之前在服务器部署neo4j失败,无奈只能在本地部署,导致后期所有使用的知识图谱数据都存在本地,这里为了节省时间,先在本地安装LigthRAG完成整个实验流程,后续在学习各种服务器部署和端口调用。从基础和简单的部分先做起来吧。
1.下载
1.去github下载模型到本地,git clone https://github.com/HKUDS/LightRAG
用idea打开,pycharm新建一个虚拟解释器环境,和其他环境隔开,它的python是基于本地的python来的,左下方红色的报错环境不为空,去删除下就可以了
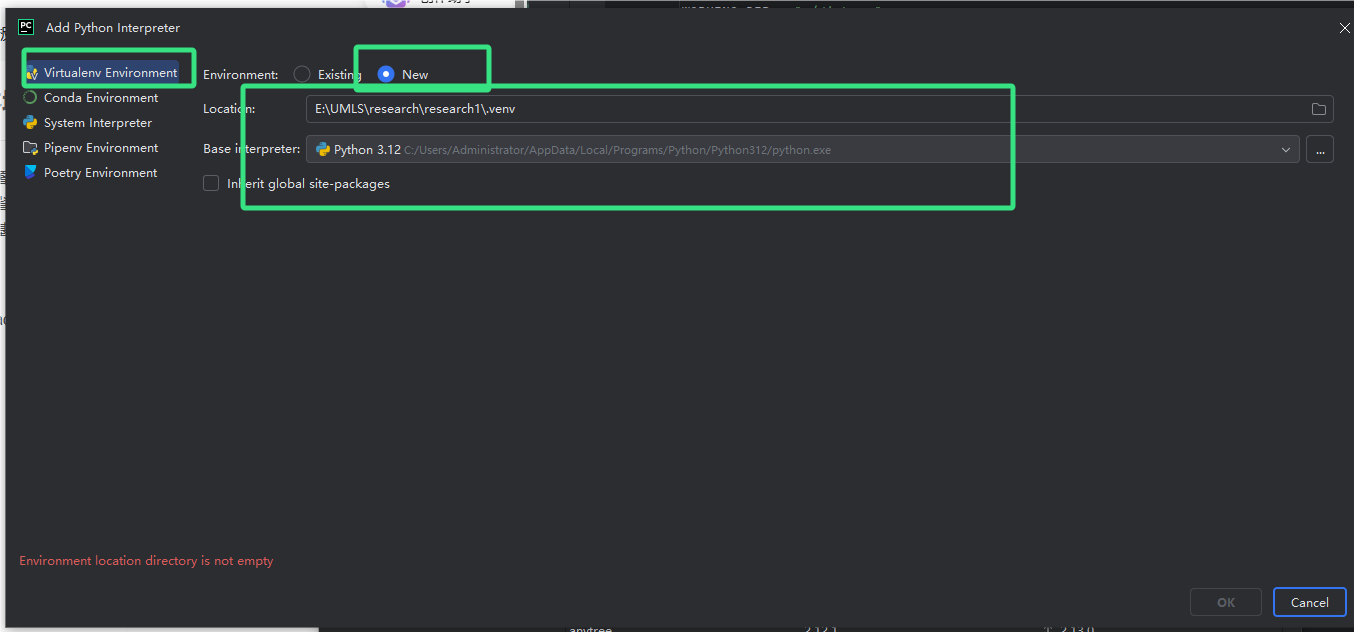
2.选择刚刚创建好的虚拟环境,右下角会变
3.cd 到LightRAG文件夹
cd LightRAG
pip install -e .
