书接上回,我们探究了大模型思考过程和返回 function/tool call 的过程;
本节我们来看一下,如何在代码里完成对 tool 的执行,拼接工具调用结果,并且拿到最终回答的整个链路。
行文思路:
- 回顾一下大模型的调用入参,重点关注下不同 message 的 role 类型
- 模拟传入工具调用内容,先明确好格式,然后传参大模型看看能否得到回答
- 推理出自动执行的工程化思路,手写一个;到这里本节内容就可以结束了
- 最后提一下 langchain 里面的 toolNode 是怎么写的,有机会后面写一篇文章专门介绍 langchain
llm 调用入参
根据前文,我们不难看出:
- 在应用层调用 llm 其实就是发起一个 http post 请求
- 请求入参就是一串 message 列表,格式长这个样子:
js
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "xxx" },
{ "role": "assistant", "content": "xxx" },
{ "role": "user", "content": "xxx" },
{ "role": "assistant", "content": "xxx" },
// ...
]这里面我们看到了三个 role:
- system:AI系统角色定义,权重占比最高
- user:用户角色
- assistant:AI 回答
llm 本质上是根据历史对话(输出),预测下一次回答(输出)。
我们来看一个最简单的调用示例:
js
/**
* 这个示例演示了如何调用 llm
*/
import OpenAI from "openai";
import 'dotenv/config';
// 这里要配置一下 .env 文件
const openai = new OpenAI({
apiKey: process.env.API_KEY,
baseURL: process.env.BASE_URL
});
async function main() {
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "hi, bro" },
{ "role": "assistant", "content": "hi, nice to meet you, bro" },
{ "role": "user", "content": "my name is stanny" },
{ "role": "assistant", "content": "stanny, you're a handsome boy!" },
// 我们让它叫邓超,看它如何应对
{ "role": "user", "content": "you're so kind, from now on, you called '邓超'" },
]
try {
// 这里本质上就是发起一个post请求,使用 api 更方便,他帮我们处理了一些优化,比如重试、错误处理等
const response = await openai.chat.completions.create({
model: "qwen-turbo",
messages,
});
console.log(response.choices[0].message.content);
} catch (error) {
console.error("发生错误:", error);
}
}
main();运行一下看下 llm 的回答:


message 列表里还允许有哪些 role?
我尝试故意传错一个角色,比如我们把参数改成
js
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "hi, bro" },
{ "role": "assistant", "content": "hi, nice to meet you, bro" },
{ "role": "user", "content": "my name is stanny" },
{ "role": "assistant", "content": "stanny, you're a handsome boy!" },
// 这里我故意改了一下 role
{ "role": "stanny", "content": "you're so kind, from now on, you called '邓超'" },
]这就报错了,而且我们得到一个有用的信息,合法的 role 应该只有如下几个
- system
- assistant
- user
- tool
- function

模拟一个 function call
经过测试,以下两种messages,传给大模型之后,都可以让大模型回答出预期答案
第一种,不透出 tool_calls 具体信息
js
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "今天是几号" },
{ "role": "assistant", "content": '让我帮你查询'},
{
"role": "function",
"name": "get_current_time",
// 工具调用结果时
"content": JSON.stringify({
"date": "2025-04-21",
"time": "14:00:00",
"weekday": "星期一",
