目标
使用 Matplotlib 进行基本的数据可视化。
学习内容
绘制折线图
绘制散点图
绘制柱状图
代码示例
-
导入必要的库
import matplotlib.pyplot as pltimport numpy as npimport pandas as pd
-
创建示例数据集
创建示例数据集data = { '月份': ['1月', '2月', '3月', '4月', '5月', '6月'], '销售额': [120, 150, 130, 160, 140, 170], '成本': [80, 90, 100, 110, 120, 130]}df = pd.DataFrame(data)print(f"示例数据集: \n{df}")
-
绘制折线图
绘制单条折线图
# 绘制单条折线图plt.plot(df['月份'], df['销售额'], marker='o', linestyle='-', color='b', label='销售额')plt.xlabel('月份')plt.ylabel('销售额 (万元)')plt.title('每月销售额折线图')plt.legend()plt.grid(True)plt.show()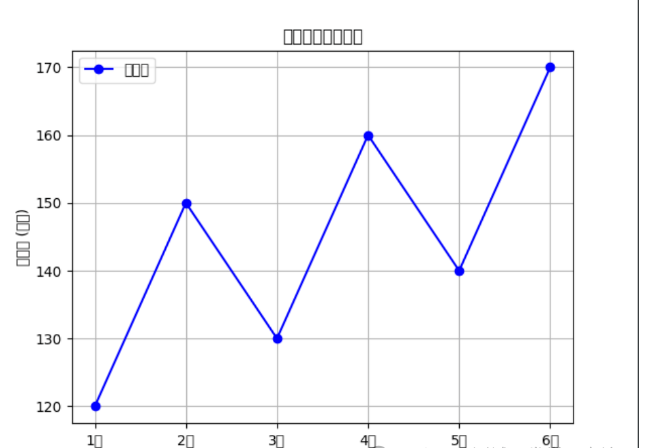
绘制多条折线图
# 绘制多条折线图plt.plot(df['月份'], df['销售额'], marker='o', linestyle='-', color='b', label='销售额')plt.plot(df['月份'], df['成本'], marker='s', linestyle='--', color='r', label='成本')plt.xlabel('月份')plt.ylabel('金额 (万元)')plt.title('每月销售额与成本折线图')plt.legend()plt.grid(True)plt.show()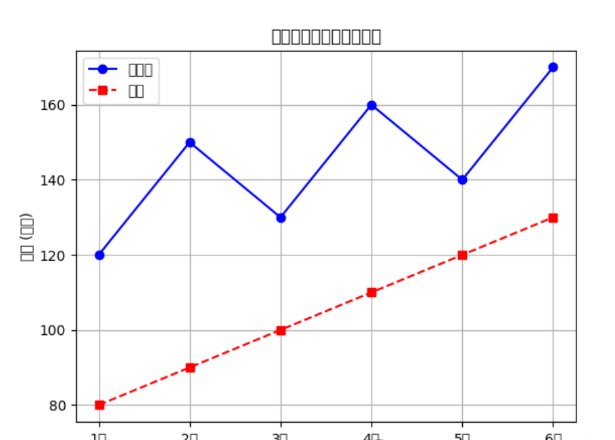
- 绘制散点图
绘制单个散点图
# 绘制单个散点图plt.scatter(df['销售额'], df['成本'], color='g', label='销售额 vs 成本')plt.xlabel('销售额 (万元)')plt.ylabel('成本 (万元)')plt.title('销售额与成本散点图')plt.legend()plt.grid(True)plt.show()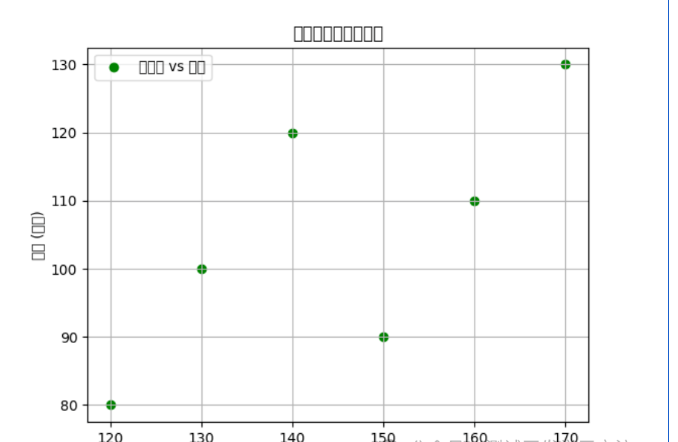
绘制带颜色和大小变化的散点图
# 绘制带颜色和大小变化的散点图sizes = df['销售额'] / 10 # 散点大小colors = np.random.rand(len(df)) # 随机颜色plt.scatter(df['销售额'], df['成本'], s=sizes, c=colors, alpha=0.5, label='销售额 vs 成本')plt.xlabel('销售额 (万元)')plt.ylabel('成本 (万元)')plt.title('销售额与成本散点图')plt.legend()plt.grid(True)plt.show()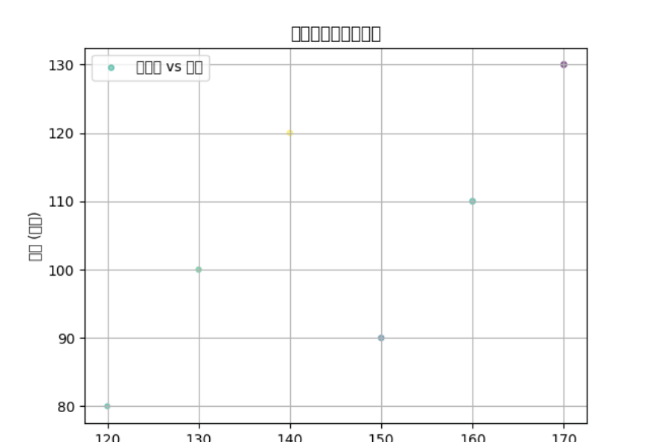
- 绘制柱状图
