qemu中使用passt来作为虚拟机的网卡NAT实现,希望能够利用它IP地址与host一致的优点。这本来是没有啥问题的,但是不知道为什么它的TCP入口流量的延迟很严重。
好吧,反正以后总是要改passt源代码的,再加上当时修了一大堆移植的bug后,就只知道有这个问题了,就干脆给修了。大约是去年11月12月左右修的,具体时间记不清了,但是记得好像花了两周左右?反正我还免费加班了。到今天过了很久了,希望我还能把这个过程写的比较完整。
passt简介
passt将外接流量转发到本地套接字中,虚拟机则是根据本地套接字的信息解析。这意味着passt到虚拟机之间需要实现一整个协议栈,至少外接交给passt的流量,passt要对应的封装为传输层中的包,再由qemu程序发给虚拟机,随后虚拟机内部再对它解包。也就是说这本质上是一个N:1:1:N的通讯。
一般给qemu加上这个参数 -net socket,connect=/tmp/passt_1.socket -net nic,model=virtio
再运行passt即可用上passt了
BUG的发现
使用RDP的时候,发现很容易连接不上,连上了界面又卡的不行。然而切换到qemu自带的-netdev user,id=usrnet0,发现使用体验还不错。到此就知道passt出问题了。
BUG的修复过程
一般发现一个BUG时,如果代码熟悉且能够确定出问题的地方时,这一步往往是省略的了。但是passt不熟悉啊,所以这一步必不可少。给BUG精确的定义,即给定一个比较稳定的复现方式,大致确定哪个模块出现问题了。这一步是需要缩小问题的范围,减少工作量。当然,范围缩小是随着理解不断深入而逐渐缩小的。
寻找稳定复现方式
复现自然不用说,稳定复现啊,这一步可以省略。
问题的全过程
RDP的使用,流量必然是从远程的电脑,到路由器,到host,再到passt,最后到虚拟机内部,之后原路返回。每一步都可能出现问题,所以需要确定是哪一步出现问题了。
抓包,缩小范围到TCP中
linux中可以使用tcpdump抓包,而windows虚拟机内部可以用wireshark抓包。不管是什么工具,我都只需要它能够显示一个包到达的时间即可。但是RDP显示的包太多了,实在不想看。
后面试了试smb,发现smb的速度略慢,按理说能有10MB/s,但是却只有5MB/s(印象中是这么多)。于是写了一个简单的echo服务与客户端,来测试一下TCP的RTT,即cli收到自己发出的消息的耗时,发现RTT有560ms左右啊
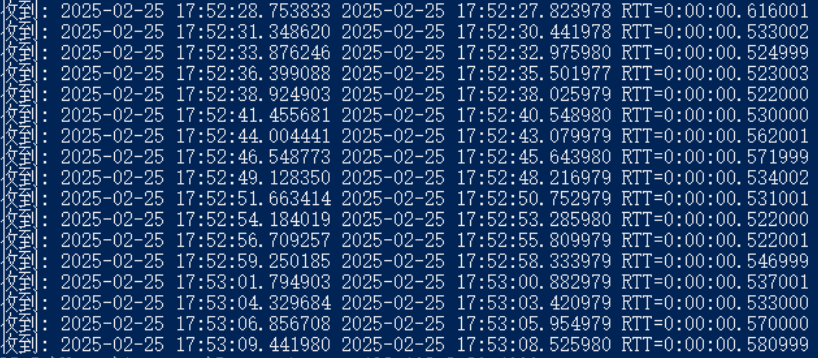
怎么回事?560ms?这才隔了一个交换机嘞。马上换到-netdev user,发现延迟是2ms左右。