接下来开始正式使用,教程如下:
如何快速部署和运行lightRag(轻量版的GraphRag), 并且进行知识图谱的可视化。_哔哩哔哩_bilibili
4.这里我打算基于LLM的现有接口来做,防止部署大模型的麻烦,所以我们打开如下demo
这里我换一下模型接口:
把所示部分换成我的deepseek-v3,我用的是下面这个平台,注册之后就能获取同款deepseek的满血接口和网页版了,花点小钱,但是解决了官网deepseek经常不回复的问题:
Deepseek PPIO算力云https://ppinfra.com/user/register?invited_by=R8Z3RZ注册后访问这里就可以对话式体验(包括可以做一些参数调整)通过上述链接加入记得50元token可通过API开发式 + 网页对话等方式,在体验满血版R1服务(也有其他多种版本),邀请朋友加入,再增 5000 万token!使用教程:用这个版本deepseek/deepseek-r1,别用community,r1和v3必须充钱,送的token可以抵扣一部分,但不能全部抵扣,但是充钱后速度确实又恢复丝滑了,换成下面这样,apikey从我充钱那个网站那里获取
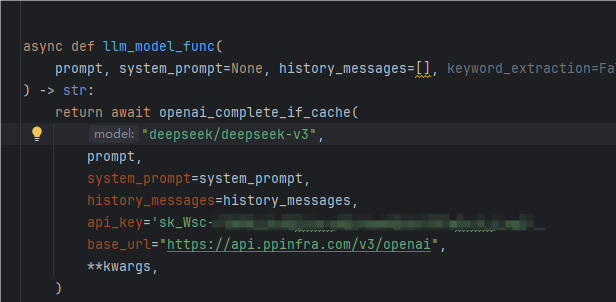
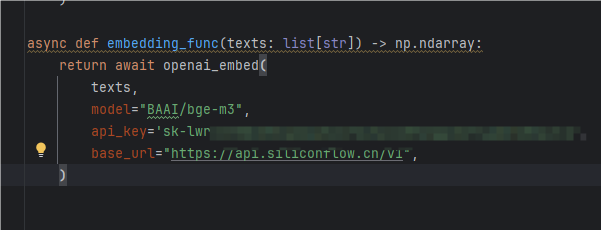
这里的嵌入模型和视频截图用到的一样,因为它免费,申请个api-key就可以用了。注意它使用的embeding是1024维度。获取链接如下:硅基流动用户系统,统一登录 SSO

所以下面的维度也要改下参数,改成1024维度

这里注意一下新的url跟之前官网给的不一样
'
准备一个测试文档:我从一个医学网站上爬取的关于阿尔兹海默的专业版介绍,存入txt
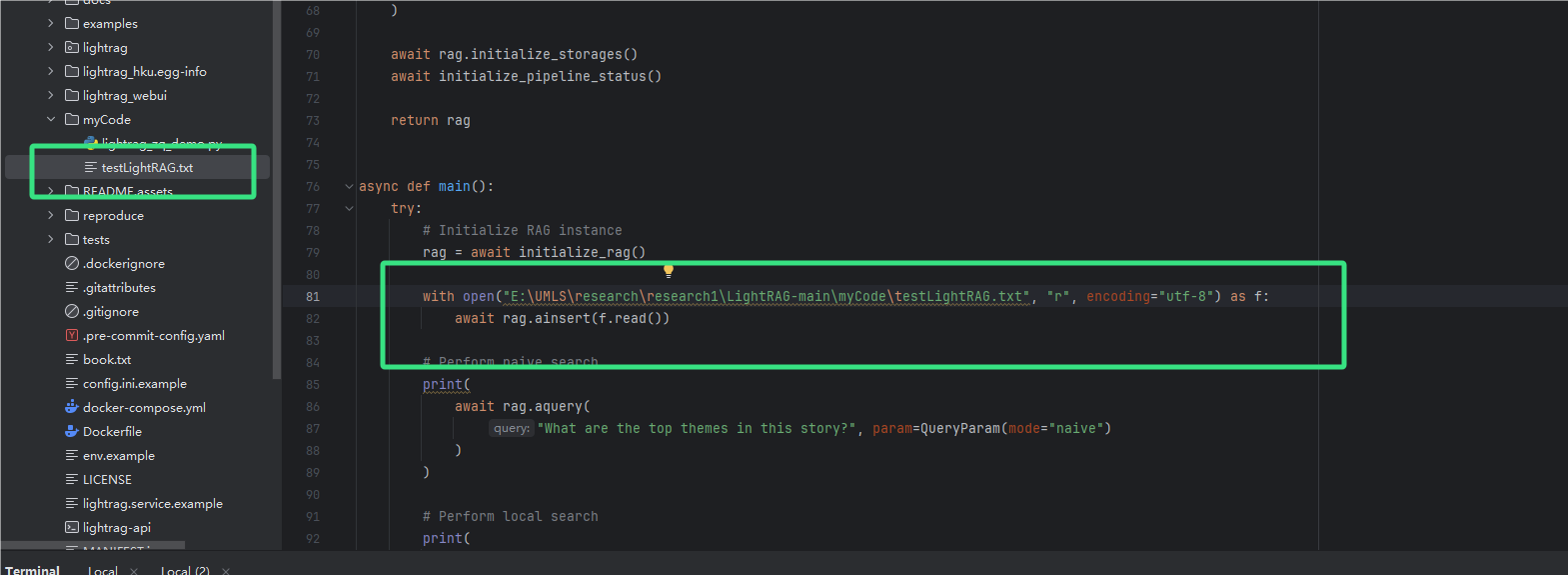
withopen的路径改成我们所需要的测试文档路径
针对文档修改下待会要测试RAG的问题
直接运行这个代码应该就行了
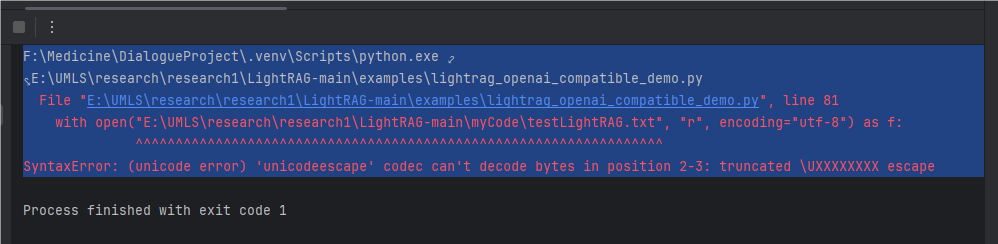
这个错误是因为在 Python 字符串中,反斜杠\在默认情况下被视为转义字符。在你的文件路径字符串中,\U被 Python 解释器识别为一个无效的转义序列,因为它后面没有跟着 8 个十六进制数字(\U用于表示 4 字节的 Unicode 字符),从而导致了SyntaxError错误。
在字符串前面加上r前缀,将其声明为原始字符串,这样 Python 就不会对反斜杠进行转义处理。:
with open(r"E:\UMLS\research\research1\LightRAG-main\myCode\testLightRAG.txt", "r", encoding="utf-8") as f:
运行完以后可以看见RAG的效果已经出来了:
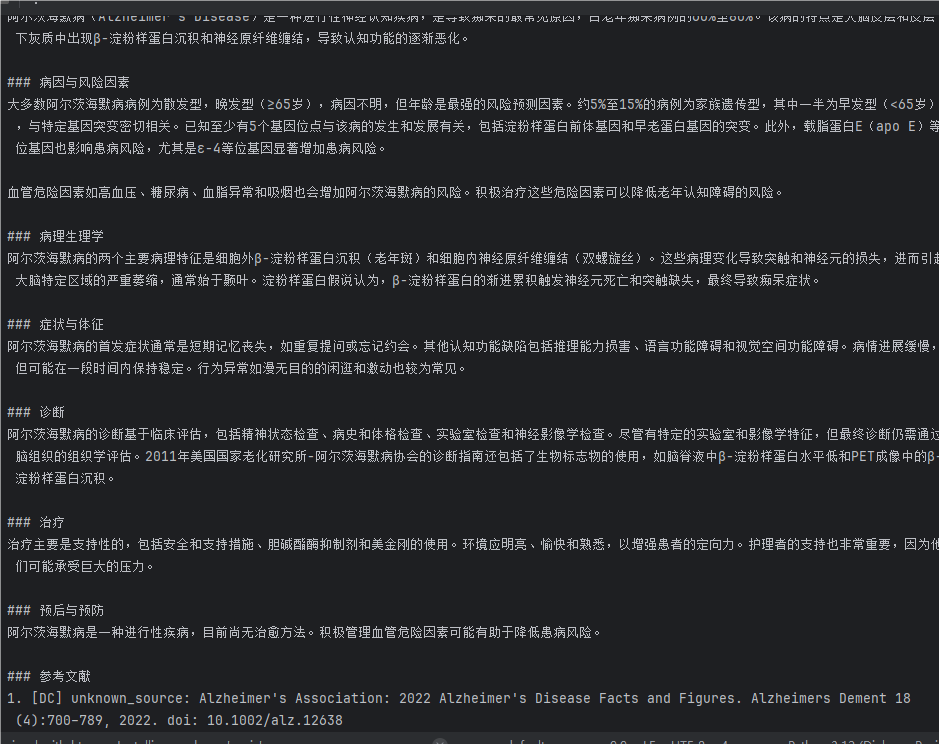
下面分析一下这些检索结果
/n
------------------------------------------------------------naive模式的输出------------------------------------
/n
阿尔茨海默病(Alzheimer's Disease)是一种进行性神经认知疾病,是导致痴呆的最常见原因,占老年痴呆病例的60%至80%。该病的特点是大脑皮层和皮层下灰质中出现β-淀粉样蛋白沉积和神经原纤维缠结,导致认知功能的逐渐恶化。
### 病因与风险因素
大多数阿尔茨海默病病例为散发型,晚发型(≥65岁),病因不明,但年龄是最强的风险预测因素。约5%至15%的病例为家族遗传型,其中一半为早发型(<65岁),与特定基因突变密切相关。已知至少有5个基因位点与该病的发生和发展有关,包括淀粉样蛋白前体基因和早老蛋白基因的突变。此外,载脂蛋白E(apo E)等位基因也影响患病风险,尤其是ε-4等位基因显著增加患病风险。
血管危险因素如高血压、糖尿病、血脂异常和吸烟也会增加阿尔茨海默病的风险。积极治疗这些危险因素可以降低老年认知障碍的风险。