"timezone": "Asia/Beijing"
})
},
];第二种,透出 tool_calls 具体信息(更规范一些)
js
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "今天是几号" },
{
"role": "assistant",
"content": null, // 如果有工具定义详情,已经表明了下一步要调用工具,这里直接传 null 也行
"tool_calls": [{
"id": "call_abc123", // 需要提供唯一的调用ID
"type": "function",
"function": {
"name": "get_current_time",
"arguments": '{}' // function 定义中不需要入参直接传空就好
}
}]
},
{
"role": "tool",
"name": "get_current_time",
// 工具调用结果时
"content": JSON.stringify({
"date": "2025-04-21",
"time": "14:00:00",
"weekday": "星期一",
"timezone": "Asia/Beijing"
})
},
];注意如果透出 tool_calls 信息,下一条回答的 role 就必须是 tool,反之,如果传了tool,那么前一条消息就必须携带 tool_calls 详情。
我尝试将第一种场景里的最后一条消息改成 tool,会得到一个报错。

接下来,我们继续探索。
上一节中我们展示了一个案例,如果调用 llm 时,绑定了 tools,它就会自己决策出要调用工具并且中断当前回答;
js
请输入您的问题:今天是几号
====================思考过程====================
好的,用户问"今天是几号",我需要知道当前的日期。
提供的工具里有get_current_time函数,这个函数可以获取当前时间。
用户没有提到城市或天气,所以不需要用到get_current_weather。
接下来我应该调用get_current_time函数来获取当前日期信息。
这个函数不需要参数,直接调用即可。
确认一下函数描述是否正确,是的,确实用于获取时间。
所以正确的工具调用应该是使用get_current_time,参数为空对象。
然后返回的结果应该包含当前日期,用户的问题就能解决了
{
choices: [
{
delta: {
content: null,
reasoning_content: null,
tool_calls: [
{
function: { name: 'get_current_time', arguments: '{}' },
index: 0,
id: 'call_c5ecd978c0f34343a8c20a',
type: 'function'
}
]
},
finish_reason: null,
index: 0,
logprobs: null
}
],
// ...
}我们来构造一个 message 列表,然后让 llm 来预测一下回答:
js
import OpenAI from "openai";
import 'dotenv/config';
const openai = new OpenAI({
apiKey: process.env.API_KEY,
baseURL: process.env.BASE_URL
});
async function main() {
const messages = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "今天是几号" },
{
"role": "assistant",
"content": null, // 如果有工具定义详情,已经表明了下一步要调用工具,这里直接传 null 也行
"tool_calls": [{
"id": "call_abc123", // 需要提供唯一的调用ID
"type": "function",
"function": {
"name": "get_current_time",
"arguments": '{}' // function 定义中不需要入参直接传空就好
}
}]
},
{
"role": "tool",
"name": "get_current_time",
// 工具调用结果时
"content": JSON.stringify({
"date": "2025-04-21",
"time": "14:00:00",
"weekday": "星期一",
"timezone": "Asia/Beijing"
})
},
];
try {
const response = await openai.chat.completions.create({
model: "qwen-turbo",
messages,
});
console.log(response.choices[0].message.content);
} catch (error) {
console.error("发生错误:", error);
}
}
main();跑一下看看:

这验证了我们之前的想法:llm 本质上是根据历史对话(输出),预测下一次回答(输出)。
不过要关注的是,这个例子中我们加了 function call 的调用结果模拟传入;
写一个 demo 让流程串起来
还记得上一节里我们打印了流式返回的结果吗?
