大纲
1.Sentinel底层的核心概念
2.Sentinel中Context的设计思想与源码实现
3.Java SPI机制的引入
4.Java SPI机制在Sentinel处理链中的应用
5.Sentinel默认处理链ProcessorSlot的构建
1.Sentinel底层的核心概念
(1)资源和规则
(2)Context
(3)ProcessorSlot
(4)Node
(1)资源和规则
一.什么是资源、规则和Entry
二.使用责任链模式 + 过滤器来收集资源的调用数据
三.如何设计Entry资源访问类
四.如何设计Entry资源访问类的子类
一.什么是资源、规则和Entry
**资源:**可以是一个方法、一个接口或一段代码。资源是被Sentinel保护和管理的对象。
**规则:**用来定义资源应遵循的约束条件。Sentinel支持多种规则类型,如流控规则、熔断降级规则等。
**Entry:**可以理解为是对资源的一次访问。
在Sentinel中,资源和规则是紧密相互关联的。Sentinel会根据配置的规则,对资源的调用进行控制,从而保证系统稳定。
二.使用责任链模式 + 过滤器来收集资源的调用数据
Sentinel要实现流控、熔断降级等功能,首先需要收集资源的调用数据。比如:QPS、请求失败次数、请求成功次数、线程数、响应时间等。
为了收集资源的这些调用数据,可以使用过滤器。将需要限制的资源配置在配置文件中,然后创建一个过滤器来拦截请求。当发现当前请求的接口已在配置文件中配置时,便需要进行数据收集。比如每次收到请求都将totalQps字段值 + 1,请求成功则再将successQps字段值 + 1。但使用一个过滤器是不够的,因为不仅有限制QPS的规则,也可能有限制异常比例的规则等。因此还需要使用责任链模式,让每一种规则都对应一个过滤器节点。这样拦截请求进行过滤时,便会形成一个过滤器处理链:开始 -> 流控过滤器 -> 黑白名单过滤器 -> 熔断降级过滤器 -> 业务 -> 结束。
三.如何设计Entry资源访问类
Entry可以理解为是对资源的一次访问。在使用责任链模式之前,需要先设计Entry资源访问类。
已知资源可以是一个方法、一个接口甚至一段代码,那么资源就肯定要有资源名称,比如方法名、接口名、其他自定义名称。因此,可以设计如下Entry资源访问类:
//资源访问类
public class Entry {
//资源名称
private final String name;
}一个资源作为API提供给第三方调用时,此时它属于入口流量。一个资源也会主动请求第三方API,此时它属于出口流量。第三方调用自己时,需要限制QPS。自己调用第三方时,第三方也有QPS限制。所以需要一个EntryType类:
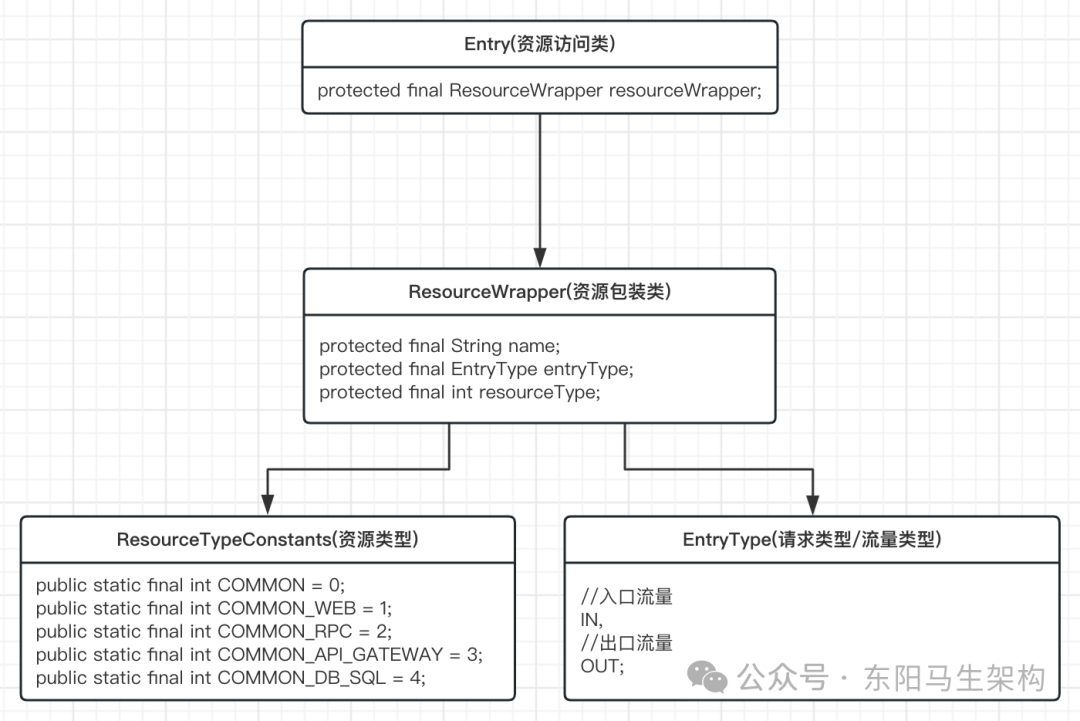
public enum EntryType {
//入口流量,资源被调用
IN,
//出口流量,资源调用其他接口
OUT;
}然后,还需要一个ResourceTypeConstants类来记录资源的类型,表明资源是HTTP接口、RPC接口、还是Gateway网关服务等。
//资源类
public final class ResourceTypeConstants {
//默认类型
public static final int COMMON = 0;
//Web类型,也就是最常见的HTTP类型
public static final int COMMON_WEB = 1;
//RPC类型,如Dubbo RPC,Grpc,Thrift等
public static final int COMMON_RPC = 2;
//API网关
public static final int COMMON_API_GATEWAY = 3;
//数据库SQL操作
public static final int COMMON_DB_SQL = 4;
}因此,一个资源起码有三个字段:名称(name)、资源类型(resourceType)以及请求类型(entryType)。将这三个字段包装成一个ResourceWrapper类,如下所示:
//资源类(资源包装类)
public class ResourceWrapper {
//资源名称
protected final String name;
//资源类型:入口流量还是出口流量
protected final EntryType entryType;
//请求类型:HTTP类型、RPC类型、API网关
protected final int resourceType;
public ResourceWrapper(String name, EntryType entryType, int resourceType) {
this.name = name;
this.entryType = entryType;
this.resourceType = resourceType;
}
}接着,将这个ResourceWrapper资源类放入到Entry资源访问类中:
public class Entry {
//封装了:名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
}
}类图如下:
同时,还需记录资源访问的开始时间和完成时间:
public class Entry {
//资源访问的开始时间
private final long createTimestamp;
//资源访问的完成时间
private long completeTimestamp;
//封装了:名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
//给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}然后,还需记录这个资源总的请求数、请求成功、请求失败等指标。可以将获取这些指标的方法放到一个interface里,然后通过interface提供的方法获取这些指标,可称这个interface为Node。
//用于统计资源的各项指标数据
public interface Node {
//总的请求数
long totalRequest();
//请求成功数
long totalSuccess();
...
