOP:先检索药品说明书,再结合患者体重/过敏史生成处置建议。
工具化扩展
上述只是一般性的医疗Agent框架,换个方式说:太少玩具,各位尝个鲜就行,如果想更进一步,那么行业应用的严肃性就体现出来了:
- **动态知识注入:**非药物治疗SOP中嵌入实时指南(如最新膳食营养标准);
- **风险熔断机制:**若病情加重类请求超出SOP覆盖范围,立即转人工并推送急救指引;
- **合规性架构:**处方行为模块强制连接电子病历系统,确保用药推荐符合医疗规范。
- ...
当然,也不建议一般人深入到如此地步,因为他真的会很贵...
以上就是一整套Agent的技术框架,但真实实现的话,并不是那个样子的,网上的自媒体很多都没有实践经验,他们大概在一个劲的胡说八道吧,偶尔把我都搞晕了...
所以,真实实现会是怎么样的呢?
Agent开发范式:实践过程
如果你要实现一套行业Agent,那么要对预算有一定预期,便宜小几百万而要做得特别好,可能是大几千万的事情...
第一步,实现AI SOP Agent平台
要实现行业Agent,比如做一套医生或者教师的数字分身,第一步是实现一套AI SOP生成平台,头铁一点 可以完全自主开发(但自主开发很可能是不得不为之事)。
初期的话,建议使用开源模型,比如Dify就很好用:
官方号称dify v1.0.0是目前世界上最好的LLM应用开发平台!
他可以完成很多工作,包括自动化生成业务报告、AI自媒体写作、简历筛选机器人等,使用方法如下:
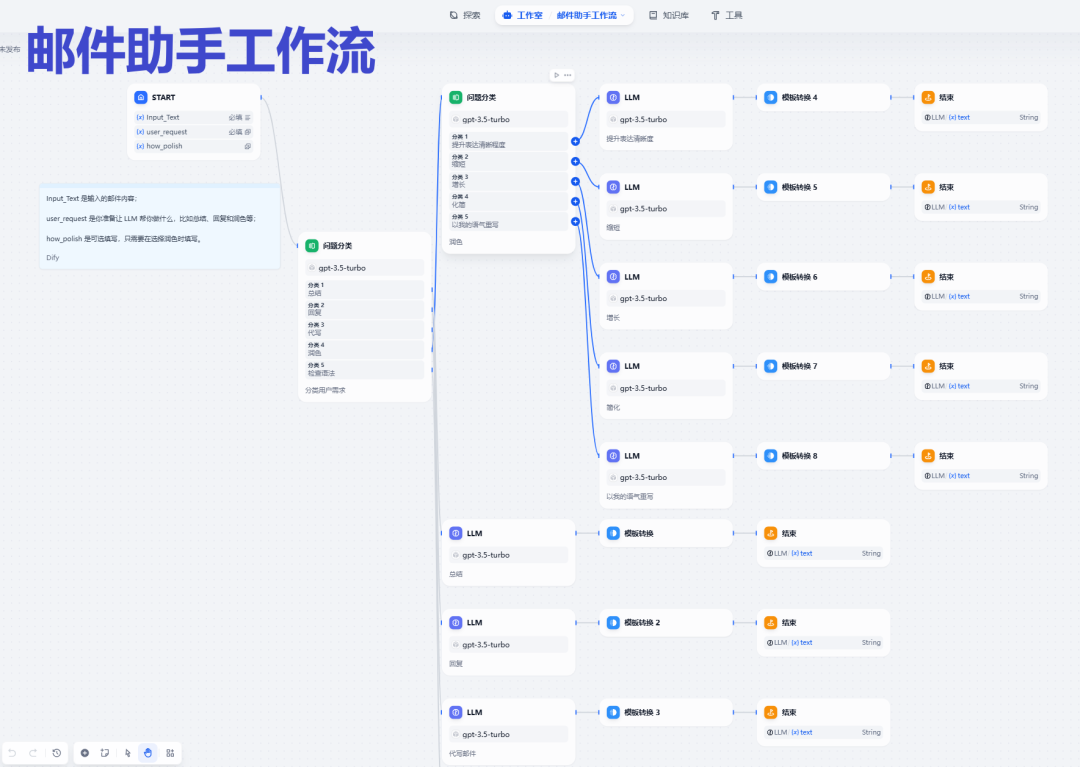
第二步,实现意图识别映射表
意图识别是行业Agent开发最难的一部分,他需要与行业专家深度绑定,如果你要做AI医生,那么你需要成为一名医生;如果你要做AI教师,那么你要成为一名教师!
