电子书地址:

1.1 引言
机器学习的目标就是构建函数的过程,通过x和y努力找到f(x)。
假设x为经验,以数据的方式存在,也就说,机器学习就是是利用"学习算法"将数据中的经验抽取到模型(计算流程=y怎样通过x得到=f(x))中的过程。
"学习算法"就是有学习能力的黑箱,那我们肯定就期望得到学习能力非常强大的黑箱,所以机器学习就是研究"学习算法"的学问。
1.2 基本术语
一、关于数据的术语
不用特别记忆,看名字就知道是啥,个别没见过的瞅瞅
1.数据集(D):x与y的集合
|----|----|----|----|----|
| 编号 | 大小 | 颜色 | 敲声 | 好瓜 |
| 1 | 大 | 黄 | 脆 | 是 |
| 2 | 小 | 黄 | 脆 | 是 |
| 3 | 大 | 绿 | 闷 | 否 |
| 4 | 大 | 绿 | 脆 | 是 |
| 5 | 小 | 绿 | 闷 | 否 |
2.示例/样本:每条记录(行),也就是关于一个对象/事件(西瓜)的描述
3.属性/特征(x):也就是反应某方面的特征,其取值成为属性值
4.属性空间/样本空间/输入空间:属性张量的空间,也就是所有特征为坐标张成的空间

一个示例成为一个特征向量,如上图中的一个点
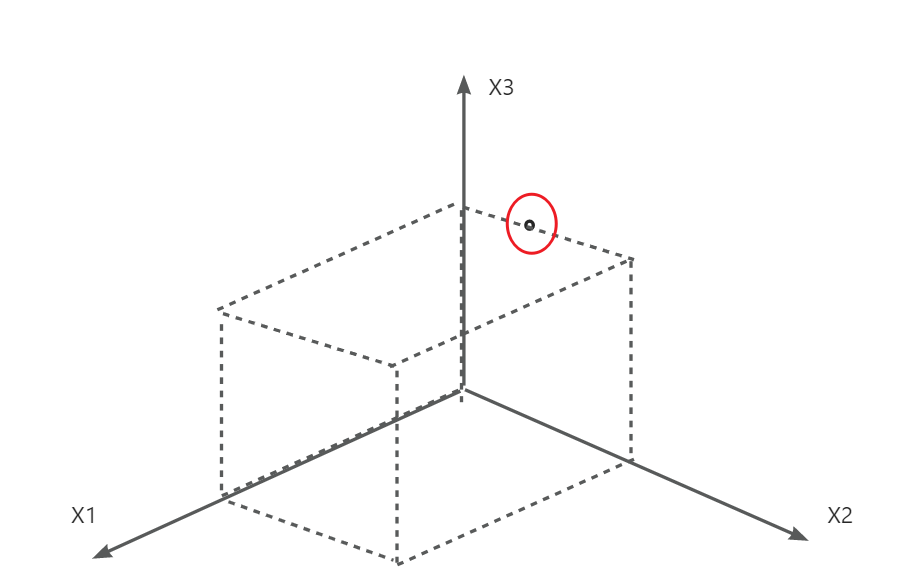
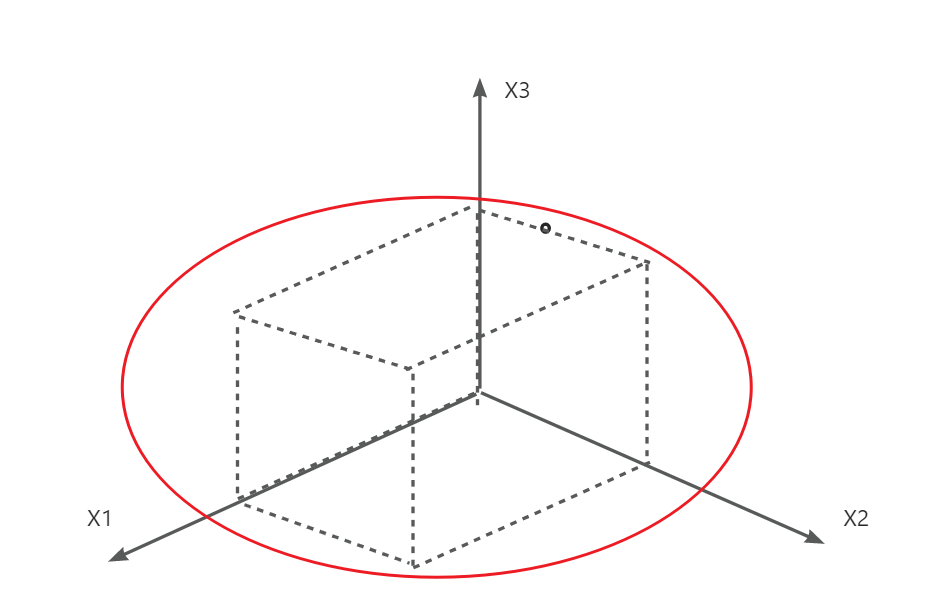
5.样本空间 :所有可能属性的取值
:所有可能属性的取值
下图虚线围成长方体中的所有点

6.维数(d):属性个数
7.训练/学习:执行某个学习算法,从数据中学得模型的过程