让我们来先回顾一下代码:
js
import OpenAI from "openai";
import readline from 'node:readline/promises';
import { stdin as input, stdout as output } from 'node:process';
import 'dotenv/config';
const openai = new OpenAI({
apiKey: process.env.API_KEY,
baseURL: process.env.BASE_URL
});
const tools = [
{
type: "function",
function: {
name: "get_current_time",
description: "当你想知道现在的时间时非常有用。",
parameters: {}
}
},
{
type: "function",
function: {
name: "get_current_weather",
description: "当你想查询指定城市的天气时非常有用。",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "城市或县区,比如北京市、杭州市、余杭区等。"
}
},
required: ["location"]
}
}
}
];
async function main() {
const rl = readline.createInterface({ input, output });
const question = await rl.question("请输入您的问题:");
rl.close();
const messages = [{ role: "user", content: question }];
let reasoningContent = "";
let answerContent = "";
let isAnswering = false;
console.log('\n', "=".repeat(20) + "思考过程" + "=".repeat(20));
try {
const stream = await openai.chat.completions.create({
model: "qwq-plus",
messages,
tools,
stream: true,
});
for await (const chunk of stream) {
// delta 片段
const delta = chunk.choices[0]?.delta;
if (!delta) continue;
if (delta.reasoning_content != null) {
// 打印思考过程
reasoningContent += delta.reasoning_content;
process.stdout.write(delta.reasoning_content);
} else if (delta.content != null) {
// 打印回答结果
if (!isAnswering) {
console.log("\n" + "=".repeat(20) + "回复内容" + "=".repeat(20));
isAnswering = true;
}
if (delta.content) {
answerContent += delta.content;
process.stdout.write(delta.content);
}
} else {
console.dir(chunk, { depth: null, colors: true });
}
}
} catch (error) {
console.error("发生错误:", error);
}
}
main(); 运行一下看看结果:
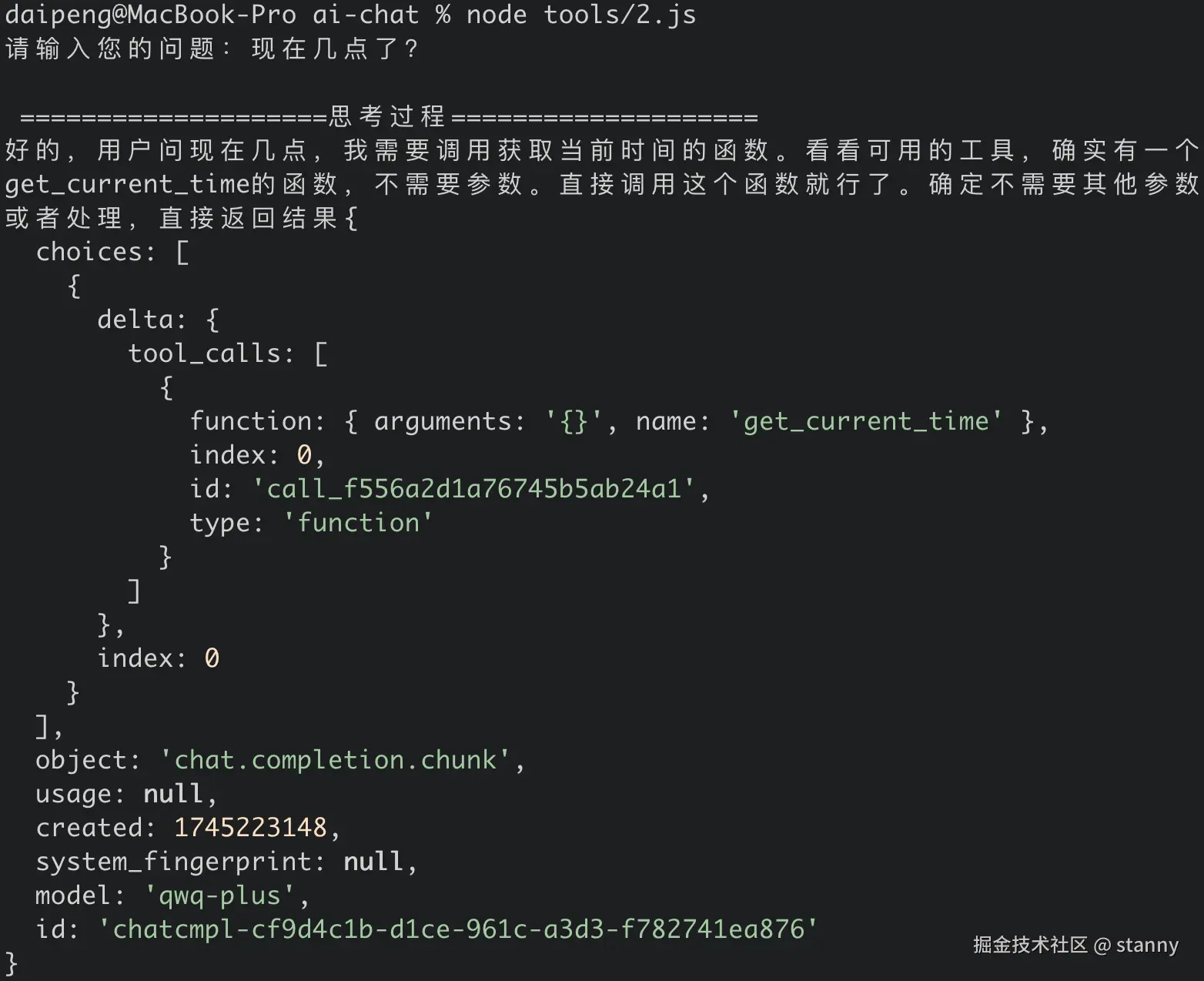
我们提问"现在几点了"
llm 的回答了思考过程,并且返回了 tool_calls 的信息;
