我自己的原文哦~https://blog.51cto.com/whaosoft/11720657
#DRAMA
首个基于Mamba的端到端运动规划器(新加坡国立)
运动规划是一项具有挑战性的任务,在高度动态和复杂的环境中生成安全可行的轨迹,形成自动驾驶汽车的核心能力。在本文中,我们提出了DRAMA,这是第一个基于Mamba的自动驾驶端到端运动规划器。DRAMA融合了相机、特征空间中的LiDAR鸟瞰图图像以及自我状态信息,以生成一系列未来的自我轨迹。与传统的基于变换器的方法不同,DRAMA能够实现计算强度较低的注意力复杂度,从而显示出处理日益复杂的场景的潜力。DRAMA利用我们的Mamba融合模块,高效地融合了相机和激光雷达的功能。此外,我们引入了一个Mamba Transformer解码器,可以提高整体规划性能。该模块普遍适用于任何基于Transformer的模型,特别是对于具有长序列输入的任务。我们还引入了一种新的特征状态丢弃,在不增加训练和推理时间的情况下提高了规划器的鲁棒性。大量的实验结果表明,与基线Transfuser相比,DRAMA在NAVSIM数据集上实现了更高的精度,参数少,计算成本低。
总结来说,本文的主要贡献如下:
- 我们介绍了一种名为DRAMA的Mamba嵌入式编码器-解码器架构,其中包括一个编码器,该编码器通过Mamba Fusion模块有效地融合了相机和LiDAR BEV图像的特征,解码器通过Mamba Transformer解码器生成确定性轨迹,该解码器普遍适用于任何基于Transformer的模型。
- 我们在DRAMA中引入了多尺度卷积和特征状态丢弃模块,并采用了差异化的丢弃策略。这些模块通过在多个尺度上提取场景信息并减轻噪声传感器输入和缺失自我状态的影响,提高了模型的有效性和鲁棒性。
- 使用NAVSIM规划基准对提出的模块和总体架构进行了评估。实验结果表明,与基线相比,我们的模型在使用较少的模型参数和较低的训练成本的情况下实现了显著的性能提升。
相关工作回顾Motion Planning for Autonomous Driving
自动驾驶的运动规划一直是机器人领域的一个长期研究课题。从传统的角度来看,运动规划是行为规划或决策的下游任务,它负责生成可驾驶和舒适的轨迹,保证安全。传统的运动规划通常依赖于几何和优化,可大致分为基于图、基于采样和基于优化的方法。基于图的方法,如A*和Hybrid A*,在离散化车辆配置空间后搜索最小成本路径。基于采样的方法在状态或动作空间内创建轨迹样本,以发现可行的路径。相比之下,基于优化的方法采用EM算法和凸优化等技术来确定满足指定约束的最佳轨迹。这些方法通常涉及大量的手动设计和优化,并且通常在动态或变化的环境中具有通用性。
随着专门用于运动规划的公共驾驶数据集和基准的发布,基于学习的轨迹规划得到了显著加速。目前,nuPlan是运动规划中最大的带注释规划数据集和基准。基于nuPlan和OpenScene数据集,最近开发了一个名为NAVSIM的数据集,以解决开环和闭环评估指标之间的不一致问题,并作为这些评估范式之间的中间地带。
基于这些开源数据集,7分析了数据驱动的运动规划方法中的误解,并提出了一种简单而高效的规划器,该规划器在nuPlan排行榜上排名第一。然而该规划器针对nuPlan指标进行了高度优化,当转移到其他场景时,其性能会下降。这些现有的基于学习的方法往往过度强调度量性能,往往以牺牲计算效率为代价。由于复杂的架构设计或用于轨迹评分和细化的在线模拟,其中许多方法由于无法实现的计算负担而变得枯燥乏味。为了提高计算强度和性能,我们提出了DRAMA,这是一种Mamba嵌入式编解码器流水线,旨在实现高效和卓越的规划性能。
State Space Models
为了减轻状态空间模型(SSM)在建模长期依赖关系时的大量计算和内存需求,10提出了结构化状态空间序列模型(S4),该模型将SSM中的A矩阵修改为具有低秩校正的条件矩阵。这种增强的模型Mamba在图像处理、语言处理和其他领域显示出巨大的应用潜力。6 从理论上证明了SSM与半可分矩阵的等价性。此外,引入了状态空间二元性(SSD)来增强原始的Mamba,该设计将多头注意力(MHA)融入SSM以优化框架,从而使改进版本(Mamba-2)表现出更大的稳定性和更高的性能。受到Mamba家族先前成功的启发,我们将最新的架构Mamba-2应用于端到端的运动规划。据我们所知,这是Mamba-2在自动驾驶领域的首次应用。为清楚和简洁起见,除非另有说明,否则所有后续提及曼巴的内容均适用于Mamba-2。
DRAMA方法详解
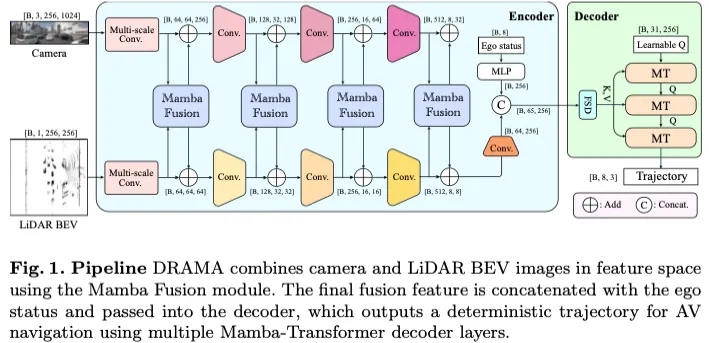
我们介绍了基于Mamba的端到端运动规划框架DRAMA,该框架使用卷积神经网络(CNN)和Mamba对相机和LiDAR BEV图像的特征进行编码和融合。解码器采用我们提出的Mamba Transformer解码器层对最终轨迹进行解码。在接下来的部分中,我们将详细探讨我们设计的四个模块:Mamba融合块、Mamba Transformer解码器层、多尺度卷积和特征状态dropout。
Mamba Fusion Block and Mamba-Transformer
Mamba Preliminaries:从连续系统导出的结构化状态空间序列模型(S4)利用1-D输入序列或函数x(t)和中间隐藏状态h(t)来产生最终输出y(t)。中间隐藏状态h(t)和输入x(t)用于通过投影矩阵A、B和C计算y(t)。
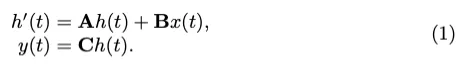
该系统应用可学习步长和零阶保持将连续系统转换为离散系统。因此,方程式(1)可以重新表述如下:

通过数学归纳,方程式(2)的最终输出可以改写如下:
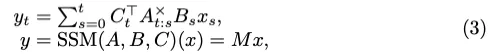
矩阵M定义如下:
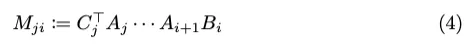
如方程(4)所述,下三角SSM变换矩阵M也满足N-顺序半可分(SSS)表示的定义。因此,SSM和SSS表示是等效的。
因此,SSS的结构化矩阵乘法可以有效地用于涉及SSM的计算。为了实现这种方法,分别使用结构化掩蔽注意力(SMA)方形模式算法和SMA线性模式算法将参数矩阵M分解为对角块和低秩块。此外,采用多头注意力(MHA)来提高模型性能。
曼巴融合:为了捕捉不同模态的多尺度背景,之前的基线在Transformer中实现了自我关注层,以融合和利用激光雷达和相机的特征。首先,对两种模态的特征进行转换和连接,生成组合特征I。然后,I将三个不同的投影矩阵、和相乘,得到Q、K和V。融合模块的最终输出可以通过以下方式计算:
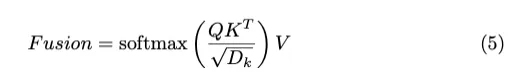
计算复杂度的总体训练由以下公式给出:
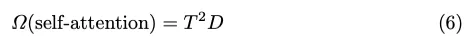
我们建议使用Mamba作为特征融合的自我关注的替代方案,因为它具有高效的矩阵计算能力。我们坚持实施融合方法,如图2所示。与4不同,我们使用Mamba-2而不是Transformer来处理融合的特征。由于传统变压器自关注中没有复杂的计算,Mamba的计算成本大大降低。假设head维度P等于状态维度D,即P=D,则训练成本由下式给出:

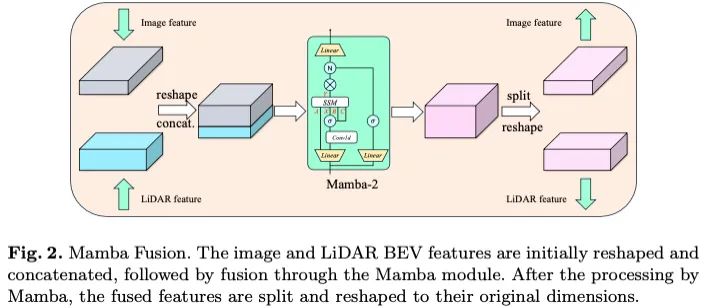
在我们的曼巴融合模块中,我们设置了T E320和P E16,理论上与自我关注相比,在融合过程中训练成本降低了约20倍。
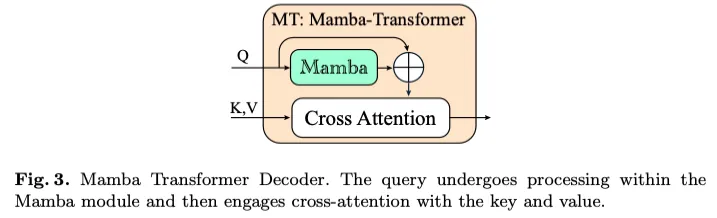
Mamba Transformer解码器:如图(3)所示,我们将Mamba和Transformer架构相结合,开发了新颖的Mamba Transformers(MT)解码器。最初,可学习的查询被传递到机器翻译的Mamba组件中,该组件的功能类似于self-att。由于与Mamba的交叉注意力仍在探索中,我们采用Transformer交叉注意力机制来处理来自Mamba的查询以及来自FSD模块的键和值。
Multi-scale Convolution
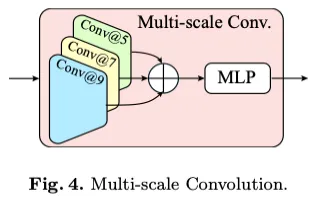
为了捕获多尺度图像特征,我们采用了多卷积设计,如图(4)所示,其中图像通过三个不同核大小的卷积层进行处理,分别为-5、7和9。这些卷积层的输出被组合在一起,并由多层感知器(MLP)层进一步编码,以增强模型的感知能力。
Feature State Dropout
由于硬件限制和机载传感器中的噪声,对周围环境的观察和感知(例如位置或速度)可能不准确,可能无法完全反映真实情况。此外,当导航模块的驾驶命令缺失时,或者在复杂的交通条件下导航时,即使在没有明确指导的情况下,模型也必须深入理解和推理场景和周围的代理,这一点至关重要。先前的研究表明,屏蔽某些图像和车辆状态特征可以提高自我监督任务和运动规划的整体性能。为了解决这些问题并基于这些见解,我们从两种模态和自我状态实现了图像特征融合的特征状态丢弃,如图5所示。最初,要编码的特征被添加了一个可学习的位置嵌入,然后是差异化的dropout来掩盖一些特征。
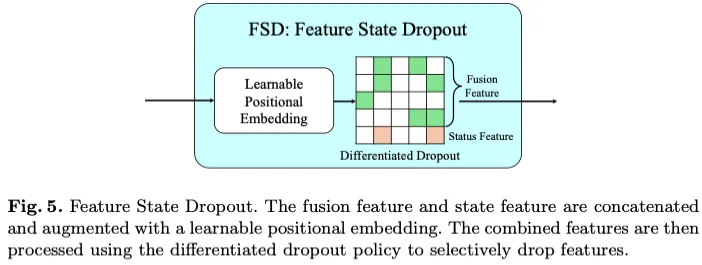
我们在DRAMA中采用了一种差异化的辍学策略,该策略对融合和自我状态特征应用了不同的辍学率。为融合特征分配相对较低的丢失率,以保持其完整性。该措施旨在避免融合感知信息的过度丢失,从而降低整体性能。
实验结果
定量结果
如表1所示,根据Transfuser(T)基线对拟议模块的评估显示,各种指标都有显著改善。整合多尺度卷积(MSC)可以提高PDM得分,从0.835增加到0.843,突出了其在捕获多尺度特征以提高整体模型性能方面的有效性。曼巴融合(MF)的加入进一步将PDM评分提高到0.848,自我进步(EP)从0.782显著提高到0.798,表明融合方式优越。特征状态丢失(FSD)显示了EP的最高单个模块增强,达到0.802,PDM得分为0.848,证明了其在减轻传感器输入不良方面的作用。此外,Mamba Transformer(MT)模块的PDM得分为0.844,碰撞时间(TTC)有了显著改善,突显了其强大的自我关注机制。在没有MSC的DRAMA中,这些模块的组合,即T+MF+FSD+MT,导致PDM得分为0.853,在所有指标上都有持续的改进,整个DRAMA模型达到了最高的PDM得分0.855,证实了综合方法的有效性。
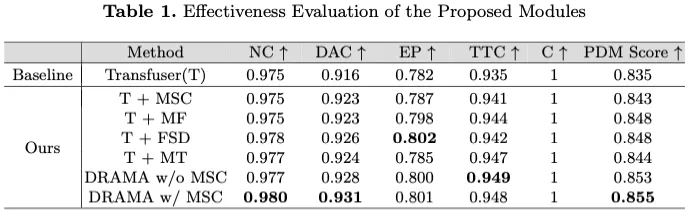
表2显示了不同特征状态丢失率对模型性能的影响,表明改变状态和融合特征的丢失率可以提高模型的鲁棒性和准确性。基线Transfuser(T)得分为0.835。引入融合丢失率为0.1的FSD将得分提高到0.842,状态丢失率为0.5的FSD得分更高,为0.844,这表明该模型受益于处理缺失的状态特征。状态丢失率为0.5和融合丢失率为0.1的组合达到了最高得分0.848,表明这两种特征类型之间的平衡丢失率优化了模型性能。

表3全面比较了各种方法的培训和验证性能,强调了拟议模块的效率。基线Transfuser(T)的总参数大小为56 MB,训练和验证速度分别为每秒4.61次迭代(it/s)和9.73次迭代/秒。引入多尺度卷积(MSC)模块将训练速度略微降低到3.77it/s,同时保持类似的验证速度,这表明在增强的特征提取和计算成本之间进行了权衡。相反,Mamba Fusion(MF)模块将总参数大小显著减小到49.9 MB,并将训练速度提高到4.92 it/s,验证速度提高到9.94 it/s,展示了其在模态融合方面的卓越效率。
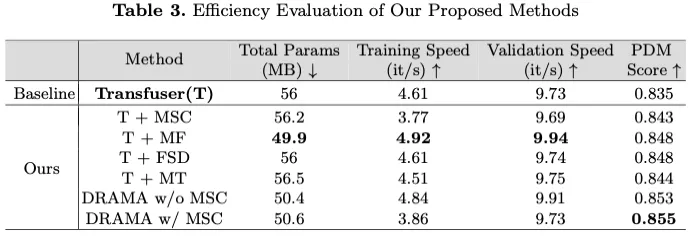
特征状态dropout(FSD)的集成保持了与基线相当的速度,在不增加计算开销的情况下证明了其效率。这一发现突显了FSD模块的通用性和轻质性,可以有效地将其整合到各种型号中以提高其性能。
Mamba Transformer(MT)模块在性能和速度方面实现了平衡的提高,尽管它将训练速度略微降低到4.51it/s。这是由于我们的输入长度T31小于状态维度D128,从而将训练成本从Ω()增加到Ω()。没有MSC的DRAMA组合架构通过将总参数减少到50.4MB,训练和验证速度分别为4.84it/s和9.91it/s,进一步提高了效率。最后,包含所有模块的完整DRAMA模型保持了50.6 MB的参数大小,但训练速度略有下降,降至3.86 it/s。尽管如此,它还是获得了最高的PDM分数,验证了集成方法的整体有效性和效率。
定性结果
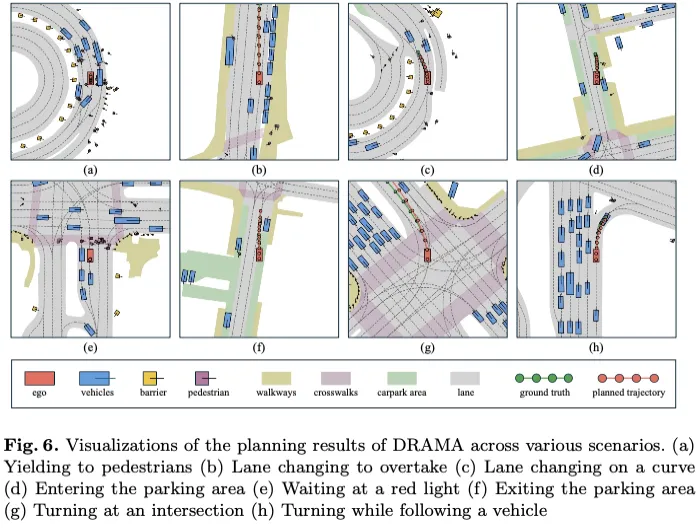
我们展示了图6所示的8个代表性场景,其中我们的DRAMA模型展示了安全准确的端到端规划结果。在子图(a)和(e)中,我们的规划师准确地发出命令,保持静止,为过街的行人让路,而不考虑是否存在明确的交通灯控制。在子图(a)中,行人在没有红绿灯的弯道过马路,而在子图中(e),行人在有红绿灯和人行横道的情况下过马路。这些场景表明,我们的规划师能够识别交通信号灯和潜在危险,做出安全的规划决策。在子图(b)和(c)中,我们的规划师根据前方车辆的低速发出变道命令。这表明我们的规划师能够生成快速复杂的规划操作,以提高驾驶效率。子图(d)和(f)展示了我们的规划师在低速场景中的熟练程度,特别是在进出停车位方面。这些例子突出了规划师的精确控制和决策能力,确保了平稳高效的停车操作。最后,子图(g)和(h)展示了我们的模型在执行右转和左转时的规划能力。这些例子突出了规划者在精确和安全地处理各种交通场景方面的适应性,展示了其对复杂驾驶操作的全面理解。
讨论和未来工作
由于NAVSIM排行榜的临时关闭和比较解决方案的可用性有限,我们采用了公共测试数据集来评估基线和我们提出的方法。基线在NAVSIM排行榜上的PDM得分为0.8483;然而,当在公共数据集上进行测试时,它下降到0.8347。我们表现最佳的方法获得了0.8548的PDM得分,这在公共测试数据集上的基线中令人惊讶。所提出的多尺度卷积有助于DRAMA的性能,尽管不影响验证速度,但牺牲了训练效率。
鉴于所提出的多尺度卷积训练速度的降低,我们将探索其他强大而高效的视觉编码器。此外,我们还将考虑在现实场景中测试我们提出的计划器。
结论
这项工作提出了一种名为DRAMA的基于Mamba的端到端运动规划器,这是Mamba在自动驾驶运动规划方面的第一项研究。我们提出的Mamba融合和Mamba Transformer解码器有效地提高了整体规划性能,Mamba Transformers为传统Transformer解码器提供了一种可行的替代方案,特别是在处理长序列时。此外,我们引入的特征状态丢弃提高了规划器的鲁棒性,可以集成到其他基于注意力的模型中,在不增加训练或推理时间的情况下提高性能。我们使用公共规划数据集NAVSIM对DRAMA进行了评估,结果表明,我们的方法在参数少、计算成本低的情况下明显优于基线Transfer。
#InstantSplat
英伟达&厦大等开源训练几秒钟,涨点62%
题目:InstantSplat: Sparse-view SfM-free Gaussian Splatting in Seconds
作者:Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, Yue Wang
机构:德克萨斯大学奥斯汀分校、英伟达研究院、厦门大学、佐治亚理工学院、斯坦福大学和南加州大学
原文链接:https://arxiv.org/html/2403.20309v2
源码链接:https://instantsplat.github.io/
内容速览
- 作者介绍了InstantSplat ,它提供了一个高效且可靠的框架,用于处理稀疏视图数据。
- 作者研究了3D-GS的局限性 ,针对SfM预处理和复杂的ADC的关键问题,InstantSplat将显式的3D-GS与基于学习的MVS的几何先验相结合。
- 作者的实验在包括MVImgNet、Tanks and Temples、MipNeRF360以及野外互联网数据的多个数据集 上进行,实验结果表明作者的方法不仅将优化时间从NoPe-NeRF的33分钟减少到作者的S版本仅需10.4秒,而且在结构相似性指数(SSIM)上实现了62%的改进,并在姿态度量上取得了显著提升。

图1.新视角合成比较(无结构从运动预处理的稀疏视图)。作者介绍了InstantSplat,一个高效的框架,用于从未加约束的稀疏视图输入中快速合成新视角。该方法结合了从多视图立体(MVS)派生的密集几何先验,基于梯度的联合优化框架能够在几秒钟内重建3D场景并合成新视角,适用于大规模场景。此外,作者的方法显著提高了以前未加约束方法的姿态估计精度和渲染质量。