8.训练数据/训练集:在数据集中划分一些数据来用于训练,用于训练的数据称为训练数据/训练集
9.训练样本:训练中的每一个样本
10.假设:学习后已经得出的规律,也就是f(x),不知道是不是对的,所有称为假设,我们假设是这样的
11.真相/真实:真正的f(x)
12.学习器:模型,就那个黑盒子
13.预测:已经训练(学习)完之后,得到了f(x),通过x预测y的过程
14.测试样本:被测试的样本,我们上面已经划分了训练集,剩下的数据用于预测(预测的数据肯定不能被训练过,比如我们高中模拟考的时候肯定不能出现高考原题)
15.标记:预测出的y
16.标记空间/输出空间 :所有y的取值种类
:所有y的取值种类
二、关于任务的术语
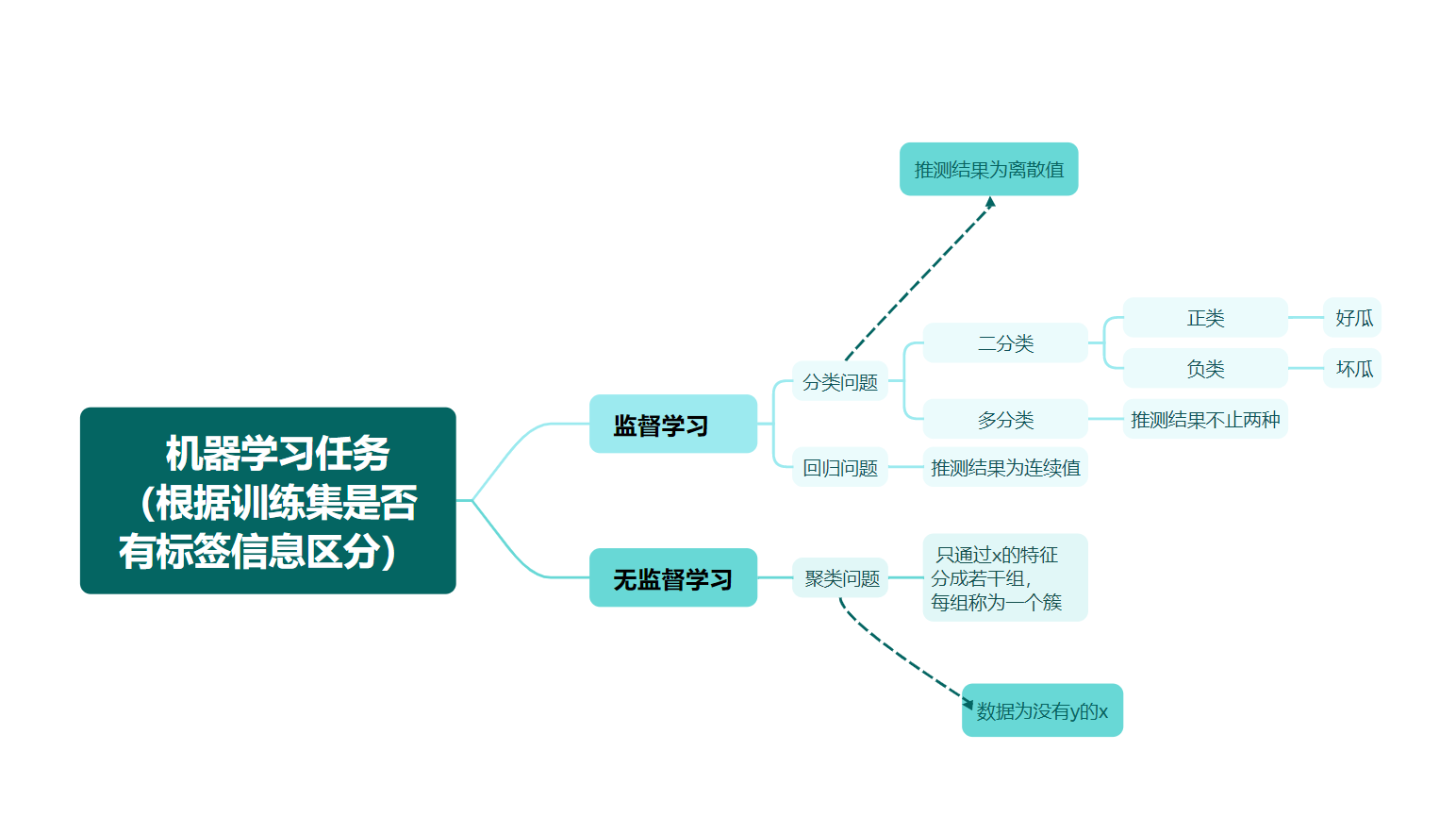
三、关于评估的术语
1.泛化:学习模型举一反三的能力,适用新样本的能力
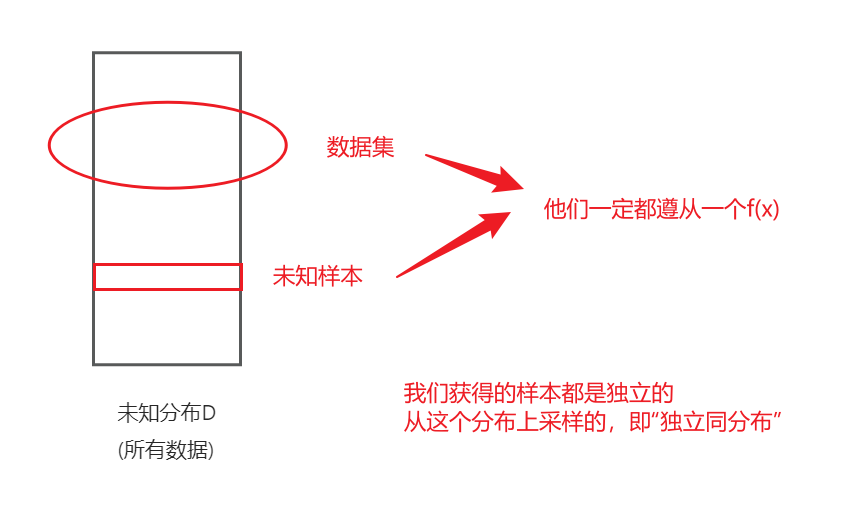
2.独立同分布:
1.3 假设空间
归纳(induction)与演绎(deduction)是科学推理的两大基本手段
归纳------>泛化,train的过程(从特殊到一般)
演绎------>特化,predict的过程(从一般到特殊)
我们现阶段机器学习的研究基本都为"从样本中学习",即"归纳的过程",因此也称为"归纳学习",这是广义上归纳学习的定义
狭义上归纳学习的定义为:从训练数据中得到概念,这很难,所有我们现阶段和此书都研究广义上的归纳学习
归纳学习的过程就是在所有假设组成的空间中进行搜索的过程