到此能够确定是这个延迟导致的RDP卡的根本无法使用吗?感觉还有其他问题,毕竟这卡到界面基本都不刷新了。不过smb大概率是和这个相关了。
那么就需要通过对比netdev user方式与passt方式了。对比发现,两者的UDP延迟接近,TCP小包延迟差异大,TCP大包延迟差异小,ping的表现相似。
到此推测网络层以及以下没有问题,传输层的TCP出现问题了。
RDP用上的协议只有UDP和TCP,所以推测大概率是TCP延迟。
头绪1,拿着现象问GPT,推测是TCP中Nagle算法导致的
询问gpt,它告诉我可能和Nagle算法相关。于是我给passt中和echo程序中能找到的用上tcp的地方加上了no delay。好家伙,延迟降了,从560ms降低到500ms了,没啥大改进。
抓包,进一步缩小范围到TCP入口流量中
GPT有时候也靠不住,还是得再看看有没有别的现象。
抓包发现,延迟主要发生在流量交给passt后,passt将数据转交给虚拟机内我的echo程序读取到数据之间,也就是TCP入口流量中。
做passt的基本是大佬吧,估计不会用什么低效的数据结构与算法,估计要么是他们忽略了什么,要么是虚拟机出现什么问题了,要么是passt与虚拟机结合方式出了写什么问题,要么是host到passt之间出现了什么问题。
回想TCP小包延迟大,大包延迟小的现象,推测可能是passt自己实现的tcp协议栈哪里出现了问题。woc,这哪里好排查啊。
passt中流量代理的过程与passt大致结构
好吧,既然如此,简单翻了一下passt的代码,发现它对tcp的实现是这样的,它只是一个传输层的转发:
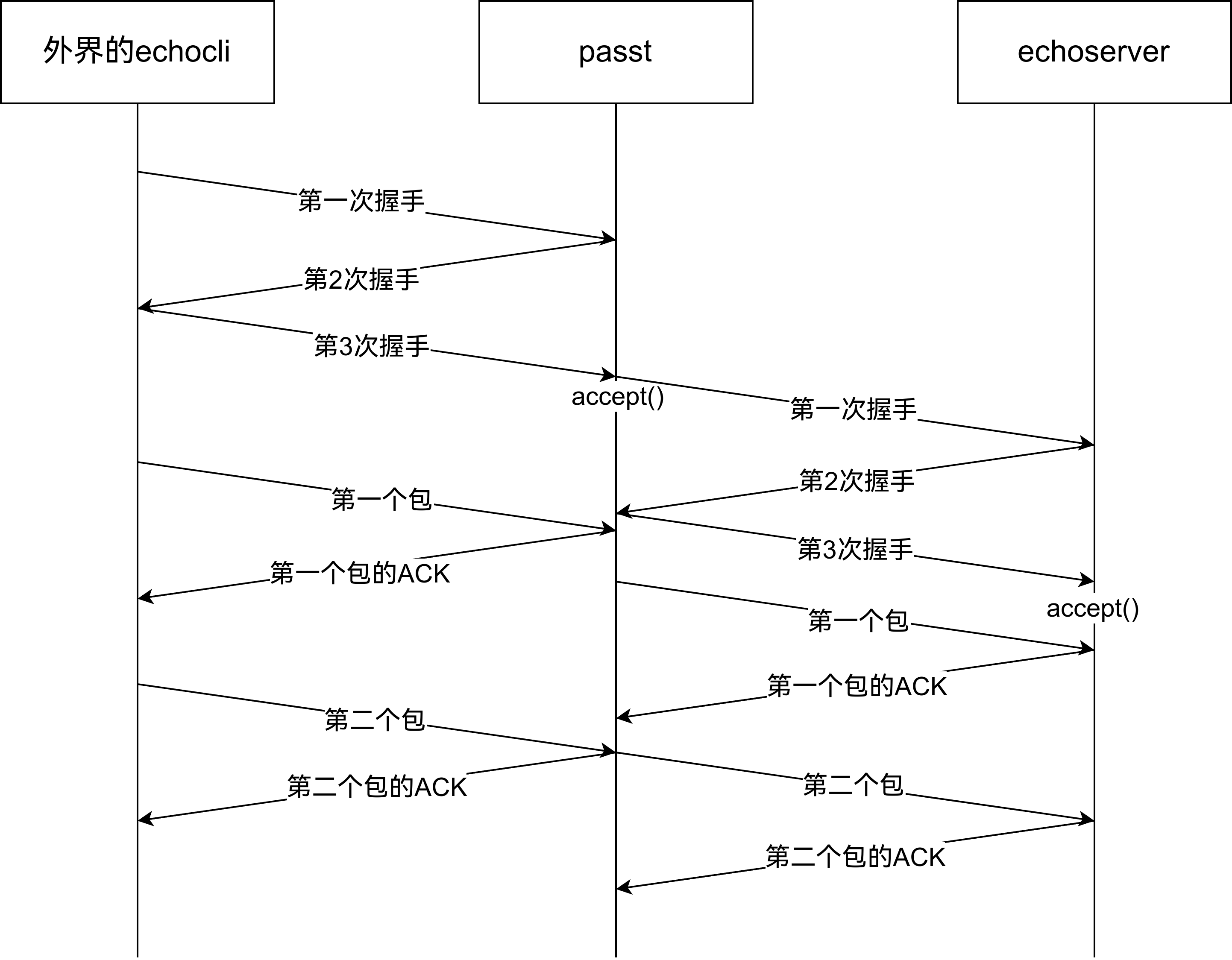
外界到passt是通过accept的,但是passt到echoserver,则是通过一个本地套接字实现。代码中有相应的表示,即flow:
c
union flow {
struct flow_common f; // 里面包含了inaddr, port等,用它可以确定tcp流量该转发给谁
struct flow_free_cluster free;
struct tcp_tap_conn tcp;
struct tcp_splice_conn tcp_splice;
struct icmp_ping_flow ping;
struct udp_flow udp;
};我们只考虑tcp,所以只看tcp_tap_conn,其内部的sock,就是图中passt accept拿到的fd:
c
struct tcp_tap_conn {
struct flow_common f; // 里面包含了inaddr, port等,用它可以确定tcp流量该转发给谁
...
