引言
随着在线旅游平台的快速发展,网络爬虫技术成为获取旅游数据的重要手段。然而,主流旅游网站(如去哪儿网、携程等)普遍部署了反爬虫机制,包括IP封禁、验证码验证、请求频率限制等技术手段,严重影响了传统爬虫的数据采集效率。为解决这一问题,本研究引入亮数据(Bright Data)网页解锁器 ,构建了一套服务于中小企业 高可用、高稳定性的旅游景点数据爬取系统。

系统架构
本系统采用分层架构设计,通过亮数据网页解锁器突破反爬限制
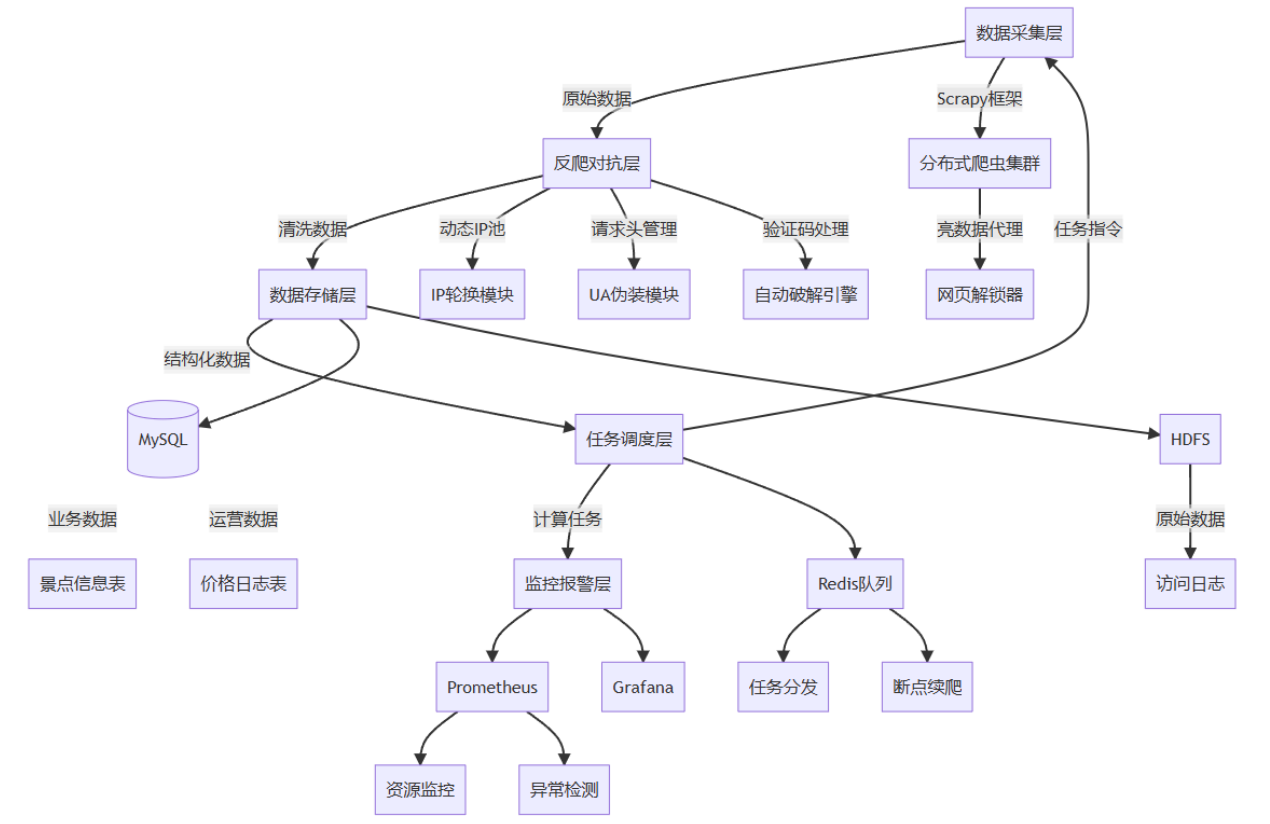
架构组成:
- 数据采集层 :基于Scrapy框架构建分布式爬虫,集成亮数据解锁器代理服务
- 反爬对抗层:通过亮数据动态IP池、请求头伪装、验证码自动破解实现反反爬
- 数据存储层:采用MySQL+HDFS混合存储,支持结构化数据与大规模日志存储
- 任务调度层:通过Scrapy-Redis实现分布式任务调度与断点续爬
- 监控报警层:基于Prometheus+Grafana监控爬虫健康状态
系统具体实现
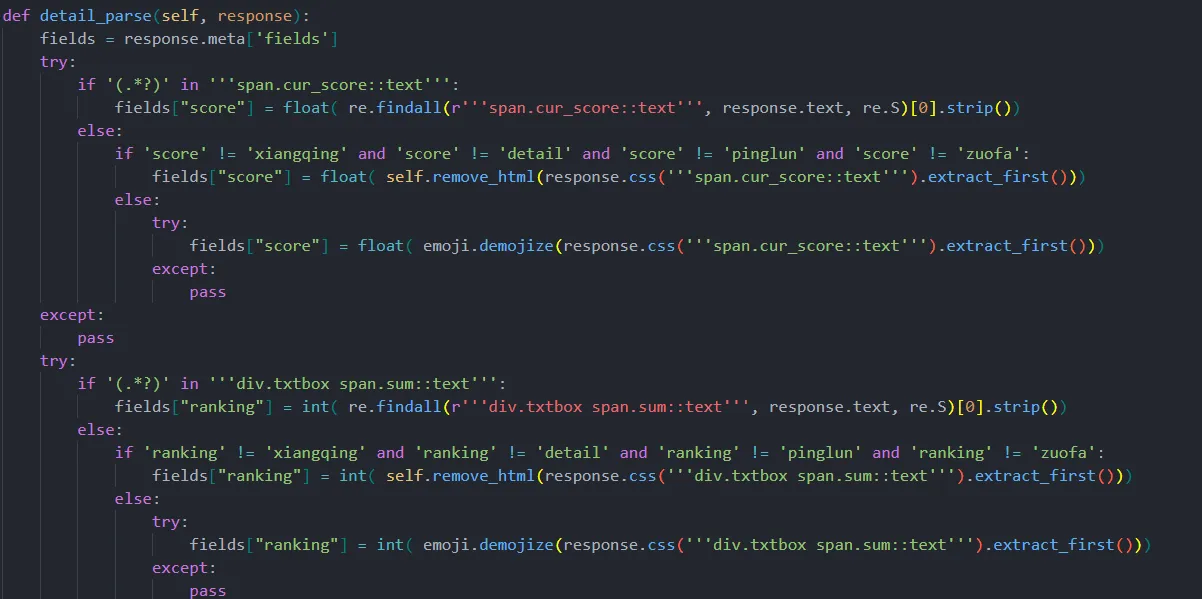
我们使用Scrapy框架来实现对国内旅游景点相关数据的爬取。首先,我们定义了一个Scrapy项目,并创建了一个爬虫(Spider)来指定要爬取的网站和提取数据的规则。然后,我们利用Scrapy提供的选择器(Selector)和管道(Pipeline)等功能,处理爬取到的数据,并将其保存到本地文件中。