### 病理生理学
阿尔茨海默病的两个主要病理特征是细胞外β-淀粉样蛋白沉积(老年斑)和细胞内神经原纤维缠结(双螺旋丝)。这些病理变化导致突触和神经元的损失,进而引起大脑特定区域的严重萎缩,通常始于颞叶。淀粉样蛋白假说认为,β-淀粉样蛋白的渐进累积触发神经元死亡和突触缺失,最终导致痴呆症状。
### 症状与体征
阿尔茨海默病的首发症状通常是短期记忆丧失,如重复提问或忘记约会。其他认知功能缺陷包括推理能力损害、语言功能障碍和视觉空间功能障碍。病情进展缓慢,但可能在一段时间内保持稳定。行为异常如漫无目的的闲逛和激动也较为常见。
### 诊断
阿尔茨海默病的诊断基于临床评估,包括精神状态检查、病史和体格检查、实验室检查和神经影像学检查。尽管有特定的实验室和影像学特征,但最终诊断仍需通过脑组织的组织学评估。2011年美国国家老化研究所-阿尔茨海默病协会的诊断指南还包括了生物标志物的使用,如脑脊液中β-淀粉样蛋白水平低和PET成像中的β-淀粉样蛋白沉积。
### 治疗
治疗主要是支持性的,包括安全和支持措施、胆碱酯酶抑制剂和美金刚的使用。环境应明亮、愉快和熟悉,以增强患者的定向力。护理者的支持也非常重要,因为他们可能承受巨大的压力。
### 预后与预防
阿尔茨海默病是一种进行性疾病,目前尚无治愈方法。积极管理血管危险因素可能有助于降低患病风险。
### 参考文献
1. [DC] unknown_source: Alzheimer's Association: 2022 Alzheimer's Disease Facts and Figures. Alzheimers Dement 18 (4):700--789, 2022. doi: 10.1002/alz.12638
2. [DC] unknown_source: Kinney JW, Bemiller SM, Murtishaw AS, et al: Inflammation as a central mechanism in Alzheimer's disease. Alzheimers Dement (NY) 4:575--590, 2018. doi: 10.1016/j.trci.2018.06.014
3. [DC] unknown_source: González A, Calfío C, Churruca M, Maccioni RB: Alzheimers Res Ther 14 (1):56, 2022. doi: 10.1186/s13195-022-00996-8
4. [DC] unknown_source: Jack CR Jr, Albert MS, Knopman DS, et al: Introduction to the revised criteria for the diagnosis of Alzheimer's disease: National Institute on Aging and Alzheimer's Association workgroups. Alzheimers Dement 7 (3):257--262, 2011. doi: 10.1016/j.jalz.2011.03.004
5. [DC] unknown_source: McKhann GM, Knopman DS, Chertkow H, et al: The diagnosis of dementia due to Alzheimer's disease: Recommendations from the National Institute on Aging-Alzheimer's Association workgroups on diagnostic guidelines for Alzheimer's disease. Alzheimers Dement 7 (3):263--269, 2011. doi: 10.1016/j.jalz.2011.03.005
/n
------------------------------------------------------------local模式的输出------------------------------------
/n
阿尔茨海默病是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。它与其他类型的痴呆症,如血管性痴呆和路易体痴呆,在病因和治疗方法上有所不同,尽管它们的症状可能相似。