绘制单个柱状图
# 绘制单个柱状图plt.bar(df['月份'], df['销售额'], color='b', label='销售额')plt.xlabel('月份')plt.ylabel('销售额 (万元)')plt.title('每月销售额柱状图')plt.legend()plt.grid(True)plt.show()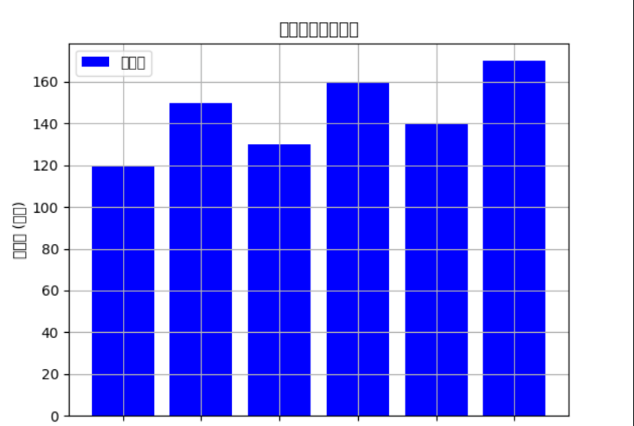
绘制堆叠柱状图
# 绘制堆叠柱状图bar_width = 0.35index = np.arange(len(df['月份']))plt.bar(index, df['销售额'], bar_width, color='b', label='销售额')plt.bar(index + bar_width, df['成本'], bar_width, color='r', label='成本')plt.xlabel('月份')plt.ylabel('金额 (万元)')plt.title('每月销售额与成本堆叠柱状图')plt.xticks(index + bar_width / 2, df['月份'])plt.legend()plt.grid(True)plt.show()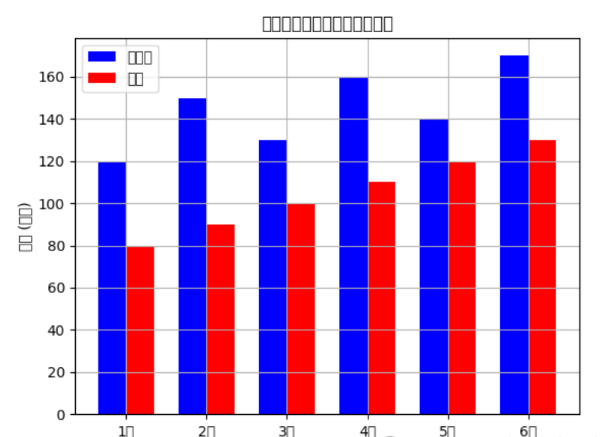
绘制并排柱状图
# 绘制并排柱状图bar_width = 0.35index = np.arange(len(df['月份']))plt.bar(index, df['销售额'], bar_width, color='b', label='销售额')plt.bar(index + bar_width, df['成本'], bar_width, color='r', label='成本')plt.xlabel('月份')plt.ylabel('金额 (万元)')plt.title('每月销售额与成本并排柱状图')plt.xticks(index + bar_width / 2, df['月份'])plt.legend()plt.grid(True)plt.show()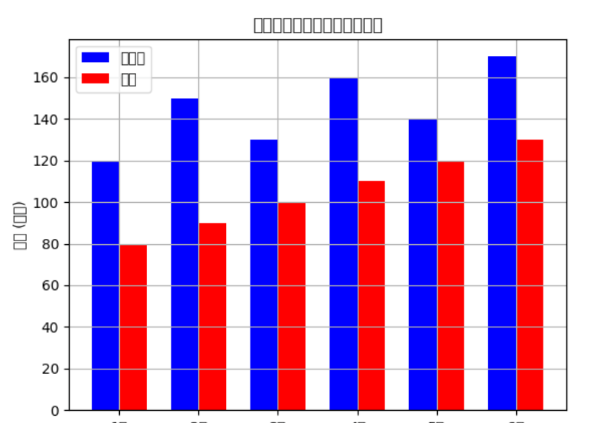
实践

绘制一个数据集的折线图和柱状图。
# 导入必要的库import matplotlib.pyplot as pltimport pandas as pd# 创建示例数据集data = { '月份': ['1月', '2月', '3月', '4月', '5月', '6月'], '销售额': [120, 150, 130, 160, 140, 170], '成本': [80, 90, 100, 110, 120, 130]}df = pd.DataFrame(data)print(f"示例数据集: \n{df}")# 绘制折线图plt.plot(df['月份'], df['销售额'], marker='o', linestyle='-', color='b', label='销售额')plt.plot(df['月份'], df['成本'], marker='s', linestyle='--', color='r', label='成本')plt.xlabel('月份')plt.ylabel('金额 (万元)')plt.title('每月销售额与成本折线图')plt.legend()plt.grid(True)plt.show()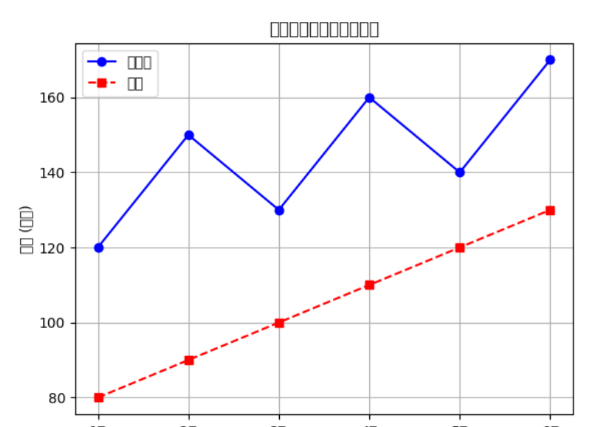
# 绘制柱状图bar_width = 0.35index = np.arange(len(df['月份']))plt.bar(index, df['销售额'], bar_width, color='b', label='销售额')plt.bar(index + bar_width, df['成本'], bar_width, color='r', label='成本')plt.xlabel('月份')plt.ylabel('金额 (万元)')plt.title('每月销售额与成本并排柱状图')plt.xticks(index + bar_width / 2, df['月份'])plt.legend()plt.grid(True)plt.show()
通过以上,你应该已经掌握了如何使用 Matplotlib 进行基本的数据可视化,包括绘制折线图、散点图和柱状图
数据聚合和分组
目标
学会使用 Pandas 进行数据聚合和分组。
学习内容
groupby 方法
聚合函数(sum, mean, max, min)
代码示例
-
导入 Pandas 库
import pandas as pd
-
创建示例数据集
创建示例数据集data = { '姓名': ['张三', '李四', '王五', '张三', '赵六', '李四'], '部门': ['销售部', '市场部', '技术部', '销售部', '财务部', '市场部'], '销售额': [120, 150, 130, 160, 140, 170], '成本': [80, 90, 100, 110, 120, 130]}df = pd.DataFrame(data)print(f"示例数据集: \n{df}")
-
使用 groupby 方法
按单一列分组
# 按 '部门' 列分组grouped_by_department = df.groupby('部门')print(f"按 '部门' 列分组的结果: \n{grouped_by_department}")获取分组后的对象
# 获取分组后的对象for department, group in grouped_by_department: print(f"部门: {department}") print(f"数据: \n{group}\n")- 聚合函数
计算每组的均值
# 计算每组的均值mean_sales_by_department = grouped_by_department['销售额'].mean()print(f"按 '部门' 列分组后,每组的销售额均值: \n{mean_sales_by_department}")计算每组的总和
# 计算每组的总和sum_sales_by_department = grouped_by_department['销售额'].sum()print(f"按 '部门' 列分组后,每组的销售额总和: \n{sum_sales_by_department}")计算每组的最大值
# 计算每组的最大值max_sales_by_department = grouped_by_department['销售额'].max()print(f"按 '部门' 列分组后,每组的销售额最大值: \n{max_sales_by_department}")计算每组的最小值
# 计算每组的最小值min_sales_by_department = grouped_by_department['销售额'].min()print(f"按 '部门' 列分组后,每组的销售额最小值: \n{min_sales_by_department}")- 多列聚合
计算多列的均值
# 计算多列的均值mean_by_department = grouped_by_department[['销售额', '成本']].mean()print(f"按 '部门' 列分组后,每组的销售额和成本均值: \n{mean_by_department}")计算多列的总和
# 计算多列的总和sum_by_department = grouped_by_department[['销售额', '成本']].sum()print(f"按 '部门' 列分组后,每组的销售额和成本总和: \n{sum_by_department}")- 多级分组
按多列分组
# 按 '部门' 和 '姓名' 列分组grouped_by_department_name = df.groupby(['部门', '姓名'])mean_sales_by_department_name = grouped_by_department_name['销售额'].mean()print(f"按 '部门' 和 '姓名' 列分组后,每组的销售额均值: \n{mean_sales_by_department_name}")实践
对一个数据集按某一列进行分组,并计算每组的均值。
# 导入 Pandas 库import pandas as pd# 创建示例数据集data = { '姓名': ['张三', '李四', '王五', '张三', '赵六', '李四'], '部门': ['销售部', '市场部', '技术部', '销售部', '财务部', '市场部'], '销售额': [120, 150, 130, 160, 140, 170], '成本': [80, 90, 100, 110, 120, 130]}df = pd.DataFrame(data)print(f"示例数据集: \n{df}")# 按 '部门' 列分组grouped_by_department = df.groupby('部门')# 计算每组的均值mean_sales_by_department = grouped_by_department['销售额'].mean()print(f"按 '部门' 列分组后,每组的销售额均值: \n{mean_sales_by_department}")# 计算多列的均值mean_by_department = grouped_by_department[['销售额', '成本']].mean()print(f"按 '部门' 列分组后,每组的销售额和成本均值: \n{mean_by_department}")