}于是,Entry资源访问类变成如下:
public class Entry {
//资源访问的开始时间
private final long createTimestamp;
//资源访问的完成时间
private long completeTimestamp;
//统计资源的各项数据指标
private Node curNode;
//封装了:名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
//给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}此外,当触发预设规则的阈值时,系统将抛出警告提示。因此还要自定义一个异常类BlockException。所以,Entry资源访问类最终如下:
//Each SphU.entry() will return an Entry.
//This class holds information of current invocation:
//createTime, the create time of this entry, using for rt statistics.
//current Node, that is statistics of the resource in current context.
//origin Node, that is statistics for the specific origin.
//Usually the origin could be the Service Consumer's app name, see ContextUtil.enter(String name, String origin).
//ResourceWrapper, that is resource name.
//A invocation tree will be created if we invoke SphU.entry() multi times in the same Context,
//so parent or child entry may be held by this to form the tree.
//Since Context always holds the current entry in the invocation tree,
//every Entry.exit() call should modify Context.setCurEntry(Entry) as parent entry of this.
public abstract class Entry {
//资源访问的开始时间
private final long createTimestamp;
//资源访问的完成时间
private long completeTimestamp;
//统计资源的各项数据指标
private Node curNode;
//异常
private BlockException blockError;
//封装了:名称(name)、请求类型(entryType)以及资源类型(resourceType)三个字段
protected final ResourceWrapper resourceWrapper;
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
//给开始时间赋值为当前系统时间
this.createTimestamp = TimeUtil.currentTimeMillis();
}
}Entry资源访问类的设计总结:
每次资源被访问时都会创建一个Entry资源访问对象。Entry资源访问对象会包含:资源名称、资源类型、请求类型、操作资源的开始和结束时间、统计各项指标的接口以及自定义流控异常。
根据这些字段可以完成以下需求:统计一个资源的出口流量、成功次数、失败次数等指标。根据规则配置判断是否超出阈值,若是则抛出自定义异常BlockException。这样的Entry资源访问类,能灵活方便管理和监控资源,满足不同的需求。
为了方便子类继承,可以将Entry资源访问类设计为抽象类。
四.如何设计Entry资源访问类的子类
假设需要提供一个外部接口(sms/send)用于发送短信服务,具体的短信发送操作是通过第三方云服务提供商提供的API或SDK完成的,第三方云服务提供商需要使用方对其提供的API或SKD进行QPS限流。
当用户请求接口sms/send到达系统时,会生成一个名为sms/send的Entry。由于当接口sms/send请求第三方API时,也需要进行限流操作,因此还会生成一个名为yun/sms/api的Entry。
可以发现这两个Entry都属于同一次请求,即这两个Entry是有关联的。
Entry(name=sms/send)的子节点是Entry(name=yun/sms/api)
Entry(name=yun/sms/api)的父节点是Entry(name=sms/send)这显然是父子关系,可以使用双向链表表示,因此需要两个指针。