### 预防措施
以下措施可以帮助降低阿尔茨海默病的发病风险:
- **智力活动**:如学习新技能或做数独。
- **身体锻炼**:有规律的身体锻炼对预防阿尔茨海默病非常重要。
- **控制高血压**和**降低胆固醇水平**:这些健康管理措施有助于降低发病风险。
- **饮食调整**:增加富含ω-3脂肪酸的食物,减少饱和脂肪酸的摄入。
- **适量饮酒**:少量饮酒可能降低风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。
### 治疗
在晚期阿尔茨海默病中,**姑息治疗**可能比激进疗法或住院治疗更为可取。
### 诊断与支持
**Alzheimer's Association**提供了关于阿尔茨海默病的诊断工具、研究支持和信息资源,有助于早期诊断和获取相关信息。
### 关键点
- 阿尔茨海默病大多数病例是零散的,年龄是最大的风险因素。
- 与其他痴呆症的区分可能困难,但通常可通过临床标准进行区分,诊断准确性可达85%。
### References
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source
/n
------------------------------------------------------------global模式的输出------------------------------------
/n
阿尔茨海默病(Alzheimer's disease)是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。这种疾病的预防措施包括智力活动、身体锻炼、控制血压和胆固醇水平等。以下是一些关键点:
### 预防措施
1. **智力活动**:如学习新技能或做数独,可以降低阿尔茨海默病的发病风险。
2. **身体锻炼**:有规律的身体锻炼是预防阿尔茨海默病的重要措施之一。
3. **饮食调整**:减少饱和脂肪酸的摄入,增加富含ω-3脂肪酸的食物,有助于降低风险。
4. **健康管理**:控制高血压和降低胆固醇水平也是预防阿尔茨海默病的关键因素。
5. **饮酒**:少量饮酒可能降低阿尔茨海默病的风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。
### 诊断与治疗
阿尔茨海默病的诊断可能与其他类型的痴呆症(如血管性痴呆和路易体痴呆)有所混淆,但通常可以通过临床标准进行区分,诊断准确性可达85%。在晚期阿尔茨海默病中,姑息治疗可能比激进疗法或住院治疗更为可取。
### 资源支持
Alzheimer's Association 是一个提供阿尔茨海默病诊断工具、研究支持和信息的网站,可以帮助患者和家属获取更多资源和信息。
### References
1. [KG] unknown_source
2. [KG] unknown_source
3. [KG] unknown_source
/n
------------------------------------------------------------hybrid模式的输出------------------------------------
/n
阿尔茨海默病(阿尔兹海默症)是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。以下是关于阿尔茨海默病的一些关键信息:
### 预防措施
1. **智力活动**:如学习新技能或做数独,可以降低发病风险。
2. **身体锻炼**:有规律的身体锻炼是预防阿尔茨海默病的重要措施之一。
3. **控制高血压**:降低高血压有助于减少发病风险。
4. **降低胆固醇水平**:保持健康的胆固醇水平有助于预防阿尔茨海默病。
5. **饮食调整**:富含ω-3脂肪酸、少含饱和脂肪酸的食物有助于降低风险。
6. **饮酒**:少量饮酒可能降低风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。
