code:https://github.com/ali-vilab/VACE
核心

- 单个模型同时处理多种视频生成和视频编辑任务
- 通过VCU(视频条件单元)进行实现
方法
视频任务
所有的视频相关任务可以分为4类
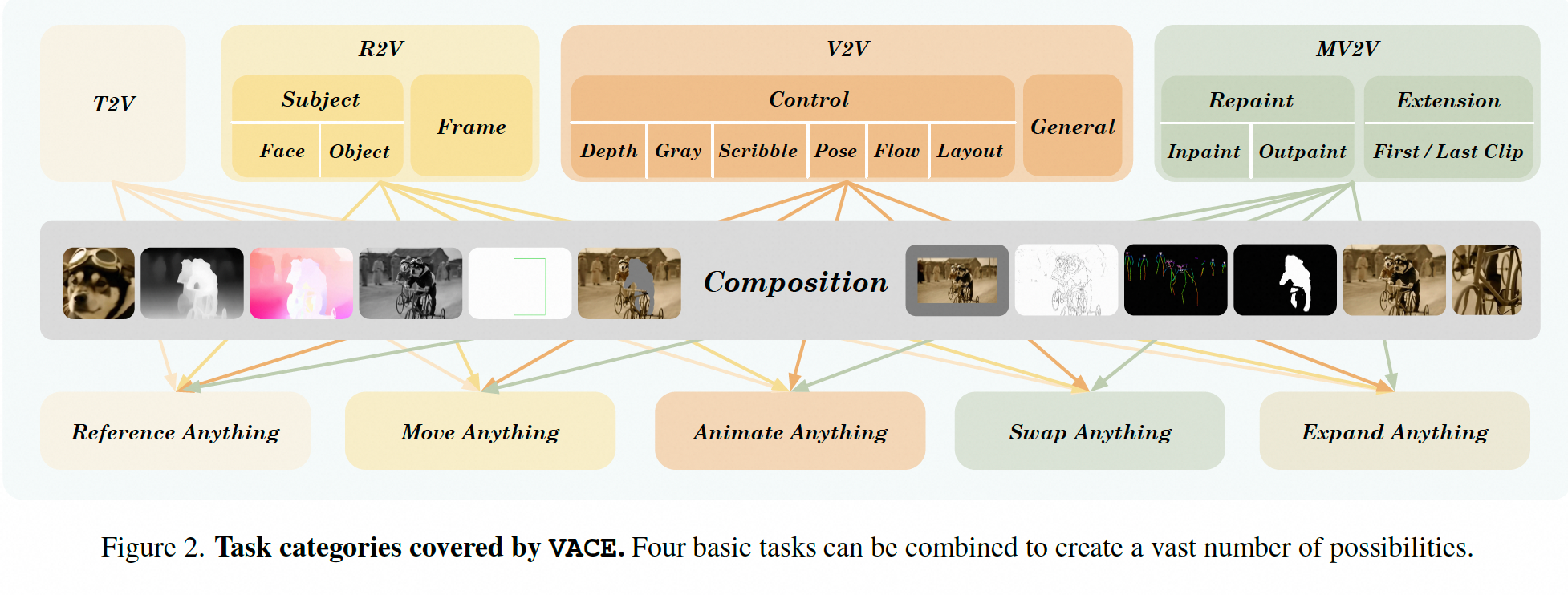
文本生视频
参考图片生视频
视频生视频
视频+mask生视频
VCU
对上述4个任务,制定一个统一的输入范式。text,frame以及mask。
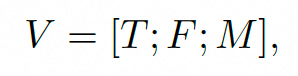
对于每一个不同的任务,text不用变,主要变化F以及M。对于参考图+视频,无非是多了l个参考图的输入。mask对应设置如下表所示。
这样就统一了不同类型任务的输入。

结构
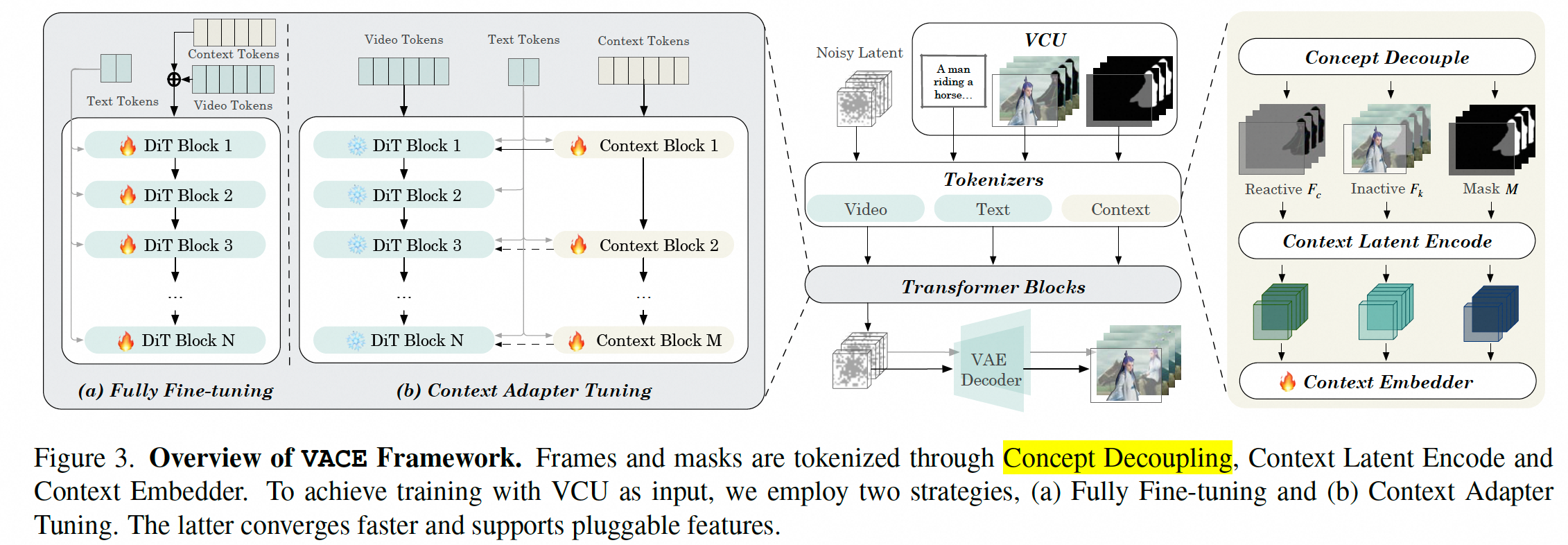