摘要
在3D计算机视觉领域,从稀疏图像集合中进行新视角合成(NVS)技术已取得显著进展,但其依赖于使用结构从运动(SfM)进行精确的相机参数初始估计。例如,最近开发的高斯溅射技术严重依赖于SfM派生点和姿态的准确性。然而,SfM过程既耗时又经常在稀疏视图场景中不可靠,其中匹配特征稀缺,导致累积误差和跨数据集的有限泛化能力。在本研究中,作者引入了一个新颖高效的框架,以增强从稀疏视图图像的稳健NVS。作者的框架InstantSplat,集成了多视图立体(MVS)预测和基于点的表示,以在几秒内从稀疏视图数据构建大规模场景的3D高斯。
- 引言
新视角合成(Novel-view synthesis, NVS)一直是计算机视觉领域长期追求的目标。它涉及到在任意视点渲染在训练期间未见过的图像。然而,以"随意"的方式捕获场景,使用有限的观察视图(称为稀疏视图)和低成本传感器(如智能手机),则更具挑战性。因此,采用一种能直接从少量未校准图像重建3D场景的高效框架对于扩展3D内容创作、数字孪生构建、节能机器人和增强现实应用至关重要。
尽管最近的进步已经显示出在减少所需训练视图数量方面的显著进展,但稀疏视图合成(Sparse-view synthesis, SVS)中的一个重大挑战仍未解决:稀疏输入数据通常缺乏足够的重叠,阻碍了像COLMAP这样的结构从运动(Structure from Motion, SfM)流程估计准确的相机参数。先前在SVS领域的研究通常假设即使在稀疏视图场景中也能精确地获得相机姿态,这是通过利用密集视图进行预计算实现的,但这种假设很少有效。此外,SfM步骤中的累积误差可能传播到后续步骤,导致次优的重建和视图合成。另一系列研究探索了无姿态设置,如NeRFmm、Nope-NeRF和CF3DGS。它们也假设了密集的数据覆盖,通常来源于视频序列。这样的密集数据需要一个广泛的优化过程,通常需要数小时来优化单个3D场景。
最近,3D高斯溅射(3D Gaussian Splatting, 3D-GS)被引入作为一种表达性强且高效的场景表示技术,促进了高速和高保真的训练和渲染。该方法利用一组各向异性的3D高斯,这些高斯在COLMAP派生的点上初始化。优化过程由多视图光度损失驱动,并由自适应密度控制(Adaptive Density Control, ADC)补充,这是一种启发式规则,控制3D原语的创建或删除。然而,由于COLMAP创建的点的数量不同,ADC参数需要针对每个场景进行调整,并且显著影响3D-GS的性能。如表1所示,仅仅降低密集化阈值以促进产生更多的原语就显著提高了"自行车场景"的重建质量。因此,尽管3D-GS在视图合成性能上取得了最先进的成果,但由于视图稀疏性和对COLMAP的依赖,3D-GS仍然存在问题。
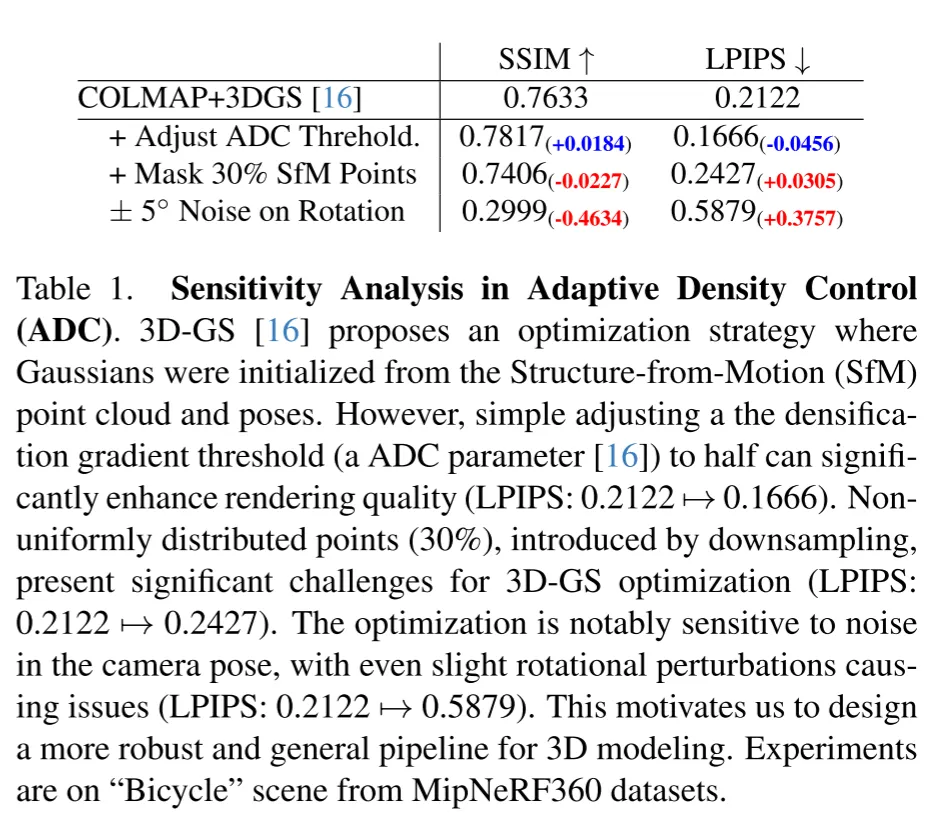
表1.自适应密度控制(ADC)的敏感性分析。3D-GS提出了一种优化策略,其中高斯是从结构从运动(SfM)点云和姿态初始化的。然而,简单地将密集化梯度阈值(一个ADC参数)调整到一半可以显著提高渲染质量(LPIPS: 0.2122 → 0.1666)。通过下采样引入的非均匀分布点(30%),对3D-GS优化提出了重大挑战(LPIPS: 0.2122 → 0.2427)。优化过程对相机姿态的噪声非常敏感,即使是轻微的旋转扰动也会引起问题(LPIPS: 0.2122 → 0.5879)。这激发了作者设计一个更健壮和通用的3D建模流程。
- 方法
首先,作者讨论将多视图立体(MVS)与3D高斯溅射(3D-GS)整合到一起的总体流程,以解决依赖于结构从运动(SfM)的稀疏视图重建和训练效率问题(第3.1节)。接着,作者提出一个高效的、感知置信度的点下采样器,用以解决场景过度参数化问题(第3.2节)。作者同样展示一个基于梯度的联合优化框架,该框架依赖于光度损失以自监督的方式对齐高斯和相机参数(第3.3节)。InstantSplat的概览见图2。
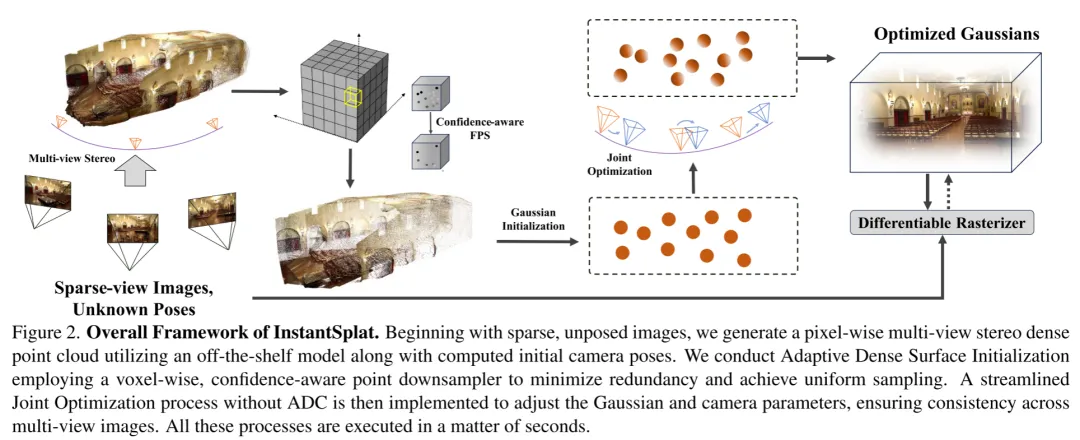
图2.InstantSplat的整体框架。从稀疏、未加姿势的图像开始,作者使用现成的模型生成像素级的多视图立体密集点云,并计算初始相机姿态。作者采用自适应密集表面初始化,使用基于体素的、感知置信度的点下采样器来最小化冗余并实现均匀采样。然后实施了一个简化的无ADC的联合优化过程,以调整高斯和相机参数,确保多视图图像的一致性。所有这些过程都在几秒钟内执行。
3.1 多视图立体与高斯溅射的结合
3D高斯溅射(3D-GS)是一种显式的3D场景表示方法,它使用一组3D高斯来模拟场景。一个3D高斯由均值向量 和协方差矩阵
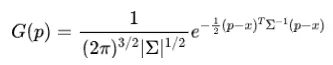
为了表示与视图方向相关的属性,每个高斯附着有球谐系数,并通过对颜色 的计算来渲染,其中 是3D点到相机的距离, 是颜色值。颜色的计算通过球谐基函数 完成,并且颜色
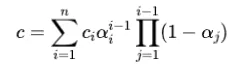
其中 是从第 个高斯的球谐系数计算出的颜色, 是通过学习到的每个高斯的不透明度参数乘以2D高斯得到的。2D协方差矩阵是通过将3D协方差矩阵投影到相机坐标系来计算的。3D协方差矩阵被分解为缩放矩阵和旋转矩阵。总结来说,3D-GS使用一组3D高斯 来表示场景,每个3D高斯 的特征由位置 ,一系列球谐系数 ,不透明度 ,旋转 和缩放
尽管3D-GS在渲染上是高效的,但基于点的3D-GS面临着由于COLMAP的稀疏SfM点或随机初始化的高斯带来的优化问题。SfM在匹配特征稀缺时通常失败,特别是在处理稀疏视图数据时。此外,从COLMAP到GS优化的顺序处理流程缺乏一个纠错机制来解决累积误差,这就需要在GS中仔细选择超参数。例如,自适应密度控制(Adaptive Density Control, ADC)需要一个复杂的策略来确定何时、何地以及如何生成新的高斯,作者在表1中展示了一个例子。
为了解决与自适应密度控制(ADC)相关的敏感性问题,作者寻求一种能够缓解ADC敏感性问题的密集立体点云。然而,传统的立体匹配流程效率较低,并且比SfM过程需要更多的时间。幸运的是,基于深度学习的密集立体框架的发展已经将预测与比例相关的深度图的时间缩短到毫秒级,尽管它们仍然假设已知的相机参数。最近,DUSt3R仅接受两张图像作为输入,并直接生成每个像素的点图和置信度图作为输出。然后可以利用非常高效的后处理优化来解决每视图像素到3D映射和增量相对姿态的问题。具体来说,DUSt3R的训练目标是基于两个输入视图的未投影和归一化的点图的回归:
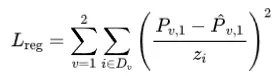
其中视图 , 和 分别是预测值和真实值。为了处理预测值和真实值之间的比例模糊性,DUSt3R通过比例因子 和 归一化预测和真实点图,这些因子简单地表示所有有效点到原点的平均距离,记为 。然后,像素级的置信度
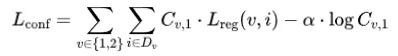
其中
恢复相机参数
作者从像素格到点图的1:1映射中获得,作者可以建立从2D到相机坐标系的映射。作者首先基于Weiszfeld算法解决一个简单的优化问题,以计算每台相机的焦距:
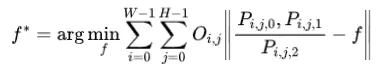
其中 和 表示中心化的像素索引。假设与COLMAP用于单场景捕获的单相机设置类似,作者提出通过所有训练视图的平均值来稳定估计的焦距: 。结果 表示在后续流程中使用的计算出的焦距。相对变换
对全局对齐的姿态进行配对
DUSt3R最初以图像对为输入,如果从场景捕获超过两个视图,则需要后处理来对齐比例。根本原因是预测的点图在其自己的标准化尺度内,并且每个独立计算的相对姿态的不对齐导致显著的尺度变化,从而产生不准确的相机姿态。与DUSt3R类似,作者首先为所有N个输入视图构建一个完整的连通图 ,其中顶点 和每条边 表示图像 和 之间的共享视觉内容。为了将最初预测的点图 转换为全局对齐的点图 ,作者更新点图、变换矩阵和比例因子:对于完整的图,任何图像对 ,点图 和置信度图 。为了清晰起见,让作者定义 和 , 和 。边的变换矩阵 的优化、比例因子 和点图
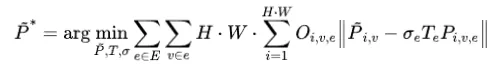
这里,作者稍微滥用了符号,如果 ,则使用 表示 。对于给定的对 ,相同的刚性变换 应该对齐两个点图 和 与世界坐标点图 和 ,因为根据定义 和 都是在相同的坐标框架中表达的。为了避免平凡最优解 ,DUSt3R强制执行
对齐点云后,作者开始整合过程,通过将每个点作为原语初始化3D高斯。然而,由于像素级预测,密集的立体点云高度过度参数化,伴随着次优的姿态估计。如表4的第一行所示,作者观察到从像素级点图初始化的相机姿态与COLMAP处理所有密集序列时产生的姿态有显著差异。这表明简单的整合会产生次优结果。
3.2 自适应密集表面点初始化
作者的目标是从像素级预测开始减少点的冗余。具体来说,作者提出利用前一步骤中得到的初始场景尺度和置信度图
自适应体素网格划分
给定 个点,作者动态地将空间划分为 个自适应网格。每个网格,或体素 ,是根据每个维度( )的场景范围被划分为 个相等的段来定义的,从而产生自适应网格边界。每个点
感知置信度的点云下采样
在每个体素 内,对一组点

图3.普通下采样前后的可视化。基于预测的置信度图直接下采样会导致缺失块,即使将场景划分为3x3网格。这一结果激发了开发更具适应性的采样策略。
作者首先在每个体素 中随机选择一个点
对于 到
其中 是体素中最终返回的点集, 表示欧几里得距离, 是体素
3.3 联合优化对齐
作者基于采样的点云初始化高斯,采用3D-GS中描述的启发式规则。为了缓解由噪声点云和不准确相机姿态引起的问题,作者引入了一个自校正机制。这个机制通过使用光度损失,适用于相机和高斯参数的梯度优化。
自我监督下的梯度优化
给定多个视图和一个由一组高斯 表示的粗糙3D模型,以及初始相机姿态 ,作者探索使用梯度下降来最小化真实像素和模型渲染之间的残差。具体来说,作者对所有高斯参数和相机参数进行联合优化。这种调整允许 在目标视图位置
在测试视图上对齐相机姿态
4.实验
4.1 实验设置
数据集
实验遵循先前无姿态方法的实验设置,作者使用了"坦克和庙宇"数据集中的所有八个场景,并使用不同数量的视图。此外,作者还从MVImgNet数据集中提取了七个户外场景,包括轿车、SUV、自行车、椅子、梯子、长凳和桌子等多样化的场景类型。作者还首次尝试在MipNeRF360数据集上进行评估,并使用12个训练视图。作者也在野外数据上测试了InstantSplat,包括从Sora视频中提取的帧、使用NASA网站上的Perseverance漫游者的导航立体相机数据,以及从DL3DV10K数据集中随机抽取的三个训练视图。作者将发布代码和数据。
训练/测试数据集划分
作者从每个数据集中均匀采样24幅图像,用于训练和评估,以覆盖整个数据集。测试图像(12幅,不包括首尾图像)对于所有设置都是均匀选择的,而N个训练图像是从剩余的12幅图像中均匀选择的,用于稀疏视图训练。具体来说,作者从MVImgNet和坦克与庙宇数据集中均匀采样了24幅图像,而MipNeRF360数据集的采样是从前48帧中进行的,因为它是从不同高度捕获的完整360度旋转。作者变化稀疏视图的数量N从3到12,以评估所有采用的算法。
度量标准
作者在基准数据集上评估了两项任务:新视角合成和相机姿态估计。对于新视角合成,作者使用了包括峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像块相似性(LPIPS)在内的标准评估指标。作者报告了相机旋转和平移误差,重点关注绝对轨迹误差(ATE)和相对姿态误差(RPE)。
基线比较
在无姿态方法上,作者的比较包括Nope-NeRF和CF-3DGS,它们都支持单目深度图和真实相机内参。作者还考虑了NeRFmm,它涉及NeRF和所有相机参数的联合优化。此外,作者将作者的方法与使用COLMAP进行预先计算相机参数的3D-GS和FSGS进行了比较。
实现细节
作者的实现利用了PyTorch框架。对于作者的"粗到细"(Ours-S)方法,优化迭代设置为200次,而对于作者的"特大"(Ours-XL)方法,迭代次数为1000次,以实现质量和训练效率的平衡。作者使用DUSt3R以512的分辨率预测多视图立体深度图。为了公平比较,作者在一块Nvidia A100 GPU上进行实验。
4.2 实验结果
在"坦克和庙宇"数据集上,作者对新视角合成和姿态估计任务进行了定量和定性评估。评估结果总结在表2和图4中。Nope-NeRF利用多层感知器(MLPs)在渲染质量和姿态估计精度方面取得了有希望的结果。然而,它倾向于产生过度模糊的图像(见图4的第三列),这归因于其几何场的严格约束,并显示出对单个场景的长时间训练和推理时间(约3秒每帧)用于渲染一张图像。CF-3DGS采用高斯溅射,并集成了局部和全局优化阶段,具有自适应密度控制和不透明度重置策略,在新视点上渲染时容易出现伪影,这是由于复杂的优化过程加上错误的位姿估计所致,如图4所示。此外,Nope-NeRF和CF-3DGS都假设已知且准确的焦距。NeRFmm,旨在同时优化相机参数和辐射场,由于简单的联合优化固有挑战,倾向于产生次优结果。位姿指标揭示了由于稀疏观测和估计不准确的位姿而产生的伪影,如表2所示。这个问题对于依赖于类似于SLAM的密集视频序列的CF-3DGS和Nope-NeRF特别有害,因此在将密集视频帧采样为稀疏多视图图像时遇到困难。相反,作者的方法以MVS场景结构初始化,并采用基于梯度的联合优化过程,提供了增强的鲁棒性和更优越的性能。在MVImgnet数据集上使用三个训练图像进行的额外实验,以及在MipNeRF360数据集上使用12个训练视图的实验,展示在表3中。值得注意的是,InstantSplat在所有评估的数据集和视觉指标中一致优于所有基线。作者的方法不仅将优化时间从33分钟(NoPe-NeRF)减少到仅10.4秒(Ours-S),而且在结构相似性指数(SSIM)上提高了62%,在位姿指标上也有显著提升。
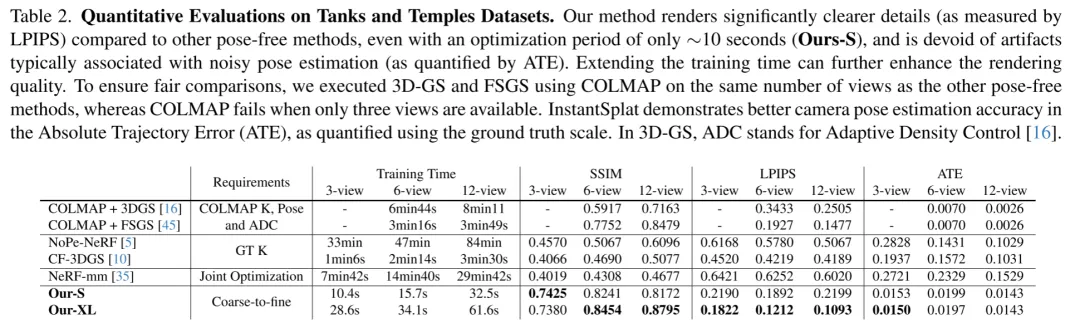
表2.在"坦克和庙宇"数据集上的定量评估。作者的方法在渲染更清晰的细节方面(通过LPIPS测量)与其他无姿态方法相比有显著优势,即使优化时间仅为大约10秒(作者的-S),并且没有通常与嘈杂的姿态估计相关的伪影(通过ATE量化)。延长训练时间可以进一步提高渲染质量。为了确保公平比较,作者在与其他无姿态方法相同的视图数量上执行了3D-GS和FSGS使用COLMAP,而COLMAP在只有三个视图可用时失败。InstantSplat在绝对轨迹误差(ATE)方面展示了更好的相机姿态估计精度,使用地面真实尺度进行量化。| ©【计算机视觉life】编译

图4.InstantSplat与各种无姿态基线方法之间的视觉比较。InstantSplat在只有三个训练图像的情况下,在"坦克和庙宇"数据集和MVImgNet数据集上实现了忠实的3D重建,并渲染了新视角。在最具挑战性的MipNeRF360数据集上,该数据集以不同高度捕获了360度视图------这是以前无姿态文献中未探索过的场景------InstantSplat仍然能够合理地重建场景表示,从而实现新视角的渲染。作者省略了与3D-GS和FSGS的比较,因为它们需要COLMAP来获取SfM姿态,而在这些设置中COLMAP失败了。| ©【计算机视觉life】编译
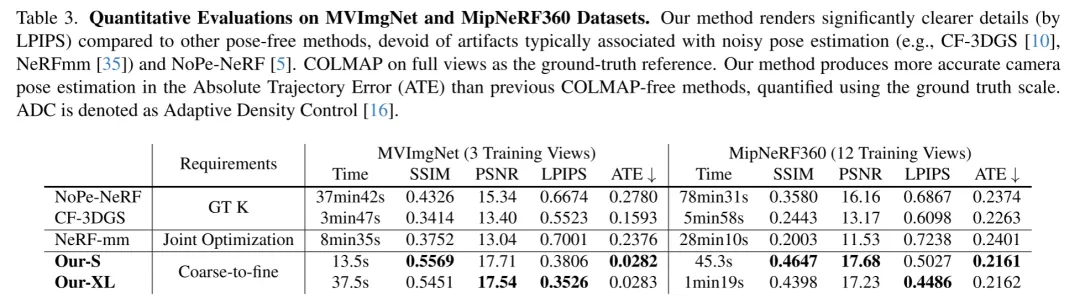
表3.在MVImgNet和MipNeRF360数据集上的定量评估。作者的方法在渲染更清晰的细节方面(通过LPIPS测量)与其他无姿态方法相比有显著优势,没有通常与嘈杂的姿态估计相关的伪影(例如CF-3DGS、NeRFmm和NoPe-NeRF)。使用完整视图的COLMAP作为真实参考。作者的方法在绝对轨迹误差(ATE)方面产生了比先前无需COLMAP的方法更准确的相机姿态估计,使用地面真实尺度进行量化。
4.3 消融分析
为了验证作者的设计方案,作者进行了消融实验,从使用不可微分的结构从运动(SfM)辅以具有自适应密度控制的高斯溅射,转变到采用多视图立体(MVS)结合自适应表面点下采样和联合优化,以实现高效和稳健的稀疏视图3D建模。实验在教堂场景上进行,使用来自400个密集视图的COLMAP位姿作为真值,除非另有说明。
- 问题1: 多视图立体预测的准确性如何?