假设空间:以任务结束的所有可能性种类组成的空间
比如我们的任务是找好瓜,那么我们任务的结束就是找到或者没找到好瓜,找到好瓜的情况很多,得到好瓜所有的情况种类加上没找到好瓜就是假设空间的大小。
假设空间规模:所有好瓜的取值+1(未找到好瓜)
1.4 归纳偏好
每次我们学习的过程都会找到很多个f(x),我们必须选一个来用于表示,这个选择的过程被称为"偏好/归纳偏好"
好比我们现在在一片大雾的山谷中行走,我们要从x点到y点走最短的路,我们会从所有我们认为可能是最短的路中选择一条走。
那么我们如何从好几条可能最短的路中选一条呢?------这如同我们"价值观"的选择
归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或"价值观".那么,有没有一般性的原则来引导算法确立"正确的"偏好呢?------类比社会主义核心价值观,这是我们价值观的原则
**"奥卡姆剃刀"(Occam's razor)是一种常用的、自然科学研究中最基本的原则,即"若有多个假设与观察一致,则选最简单的那个",**就好比拟合的时候我们会选择最平滑的曲线
但是我们怎么就能知道最简单的那个就一定更好呢?很有可能复杂的那种情况才更好,这个时候我们引入训练集外的误差来算算到底哪个更好:
我们全假设最简单的情况,样本空间(所有x组合的可能)和假设空间(所有y组合的可能)都是离散的

我们表达出总的错误率也就表达出了训练集外的误差,那么我们错误率就为:所有样本推测错误的概率乘以样本本身出现的概率,再乘以所有(这个样本用什么模型推测出来的)本身的这个模型被选择的概率。