重构了DiT模型用于VACE
Context Tokenization
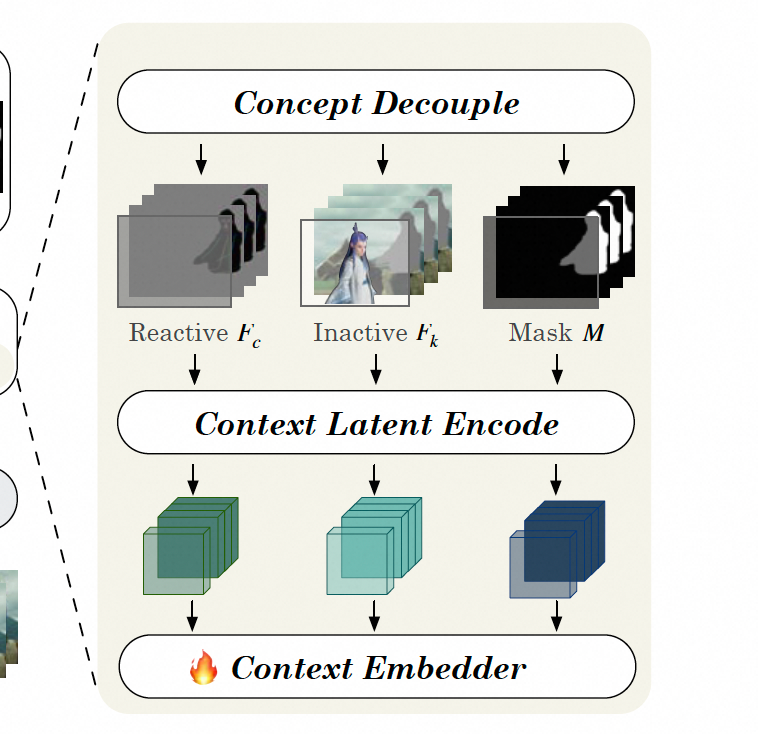
- 概念解耦。主要是将视频分为了2部分,一部分是和mask有交互的,需要重新生成;一部分和mask无交互的,需要保持不变。
- Context Latent Encoding.解藕的两部分以及原始视频、mask分别encoder到latent空间,shape保持一致
- Context Embedder 将上述3个concat一起输入到transformer中
代码如下:
python
def vace_encode_frames(self, frames, ref_images, masks=None):
if ref_images is None:
ref_images = [None] * len(frames)