Scrapy框架具有高度可定制性和灵活性,用户可以根据自己的需求定义不同的爬虫规则和数据处理逻辑,适用于各种类型的网站数据爬取任务。通过Scrapy框架,我们可以快速、高效地获取国内旅游景点相关数据,为后续的数据分析和可视化工作提供了可靠的数据基础。
首先需要定义一个数据变量,设置好对应的爬取网站,以及需要的参数。这里需要设计好网站以及主机名等等。

接下来开始编写爬虫的逻辑,对我们爬取到的数据的列表进行解析,解析完成之后我们放入对应的mysql数据库中存储,
亮数据解锁器集成
- 亮数据(Bright Data)简介
亮数据是全球领先的商用 公开网络数据平台,其网络解锁器(Web Unlocker)服务专门针对反爬场景设计,具有以下核心能力:
| 核心功能 | 技术指标 | 中小企业价值 |
|---|---|---|
| 智能IP轮换 | 覆盖195个国家/地区,5000万+住宅IP | 无需自建代理池,降低运维成本 |
| 自动JS渲染 | 支持Chrome 102+引擎 | 完整获取动态加载内容 |
| 验证码自动破解 | 98.7%的验证码通过率 | 减少人工干预频率 |
| 请求头智能管理 | 内置10万+设备指纹库 | 模拟真实浏览器环境 |
| 流量成本优化 | $0.5/GB起 | 比自建代理成本降低60% |
- 注册与配置流程
步骤1:注册亮数据账号
访问亮数据官网,选择"Start Free Trial",使用企业邮箱注册(可享受中小企业专属优惠)
