原文作者:aircraft
原文链接:pytorch 实战教程之 Feature Pyramid Networks (FPN) 特征金字塔网络实现代码 - aircraft - 博客园
学习YOLOv5前的准备就是学习DarkNet53网络,FPN特征金字塔网络,PANet结构,SPPF结构等。本篇讲FPN特征金字塔网络。。。
特征金字塔网络(Feature Pyramid Networks, FPN)结构详解
1. 核心思想
FPN 通过结合 深层语义信息 (高层特征)和 浅层细节信息(低层特征),构建多尺度的特征金字塔,显著提升目标检测模型对不同尺寸目标的检测能力。
2. 网络结构组成
FPN 由以下核心组件构成:
| 组件 | 作用 | 对应代码部分 |
|---|---|---|
| 骨干网络(自底向上C2-C5) | 提取多尺度特征(如ResNet) | layer1-layer4 |
| 自顶向下路径(P5-P2) | 通过上采样传递高层语义信息 | _upsample_add |
| 横向连接 | 将不同层级的特征对齐通道后融合 | latlayer1-latlayer3 |
| 特征平滑层 | 消除上采样带来的混叠效应 | smooth1-smooth3 |
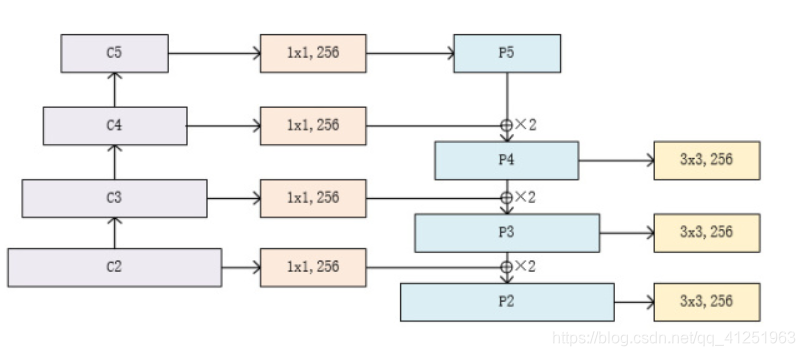
3. 详细结构分解
3.1 骨干网络(Bottom-Up Pathway)
在这个过程中,特征图的分辨率逐渐降低,而语义信息逐渐丰富。每一层特征图都代表了输入图像在不同尺度上的抽象表示
-
作用:逐级提取特征,分辨率递减,语义信息递增
-
典型实现:ResNet的四个阶段(C1-C5)
-
输出特征图:
`C2: [H/4, W/4, 256] (高分辨率,低层细节) C3: [H/8, W/8, 512] C4: [H/16, W/16, 1024] C5: [H/32, W/32, 2048] (低分辨率,高层语义)` -
代码对应:
# 构建四个特征提取阶段(stage)
# stage1: 不进行下采样(stride=1)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
# stage2: 进行下采样(stride=2)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)骨干网络(自底向上,从C2到C5):
C2到C5代表不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
Bottleneck结构(瓶颈残差块):包含三个卷积层,能够有效减少参数数量并提升性能。ResNet-18使用基础的残差块BasicBlock:两个3*3的卷积层,而ResNet-50使用Bottleneck块:一个1*1的卷积层降低通道数目,然后到3*3的卷积层融合特征,再到1*1的卷积层恢复通道数。
3.2 自顶向下路径(Top-Down Pathway) (从P5-P2):
为了解决高层特征图分辨率低、细节信息少的问题,FPN引入了自顶向下的特征融合路径。首先对C5进行1x1卷积降低通道数得到P5,然后依次进行双线性差值上采样后与C2-C4层横向连接过来的数据直接相加,分别得到P4-P2,P4,P3,P2在通过一个3*3的平滑卷积层使得数据融合输出。
流程:
- 顶层处理:C5 → 1x1卷积 → P5
- 逐级上采样:P5 → 上采样 → 与C4融合 → P4 → 上采样 → 与C3融合 → P3 ...