接下来我们要做的就是:
- 手动调用 function
- 向历史对话消息里 push 两条信息:
-
- AI 调用工具的信息
- 工具的调用结果
- 对话消息传给 llm,再调用一次拿到最终结果。
我们来尝试实现一下:
js
import OpenAI from "openai";
import readline from 'node:readline/promises';
import { stdin as input, stdout as output } from 'node:process';
import 'dotenv/config';
const openai = new OpenAI({
apiKey: process.env.API_KEY,
baseURL: process.env.BASE_URL
});
// 定义工具函数
async function getCurrentWeather(args) {
const location = args.location;
// 这里可以调用天气API获取天气信息
// 这里只是一个示例,返回固定的天气信息
return {
"location": location,
"temperature": 25,
"weather": "晴",
"humidity": 40
}
}
async function getCurrentTime() {
const now = new Date();
// 获取日期
const date = now.toISOString().split('T')[0];
// 获取时间
const time = now.toLocaleTimeString('zh-CN', {
hour12: false,
timeZone: 'Asia/Shanghai'
});
// 获取星期
const weekdays = ['星期日', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六'];
const weekday = weekdays[now.getDay()];
return {
date,
time,
weekday,
timezone: 'Asia/Shanghai'
};
}
const tools = [
{
type: "function",
function: {
name: "get_current_time",
description: "当你想知道现在的时间时非常有用。",
parameters: {}
}
},
{
type: "function",
function: {
name: "get_current_weather",
description: "当你想查询指定城市的天气时非常有用。",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "城市或县区,比如北京市、杭州市、余杭区等。"
}
},
required: ["location"]
}
}
}
];
async function main() {
const rl = readline.createInterface({ input, output });
const question = await rl.question("请输入您的问题:");
rl.close();
const messages = [{ role: "user", content: question }];
callModel(messages);
async function callModel(messages) {
let reasoningContent = "";
let answerContent = "";
let isAnswering = false;
let toolCalls = [];
console.log('\n', "=".repeat(20) + "思考过程" + "=".repeat(20));
try {
const stream = await openai.chat.completions.create({