步骤2:创建解锁器服务
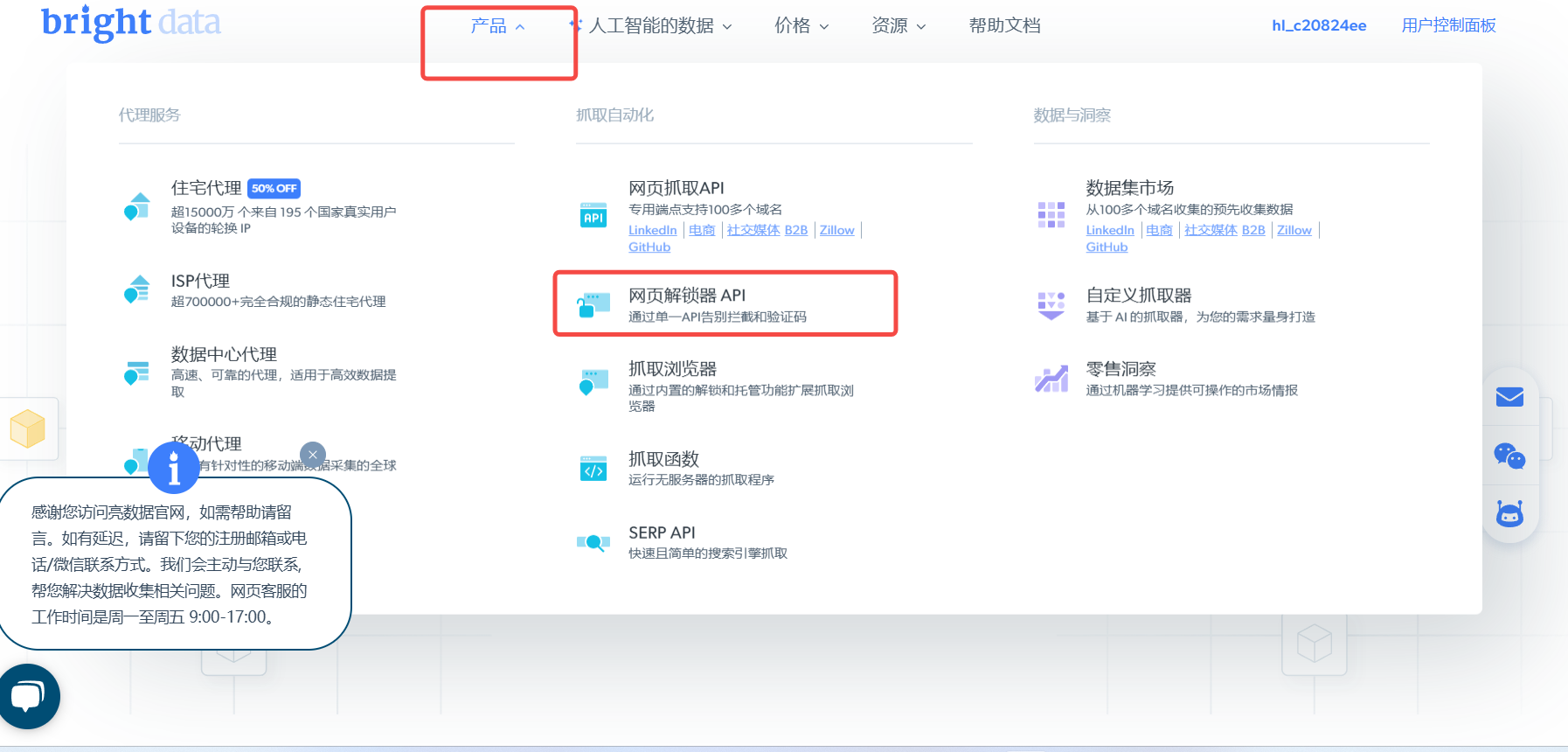
步骤3:获取连接凭证集成
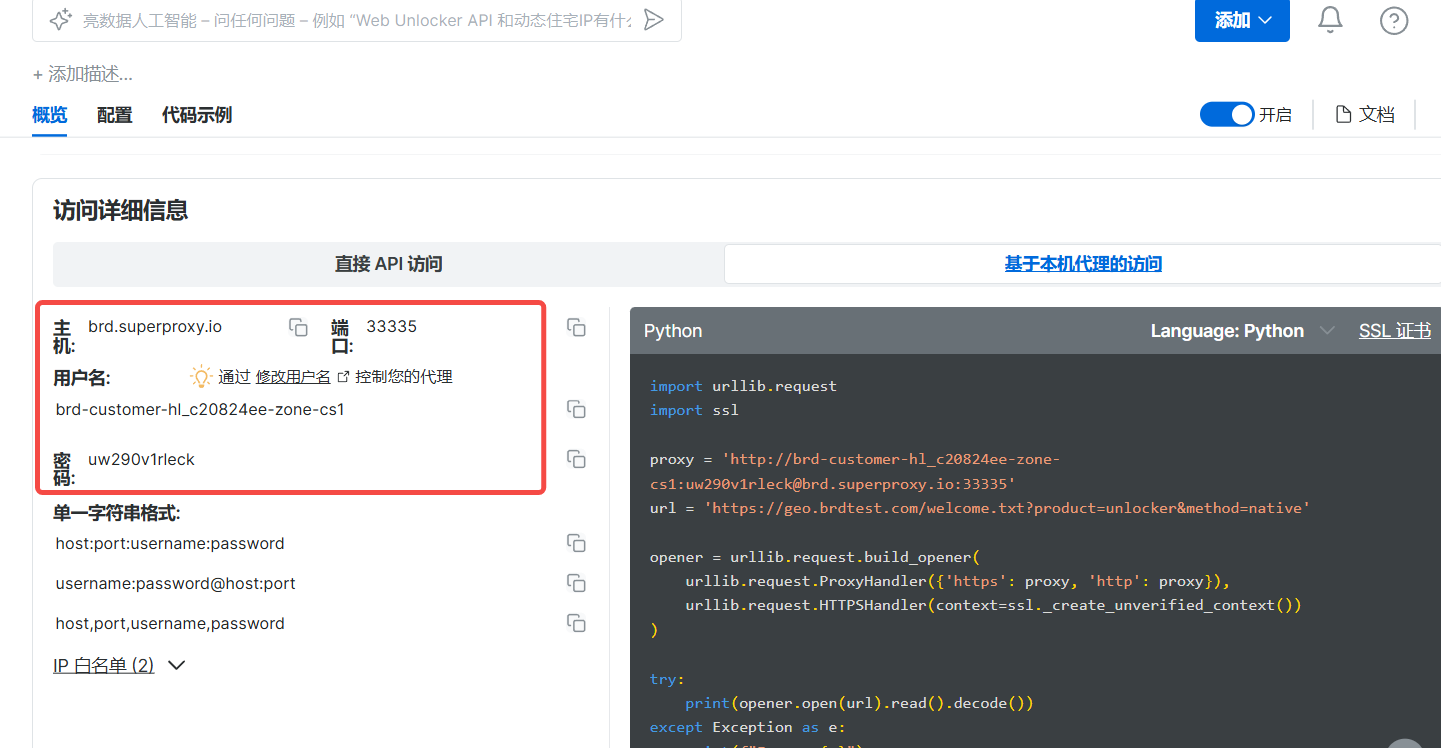
python
# settings.py
BRIGHTDATA_USER = 'your_username'
BRIGHTDATA_PASS = 'your_password'
BRIGHTDATA_PORT = 22225
DOWNLOADER_MIDDLEWARES = {
'scrapy_brightdata.BrightDataMiddleware': 723,
}
# middlewares.py
class BrightDataMiddleware:
def process_request(self, request, spider):
request.meta['proxy'] = f"http://{BRIGHTDATA_USER}:{BRIGHTDATA_PASS}@zproxy.lum-superproxy.io:{BRIGHTDATA_PORT}"
request.headers['User-Agent'] = random.choice(USER_AGENT_POOL) # 动态UA池
return None亮数据服务提供:
- 动态住宅IP:每分钟自动切换IP地址,模拟真实用户行为