### 与其他痴呆症的区别
阿尔茨海默病与血管性痴呆和路易体痴呆是不同类型的痴呆症,尽管症状相似,但病因和治疗方法有所不同。
### 晚期治疗
在晚期阿尔茨海默病中,姑息治疗可能比激进疗法或住院治疗更为可取。
### 资源支持
Alzheimer's Association 提供关于阿尔茨海默病的诊断工具、研究支持和信息资源。
### 关键点
- 大多数阿尔茨海默病病例是零散的,年龄是最大的风险因素。
- 区分阿尔茨海默病和其他原因引起的痴呆(如血管性痴呆、路易体痴呆)可能困难,但通常可使用临床标准区分,诊断准确性达85%。
### References
1. [KG] unknown_source
2. [KG] unknown_source
3. [KG] unknown_source
4. [KG] unknown_source
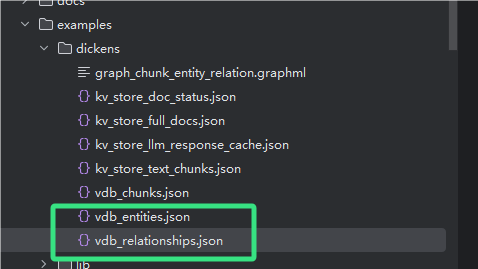
5. [KG] unknown_source运行之后会在example里生成/dickens文件夹,生成这个运行过程中生成的一些过程文件,如果运行正确,会生成如下文件(包含知识图谱的边,节点等内容),根据所至py文件运行一下,生成可视化:

运行可视化相关的py文件之后,
按照之前代码的逻辑,运行后会在当前工作目录生成knowledge_graph.html文件,你可以通过以下方式查看可视化效果:
- 文件资源管理器 :打开文件资源管理器,导航到运行代码时所在的目录(根据代码中
net.show("knowledge_graph.html"),推测是E:\UMLS\research\research1\LightRAG-main\examples目录)。找到knowledge_graph.html文件,双击打开它,浏览器会加载并展示可视化的图形。 
这个目录可以看生成的实体和关系,我第一次运行没抽取出来,应该是文档模型抽风了,再运行一次就好啦
知识图谱的效果如下:

接下来研究下怎么把LightRAG生成的图谱存入neo4j,方便后续使用

neo4j中我已经提前存过其它知识图谱了,我想在不干扰原图谱的情况下,把新图谱存入已有的database,方法就是在节点和关系上都打上特殊的标签,查询和使用的时候带上标签就行,因此,我要对demo里的example进行以下修改,代码如下:
import os
import json
from lightrag.utils import xml_to_json
from neo4j import GraphDatabase
WORKING_DIR = "./dickens"
BATCH_SIZE_NODES = 500
BATCH_SIZE_EDGES = 100
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
def convert_xml_to_json(xml_path, output_path):
if not os.path.exists(xml_path):
print(f"Error: File not found - {xml_path}")
return None
json_data = xml_to_json(xml_path)
if json_data:
with open(output_path, "w", encoding="utf-8") as f:
json.dump(json_data, f, ensure_ascii=False, indent=2)
print(f"JSON file created: {output_path}")
return json_data
else:
print("Failed to create JSON data")
return None
def process_in_batches(tx, query, data, batch_size):
for i in range(0, len(data), batch_size):
batch = data[i: i + batch_size]
print(f"[INFO] Inserting batch {i // batch_size + 1} with {len(batch)} items...")