- 问题2: 焦距平均的效果如何?
- 问题3: 自适应密集表面初始化在减少冗余的同时是否保持了重建精度?
- 问题4: 联合优化对于实现准确渲染是否必要?
- 问题5: 使用稀疏视图图像的InstantSplat是否能够达到之前使用密集视图配置的方法的渲染质量?
作者评估了从MVS点云图派生的相机位姿的准确性,如第3.1节所详述。正如表4的第一行和第四行所示,MVS初始化的场景几何有相当大的提升空间。
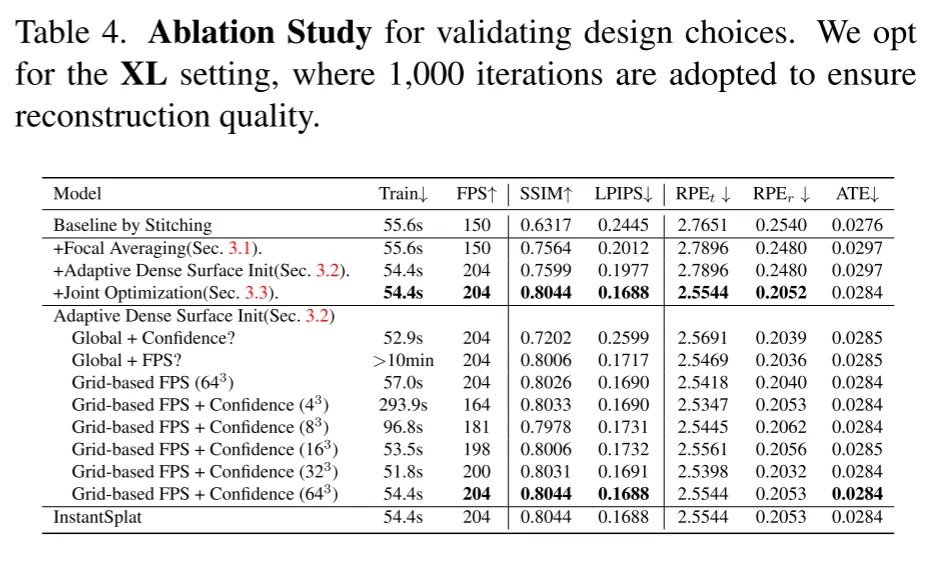
表4.消融研究,验证设计选择。作者选择XL设置,在1000次迭代中采用,以确保重建质量
从所有图像聚合焦距为优化3D表示提供了稳定的基础,如表4的第二行所示,视图合成质量得到了显著提升。
采用自适应密集表面初始化,使用并行基于网格的最远点采样(FPS),考虑到置信水平,能够有效降低冗余同时保持精度(参见表4的第三行)。作者实验中选择了643个网格。
联合优化,使用粗糙的3D模型和光度误差,可以进一步增强渲染和姿态精度。
- 结论
作者介绍了InstantSplat,这是一个旨在在几秒钟内从稀疏视图、无姿态的图像重建场景的框架。作者的方法利用多视图立体(MVS)的能力进行粗糙的场景初始化,并提出了一种基于梯度的自监督联合优化机制,用于高斯属性和相机参数的优化。与之前表现最佳的无姿态方法相比,作者已经将所需的视图数量从数百个减少到仅有几个,从而仅使用最少的图像和无姿态视图实现了大规模3D建模。
然而,InstantSplat受限于MVS对全局对齐点云的需求,在处理超过数百个图像的场景时存在限制。通过渐进式对齐来解决这一局限性将是作者未来工作的一部分。
#自动驾驶行车泊车的功能~方案
自动驾驶的两大基础任务:行车&泊车
说起智能驾驶最核心的功能,无疑是行车和泊车。行车功能几乎占据了智能驾驶99%的时间,日常使用最多的自适应巡航控制(ACC)、车道居中控制(LCC)、自动变道辅助(ALC)、高速领航驾驶辅助(NOA)等等都属于行车的范畴。泊车功能相对简单一些,主要是低速场景的车位泊入及泊出,包含低速遥控泊车(RPA)、 记忆泊车(HPA)和代客泊车(AVP)。
**行车泊车功能的实现包括感知、预测、规划等多个任务,而评价智驾功能安全性及舒适度的决定因素在于规划控制。**规划控制作为整个自动驾驶/机器人算法流程中最下游的模块,直接影响司机和乘客的乘车体验,更直接一点:转弯加减速是否丝滑、行车轨迹规划是否符合人类驾驶习惯、车位泊入是否顺畅等等。
虽然特斯拉FSD V12之后,国内各大新势力都在攻坚端到端。但据了解,国内端到端落地尚不明朗,很多公司的端到端虽然已经对外声称上车,但效果相比于rule-based方案,仍然有较大差异。很多公司仍在demo阶段,还不敢投入主战场。直接使用模型输出的规划结果,不出意外的话会不停地『画龙』,安全性根本无法保障,因此仍然需要传统规控兜底。特别是对安全性要求更高的L4,传统规控仍然占据主导地位,短时间内想要替换比较困难。
业内主流的决策规划框架
规划控制发展至今,行业也衍生出很多的决策规划框架,目前主要有以下三大类:
- 路径速度解耦的决策规划框架;
- 时空联合的决策规划框架;
- 数据驱动的决策规划框架。
据了解,业内绝大多数公司采用的都是路径速度解耦的决策规划框架 。并且这种方法的上限也是很高的,不少公司都基于该框架实现了无人化的操作。而这种框架最具代表性的方法便是百度Apollo EM Planner,像地平线、大疆、华为、Momenta等诸多主流自动驾驶和芯片公司都有Apollo的影子或基于此直接进行二次开发。
自动驾驶领域为了缩短开发周期,减少框架稳定性的验证,一般会基于优秀的开源框架进行二次开发,比如ROS、Apollo等,重复造轮子对快节奏的自动驾驶行业不是很可取。
而Apollo从2017年4月发布1.0到2023年12月的9.0,已经走过了7个年头。作为最成熟的开源框架影响了无数的自动驾驶从业者,开源Apollo框架集成了很多实用的算法,工程架构完备且方便迁移使用,所以很多初创公司更是直接基于Apollo框架开发产品,可以说Apollo推动了自动驾驶行业的快速发展,这一点百度真的很有远见。

因此,对于刚入门决策规划的小白来说,Apollo决策规划框架是最合适的入门学习内容;对正在找工作和已经工作的同学来说,Apollo也是面试和开发绕不开的点。
- 从学习/工程角度来说:Apollo框架工程性强,C++代码规范,集成了众多优秀的算法实现。
- 从面试角度角度来说:对于大部分基础问题, 几乎都可以从Apollo开源代码里找到答案!
- 从就业角度来说 :百度的招聘直接明确的标明"熟悉开源Apollo"优先。如果你学过 Apollo, 绝对是一个很大的加分项。
决策规划的难点在哪里?
整体来说,规划控制相比于感知对理论知识的要求较高。目前业界主流的行车规划EM Planner、泊车规划Hybrid A*。且量产部署均是基于C++开发优化。这段时间有很多小伙伴咨询行车&泊车决策规划的相关问题,市面上已有的鞠策规划相关学习资料质量参差不齐,许多同学在资料搜集和入门学习的时候踩了较多坑:
决策规划算法类别很多,网上找不到系统学习的资料,刚入门的同学不知道从何下手,论文也看的一知半解...
C++入门学习十分困难,工程框架看不懂...
理论搞懂了,但是算法怎么具体实现行车&泊车功能的,一头雾水...
Apollo开源框架好复杂,刚上手难度太大...
第一章、Apollo整体架构介绍
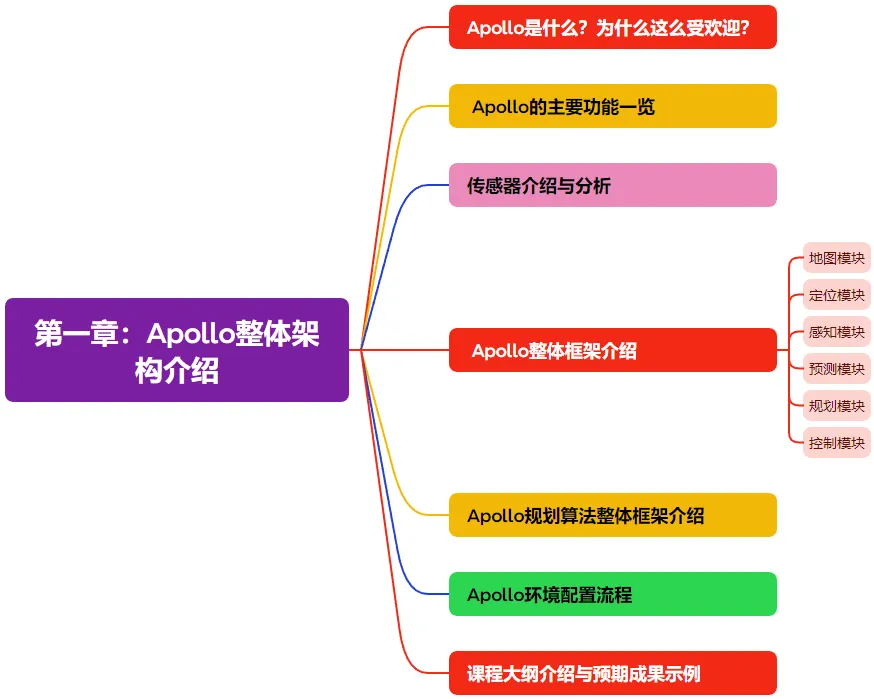
第一章为总纲篇,从整体上带大家了解Apollo框架。Apollo是什么?有哪些主要的模块?每个模块的功能是什么?进一步聚焦到Apollo规划算法的介绍上,并会讲解如何配置Apollo。总结来说,第一章会从整体上阐述本框架及预期的学习成果。
第二章、智能驾驶行泊功能与方法介绍
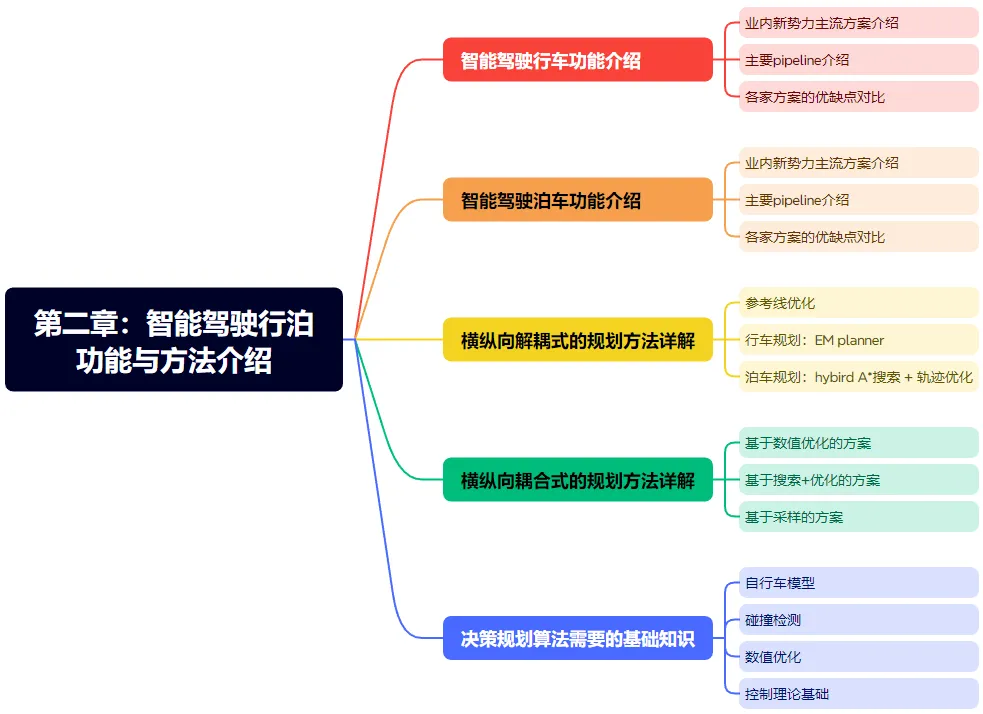
第二章进入到基础讲解。首先概括性的介绍智能驾驶的行车功能和泊车功能,进一步对业内主流方案展开介绍并对比各自的优缺点。这是很多刚入门的同学所欠缺的,很多同学只注重具体的技术,而忽略了大局观。接着老师会带大家系统性的复盘规划控制的相关内容,从横纵向解耦到横纵向耦合再到决策规划的基础知识。总结来说,第二章是基石,从宏观上了解行泊功能的现状,从微观上掌握决策规划的基础。
第三章、行车功能:参考线平滑算法
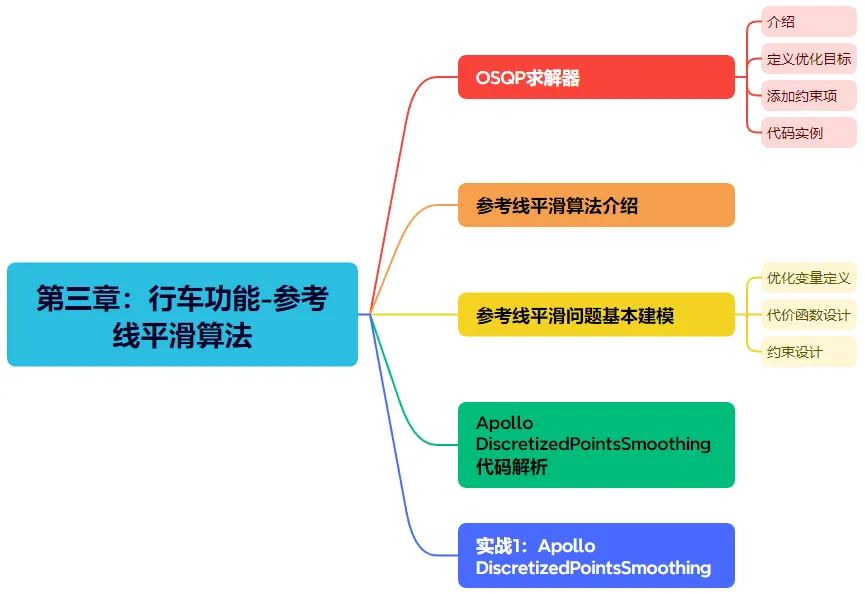
第三章进入到具体的行车功能参考线平滑算法讲解。首先明确为什么要做参考线平滑以及问题的基本建模。然后深入剖析OSQP求解器。最后上手实战,带大家一起学习Apollo DiscretizedPointsSmoothing的核心代码!
第四章、行车功能:决策算法
第四章则是讲解行车功能的决策算法。带大家全面复盘主流的决策算法,包含Apollo DP算法、博弈论、POMDP、MCTS以及深度学习的相关算法。最后上手实战,实现一个基于博弈论的MCTS加速加速交互算法。这块也是目前业界落地的最前沿。
第五章、行车功能:路径优化算法
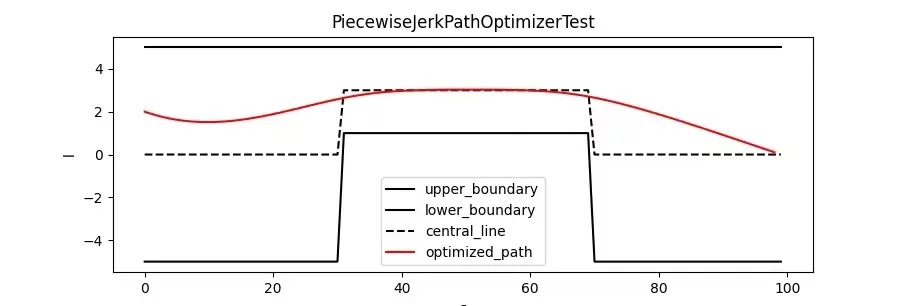
第五章进一步对Apollo行车路径优化算法展开讲解。首先整体上介绍路径规划,进一步讲解路径规划问题的基本建模和表达曲线的不同方式。最后上手实战,详细讲解Apollo PieceWiceJerkPathOptimizer模块的核心代码。
第六章、行车功能:速度规划算法
第六章讲解行车的最后一个算法模块------速度规划算法。基于路径规划问题的基本建模。进一步展开实战,详细讲解Apollo PieceWiceJerkSpeedOptimizer模块的核心代码。
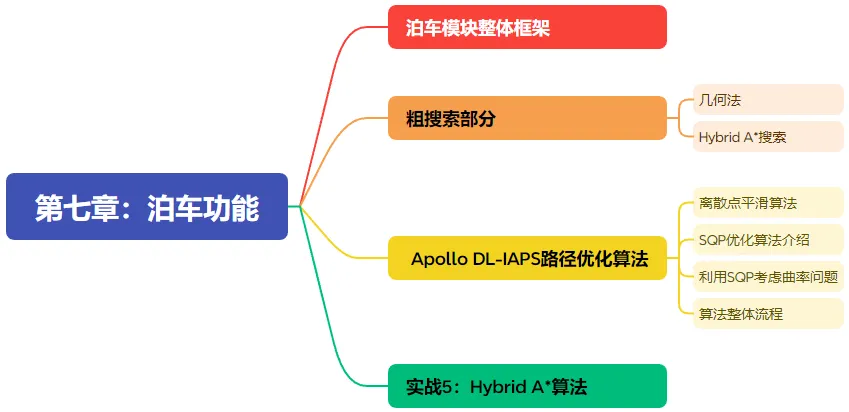
第七章、泊车功能
经过前四章节行车模块的讲解,大家已经对Apollo规划控制有了一个更深入的理解。第七章则聚焦在泊车功能的讲解上。首先从整体上带大家过一遍泊车模块的框架,进一步详细讲解泊车的粗搜索部分。然后剖析Apollo DL-IAPS路径优化算法。最后实战Hybrid A*算法。
#SimpleLLM4AD
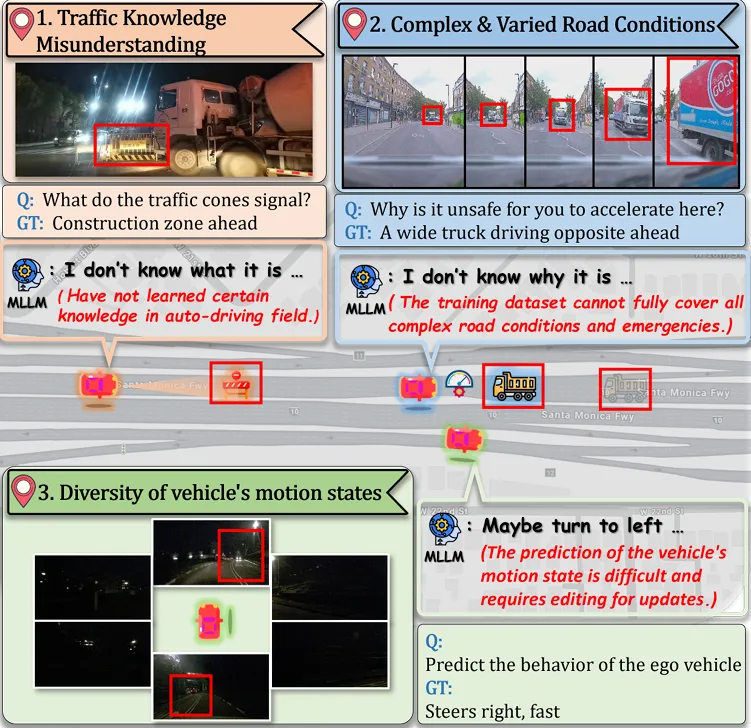
SimpleLLM4AD攻克复杂驾驶场景!自动驾驶端到端视觉语言模型
题目:SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving
作者:Peiru Zheng, Yun Zhao, Zhan Gong, Hong Zhu, Shaohua Wu
机构:IEIT Systems
原文链接:https://arxiv.org/html/2407.21293v1****
内容速览
- 作者利用GVQA的逻辑依赖性 ,使用相关问题的答案作为当前问题的上下文信息,显著提高了LLMs在准确性(ACC)和语言得分方面的能力。
- 作者优化了提示语,以进一步提高LLMs的性能。作者简化了上下文的简单问答(Q+A)格式,使LLMs更容易、更高效地利用先前的知识。
- 作者将目标检测分支引入到LLM优化过程中,包括目标定位、颜色识别和分类。这些额外的分支为LLMs提供了更丰富的上下文线索,进一步提高了它们的性能。
1.引用
在自动驾驶领域,大型语言模型(LLMs)的快速发展为端到端自动驾驶(e2eAD)带来了新的机遇。本文提出了一种名为SimpleLLM4AD的e2eAD方法,该方法利用视觉-语言模型(VLM)将自动驾驶任务划分为感知、预测、规划和行为四个阶段。每个阶段由多个视觉问答(VQA)对组成,这些VQA对相互连接,形成一个图结构,称为图视觉问答(GVQA)。通过VLM逐步推理GVQA中的每个VQA对,作者的方法能够实现用语言进行端到端驾驶。在感知阶段,系统从驾驶环境中识别和分类目标。预测阶段涉及预测这些目标的潜在运动。规划阶段利用收集到的信息制定驾驶策略,确保自动驾驶车辆的安全性和效率。最后,在行为阶段,将计划的行动转化为车辆可执行的命令。作者的实验表明,SimpleLLM4AD在复杂驾驶场景中取得了竞争性的性能。1. 引言
自动驾驶技术近十年来受到了学术界和工业界的广泛关注。一个充满安全的道路、缓解交通拥堵以及为更多人提供出行便利的未来愿景,正推动着这一领域技术的迅猛发展。传统上,自动驾驶技术依赖于感知、预测、规划和控制等多个模块的串联处理流程。但这种串联的模块化方法可能会导致在复杂多变的交通环境中性能不佳,因为模块间的误差可能会累积放大。
随着大型语言模型(LLMs)的兴起,作者看到了重新定义自动驾驶方法的新机遇。特别是当这些模型与视觉-语言模型(VLMs)结合时,它们在理解视觉输入并生成类似人类的文本方面展现出了令人瞩目的能力。这些能力可以被用来构建更加连贯和一体化的自动驾驶系统,这些系统能够进行细致的推理和决策。
在本研究中,作者提出了SimpleLLM4AD,这是一种端到端的自动驾驶方法,它充分利用了VLMs的强大功能。作者的方法打破了传统的自动驾驶流程,将其重新构建为四个紧密相连的阶段:感知、预测、规划和行为。每个阶段都构建在一系列视觉问答(VQA)对上,这些VQA对通过形成图视觉问答(Graph VQA, GVQA)相互连接。这种基于图的结构使系统能够系统地推理每对VQA,确保从感知到行动的信息流和决策过程的连贯性。
在SimpleLLM4AD的感知阶段,ViT模型被用来处理原始的视觉数据,提取有意义的特征并识别驾驶环境中的物体。这些视觉洞察随后被转化为语言模型能够理解的格式,允许对场景进行更精细的分析。预测阶段中,系统将预测已识别物体的未来状态,考虑它们可能的运动和相互作用。这种预测能力对于预见潜在的危险和规划安全的驾驶策略至关重要。规划阶段涉及将前几个阶段收集的信息综合起来,制定一个旨在优化安全性和效率的驾驶策略,同时考虑到驾驶环境的动态性。最终,在行为阶段,计划中的行动被转化为车辆可执行的命令,确保精确的控制和响应。
作者的实验结果表明,SimpleLLM4AD在驾驶基准测试中不仅展现出了竞争性的性能,而且在复杂场景中也显示出了增强的鲁棒性。通过整合VLMs,系统能够做出更加上下文感知的决策,显著提升了其可靠性和安全性。作者的主要贡献可以总结如下:
- 作者利用GVQA的逻辑依赖性,将相关问题的答案作为当前问题的上下文信息,这种方法已被证明可以显著提高LLMs在准确性和语言得分方面的表现。
- 作者改进了提示语,以进一步提升LLMs的性能。作者优化了简单的问答格式,简化了上下文信息,使LLMs更容易、更高效地利用先前的知识。
- 最后,作者引入了目标检测分支到LLM优化过程中,包括目标定位、颜色识别和分类。这些额外的分支为LLMs提供了更丰富的上下文线索,从而进一步提高了它们的性能。
3. 方法 3.1 总体架构
作者的方法流程详见图1。整个系统由两大核心模块构成:一个负责图像处理的视觉编码器,以及一个专门处理问题的LLM解码器。
Figure 1. 整体架构图。展示了作者方法的流程图,包括视觉编码器处理图像和语言模型解码器处理问题的两个主要模块。
视觉编码器:作者选用了InternViT-6B作为视觉编码器。这款具有60亿参数的视觉变换器由Chen等人首次提出,并利用来自互联网的海量图像-文本数据进行了预训练,以与大型语言模型相匹配。查询模型充当视觉编码器与LLM解码器之间的桥梁,负责对齐视觉与文本两种模态。该视觉-文本对齐组件初始化时采用了增强多语言能力的LLaMA模型。
LLM解码器:作者采用了Vicuna-13B作为LLM解码器,这是一个开源的大型语言模型,基于从ShareGPT收集的用户共享对话数据对LLaMA模型进行了微调。尽管不同问题共用同一LLM解码器模型,作者设计了一种GVQA策略来增强语言模型的能力,并根据不同问题类型定制了专门的提示。
在本方法中,nuScenes数据集中的每一帧关键图像都会经历一系列问答对的处理。首先,利用InternViT-6B将关键帧中的六张图像编码成特征图。然后,在查询模块中,这些图像特征与问答对中的问题文本以及96个可学习查询进行互动。查询模块将InternViT-6B生成的图像标记转换成与LLMs对齐的表示形式。最终,查询模块的输出被送入Vicuna-13B以生成答案。值得注意的是,前一步生成的答案会与下一个问题结合,形成一个信息丰富的新问题。通过这种方式迭代,逐步完成端到端自动驾驶任务。
这种模块化的设计确保了从视觉编码到视觉-文本对齐,再到语言生成的每个处理阶段都针对其特定功能进行了优化,同时在整个流程中保持了无缝集成。这种架构不仅提升了系统处理复杂视觉和语言输入的能力,还确保了信息的连贯流动,使得在自动驾驶场景中的决策更为精确和具有上下文感知。
3.2 GVQA逻辑依赖性
SimpleLLM4AD方法涵盖了四个阶段的序列,每个阶段都由它们包含的问答对的逻辑依赖性紧密相连。如图2所示,GVQA的逻辑依赖性以图形化的方式呈现,揭示了整个过程中问答对之间相互连接的本质。图中包含两个主要元素:节点(N)和边(E)。节点(N)代表单独的问答对,而连接它们的边(E)则表示它们之间的逻辑依赖性。具体来说,前一个节点(NP)的答案作为后续节点(NS)的上下文信息。
Figure 2. GVQA逻辑依赖图。展示了自动驾驶过程中各个问答对(QA pairs)之间的逻辑依赖关系,其中节点(N)代表单独的问答对,边(E)表示它们之间的逻辑联系。
在自动驾驶的背景下,理解这些逻辑依赖性对于系统的决策过程至关重要。例如,在感知阶段,系统必须识别当前场景中的关键目标,这些目标将作为未来推理和驾驶决策的依据。这一初步识别为预测阶段奠定了基础,系统在该阶段评估目标的运动状态,并预测它们可能的未来状态。
规划阶段接着利用感知和预测阶段收集的信息,为自动驾驶车辆制定一个安全高效的行动方案。这包括考虑对已识别目标可能采取的行动,并预测这些行动的结果,如碰撞的可能性和所提议机动的安全性。
图2清晰地展示了从一个阶段到下一个阶段的逻辑流程,每个节点代表一个关键的决策点或信息里程碑。例如,节点(c1,CAM_FRONT,714.3,503.6)代表了由前摄像头捕获的目标的识别和初步评估。随后的节点则基于这一信息进一步提问,询问目标的运动状态以及它可能如何与场景中的其他目标,如节点(c3,CAM_FRONT,1300.8,531.7)所代表的另一辆车或显著障碍物,进行交互。
连接这些节点的边指示了逻辑流程和系统思维过程的进展。例如,关于目标'c1'是否会进入目标'c3'运动方向的问题,是基于前一节点得出的答案。同样,关于自动驾驶车辆行动的决策过程也取决于前几个阶段的预测和评估。