else:
assert len(frames) == len(ref_images)
if masks is None:
latents = self.vae.encode(frames)
else:
inactive = [i * (1 - m) + 0 * m for i, m in zip(frames, masks)]
reactive = [i * m + 0 * (1 - m) for i, m in zip(frames, masks)]
inactive = self.vae.encode(inactive)
reactive = self.vae.encode(reactive)
latents = [torch.cat((u, c), dim=0) for u, c in zip(inactive, reactive)]
cat_latents = []
for latent, refs in zip(latents, ref_images):
if refs is not None:
if masks is None:
ref_latent = self.vae.encode(refs)
else:
ref_latent = self.vae.encode(refs)
ref_latent = [torch.cat((u, torch.zeros_like(u)), dim=0) for u in ref_latent]
assert all([x.shape[1] == 1 for x in ref_latent])
latent = torch.cat([*ref_latent, latent], dim=1)
cat_latents.append(latent)
return cat_latents3.3.2. Fully Fine-Tuning and Context Adapter Tuning
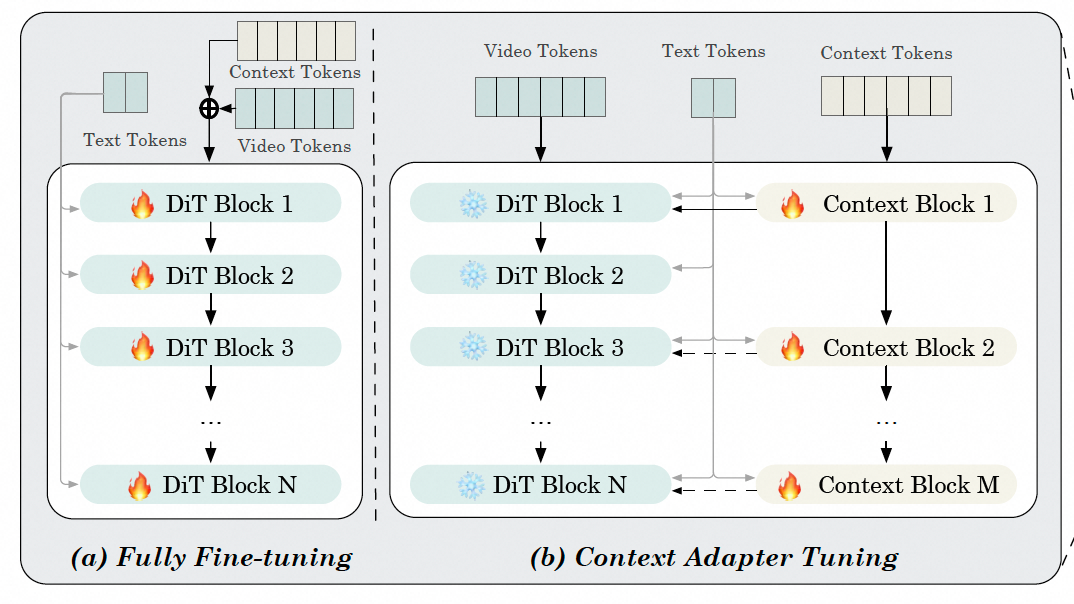 作者设计了两种训练方式。
作者设计了两种训练方式。
- 全训练。直接将video tokens和context tokens相加,然后训练整个DiT
- Context Adapter Tuning。直训练context Block和context Embed。DiT不动,cotext作为一个控制信号注入到DiT。参考了Res-tuning,也有点controlnet到结构。
后文也有提到Context Adapter Tuning的效果更好,所以关注这个就可以。
结果
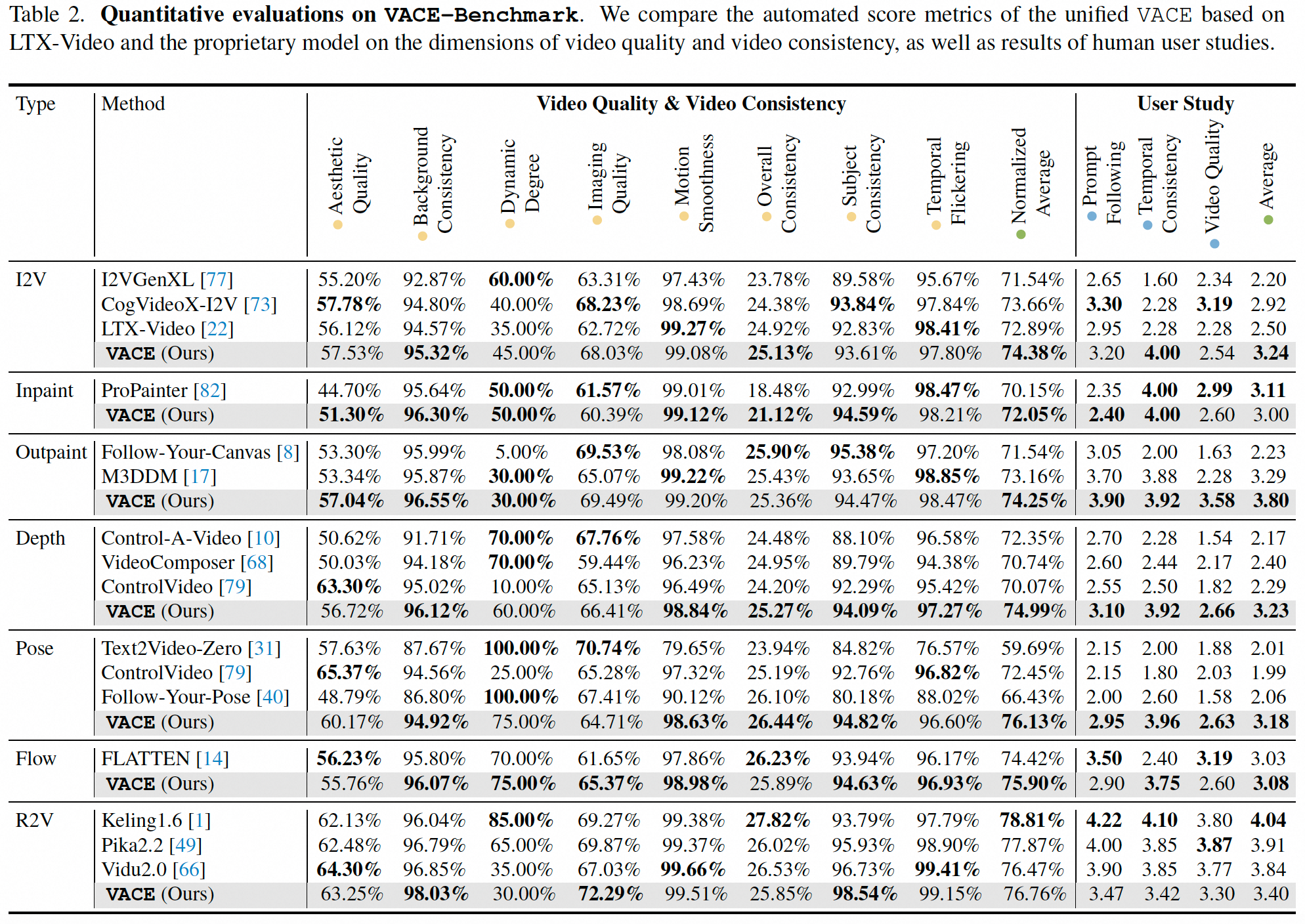