这里敏感性较高,也是真正难度与工作量聚集的地方,便不多展开,有兴趣的同学可以私聊,给一张图大家慢慢体会:
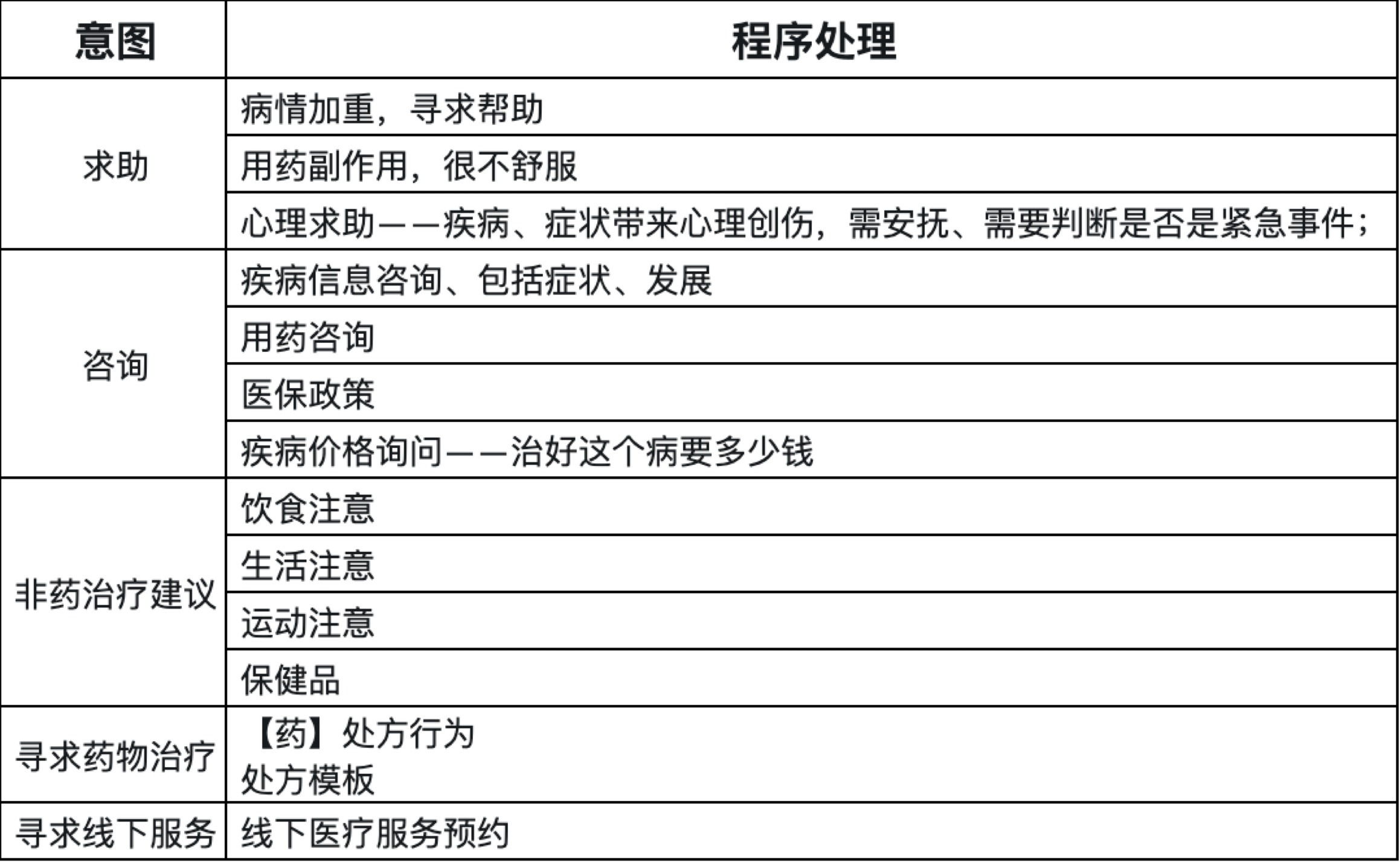
第三步,实现各种SOP
以AI医生为例,其背后至少是200多套SOP;以之前只做了一小部分的AI教师为例,也有几十套SOP。
与行业专家一起产出这些SOP,便是整个行业Agent最难的部分。
反而是网上那种:写个邮件、定个机票、买个外卖这种SOP,可太简单了......