- 智能JS渲染:自动执行页面JavaScript代码
自适应爬取策略设计
针对不同反爬强度动态调整爬取参数:
python
class AdaptiveScheduler:
def __init__(self):
self.request_interval = 3 # 初始请求间隔
def adjust_speed(self, response):
if response.status == 403:
self.request_interval *= 1.5 # 遭遇封禁时降低频率
logger.warning(f"触发反爬,调整间隔至{self.request_interval}s")
elif len(response.css('.captcha')) > 0:
self.solve_captcha(response) # 自动处理验证码
else:
self.request_interval = max(1, self.request_interval*0.9)数据解析与存储
采用XPath+CSS混合选择器应对页面结构变化:
python
def parse_attraction(self, response):
item = AttractionItem()
# 基础信息提取
item['title'] = response.xpath('//h1[@class="title"]/text()').get()
item['score'] = response.css('div.score::text').re_first(r'(\d\.\d)')
# 动态加载内容处理
comment_api = response.xpath('//@data-comment-api').get()
yield scrapy.Request(comment_api,
meta={'item': item},
callback=self.parse_comments)
def parse_comments(self, response):
data = json.loads(response.text)
item = response.meta['item']
item['comments'] = [c['content'] for c in data['list']]
yield item存储模块采用双写策略,同时写入MySQL与HDFS:
python
class DualWriterPipeline:
def process_item(self, item, spider):
# MySQL写入
self.mysql_conn.execute("""
INSERT INTO attractions
(title,score,comments)
VALUES (%s,%s,%s)
""", (item['title'], item['score'], json.dumps(item['comments'])))