最后面这句我们再仔细解释一下,就是比如我们每个人面对每场考试的同一个题,有可能会做出来的结果不一样,所以每次我们训练之后得出的函数模型也可能不同,那么这个模型本身选择的这个函数h(x)的出现也是有概率的。
现在我们表达出了总误差,我们现在来简化以下这个误差看看这个误差和什么有关,还是假设最简单的可能,现在我们只考虑二分类问题,进一步:

进一步化简我们发现,最后的错误率中h约没了,这说明错误率与这个函数无关。
当然这是不可能的,因为假设前提是f是均匀出现的,这个假设本身不成立,那对于好学生肯定想出来更好方法的概率要比没想出来的方法的概率大的。
这引出了下面的启示,"没有免费的午餐"定理

周志华老师告诉我们:脱离具体谈"什么算法好毫无意义",我们要根据具体实际选择合适的算法模型
1.5 发展历程
人工智能的发展历程:
1."推理期":机器逻辑推理
2."知识期":人民把大量知识总结出来教给机器
3."机器学习时期":三个流派(1)联结主义(2)符号主义(3)统计学习
目前我们研究的是统计学习流派中"从样例中学习"
著名代表(1)归纳逻辑程序设计:让机器写代码(2)基于神经网络的联结主义学习(3)支持向量机(4)深度学习:很多层的神经网络
值得一提的是深度学习在上个世纪末因为算力的局限难以解决很多问题,当时被人称为垃圾,被骂的不行,现在他又成为了我们最热潮的领域,被称为"通用人工智能"(可自主学习知识)的曙光。
历史真的是个圈,或许我们之后也会陷入相同处境,我们自己能做的当然之只能是保持清醒,不要受他人指点而放弃。
1.6 应用介绍
自己看看