通过明确这些逻辑依赖性,SimpleLLM4AD方法确保了自动驾驶决策制定的连贯性和系统化,这不仅有助于开发更复杂的AI系统,还提高了这些系统决策的透明度和可靠性。
4 实验 4.1 数据集与评估指标
在本项研究中,作者采用了专为自动驾驶模型量身定制的DriveLM-nuScenes数据集,进行模型的微调和性能评估。该数据集包含4072帧的训练集和799帧的验证集,为模型的深入学习和精准评估提供了坚实的数据支撑。数据集精心设计,涵盖了从简单到复杂的各类驾驶场景,包括场景描述和细致的帧级问答对,这些问答对被划分为感知、预测和规划三个关键领域,以确保对驾驶环境的全面和深入理解。
感知领域的问题旨在对整个驾驶场景进行细致的审视,包括对场景中各目标的识别与分类。这些问题部分由人工精确标注,部分则基于场景中目标的特性,自动生成问题,同时借助nuScenes和OpenLane-V2数据集的真实信息进行辅助。
预测领域的问题专注于对关键目标在未来帧中的状态进行预测,包括它们可能的运动轨迹和行为变化。鉴于预测任务的复杂性,所有相关问题的答案均经过人工细致标注,以确保预测的准确性和可靠性。
规划领域的问题则涉及自动驾驶车辆在当前场景中的行动策略,包括对车辆接下来应采取的行动进行规划和决策。这些问题同样需要人工标注,以确保对规划过程的深入理解和准确表达。
在数据集中,每个关键目标都通过一个编码标签<c, CAM, x, y>来明确标识,其中c代表目标的唯一标识符,CAM指代摄像头的视角,而(x, y)则是目标在摄像头视野中的2D边界框坐标。此外,数据集为每个关键帧配备了一个字典,详细记录了各关键目标的基本信息,包括边界框的尺寸、类别、运动状态和视觉描述等。
为了全面评估模型在自动驾驶任务中的表现,作者选用了以下评估指标:
- VQA评估指标:包括BLEU、ROUGE_L、METEOR、CIDEr和SPICE等,这些指标综合考量了模型在视觉问答任务中的准确性和语言生成的质量。
- BLEU:衡量生成文本与参考文本之间n-gram重叠的程度。
- ROUGE_L:通过最长公共子序列计算模型输出和参考答案之间的相似度。
- METEOR:考虑同义词和句法结构,提供模型输出和参考之间的对齐。
- CIDEr:通过n-gram TF-IDF向量的余弦相似性计算语义一致性。
- SPICE:通过场景图的F-scores评估预测和参考场景图之间的对齐。
- GPT得分:由ChatGPT提供,根据模型的推理能力,对预测的质量进行0到100分的评分,以更细致地评估语义的准确性。
- 行为任务指标:专注于评估模型对自动驾驶车辆行为预测的准确性,包括行为分类的准确度、行为速度和转向的准确性。
- 分类准确性:评估行为预测的准确性,通过比较预测行为与真实情况的一致性。
这些评估指标共同构成了一个全面的评估体系,使作者能够从多个维度细致地评估和理解模型的性能,确保评估结果的准确性和全面性。
4.2 实施细节
在本项研究中,作者对SimpleLLM4AD模型进行了精细的微调,使用了DriveLM-nuScenes数据集来优化模型表现。作者沿用了InternViT-6B模型的预训练权重,并且在微调过程中将其固定,以保留其在大规模图像-文本数据预训练中获得的知识。进一步地,作者的模型中QLLaMA和96个可训练的查询组件在微调中被特别优化,以提升模型对问题的理解和回答能力。至于Vicuna13B这一大型语言模型,作者采取了两种策略:一是完全冻结其参数,保持其原始的通用语言理解能力;二是通过参数高效微调(PEFT)技术如LoRA对其进行微调,以适应特定的自动驾驶任务。在模型输入方面,作者将图像分辨率统一设置为224×224像素,以确保数据的一致性并适配模型的输入需求。微调操作是在NVIDIA GPU上执行的,作者选择了1e-4的学习率和16的全局批量大小,这样的参数配置旨在实现模型的稳定学习与有效收敛。
4.3 在DriveLM-nuScenes上的测试成果
在DriveLM-nuScenes数据集上的测试表明,经过精心微调的SimpleLLM4AD模型在自动驾驶的多项任务中均展现出了卓越的性能。作者的模型不仅在感知、预测和规划等关键环节上表现突出,更在复杂多变的交通场景中证明了其强大的应用潜力。
Table 1. DriveLM-nuScenes基准测试结果(测试集)。列出了不同方法在DriveLM-nuScenes数据集测试集上的表现,包括准确度、ChatGPT匹配度、BLEU1、ROUGEL、CIDEr得分和最终得分。
在与现有自动驾驶模型的对比测试中,SimpleLLM4AD在多个评估维度上均取得了显著的优势。相较于DriveLM baseline基线模型,SimpleLLM4AD在准确性和语言得分上的巨大提升,使得其在测试集上的综合得分高达52.7分,这一分数的显著提高充分展现了SimpleLLM4AD处理复杂驾驶情境的优越能力。
Figure 3. 结果展示。展示了SimpleLLM4AD方法在DriveLM-nuScenes基准测试中的部分结果。
4.4 消融研究分析
在本研究的探索阶段,作者对SimpleLLM4AD模型在多种不同配置下进行了训练与推理。这些不同方案的主要区别在于提示(prompt)的处理方式和关键目标的检测方法。表1所展示的基线性能是基于作者自行创建的验证集,使用LLaMA-Adapter-V2模型进行评估得出的。该验证集是通过从原始训练集中每六个场景中选取一个场景来构成的。
Table 2. DriveLM-nuScenes不同设置的结果(作者自行划分的验证集)。展示了SimpleLLM4AD在不同配置下的性能,包括准确度、匹配度、BLEU1、ROUGEL和CIDEr得分。
注意:表2中的"匹配度"仅指代边界框坐标的匹配程度;与表1不同,表1中的"匹配度"既包括边界框坐标匹配也包括ChatGPT得分。
思维链(Chain of Thought, CoT)的应用
思维链是一种在提示中包含推理中间步骤的方法,它不仅包括任务的输入和输出。文献显示,这种方法能显著提升大型语言模型解决问题的能力,而无需对模型进行任何更新。
在SimpleLLM4AD模型中,作者采用思维链的方式,使用前一个问题的答案(NP)作为后一个问题(NS)的上下文信息。NS始终是数据集中紧随NP之后的QA对。与DriveLM基线相比,采用CoT的版本A在准确度和语言得分上均有显著提升。
DriveLM-nuScenes数据集中的每个帧都以"当前场景中的重要目标是什么?"这个问题开始,作者称之为N0。在版本B中,作者将N0和NP的答案结合起来,作为每个NS的上下文。
思维图谱(Graph of Thought, GoT)的探索
与思维链不同,思维图谱允许当前任务利用任何先前的QA对作为上下文,并允许任何后续问题引用当前任务的结果。经过多种逻辑依赖图的尝试,作者发现图2所示的结构最为有效。采用GoT安排上下文的方式,使得版本C在性能上取得了显著提升。
提示的优化
精心设计的提示对于提升大型语言模型的性能至关重要。在DriveLM基线的解决方案中,传递给后续问题的上下文是前一个问题和答案的组合,这可能导致上下文冗余且难以理解。因此,作者优化了提示的格式,简化了上下文信息,使其更加易于LLMs处理和利用。
例如,原始的N0答案可能会这样描述:"自我车前有一辆红色汽车、一辆白色SUV、一辆白色轿车、一辆黑色轿车,以及前方的一个红色信号灯。这些目标的ID分别是..."。为了简化,作者将其改写为:"目标<c1,CAM_FRONT,714.3,503.6>是自我车前部的一辆红色汽车。"
如您所见,同一目标的颜色/类别信息和坐标信息在两个句子中分别描述,这可能会使LLMs感到困惑。因此,当将其用作后续问题的上下文时,作者将答案格式化为:"<c1,CAM_FRONT,714.3,503.6>是自我车前部的一辆红色汽车。"
作者只提供当前问题中提到的目标的信息,而不是N0中检测到的所有目标。
此外,作者将其他QA对修改为陈述句,当用作上下文时。例如,像"<c1,CAM_FRONT,714.3,503.6>是否会在自我车的移动方向上?否。"这样的QA对在用作上下文时将被修改为"<c1,CAM_FRONT,714.3,503.6>不会在自我车的移动方向上。"
通过重新格式化QA对,简洁且信息丰富的上下文在版本D中提供了语言得分的提高。
关键目标检测的改进
格式指令为"依次输入六张图片。前六张图片中的第一张是 <CAM_FRONT>,位于自我车前部。第二张是<CAM_FRONT_LEFT>,位于自我车前部左侧。第三张是<CAM_FRONT_RIGHT>,位于自我车前部右侧。第四张是<CAM_BACK>,位于自我车后部。第五张是<CAM_BACK_LEFT>,位于自我车后部左侧。第六张是<CAM_BACK_RIGHT>,位于自我车后部右侧。<数字,数字>是图片中目标框中心的坐标(1600*900)。"
为了提高模型性能,作者集成了格式指令来引导LLMs。利用现有的成熟检测网络,例如dino v2,作者获得了强大的目标检测输出。此外,作者还训练了一个专门的检测分类网络,它不仅能够检测目标,还能识别目标的颜色、精确位置甚至方向等关键属性。这使作者能够生成详细的描述,如:"自我车前有一辆红色汽车,其框中心坐标为714.3,503.6。"
- 结论
本文提出了SimpleLLM4AD,一个端到端的自动驾驶多模态语言模型,它在复杂驾驶环境中展现出了卓越的性能。通过融入视觉-语言模型(VLM),作者的系统能够在决策过程中实现更深层次的情境感知和连贯性,显著增强了自动驾驶系统的稳健性和可信度。此外,作者的研究还展示了大型语言模型(LLMs)在提升多模态人工智能应用方面的潜力,为自动驾驶领域未来的技术进步奠定了基础。
#端到端最前沿论文
End to End methods for Autonomous Driving
近几年,自动驾驶技术的发展可谓是日新月异。从2021年的BEV+Transformer范式到2022年的Occupancy网络,再到2023年以来,"端到端"思路被炒得火热,如今各大厂商几乎都推出了自己的做端到端系统:2023年8月特斯拉发布FSD V12;2024年4月商汤绝影发布面向量产的端到端自动驾驶解决方法UniAD;2024年5月,百度发布Apollo ADFM作为支持L4级别自动驾驶的大模型;2024年5月,小鹏汽车也发布自己的端到端大模型包含感知大模型XNet+规控大模型XPlanner+大语言模型XBrain三个部分......
不论是主机厂还是智驾解决方案供应商,每一家都有自己的端到端算法,但是到底什么是端到端?业内一直在讨论,没有一个明确的定义。但是笔者认为,来自大佬王乃岩的知乎回答,可能可以给读者们提供一些思考。简单总结就是:输入各种传感器的数据,可以直接输出控制信号的或者行驶轨迹的,可以称之为狭义端到端 ;而广义端到端 可以认为是提供了一种对于感知信息(也许是隐式)的全面表示,能够自动地无损地作用于PnC的模型。
对于我们自动驾驶从业人员来说,follow新的技术,一直是我们的工作之一。今天笔者就带来一份详细的端到端自动驾驶论文的总结,供大家学习入门。
ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
论文链接:https://arxiv.org/pdf/2207.07601
论文时间:2022.7
论文作者:Shengchao Hu, Li Chen, Penghao Wu, et al.
所属团队:上海交通大学人工智能实验室,上海市人工智能实验室,加利福尼亚州圣地亚哥分校,et al.
这篇论文提出了一个名为ST-P3的端到端视觉基础自动驾驶系统,旨在通过空间-时间特征学习来提升自动驾驶任务中的感知、预测和规划性能。现有的自动驾驶范式通常采用多阶段分散的流水线任务,但这种方法的缺点在于各个阶段间可能存在信息损失和不一致性。为了克服这些问题,ST-P3采用了一种一体化的方法,直接从原始传感器数据生成规划路径或控制信号,从而在整个网络中同时优化特征表示。ST-P3系统的核心在于其空间-时间特征学习方案,该方案通过三个主要的技术改进来增强特征学习:自我中心对齐累积技术 (Ego-centric Aligned Accumulation):在感知阶段,该技术通过预测深度信息将多视角相机输入的特征转换到3D空间,并在变换到鸟瞰图(BEV)之前,将过去和当前的3D特征进行累积,以保留几何信息。双通道建模 (Dual Pathway Modelling):在预测阶段,ST-P3不仅考虑当前状态的不确定性,还结合了过去的运动变化,通过两个通道来增强对未来场景的预测能力。先验知识精细化单元(Prior-Knowledge Refinement):在规划阶段,ST-P3利用从早期网络阶段获得的中间表示来规划安全舒适的轨迹,并引入一个精细化模块来进一步优化轨迹,考虑如交通信号灯等视觉元素。
Planning-oriented Autonomous Driving
论文链接:https://arxiv.org/pdf/2212.10156
论文时间:2023.3
论文作者:Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, et al.
所属团队:OpenDriveLab, OpenGVLab,上海人工智能实验室, 武汉大学, 商汤科技研究院
在传统的自动驾驶系统中,感知、预测和规划任务通常由独立的模型分别处理,这种模块化的方法虽然简化了研发流程,却存在着信息在模块间传递时丢失、误差累积以及特征对齐问题。UniAD通过一个统一的网络将这些任务整合在一起,优化了任务间的信息流通和协调,从而显著提升了整个系统的性能和可靠性。UniAD的核心是其端到端的设计,它将多个关键任务------包括目标检测、多目标跟踪、在线地图构建、运动预测、占用预测和规划------封装在一个网络中。这种设计允许系统从全局视角捕获驾驶场景的语义和几何信息,并通过统一的查询接口实现不同任务间的有效通信。例如,感知模块的输出可以直接用于预测模块,而预测结果又可以指导规划器制定安全有效的行驶策略。从实现的角度说,UniAD采用了Transformer解码器结构,利用自注意力机制来处理感知和预测任务中的序列化数据。它通过TrackFormer进行目标的检测和跟踪,通过MapFormer实现在线地图构建,通过MotionFormer预测其他车辆和行人的未来运动轨迹,通过OccFormer预测未来场景的占用网格图。最终,规划器结合这些信息,使用非线性优化策略生成最终的行驶轨迹,确保自动驾驶车辆能够安全地导航。
ReasonNet: End-to-End Driving with Temporal and Global Reasoning
论文链接:https://arxiv.org/pdf/2305.10507
论文时间:2023.5
论文作者:Hao Shao, Letian Wang, Ruobing Chen, et al.
所属团队:商汤科技研究院, 多伦多大学, 香港中文大学 MMLab, 上海人工智能实验室
ReasonNet是为解决自动驾驶车辆在城市密集交通场景中部署的挑战而设计的端到端驾驶框架。该框架特别关注于预测场景的未来演变和对象的未来行为,以及处理罕见的不利事件,如遮挡对象的突然显现。这些能力对于确保自动驾驶车辆能够安全、可靠地运行至关重要。框架的核心在于其两个创新的推理模块:时序推理和全局推理。时序推理模块通过分析和融合不同帧之间的特征,有效地处理了对象随时间的运动和相互作用,同时维护了一个记忆库来存储和利用历史特征,这有助于对遮挡对象进行追踪和预测。全局推理模块则进一步增强了框架的能力,通过模拟对象与环境之间的交互和关系,来识别和处理不利事件,尤其是那些可能被遮挡的对象,从而提高了整体的感知性能。为了全面评估框架的性能,研究者开发了DriveOcclusionSim,这是一个包含多种遮挡事件的驾驶模拟基准测试。ReasonNet的成功不仅体现在理论上,更在于其在实际模拟环境中的卓越表现。该框架通过多任务学习,联合目标包括对象检测、占用预测、交通标志预测和路径点预测,提高了对复杂交通场景的全面理解。此外,框架中的感知模块能够处理和融合来自多个传感器的数据,生成对导航至关重要的鸟瞰图特征。控制策略则利用预测的路径点和交通标志来指导自动驾驶车辆的行驶。
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
论文链接:https://arxiv.org/pdf/2308.01006
论文时间:2023.8
论文作者:Tengju Ye2, Wei Jing3, Chunyong Hu, et al.