# HDFS写入
hdfs_path = f"/tourism/{datetime.today().isoformat()}.json"
self.hdfs_client.write(hdfs_path, json.dumps(item))
return item完成对网址的访问、对网页的解析,爬取到所需的旅游景点数据,接下来,需要对该数据进行预处理操作,通过Jupyter Notebook读取CSV数据文件
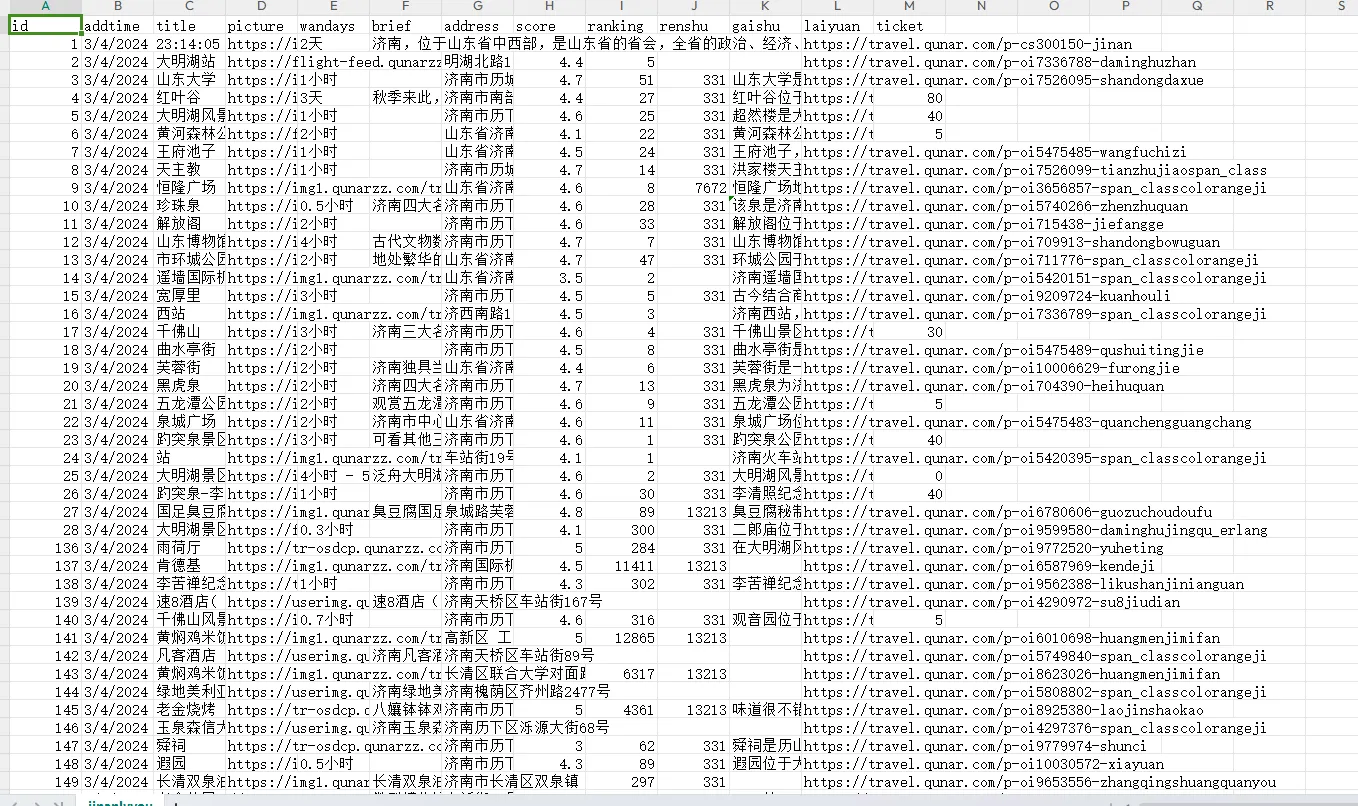
在读取数据时,有Unnamed:0列,这一列是不需要的数据,所以在预处理过程中,需删除该列
数据中若出现缺失数据,则会对整体性造成影响,先要进行缺失值统计,若有空值,可以填补或删除缺值所在的行或者列,以便提高后续模型的准确度。数据并未存在缺失值,所以无需进行缺失值处理。
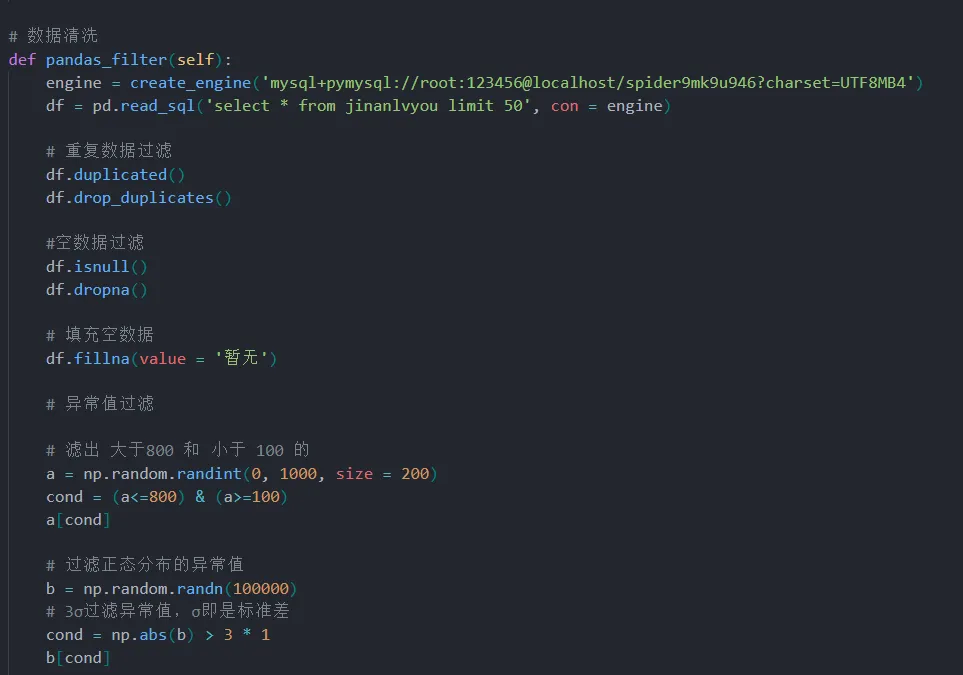
在数据计算方面,我们可以对景点数据进行统计分析,比如计算不同类型景点的数量分布情况,评估各景点的平均游玩时间和评分分布。这些计算可以帮助我们了解景点之间的竞争关系和优势劣势,为旅游者提供更全面的旅行建议。
通过可视化分析,我们可以将复杂的数据转化为直观的图表,比如柱状图、饼图、热力图等,展示景点的分布情况、评分趋势等。这些图表可以帮助我们更好地理解景点数据,发现潜在的市场趋势和规律。

python
getDataList() {
let params = {
page: 1,