此外,由于这两个Entry属于同一个请求,即它们位于同一个作用范围内。因此,需要一个字段来表示作用范围。
最后,由于需要通过设置一系列的过滤器来采集Entry的各规则下的指标。所以,还需增加一个存放处理链(处理器插槽链条)类型的字段。
综上,可以设计Entry的子类CtEntry如下:
//Entry的子类
class CtEntry extends Entry {
//指向上一个节点,父节点,类型为Entry
protected Entry parent = null;
//指向下一个节点,子节点,类型为Entry
protected Entry child = null;
//作用域,上下文
protected Context context;
//处理链(处理器插槽链条)
protected ProcessorSlot<Object> chain;
}(2)Context
Context对象的用途是存储请求调用链中关联的Entry信息。在Sentinel中,每个请求都有一个与之关联的Context实例。当系统接收到一个请求时,就会创建出一个Context。请求的处理过程中可能会涉及多个资源,Context便会在多个资源中传递。
Context类的设计如下:
public class Context {
//名称
private final String name;
//处理到哪个Entry了
private Entry curEntry;
//来源,比如请求 IP
private String origin = "";
}可以发现Context比较简单,它就像一个容器一样。Context会关联此次请求的所有资源,即包含一个Entry双向链表。一个Context的生命周期内可能有多个资源操作,并非是一个接口对应一个Context,可以是多个接口对应一个Context。比如A调用B,B调用C,那么A、B、C三个资源就属于同一个Context。Context生命周期内的最后一个资源退出时就会清理并结束该Context。
Context类的设计总结:
在处理一个请求对应的一个资源时或者多个资源时,这些资源的操作必须要建立在一个Context环境下,而且每一个资源的操作必须要通过Entry对象来完成。也就是一个请求对应一个Context,一个请求可能操作多个资源。而多个资源又对应多个Entry,但这些Entry却都属于同一个Context。
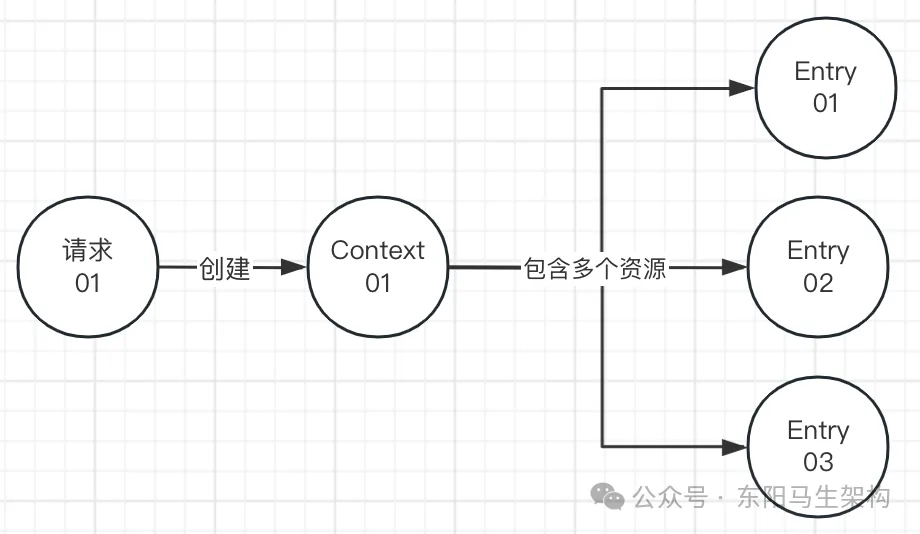
(3)ProcessorSlot
ProcessorSlot就是一个用于负责数据采集的处理链(处理器插槽链条)的节点。每当一个资源被调用时都会创建一个Entry资源访问对象。Entry资源访问对象中就有一条节点为ProcessorSlot的处理链,对应于Entry对象的chain属性。这意味着在创建Entry对象时,也会生成一系列ProcessorSlot处理槽,这些ProcessorSlot处理槽各自承担不同的职责。
一.NodeSelectorSlot
NodeSelectorSlot负责构建资源的调用路径,然后将这些资源的调用路径以树状结构存储起来,方便后续根据资源的调用路径进行数据统计和限流降级。
二.ClusterBuilderSlot
ClusterBuilderSlot负责实现集群限流功能,ClusterBuilderSlot会将请求的流量信息汇报到集群的统计节点,然后根据集群限流规则决定是否应该限制请求。
三.StatisticSlot
StatisticSlot负责记录资源的访问统计信息,比如通过的请求数、阻塞的请求数、响应时间等。StatisticSlot会将每次资源访问的信息记录在资源的统计节点中,这些统计信息是Sentinel执行流量控制(如限流、熔断降级等)的重要指标。
四.SystemSlot
SystemSlot用于实现系统保护功能,它会提供基于系统负载、系统平均响应时间和系统入口QPS的保护策略。
五.AuthoritySlot
AuthoritySlot用于实现授权规则功能,比如基于黑白名单的访问权限。
六.FlowSlot
FlowSlot用于实现流量控制功能,比如对不同来源的流量进行限制、基于调用关系对流量进行控制。
七.DegradeSlot
DegradeSlot用于实现熔断降级功能,可以支持基于异常比例、异常数和响应时间的降级策略,处理链(处理器插槽链条)之间的关系图如下:
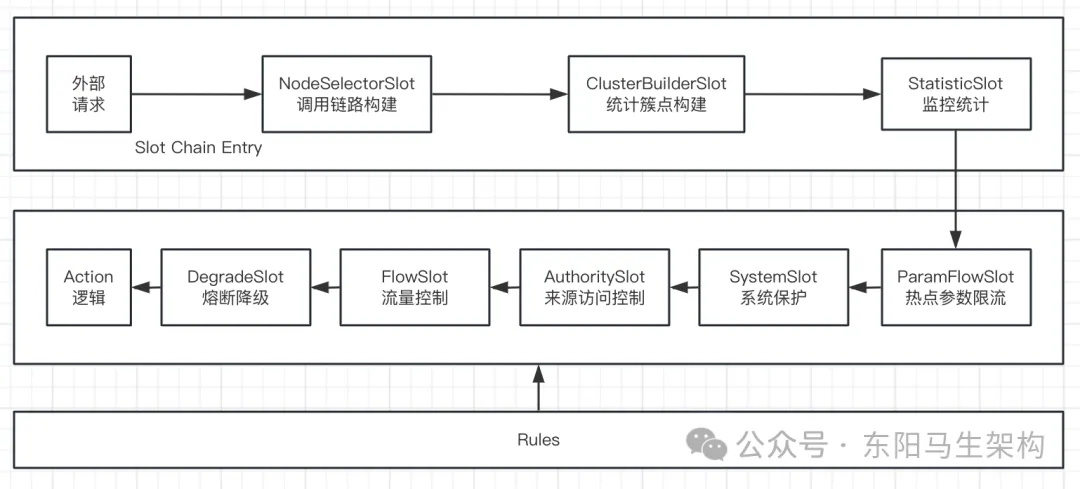
ProcessorSlot的用途总结:负责构建调用路径树、进行数据采集、实施流量控制和熔断降级等规则。
(4)Node
Node的用途很简单,就是基于处理槽采集的数据进行统计。比如统计总的请求量、请求成功量、请求失败量等指标。因此可以定义如下接口:
public interface Node {
//获取总请求量
long totalRequest();
//获取请求成功量
long successRequest();
//获取请求失败量
long failedRequest();
...