所属团队:西湖大学,Udeer.ai,菜鸟网络,阿里巴巴集团
这篇论文提出了一个名为FusionAD的新型自动驾驶多模态融合神经网络框架,首次探索了如何将相机和激光雷达的信息融合,以端到端的方式优化预测和规划任务。具体来说,研究者首先构建了一个基于Transformer的多模态融合网络,有效地产生基于融合的特征。与基于相机的端到端方法UniAD相比,FusionAD进一步建立了一个融合辅助的模态感知预测和状态感知规划模块(FMSPnP),该模块利用多模态特征进行优化。在nuScenes数据集上进行的广泛实验表明,FusionAD在感知任务(如检测和跟踪)上平均提高了15%,在占用预测精度上提高了10%,在平均位移误差(ADE)分数上从0.708降低到0.389,并减少了碰撞率从0.31%到0.12%。这些结果表明,FusionAD在预测和规划任务上达到了当时最先进的性能,同时在中间感知任务上也保持了竞争力。FusionAD的核心贡献在于提出了一种基于BEV(鸟瞰图)融合的多传感器、多任务端到端学习方法,与仅基于相机的BEV方法相比,大大改进了结果。研究者提出的FMSPnP模块结合了模态自注意力和细化网络,用于预测任务,以及放松的碰撞损失和与矢量化自我信息的融合,用于规划任务。实验研究表明,FMSPnP提高了预测和规划结果。
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
论文链接:https://arxiv.org/pdf/2303.12077
论文时间:2023.8
论文作者:Bo Jiang, Shaoyu Chen, Qing Xu, et al.
所属团队:华中科技大学,地平线
VAD通过将驾驶场景建模为完全矢量化的表示来实现高效和安全的轨迹规划。与依赖于密集光栅化场景表示(例如语义地图、占用地图等)的传统方法相比,VAD利用矢量化的智能体运动和地图元素作为明确的实例级规划约束,不仅提高了规划的安全性,还显著提升了计算效率。在nuScenes数据集上的实验表明,VAD在减少规划误差和碰撞率方面取得了突破性进展,同时大幅提高了推理速度,这对于自动驾驶系统的实际部署至关重要。VAD的核心优势在于其创新的矢量化规划约束,这些约束包括自车的碰撞约束、自我边界越界约束和自我车道方向约束,它们共同作用于规划轨迹,确保了自动驾驶车辆在复杂交通环境中的安全性和合理性。此外,VAD采用了BEV(鸟瞰图)查询和agent查询,通过注意力机制隐式学习场景特征,并利用这些特征指导规划决策。VAD的端到端学习框架允许模型直接从传感器数据中学习,无需依赖预先构建的地图或复杂的后处理步骤,这一点在提高规划速度和减少计算资源消耗方面发挥了关键作用。
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
论文链接:https://arxiv.org/pdf/2402.13243
论文时间:2024.2
论文作者:Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, et al.
所属团队:华中科技大学,地平线
VADv2是一篇探索概率规划在端到端自动驾驶中的应用的研究论文。这项工作的核心是解决传统确定性规划方法在处理规划不确定性时的不足,特别是在面对非凸可行解空间时的挑战。本文提出的模型采用概率规划范式,将规划策略视为环境条件化的非平稳随机过程,通过从大规模驾驶演示中学习,来拟合连续规划动作空间的概率分布。输入是多视图图像序列,这些图像以流式传输的方式被转换成环境token嵌入,模型输出动作的概率分布,并从中采样一个动作来控制车辆。这样的概率规划方法具有两个显著优势。首先,概率规划能够对每个动作与环境之间的相关性进行建模,与只能为目标规划动作提供稀疏监督的确定性建模不同,概率规划可以为规划词汇表中的所有候选动作提供监督,从而带来更丰富的监督信息。其次,概率规划在推理阶段非常灵活,能够输出多模态规划结果,并且易于与基于规则和基于优化的规划方法相结合。此外,我们可以灵活地将其他候选规划动作添加到规划词汇表中,并评估它们,因为我们对整个动作空间进行了分布建模。VADv2的框架包括场景编码器、概率规划模块和训练过程。场景编码器将传感器数据转换为实例级token嵌入,包括地图token、智能体token、交通元素token和图像token。概率规划模块则利用大规模驾驶演示和场景约束来监督预测的分布。训练过程中,VADv2采用分布损失、冲突损失和场景token损失三种监督信号,以学习从驾驶演示中得到的概率分布。
SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation
论文链接:https://arxiv.org/pdf/2405.19620
论文时间:2024.5
论文作者:Wenchao Sun, Xuewu Lin, Yining Shi, et al.
所属团队:清华大学,地平线
这篇论文提出了SparseDrive,一种端到端的自动驾驶系统,旨在解决现有自动驾驶模型在规划安全性和效率方面的不足。传统的自动驾驶系统采用模块化设计,将感知、预测和规划等任务解耦为独立的模块,这导致了信息丢失和误差累积。而端到端的方法虽然在优化时能够全面考虑,但其性能和效率通常不尽人意,特别是在规划安全方面。SparseDrive通过探索稀疏场景表示和重新审视端到端自动驾驶的任务设计,提出了一种新颖的范式。具体来说,SparseDrive由一个对称的稀疏感知模块和一个并行运动规划器组成。稀疏感知模块通过对称的模型架构统一了检测、跟踪和在线地图构建任务,学习驾驶场景的完全稀疏表示。并行运动规划器则利用从稀疏感知中获得的语义和几何信息,同时进行运动预测和规划,产生多模态轨迹,并采用分层规划选择策略,包括碰撞感知重分模块,以选择合理且安全的轨迹作为最终规划输出。SparseDrive的设计有效提高了端到端自动驾驶的性能和效率。在nuScenes数据集上的实验结果表明,SparseDrive在所有任务的性能上都大幅超越了先前的最先进方法。此外,SparseDrive的碰撞感知重分模块和多模态规划方法,使得规划器能够基于运动预测结果评估规划轨迹的碰撞风险,并据此调整轨迹的得分,从而确保了规划的安全性。SparseDrive的这些设计选择通过广泛的消融实验得到了验证,证明了其在提高规划性能方面的有效性。
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
论文链接:https://arxiv.org/pdf/2406.06978
论文时间:2024.6
论文作者:Zhenxin Li, Kailin Li, Shihao Wang, et al.
所属团队:英伟达,复旦大学,华东师范大学,北京理工大学,南京大学,南开大学
Hydra-MDP是一篇探讨端到端自动驾驶多模态规划的论文,提出了一种新颖的多教师模型范式,通过从人类和基于规则的教师那里进行知识蒸馏来训练学生模型。通过一个多头解码器来实现多模态规划,该解码器学习针对不同评估指标量身定制的多样化轨迹候选。与传统的端到端方法不同,Hydra-MDP不依赖于不可微的后处理过程,而是利用基于规则的教师的知识,以端到端的方式学习环境如何影响规划。Hydra-MDP的解决方案包括感知网络和轨迹解码器两个主要部分。感知网络基于官方挑战基线Transfuser构建,利用图像和激光雷达数据提取环境token,这些tokens编码了丰富的语义信息。轨迹解码器则采用固定规划词汇表来离散化连续动作空间,并通过多层变换器编码器和解码器结合环境线索。论文的关键创新之一是多目标Hydra蒸馏策略,通过两步过程扩展学习目标:首先,对整个训练数据集的规划词汇进行离线模拟;其次,在训练过程中引入模拟得分的监督。这种策略将规则基础的驾驶知识蒸馏到端到端规划器中,提升了闭环性能。
End-to-End Autonomous Driving without Costly Modularization and 3D Manual Annotation
论文链接:https://arxiv.org/pdf/2406.17680
论文时间:2024.6
论文作者:Mingzhe Guo, Zhipeng Zhang, et al.
所属团队:北京交通大学,卡尔动力KARGOBOT
这篇论文提出了一种名为UAD(U nsupervised pretext task for end-to-end A utonomous Driving)的新方法,旨在解决当前端到端自动驾驶(E2EAD)模型在环境感知和预测任务中对昂贵的模块化和手动3D标注的依赖问题。UAD的核心创新在于引入了一个无监督的前置任务,通过预测驾驶场景中的角空间对象性和时序动态来模拟环境,从而消除了对手动标注的需求。此外,UAD采用了自监督的训练策略,通过学习在不同增强视图下预测轨迹的一致性,增强了在转向场景中的规划鲁棒性。UAD方法的提出基于对现有E2EAD模型的观察,这些模型通常模仿传统驾驶栈中的模块化架构,需要大量高质量的3D标注数据来监督感知和预测子任务。这种设计虽然取得了突破性进展,但存在明显的缺陷:一是对大规模训练数据的扩展构成了重大障碍;二是每个子模块在训练和推理中都需要大量的计算开销。为了解决这些问题,UAD框架采用了一个新颖的角度感知预文本设计,通过预测BEV空间中每个扇区区域的对象性来获取空间知识,并通过自回归机制预测未来状态来捕获时序信息。在实验中,UAD在nuScenes数据集上取得了最佳的开放环路评估性能,并在CARLA模拟器中展示了稳健的闭环路驾驶质量。
DRAMA: An Efficient End-to-end Motion Planner for Autonomous Driving with Mamba
论文链接:https://arxiv.org/pdf/2408.03601
论文时间:2024.8
论文作者:Chengran Yuan, Zhanqi Zhang, Jiawei Sun, et al.
所属团队:新加坡国立,Moovita
这篇论文介绍了一种叫作DRAMA的新型端到端运动规划器,它基于Mamba模型,旨在解决自动驾驶领域中的运动规划问题。运动规划是自动驾驶车辆的核心能力之一,它负责生成在复杂和高度动态环境中既安全又可行的轨迹。然而,由于其他道路使用者的意图预测、交通标志和信号的理解、道路拓扑结构的复杂性等因素,实现可靠和高效的轨迹规划是一个挑战。DRAMA通过融合相机、激光雷达鸟瞰图(BEV)图像以及自车状态信息,生成一系列未来自车轨迹。与传统基于Transformer的方法相比,这些方法由于注意力机制的二次复杂度而在序列长度上计算量大,DRAMA通过减少计算密集度的注意力复杂度,展现出处理日益复杂场景的潜力。利用Mamba融合模块,DRAMA高效且有效地融合了相机和激光雷达模态的特征。此外,论文还引入了Mamba-Transformer解码器,增强了整体规划性能,这一模块普遍适用于任何基于Transformer的模型,尤其是对于长序列输入的任务。论文还引入了一种新颖的特征状态丢弃(Feature State Dropout, FSD)机制,该机制通过在训练和推理时不增加时间的情况下,通过减少有缺陷的传感器输入和丢失的自车状态的不利影响,提高了规划器的鲁棒性。具体来说,DRAMA采用了一个编码器-解码器架构,其中编码器利用多尺度卷积和Mamba融合模块有效地从相机和激光雷达BEV图像中提取特征,并通过FSD模块增强模型的鲁棒性。解码器则采用了Mamba-Transformer解码层来生成自车的未来轨迹。这种架构不仅提高了模型的效率和性能,而且通过减少模型大小和训练成本,提高了模型的可扩展性和实用性。论文的实验部分展示了DRAMA在多种场景下的规划结果,包括在没有明确交通信号控制的情况下准确执行停车让行行人的命令,以及在低速场景中熟练地进行停车操作。
#MoManipVLA
通用移动操作VLA策略迁移!
本文为论文作者投稿,这里提出了 MoManipVLA ,一种全新的通用移动操作视觉-语言-动作模型(Vision-Language-Action Model, VLA )。该模型能够在真实场景中仅用 50 个训练轨迹 即实现 40% 的成功率,显著提升了移动操作任务的效率与泛化能力。
论文地址: https://arxiv.org/abs/2503.13446
项目主页: https://gary3410.github.io/momanipVLA/
- 简介
移动操作使机器人能够在广阔空间内执行复杂的操作任务,这需要对移动底座和机械臂进行全身协调控制。随着居家服务、智能制造、物流仓储等领域对机器人自主移动操作需求的日益增长,任务复杂性和物体多样性对移动操作模型的泛化性提出了严峻挑战。
然而,现有的移动操作框架缺少大规模预训练,导致整体泛化性低下。同时,收集手脚协同的移动操作数据轨迹昂贵成本,进一步限制了移动操作模型性能。
近年来,视觉-语言-动作模型(VLA) 1, 2 在任务泛化和场景适应方面展现了卓越性能。然而,现有的 VLA 研究主要聚焦于固定底座操作,由于缺乏对移动底座动作的预测能力,使其难以直接应用于移动操作场景。为此,我们提出了 MoManipVLA,一个高效的策略迁移框架,将固定底座的 VLA 模型迁移到移动操作任务中。
具体而言,MoManipVLA 利用预训练的 VLA 模型生成高泛化的 末端执行器路标(Waypoint) ,以指导移动操作轨迹的生成。同时,我们为移动底座和机械臂设计了基于场景约束的 运动规划目标,包括:
- 可达性(Reachability)
- 轨迹平滑性(Smoothness)
- 避碰(Collision Avoidance)
从而最大限度地提高移动操作轨迹的 物理可行性 。为了高效规划全身运动,我们提出了一种 双层轨迹优化框架(Bi-level Trajectory Optimization):
- 上层优化 负责预测底座运动轨迹,以增强机械臂的操作策略空间。
- 下层优化 选择机械臂的最佳轨迹,确保其遵循 VLA 模型的规划完成任务。

更详细的demo video可以在项目主页观看。
- 方法
我们的方法的核心思想是 利用 VLA 的强泛化能力,引导机器人底座和手臂的轨迹生成 ,通过 动作规划目标 生成物理可行的轨迹,让机械臂末端执行器在移动操作设定下到达 VLA 预测的路标,从而完成后续操作任务。
2.1 策略迁移网络
在大规模互联网数据集上预训练的 VLA 模型在 任务泛化 和 场景迁移 方面展现了极强的性能。然而,现有的 VLA 仅限于 固定底座操作 。为了高效迁移到 移动操作任务 ,我们提出了 MoManipVLA 框架,具体如图1所示。
图1 整体框架流程图
具体来说:
- VLA 模型生成末端执行器路标 ------ 通过视觉观测,预训练 VLA 模型输出机械臂末端执行器的高泛化路标。
- 优化动作规划目标 ------ 设计 运动规划优化目标(Motion Planning Objectives),确保交互轨迹物理可行(可达性、避碰、平滑性)。
- 双层轨迹优化框架 ------ 由于底座和机械臂的位姿搜索空间庞大,我们进一步提出 双层轨迹优化框架(Bi-level Trajectory Optimization):
- 上层优化 预测底座运动轨迹,以增强后续操作策略空间,确保末端执行器可以到达路标。
- 下层优化 机械臂动作,以精准执行 VLA 预测的目标路标。
2.2 移动运动规划目标
运动规划旨在为机器人底座和手臂生成路标之间的运动轨迹。我们通过设计不同的约束来为交互轨迹赋予可达性、平滑性和无碰撞物理含义。我们主要设计了三个约束:可达性(Reachability cost)、平滑性(Smoothness cost)和避碰(Collision cost),具体如图2所示。
图2 动作规划约束示意图
- 可达性(Reachability Cost):
-
由于移动操作需要机器人与大范围内的物体进行交互,底座位姿显著影响手臂能否到达目标物体。
-
我们使用 逆运动学(IK)求解器 计算可达性成本。
-
在最大迭代次数()内获取关节角度解表明轨迹是可到达的。迭代次数越多,IK求解速度越慢意味着关节角度越接近范围限制,可达成本越高。
-
轨迹平滑性(Smoothness Cost):
-
约束机器人手臂 关节角度 以及 底座的平移和旋转 保持连续平滑,避免突然变化。
-
平滑轨迹 有助于机器人控制的稳定性。
-
避碰(Collision Cost):
- 机器人需要避免 手臂、移动底座和环境中的物体 之间的碰撞,以确保安全。
- 我们利用 nvblox 计算 ESDF(欧几里得距离场) ,并通过 随机采样机器人表面上的查询点 评估碰撞风险。
- 其中, 为安全距离阈值。只有当距离小于该阈值时,才会对整体目标产生贡献,从而促使生成的轨迹尽可能远离障碍物。
2.3 双层轨迹优化框架
由于 移动底座和机械臂的姿态搜索空间庞大 ,直接搜索最优解非常困难。因此,我们提出 双层轨迹优化框架 来提高轨迹生成的效率:
- 上层优化 预测底座轨迹,以增强后续机械臂的操作策略空间。
- 下层优化 机械臂轨迹,使其遵循预训练 VLA 模型的规划完成操作任务。
具体如图3所示
图3 双层优化示意图
整个双层轨迹优化算法流程可以概括为以下伪代码:
- 初始化:根据当前观测状态与 VLA 预测的路标,利用线性插值生成初始轨迹。设定初始时刻 。
- 上层优化阶段:
- 对于每个迭代步 ,固定当前机械臂状态,随机采样底座候选轨迹;
- 针对每个底座候选随机采样交互轨迹并计算期望成本,选择期望值较低的候选作为新的底座状态;
- 更新底座轨迹直到满足终止条件。
- 下层优化阶段:
- 固定优化后的底座轨迹,利用 Dual Annealing 算法对机械臂轨迹进行细化;
- 在每次迭代中,通过 IK 求解器更新机械臂关节角度,并计算平滑性与碰撞成本;
- 最终确定机械臂的最优轨迹,使末端执行器精准到达目标路标。
-
终止:当整体目标函数收敛或达到最大迭代次数时,输出最终生成的轨迹。
-
实验与评估
为了验证 MoManipVLA 的有效性,我们在模拟环境与真实机器人平台上进行了实验。下面详细介绍实验设置、评估指标以及结果分析。
3.1 OVMM 基准测试
我们在 Open Vocabulary Mobile Manipulation (OVMM) 基准测试平台上进行实验。该平台包含 60 个模拟场景模型以及超过 18,000 个 3D 物体模型。任务定义为 "将目标物体从容器 A 移动到容器 B",涵盖导航、目标定位、抓取和放置等多个阶段。
我们的方法分别实现了4.2%的总体成功率和11.2%的部分成功率增益。这表明我们的方法可以协调机器人底座和手臂的运动,使末端执行器与目标对象保持合理的空间关系。
下表展示了各方法在 OVMM 模拟器上的详细对比结果。
3.2 真实世界实验
我们使用hexman echo plus底座和RM65机械臂组成移动实验平台,利用Grounding SAM3获取机械臂和目标物体mask,以分别用于生成碰撞查询点和构造不包含目标物体的ESDF。我们遵循ORB-SLAM设定使用Realsense T265来获取相机实时位姿。得益于预训练VLA模型的泛化能力,仅使用50个样本完成VLA微调,在移动操作任务上达到40%的成功率。可视化结果如图4所示。
图4 真实世界移动操作可视化
-
讨论4.1 方法优势
-
高泛化能力
MoManipVLA 能够利用大规模数据中学到的知识,实现跨任务、跨场景的高泛化性。实验结果显示,在仅 50 个样本的微调下,真实环境任务的成功率已达到 40%,证明了该方法在数据稀缺场景下的有效性。 -
物理可行性保障
MoManipVLA 生成的轨迹在物理上更为安全和可执行。可达性、平滑性和避碰三重约束的引入确保了生成轨迹不仅满足任务目标,同时符合机器人运动学与动力学约束。 -
高效的双层优化框架
将高维度的全身搜索问题分解为底座与机械臂两个子问题,通过双层优化策略降低了计算复杂度,系统在保持高成功率的同时实现了实时性能。
4.2 方法局限性与未来工作
尽管 MoManipVLA 在多任务上取得显著进展,但其仍依赖预训练模型的质量、存在搜索空间非凸局部最优问题以及长时任务规划不足,未来将通过引入全局优化方法、基于学习的搜索策略和集成任务规划模块等手段加以改进。
参考文献
1 Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864, 2024.
2 MooJinKim,KarlPertsch, SiddharthKaramcheti, TedXiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
3 Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159, 2024.