int sock:FD_REF_BITS;
...
};其他的内容看不懂,反正accept拿到的fd就在这里了。
从简单到困难挨个排查
到此,想到了几个可能:
- passt收到外界流量耗时过长。这个好试,找找回调(比如下面这个),在周围打日志就行了。但是发现不是这里
c
/**
* tcp_data_from_sock() - Handle new data from socket, queue to tap, in window
* @c: Execution context
* @conn: Connection pointer
*
* Return: negative on connection reset, 0 otherwise
*
* #syscalls recvmsg
*/
static int tcp_data_from_sock(const struct ctx *c, struct tcp_tap_conn *conn)
{
if (c->mode == MODE_VU)
return tcp_vu_data_from_sock(c, conn);
return tcp_buf_data_from_sock(c, conn);
}- 缓冲区转移到本地套接字太慢,好难排查,但是似乎不太可能,毕竟只有TCP入口流量慢
- qemu拿到的是数据链路层的数据,所以是windows解包慢了。但是NAT不慢啊
- windows缓冲区到echo server慢了,如果能够抓到内核态的状态,那这个就好排查了
2和3都是很难排查的,拿着flow设置条件断点?windows虚拟机一启动多少tcp流量啊,分得清吗?看到眼花缭乱还差不多。
gpt说,wireshark能拿到内核态的包到达情况,4这个猜想更加容易,我就试试吧。
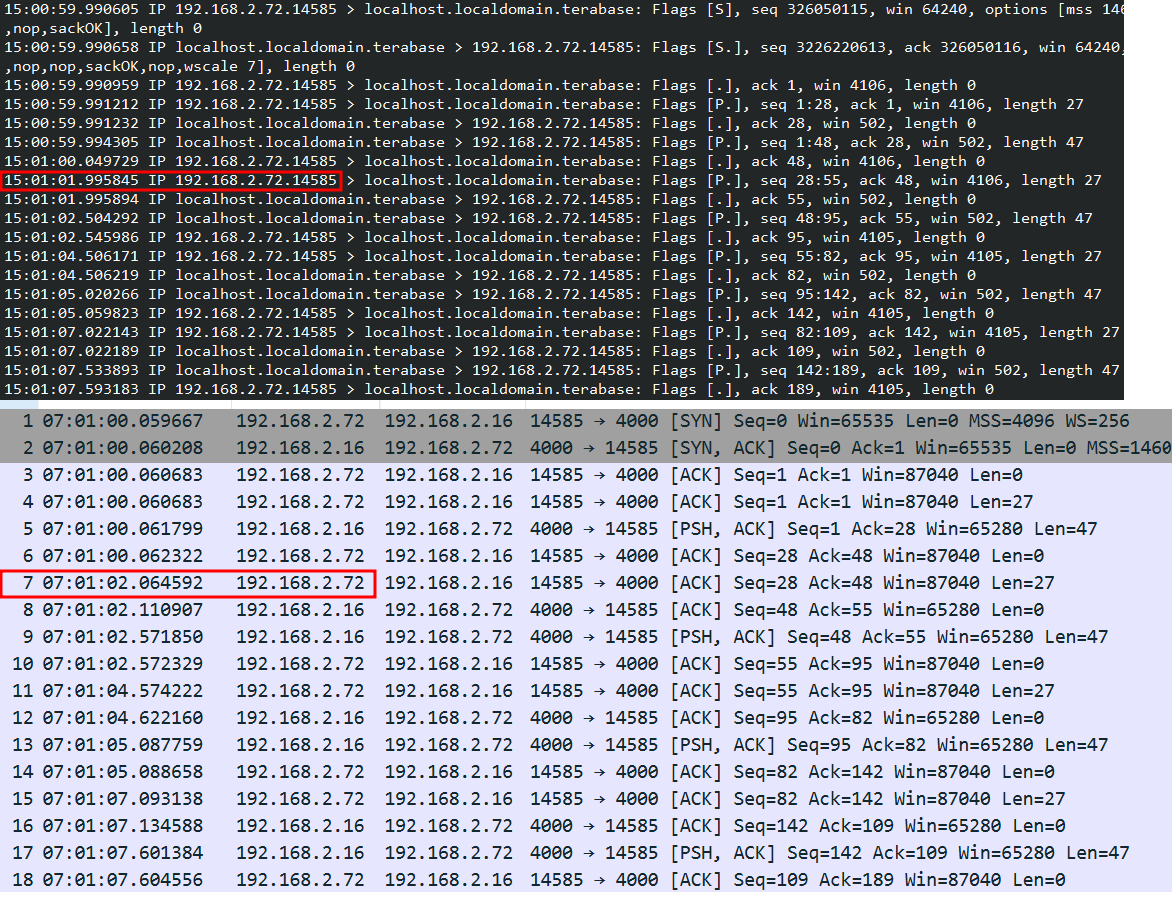
图中标红的两个包,上面是到达host的时间,下面是到达windows的时间。截图时windows有时区转换的问题,所以只看秒数,但是二者还是有70ms左右的计算偏差(不是延迟),两者相差不久啊。结果扭头一看,wireshark拿到包的时间和echo server拿到包的时间一对比,woc,问题发生在windows缓冲区到达echo server上???
好吧,目前确定延迟产生的位置了,把上面的截图画下来就是这样的。这里也去掉了前面说的70ms偏差,希望能好懂一些吧。
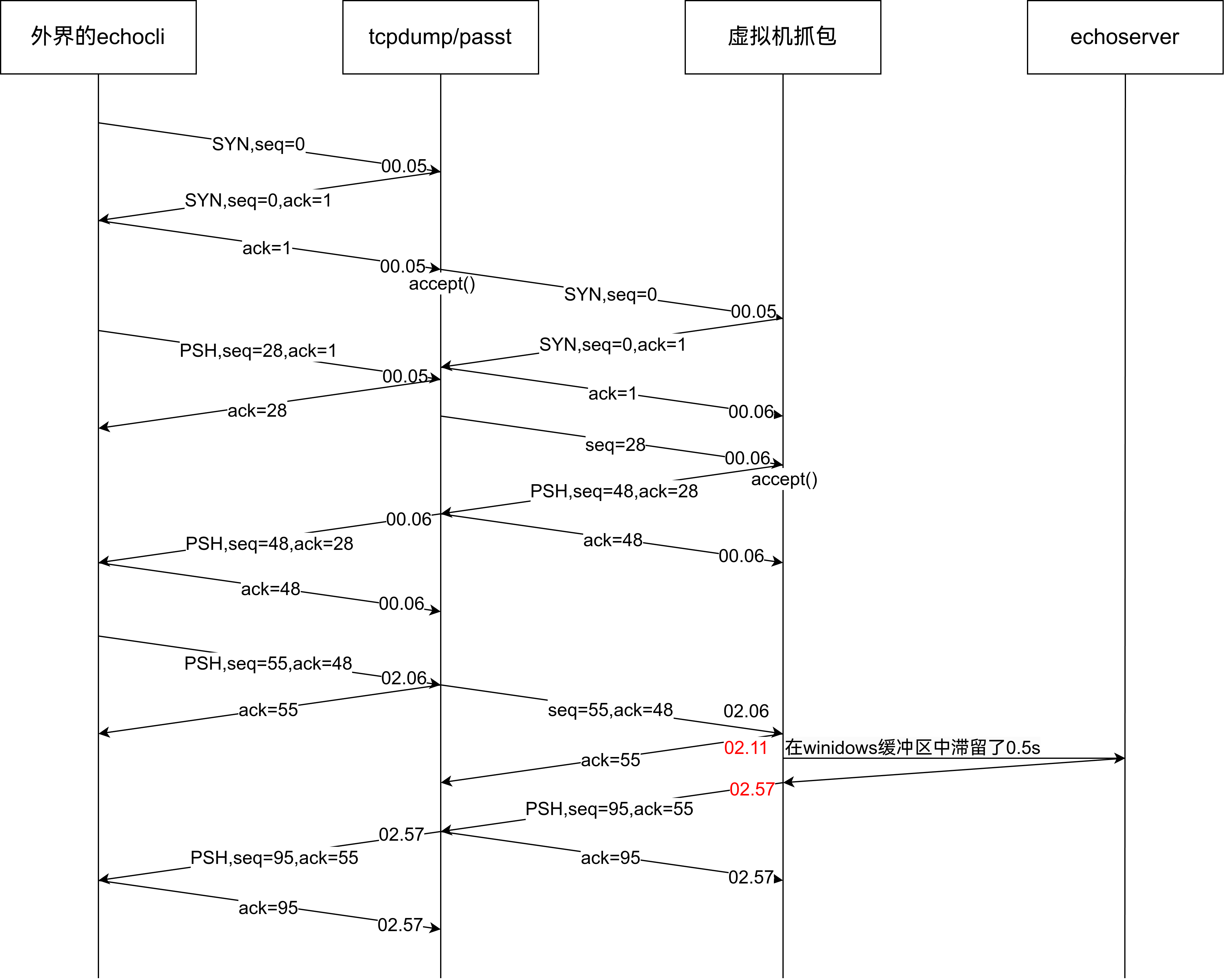
这可是windows自己的毛病啊?真的没法弄吗?
好吧,当时还真觉得没法弄了。第二天想到netdev user可以,那么为什么passt不行,是不是缺了什么?
继续对比吧。发现一个现象:netdev user里面拿到的包的PSH数量多得多!
