简介
一个操作系统,要实现对内存的管理,需要实现如下几个核心目标:
- 分配与回收
高效分配,减少内存碎片和内存利用率 - 空间扩充
内存虚拟化,让进程享受近乎无限的内存地址。 - 存储隔离
保证各个进程之间不会越界访问。 - 高效通信
支持进程间内存共享,提高交换效率。
分配与回收
先来分享一个前置知识:
1.内部碎片
分配给进程的内存区域中,有些部分是空闲没有用上。
比如SQL Server , .NET CLR 。 他们自己内部一套实现了内存管理,因此要先预申请大量内存。
2.外部碎片
内存中某些空闲分区由于太小难以利用上
连续内存分配
为进程分配的必须是一个连续的内存空间
单一连续分配
long long years ago ,单任务系统时代(MS-DOS),由于是单任务操作系统。所以内存中只会有一道用户程序。该程序独享整个用户态空间。
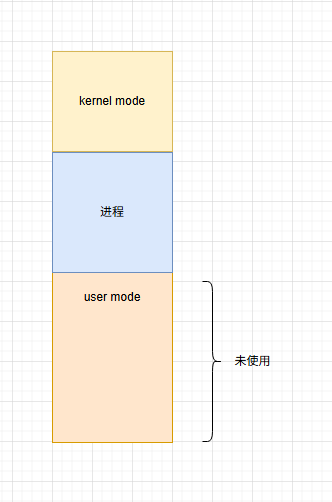
- 优点
实现简单:直接采用覆盖技术扩充内存,且不需要进程隔离
无外部碎片:就一个程序能有啥碎片? - 缺点:
有内部碎片
固定分配
随着多任务操作系统的兴起,单一连续分配已经不能满足需求。因此发展成,讲整个用户态空间划分为若干个固定大小的分区,每一个分区中只运行一个进程。形成了最早,最原始的多进程内存管理。
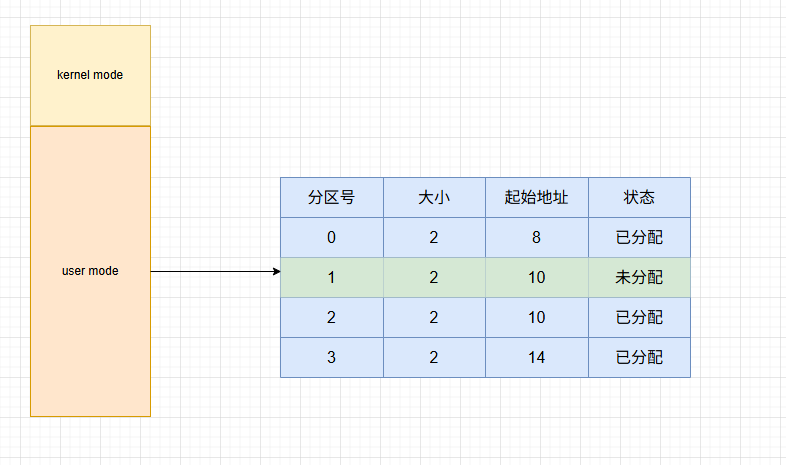
- 优点
实现简单,不会产生外部碎片。 - 缺点
-. 当程序太大,分区表中所有分区都无法满足,此时就需要采用覆盖技术来解决。但会降低性能。
-. 会产生内部碎片,一个10M大小的分区,只放了一个9M的程序,还有1M空间被浪费。
-. 分区固定,缺乏灵活性
虽然也有将要分区表划分为不同大小的分区,以此提交灵活性。但依旧是固定分配的范畴。
动态分配
为了解决固定分配的痛点,操作系统又发展出动态分区分配策略。
这种分配方式不会预先划分内存区域,而是在进程装入内存时,根据进程大小动态建立分区。

- 优点
不会产生内部碎片,外部碎片可以通过压缩来缓解。 - 缺点
实现复杂,内存回收时要考虑前后相邻,合并的情况。
动态分配算法
首次适应(First Fit)
- 原理
从低地址/起始地址开始搜索,选择满足大小的第一个空闲空间。分割后分配(剩余部分仍为空闲块)。 - 优点
快速,无需遍历所有空闲块。 - 缺点
在低地址区域留下大量碎片
【100kb,200kb,50kb】,申请150,选择第二个,变成【100kb,50kb,50kb】
邻近适应(Next Fit)
由首次适应演变而来
- 原理
从上一次分配结束的位置开始搜索,找到第一个足够大的空闲块(类似首次适应) - 优点