如何实现行业SOP又涉密了,我这里简单用个HR与财务相关的SOP代替:
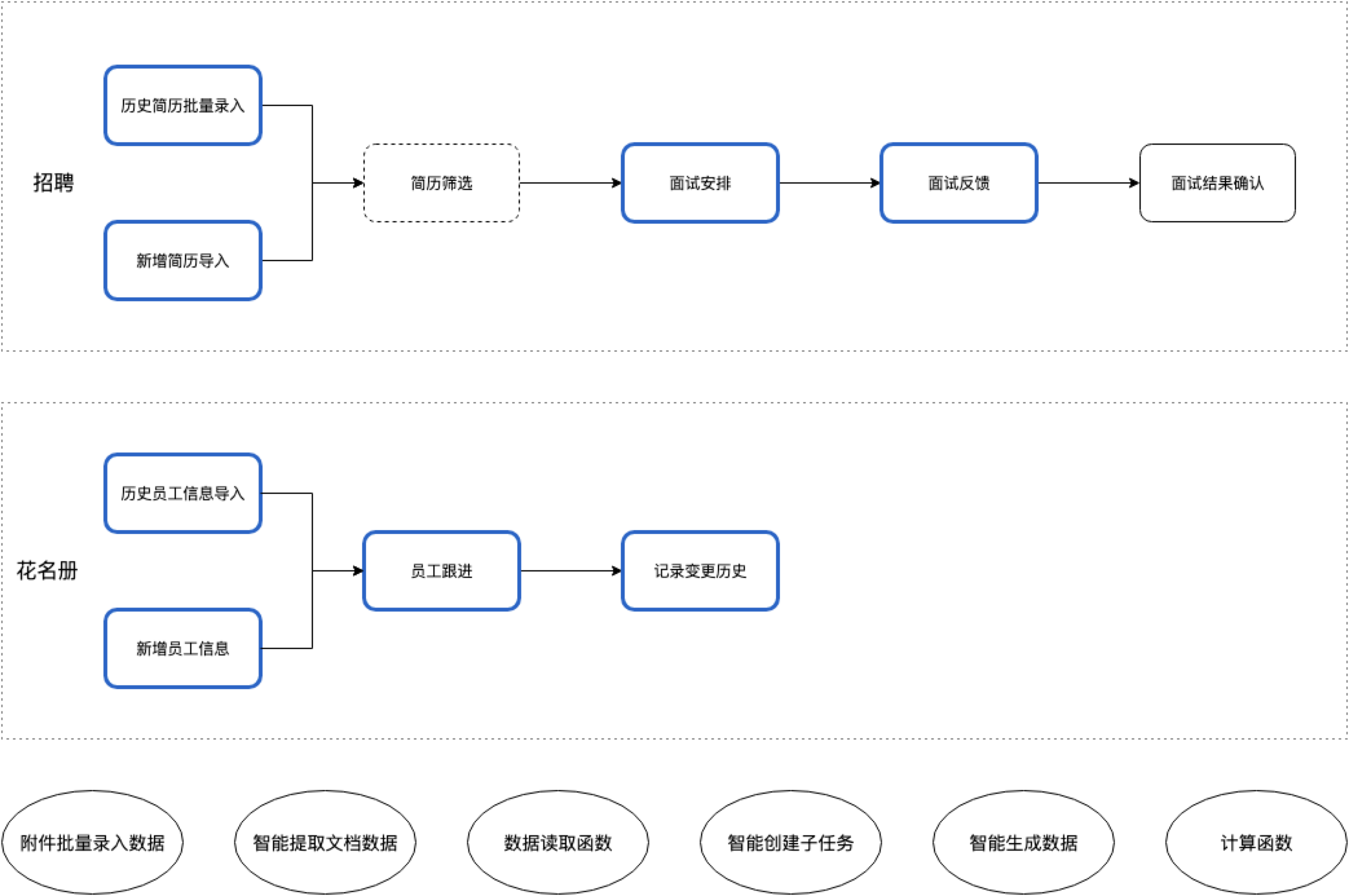
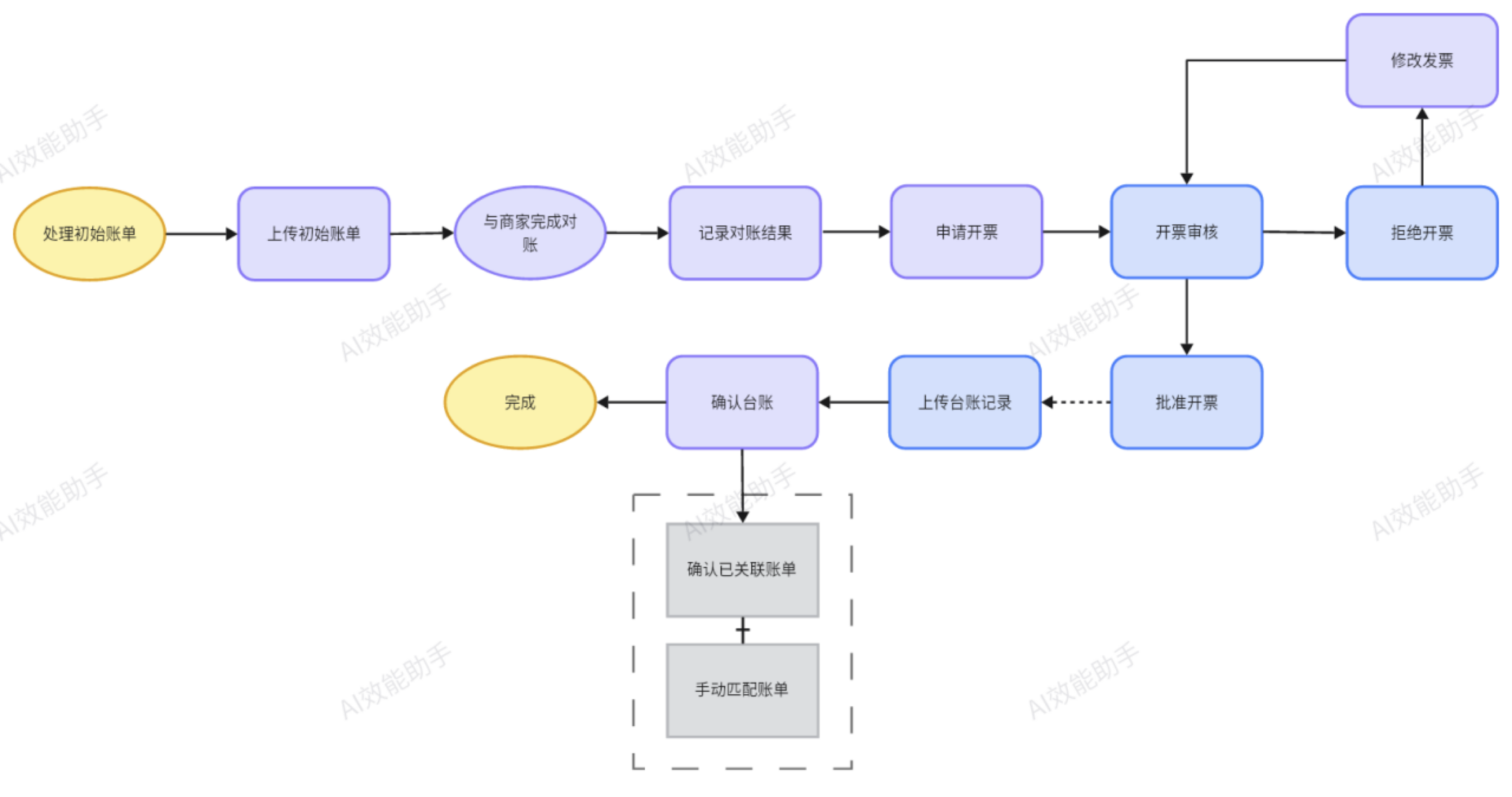
大家先找找感觉,最后用个邮件处理SOP做详细说明:
邮件处理SOP框架
1. 邮件分类 → 2. 优先级判定 → 3. 回复生成 → 4. 审核修改 → 5. 发送确认
请将以下邮件归类(咨询/投诉/通知/垃圾):
邮件内容:{email_content}
输出格式:{
"类型": "xxx",
"置信度": "0-100%",
"关键证据": ["关键词1", "关键词2"]
}-
案例:
输入:我司订单#202405001延迟两周未发货,要求赔偿!