}即然Node是一个接口,那么需要提供一个具体的实现类。由于Node接口主要关注统计相关功能,因此可将实现类命名为StatisticNode,如下所示:
public class StatisticNode implements Node {
...
}通过StatisticNode类可完成Node接口定义的各种性能指标的收集和计算。但为了更多维度的计算,比如:上下文Context维度、资源维度等,还需要额外设计如下三个子类:
一.DefaultNode(单机里的资源维度)
默认节点,用于统计名字相同的Context下的某个资源的调用数据,意味着DefaultNode是以Context和ResourceWrapper为维度进行统计。
二.EntranceNode(接口维度)
继承自DefaultNode,是名字相同的Context的入口节点。用于统计名字相同的Context下的所有资源的调用数据,维度为Context。注意:默认创建的Context都是名字相同的,一个线程对应一个Context。所以EntranceNode可以理解为统计某接口被所有线程访问的调用数据。
三.ClusterNode(集群中的资源维度)
ClusterNode保存的是同一个资源的相关的统计信息,ClusterNode是以资源为维度的,不区分Context。
//Holds real-time statistics for resources.
public interface Node extends OccupySupport, DebugSupport {
...
}
public class StatisticNode implements Node {
...
}
//A Node used to hold statistics for specific resource name in the specific context.
//Each distinct resource in each distinct Context will corresponding to a DefaultNode.
//This class may have a list of sub DefaultNodes.
//Child nodes will be created when calling SphU.entry() multiple times in the same Context.
public class DefaultNode extends StatisticNode {
...
}
//A Node represents the entrance of the invocation tree.
//One Context will related to a EntranceNode, which represents the entrance of the invocation tree.
//New EntranceNode will be created if current context does't have one.
//Note that same context name will share same EntranceNode globally.
public class EntranceNode extends DefaultNode {
...
}
//This class stores summary runtime statistics of the resource, including rt, thread count, qps and so on.
//Same resource shares the same ClusterNode globally, no matter in which Context.
public class ClusterNode extends StatisticNode {
...
}
//The ClusterNode is uniquely identified by the ResourceId.
//The DefaultNode is identified by both the resource id and Context.
//In other words, one resource id will generate multiple DefaultNode for each distinct context,
//but only one ClusterNode.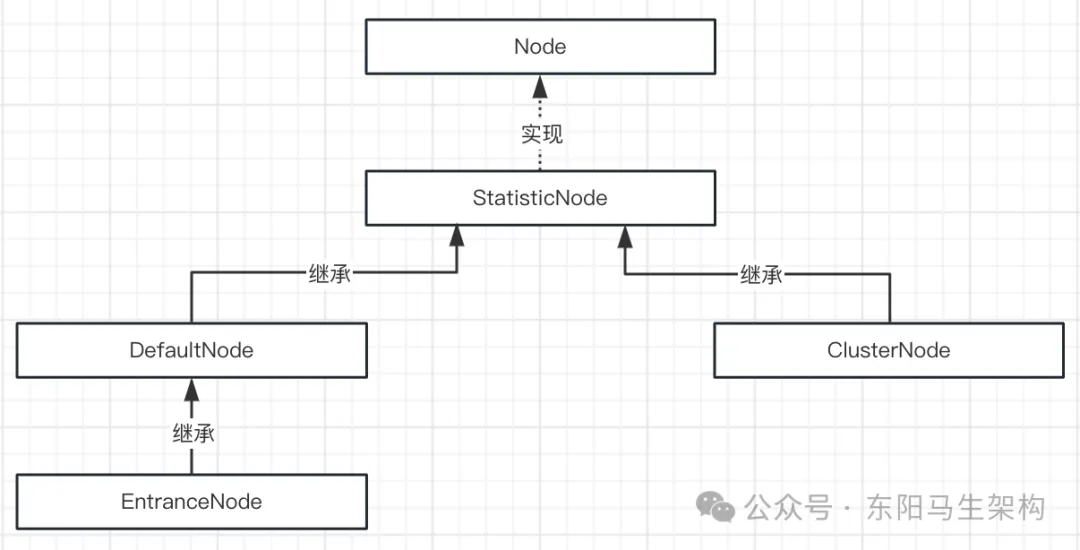
**三者的区别:**DefaultNode统计的是名字相同的Context下的某个资源的调用数据,EntranceNode统计的是名字相同的Context下的全部资源的调用数据,ClusterNode统计的是某个资源在所有Context下的调用数据。
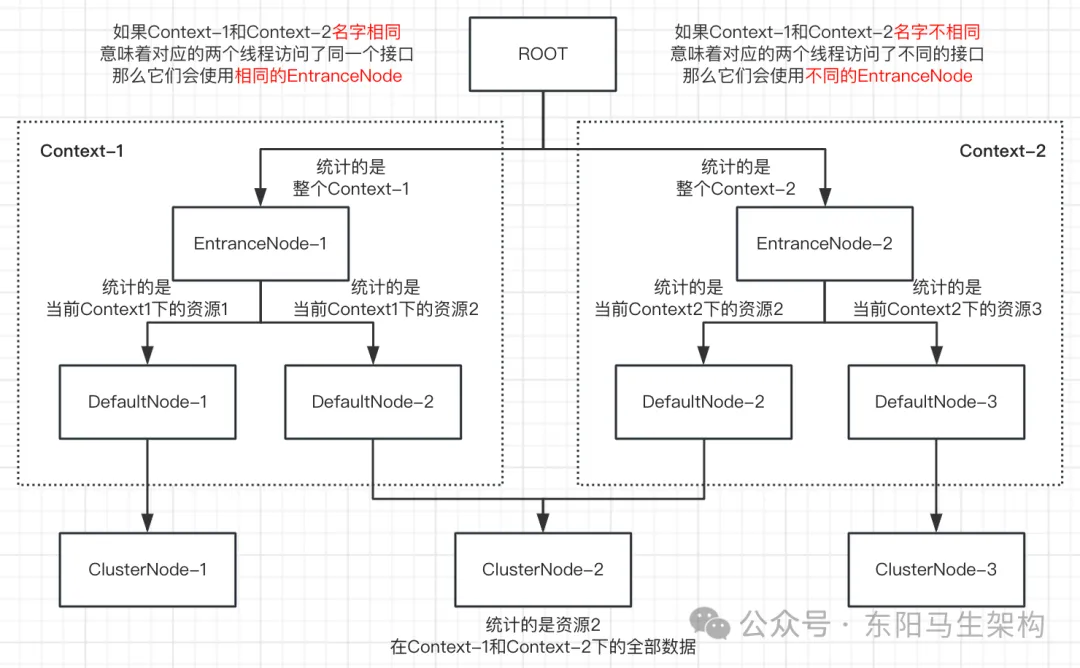
注意:资源可以是一个方法、一个接口或一段代码。一个请求会对应一个Context,一个请求可能包含多个方法,所以一个请求可能操作多个资源,一个Context可能包含多个资源。
**Node的用途总结:**统计各种维度的各种数据指标。
(5)总结
一.资源访问对象Entry
每次访问资源都会创建一个Entry资源访问对象。每个Entry对象都会包含资源的基本信息(如名称、请求类型、资源类型等)、数据采集链和获取指标信息的方法(如QPS、成功请求数、失败请求数等)。由于一次请求可能涉及多个资源,因此Entry资源访问对象采用双向链表结构。
二.管理资源对象的上下文Context
资源的操作要在一个Context环境下进行,一个Context可包含多个资源。
三.请求、Entry、Context、ProcessorSlot、Node之间的关系
每次访问资源都要创建一个Entry对象,资源操作要建立在一个Context环境下。一个请求对应一个Context,一个Context可以包含多个资源,也就是一个Context会包含一条完整请求链路中涉及的所有资源。每个资源都通过ProcessorSlot进行数据采集和规则验证,而采集完的数据交由Node去做聚合统计分析。