P5 (高层语义)
↓ 上采样2x
P4 = P5上采样 + C4投影
↓ 上采样2x
P3 = P4上采样 + C3投影
↓ 上采样2x
P2 = P3上采样 + C2投影核心操作就是通过双线性上采样后的高层特征与浅层数据直接相加后续融合:
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.interpolate(x, (H,W), mode='bilinear') + y # 双线性上采样3.3 横向连接(Lateral Connections):
目的是为了将上采样后的高语义特征与浅层的定位细节进行融合,实现多尺度特征融合(通过横向连接将浅层细节与深层语义结合),横向连接不仅有助于传递低层特征图的细节信息,还可以增强高层特征图的定位能力。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256。因此需要对特征C2------C4进行1x1卷积使得其通道数变为256.,然后两者进行逐元素相加得到P4、P3与P2。
- 作用:将骨干网络特征与上采样特征对齐通道
- 实现方式:1x1卷积(通道压缩/对齐)
- 代码对应:
self.latlayer1 = nn.Conv2d(1024, 256, 1) # C4 (1024通道) → 256通道
self.latlayer2 = nn.Conv2d(512, 256, 1) # C3 (512通道) → 256通道
self.latlayer3 = nn.Conv2d(256, 256, 1) # C2 (256通道) → 保持256通道3.4 特征平滑(Smoothing):
得到相加后的特征后,利用3x3卷积对生成的P2,P3,P4进行融合。目的是消除上采样过程中带来的重叠效应,以生成最终的特征图。
- 作用:消除上采样导致的锯齿状伪影
- 实现方式:3x3卷积(不改变分辨率)
- 代码对应:
self.smooth1 = nn.Conv2d(256, 256, 3, padding=1) # P4平滑
self.smooth2 = nn.Conv2d(256, 256, 3, padding=1) # P3平滑
self.smooth3 = nn.Conv2d(256, 256, 3, padding=1) # P2平滑4. 输出特征金字塔
| 特征层 | 分辨率(相对于输入) | 通道数 | 适用目标尺寸 |
|---|---|---|---|
| P2 | 1/4 | 256 | 小目标(<32x32像素) |
| P3 | 1/8 | 256 | 中等目标(32-96像素) |
| P4 | 1/16 | 256 | 大目标(>96x96像素) |
| P5 | 1/32 | 256 | 极大目标/背景 |
- 通过上述步骤,FPN构建了一个特征金字塔(feature pyramid)。这个金字塔包含了从底层到顶层的多个尺度的特征图,每个特征图都融合了不同层次的特征信息。
- 特征金字塔的每一层都对应一个特定的尺度范围,使得模型能够同时处理不同大小的目标。
5. 设计优势
- 多尺度预测:每个金字塔层都可独立用于目标检测
- 参数共享:所有层级使用相同的检测头(Head)
- 计算高效:横向连接仅使用轻量级的1x1卷积
- 端到端训练:整个网络可联合优化
6. 典型应用场景
- 目标检测:Faster R-CNN、Mask R-CNN
- 实例分割:Mask预测分支可附加到各金字塔层
- 关键点检测:高分辨率特征层(如P2)适合精细定位
基于pytorch的实现代码(可复制直接运行,注释都打的挺详细了,仔细看即可):
'''
Feature Pyramid Networks (FPN) 特征金字塔网络实现
论文: 《Feature Pyramid Networks for Object Detection》
核心思想:通过自顶向下路径和横向连接,构建多尺度特征金字塔
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Bottleneck(nn.Module):
"""ResNet的瓶颈残差块,通道扩展比例为4"""
expansion = 4 # 输出通道扩展倍数(最终输出通道数 = planes * expansion)
def __init__(self, in_planes, planes, stride=1):
"""
参数说明:
in_planes: 输入特征图的通道数
planes: 中间层的基准通道数(实际输出通道为 planes * expansion)
stride: 第一个卷积层的步长(用于下采样)
"""
super(Bottleneck, self).__init__()
# 第一层:1x1卷积压缩通道(通道数:in_planes -> planes)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
# 第二层:3x3卷积处理特征(通道数不变,可能进行下采样)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
# 第三层:1x1卷积恢复通道数(通道数:planes -> planes*expansion)
self.conv3 = nn.Conv2d(planes, self.expansion*planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
# 捷径连接(当输入输出维度不匹配时,使用1x1卷积调整)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
# 主路径处理
out = F.relu(self.bn1(self.conv1(x))) # 压缩通道
