GPT-1(Generative Pre-Training 1)
⭐模型结构
-
Transformer only-decoder:GPT-1模型使用了一个12层的Transformer解码器。具体细节与标准的Transformer相同,但位置编码是可训练的。
-
注意力机制:
-
原始Transformer的解码器包含两种注意力机制:交叉注意力(cross-attention,其中键和值来自编码器,查询来自解码器)和掩码多头自注意力(mask multi-head attention)。
-
GPT-1模型只使用了掩码多头自注意力。
-

图示说明
-
左侧图示:展示了Transformer的架构,包括12层的解码器、层归一化(Layer Norm)、前馈网络(Feed Forward)、掩码多头自注意力(Masked Multi Self Attention)以及文本和位置嵌入(Text & Position Embed)。
-
右侧图示 :展示了不同任务的输入转换和训练目标。所有结构化的输入都被转换为标记序列,然后通过预训练模型处理,最后通过一个线性-softmax层进行分类。
不同任务的训练目标
1. 分类(Classification)
输入格式 :Start Text Extract
-
解释:输入文本以"Start"标记开始,后面跟着要分类的文本,最后以"Extract"标记结束。
-
处理流程:
-
输入文本经过文本和位置嵌入(Text & Position Embed)。
-
嵌入后的文本输入到Transformer模型中进行处理。
-
Transformer的输出经过一个线性层(Linear),输出分类结果。
-
2. 蕴含(Entailment)
输入格式 :Start Premise Delim Hypothesis Extract
-
解释:输入包含两个部分,前提(Premise)和假设(Hypothesis),中间用分隔符(Delim)分开,以"Start"标记开始,最后以"Extract"标记结束。
-
处理流程:
-
输入文本经过文本和位置嵌入(Text & Position Embed)。
-
嵌入后的文本输入到Transformer模型中进行处理。
-
Transformer的输出经过一个线性层(Linear),输出蕴含关系的分类结果(例如,前提是否蕴含假设)。
-
3. 相似性(Similarity)
输入格式 :Start Text 1 Delim Text 2 Extract
-
解释:输入包含两个文本,中间用分隔符(Delim)分开,以"Start"标记开始,最后以"Extract"标记结束。
-
处理流程:
-
输入文本经过文本和位置嵌入(Text & Position Embed)。
-
嵌入后的文本输入到两个Transformer模型中进行处理(每个文本一个Transformer)。
-
两个Transformer的输出经过一个线性层(Linear),输出两个文本的相似性得分。
-
4. 多项选择(Multiple Choice)
输入格式 :Start Context Delim Answer 1 Extract 等
-
解释:输入包含一个上下文(Context)和多个可能的答案(Answer),每个答案之间用分隔符(Delim)分开,以"Start"标记开始,最后以"Extract"标记结束。
-
处理流程:
-
输入文本经过文本和位置嵌入(Text & Position Embed)。
-
嵌入后的文本输入到Transformer模型中进行处理。
-
Transformer的输出经过一个线性层(Linear),输出每个答案的选择概率。
-
训练范式
训练范式(Training Paradigm)是指在机器学习和深度学习中,用于训练模型的一系列方法和策略。它定义了模型如何从数据中学习以及如何优化其参数。不同的训练范式适用于不同的任务和数据类型,常见的训练范式包括:
详见上一篇文章
-
监督学习(Supervised Learning)
-
无监督学习(Unsupervised Learning)
-
半监督学习(Semi-supervised Learning)
-
自监督学习(Self-supervised Learning)
-
强化学习(Reinforcement Learning)
-
迁移学习(Transfer Learning)
-
多任务学习(Multi-task Learning)
GPT-1模型的训练范式
- 自监督预训练 + 有监督微调:主要思想是无监督学习。
预训练的标准语言模型目标函数
-
目标函数:根据前面K个词预测下一个词。
-

- 解释:这是一个自回归模型,给定前面的K个词,预测下一个词的概率。
微调的目标函数
-
目标函数:用的是完整的输入序列加标签,有监督目标函数加无监督目标函数,y是标签。
-
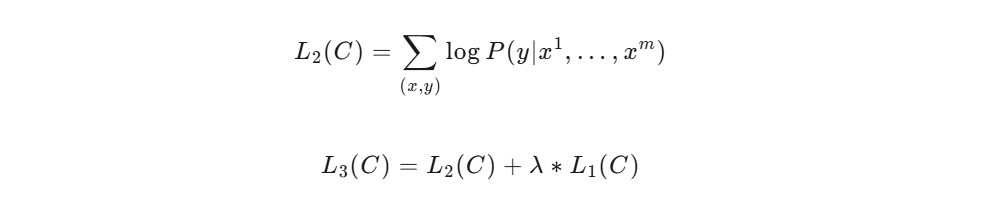
- 解释:这是一个有监督学习目标函数,给定输入序列x,预测标签y的概率。同时加入无监督目标函数L1,以增加模型的泛化性和加速收敛。
输入形式创新
-
输入形式:通过在序列前后添加Start和Extract特殊标识符来表示开始和结束,序列之间添加必要的Delim标识符来表示分隔。
- 解释:通过这种方式,可以处理不同的下游任务。例如,分类任务、蕴含任务、相似性任务和多项选择任务。