平衡内存碎片分配位置,较少低地址碎片的堆积,且搜索效率高于首次适应 - 缺点
只是平衡内存碎片分配的位置,但碎片问题依旧存在。且会提前消耗大空闲分区。
最佳适应(Best Fit)
- 原理
搜索所有空闲块,选择满足大小的最小空闲块。分割后分配(剩余部分仍为空闲块)。 - 优点
内存利用率最高,会有更多大分区被保留下来,能够满足大进程需求 - 缺点
产生大量极小内存碎片,且难以利用。
【100kb,200kb,50kb】,申请49,选择第三个,变成【100kb,200kb,1kb】
最坏适应(Worst Fit)
为了解决最佳适应的缺点,又衍生出最坏适应
- 原理
搜索所有空闲块,选择满足大小的最大空闲块。分割后分配(剩余部分仍为空闲块)。 - 优点
避免产生微小碎片 - 缺点
提前消耗大内存块,等大进程来时无法满足。
【100kb,200kb,50kb】,申请15个10,选择第二个,变成【100kb,50kb,50kb】,此时再申请200,无空间可用。
总结
| 算法 | 核心策略 | 优点 | 缺点 | 典型场景 |
|---|---|---|---|---|
| 首次适应 | 第一个足够大的块 | 分配速度快,实现简单 | 低地址碎片多 | 实时性要求高的系统 |
| 最佳适应 | 最小足够大的块 | 内存利用率高 | 微小碎片多,效率低 | 内存紧张、小内存请求多 |
| 最坏适应 | 最大空闲块分割 | 减少微小碎片 | 大内存块可能提前耗尽 | 中等大小内存请求为主 |
| 邻近适应 | 从上一次位置开始搜索 | 分配均衡,减少碎片堆积 | 性能中等 | 通用多任务系统 |
tips: 一个反直觉的知识
由于最佳适应/最坏使用需要检索整个空闲块,所以为了提高搜索效率。往往要对空闲块进行排序操作。而邻近适应在实际应用中,并没什么卵用,反而影响大进程的调度。
因此综合下来,反而是首次适应的综合效率更好。
动态回收算法
边界标记法
每个内存块头部记录块大小和分配状态,尾部存储前一个块的头部地址(或状态),释放时通过前后块地址判断是否相邻空闲:
前向合并:后一个块是空闲块,合并为一个大空闲块。
后向合并:前一个块是空闲块,合并为一个大空闲块。
双向合并:前后块均为空闲块,合并为一个更大的块。
非连续内存分配
为进程分配的是一些分散的空间
从上面可以看出,连续内存分配的有如下几个痛点:
- 外部碎片严重,内存利用率低
动态分配在申请和释放过程中,会产生大量不连续的空闲块。需要定期"压缩"内存,而压缩会消耗大量CPU时间。 - 开销大
动态分配算法中(首次适应,最佳适应,最坏适应)等算法需要遍历整个空闲块,时间复杂度为O(n).
