1. 前言
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
2. 正文
2.1 yield
最开始发现于:rollout_storage.py文件下的mini_batch_generator函数:
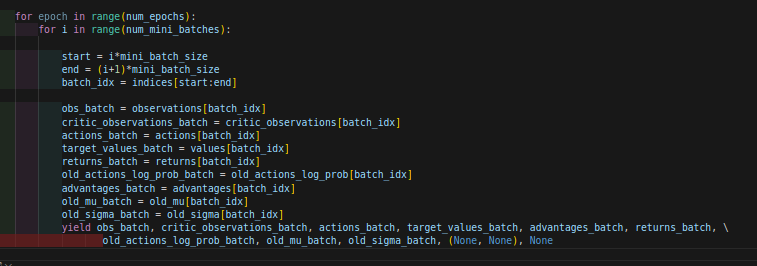
感觉这个最外层的num_epochs也没用啊?直到我看到了yield,然后去外面的函数看了看它的调用,发现了一个好玩的事情:

才知道这里的roll out的打乱前的batch是按照一个迭代器产生的,我自己也试了一下,确实我之前都没注意到这一点。
相较于return,yield最大的特点是可以手动的推进迭代,举个🌰:
def f1(): for i in range(5): yield i a = f1() print(next(a)) print(next(a)) print(next(a)) print(next(a))输出:
而return只是返回了一个值,程序运行到这里就断开了,所以不少函数用return作为中断,而yield可以循环返回值,而且函数也不会中断,相当于自己写了一个迭代器,根据自己的需要从迭代器里面"拿"数据,这样解释应该会通俗易懂。

但当然也可以这么写,一下就可以取出迭代器里的所有值了:
def f1():
for i in range(5):
yield i+1,i+2,i+3
generator = f1()
for a,b,c in generator:
print(a,b,c)输出:

然后在代码中:
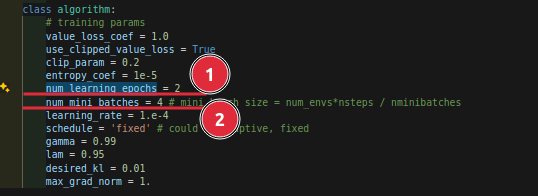
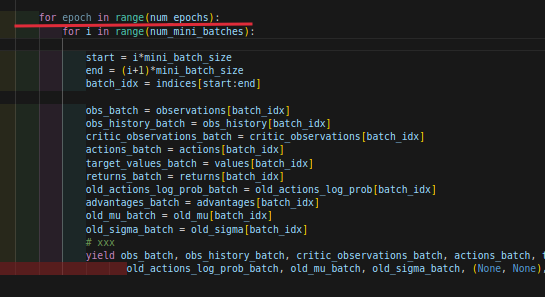
圈1 表示随机化roll out storages的循环次数:(注意可以自己看代码,这个epochs的每次循环输出的数据其实是重复的),这里就用到了我前面提到的yield的用法,generator迭代器。
这个值调的大,那么在update的时候迭代的次数就越多,其所在位置如下所示:rsl_rl/ppo.py
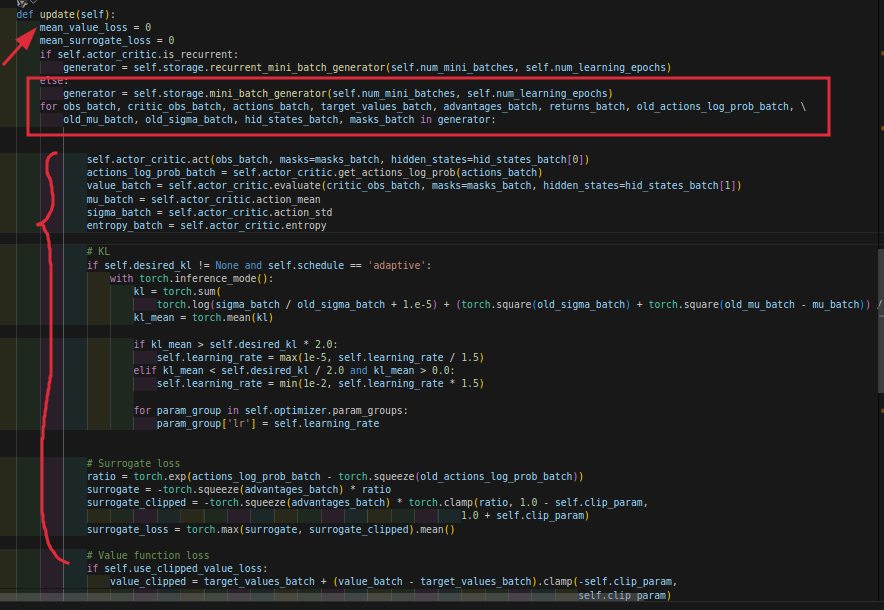
下面的
KL的注释可以不用管他,这个就是一个调整学习率的地方,在.config文件的schedule处可以自行设置,选择fixed就是不更新学习率,始终是一个值,adaptive就是可以更新。
然后回到上面,圈2表示的是batch的数量batch_num,也就是按照一个batch_size大小取样,一共取batch_num次,也就是上面图所表示的内层循环。
注意这个两个值不要开太大,要学会取舍,不然可能会不收敛而且learning_time会"炒鸡"慢
3. 后记
这篇博客暂时记录到这里,日后我会继续补充。