#GAIA-2
Wayve全新世界模型来了~GAIA-2
- 论文标题:GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2503.20523
- 项目主页:https://wayve.ai/thinking/gaia-2/
- 星球链接:https://t.zsxq.com/i1P7b

核心创新点:
1. 可控多摄像头一致性的高分辨率视频生成
- 采用潜在扩散模型(Latent Diffusion Model)架构,支持同时生成5个视角的高分辨率视频(448×960),确保跨摄像头视角的时空一致性(spatiotemporal coherence)。通过**时空分解Transformer(Space-Time Factorized Transformer)**与相机参数编码,解决了多视图同步生成的难题,满足自动驾驶系统对多传感器输入的需求。
2. 细粒度结构化条件控制机制
引入多模态条件接口,支持对以下元素的精准控制:
- 车辆动力学(如速度、曲率);
- 动态代理状态(3D边界框的位置、朝向、类别);
- 环境元数据(天气、时间、地理区域、车道类型、交通信号);
- 外部语义嵌入(CLIP文本/图像嵌入、专有驾驶场景嵌入)。
通过**自适应层归一化(Adaptive Layer Norm)和交叉注意力(Cross-Attention)**实现多条件融合,生成场景的多样性与可控性显著提升。
3. 高效连续潜在空间建模
- 相比前代模型GAIA-1的离散潜在空间,GAIA-2采用连续潜在空间,结合32×空间压缩率与64通道高语义维度,在压缩效率(总压缩率384×)与重建质量间取得平衡。通过**流匹配(Flow Matching)**训练框架与双模态时间分布策略(Bimodal Logit-Normal Distribution),优化了潜在状态的预测稳定性与生成质量。
4. 灵活推理模式与编辑能力
支持四种生成模式:
- 从零生成(From-Scratch Generation);
- 自回归长时预测(Autoregressive Rollout);
- 时空修复(Spatial-Temporal Inpainting);
- 场景语义编辑(Real-Scene Editing)(如修改天气、道路布局)。
通过分类器无关指导(Classifier-Free Guidance)与选择性空间噪声注入,实现复杂场景的精细化控制。
5. 大规模异构数据驱动训练
- 基于覆盖英、美、德三国的25万小时驾驶数据(5-6摄像头、多车辆平台),涵盖多样地理环境与边缘案例。通过地理隔离验证策略(Geographically Held-Out Validation)与联合概率分布平衡,确保模型泛化能力,生成内容覆盖典型场景与安全关键事件(如紧急制动、危险变道)。
6. 跨模态潜在嵌入集成
支持与外部模型的深度集成,例如:
- CLIP嵌入实现零样本语义控制;
- 专有驾驶场景嵌入编码高抽象场景语义(如超车、路口转向)。
该设计扩展了生成场景的语义连贯性,并为下游规划模块提供兼容接口。
ADS-Edit
- 论文标题:ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
- 论文链接:https://arxiv.org/abs/2503.20756
- 星球链接:https://t.zsxq.com/OtKim
核心创新点:
1. 多模态知识编辑框架
- 首次提出面向自动驾驶系统的结构化知识编辑范式,集成摄像头、激光雷达、雷达等多传感器数据的语义关联与动态修正机制,支持感知-决策闭环中的知识一致性验证。
2. 时空对齐的增量式标注
- 开发基于时空约束的半自动标注算法(ST-IAA),实现多模态数据在时序维度(0.1s级同步精度)和空间维度(厘米级配准误差)的精准对齐,支持动态场景的增量式知识更新。
3. 长尾场景覆盖增强
- 构建包含21类罕见场景(极端天气、异形障碍物等)的多模态知识图谱,通过对抗生成与物理仿真融合技术,将边缘案例的覆盖率提升至89.7%(基准数据集对比)。
4. 可解释性编辑评估体系
- 提出知识编辑质量的三维评估指标(KE3:一致性、完备性、可迁移性),集成基于因果推理的错误溯源模块,使模型修正过程的可解释性提升42.6%(消融实验数据)。
SaViD
- 论文标题:SaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
- 论文链接:https://arxiv.org/abs/2503.20614
- 论文代码:https://github.com/sanjay-810/SAVID
- 星球链接:https://t.zsxq.com/2J4YF
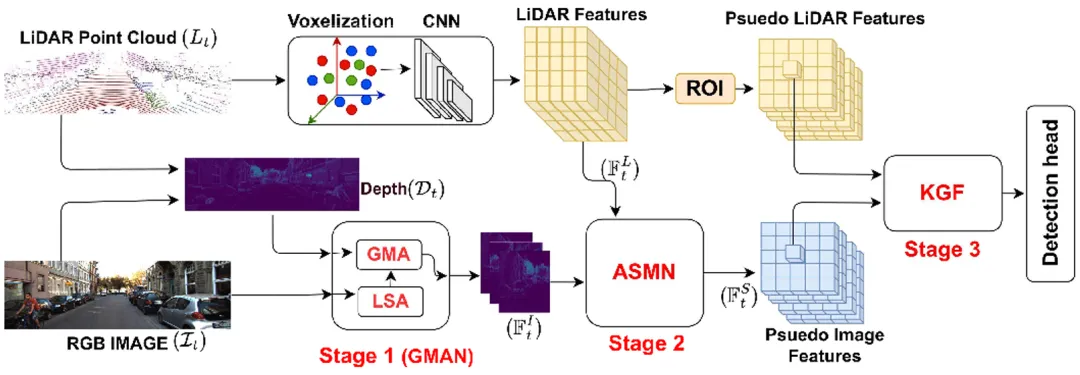
核心创新点:
1. GMAN(全局记忆注意力网络)
- 提出结合局部-全局注意力的视觉Transformer架构,首次将LiDAR生成的深度图(Dt)作为全局查询(Global Query),通过频域FFT-iFFT层增强图像特征提取。其Global Memory Attention (GMA)模块通过跨模态注意力机制(LiDAR点云与图像特征交互)实现远距离场景的全局上下文建模,并引入LSTM进行时序特征累积。
2. ASMN(注意力稀疏记忆网络)
- 设计单阶段稀疏融合机制,通过稀疏注意力(Sparse Attention)与LSTM耦合,解决LiDAR体素特征(FLt)与图像特征(FIt)的跨模态对齐问题。首次将LiDAR体素特征作为全局查询,与图像特征的键值对进行动态关联,生成跨模态对应图(Correspondence Map),提升稀疏点云与高分辨率图像的融合鲁棒性。
3. KGF(KNN连通图融合)
- 提出无参数的基于KNN的图融合技术,通过余弦相似度计算LiDAR伪点云(FLt)与图像特征(FSt)的局部邻域关联,采用通道加权策略(Channel-weighted Sum)实现多模态特征的空间对齐。该方法无需可学习参数,通过几何约束增强远距离目标的定位精度。
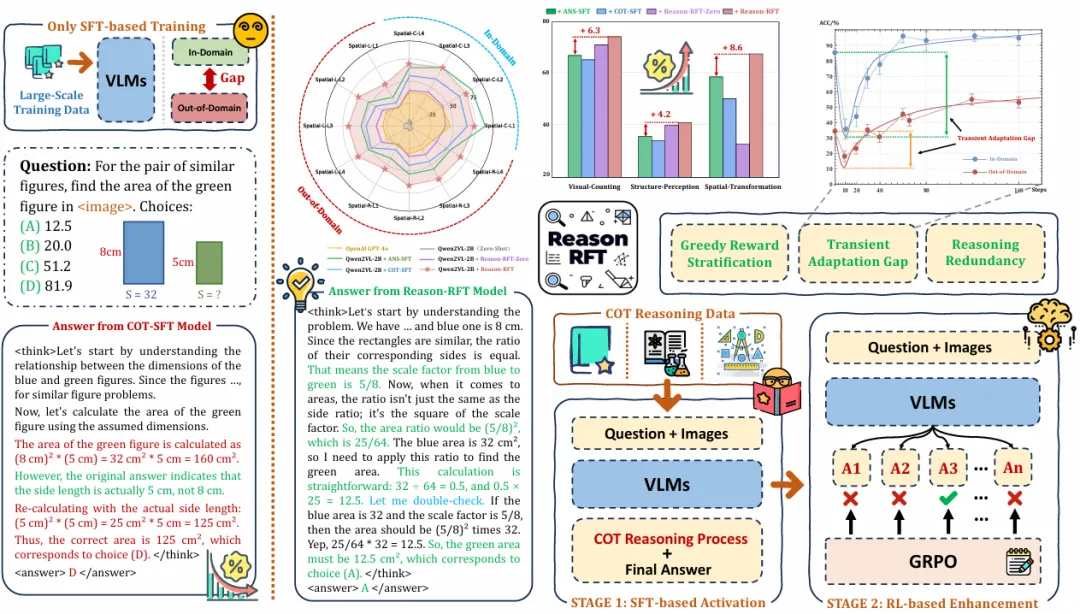
Reason-RFT
- 论文标题:Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning
- 论文链接:https://arxiv.org/abs/2503.20752
- 星球链接:https://t.zsxq.com/Svye4
核心创新点:
1. 两阶段强化微调框架
- SFT + GRPO协同优化 :
首创性结合监督微调(Supervised Fine-Tuning, SFT)与组相对策略优化(Group Relative Policy Optimization, GRPO),形成两阶段训练范式。
- 阶段1(SFT激活推理潜力) :通过高质量领域特定数据集(含Chain-of-Thought推理链)激活模型基础推理能力。
- 阶段2(GRPO强化推理极限) :引入GRPO算法,通过动态奖励机制(格式奖励+准确性奖励)推动模型突破推理边界,增强跨任务泛化性。
2. 多维度奖励机制设计
- 混合奖励函数 :
- 格式奖励(Format Reward) :强制模型生成结构化推理过程(如
<summary>和<caption>标记),确保逻辑可解释性。 - 准确性奖励(Accuracy Reward) :结合精确匹配与部分匹配奖励(Partial Matching),动态平衡推理严谨性与灵活性。
- 部分匹配机制 :允许对部分正确步骤赋权,缓解传统强化学习对完全正确路径的过度依赖。
3. 领域自适应数据集构建
- 跨模态任务覆盖 :重构涵盖视觉计数(Visual Counting)、结构感知(Structure Perception)、空间变换(Spatial Transformation)的标准化数据集(60K训练集+6K测试集)。
- 严格数据筛选 :通过去遮挡、冗余动作消除、多步位移合并等策略,确保数据唯一性与解空间清晰性。
4. 性能与效率突破
- 跨域泛化优势 :在OOD(Out-of-Domain)场景中表现稳定,显著超越传统SFT及纯RL方法(如CoT-SFT)。
- 数据效率 :仅需20%训练数据即可达到SFT基线95%性能,支持少样本学习场景。
- 多任务统一性 :在几何理解、空间推理等任务中实现统一建模,降低领域迁移成本。
#智驾平权时代的六剑客~
当主机厂开始卷智驾普及竞赛时,一些智驾公司却陷入了没有定点项目可做的困境。
某主打低阶L2业务的智驾公司在某头部主机厂的一系列定点项目被取消,说明浑水摸鱼的"关系"时代已经结束了,各家开始真正的比拼技术实力和产品力。
过去两家的关系堪称"老铁",这家智驾公司每年都从这家头部主机厂获得大量的定点项目。
变化源自于2月10日晚比亚迪的智驾发布会,这家头部主机厂将10万以上车型的低阶L2全部取消,改为标配中阶方案。并且打包成一个平台,统一交给了擅长中高阶、具有规模化量产能力的智驾供应商。
丢了定点,导致原本谈好的融资也黄了。对这家公司来说,Winter is coming。
而面临这样处境的智驾公司并不止这一家,今年主机厂定点的流向变了,这也预示着智驾公司靠"关系"吃饭的时代结束,靠技术本事吃饭的时代来临。
华为,魔门塔,地平线,轻舟,元戎,大疆,构成了智驾新时代的六剑客。预计这六剑客2025年的中高阶定点量产将达到数十个车型,少的也有一二十个车型,智驾平权时代的六剑客迎来长坡厚雪时代。
反观另外一些"明星智驾公司",忙于自己内部纷争和争权夺利,逐渐的退出了智驾的牌桌,在2024年接连丢掉定点,以至于到现在还没有中高阶定点量产项目。智驾平权时代的六剑客开始了行业的拨乱反正,良币驱逐劣币时代真正开始。
从2024年上半年率先攻下城区无图NOA的三剑客华元魔,到2025年强势崛起的平台化三剑客华为、魔门塔、轻舟,加上传统四大豪强地大华魔,一起构成了2025年智驾平权时代的六剑客。
- 平台化订单时代
进入25年,主机厂的定点项目正在从算法能力差的智驾公司流向算法好、工程能力强的智驾公司。
大批做低阶L2的智驾公司陷入困境,要么拿不到定点,要么手里的定点量大幅缩水。背后的原因很简单,原本10万到20万的车型大量搭载的是低阶L2,今年主机厂将低阶L2改为标配中阶方案。而这些智驾公司又不具备中阶的能力,被主机厂扫地出门是必然之举。
拿不到定点,这些智驾公司未来的命运可想而知。
定点流向了擅长做中高阶智驾的公司,比如智驾六剑客,华为、魔门塔、地平线、轻舟、元戎、大疆。智驾六剑客替代了原来做低价L2的智驾公司,而且不少拿到的还是平台化订单(十个车型起步的订单)。
智驾行业马太效应出现,项目在快速的向少数智驾公司集中。这和智驾进入平台化阶段有关系。
主机厂在卷智驾上普遍性的采取了平台化做法。
目前来看传统主机厂规划了中算力(80到100tops)、中高算力(200tops左右)、高算力(500tops以上)的三种平台,同一个平台都是统一的软硬件配置。不同的车型按照能承受的智驾软硬件成本分别规划不同算力平台。
头部主机厂规划一个平台,少则覆盖一二十个车型,多则几十个车型。而主机厂挑选智驾供应商的逻辑也变了,倾向于将一个平台选择一两个供应商来做,而不是像过去"海王选妃"的分散模式,一两个车型就选一个智驾供应商。
平台化量产能力,也成为主机厂挑选智驾供应商最看重的点之一。具有平台化能力的智驾公司,成为主机厂优先的选择。
比如某头部主机厂原本规划了一个智驾平台包含十多个车型交给了一家智驾公司来做,在比亚迪智驾发布会之后,又追加了十个车型给这家智驾公司。
主机厂锅里的肉不再是分着吃了,而是集中给少数公司吃。这也意味着平台化催生了大客户订单,拿到一个平台化的订单,少则十多个车型,多则几十个车型。
都有谁拿到了平台化的订单呢?目前来看,华为、Momenta、轻舟都拿到了。
华为大量拿到"投华"的国企系主机厂订单,Momenta则是拿到大批海内外主机厂的中高阶订单,而从L4转型做量产稍晚的轻舟,也跑到了前头,拿到数家头部主机厂的平台化订单,手握量产车型达到几十个,量产规模将达到上百万辆。
正是因为拿到了平台化的订单,华为、Momenta、轻舟手握的定点项目以及量产规模位列第一梯队。
- 生死的门槛
智驾行业到了淘汰赛阶段,一些公司开始在举步维艰的挣扎。
比如某头部主机厂孵化的智驾公司A,就被整顿重组了一番。按说作为主机厂的"亲儿子",在今年智驾普及时最应该受益的,但是由于自身的算法和量产能力不行,非但没吃到肉,反而使这家头部主机厂对其非常不满,花了那么多钱,到了要打仗的时候上不了战场。
A公司在成立时顶着"头部主机厂+技术大牛"的帽子,颇为风光。但这几年做的都是"套壳"的事,算法要么是买的要么是供应商在幕后做Tier 2,自己就是一个总集成的角色。
虽然A公司对外一直宣称量产了很大规模、研发了中高阶方案,但是这家头部主机厂高层是心里非常清楚:花了很多钱却是技术空心化的结果。
到了今年,高层的不满转化为整顿。自研业务收归到研究院,剩余的管理供应商的业务也由高层的嫡系掌管。而原管理团队被架空,作为创始人的技术大牛,成了对外PR宣传的"吉祥物"。
行业内的另一家智驾公司B,则是陷入了没有项目可做、融不来钱的生死边缘。B公司在行业一直是作为明星独角兽存在的,也拿到了一家头部主机厂的大客户订单。却因为缺乏大规模平台化量产的能力,导致量产暴雷,最终被该主机厂清理出门。
智驾普及,也是许多智驾公司生存还是覆灭的时刻。
对于智驾公司来说,未来想生存下来脱颖而出需要具备两个硬性能力条件,否则就是覆灭。
一是能拿到主机厂平台化订单的能力。这样的大客户订单意味着粮草,既是丰厚的项目收入,也是吸引资本投资的筹码。
二是具备技术升维向上做城区NOA的能力。智驾技术每年都在迭代,今年卷的是高速NOA普及,未来就是卷城区NOA的普及,只有具备技术升维的能力,才能持续留在牌桌上。
而想要具备这两种能力,又很考验一家公司的内功,需要从技术、战略、节奏等几方面都做对做好。对于智驾六剑客而言,能在过去几年的腥风血雨中存活下来,并不断壮大,公司的老板和管理层显然是有这种大局观的。
华为的技术实力有目共睹,不仅智驾做的好,还能教传统主机厂造车;Momenta一直是传统主机厂依赖的在智驾上追赶新势力重要帮手;轻舟则是L4公司转型而来,在技术上有深厚的积累,注重智驾方案生命周期的性价比。
之所以2025年华为、Momenta、轻舟能拿到平台化订单,很重要的原因是在过去两年锤炼了平台化量产的能力。所以在主机厂用平台化的方式卷智驾的时候,这三家起到了"客户口渴正好送水"的作用。
结束语
经过近几年的洗礼,特别是2025年比亚迪、吉利、奇瑞开始全系全车型标配中高阶智驾功能,智驾公司的分水岭开始出现,同时智能驾驶行业也开始拨乱反正,优秀的公司开始得到主机厂的青睐,特别是以智驾六剑客为代表的良币,开始驱逐市场上的劣币。
其实这也是许多行业演变的底层规律,一个行业处于早期阶段的时候是百花齐放,会诞生许多大大小小的公司,而到了成熟阶段,则会出现供给侧收敛,许多公司被淘汰,市场份额向少数公司集中。
2025年,智驾开始从早期阶段进入成熟阶段,那些既锤炼了内功又拿到平台化订单的公司,则会出现滚雪球的效应,持续的向前将雪球滚的更大。
#CoVLA
自动驾驶VLA数据集~
原文:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
针对VLM的自动驾驶领域的数据集数据量较少,本文采集了80个小时的驾驶视频构建了CpVLA数据集,包含详尽的传感器信息和全自动生成的语言文本描述。
文章以caption+轨迹 作为数据集的构成要件,例子如下