释放算法中,需要合并相邻的空闲块,逻辑复杂且耗时。 - 不支持虚拟化
动态分配要求是对物理内存的的规划,需要对物理内存进行动态分配。因此无法运行大于物理内存的程序。 - 管理困难
因为进程地址是单一连续区域,所以难以对程序进行单独的隔离与管理(如代码段、数据段)。
为解决上述问题,又进化出了非连续的分配管理方式。
页(Paging)
原理 :将物理内存划分为固定大小的页框(Page Frame,4kb),而程序的逻辑地址空间页划分为相同大小的页(Page,4KB)。通过页表(Page Table)完成页到页框的映射,并允许页在物理内存中的不连续。
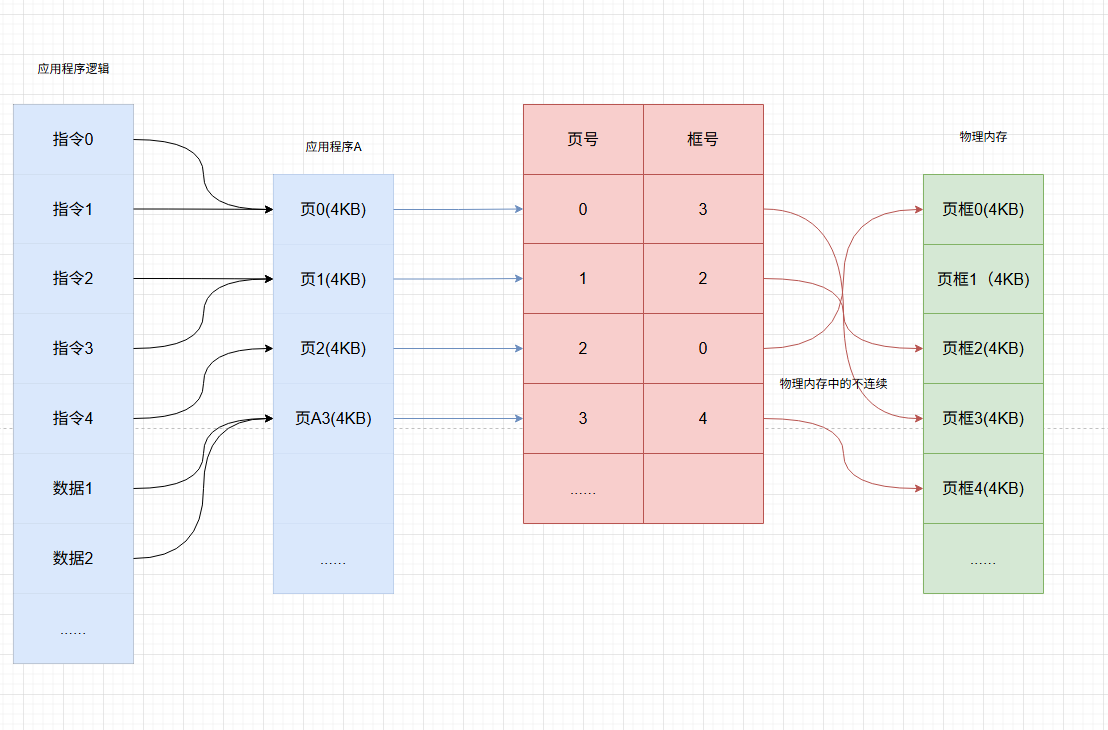
- 优点
完全消除外部碎片,支持虚拟内存地址 - 缺点
存在页内碎片(最后一页可能未填满),页表本身也占用内存
页表转换过程没有图示如此简单,有兴趣可以自行查找资料。
硬件对页的优化
为了加速页表的转换,硬件也使出了多种手段。
- TLB
缓存近期访问的页表项,将地址转换从两次降为一次,(查页表+访问物理内存)=>直接访问物理内存。 - 多级列表
将页表分页存储,减少内存占用。例如,x86-64采用五级页表,支持64位虚拟地址空间。
页管理方式很好,但依旧难以对程序进行单独的隔离与管理(如代码段、数据段)。
段(Segmentation)
原理 :将程序的逻辑模块(如代码段,数据段,栈)分组,每个段在逻辑上连续,但在物理上不连续,通过段表(Segment Table)来实现转换。