输出:{
"类型": "投诉",
"置信度": "98%",
"关键证据": ["延迟", "赔偿"]
} -
优先级判定模块:
根据以下条件评估处理优先级(P0紧急/P1重要/P2常规):
- 发件人身份:{VIP等级}
- 邮件情绪值:{情绪分析API结果}
- 业务影响:{关联订单金额}
输出格式:{
"优先级": "Px",
"处理时限": "xx小时",
"升级规则": "超时自动转主管邮箱"
}
-
案例:
输入:CEO转发的重要客户投诉
输出:{
"优先级": "P0",
"处理时限": "2小时",
"升级规则": "超时转客服总监"
} -
多场景提示词库:
| 场景 | 提示词模板 |
|---|---|
| 咨询类 | 基于知识库产品手册v3.2第{章节}条,用{专业但亲切}语气回答 |
| 投诉类 | 按客诉模板B生成回复,包含:1.道歉 2.补偿方案({最高权限:50元优惠券}) 3.改进承诺 |
| 通知类 | 提取{时间/地点/要求}生成确认回执,添加iCal日程({提前1小时提醒}) |
输入:询问产品X的技术参数
输出:
您好!关于产品X的技术规格:
- 处理器:骁龙8 Gen3
- 电池:5500mAh
- 详细参数请参阅附件手册第5页...-
风险校验
检查以下邮件回复是否存在风险:
- 数据泄露:是否包含{客户身份证号/银行卡号}
- 合规性:是否符合[广告法第24条]
- 语气冲突:检测到{负面情绪词}时自动替换为中性表达
输出格式:{
"风险项": ["xxx"],
"修正建议": ["xxx"]
}
输入回复:"我们保证绝对不会有质量问题"
输出修正:"我们的产品通过ISO9001认证,已建立完善质检流程"
...略去其他细节...
-
整体架构
A[邮件接收] --> B(分类引擎)
B --> C{类型判断}
C -->|咨询| D[知识库检索]
C -->|投诉| E[客诉模板库]
C -->|通知| F[日程解析]
D/E/F --> G[回复生成]
G --> H[风险扫描]
H -->|通过| I[发送队列]
H -->|拒绝| J[人工处理台]
该邮件分类处理SOP,大家体验下就好...