作者自己构建了一个新的数据集,用于评估多类视频任务。
定量
多个任务上的性能超过了sota,特别是在视频质量和视频一致性方面。例如,在图像到视频(I2V)任务中,VACE在多个指标上优于I2VGenXL、CogVideoX-I2V和LTX-Video-I2V等方法。
但是在R2V任务上,keling更胜一筹
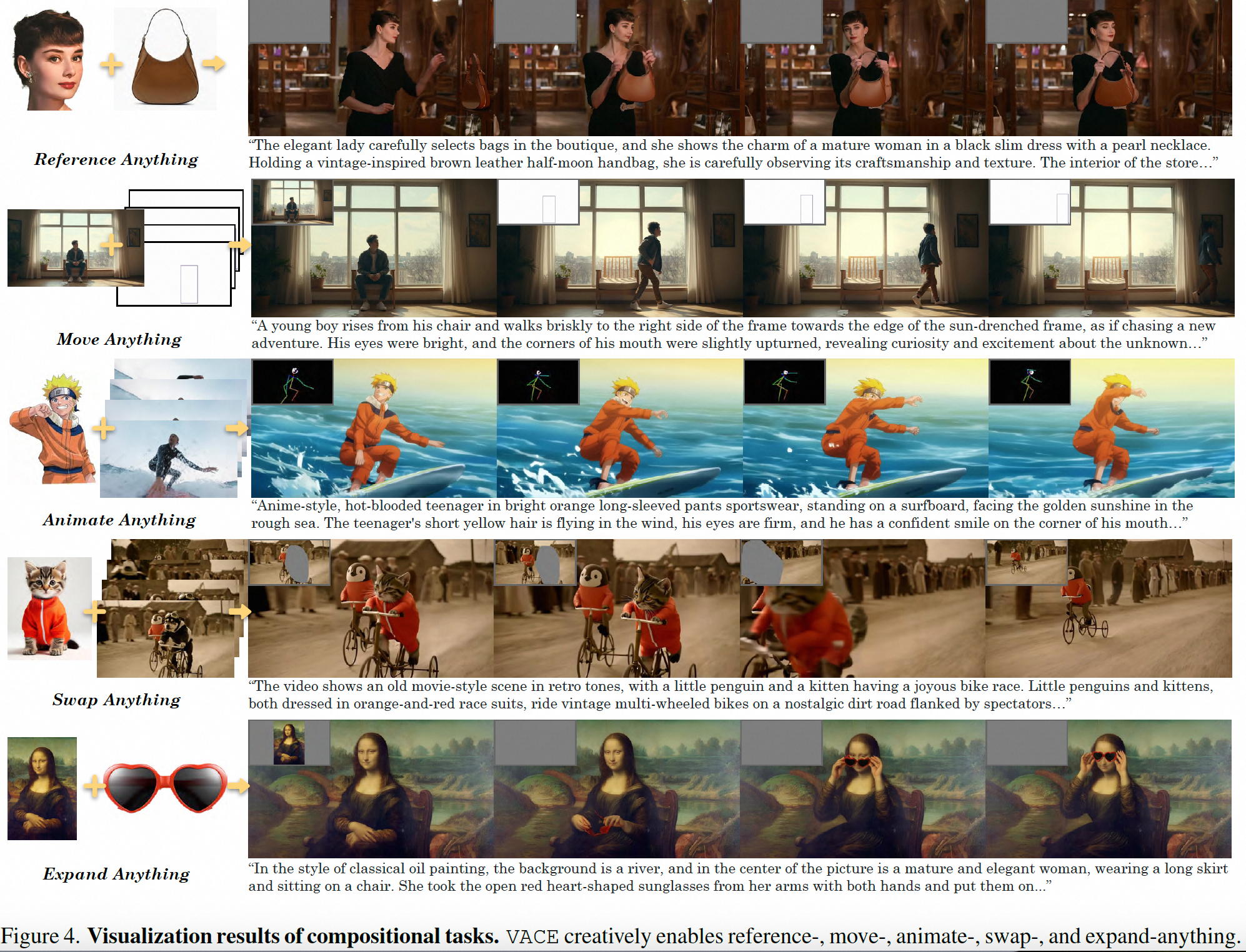
定性
消融实验
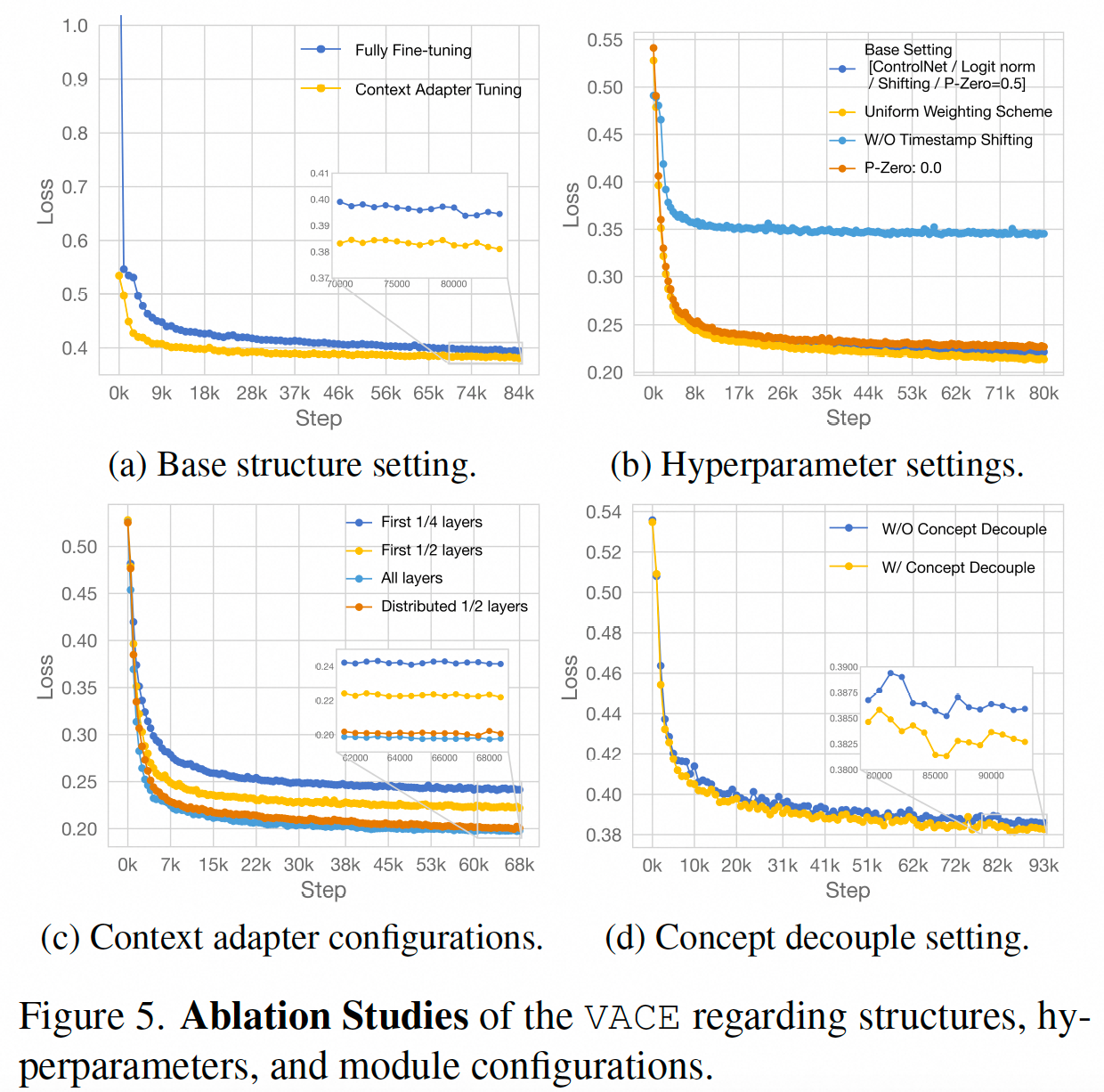
- Context Adapter Tuning的训练方式更好
- 超参数设置Uniform最好
- Context Adapter设置所有layers最好
- Concept 解耦更好一点
局限(C.1. Limitations)