limit: 10,
sort: 'score',
order: 'desc',
}
this.$http({
url: "jinanlvyou/page",
method: "get",
params: params
}).then(({ data }) => {
if (data && data.code === 0) {
this.boardDataList = data.data.list;
}
});
},可视化大屏可以将旅游景点的数据计算挖掘结果一目了然、多维度的展示。通过以上的可视化大屏应用设计,可以为日后的旅游景点数据的大数据智能分析产品提供可行的设计方案。

亮数据SERP API
通过亮数据网页解锁器 与智能化服务架构,有效突破了主流旅游网站(携程、去哪儿网等)的反爬限制。系统依托亮数据全球覆盖的动态住宅IP池,每分钟自动切换真实用户IP地址,结合设备指纹伪装与浏览器环境模拟技术,彻底规避了传统爬虫因IP封禁或请求特征异常导致的采集失败问题。不仅如此,还有搜索引擎爬虫SERP ,它立即从热门搜索引擎(Google、Bing、Yandex 等)获取数据。我们使用动态住宅IP处理抓取、解决 CAPTCHA、渲染 JS、创建自定义指纹等。
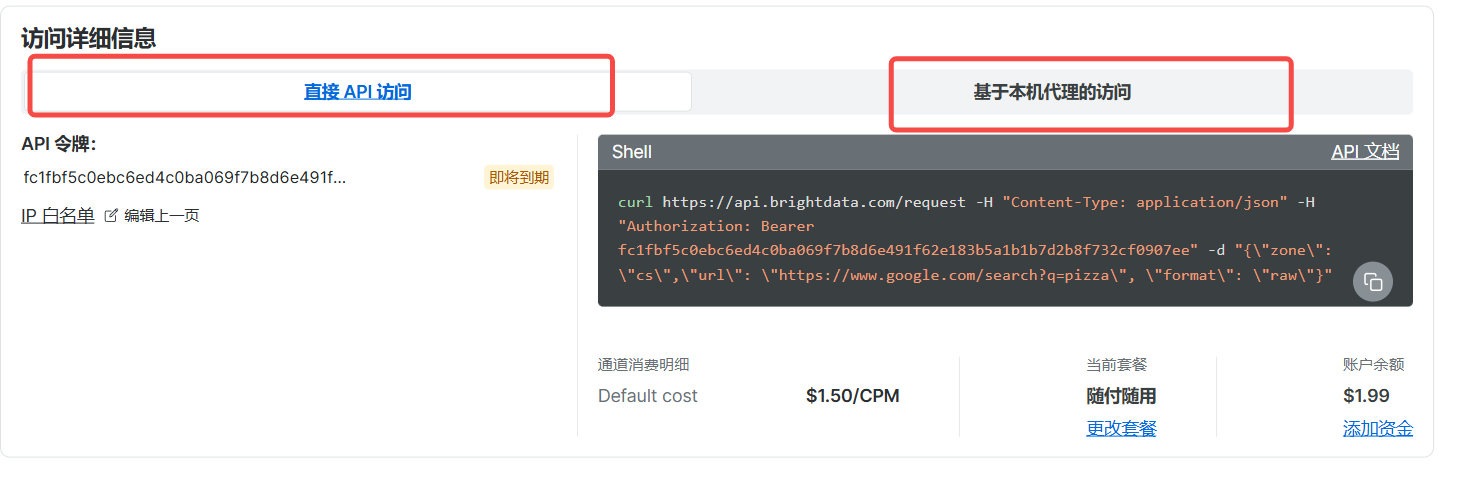
允许直接访问以及本机代理访问:
- 直接API访问
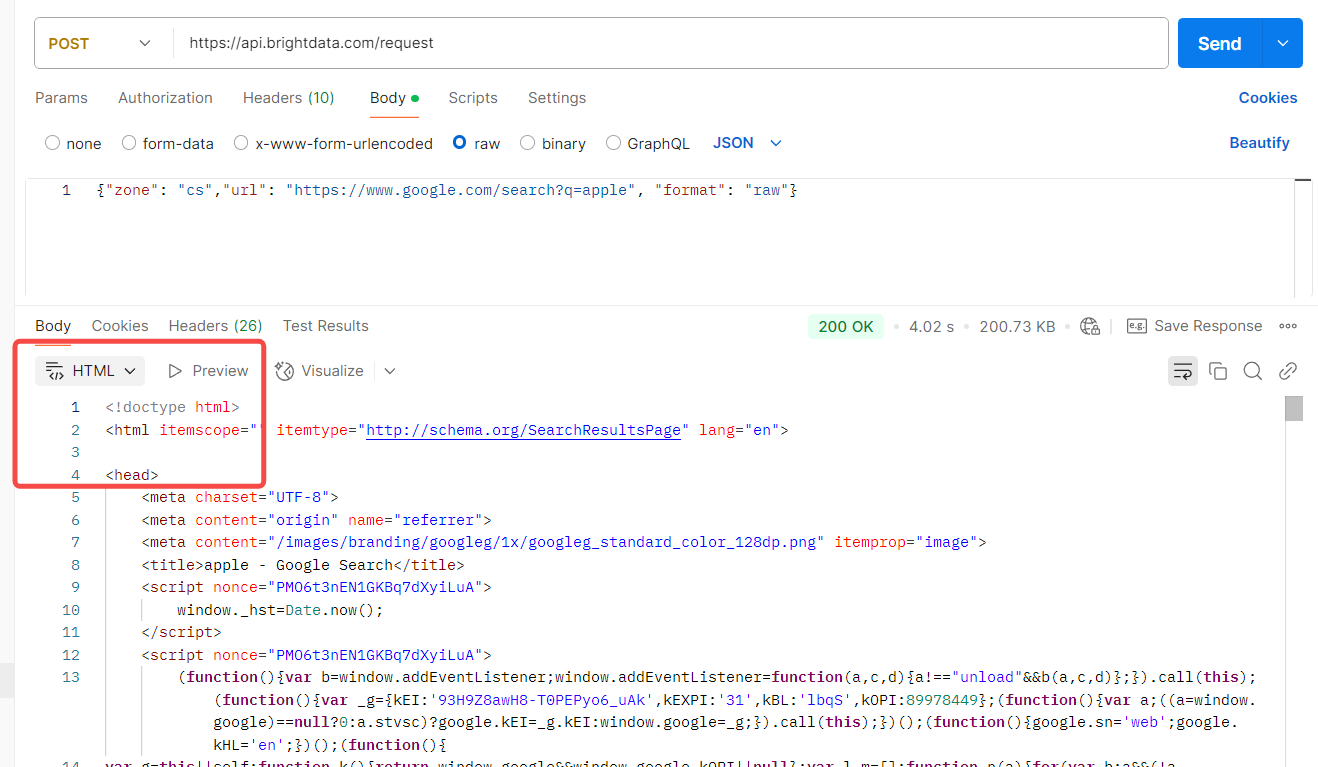
- 本机代理访问:
python
import urllib.request
import ssl
proxy = 'http://brd-customer-hl_c20824ee-zone-cs:e50klt29lqqo@brd.superproxy.io:33335'
url = 'https://www.google.com/search?q=pizza'
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy, 'http': proxy}),
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
try:
print(opener.open(url).read().decode())
except Exception as e:
print(f"Error: {e}")结语
本研究成功构建了一套基于亮数据网页解锁器的高效旅游数据采集分析系统,攻克了旅游网站反爬机制的技术难题,为中小企业 的商业 数据智能应用提供了创新解决方案。
🚀 无需攻克反爬难关,不必组建技术团队,亮数据网络解锁器与SERP API为中小企业 量身打造:
✅ 零门槛接入 :3行代码即可获取全网旅游数据,告别IP封禁与验证码困扰
✅ 成本直降60% :动态IP+智能调度,数据成本低至0.5/千条,比自建方案节省15,000+/年
✅ 合规无忧保障:GDPR认证+全程加密,规避法律风险