out = F.relu(self.bn2(self.conv2(out))) # 空间特征处理(可能下采样)
out = self.bn3(self.conv3(out)) # 恢复通道数
# 残差连接(如果维度不匹配,通过shortcut调整)
out += self.shortcut(x)
out = F.relu(out)
return out
class FPN(nn.Module):
"""特征金字塔网络主结构"""
def __init__(self, block, num_blocks):
"""
参数说明:
block: 基础构建块类型(本代码中使用Bottleneck)
num_blocks: 每个stage包含的block数量(列表长度必须为4)
"""
super(FPN, self).__init__()
self.in_planes = 64 # 初始通道数(会在_make_layer中自动更新)
# ----------------- 骨干网络初始化 -----------------
# 初始卷积层(模仿ResNet的前处理)
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# 构建四个特征提取阶段(stage)
# stage1: 不进行下采样(stride=1)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
# stage2: 进行下采样(stride=2)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# ----------------- 特征金字塔网络组件 -----------------
# 顶层特征处理(将stage4的输出通道压缩到256)
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0)
# 横向连接层(Lateral Connections)
# 将各stage的输出通道统一为256
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0) # stage3输出通道是1024
self.latlayer2 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0) # stage2输出通道是512
self.latlayer3 = nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0) # stage1输出通道是256
# 特征平滑层(消除上采样带来的混叠效应)
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
def _make_layer(self, block, planes, num_blocks, stride):
"""
构建一个特征处理阶段(stage)
参数:
block: 块类型(Bottleneck)
planes: 该stage的基础通道数
num_blocks: 包含的block数量
stride: 第一个block的步长
"""
# 生成步长列表:第一个block可能下采样,后续保持分辨率
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
# 逐个添加block,并自动更新输入通道数
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion # 更新为当前block的输出通道数
return nn.Sequential(*layers) # 将多个block打包为顺序模块
def _upsample_add(self, x, y):
"""
特征图上采样并相加(特征融合核心操作)
参数:
x: 高层特征(需要上采样)
y: 低层特征(需要通道对齐)
"""
# 获取低层特征y的空间尺寸
_,_,H,W = y.size()
# 双线性插值上采样(确保尺寸匹配)
return F.interpolate(x, size=(H,W), mode='bilinear', align_corners=False) + y
def forward(self, x):
# ----------------- 自底向上路径(骨干网络) -----------------
# Stage 0: 初始卷积+池化
c1 = F.relu(self.bn1(self.conv1(x))) # [1,64,300,450] (假设输入600x900)
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1) # [1,64,150,225]
# Stage 1-4: 通过四个特征阶段
c2 = self.layer1(c1) # [1,256,150,225] (2个Bottleneck,每个输出256通道)
c3 = self.layer2(c2) # [1,512,75,113] (下采样,2个Bottleneck)
c4 = self.layer3(c3) # [1,1024,38,57] (继续下采样)
c5 = self.layer4(c4) # [1,2048,19,29] (最终高层特征)
# ----------------- 自顶向下路径(特征金字塔构建) -----------------
# 顶层特征处理
p5 = self.toplayer(c5) # [1,256,19,29] (2048->256通道)
# 特征融合(自上而下)
p4 = self._upsample_add(p5, self.latlayer1(c4)) # [1,256,38,57]