model: "qwq-plus",
messages,
tools,
stream: true,
});
for await (const chunk of stream) {
// delta 片段
const delta = chunk.choices[0]?.delta;
if (!delta) continue;
if (delta.reasoning_content != null) {
// 打印思考过程
reasoningContent += delta.reasoning_content;
process.stdout.write(delta.reasoning_content);
} else if (delta.content != null) {
// 打印回答结果
if (!isAnswering) {
console.log("\n" + "=".repeat(20) + "回复内容" + "=".repeat(20));
isAnswering = true;
}
if (delta.content) {
answerContent += delta.content;
process.stdout.write(delta.content);
}
} else if (delta.tool_calls?.length) {
// 调用工具
const toolCall = delta.tool_calls[0];
const functionName = toolCall.function.name;
if (!functionName) continue;
const functionArgs = JSON.parse(toolCall.function.arguments);
toolCalls.push(toolCall);
console.log("\n" + "=".repeat(20) + "工具调用:" + functionName + "=".repeat(20));
// 调用函数
let functionResponse;
if (functionName === "get_current_weather") {
functionResponse = await getCurrentWeather(functionArgs);
} else if (functionName === "get_current_time") {
functionResponse = await getCurrentTime();
} else {
console.error("未知的函数名称:", functionName);
continue;
}
if (!functionResponse) {
console.error("函数调用失败:", functionName);
continue;
}
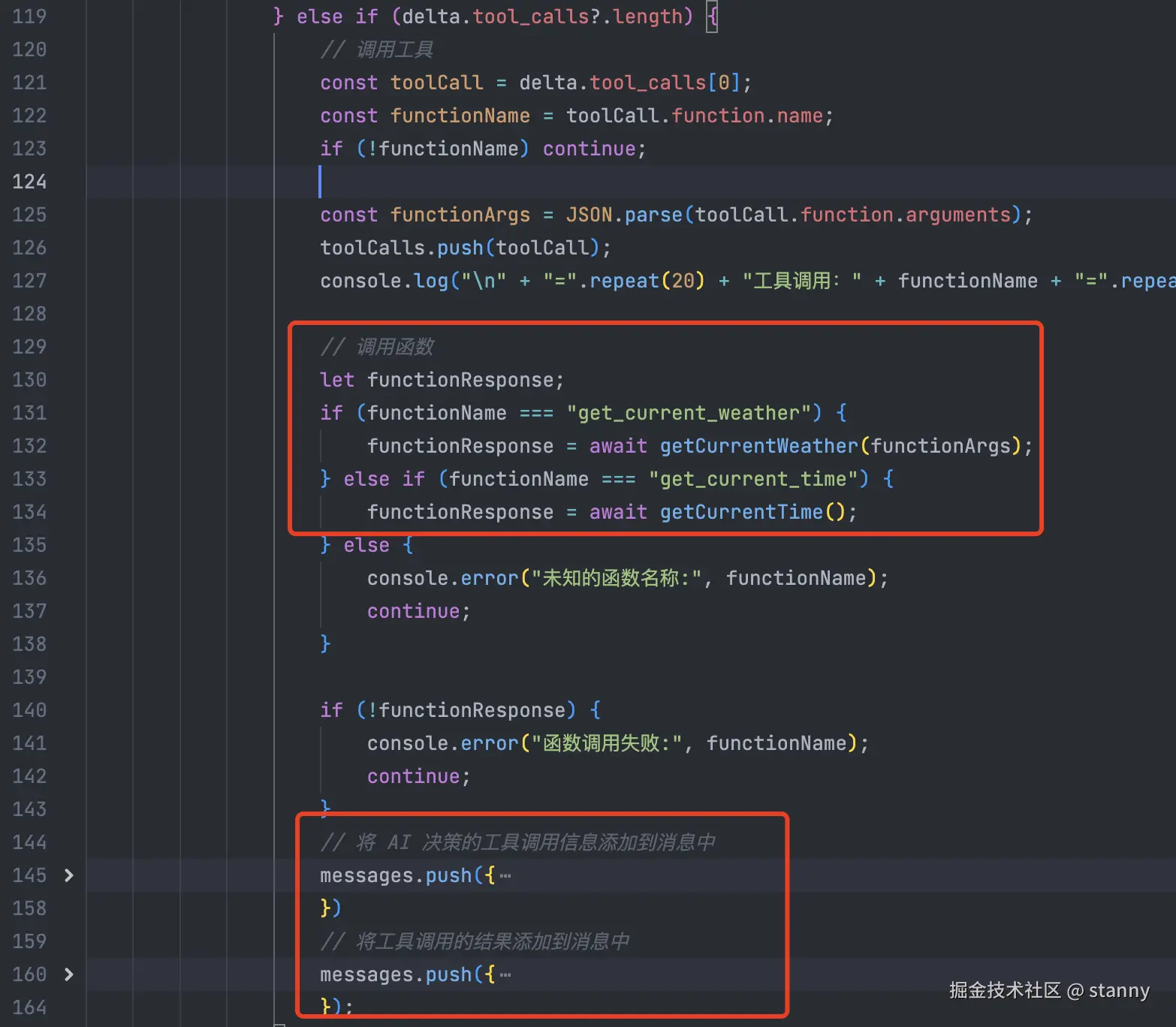
// 将 AI 决策的工具调用信息添加到消息中
messages.push({
role: "assistant",
content: null,
tool_calls: [
{
id: toolCall.id,
type: "function",
function: {
name: functionName,
arguments: JSON.stringify(functionArgs),
}
}
]
})
// 将工具调用的结果添加到消息中
messages.push({
role: "tool",
name: functionName,
content: JSON.stringify(functionResponse)
});
}
}
if (toolCalls.length) {
// 再调用一次 llm
console.log("\n" + "=".repeat(20) + "再次调用 LLM" + "=".repeat(20));
console.dir(messages, { depth: null });