**总之:**每个请求都需要与Context绑定,一个Context可以关联多个资源。每个资源都通过处理链ProcessorSlot进行数据采集和规则验证。ProcessorSlot数据采集完成后,会通过Node进行统计和分析。
2.Sentinel中Context的设计思想与源码实现
(1)初始化Entry和Context的设计思想
(2)初始化Entry的源码---将处理链、Context与Entry对象绑定
(3)初始化Context的源码---如何创建Context和EntranceNode
(4)总结
(1)初始化Entry和Context的设计思想
一.Context对象的name属性一般取默认值
Context对象是有一个name属性的,所以如果没有指定Context对象的name属性,则Context对象的name默认为sentinel_default_context。
Context context = InternalContextUtil.internalEnter("sentinel_default_context");二.使用ThreadLocal绑定线程和Context对象
由于一个请求要与一个Context对象进行绑定,一个请求由一个线程处理。所以可以定义一个ThreadLocal变量,让一个线程与一个Context对象绑定。
//存放线程与Context的绑定关系
private static ThreadLocal<Context> contextHolder = new ThreadLocal<>();三.如何初始化Entry对象
由于一个请求涉及多个资源,即一个Context对象会包含多个Entry对象,所以每个Entry对象必然属于某个Context对象。因此初始化Entry对象时需要将Context对象绑定到Entry对象中,这可以在Entry的构造方法中传入一个Context对象。当然Entry的构造方法也会传入一个ResourceWrapper对象,因为Entry的基本属性(名称、请求类型、资源类型)会封装在ResourceWrapper对象中。当然,Entry对象还需要的关键属性有:ProcessorSlot和Node。
//初始化Entry的基本属性
ResourceWrapper resource = new ResourceWrapper("/hello/world", EntryType.OUT, ResourceTypeConstants.COMMON);
//初始化Context
Context context = InternalContextUtil.internalEnter("sentinel_default_context");
//放到Entry当中
CtEntry entry = new CtEntry(resourceWrapper, context);(2)初始化Entry的源码---将处理链、Context与Entry对象绑定
Sentinel创建资源访问对象的入口是:SphU.entry("/hello/world"),在执行SphU.entry()方法时会初始化一个Context对象,其中便会调用CtSph.entry()方法创建一个Entry资源访问对象。
在CtSph的entry()方法中,首先会创建一个StringResourceWrapper对象,然后调用CtSph的entryWithPriority()方法执行如下的处理逻辑:初始化Context -> 将Context与线程绑定 -> 初始化Entry -> 将Context和ResourceWrapper放入Entry中。
在CtSph的entryWithPriority()方法中,由于创建一个Entry资源访问对象时,需要传入当前线程对应的Context,所以首先会调用ContextUtil的getContext()方法从当前线程中获取Context。如果获取到的Context为空,也就是当前线程没有绑定Context,那么就调用InternalContextUtil的internalEnter()方法创建一个Context对象,也就是调用ContextUtil的trueEnter()方法创建一个Context对象,并把这个Context对象放入ThreadLocal线程变量contextHolder中。然后调用CtSph的lookProcessChain()方法初始化处理链,接着创建一个Entry资源访问对象并将处理链、Context与该Entry资源访问对象绑定,最后调用ProcessorSlot的entry()方法执行处理链节点的数据采集 + 规则验证。
//The fundamental Sentinel API for recording statistics and performing rule checking for resources.
public class SphU {
private static final Object[] OBJECTS0 = new Object[0];
...
//Record statistics and perform rule checking for the given resource.
//@param name the unique name of the protected resource
public static Entry entry(String name) throws BlockException {
//调用CtSph.entry()方法创建一个Entry资源访问对象,默认的请求类型为OUT
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}
...
}
//Sentinel Env. This class will trigger all initialization for Sentinel.
public class Env {
//创建一个CtSph对象
public static final Sph sph = new CtSph();
static {
//If init fails, the process will exit.