p3 = self._upsample_add(p4, self.latlayer2(c3)) # [1,256,75,113]
p2 = self._upsample_add(p3, self.latlayer3(c2)) # [1,256,150,225]
# ----------------- 特征平滑处理 -----------------
p4 = self.smooth1(p4) # 保持[1,256,38,57]
p3 = self.smooth2(p3) # 保持[1,256,75,113]
p2 = self.smooth3(p2) # 保持[1,256,150,225]
return p2, p3, p4, p5 # 返回多尺度特征(分辨率从高到低排列)
def FPN18():
"""构建FPN-18结构(类似ResNet-18的配置)"""
# 参数说明:4个stage分别包含2,2,2,2个Bottleneck块
return FPN(Bottleneck, [2,2,2,2])
def test():
"""测试函数:验证网络结构"""
net = FPN18()
# 生成随机输入(1张3通道的600x900图像)
input_tensor = Variable(torch.randn(1,3,600,900))
# 前向传播获取各层特征
feature_maps = net(input_tensor)
# 打印各层输出尺寸
for i, fm in enumerate(feature_maps):
print(f"P{i+2} shape: {fm.size()}")
test()
#if __name__ == "__main__":
# test()
"""
预期输出(当输入为600x900时):
P2 shape: torch.Size([1, 256, 150, 225]) # 最高分辨率特征
P3 shape: torch.Size([1, 256, 75, 113])
P4 shape: torch.Size([1, 256, 38, 57])
P5 shape: torch.Size([1, 256, 19, 29]) # 最低分辨率特征
"""可能有疑问的代码段详细讲解:
def _make_layer(self, block, planes, num_blocks, stride):
"""
构建一个特征处理阶段(stage)
参数:
block: 块类型(Bottleneck)
planes: 该stage的基础通道数
num_blocks: 包含的block数量
stride: 第一个block的步长
"""
# 生成步长列表:第一个block可能下采样,后续保持分辨率
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
# 逐个添加block,并自动更新输入通道数
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion # 更新为当前block的输出通道数
return nn.Sequential(*layers) # 将多个block打包为顺序模块FPN(Bottleneck, 2,2,2,2),给FPN网络传瓶颈残差块和 2,2,2,2每层块的数量
block参数这里就指代Bottleneck类,num_blocks就是这里几个块组合,stride步长第一行 :strides = [stride] + [1]*(num_blocks-1)
- 这里创建了一个列表
strides,由传入的stride参数和一个包含num_blocks-1个1的列表拼接而成。 - 例如,如果
num_blocks=3且stride=2,则strides为[2, 1, 1]。 - 这样做的目的是让第一个block使用给定的
stride(可能进行下采样),后续的block使用步长1,保持分辨率不变。
第二行 :layers = []
- 初始化一个空列表
layers,用于存放该阶段的所有block。
第三行 :for stride in strides:
- 遍历之前生成的
strides列表中的每一个stride值。
第四行 :layers.append(block(self.in_planes, planes, stride))
- 将新创建的block实例添加到
layers列表中。 block是传入的块类型,如Bottleneck。self.in_planes是当前输入的通道数,planes是该块的基础通道数,stride是当前步长。- 这一步实例化一个block,并将其添加到层列表中。
第五行 :self.in_planes = planes * block.expansion
- 更新
self.in_planes为planes乘以block的扩展系数(例如Bottleneck的expansion是4)。 - 因为每个block的输出通道数是
planes * expansion,所以下一个block的输入通道数需要更新为此值。
第六行 :return nn.Sequential(*layers)
- 将
layers列表中的block按顺序组合成一个Sequential模块。 *layers是将列表解包为多个参数,Sequential会按顺序堆叠这些block。
参考博客:
https://blog.csdn.net/a8039974/article/details/142288667?spm=1001.2014.3001.5502
https://blog.csdn.net/a8039974/article/details/142288667?spm=1001.2014.3001.5502