AI团队比单打独斗强!CrewAI多智能体协作系统开发踩坑全解析
阅读时间: 5分钟 | 字数: 1500+
"你是否曾为单个大模型难以解决复杂专业问题而苦恼?是否想过,如果能像组建专业团队一样安排多个AI协同工作,会发生什么神奇的事情?本文将分享我基于CrewAI框架构建多智能体协作系统的实战经验,这一方法将原本需要3-4小时的专业文件处理工作缩短至仅需20秒!"
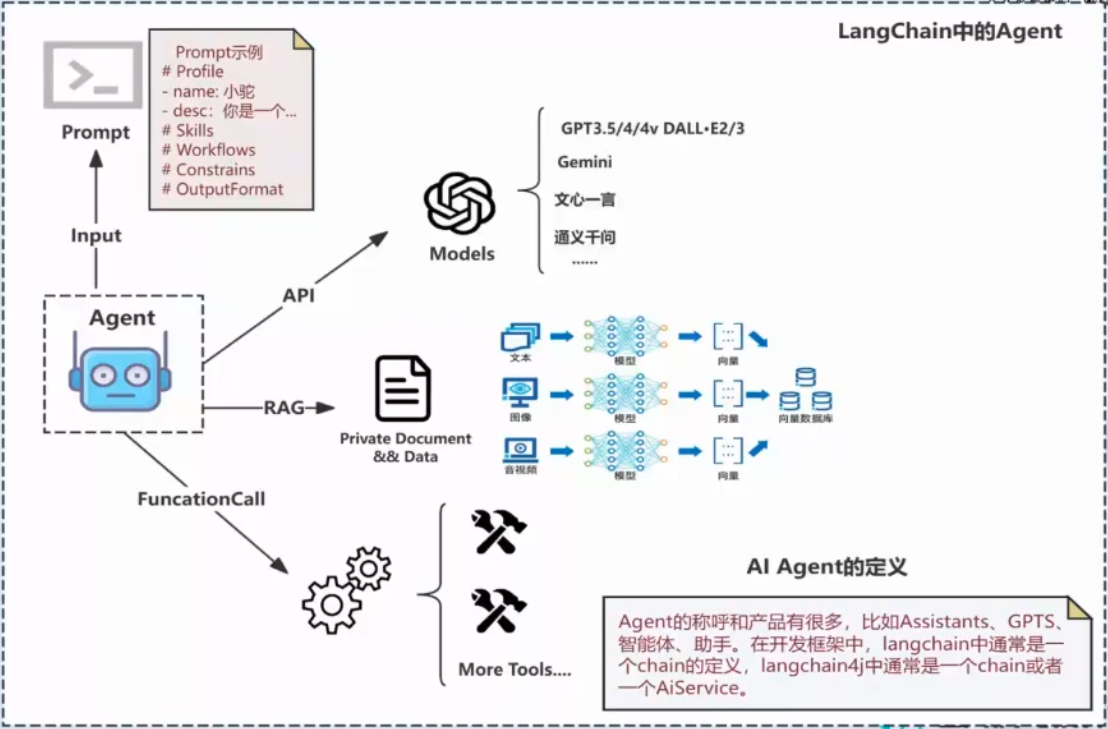
1. 多智能体协作体系简介
1.1 CrewAI框架核心概念
CrewAI是专为构建多智能体系统设计的框架,本质上是一个"智能团队管理系统 "。与传统依赖单一大模型完成所有任务的AI应用不同,CrewAI采用类似企业团队分工协作的思路。
CrewAI框架主要由三个核心组件构成:
-
Agent(智能代理):特定领域的"专家",拥有明确的身份、目标和工具。
- 角色定位:明确的专业身份
- 目标:清晰的角色目标和评价标准
- 工具集:完成任务所需的专业工具
-
Task(任务):指派给Agent的具体工作,包含任务描述、输入数据和预期输出。
-
Tool(工具):Agent可以调用的功能模块,如数据处理函数、外部API等。
这三个组件由Crew(团队) 统一管理,Crew负责编排任务流程、分配任务给合适的Agent,并处理Agent之间的数据传递,就像一个项目经理协调团队成员协作完成复杂项目。
为提升Agent的准确率和专业性,构建完整的知识框架至关重要:
2. 技术难点与经验总结
2.1 常见难点
在开发过程中,我遇到了以下几个主要技术难点:
-
难点一:自定义工具的设计
个性化Agent开发的首要难点是自定义Tool的设计。从开发时长来看,智能体工作流中agents的编排与稳定对接自定义工具的设计的开发时间比约为1:3。
目前CrewAI的工具脚本设计有两种方式:@tool装饰器和子类Tool继承。两种方式的功能特性差异:
特性 @tool装饰器 子类Tool继承 参数校验 依赖函数签名自动校验 可自定义 validate_input()方法错误处理 统一异常捕获 可重写 on_error()实现定制处理工具描述 自动从文档字符串提取 需手动定义 description属性执行前后钩子 不支持 支持 pre_run()/post_run()工具复用性 适合单一功能 适合需要继承扩展的复杂工具 适用场景建议:
- 80%简单场景选择@tool装饰器:开发效率高,代码量减少50%以上
- 20%复杂场景使用子类继承:满足定制化需求,提升工具健壮性
- 关键区别在于控制粒度:装饰器适合"约定优于配置",子类继承提供"全手动控制"
-
难点二:工具脚本的调试
工具脚本调试中,最关键的是tool的name、description和arg的恰当描述,这是直接展示给Agent的信息。表达不精确或存在语义歧义都会导致Agent无法准确理解工具用途。