数据集依然存在不均衡的问题:自车静止和方向盘0度占据了数据集的绝大多数,数据不均衡现象十分严重
文章还提出了CoVLA-Agent架构,基于ViT和Llama2构建多模态大模型,mlp作为视觉连接器
场景描述用LLM直接出,轨迹把最后10个额外的token连接MLP输出
MLP单独训练ADE和FDE损失
测试了CoVLA的效果,可视化看起来使用GT caption的轨迹(蓝线)比使用预测caption的轨迹(红线)离GT(绿线)更远,说明好的caption对预测有辅助作用
文章统计了每个关键字对应的指标,发现以下关键字的轨迹误差较大,减速、左转、加速、弯道、右转,符合直觉
#ChatBEV
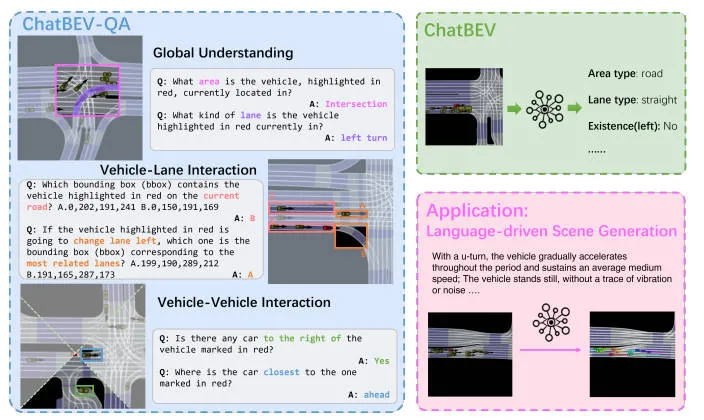
上交最新!VLM从BEV问答到场景生成,重新理解自动驾驶上帝视角~
在自动驾驶与智能交通领域,基于BEV地图的理解是实现安全决策的核心挑战之一。本文提出了BEV视觉问答基准 ChatBEV-QA,突破传统数据集任务单一、规模有限的瓶颈,覆盖全局场景、车辆-车道交互、车辆-车辆交互三大维度。此外,本文微调的视觉语言模型 ChatBEV 在多任务中表现卓越,在全局理解、车辆-车道交互以及车辆-车辆交互等诸多任务上均实现了80%的以上的精度,显著超越了现有的方法。
交通场景理解是一项基本任务,旨在感知和解释交通场景中的周围环境。它在智能交通系统和自动驾驶任务中起着至关重要的作用,通过实现智能的决策并确保车辆在现实条件下安全高效地运行,为下游任务奠定基础。例如,在智能交通系统中,交通场景理解通过分析车道结构、交通状况和车辆相互作用来优化交通流量并防止事故发生。在自动驾驶方面,它增强了实时运动规划以实现更安全的导航,并通过情境感知引导改进了场景模拟,确保结果更加精确和可控。
随着视觉语言模型 (VLM) 的发展,最近的研究探索了它们在交通场景理解中的应用。利用其卓越的推理和泛化能力,VLM 能够比传统的、特定于任务的方法更全面地理解场景,而后者往往缺乏整体方法。然而,这一研究领域仍处于早期阶段,充分利用 VLM 进行场景理解需要进一步研究。
为了更好地利用 VLM 的功能并将其无缝地融入到各种任务中,本文工作专注于使用BEV地图进行交通场景理解,这有两个主要优势:
- BEV 图像广泛应用于智能交通系统或自动驾驶,因为它们提供了清晰、直观的环境表征,并且可以轻松地从多模态感知输入中得出,从而确保与下游应用程序的顺利集成
- 直接使用 BEV 可让VLM充分利用其在推理方面的优势,同时减轻其在复杂感知处理方面的弱点,因为 BEV 地图可以独立于原始传感器数据获得。这不仅提高了计算效率,而且还提高了复杂交通环境中的准确性,使VLM更有效地应用于实际应用场景
然而,对 BEV 地图理解的研究一直受到限制,主要是由于缺乏高质量的 BEV 地图注释数据。因此,针对目前的挑战,我们在文中提出了一个名为ChatBEV-QA的Benchmark。该Benchmark是一个基于 BEV 地图的新型场景理解VQA数据集,旨在涵盖广泛的场景理解任务。在此数据集的基础上,我们进一步微调了一个名为ChatBEV的视觉语言模型以进行地图理解,从而实现语言驱动的上下文准确和逻辑一致的交通场景生成。
文章链接:https://arxiv.org/pdf/2503.13938#/;****
ChatBEV-QA数据集
自动化数据构建管道
我们提出了一个三步自动化流程,从 nuPlan 数据集生成 ChatBEV-QA 数据,如下图所示。首先,我们设计各种问题来涵盖全面的理解任务。然后,我们提取必要的注释并生成信息丰富的 BEV 图。最后,VQA 生成器根据问题创建VQA数据,标注和BEV地图。
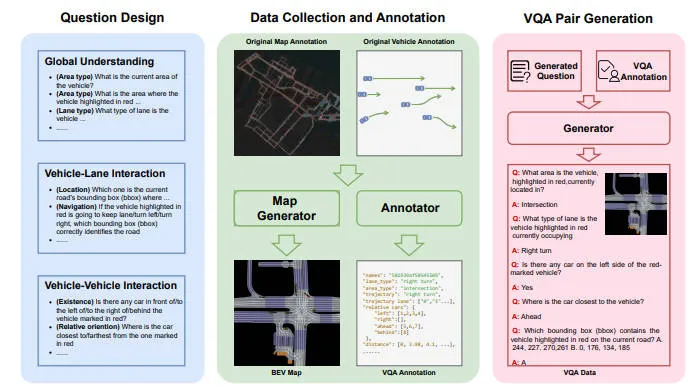
第一步:问题设计
在本文中,我们建议从三个方面进行全面了解,并据此进一步发展六种不同类型的问题。
- 全局理解:了解更广泛的环境背景对于预测车辆行为至关重要。不同的场景会产生不同的运动模式,例如,十字路口的车辆更有可能转弯,而停车场的车辆则倾向于保持静止。因此我们引入了area type和lane type两种关键问题。
- 车辆与车道的相互作用:最近的研究经常忽视车辆与车道的相互作用,而这对于响应道路特征、交通规则和环境因素的自适应导航至关重要。因此我们引入了location以及navigation两个重要的角度。
- 车辆与车辆交互:车辆与车辆交互对于空间关系建模至关重要,直接影响行为协调。因此引入了existence以及relative orientation两类问题。
这些问题提供了一个结构化的框架,用于理解场景中车辆行为和交互的各个维度。为了增加多样性,我们进一步为每种问题类型设计了多个模板。
第二步:数据收集和标注
nuPlan 的原始注释涵盖了车辆位置、速度和车道细节等基本信息。我们增强了数据集,并设计了一个注释器,该注释器具有广泛的基于规则的函数,可以提取高级语义信息并适用于设计的问题。我们通过迭代的人工参与审查过程严格完善函数的设计,确保其输出与人类判断紧密一致。
- area type代表指示车辆当前所处的区域类型;
- lane type指定车辆当前所在车道的类型;
- trajectory描述车辆未来 50 个时间戳的轨迹对应的类别;
- trajectory lane捕获接下来 50 帧中与轨迹对应的所有车道 ID;
- relative cars存储车辆周围四个方向的其他车辆的 ID;
- distance计算当前车辆与场景中所有其他车辆之间的距离;
第三步:VQA对生成
有了问题模板和注释,就可以通过 VQA 生成器生成问题答案对。对于车道类型和区域类型的问题,生成器会随机选择一个模板并使用相应的注释文本作为答案。对于位置和导航问题,我们通过提供多项选择来简化问题。原始 nuPlan 数据集呈现长尾分布,例如直车道上有大量车辆,而转弯车道上车辆相对较少,导致答案类别分布不平衡,这可能会使模型性能偏向更常见的场景。为了缓解这个问题,我们采用了随机欠采样技术,在数据集构建过程中有选择地从多数类别中删除一定比例的样本,从而促进更均衡的分布。
数据集统计和指标
由于整个 nuPlan 数据集非常大,我们从 nuPlan-mini 拆分中构建数据,从而提供更小、更易于管理的子集。总体而言,我们的 ChatBEV-QA 包含 25331 张 BEV 图像的 137818 个问答对,其中 21634 张 BEV 图像中有 116112 个问题用于训练,3697 张 BEV 图像中有 21706 个问题用于测试,平均每张图像约有 5.44 个问题。
下图展示了训练集上每个问题的问题类型和答案的分布,凸显了 ChatBEV-QA 的均衡组成。
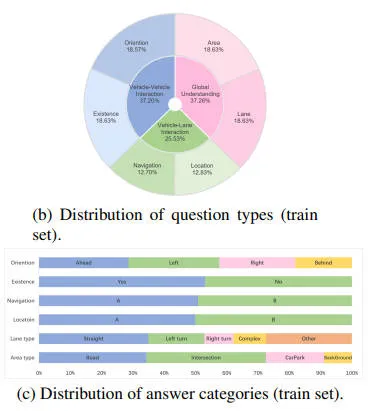
由于我们设计的问题的答案属于特定集合,因此我们使用 top-1 准确率作为评估指标,这与以前的 VQA 工作中的常见做法一致。我们还分别评估了不同问题类型的表现,从而可以更详细地了解模型处理场景理解各个方面的能力。
ChatBEV系列模型
除了提出的数据集以外,我们也提供了我们的基线模型。由于 BEV 表示固有的紧凑性,其包含不同于自然图像的特定结构和与任务相关的语义信息,因此现有的 VLM 直接应用于此任务被证明是不够的。
为了解决这个问题,我们通过使用 LoRA 的视觉指令调整对几个先进的 VLM 进行了微调,并根据 BEV 地图理解的独特需求对其进行了定制。
语言驱动场景生成
在本文中,我们提出了一种新颖的基于扩散的架构,其中 ChatBEV 充当地图理解提取器,提供全面的场景理解,从而有助于生成更精确、更具情境信息的输出。其整体流程如下图所示。
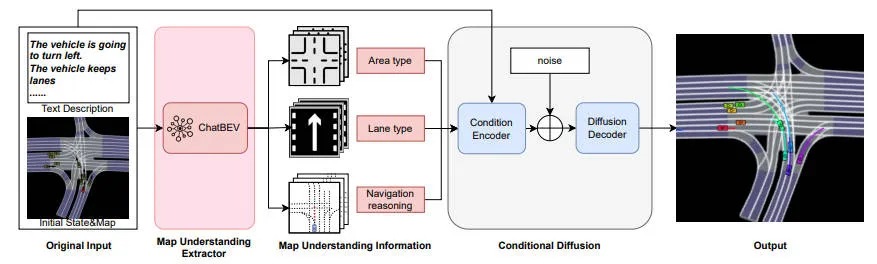
地图理解提取器
给定场景中车辆的初始状态和相应的文本描述,我们首先提取地图理解信息,并将其与原始输入整合,形成下一个模块的最终输入。这里我们考虑两种有助于后续场景生成的地图理解信息,包括全局理解信息和场景推理信息。考虑到车辆对场景的整体理解,例如其当前所在的区域和车道,会影响其特定的运动模式,我们引入了全局理解信息以及车道类型的one-hot向量。为了提供更精确、文本对齐的导航指导,我们引入了导航推理信息,这表示车辆根据文本中描述的轨迹类型可能选择的最可能车道的中心线数据。
条件扩散模型
我们的条件编码器旨在有效地整合各种条件输入,并提供信息丰富的条件嵌入,从而促进后续的解码过程。在提取器之后,条件编码器为每个场景接受三种类型的输入:初始状态、文本描述和理解信息。对于每个输入,采用相应的前馈编码模块来提取嵌入,然后沿时间维度进行广播,之后将它们连接起来形成最终的条件嵌入。
给定条件输入,扩散解码器通过迭代细化噪声数据,在每个时间戳生成预测轨迹。这里我们采用 CTG++ 作为我们的扩散解码器模块。该过程首先将来自条件编码器的条件嵌入与来自前馈模块的预测未来轨迹嵌入沿时间维度连接起来。采用去噪步骤 k 的正弦位置编码来结合时间动态。编码轨迹经过时间注意块来捕捉代理关系,然后经过空间注意块来捕捉几何关系。然后,地图注意层将车道点转换为车道向量,通过多头注意实现地图感知。最后,将编码的轨迹投影回输入维度,产生预测的动作轨迹,然后通过动态函数获得结果。
实验结果
我们在ChatBEV-QA上进行了实验,并将实验结果汇总在了如下的表格中。根据相应的实验结果可以看出,即使经过仔细的训练,传统方法也难以准确解释 BEV 图并生成精确、合理的答案。
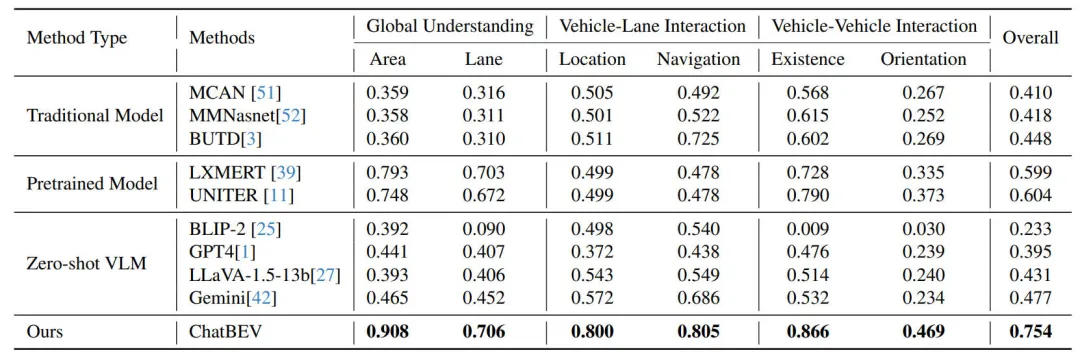
虽然 LXMERT和UNITER比传统方法取得了显著的进步,凸显了利用先验知识和预训练视觉语言模型的泛化能力的好处,但它们的性能仍然不够理想,特别是在车道交互推理方面,凸显了它们在适应 BEV 地图理解方面的局限性。Zero shot VLM 的表现与经过训练的传统方法相当,这表明领域差距显著影响了 VLM 的性能。相比之下,我们的 ChatBEV 在对数据集进行微调后,显著超越了现有方法,证明了我们的数据集和微调模型对于场景理解任务的有效性。
此外,我们通过微调几个最先进的模型来评估不同基础 VLM 的影响,包括 LLaVA、BLIP和 InternLM-Xcomposer2,相关的实验结果汇总在如下表格中。

为了评估场景理解对场景生成的影响并评估 ChatBEV 的贡献,我们比较了模型在各种输入条件下的生成性能,实验结果如下表所示。
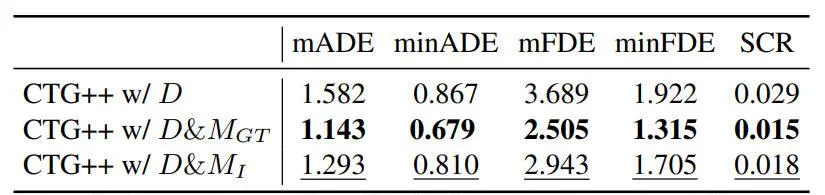
通过实验结果可以看出,仅提供文本输入对于准确场景生成的指导有限。添加真值地图理解可显著提高重建能力。虽然 ChatBEV 可能会在场景理解中引入一些错误,但它的加入仍然提高了性能。
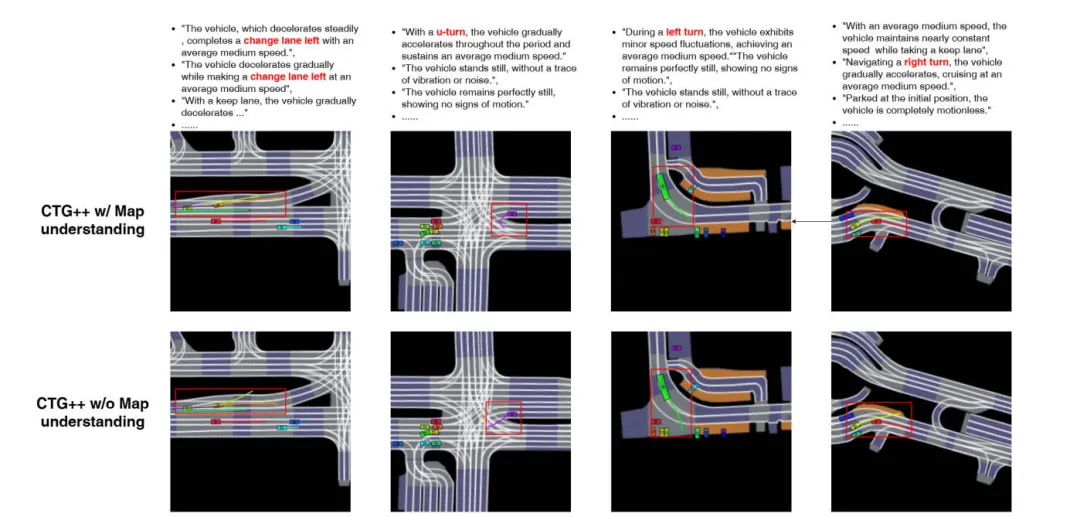
我们对结合地图理解信息的方法和不基于 CTG++ 扩散解码器的方法进行了定性比较。下图展示了几个示例。可以看出,在结合地图理解信息后,该模型表现出对车道地图的更好、更直观的理解,并减少了跑出车道的情况。
结论
在本文中,我们引入了 ChatBEV-QA,这是一个可扩展的 BEV的VQA 基准,涵盖了广泛的场景理解任务。在此基础上,我们的 ChatBEV 模型在全面场景理解方面表现出色,可以提供高级指导,实现更可控的场景生成。此外,我们的基准测试目前仅关注静态场景和与车辆相关的任务,缺乏理解动态场景和行人活动的能力。我们未来的工作将扩展到更复杂的环境,结合多智能体交互、时间推理来增强通用性。
#自动驾驶中基于学习的三维重建:综述
摘要
本文介绍了自动驾驶中基于学习的三维重建:综述。基于学习的三维重建已经成为自动驾驶领域的一项变革性技术,它通过高级的神经表示实现了动态和静态环境的精确建模。三维重建为自动驾驶领域中重要任务提供了开创性解决方案,例如场景理解和闭环仿真。本文从检查输入模态开始,研究了三维重建的细节,并且对最新的研究进展进行多角度的深入分析。具体而言,本文首先系统性地介绍了基础知识,包括基于学习的3D重建的数据格式、基准和技术基础,有助于根据硬件配置和传感器套件即时确定合适的方法。然后,本文回顾了自动驾驶中基于学习的三维重建方法,根据子任务对方法进行分类,并且进行多维分析和总结,以建立全面的技术参考。本文在自动驾驶中基于学习的三维重建背景下,总结了其发展趋势和现存的挑战。本文希望本综述能够激发未来的研究。
主要贡献
本文的贡献总结如下:
1)本文引入了基于学习的三维重建基础知识,包括数据模态、基准和技术基础,实现了与任务特定要求一致的快速算法选择;
2)本文对驾驶场景中不同重建范围的相关工作进行系统性总结,实现了对特定目标的多角度分析和跨方法比较;
3)本文分析了三维重建在实际自动驾驶任务中的应用,突出了未来发展的新兴技术趋势。
论文图片和表格
总结
尽管基于学习的三维重建为自动驾驶系统引入了变革性技术,但是在可扩展性、动态场景重建和实时约束等各个方面仍然存在关键挑战。本项综述系统性地概述了自动驾驶中基于学习的三维重建技术,涵盖了数据、技术进展和新兴趋势。本文从基础知识到尖端技术进行依次概述,为研究者和从业者提供了可行的见解和参考。本文希望本项综述能够激发未来进一步的创新。
#OpenDriveVLA
慕尼黑工大最新!基于大型VLA模型的端到端自动驾驶~专为端到端自动驾驶设计的VLA模型
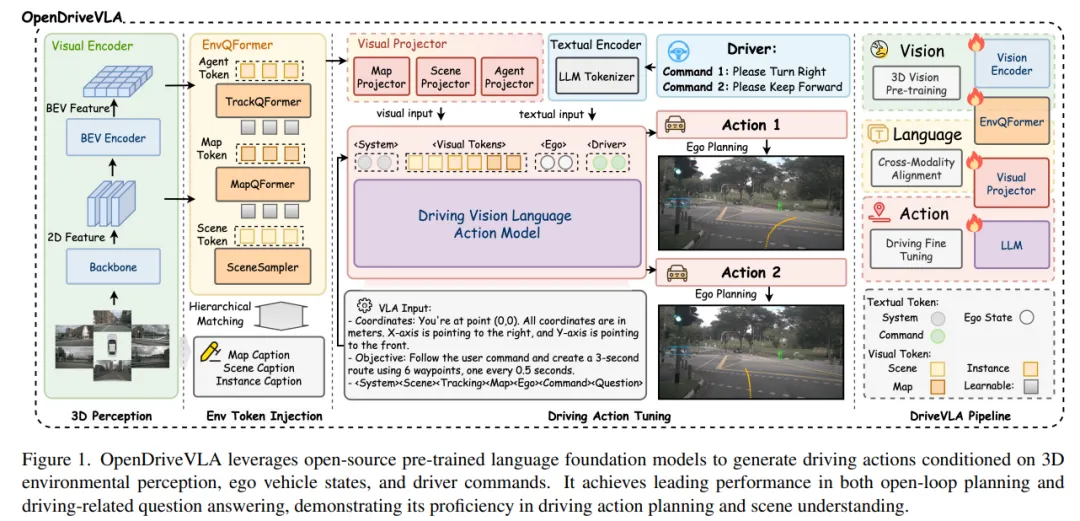
OpenDriveVLA是一种专为端到端自动驾驶设计的视觉语言动作(VLA)模型。OpenDriveVLA基于开源预训练的大型视觉语言模型(VLMs),以3D环境感知、自车状态和驾驶员指令为条件,生成可靠的驾驶动作。为了弥合驾驶视觉表征与语言嵌入之间的模态差距,提出了一种分层视觉语言对齐过程,将2D和3D结构化视觉token投影到统一的语义空间中。此外,OpenDriveVLA通过自回归的车辆 - 环境 - 自车交互过程,对自车、周围车辆和静态道路元素之间的动态关系进行建模,确保在空间和行为上都能提供信息的轨迹规划。在nuScenes数据集上进行的大量实验表明,OpenDriveVLA在开环轨迹规划和与驾驶相关的问答任务中均取得了最先进的成果。定性分析进一步说明了OpenDriveVLA在遵循高级驾驶指令方面的卓越能力,以及在具有挑战性的场景中稳健生成轨迹的能力,突出了其在下一代端到端自动驾驶中的潜力。我们将发布代码,以促进该领域的进一步研究。
项目链接:http://drivevla.github.io
背景介绍与领域发展
端到端学习框架已成为自动驾驶领域一种很有前景的范式,它使感知、预测和规划能够在统一的神经网络中进行联合优化。通过利用大规模驾驶数据,这些模型直接从原始传感器输入中学习驾驶策略,在各种驾驶场景中都取得了令人瞩目的性能。尽管取得了显著进展,但现有的端到端驾驶方法仍然面临严峻挑战,特别是在对长尾场景的泛化能力有限、对复杂驾驶场景中高级语义的理解不足,以及任务驱动规划的推理能力不够灵活等方面。
与此同时,大语言模型(LLMs)和视觉语言模型(VLMs)展现出强大的context学习、常识理解和零样本-少样本泛化能力。这些新兴能力凸显了它们在自动驾驶领域的潜力,尤其是考虑到对各种现实世界驾驶条件下稳健场景理解的迫切需求。然而,直接将现有的VLMs应用于自动驾驶面临着根本性的挑战。首先,当前的VLMs主要针对静态2D图像-语言任务进行优化,在动态3D驾驶环境中的空间推理性能较差。此外,这些模型经常产生幻觉输出,即不正确或过于自信的描述,这在自动驾驶中会严重危及安全。
受这些限制的启发,我们的工作旨在回答一个核心问题:如何利用VLMs的新兴能力生成可靠的驾驶动作,同时降低幻觉风险,并平衡推理速度和规划有效性?