callModel(messages);
}
} catch (error) {
console.error("发生错误:", error);
}
}
}
main(); 几个实现重点我截图展示一下

我们最终跑起来看一下运行结果:
js
请输入您的问题:现在是什么时间
====================思考过程====================
好的,用户问现在是什么时间,我需要调用获取当前时间的函数。看一下提供的工具,有一个get_current_time函数,不需要参数。直接调用这个函数就能得到当前时间了。确认一下用户可能需要的时区,但函数可能已经默认返回本地时间,所以应该没问题。不需要其他参数,直接调用即可。
</think>
====================工具调用:get_current_time====================
====================再次调用 LLM====================
[
{ role: 'user', content: '现在是什么时间' },
{
role: 'assistant',
content: null,
tool_calls: [
{
id: 'call_72474905434a4715aec248',
type: 'function',
function: { name: 'get_current_time', arguments: '{}' }
}
]
},
{
role: 'tool',
name: 'get_current_time',
content: '{"date":"2025-04-21","time":"18:00:41","weekday":"星期一","timezone":"Asia/Shanghai"}'
}
]
====================思考过程====================
好的,用户之前问过"现在是什么时间",我调用了get_current_time函数,现在收到了响应。需要把当前时间以自然的方式回复给他。
首先,看一下返回的数据:日期是2025年4月21日,时间18点00分41秒,星期一,时区上海。用户可能需要简洁的信息,不需要太复杂。
要组织语言,确保信息清晰。比如:"当前时间是18点00分,今天是2025年4月21日星期一。" 这样分两部分说时间和平日,容易阅读。
另外,可能用户有其他需求,比如是否需要时区说明?响应里有时区信息,但用户可能已经知道,因为问题里没特别提。不过加上可能更好,比如"(上海时区)"作为补充。
检查有没有格式错误,比如日期和时间的格式是否正确。确认无误后,用中文自然表达,保持口语化,不用专业术语。确保没有使用任何markdown,只用纯文本。
最后,确保回答准确,没有遗漏关键信息。用户可能只需要时间,但日期和星期也是有用的,所以都包含进去。这样回答应该能满足需求。
====================回复内容====================
当前时间是18点00分,今天是2025年4月21日星期一(上海时区)。当然这里只是实现了最简单的自动执行 function,很多边界 case 也没有深入去考虑。
不过可以让大家可以清晰的看到,如何结合 function call,让大模型获得"外挂"能力。
业界也有一些成熟的方案出来了,有兴趣可以看看 langgraph 的方案,找机会我也会整理一篇有关 langchain/langgraph 入门的文章分享出来。
总结
本文我们首先回顾了一下大模型的调用入参,这里我们关注到 message 主要分为以下几种 role
- system
- assistant
- user
- tool
- function
然后结合模型调用示例,我们得出一个结论:
大模型本质上是根据历史对话(输出),预测下一次回答(输出)。
接着手动模拟了一个包含function call 的历史对话,让大模型预测出回答。
最后写了一个简单的demo:
当识别到 llm 需要调用工具时,用代码控制自动执行工具,并且拼接工具调用结果,再次调用 llm 得出最终结果。