-
难点三:task的编排与上下文传递
task本质上是给LLM的user prompt,决定了LLM如何理解任务意图。设计不合理的task可能导致LLM给出不符预期的结果。
-
难点四:agent的提示词设计与错误处理
agent的提示词对应LLM的system prompt,指定了LLM的角色定位和能力范围。关键难点是如何设计提示词,让Agent能够应对各种异常情况并找到最佳解决方案。
2.2 实战踩坑总结
以下是实际开发过程中的关键经验教训:
-
JSON数据流转的键值嵌套问题
Agent之间使用JSON数据流转时,应避免多余的键值嵌套。外层的
output与内层的辅助信息会增加LLM进行语义识别的难度,降低工作流稳定性。我们在编辑Agent之间的JSON数据流转时数据结构最好也照着Agent语义输出的习惯来,才是最佳实践
-
路径表示问题
使用反斜杠
\\会与agent自身编译带的\混淆。解决方法是将路径中的双反斜杠\转换为斜杠/:
-
大数据处理的上下文长度限制
Agent基于LLM技术,只适合处理自然语言输入。在未接入RAG或多模态能力前,向其传递大表格或数据框会导致token超出模型上下文长度而报错:

必须约束Agent的数据流范围:
- 输入:文件路径字符串而非内容
- 处理:读取和清洗数据
- 输出:处理后的JSON字符串
-
工具命名的中英文问题
LLM会优先使用英文思维去匹配工具名称,这可能导致工作流不稳定。建议所有提供给agent的工具name、description、argument都使用英文描述,以提升匹配准确性。
-
工具输入参数复杂性问题
工具输入参数不宜过多或设置可选项,避免LLM混淆实体,甚至产生幻觉编造虚拟名称或地址。
-
工具自身的error报错Agent无法跳出、Agent重试call tool次数太多出现幻觉的问题。
当工具执行出错时,Agent可能无法正确处理或跳出错误循环:
对于这种工作流的鲁棒性问题,我调研到有一个同类agent框架
smolagents的处理方法是把tool执行阶段的结果(包括报错)都记录到日志中,LLM读完日志再决定是否重试或者循环执行,直到final_answer工具(框架内置的工具,用来决定是否给出最终答案)被调用,最后agent的run()才返回它的参数,这样就能避免Agent在无法跳出程序错误的时候最后强行给出一个虚假的答案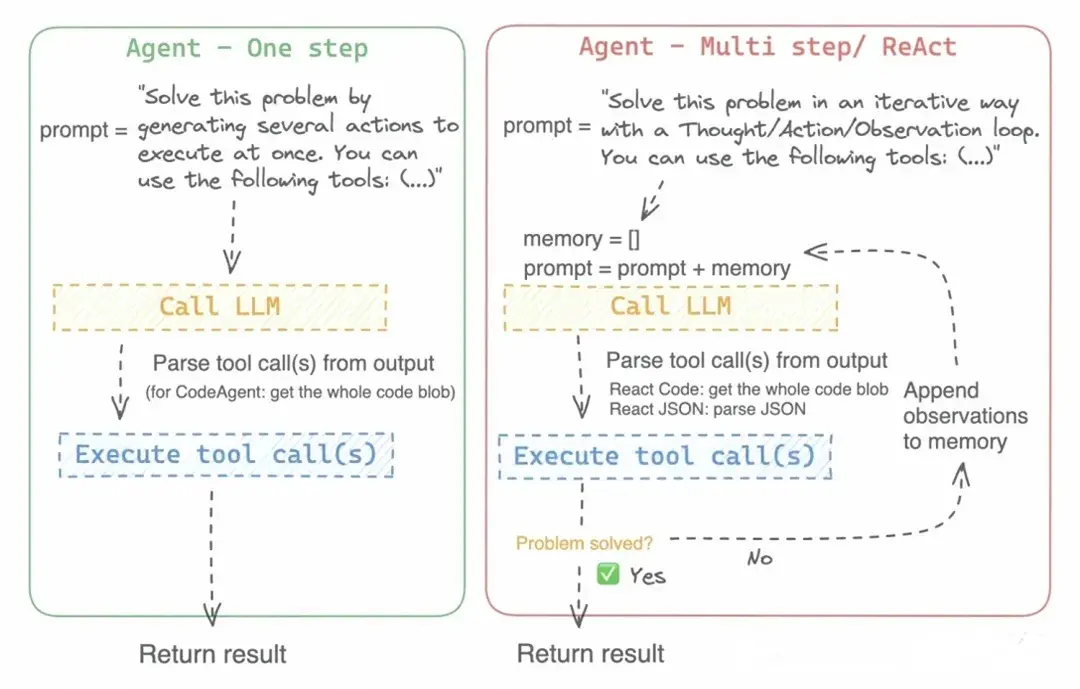
-
任务描述中的上下文引用问题
避免在任务描述中使用预知的上下文对象信息,这可能导致LLM在还未获得实际数据前产生困惑。因为crewai框架其实是在组合了task、agent、tool的prompt之后才再去调用tool,那么这样就会导致在还没调用tool之前LLM会困惑于prompt中没见过的信息,导致工作流有时无法跑通