InitExecutor.doInit();
}
}
public class CtSph implements Sph {
...
//Record statistics and perform rule checking for the given resource.
//@param name the unique name for the protected resource
//@param type the traffic type (inbound, outbound or internal).
//This is used to mark whether it can be blocked when the system is unstable, only inbound traffic could be blocked by SystemRule
//@param count the amount of calls within the invocation (e.g. batchCount=2 means request for 2 tokens)
//@param args args for parameter flow control or customized slots
@Override
public Entry entry(String name, EntryType type, int count, Object... args) throws BlockException {
//StringResourceWrapper是ResourceWrapper的子类,且StringResourceWrapper的构造方法默认了资源类型为COMMON
StringResourceWrapper resource = new StringResourceWrapper(name, type);
return entry(resource, count, args);
}
//Do all {@link Rule}s checking about the resource.
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
//调用CtSph.entryWithPriority()方法,执行如下处理:
//初始化Context -> 将Context与线程绑定 -> 初始化Entry -> 将Context和ResourceWrapper放入Entry中
return entryWithPriority(resourceWrapper, count, false, args);
}
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args) throws BlockException {
//从当前线程中获取Context
Context context = ContextUtil.getContext();
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
//如果没获取到Context
if (context == null) {
//Using default context.
//创建一个名为sentinel_default_context的Context,并且与当前线程绑定
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
//Global switch is close, no rule checking will do.
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
//调用CtSph.lookProcessChain()方法初始化处理链(处理器插槽链条)
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
//创建出一个Entry资源访问对象,将处理链(处理器插槽链条)、Context与Entry资源访问对象绑定
//其中会将Entry的三个基础属性(封装在resourceWrapper里)以及当前Entry所属的Context作为参数传入CtEntry的构造方法
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
//处理链(处理器插槽链条)入口,负责采集数据,规则验证
//调用DefaultProcessorSlotChain.entry()方法执行处理链每个节点的逻辑(数据采集+规则验证)
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
//规则验证失败,比如:被流控、被熔断降级、触发黑白名单等
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
...
private final static class InternalContextUtil extends ContextUtil {
static Context internalEnter(String name) {
//调用ContextUtil.trueEnter()方法创建一个Context对象
return trueEnter(name, "");
}
static Context internalEnter(String name, String origin) {
return trueEnter(name, origin);
}
}
}
public class StringResourceWrapper extends ResourceWrapper {
public StringResourceWrapper(String name, EntryType e) {
//调用父类构造方法,且默认资源类型为COMMON
super(name, e, ResourceTypeConstants.COMMON);
}
...
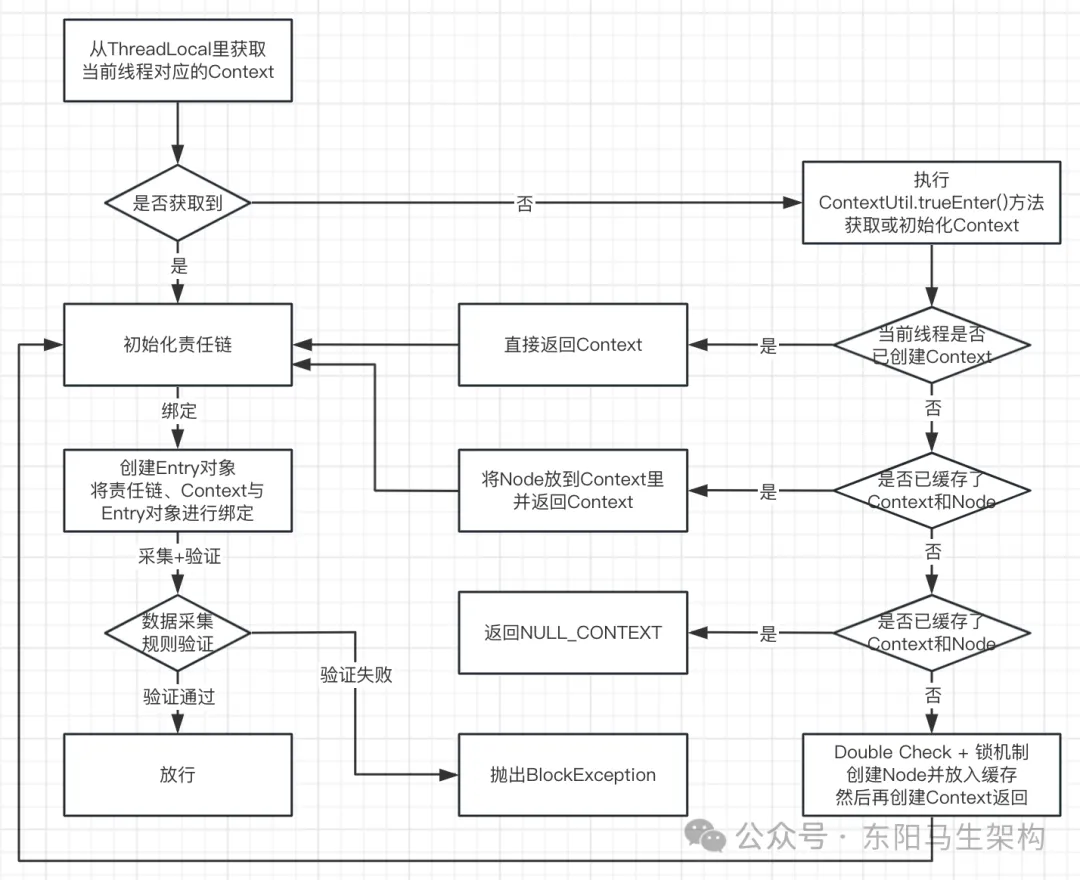
}初始化Context的核心源码总结:
1.从当前ThreadLocal里获取Context
2.获取不到Context,则创建Context并将Context放到ThreadLocal里,与当前请求线程绑定
3.初始化处理链(处理器插槽链条)
4.将处理链(处理器插槽链条)、Context与Entry资源访问对象绑定
5.执行每一个链条的逻辑(数据采集 + 规则验证)
6.验证失败抛出BlockException(3)初始化Context的源码---如何创建Context和EntranceNode
ContextUtil的trueEnter()方法会尝试从ThreadLocal获取一个Context对象。如果获取不到,那么再创建一个Context对象然后放入到ThreadLocal中。
由于当前线程可能会涉及创建多个Entry,所以该方法需要注意并发问题。但是并非在创建Context时需要注意并发,因为一个线程本就需要一个Context。而是在创建Context对象所需的EntranceNode对象时才需注意并发,因为相同名字的Context对象会共用同一个EntranceNode对象。默认情况下,创建的Context对象都是有相同名字的,这样一个EntranceNode对象就可以对当前机器的所有请求进行统计。
其中在创建EntranceNode对象时,会使用Double Check + 锁的机制,先从缓存EntranceNode对象的Map中尝试获取已存在的EntranceNode。如果获取不到EntranceNode,那么再去创建EntranceNode对象,然后使用写时复制 + 锁去更新缓存EntranceNode对象的Map。
//Utility class to get or create Context in current thread.