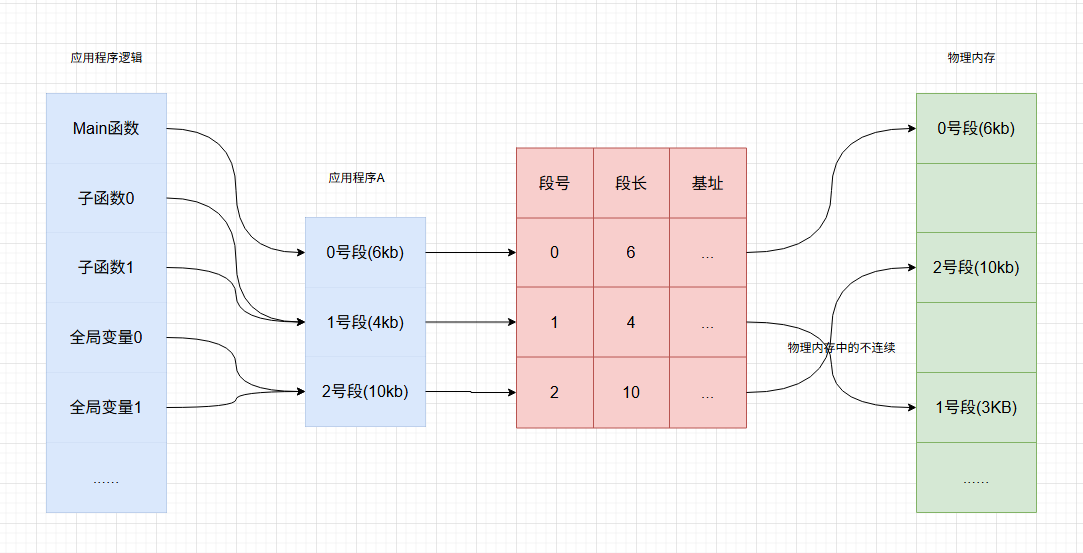
- 优点
符合程序逻辑的结构,很方便的按照分组来实现共享和保护。
比如:多个进程共享同一段代码段。代码段设置只读,数据段设置可写。 - 缺点
可能产生外部碎片,因为段与动态分配很像,不确定大小,所以在分配过程中难免产生碎片。
段也可以引用TLB机制与多级段表来优化效率。
段页(Segmentd Paging)
原理 :结合分页与分段的优势,先将程序划分为段,再将每个段划分为页。通过段表和页表的多级映射实现地址转换。
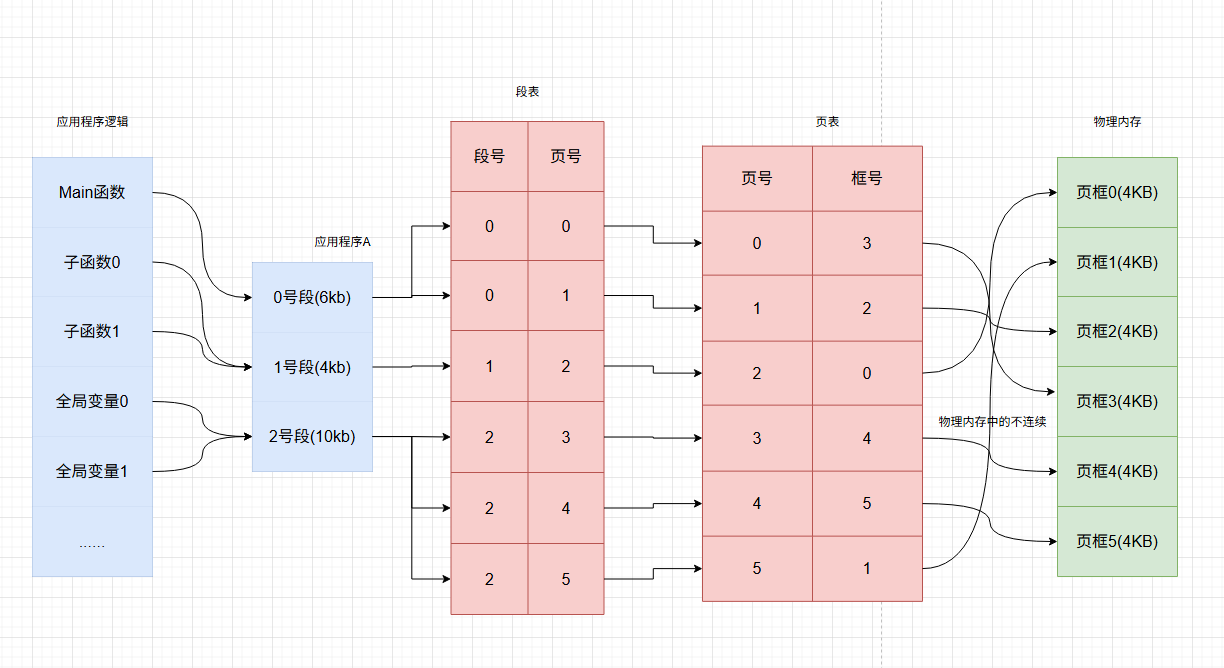
- 优点
兼顾逻辑分段和物理分页的效率,支持虚拟内存和内存保护 - 缺点
空间占用大,地址转换效率低,需要三次(查段表+查页表+访问物理内存)。
现代操作系统的设计应用
- Linux
采用分页方案,使用四级页表(64 位系统),支持大页(Huge Pages,如2MB/1GB)减少页表开销。 - Windows
使用段页方案,使用简化版的段与页,同样使用四级页表与大页。
空间扩充(虚拟化)
为什么我们需要虚拟化内存?
在上述的连续分配/非连续内存分配方案中,进程一次性全部载入内存后才能开始运行。很多暂时用不到的数据也会长期占用内存,导致内存利用率不高。
举个例子,有一个经典游戏叫<三男一狗>,他的容量大小将近100g,如果按照目前的方式,内存容量完全不够。