OpenDriveVLA是一种专为端到端自动驾驶设计的新型视觉语言动作模型。OpenDriveVLA利用开源预训练的语言基础模型,以多模态输入(包括3D环境感知、自车状态和驾驶员指令)为条件,生成可解释且可靠的驾驶轨迹。OpenDriveVLA在统一模型中弥合了视觉语言理解与轨迹生成之间的差距。它在开环规划和与驾驶相关的问答基准测试中经过严格评估,取得了领先的结果,展示了卓越的轨迹生成和驾驶场景理解能力。贡献总结如下:
- OpenDriveVLA是一种端到端的视觉语言动作模型,它以多模态输入为条件生成可靠的驾驶轨迹;
- 引入了一种分层视觉语言特征对齐模块,将结构化的2D和3D视觉token投影到统一的语义embedding空间中,以促进语言引导的轨迹生成;
- 设计了一种车辆 - 环境 - 自车交互过程,以捕捉自车、动态车辆和静态地图元素之间的交互,显著提高了复杂交通场景中运动预测的准确性和轨迹的可靠性;
- 在nuScenes数据集上进行的大量实验表明,OpenDriveVLA在开环规划和与驾驶相关的问答任务中均取得了最先进的成果,始终优于先前基于LLM的方法和端到端自动驾驶方法。
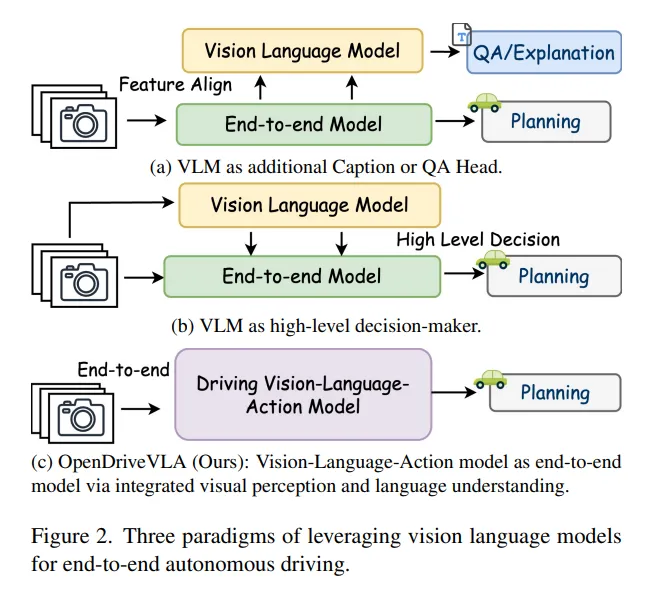
相关工作一览 1)端到端自动驾驶
自动驾驶经历了两个不同的发展阶段。传统方法依赖于模块化设计,将系统分解为感知、预测和规划组件。虽然这种结构确保了可解释性,并允许进行独立优化,但它们存在阶段之间的级联错误,并且没有针对最终规划目标进行全局优化。相比之下,端到端自动驾驶框架通过在统一的神经网络中联合优化感知、预测和规划来解决这个问题。这些模型直接从原始传感器输入中学习驾驶策略,提高了模型对各种驾驶条件的适应性。然而,现有的端到端方法仍然面临语义推理瓶颈,它们难以完全理解高级场景语义、推断复杂的车辆交互,并且难以适应动态的任务要求。此外,它们的决策过程仍然不透明,使得在长尾或未见场景中诊断故障案例变得困难。
2)多模态大语言模型
大语言模型在context学习、指令遵循和推理方面展现出强大的新兴能力。通过在海量的互联网规模数据上进行训练,这些模型获得了广泛的世界知识,并在各种任务中表现出很强的适应性。它们的成功也推动了大型视觉语言模型的兴起,这些模型通过将视觉编码器与语言模型集成,将这些能力扩展到跨模态推理中。诸如GPT-4V、LLaVA、DeepSeekVL和Qwen-VL等最先进的视觉语言模型在开放域任务中展示了强大的视觉理解和多模态推理能力。然而,这些模型主要在静态2D图像或视频上进行训练,在动态3D驾驶环境中的空间推理能力有限。此外,视觉语言模型容易产生幻觉,通常会给出过于自信但不正确的描述,这在安全关键的规划场景中构成了严重风险。最近,视觉语言动作模型已经出现,可以直接从视觉输入中预测动作,在机器人操作任务中表现出强大的性能。然而,这种基于语言条件的动作生成在端到端自动驾驶中的应用仍有待探索。
3)自动驾驶中的语言模型
大语言模型和视觉语言模型都已应用于广泛的自动驾驶任务,包括感知、场景描述、合成数据生成和高级决策。在端到端自动驾驶的范围内,现有工作通常遵循三种设计策略。如图2所示,一类研究将语言头(如字幕或问答模块)集成到驾驶模型中,以增强可解释性。第二类使用语言模型生成高级驾驶指令,如方向命令或抽象操作,随后由单独的规划模块将其解释为低级控制。这种方法允许语言模型影响决策,但在推理和运动规划之间保持模块化分离,使得联合优化具有挑战性。第三类直接应用视觉语言模型从单目视频输入中预测驾驶动作。这些方法处理2D图像,并根据视觉观察生成速度和转向命令,而没有对驾驶场景中的3D空间布局或多车辆交互进行显式建模。这限制了它们在复杂交通环境中对深度、遮挡和车辆动态进行推理的能力。这项工作旨在研究大语言模型如何在端到端自动驾驶框架中统一跨模态语义推理和3D实例感知轨迹规划。
OpenDriveVLA方法
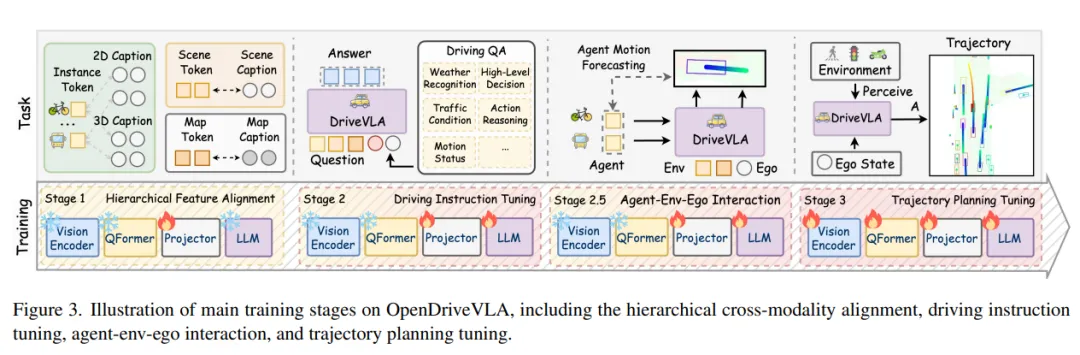
OpenDriveVLA的整体架构如图1所示,其多阶段训练过程在图3中进一步详细说明。OpenDriveVLA从一个预训练的视觉编码器开始,该编码器从多视图图像中提取token化的环境表示。然后,这些视觉token通过跨模态学习对齐到文本域。对齐之后,OpenDriveVLA进行驾驶指令调整,接着进行车辆 - 环境 - 自车交互建模。最后,OpenDriveVLA进行端到端训练,以在对齐的视觉语言token和驾驶指令的指导下预测自车的未来轨迹。
1)3D视觉环境感知
最近基于视觉语言模型的自动驾驶方法通常依赖于2D视觉编码器,其中视觉token的选择和注意力通过语言监督间接引导,通常以问答任务的形式。虽然这种设计在开放域视觉语言应用中有效,但它缺乏明确的3D空间定位和结构化的目标级注意力,这可能会在安全关键的驾驶场景中导致严重的幻觉。为了缓解这个问题,OpenDriveVLA采用了以视觉为中心的查询模块,模型首先通过3D视觉任务学习关注与驾驶相关的对象和地图token,确保可靠的视觉token proposal。
给定一组多视图图像 ,视觉模块首先使用共享的2D骨干网络从每个图像中提取多尺度2D特征,表示为 (f2D) 。然后,这些2D特征在不同视图之间进行聚合,并提升到鸟瞰图(BEV)空间,生成BEV特征 。为了获得结构化的环境表示,采用了三个视觉查询模块:全局场景采样器 、车辆查询transformer 和地图查询transformer 。每个模块都专注于提取驾驶环境特定语义方面的token。全局场景采样器从多视图2D特征中编码周围的驾驶场景context,生成场景token 。车辆查询transformer检测并跟踪场景中的动态车辆,提取以车辆为中心的token ,其中 表示检测到的车辆数量。同时,地图查询transformer提取静态结构信息,如车道边界和可行驶区域,形成地图token 。通过以视觉为中心的感知任务,包括3D检测、跟踪和分割,视觉编码器生成结构化的环境token,以空间定位的方式捕捉动态车辆行为和静态地图结构。输出的token表示为 ,作为后续阶段的视觉环境表示。
2)分层视觉语言对齐
为了弥合提取的视觉token与预训练大语言模型的词embedding空间之间的模态差距,采用了分层视觉语言特征对齐策略。给定从3D视觉感知模块中提取的视觉token,引入了三个特定于token的投影器 。在训练过程中,从3D检测和跟踪任务中得到的每个活跃车辆查询 ,也会与相应的真实字幕 匹配。这些字幕提供了详细的描述,包括2D外观描述和3D空间位置。对于编码整体空间context和静态结构属性的场景和地图token,采用样本级对齐,其中每个token与场景级字幕 或 匹配。场景token 捕捉全局2D环境context,而地图token 编码诸如车道拓扑、道路边界和可行驶区域等结构元素。这些token中的每一个都与相应的字幕对齐,表示为 和 。在这个阶段,视觉编码器和预训练的大语言模型都保持冻结状态,只有特定于token的投影器是可训练的。前向对齐步骤公式如下:
3)驾驶指令调整
为了将高级驾驶知识嵌入到OpenDriveVLA中并增强其推理能力,我们在训练过程中引入了一个专门的驾驶指令调整阶段。没有在推理时进行显式的思维链(CoT)推理,因为这会显著增加延迟,而是通过有监督的指令调整将基本的驾驶知识提炼到模型中,以在推理速度和推理效率之间取得平衡。
在调整过程中,使用精心策划的驾驶指令问答数据集将语言领域的驾驶知识注入到模型中。该数据集涵盖了广泛的与驾驶相关的推理,包括感知理解、运动预测、注意力分配、动作推理和高级决策。通过在这些多样化的驾驶查询上进行训练,OpenDriveVLA学习对驾驶场景进行context理解、遵循命令,并生成在语义和行为上有依据的规划决策。我们将调整数据表示为指令 - 响应对 ,其中 。这里, 表示与驾驶相关的问题, 编码文本形式的自车状态。给定这种多模态输入,大语言模型以自回归的方式学习生成目标响应。在指令调整过程中,视觉编码器保持冻结状态,而特定于token的投影器和大语言模型设置为可训练。指令预测过程如下:
4)车辆 - 环境 - 自车交互
自动驾驶中可靠的轨迹规划需要对环境进行空间定位的3D表示。除了感知之外,它还必须理解自车与周围车辆之间的动态交互。有效的交互建模对于确保在现实世界驾驶约束下规划的轨迹既可行又无碰撞至关重要。然而,现有的预训练大语言模型缺乏对3D驾驶场景中空间推理的固有归纳偏差,因为它们主要在2D视觉语言和基于文本的数据集上进行训练。为了解决这个限制,引入了一个条件车辆运动预测任务,作为3D车辆 - 环境 - 自车交互建模的代理任务,使模型能够学习空间定位的运动模式。在这个阶段,OpenDriveVLA捕捉多车辆动力学的潜在结构,增强其场景感知轨迹生成能力,并改善在复杂交通场景中的决策。
给定场景和地图token以及自车状态 ,大语言模型基于投影的视觉嵌入 预测每个检测到的车辆的未来运动。车辆 的未来运动表示为一系列路标点 。预测的轨迹以场景context、地图结构和自车状态为条件,使OpenDriveVLA能够推断出具有交互感知和空间定位的运动序列。第 (i) 个车辆的学习目标公式为:
这为OpenDriveVLA提供了必要的空间先验,使其能够弥合高级语义推理与基于物理的运动规划之间的差距。
5)端到端轨迹规划
在这个阶段,OpenDriveVLA将未来的驾驶动作规划为未来几秒内的一系列路标点,表示为 。每个路标点 代表自车在时间步 (t) 的2D坐标 。为了使用大语言模型进行自回归生成,路标点首先被token化为一系列离散的文本token: 。然后,生成过程被转化为一个因果序列预测任务,其中每个token都基于视觉感知token 、自车状态 和驾驶命令 进行预测:
在训练过程中,整个模型,包括视觉编码器、跨模态投影器和大语言模型,进行端到端的联合优化。在推理时,模型以自回归的方式生成token化的轨迹 ,然后解码回数值路标点:
实验分析
1)训练数据
在nuScenes数据集上开展实验,按照标准将数据划分为训练集和验证集。OpenDriveVLA使用训练集以及对应的问答字幕进行训练,而验证集仅用于性能评估,以此确保能与之前的研究进行公平对比。各阶段的训练数据信息如表1所示。
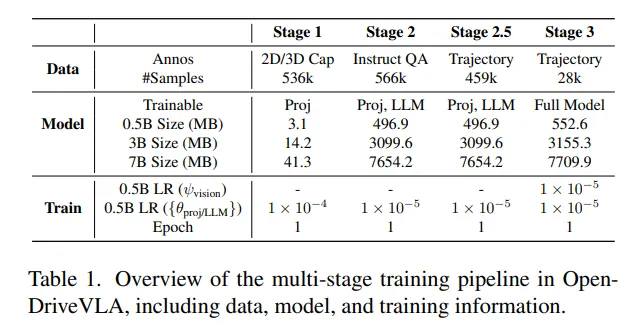
视觉语言对齐:在进行智能体特征对齐时,我们对实例字幕进行了后处理,这些字幕提供了单个物体的2D视觉描述。为进一步增强空间感知能力,每个物体的字幕都增加了相应的鸟瞰图(BEV)坐标,这样模型就能将物体属性与精确的空间位置关联起来。对于场景token,我们对多视图场景描述进行处理,将其合并为统一的摘要,以描述所有摄像头视角下的驾驶环境。对于地图token,结构化语言描述源自真实标注,将车道分隔线、人行横道和道路边界等地图元素转化为描述性文本。
驾驶指令调整:采用了多个源自nuScenes的面向指令的数据集,将特定的驾驶知识融入OpenDriveVLA。把多个数据集统一为标准化的基于指令的问答格式,其中包括从nuCaption、nuScenesQA和nuX数据集收集的与驾驶相关的问答对。每一个问答对都以结构化的环境视觉token和自车状态为条件,保证了不同数据源之间的一致性。这种多模态指令调整过程使OpenDriveVLA能够有效地将语言理解与环境感知和场景理解相结合,在语言空间中实现感知、推理和行动的衔接。
运动预测和轨迹预测 :在自车系统中对智能体运动预测和自车轨迹规划进行了公式化处理,模型直接预测每个实体相对于自车的局部坐标系内的未来位移,用于规划和预测。这种公式化处理以空间一致的方式捕捉了所有实体的运动动态。参照相关研究,自车状态被编码为文本输入,以确保在整个训练过程中模型都能感知自车状态。这两个任务都预测未来3秒的轨迹,采样间隔为0.5秒,每个轨迹产生6个路标点。
2)评估
在nuScenes基准测试的开环规划任务中对OpenDriveVLA进行评估,该模型在ST-P3和UniAD两种设置下接受评估。评估指标包括1秒、2秒和3秒时的L2位移误差,以及预测范围内的平均碰撞率。为了评估OpenDriveVLA的场景理解能力,在驾驶指令调整阶段之后,直接在三个驾驶视觉问答(VQA)数据集(即nuCaption、nuScenesQA和nuX)上评估其性能。VQA评估采用标准的MLG指标,包括BLEU、METEOR、CIDEr、BERT-Score等。
3)实现细节
OpenDriveVLA中的3D视觉感知模块采用以视觉为中心的设计,使用ResNet101骨干网络进行2D特征提取。该感知backbone网络通过3D目标检测、目标跟踪和地图分割的多任务学习进行预训练,得到的BEV特征图空间分辨率为200×200。为构建统一的场景表示,全局场景采样器对每个相机视角应用2D自适应池化,然后将池化后的多视图特征连接成一个全局场景token。智能体和地图token则从各自的查询transformer模块的最后一层提取。每种类型的token随后使用具有GeLU激活函数的单独两层MLP映射到语言空间。这里采用Qwen 2.5-Instruct作为预训练的大语言模型,在训练过程中对其进行全参数调整。模型在4个NVIDIA H100 GPU上进行训练,bs大小为1,大约需要两天完成训练。推理时将解码温度设置为0,以确保生成确定性的轨迹。在第3阶段,冻结2D主干网络。详细的训练配置总结在表1中。
4)主要结果
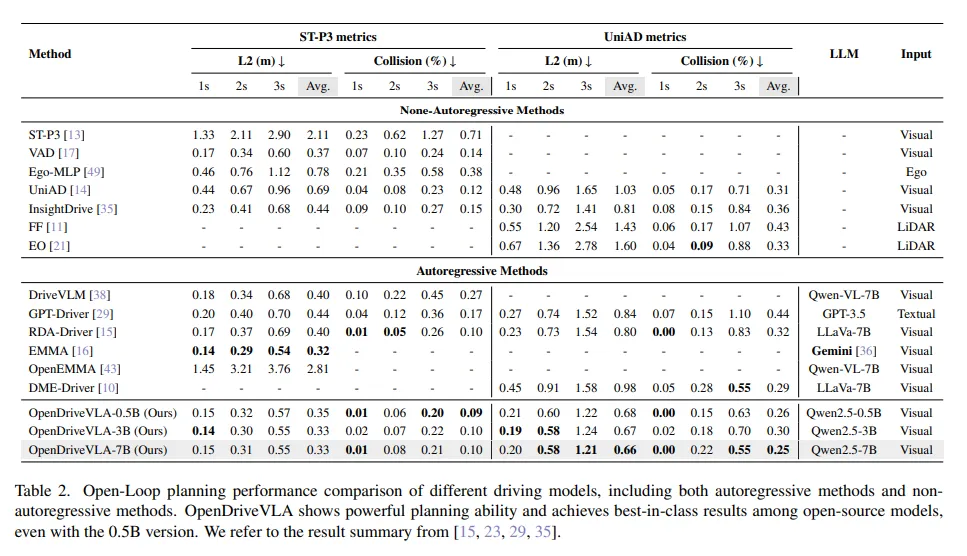
开环轨迹规划:使用ST-P3和UniAD指标在开环轨迹规划任务中评估OpenDriveVLA,以全面评估其在空间准确性和避撞方面的性能。如表2所示,OpenDriveVLA在两种设置下均取得了最先进的性能。3B和7B版本的OpenDriveVLA在ST-P3指标下的平均L2误差均为0.33米,优于先前的自回归语言模型。在UniAD指标下,OpenDriveVLA-7B也表现出色,平均L2误差为0.66米。这些结果验证了OpenDriveVLA的有效性。值得注意的是,尽管OpenDriveVLA-0.5B的参数数量明显较少,但它也取得了具有竞争力的性能,并且在很大程度上优于先前更大的模型。这凸显了OpenDriveVLA的效率,即使模型规模减小,它也能实现强大的空间和语义推理,使其成为一种有效且可扩展的语言引导规划解决方案。
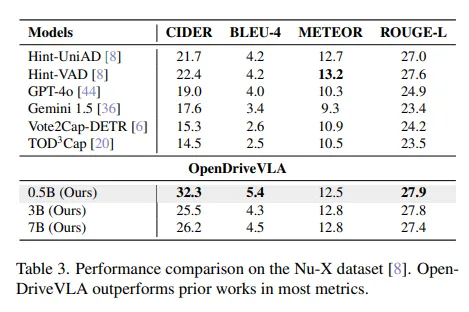
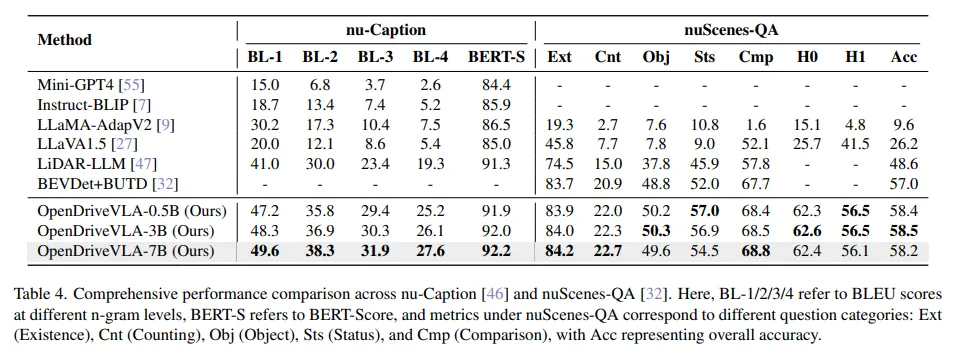
驾驶问答 :在基于nuScenes的三个数据集上对OpenDriveVLA的驾驶VQA任务进行评估,结果如表4和表3所示。OpenDriveVLA在所有三个数据集上均达到了一流的性能,在大多数指标上始终优于先前的语言增强驾驶模型和通用多模态基线模型。在nuCaption数据集上,OpenDriveVLA在所有评估模型中取得了最佳的字幕生成性能,优于通用多模态大语言模型LLaVA1.5和Mini-GPT4,以及特定于自动驾驶的模型LiDAR-LLM。对于nuScenesQA数据集,OpenDriveVLA也表现出色。与直接将BEV特征与语言模型融合的模型(如BEVDet+BUTD)相比,OpenDriveVLA在与物体和状态相关的问题上具有明显优势,这突出了其基于空间的视觉语言对齐的优势。值得注意的是,OpenDriveVLA-0.5B在Nu-X数据集上甚至超过了更大的7B模型,这表明即使使用轻量级大语言模型,它也具有强大的场景理解能力。
5)消融研究
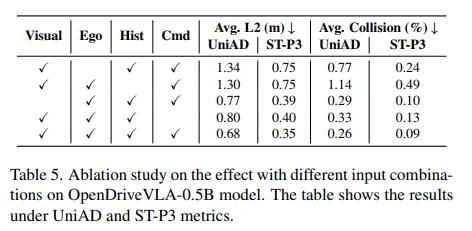
消融研究考察了输入模态对OpenDriveVLA轨迹规划的影响。表5中的结果表明,视觉输入增强了决策过程,而文本高级命令和历史状态信息进一步优化了轨迹生成,这表明了语义意图和时间context的贡献。此外,发现自车状态信息在nuScenes开环规划基准测试中的轨迹预测中起着重要作用,这与先前的研究结果一致。由于数据集的分布不均衡,许多场景涉及保持当前状态,模型倾向于过度依赖自车状态历史,导致预测偏向保守。因此,为了进一步评估OpenDriveVLA的泛化能力和执行指令动作的能力,我们进行了定性研究,以检验它对不同人类命令执行各种动作的能力。
6)定性结果
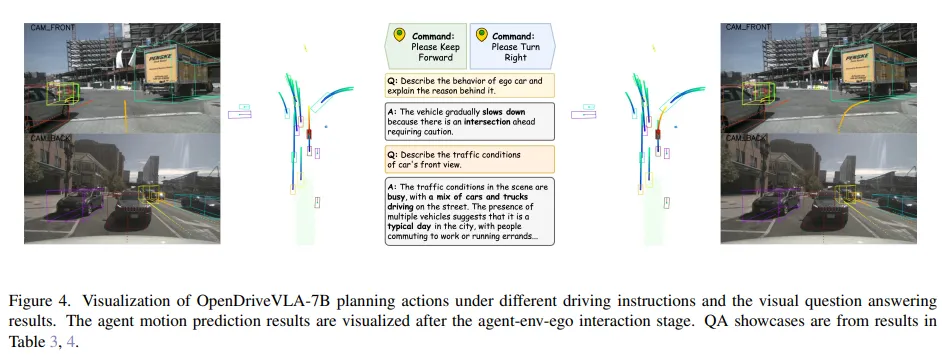
驾驶指令跟随:图4展示了在交叉路口,OpenDriveVLA-7B在两种不同驾驶指令("直走"和"右转",以右转为真实情况)下的轨迹规划。结果表明,OpenDriveVLA能够准确解释驾驶员指令并生成相应的轨迹动作。预测的轨迹既遵循给定的指令,又能感知环境并在context上合理,展示了我们模型在复杂驾驶场景中强大的指令跟随能力和泛化能力。
与先前方法的比较:图5比较了OpenDriveVLA-7B和UniAD的开环规划结果。定性结果表明,OpenDriveVLA生成的轨迹更加稳定和适应性强,因为在窄路场景中,UniAD对右侧停放的车辆往往反应过度。与UniAD相比,OpenDriveVLA有效地保持了轨迹的平滑性和环境感知能力,展示了其在处理复杂驾驶场景方面的改进能力。

7)讨论与局限性
尽管OpenDriveVLA在各项基准测试中表现出色,但仍存在一些局限性。它缺乏明确的思维链推理,而是依赖于驾驶指令调整中的隐含推理,这可能会削弱其在复杂场景中的推理能力。此外,尽管其输入和输出的token有限,但其自回归特性阻碍了在高速驾驶中的实时部署,需要进一步优化。另外,其在开环设置下的评估并未考虑交互式交通环境中的稳健性。
参考
1 OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model