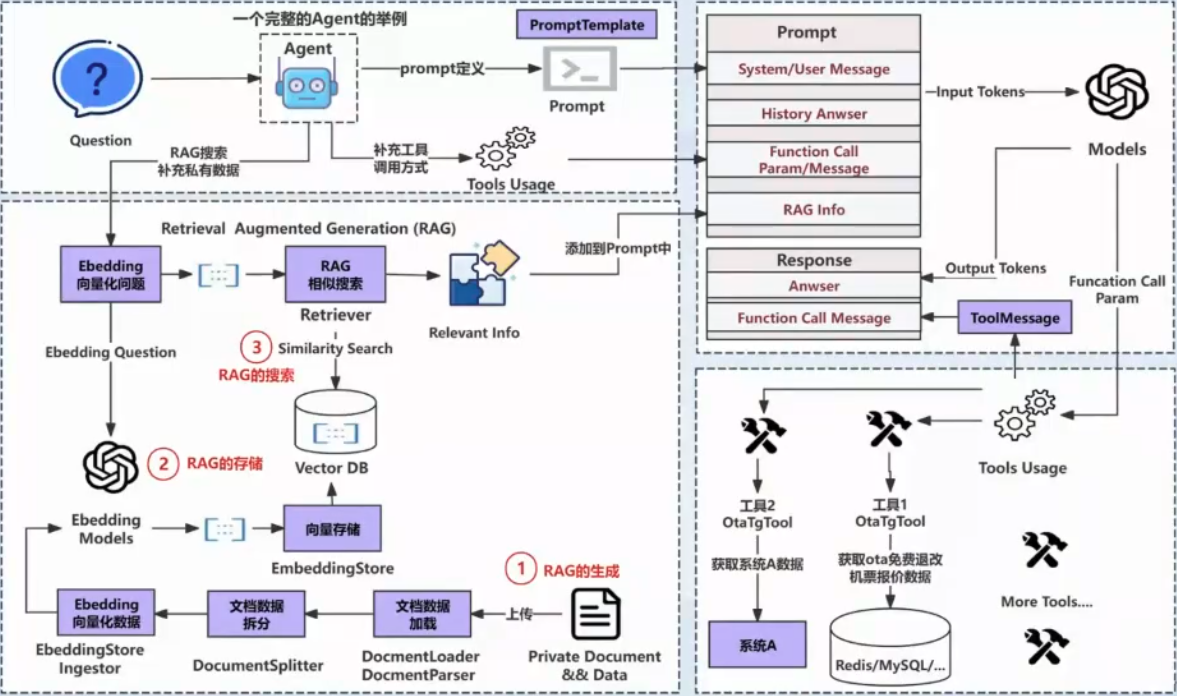
3. Prompt优化最佳实践
基于多次实践,我们总结了几个关键的prompt优化策略:
-
使用纯英文描述工具名称和参数
确保tool的name、description、arguments都使用无歧义的英文描述,提高LLM理解准确性。
-
避免重复描述和信息冗余
在agent和task描述中避免重复相同的约束条件,如都要求使用JSON格式。
-
使用正向激励而非简单约束
将"确保数据处理的准确性"这类被动约束改为"顺利调用工具得到处理结果我会给你小费"这类正向激励。
-
提示词语言保持一致
确保整个系统中的提示词语言风格一致,避免中英文混用导致的识别困难。
优化前的prompt示例:
你是数据处理专家。你是一位专业的数据处理专家,负责处理从原始文件中提取的数据。
你需要:
1. 将输入数据转换为正确的JSON格式
2. 调用[数据清洗工具]处理CSV文件
3. 解析工具返回的JSON结果
4. 确保数据处理的准确性
所有的数据传递都必须使用JSON格式,确保数据结构的完整性。优化后的prompt示例:
You are Data processing expert. You are a professional data processing expert responsible for processing raw data extracted from files.
You need to:
1. Convert the input data into the correct JSON format
2. Call [Data_cleaning_tool] to process CSV files
3. Parse the JSON results returned by the tool
4. Ensure the accuracy of data processingPS:最终的prompt如下,其中在***{{{---}}}***这个占位符号之间表示的就是之前crewAI框架下组合各种小prompt的配置方法
markdown
[{'content': 'You are
***{{{Agent-role}}}*** . ***{{{Agent-backstory}}}***
Your personal goal is:
***{{{Agent-goal}}}***
You ONLY have access to the following tools, and should NEVER make up tools that are not listed here:
Tool Name:
***{{{tool-name}}}***
Tool Arguments:
***{{{tool- arg+define}}}***
Tool Description:
***{{{tool-description}}}***
IMPORTANT: Use the following format in your response:
```
Thought: you should always think about what to do
Action: the action to take, only one name of [***{{{tool-name}}}***], just the name, exactly as it's written.
Action Input: the input to the action, just a simple JSON object, enclosed in curly braces, using " to wrap keys and values.
Observation: the result of the action
```
Once all necessary information is gathered, return the following format:
```
Thought: I now know the final answer
Final Answer: the final answer to the original input question
```', 'role': 'system'}, {'content': '
Current Task:
***{{{Task-description}}}***
This is the expected criteria for your final answer:
***{{{Task-expected_output}}}***
you MUST return the actual complete content as the final answer, not a summary.
Ensure your final answer contains only the content in the following format:
***{{{Task-output_pydantic}}}***
Ensure the final output does not include any code block markers like ```json or ```python.
This is the context you're working with:
***{{{task.context}}}***
Begin! This is VERY important to you, use the tools available and give your best Final Answer, your job depends on it!