虚拟化的理论支持:局部性原理
-
时间局部性
如果执行了进程中的某条指令,那么不久后这条指令很有可能再次执行,如果某个数据被访问过,也很有可能再次被访问。 -
空间局部性
一旦程序访问了某个存储单元,那么其附近的存储单元页很有可能被访问。int i;
int a[100];//空间局限性,变量/存储单元基本上都是集中定义在一起,连续存放for(i=0;i<100;i++){ //时间局部性,程序中充斥着大量的循环
a[i]=i;
}
基于局部性原理,在程序载入内存时。
- 可以将程序中
先用到的部分先载入内存,暂时用不到的暂不加载。 - 当所访问的信息
不存在时,由操作系统继续从外存(硬盘)加载到内存(缺页故障)。 - 当内存不够时,由操作系统负责
将用不到的内存swap到外存(硬盘)。
在操作系统的管理下,对于程序而言,它看到的是一个近乎无限大的内存空间,这就是虚拟内存技术。
如何实现虚拟内存?
虚拟内存有以下三个主要特征:
- 多次性
无需在程序运行时一次性全部装入,允许分成多次调用。 - 对换性
无需一直常驻内存,在合适的情况下,允许swap到外存(硬盘)。 - 虚拟性
从逻辑上扩充了内存的容量。"欺骗"进程不再关注实际内存大小。
因为虚拟内存多次性的存在,如果采用连续分配的方式,就实现不了了。因此,虚拟内存的实现需要建立在'离散分配'的内存管理方式。
没错,正是在下!非连续内存分配!