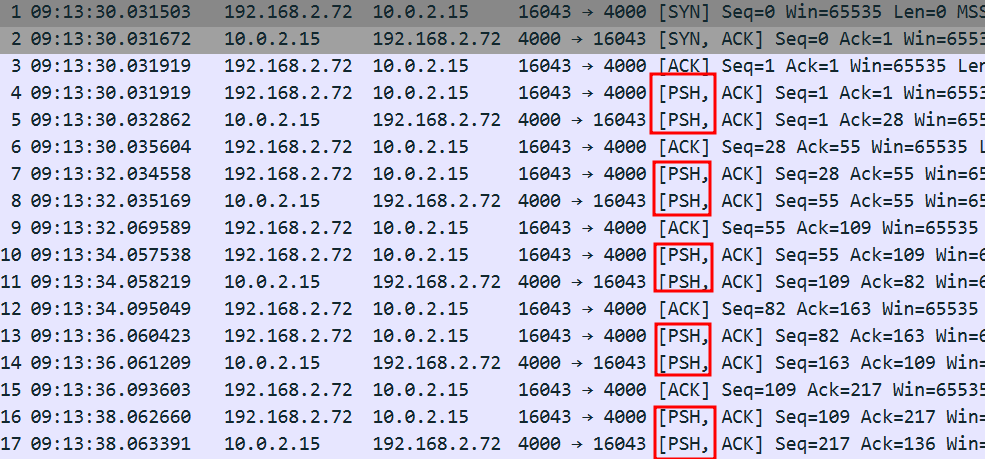
和上面的图对比一下就知道了,该不会就是这个问题吧??
问了下GPT,说PSH这个参数用于通知接收方立即将接收到的数据传递给应用程序,减少应用程序的等待时间。
感觉就是这个了。GPT也不知道该如何给一个包设置PSH,那么看看passt里面能不能吧。
PSH是TCP header中的一个标志位,应该需要找tcp header之类的结构体。代码中找到的是tcphdr这个结构体,它由操作系统提供。仔细看看,内部确实有一个psh。
struct tcphdr
{
uint16_t fin:1;
uint16_t syn:1;
uint16_t rst:1;
uint16_t psh:1;
uint16_t ack:1;
uint16_t urg:1;
};那么问题来了,该放在哪里?我想应该是设置ack之类的地方,从上图看,感觉PSH和ACK会一起出现。找到了这些地方:tcp_data_to_tap,tcp_fill_header,tcp_prepare_flags,tcp_rst_no_conn,tcp_vu_send_flag,tcp_uv_prepare。
看着注释,感觉带uv的代码是pasta的实现,不管他。另外那些,试了,有一些会导致tcp总是被RST,只有tcp_data_to_tap这里设置PSH是能用的。
然后试了下,延迟降低了,RDP能用了!