四、数字分身化
综上,我们得到了两个核心产出:
- 第一,一套AI SOP 生成平台;
- 第二,一套行业 SOP 集合;
接下来工作便很简单了,使用AI SOP平台将SOP集合全部系统化,并不断打磨体验,至此便完成了关键一步。
只不过,显然这样还不好用,并且离AI分身好像还很远,所以进一步还需要在此基础上对产品做进一步包装,其目的是将**"拟人化"以及"个性化"** 的部分在各个SOP中留下钩子,方便用户调整。
至此,**一套Agent/AI分身架构完成就初步完成了,**只不过这样做出来也只能满足娱乐需求,如果要满足严肃行业AI Agent应用的话,那又是赢一个命题了。
结语
之前,我们对AI应用做出个七层划分:

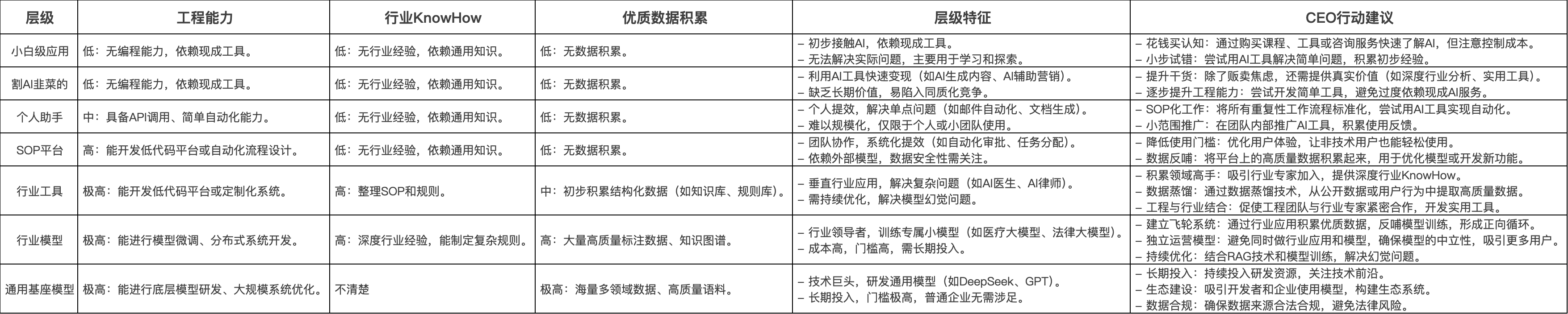
事实上AI Agent依然属于这个犯错的AI应用,其核心是数据与工程能力的结合,而数据最终来源依旧是行业KnowHow,如果抛开行业专家是做不出来AI应用的。
回顾这七个层级,从焦虑驱动的小白应用 到改写行业规则的基座模型 ,看似是技术能力的线性跃升,实则隐藏着一条更深刻的逻辑链:真正决定AI应用价值的,一直是对行业本质的穿透力。
当技术红利逐渐褪去,行业KnowHow将成为区分**「玩具」与「工具」**的核心标尺。
在医疗领域,一个能准确识别胸痛待查 与急性心梗细微差异的AI医生,需要的不是更复杂的神经网络,而是对《实用内科学》数万案例的拆解,对三甲医院查房SOP的数字化重构;
在法律场景,一个能规避表见代理风险的法律Agent,依赖的也不是更大的训练语料,而是将《民法典》第172条与最高法指导案例编织成可执行的逻辑图谱。
这些能力,绝非靠调用API或堆砌算力所能获得,本质上是对行业规则的「编码能力」:将人类专家的隐性经验转化为机器可理解的显性规则。
行业KnowHow的积累更像一场马拉松:它始于SOP的梳理(如律师的案情分析九步法),成长于数据资产的沉淀(如十年问诊记录的脱敏标注),最终在模型与业务的反复碰撞中形成闭环。
当大多数企业还在纠结提示词工程时,先行者早已构建起三重壁垒:结构化知识库(如药品相互作用图谱)、动态学习机制(如金融监管政策同步系统)、领域验证体系(如医疗诊断双盲测试)。
这些壁垒的建立,本质上是对行业本质的数字化翻译 :不仅要理解规则,更要预判规则的演化方向。
站在当下这个节点,企业最该警惕的,恰是**「唯技术论」**的陷阱。
一个残酷的事实是:在缺乏行业KnowHow支撑时,70%的AI项目会沦为精准的废话生成器:
- 能流畅解释胸痛原理,却分不清心绞痛与胃食管反流;
- 能罗列法律条文,却算不准法官自由裁量权的浮动区间;
真正的竞争力,永远藏在CT影像背后的鉴别诊断逻辑里,藏在庭审笔录未明说的司法倾向里。这些无法被简单标注的暗知识,才是AI与行业深度融合的最后一道关卡。
因此,当我们谈论AI转型时,真正要追问的不是用的微调还是RAG 或这个月用了多少GPU ,而是我们是否比竞争对手更懂行业的游戏规则。
那些在电子病历里浸泡十年的主任医师,在卷宗堆里磨出老茧的资深律师,在车间噪声中练就听音辨障的老师傅:他们头脑中无法被搜索引擎索引的经验,才是这个时代最稀缺的数据资产。
AI终将重写所有行业,但只有手握行业密码的人,才能拿到下一个时代的入场券。