少林功夫+足球=大有搞头!非连续内存分配+虚拟内存=目前主流操作系统的选择
因此,在非连续内存分配的基础上,再由操作系统添加缺页故障纠错(多次性)与swap(对换性)功能,即可实现。
如何实现添加缺页故障纠错(请求分页)
- 请求页表
与之前提到过的页管理相比,为了实现添加缺页故障纠错,操作系统需要知道每个页是否已经载入内存,如果没有,需要存储外存的位置。
那么,我们对之前页的模型图稍加扩充,就变成了下面的这个样子,该页表也被称为请求页表
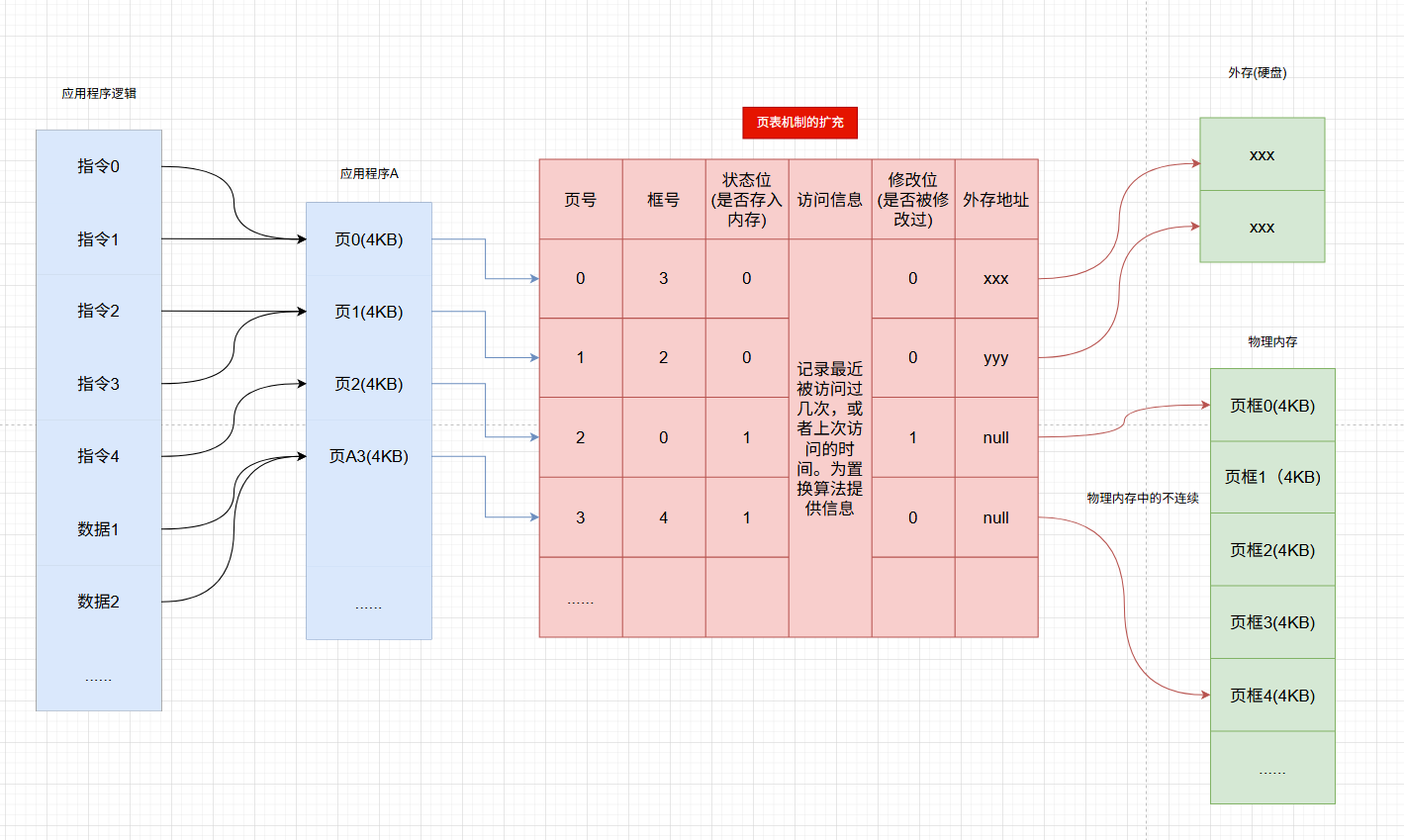
- 缺页中断机构
在请求分页中,当要访问的页不存在时,操作系统便会产生一个缺页中断,然后系统故障Fault,搜索中断描述表(Interrupt Descriptor Table),找到对应的中断处理程序。
此时缺页的进程会陷入阻塞,放入阻塞队列,调页完成后再将其唤醒,放回就绪队列。
调页:如果内存中有空闲块,则为进程分配一个空闲块,并更新请求页表。
如果内存空间不足,则由页面置换算法选择一个淘汰的页,若页被修改过,则将其写回外存。如果修改过,直接丢弃。完成后更新请求页表。
页面置换算法
页面置换算法是虚拟内存管理的核心技术,用于在物理内存不足时,选择将哪些页面从内存中置换到外存,以腾出空间加载新页面
-
OPT, Optimal Algorithm
原理:选择未来最长时间不被访问的页面,理论上缺页率最低
优点:性能最佳
缺点:无法实现,因为操作系统无法预知程序的行为
-
FIFO, First-In-First-Out
原理:置换最早进入的页面
优点:实现简单,用一个链表记录进入队列即可实现
缺点:产生belady异常,且与程序运行规律不相符,因为最早进入的页面,往往最经常被使用。
比如你代码中的第一个变量,其生命周期大概率跟随整个方法。
-
LRU, Least Recently Used
原理:淘汰最近最久未使用的页面,当缺页时,逆向扫描最后出现调页的页号就是被淘汰的页
优点:贴合局部性原理,性能接近OPT
缺点:实现复杂,需要硬件支持
-
Clock Algorithm,CLOCK
在上面介绍的几种算法中,OPT性能最好,但无法实现。FIFO实现简单,但性能查。LRU算法接近OPT,但开销大,需要硬件支持。
而CLOCK算法则比较均衡。
原理:为每个页设置一个访问位(R),并将整个页表链接起来形成一个环形队列。首次扫描:若页面 R 位为 1,清 0 并跳过;若为 0,置换该页面。若未找到可置换页面,重复扫描
优点:实现复杂度低,比 FIFO 更高效
缺点:仅用访问位,可能置换频繁访问但近期未被访问的页面
-
Modified Clock Algorithm
该算法是对CLOCK的改进,增加修改位(M),优先置换未被修改且未被访问的页面(减少写回外存的开销),第一轮扫描:找 R=0 且 M=0 的页面(最优候选),若未找到,第二轮扫描:找 R=0 且 M=1 的页面(需写回外存)。
过程中清除 R 位,避免重复扫描
优点:结合访问频率和修改状态,减少 I/O 操作(优先置换干净页面,无需写回)
缺点:精度低于LRU算法
| 算法 | 核心思想 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|---|
| OPT | 未来最远访问 | 理论最优 | 无法实现 | 性能基准 |
| FIFO | 最早进入内存 | 实现简单 | 可能置换活跃页面,Belady现象 | 早期系统(如简单嵌入式) |
| LRU | 最近最少使用 | 贴近局部性,性能优秀 | 实现复杂(需硬件支持) | 通用操作系统(Linux、Windows) |
| Clock/改进版 | 访问位+修改位近似LRU | 平衡性能与实现复杂度 | 精度低于LRU | 实际系统(如Android) |
现代操作系统(如 Linux)通常采用 LRU 改进算法(如反向映射、大页支持),并结合硬件加速(TLB缓存地址转换),在缺页率和性能之间实现高效平衡。
熟悉Redis的朋友肯定对此不陌生