- 生成的质量和风格受基础模型的影响。小模型快,但是质量和连贯性不好。例如身份一致性差,对输入的控制能力较弱。大模型慢,质量高。
- VACE的训练数据不足,训练时间不足
- 用户使用起来更复杂一些(对比单一任务模型)
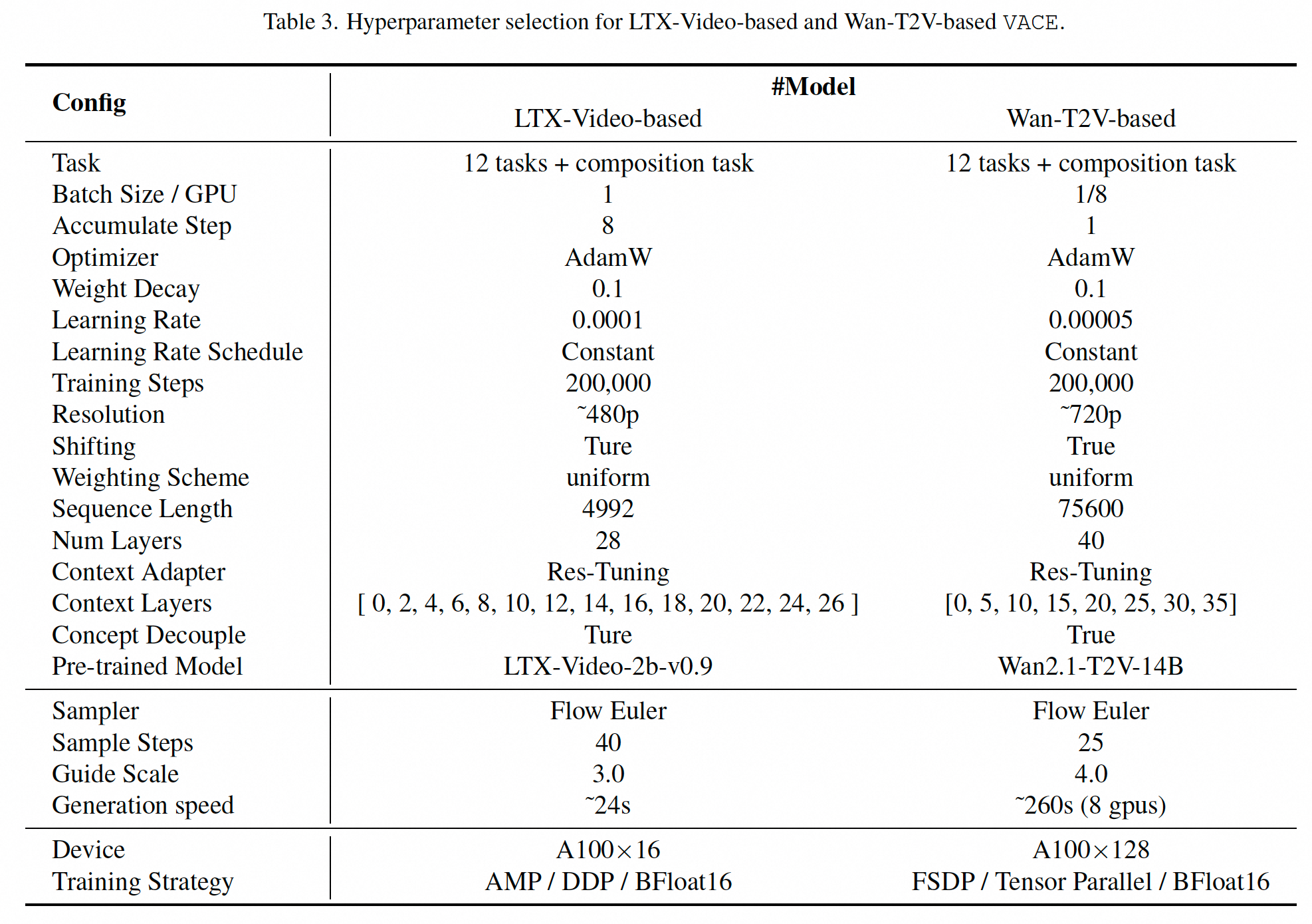
细节
基础模型
在LTX-Video-2B和WAN-T2V-14B两个模型基础上训练
训练卡数:16张A100/128张A100
训练分为3个阶段
- 基础任务训练,作为构建更复杂任务的基石。具体任务为视频修复和视频扩展
- 任务扩展训练,扩展模型的能力。包括单输入参考帧到多输入参考帧和单一任务到组合任务
- 质量提升训练,提升模型生成视频的质量,特别是在高分辨率和长视频序列上的表现。
训练参数
总结
主要是统一了多个不同的视频任务,使得单一模型拥有复杂的能力。创新点注意围绕着接口设计、训练设计。模型核心结构未变。