//Each SphU.entry() should be in a Context.
//If we don't invoke ContextUtil.enter() explicitly, DEFAULT context will be used.
public class ContextUtil {
//Store the context in ThreadLocal for easy access.
//存放线程与Context的绑定关系
//每个请求对应一个线程,每个线程绑定一个Context,所以每个请求对应一个Context
private static ThreadLocal<Context> contextHolder = new ThreadLocal<>();
//Holds all EntranceNode. Each EntranceNode is associated with a distinct context name.
//以Context的name作为key,EntranceNode作为value缓存到HashMap中
private static volatile Map<String, DefaultNode> contextNameNodeMap = new HashMap<>();
private static final ReentrantLock LOCK = new ReentrantLock();
private static final Context NULL_CONTEXT = new NullContext();
...
//ContextUtil.trueEnter()方法会尝试从ThreadLocal获取一个Context对象
//如果获取不到,再创建一个Context对象然后放入ThreadLocal中
//入参name其实一般就是默认的Constants.CONTEXT_DEFAULT_NAME=sentinel_default_context
//由于当前线程可能会涉及创建多个Entry资源访问对象,所以trueEnter()方法需要注意并发问题
protected static Context trueEnter(String name, String origin) {
//从ThreadLocal中获取当前线程绑定的Context对象
Context context = contextHolder.get();
//如果当前线程还没绑定Context对象,则初始化Context对象并且与当前线程进行绑定
if (context == null) {
//首先要获取或创建Context对象所需要的EntranceNode对象,EntranceNode会负责统计名字相同的Context下的指标数据
//将全局缓存contextNameNodeMap赋值给一个临时变量localCacheNameMap
//因为后续会对contextNameNodeMap的内容进行修改,所以这里需要将原来的contextNameNodeMap复制一份出来
//从而避免后续对contextNameNodeMap的内容进行修改时,可能造成对接下来读取contextNameNodeMap内容的影响
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
//从缓存副本localCacheNameMap中获取EntranceNode
//这个name其实一般就是默认的sentinel_default_context
DefaultNode node = localCacheNameMap.get(name);
//如果获取的EntranceNode为空
if (node == null) {
//为了防止缓存无限制地增长,导致内存占用过高,需要设置一个上限,只要超过上限,就直接返回NULL_CONTEXT
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
//如果Context还没创建,缓存里也没有当前Context名称对应的EntranceNode,并且缓存数量尚未达到2000
//那么就创建一个EntranceNode,创建EntranceNode时需要加锁,否则会有线程不安全问题
//毕竟需要修改HashMap类型的contextNameNodeMap
//通过加锁 + 缓存 + 写时复制更新缓存,避免并发情况下创建出多个EntranceNode对象
//一个线程对应一个Context对象,多个线程对应多个Context对象
//这些Context对象会使用ThreadLocal进行隔离,但它们的name默认都是sentinel_default_context
//根据下面的代码逻辑:
//多个线程(对应多个Context的name默认都是sentinel_default_context)会共用同一个EntranceNode
//于是可知,多个Context对象会共用一个EntranceNode对象
LOCK.lock();
try {
//从缓存中获取EntranceNode
node = contextNameNodeMap.get(name);
//对node进行Double Check
//如果没获取到EntranceNode
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
//创建EntranceNode,缓存到contextNameNodeMap当中
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
//Add entrance node.
//将新创建的EntranceNode添加到ROOT中,ROOT就是每个Node的根结点
Constants.ROOT.addChild(node);
//写时复制,将新创建的EntranceNode添加到缓存中
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
//解锁
LOCK.unlock();
}
}
}
//此处可能会有多个线程同时执行到此处,并发创建多个Context对象
//但这是允许的,因为一个请求对应一个Context,一个请求对应一个线程,所以一个线程本来就需要创建一个Context对象
//初始化Context,将刚获取到或刚创建的EntranceNode放到Context的entranceNode属性中
context = new Context(node, name);
context.setOrigin(origin);
//将创建出来的Context对象放入ThreadLocal变量contextHolder中,实现Context对象与当前线程的绑定
contextHolder.set(context);
}
return context;
}
...