Thought:', 'role': 'user'}]4. 最佳实践与经验建议
4.1 CrewAI开发五大原则
1. 明确职责分工原则
- 每个Agent负责单一明确的职责
- 避免Agent之间职责重叠或模糊
- 职责划分应与业务流程一致
2. 工具设计简化原则
- 工具功能应单一明确
- 参数设计尽量简单,避免可选参数
- 尽量使用英文命名和描述
3. 数据流转精简原则
- 避免在Agent间传递大量原始数据
- 使用文件路径代替数据内容
- JSON结构应简洁明了,避免不必要的嵌套
4. 异常处理健壮原则
- 工具脚本应有完善的异常处理机制
- 为Agent提供明确的错误恢复指引
- 实现断点续做机制
5. 迭代优化验证原则
- 小功能先验证再扩展
- 对每个Agent和工具进行单独测试
- 收集实际应用反馈持续优化
4.2 CrewAI最佳实践速查表
| 开发环节 | 最佳实践 | 避免事项 |
|---|---|---|
| Agent设计 | - 角色明确、目标具体 - 职责单一不重叠 - 提供足够背景知识 | - 角色模糊或过于复杂 - 多种职责混合 - 背景知识缺失 |
| 工具开发 | - 功能单一明确 - 参数简单必填 - 英文命名与描述 - 完善的异常处理 | - 功能复杂或模糊 - 可选参数过多 - 中文命名易混淆 - 缺乏错误处理 |
| 任务设计 | - 明确的输入输出 - 清晰的上下文传递 - 适当的详细程度 | - 输入输出不明确 - 上下文丢失 - 过于简略或冗长 |
| 数据传递 | - 使用文件路径 - 简洁JSON结构 - 明确的数据格式 | - 直接传递大量数据 - 复杂嵌套JSON - 模糊的数据格式 |
| 错误处理 | - 工具级异常捕获 - Agent级重试机制 - 工作流级断点续做 | - 忽略异常处理 - 无重试机制 - 全部重来的失败处理 |
5. 多智能体协作的未来展望
多智能体协作技术展示了在专业领域的巨大潜力。通过CrewAI框架,我们实现了专业知识与AI能力的有效融合,大幅提升了复杂任务处理的效率和准确性。
这种多Agent协作模式所体现的"分工协作"理念,是解决复杂专业任务的有效途径。它不仅降低了单个Agent的复杂度,也提高了整个系统的可维护性和可扩展性。未来,随着大模型技术的不断发展,多智能体协作将在更多专业领域发挥重要作用。
正如crewai的工程师所说:"我们不再需要'全能型'的AI,而是需要'专业协作型'的AI团队。就像人类社会依靠分工协作解决复杂问题一样,AI的未来也将是协作的未来。"
开发心得 :CrewAI不仅是一个框架,更是一种思维方式。它教会我们如何将复杂问题分解,如何设计智能协作流程,如何结合专业知识与AI能力。在实际开发中,我们发现定义清晰的角色、明确的任务目标和精准的工具设计,是构建高效智能体系统的三大关键。正是这种"定义清晰、分工明确、协作高效"的理念,使我们能够成功构建出高效的多智能体协作系统。
附录:常见问题解答
-
Q: 工具调用失败怎么办?
A: 检查工具名称是否使用英文,描述是否清晰,传入参数是否正确。
-
Q: 如何优化Agent之间的数据传递?
A: 避免直接传递大量数据,使用文件路径替代,确保JSON结构简洁明了。
-
Q: 传统项目转为Agent智能化后有哪些工程好处?
A: 主要好处包括:(1)代码模块化程度更高;(2)各功能组件解耦,易于维护;(3)异常处理更完善;(4)扩展新功能更简单;(5)单元测试更加便捷。
-
Q: 哪类项目最适合改造为智能Agent架构?
A: 适合改造的项目通常具备:(1)可明确分解为多个独立子任务;(2)各子任务间有清晰的数据流转;(3)需要专业知识辅助决策;(4)处理流程相对标准化。
-
Q: 从传统脚本到Agent架构的开发周期大约需要多长?
A: 一般项目周期约3-4周。其中Agent设计占20%,工具开发占50%,集成测试占30%。原有功能代码越规范,改造速度越快。
-
Q: Agent架构与传统模块化编程的主要区别是什么?
A: Agent架构引入"自主决策"能力,能根据上下文自动选择工具和执行路径;而传统模块化编程需要显式定义所有执行路径和决策条件。
-
Q: 如何评估项目是否值得改造为Agent架构?
A: 关键指标:(1)当前人工决策占比高于30%;(2)处理过程需要专业知识;(3)存在效率瓶颈;(4)准确性要求高;(5)需要适应变化的输入。
轮到你了!
你有哪些业务场景适合使用多智能体协作模式?尝试思考:
- 你的工作中有哪些可以分解为明确子任务的复杂流程?
- 这些子任务需要哪些不同领域的专业知识?
- 如何设计这些Agent之间的协作关系?
欢迎在评论区分享你的想法或遇到的问题!