tx.run(query, {"items": batch})
def main():
xml_file = os.path.join(WORKING_DIR, "graph_chunk_entity_relation.graphml")
json_file = os.path.join(WORKING_DIR, "graph_data.json")
json_data = convert_xml_to_json(xml_file, json_file)
if json_data is None:
return
nodes = json_data.get("nodes", [])
edges = json_data.get("edges", [])
print(f"[INFO] Total nodes found: {len(nodes)}")
print(f"[INFO] Total edges found: {len(edges)}")
if len(nodes) == 0 and len(edges) == 0:
print("[ERROR] No nodes or edges found!")
return
# 自动创建所有节点属性
create_nodes_query = """
UNWIND $items AS node
MERGE (e:Entity {id: node.id})
SET e += node
WITH e, node
CALL apoc.create.addLabels(e, ['med_network', node.entity_type]) YIELD node AS labeledNode
RETURN count(*)
"""
# 自动创建所有边属性
create_edges_query = """
UNWIND $items AS edge
MERGE (source:Entity {id: edge.source})
MERGE (target:Entity {id: edge.target})
WITH source, target, edge,
'med_network_' + REPLACE(SPLIT(edge.keywords, ',')[0], '\"', '') AS relType
CALL apoc.create.relationship(source, relType, edge, target) YIELD rel
RETURN count(*)
"""
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
try:
with driver.session(database="umls") as session:
print("[INFO] Inserting nodes...")
session.execute_write(process_in_batches, create_nodes_query, nodes, BATCH_SIZE_NODES)
print("[INFO] Inserting edges...")
session.execute_write(process_in_batches, create_edges_query, edges, BATCH_SIZE_EDGES)
print("[SUCCESS] med_network knowledge graph inserted with full attributes!")
except Exception as e:
print(f"[ERROR] Neo4j execution error: {e}")
finally:
driver.close()
if __name__ == "__main__":
main()效果如下,不知道为啥插入还有中英文的版本,但我的原文档没有英文:

下面是大模型对于存在英文抽取的解释:
这个现象其实是 LightRAG 知识图谱构建逻辑的必然结果,核心原因是 ------
LightRAG 的知识抽取模型(特别是 Entity 和 Relation 的抽取)默认是使用英文基础模型或者英文优先的多语言模型,它并不完全区分输入文本的语言。
具体机制
LightRAG 的流程大致是:
-
输入文档(不管是中文/英文)
-
切分句子 -> 分词 -> 实体识别(NER)-> 关系抽取(RE)
-
将识别到的 Entity / Relation 存入 Neo4j 等图数据库
-
Entity 和 Relation 的命名依赖:
-
文本中出现的原文
-
模型内置的英文知识库(Embedding / LLM 检索补全)
-
Tokenizer(很多是英文分词器)
-
-
最终生成的三元组:
mathematica
复制编辑
(中文Entity, 英文Relation, 中文Entity) (英文Entity, 英文Relation, 英文Entity) (中文Entity, 中文Relation, 英文Entity)
这种混合非常常见。
为什么中文文档中会混入英文 Entity/Relation?
| 原因 | 说明 |
|---|---|
| 1. Entity Linking / Entity Normalization | 抽取到的实体如果在英文知识库有对应 entry,可能会被自动转为英文版 |
| 2. Relation Schema 设计是英文 | LightRAG 内置的 relation schema 直接是英文 ,比如:cause_of、located_in、treats |
| 3. 使用的 NER 和 RE 模型是英文优先 | 中文的实体如果模型觉得是医学术语、专业词汇,容易强行补全英文对应 |
| 4. tokenizer 或 embeddings 不支持纯中文 | 很多 pretrain 的模型使用英文词表为主,导致中英文混用是常态 |
举个例子
输入中文:
阿尔茨海默病 是一种 神经系统疾病
LightRAG 知识图谱输出:
css
复制编辑
(:Entity {id: '阿尔茨海默病'}) -[:type_of]-> (:Entity {id: 'neuro disease'})
原因是:
-
type_of来自内置 relation schema -
neuro disease是模型自动 linking 到医学知识库的英文 entry
如何避免这种情况?
方法一:定制 relation schema
-
全部中文定义 relation
-
代码中指定:
python
复制编辑
relation_schema = { '属于': 'type_of', '位于': 'located_in', '导致': 'cause_of', ... }
抽取后强制替换 relation 名称。
方法二:禁用 entity linking
-
不让模型自动 link 英文知识
-
保留原文 entity
-
只做中文实体 + 中文关系
缺点:丧失一部分跨语言知识补全能力
方法三:自定义抽取模型
-
用中文NER + 中文RE
-
推荐:
-
中文版 Bert-NER
-
中文版 CasRel / TPLinker
-
-
Huggingface 已有很多中文版本
方法四:抽取后做一遍 entity normalize
-
自定义 entity normalization 映射表
-
将所有英文 entity 替换回中文
最推荐的方案
| 场景 | 推荐做法 |
|---|---|
| 医疗知识图谱、科研知识图谱 | 保留中英文双语(专业英文保留,有利于跨文献对齐) |
| 面向C端业务、用户知识问答 | 强制全中文化,优化体验 |
结论
你现在看到的中英文混杂,是 LightRAG 知识抽取模型为了增强知识丰富度**,主动做的 linking 行为**------ 但可以通过定制 relation schema、entity normalize 或自定义模型来控制。
其它:
词嵌入模型,如果要用LightRAG处理的原文档是中文的,可以去魔塔下载bge-large-zh-v1.5
了解一下LightRAG
知识图谱抽取过程)(是用提前写好的大模型提示词封装好之后完成的)
学习资料来自下方博主:基于知识图谱做rag Lightrag中实体关系的提取及图谱的生成_哔哩哔哩_bilibili

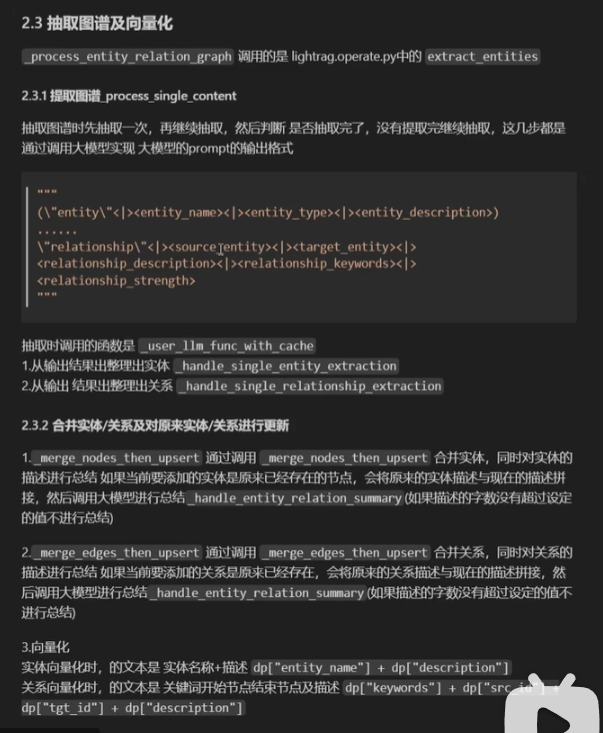
抽取的内容不仅有实体、关系、还有关系强度。其中节点和关系都有一个描述,当再次抽取到类似实体和关系时,知识图谱的节点和边不会更新,但是他们的描述会更新

5.怎么运行
需要三个主要部分:调用处理大模型、调用嵌入模型,运行lightRAG的主代码(标志是会执行rag.insert(f.aread这一句)
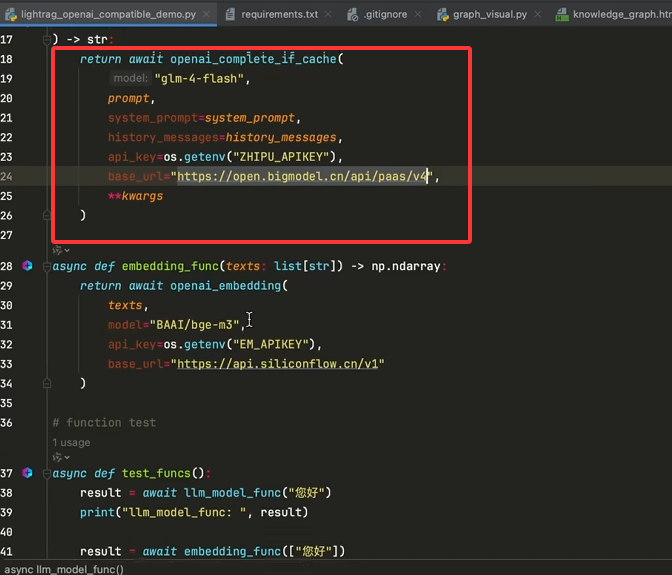
第一部分 配置大模型和嵌入模型的代码长下面这样,这里的模型是调接口获得的,应该是阿里云的智谱平台
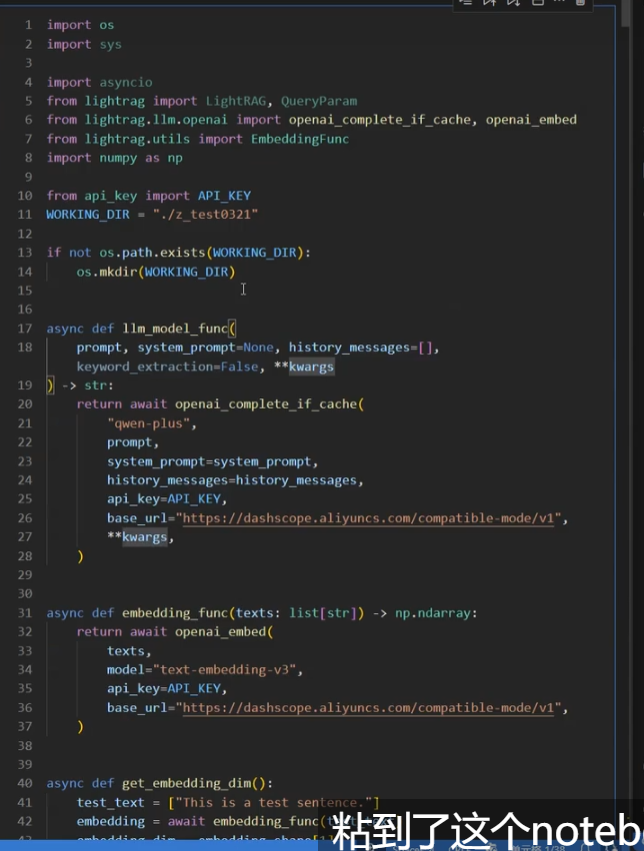
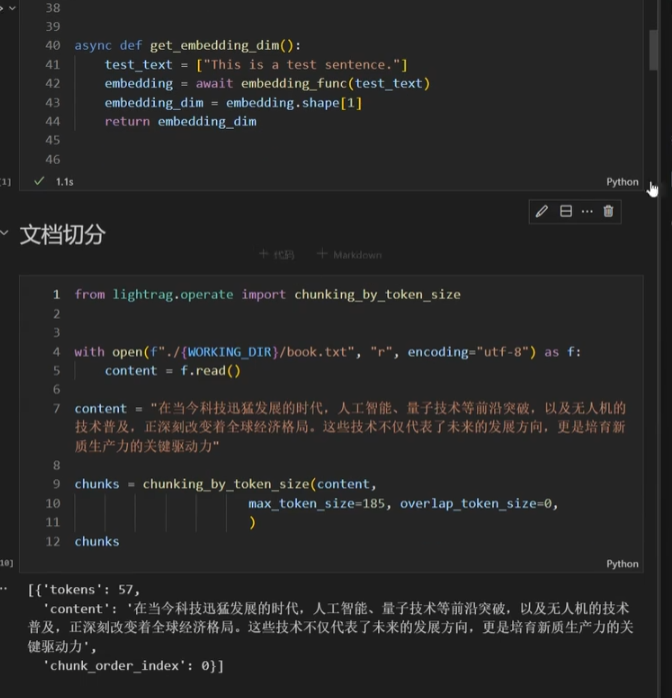
主代码如下:
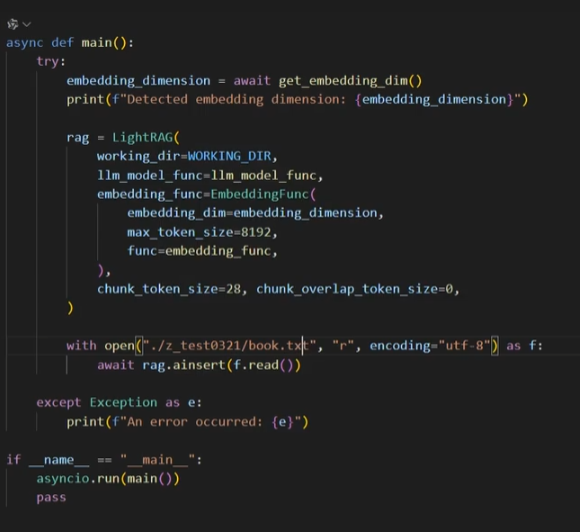
运行主函数后,就会从ainsert进行文档处理,分块,分布抽取等过程,关系和实体都处理完之后会做向量化保存
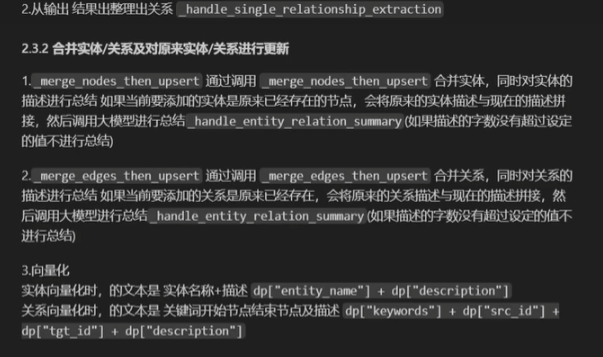
接着用大模型进行去重,判断实体等是否相同dakda'k,