}(4)总结
初始化Entry和Context的整体流程:
3.Java SPI机制的引入
(1)Java SPI机制的简介
(2)基于Java SPI机制开发日志框架的示例
(3)ServiceLoader的原理简介
(1)Java SPI机制的简介
SPI(Service Provider Interface)是Java提供的一种轻量级的服务发现机制,可以让开发者通过约定的方式,在程序运行时动态加载和替换接口的实现,从而提高程序的扩展性和灵活性。
比如在写框架时可以先写一个接口,然后内置几种实现类(实现不同算法)。但是业务系统接入这个框架时应该选择哪种算法、采取哪个实现类呢?这时就可以通过配置来完成。
首先将接口实现类的全限定名配置在配置文件中,然后当业务系统启动时,框架会读取配置文件并解析出配置类的全限定名,接着通过反射机制在运行时动态替换接口的默认实现类。
(2)基于Java SPI机制开发日志框架的示例
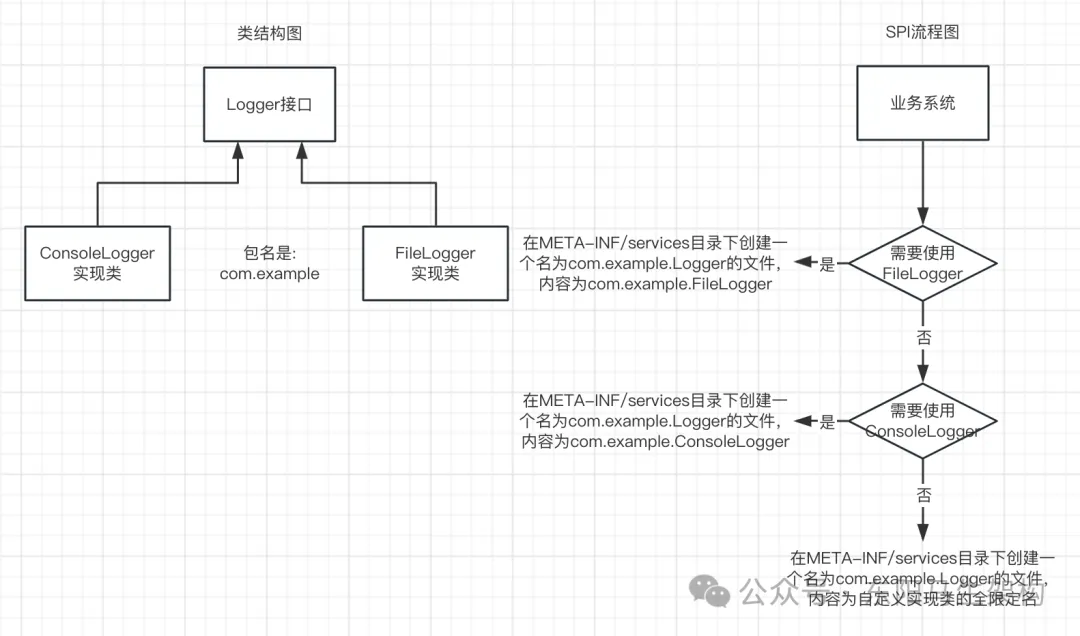
假设要开发一个日志框架,其中需要实现一个Logger接口,用于记录日志。我们希望在框架中预置两个Logger实现类:ConsoleLogger和FileLogger,同时也希望用户可以根据自己的需要扩展Logger实现类。
步骤一:定义Logger接口
public interface Logger {
void log(String message);
}步骤二:在框架中内置ConsoleLogger和FileLogger实现类
public class ConsoleLogger implements Logger {
@Override
public void log(String message) {
//直接打印到控制台
System.out.println("[ConsoleLogger] " + message);
}
}
public class FileLogger implements Logger {
@Override
public void log(String message) {
//将日志写入文件
}
}步骤三:实现SPI机制 + 扩展Logger实现类
首先,在META-INF/services目录下创建文件"com.example.Logger",文件内容为Logger实现类的全限定名。例如,如下的MyLogger就是用户自定义的Logger实现类。
com.example.MyLogger然后,在框架中读取Logger实现类的全限定名,并实例化Logger实现类,这可以通过以下代码实现。这段代码会从META-INF/services目录下读取Logger实现类的全限定名,然后通过Java反射机制实例化对应的Logger实现类,并调用其log()方法。
public static void main(String[] args){
ServiceLoader<Logger> loggerServiceLoader = ServiceLoader.load(Logger.class);
for (Logger logger : loggerServiceLoader) {
logger.log("Hello, Java SPI!");
}
}(3)ServiceLoader的原理简介
ServiceLoader是Java提供的一种基于SPI机制的服务加载器,它可以在程序运行时动态加载和实例化实现了某个接口的类。所以通过ServiceLoader机制,可以方便地扩展和替换程序中的实现类。
ServiceLoader的使用非常简单,只要首先按照规范创建接口和实现类,然后在META-INF/services目录下创建以接口全限定名命名的文件,接着在文件中写入实现类的全限定名,最后调用ServiceLoader的load()方法便可以加载并实例化实现类。
ServiceLoader的load()方法会根据传入的接口获取接口的全类名,然后将前缀/META-INF/services与接口的全类名拼接来定位到配置文件,接着读取配置文件的内容获取文件中的字符串,最后解析字符串得到实现类的全类名并添加到一个数组。
ServiceLoader实现了迭代器Iterable接口,当遍历ServiceLoader时,ServiceLoader会调用Class的forName()方法加载类并通过反射创建实例。如果没有指定类加载器,则会使用当前线程的上下文类加载器来加载类。通过这种方式,就可以方便地扩展和替换程序中的实现类。
(4)总结
Java SPI是一种轻量级的服务发现机制,可以动态加载和替换接口实现类。通过约定的方式,开发者可在程序运行时动态地加载和替换接口的实现,从而提高程序的扩展性和灵活性。
Java SPI机制通常与ServiceLoader一起使用,ServiceLoader会从META-INF/services目录下的配置文件中,读取接口实现类的全限定名,并通过Java反射机制实例化对应的类,从而实现对接口实现类的动态加载和替换。
SPI机制在开源项目中被广泛使用,例如SpringBoot、RocketMQ、Dubbo、Sentinel等。
Java SPI的使用流程图如下: