ESP32C3语音AI对话代码分析
代码:基于立创实战派C3例程删改(LCD屏幕显示,触摸和LVGL)和分析
硬件:立创实战派C3
立创官方例程教程链接:第16章 桌面天气助手 | 立创开发板技术文档中心
整体流程图:
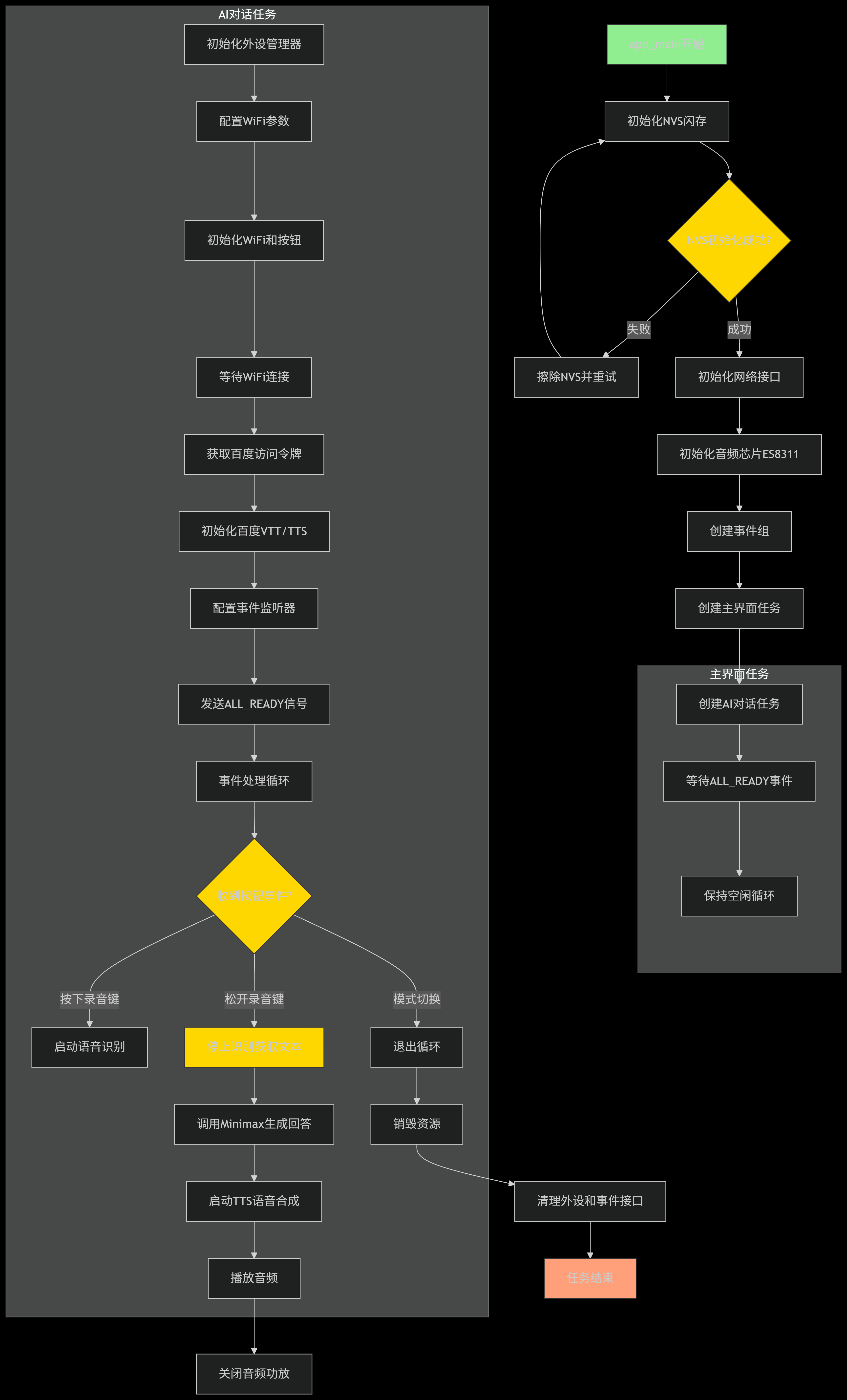
流程图说明:
主程序初始化阶段:
先进行NVS闪存初始化(含失败重试机制)
初始化网络接口和音频硬件
创建事件组和两个主要任务
主界面任务:
等待系统准备完成事件
保持空循环等待后续扩展
AI对话核心任务:
初始化外设和网络连接
配置语音识别/合成模块
通过事件驱动机制处理按钮操作
实现完整的语音交互流程:
按钮按下开始录音
按钮松开触发AI处理
语音合成播放回答
graph TD
A[app_main开始] --> B[初始化NVS闪存]
B --> C{NVS初始化成功?}
C -- 失败 --> D[擦除NVS并重试]
D --> B
C -- 成功 --> E[初始化网络接口]
E --> F[初始化音频芯片ES8311]
F --> G[创建事件组]
G --> H[创建主界面任务]
H --> I[创建AI对话任务]
subgraph 主界面任务
I --> J[等待ALL_READY事件]
J --> K[保持空闲循环]
end
subgraph AI对话任务
L[初始化外设管理器] --> M[配置WiFi参数]
M --> N[初始化WiFi和按钮]
N --> O[等待WiFi连接]
O --> P[获取百度访问令牌]
P --> Q[初始化百度VTT/TTS]
Q --> R[配置事件监听器]
R --> S[发送ALL_READY信号]
S --> T[事件处理循环]
T --> U{收到按钮事件?}
U -- 按下录音键 --> V[启动语音识别]
U -- 松开录音键 --> W[停止识别获取文本]
W --> X[调用Minimax生成回答]
X --> Y[启动TTS语音合成]
Y --> Z[播放音频]
U -- 模式切换 --> AA[退出循环]
AA --> AB[销毁资源]
end
Z --> AC[关闭音频功放]
AB --> AD[清理外设和事件接口]
AD --> AE[任务结束]代码:
app_main开始
c
/**************************** 主函数 **********************************/
void app_main(void)
{
/************ 初始化NVS *************/
esp_err_t err = nvs_flash_init();
if (err == ESP_ERR_NVS_NO_FREE_PAGES) {
// NVS partition was truncated and needs to be erased
// Retry nvs_flash_init
ESP_ERROR_CHECK(nvs_flash_erase());
err = nvs_flash_init();
}
ESP_ERROR_CHECK(esp_netif_init());
/******* 初始化ES8311音频芯片 (注意:这个里面会初始化I2C 后面初始化触摸屏就不用再初始化I2C了) ********/
ESP_LOGI(TAG, "[ 2 ] Start codec chip");
audio_board_handle_t board_handle = audio_board_init();
audio_hal_ctrl_codec(board_handle->audio_hal, AUDIO_HAL_CODEC_MODE_BOTH, AUDIO_HAL_CTRL_START);
es8311_codec_set_voice_volume(100); // 最大音量
es8311_pa_power(false); // 关闭声音
// 创建一个事件组
// xEventGroupCreate 是 FreeRTOS 提供的一个函数,用于创建一个事件组
// 事件组是一种用于任务间通信的机制,通过设置和清除事件标志来实现任务的同步
// my_event_group 是一个事件组的句柄,用于后续对事件组进行操作
my_event_group = xEventGroupCreate();
/****************** 创建任务 **********************/
xTaskCreate(main_page_task, "main_page_task", 8192, NULL, 5, NULL);
xTaskCreate(ai_chat_task, "ai_chat_task", 8192, NULL, 5, NULL);
while (1) {
vTaskDelay(pdMS_TO_TICKS(10));
}
}主函数流程:
txt
A[app_main开始] --> B[初始化NVS闪存]
B --> C{NVS初始化成功?}
C -- 失败 --> D[擦除NVS并重试]
D --> B
C -- 成功 --> E[初始化网络接口]
E --> F[初始化音频芯片ES8311]
F --> G[创建事件组]
G --> H[创建主界面任务]
H --> I[创建AI对话任务]初始化NVS
作用:
NVS(Non-Volatile Storage,非易失性存储)
主要功能
-
持久化数据存储
-
存储关键数据:Wi-Fi 凭证、设备配置、传感器校准参数等
-
支持断电保存:数据在设备断电/重启后仍能保留
-
示例场景:
// 保存Wi-Fi密码 nvs_set_str(nvs_handle, "wifi_pswd", "87654321");
-
-
键值对存储
- 采用简单的 key-value 结构
- 支持多种数据类型:
-
系统参数管理
- 存储固件运行状态(如首次启动标志)
- 保存OTA升级相关信息
合理使用NVS可以显著提升用户体验(如记住网络配置、语音偏好设置等)。
代码实现:
c
/************ 初始化NVS *************/
esp_err_t err = nvs_flash_init();
if (err == ESP_ERR_NVS_NO_FREE_PAGES) {
// NVS partition was truncated and needs to be erased
// Retry nvs_flash_init
ESP_ERROR_CHECK(nvs_flash_erase());
err = nvs_flash_init();
}初始化网络接口
c
ESP_ERROR_CHECK(esp_netif_init());//于初始化 ESP-IDF 中的网络接口。作用:
esp_netif_init() 是 ESP-IDF 网络接口模块的核心初始化函数,其作用可概括为使能为应用程序提供网络服务的底层基础结构。完整作用和机制如下:
功能作用
- 初始化底层网络协议栈
- 资源分配 ▸ 分配TCP/IP适配器和网络接口控制器所需的内存与管理结构,包括线程/队列等依赖项。
- 基础配置构建器 ▸ 建立与LwIP协议栈的关联环境,支持IP分配、Socket实现、DNS功能等。
- 注册默认事件处理
- (如IP获取失败或网络状态变更事件)绑定到
esp_event_loop,确保回调系统正常运行。
- (如IP获取失败或网络状态变更事件)绑定到
- 准备抽象接口
- 为后续创建的具体网络驱动接口(如Wi-Fi AP/STA、以太网)提供基础虚拟适配功能,使其能按标准方法与网络数据交互。
即使在不直接操作TCP/IP的高层应用(如仅使用HTTP-Server通过esp_http_server发起服务),也必须预确保**esp_netif_init()的成功调用顺序**,所有网络硬件驱动在启动时要求底层的基础结构已经处于有效活跃状态。
因此建议在所有涉及网络连接的ESP项目中都优先启用此函数以维护功能的兼容性稳定性。
初始化es8311音频芯片
main中:
c
ESP_LOGI(TAG, "[ 2 ] Start ES8311 Init");//打印调试信息
audio_board_handle_t board_handle = audio_board_init();
audio_hal_ctrl_codec(board_handle->audio_hal, AUDIO_HAL_CODEC_MODE_BOTH, AUDIO_HAL_CTRL_START);
es8311_codec_set_voice_volume(100); // 最大音量
es8311_pa_power(false); // 关闭声音main->audio_board_init(void):
c
// 定义一个静态的全局变量,用于存储音频板句柄
static audio_board_handle_t board_handle = 0;
// 初始化音频板
audio_board_handle_t audio_board_init(void)
{
// 检查音频板是否已经初始化
if (board_handle) {
// 如果已经初始化,打印警告日志
ESP_LOGW(TAG, "The board has already been initialized!");
// 返回当前已初始化的音频板句柄
return board_handle;
}
// 分配内存用于存储音频板句柄结构体
board_handle = (audio_board_handle_t) audio_calloc(1, sizeof(struct audio_board_handle));
// 检查内存分配是否成功
AUDIO_MEM_CHECK(TAG, board_handle, return NULL);
// 初始化音频编解码器
board_handle->audio_hal = audio_board_codec_init();
// 返回初始化后的音频板句柄
return board_handle;
}main->audio_board_init(void)->audio_board_codec_init(void):
c
// 初始化音频编解码器
audio_hal_handle_t audio_board_codec_init(void)
{
// 获取默认的音频编解码器配置
audio_hal_codec_config_t audio_codec_cfg = AUDIO_CODEC_DEFAULT_CONFIG();
// 初始化音频编解码器
audio_hal_handle_t codec_hal = audio_hal_init(&audio_codec_cfg, &AUDIO_CODEC_ES8311_DEFAULT_HANDLE);//esp-adf音频框架
// 检查编解码器句柄是否为空
AUDIO_NULL_CHECK(TAG, codec_hal, return NULL);
// 返回初始化后的音频编解码器句柄
return codec_hal;
}main->audio_board_init(void)->audio_board_codec_init(void)->AUDIO_CODEC_DEFAULT_CONFIG():
c
// 声明一个外部变量,指向audio_hal_func_t类型的默认处理函数,用于ES8311音频编解码器
extern audio_hal_func_t AUDIO_CODEC_ES8311_DEFAULT_HANDLE;
// 定义一个宏,用于生成默认的音频编解码器配置结构体
// 配置ADC输入为线路1
// 配置DAC输出为所有通道
// 配置编解码器模式为同时支持ADC和DAC
// 配置I2S接口参数
// 配置I2S工作模式为从模式
// 配置I2S格式为普通模式
// 配置采样率为16kHz
// 配置位长为16位
#define AUDIO_CODEC_DEFAULT_CONFIG(){ \
.adc_input = AUDIO_HAL_ADC_INPUT_LINE1, \
.dac_output = AUDIO_HAL_DAC_OUTPUT_ALL, \
.codec_mode = AUDIO_HAL_CODEC_MODE_BOTH, \
.i2s_iface = { \
.mode = AUDIO_HAL_MODE_SLAVE, \
.fmt = AUDIO_HAL_I2S_NORMAL, \
.samples = AUDIO_HAL_16K_SAMPLES, \
.bits = AUDIO_HAL_BIT_LENGTH_16BITS, \
}, \
};创建事件组
static EventGroupHandle_t my_event_group;
my_event_group = xEventGroupCreate();用于同步界面显示任务和AI对话任务。
流程:AI对话任务获取输出->事件组置位
显示任务->阻塞等待事件组
创建AI对话任务
c
/****************** 创建任务 **********************/
xTaskCreate(ai_chat_task, "ai_chat_task", 8192, NULL, 5, NULL);// AI对话任务
while (1) {
vTaskDelay(pdMS_TO_TICKS(10));
}AI对话任务
c
/**************************** AI对话任务函数 **********************************/
void ai_chat_task(void *pv)
{
ESP_LOGI(TAG, "[ 1 ] Initialize Buttons & Connect to Wi-Fi network, ssid=%s", CONFIG_WIFI_SSID);//打印调试信息初始化按钮,连接wifi
//初始化esp-adf外设框架为默认配置
// Initialize peripherals management
esp_periph_config_t periph_cfg = DEFAULT_ESP_PERIPH_SET_CONFIG();
//periph_cfg.task_stack = 8*1024;
esp_periph_set_handle_t set = esp_periph_set_init(&periph_cfg);
//配置wifi参数
periph_wifi_cfg_t wifi_cfg = {
.wifi_config.sta.ssid = CONFIG_WIFI_SSID,// 这里修改成自己的wifi名称
.wifi_config.sta.password = CONFIG_WIFI_PASSWORD,// 这里修改成自己的wifi密码
};
esp_periph_handle_t wifi_handle = periph_wifi_init(&wifi_cfg);// 初始化wifi
// Initialize Button peripheral
//配置按键外设参数
periph_button_cfg_t btn_cfg = {
.gpio_mask = (1ULL << get_input_mode_id()) | (1ULL << get_input_rec_id()),
};
esp_periph_handle_t button_handle = periph_button_init(&btn_cfg);
// Start wifi & button peripheral
//启动按键和wifi外设
esp_periph_start(set, button_handle);
esp_periph_start(set, wifi_handle);
// wifi连接(阻塞等待连接成功)
periph_wifi_wait_for_connected(wifi_handle, portMAX_DELAY);
//获取百度语音服务的访问令牌(Access Token)
if (baidu_access_token == NULL) {// 百度token计算
// Must freed `baidu_access_token` after used
baidu_access_token = baidu_get_access_token(CONFIG_BAIDU_ACCESS_KEY, CONFIG_BAIDU_SECRET_KEY);
}
// 百度 语音转文字 初始化
baidu_vtt_config_t vtt_config = {
.record_sample_rates = 16000,//采样率
.encoding = ENCODING_LINEAR16,//编码格式(16线性)
};
baidu_vtt_handle_t vtt = baidu_vtt_init(&vtt_config);//初始化语音转文字,并返回句柄
// 百度 文字转语音 初始化
baidu_tts_config_t tts_config = {
.playback_sample_rate = 16000,
};
baidu_tts_handle_t tts = baidu_tts_init(&tts_config);
// 监听"流"
ESP_LOGI(TAG, "[ 4 ] Set up event listener");
// 初始化音频事件接口配置,使用默认配置
audio_event_iface_cfg_t evt_cfg = AUDIO_EVENT_IFACE_DEFAULT_CFG();
// 根据配置初始化音频事件接口,并获取事件接口句柄
audio_event_iface_handle_t evt = audio_event_iface_init(&evt_cfg);
// 打印日志信息,表示开始监听来自管道的事件
ESP_LOGI(TAG, "[4.1] Listening event from the pipeline");
// 设置百度语音识别的监听器,监听器为初始化的事件接口句柄
baidu_vtt_set_listener(vtt, evt);
// 设置百度语音合成的监听器,监听器为初始化的事件接口句柄
baidu_tts_set_listener(tts, evt);
// 打印日志信息,表示开始监听来自外设的事件
ESP_LOGI(TAG, "[4.2] Listening event from peripherals");
// 获取外设集的事件接口,并设置监听器为初始化的事件接口句柄
audio_event_iface_set_listener(esp_periph_set_get_event_iface(set), evt);
// 打印日志信息,表示开始监听所有管道事件
ESP_LOGI(TAG, "[ 5 ] Listen for all pipeline events");
// 给出 "已经准备好" 信号
xEventGroupSetBits(my_event_group, ALL_REDAY);
while (1) {
audio_event_iface_msg_t msg;
// 调用audio_event_iface_listen函数监听音频事件,并等待事件消息
// evt: 事件接口
// &msg: 指向存储事件消息的结构的指针
// portMAX_DELAY: 无限等待,直到接收到事件消息
if (audio_event_iface_listen(evt, &msg, portMAX_DELAY) != ESP_OK) {
// 如果监听事件失败,打印警告日志
ESP_LOGW(TAG, "[ * ] Event process failed: src_type:%d, source:%p cmd:%d, data:%p, data_len:%d",
msg.source_type, msg.source, msg.cmd, msg.data, msg.data_len);
// 继续下一次循环,处理下一个事件
continue;
}
// 使用ESP_LOGI宏记录信息日志,TAG为日志标签,格式化字符串中包含事件的相关信息
ESP_LOGI(TAG, "[ * ] Event received: src_type:%d, source:%p cmd:%d, data:%p, data_len:%d",
msg.source_type, msg.source, msg.cmd, msg.data, msg.data_len);
// 检查TTS(文本到语音)事件是否完成
if (baidu_tts_check_event_finish(tts, &msg)) {
// 如果TTS事件完成,记录信息日志
ESP_LOGI(TAG, "[ * ] TTS Finish");
// 关闭音频功率放大器
es8311_pa_power(false); // 关闭音频
// 继续下一次循环
continue;
}
// 检查事件源类型是否为按钮
if (msg.source_type != PERIPH_ID_BUTTON) {
// 如果不是按钮事件,继续下一次循环
continue;
}
// 检查事件数据是否与当前输入模式ID相同
if ((int)msg.data == get_input_mode_id()) {
// 如果相同,跳出当前循环
break;
}
// 检查事件数据是否与当前输入录音ID不同
if ((int)msg.data != get_input_rec_id()) {
// 如果不同,继续下一次循环
continue;
}
// 检查消息命令是否为按钮按下事件
if (msg.cmd == PERIPH_BUTTON_PRESSED) {
// 停止百度语音合成
baidu_tts_stop(tts);
// 打印日志,表示正在恢复管道
ESP_LOGI(TAG, "[ * ] Resuming pipeline");
// 设置LCD清除标志
lcd_clear_flag = 1;
// 启动百度语音识别
baidu_vtt_start(vtt);
} else if (msg.cmd == PERIPH_BUTTON_RELEASE || msg.cmd == PERIPH_BUTTON_LONG_RELEASE) {
// 打印日志信息,表示停止管道操作
ESP_LOGI(TAG, "[ * ] Stop pipeline");
// 调用baidu_vtt_stop函数停止语音到文本的转换,并获取原始文本
char *original_text = baidu_vtt_stop(vtt);
// 如果获取的原始文本为空,则清空minimax_content数组并继续下一次循环
if (original_text == NULL) {
minimax_content[0]=0; // 清空minimax 第1个字符写0就可以
continue;
}
// 打印日志信息,显示获取到的原始文本
ESP_LOGI(TAG, "Original text = %s", original_text);
// 设置ask_flag为1,表示有新的问题需要处理
ask_flag = 1;
// 调用minimax_chat函数,传入原始文本,获取minimax的回复
char *answer = minimax_chat(original_text);
// 如果获取的回复为空,则继续下一次循环
if (answer == NULL)
{
continue;
}
// 打印日志信息,显示minimax的回复
ESP_LOGI(TAG, "minimax answer = %s", answer);
// 设置answer_flag为1,表示有新的回答需要处理
answer_flag = 1;
// 打开音频功率放大器
es8311_pa_power(true); // 打开音频
// 调用baidu_tts_start函数,传入tts和回答文本,开始文本到语音的转换
baidu_tts_start(tts, answer);
}
}
ESP_LOGI(TAG, "[ 6 ] Stop audio_pipeline");
// 销毁百度语音识别对象
baidu_vtt_destroy(vtt);
// 销毁百度语音合成对象
baidu_tts_destroy(tts);
/* Stop all periph before removing the listener */
// 调用esp_periph_set_stop_all函数,停止所有在peripheral set中的peripherals
esp_periph_set_stop_all(set);
// 从事件接口中移除事件监听器
// esp_periph_set_get_event_iface(set)获取peripheral set的事件接口
// evt是待移除的事件监听器
// 从音频事件接口中移除监听器
audio_event_iface_remove_listener(esp_periph_set_get_event_iface(set), evt);
/* Make sure audio_pipeline_remove_listener & audio_event_iface_remove_listener are called before destroying event_iface */
// 销毁音频事件接口
audio_event_iface_destroy(evt);
// 销毁ESP外设集合
esp_periph_set_destroy(set);
// 删除当前任务
vTaskDelete(NULL);
}流程图:
AI处理部分
VTT(voice to text)语音转文字
将麦克风接收到的语音转化成文字,便于处理后上传到LLM(大模型)
流程
graph TD
A开始 --> B初始化变量: response_text, post_buffer, data_buf
B --> C配置HTTP客户端参数
C --> D生成POST请求数据
D --> E设置HTTP方法和头部
E --> F打开HTTP连接
F --> G发送POST数据
G --> H读取响应头部
H --> I分配响应数据缓冲区
I --> J读取响应内容
J --> K解析JSON响应
K --> L提取reply内容
L --> M复制内容到全局变量
M --> N清理资源
N --> O返回response_text
c
#include <string.h> // 包含字符串操作函数
#include "freertos/FreeRTOS.h" // 包含FreeRTOS操作系统相关函数和定义
#include "freertos/task.h" // 包含FreeRTOS任务管理相关函数和定义
#include "esp_log.h" // 包含ESP-IDF日志记录功能
#include "esp_wifi.h" // 包含ESP-IDF WiFi驱动相关函数和定义
#include "nvs_flash.h" // 包含ESP-IDF非易失性存储(NVS)相关函数和定义
#include "esp_http_client.h" // 包含ESP-IDF HTTP客户端相关函数和定义
#include "sdkconfig.h" // 包含SDK配置相关宏定义
#include "audio_element.h" // 包含音频元素相关函数和定义
#include "audio_pipeline.h" // 包含音频管道相关函数和定义
#include "audio_event_iface.h" // 包含音频事件接口相关函数和定义
#include "audio_common.h" // 包含音频通用功能相关函数和定义
#include "audio_hal.h" // 包含音频硬件抽象层相关函数和定义
#include "http_stream.h" // 包含HTTP流相关函数和定义
#include "i2s_stream.h" // 包含I2S流相关函数和定义
#include "mp3_decoder.h" // 包含MP3解码器相关函数和定义
#include "baidu_vtt.h" // 包含百度语音识别相关函数和定义
#include "cJSON.h" // 包含cJSON库,用于处理JSON数据
static const char *TAG = "BAIDU_VTT";
extern char *baidu_access_token;
#define BAIDU_VTT_ENDPOINT "http://vop.baidu.com/server_api?dev_pid=1537&cuid=esp32c3&token=%s"
#define BAIDU_VTT_TASK_STACK (8*1024)
// 定义一个名为 baidu_vtt 的结构体类型,用于处理百度语音识别相关的数据
typedef struct baidu_vtt {
audio_pipeline_handle_t pipeline;
char *buffer;
audio_element_handle_t i2s_reader;
audio_element_handle_t http_stream_writer;
int sample_rates;
int buffer_size;
baidu_vtt_encoding_t encoding;
char *response_text;
baidu_vtt_event_handle_t on_begin;
} baidu_vtt_t;
char ask_text[256]={0}; // 存储提问的文字
// 定义一个静态函数,用于处理HTTP流事件
static esp_err_t _http_stream_writer_event_handle(http_stream_event_msg_t *msg)
{
// 从消息中获取HTTP客户端句柄
esp_http_client_handle_t http = (esp_http_client_handle_t)msg->http_client;
// 从消息中获取用户数据,这里是一个baidu_vtt_t类型的指针
baidu_vtt_t *vtt = (baidu_vtt_t *)msg->user_data;
// 定义一个静态变量,用于记录总共写入的字节数
static int total_write = 0;
// 定义一个字符数组,用于存储长度信息
char len_buf[16];
// 如果事件ID是HTTP_STREAM_PRE_REQUEST,表示请求前的事件
if (msg->event_id == HTTP_STREAM_PRE_REQUEST) {
// 打印日志,显示请求前的信息
ESP_LOGI(TAG, "[ + ] HTTP client HTTP_STREAM_PRE_REQUEST, lenght=%d", msg->buffer_len);
// 重置总共写入的字节数
total_write = 0;
// 设置HTTP客户端的请求方法为POST
esp_http_client_set_method(http, HTTP_METHOD_POST);
// 设置POST字段的值为空,表示使用分块传输
esp_http_client_set_post_field(http, NULL, -1); // Chunk content
// 设置HTTP头,指定内容类型为audio/pcm,采样率为16000
esp_http_client_set_header(http, "Content-Type", "audio/pcm;rate=16000");
// 设置HTTP头,指定接受的响应类型为application/json
esp_http_client_set_header(http, "Accept", "application/json");
// 返回ESP_OK,表示操作成功
return ESP_OK;
}
// 如果事件ID是HTTP_STREAM_ON_REQUEST,表示请求中的事件
if (msg->event_id == HTTP_STREAM_ON_REQUEST) { // 这个if会进来好多次
// write data
int wlen = sprintf(len_buf, "%x\r\n", msg->buffer_len); // 将消息缓冲区的长度转换为十六进制字符串,并存储在len_buf中,同时计算字符串长度wlen
if (esp_http_client_write(http, len_buf, wlen) <= 0) { // 将长度字符串写入HTTP客户端,
return ESP_FAIL;
}
if (esp_http_client_write(http, msg->buffer, msg->buffer_len) <= 0) { // 将消息缓冲区的内容写入HTTP客户端,
return ESP_FAIL;
}
if (esp_http_client_write(http, "\r\n", 2) <= 0) { // 将回车换行符写入HTTP客户端
return ESP_FAIL;
}
total_write += msg->buffer_len; // 累加已写入的总字节数
printf("\033[A\33[2K\rTotal bytes written: %d\n", total_write); // 打印当前已写入的总字节数,使用ANSI转义序列清除当前行并向上移动一行
return msg->buffer_len;
}
/* Write End chunk */
if (msg->event_id == HTTP_STREAM_POST_REQUEST) { // 检查消息的事件ID是否为http post 流请求事件
// 打印日志信息,表示HTTP客户端接收到HTTP_STREAM_POST_REQUEST事件,并准备写入结束分块标记
ESP_LOGI(TAG, "[ + ] HTTP client HTTP_STREAM_POST_REQUEST, write end chunked marker");
if (esp_http_client_write(http, "0\r\n\r\n", 5) <= 0) { // 向HTTP客户端写入结束分块标记"0\r\n\r\n",长度为5个字节
// 如果写入的字节数小于等于0,表示写入失败
return ESP_FAIL;
}
return ESP_OK;
}
if (msg->event_id == HTTP_STREAM_FINISH_REQUEST) {// 检查消息的事件ID是否为完成http post 流请求事件
// 从HTTP客户端读取数据到vtt的缓冲区中,返回读取的长度
int read_len = esp_http_client_read(http, (char *)vtt->buffer, vtt->buffer_size);
// 打印读取长度
ESP_LOGI(TAG, "[ + ] HTTP client HTTP_STREAM_FINISH_REQUEST, read_len=%d", read_len);
// 如果读取长度小于等于0,表示读取失败,返回ESP_FAIL
if (read_len <= 0) {
return ESP_FAIL;
}
// 如果读取长度超过缓冲区大小减1,则截断读取长度
if (read_len > vtt->buffer_size - 1) {
read_len = vtt->buffer_size - 1;
}
// 在缓冲区末尾添加字符串结束符
vtt->buffer[read_len] = 0;
// 打印HTTP响应内容
ESP_LOGI(TAG, "Got HTTP Response = %s", (char *)vtt->buffer);
// 解析JSON格式的响应内容
cJSON *root = cJSON_Parse(vtt->buffer);
// 获取JSON对象中的"err_no"字段的整数值
int err_no = cJSON_GetObjectItem(root,"err_no")->valueint;
if (err_no == 0) // 如果转换成功
{
// 从JSON对象root中获取名为"result"的项,并赋值给指针result
cJSON *result = cJSON_GetObjectItem(root,"result");
// 从result数组中获取第一个元素,并将其值转换为字符串
char *text = cJSON_GetArrayItem(result, 0)->valuestring;
// 将获取到的字符串复制到ask_text变量中
strcpy(ask_text, text);
// 将ask_text的值赋给vtt结构体的response_text成员
vtt->response_text = ask_text;
// 使用ESP_LOGI宏打印日志信息,显示response_text的值
ESP_LOGI(TAG, "response_text:%s", vtt->response_text);
}
else{
vtt->response_text = NULL;
}
cJSON_Delete(root);
return ESP_OK;
}
return ESP_OK;
}
// 初始化百度语音识别处理句柄
baidu_vtt_handle_t baidu_vtt_init(baidu_vtt_config_t *config)
{
// 管道配置
audio_pipeline_cfg_t pipeline_cfg = DEFAULT_AUDIO_PIPELINE_CONFIG(); // 使用默认的音频管道配置
baidu_vtt_t *vtt = calloc(1, sizeof(baidu_vtt_t)); // 分配内存并初始化为0
AUDIO_MEM_CHECK(TAG, vtt, return NULL); // 检查内存分配是否成功,失败则返回NULL
vtt->pipeline = audio_pipeline_init(&pipeline_cfg); // 初始化音频管道
vtt->buffer_size = config->buffer_size; // 设置缓冲区大小
if (vtt->buffer_size <= 0) { // 如果配置的缓冲区大小不合法
vtt->buffer_size = DEFAULT_VTT_BUFFER_SIZE; // 使用默认缓冲区大小
}
vtt->buffer = malloc(vtt->buffer_size); // 分配缓冲区内存
AUDIO_MEM_CHECK(TAG, vtt->buffer, goto exit_vtt_init); // 检查内存分配是否成功,失败则跳转到exit_vtt_init
// I2S流配置
i2s_stream_cfg_t i2s_cfg = I2S_STREAM_CFG_DEFAULT_WITH_PARA(0, 16000, 16, AUDIO_STREAM_READER); // 使用默认的I2S流配置
i2s_cfg.std_cfg.slot_cfg.slot_mode = I2S_SLOT_MODE_MONO; // 设置为单声道模式
i2s_cfg.std_cfg.slot_cfg.slot_mask = I2S_STD_SLOT_LEFT; // 设置为左声道
vtt->i2s_reader = i2s_stream_init(&i2s_cfg); // 初始化I2S流
// HTTP流配置
http_stream_cfg_t http_cfg = {
.type = AUDIO_STREAM_WRITER, // 设置为HTTP流写入器
.event_handle = _http_stream_writer_event_handle, // 设置事件处理函数
.user_data = vtt, // 设置用户数据
.task_stack = BAIDU_VTT_TASK_STACK, // 设置任务堆栈大小
};
vtt->http_stream_writer = http_stream_init(&http_cfg); // 初始化HTTP流
vtt->sample_rates = config->record_sample_rates; // 设置采样率
vtt->encoding = config->encoding; // 设置编码格式
vtt->on_begin = config->on_begin; // 设置开始回调函数
// 把 I2S流 和 HTTP流 注册到管道 并链接起来
audio_pipeline_register(vtt->pipeline, vtt->http_stream_writer, "vtt_http"); // 注册HTTP流到管道
audio_pipeline_register(vtt->pipeline, vtt->i2s_reader, "vtt_i2s"); // 注册I2S流到管道
const char *link_tag[2] = {"vtt_i2s", "vtt_http"}; // 设置链接标签
audio_pipeline_link(vtt->pipeline, &link_tag[0], 2); // 链接I2S流和HTTP流
// 设置I2S采样率 位数 等参数
i2s_stream_set_clk(vtt->i2s_reader, config->record_sample_rates, 16, 1); // 设置I2S流的采样率、位数和通道数
return vtt; // 返回初始化好的句柄
exit_vtt_init:
baidu_vtt_destroy(vtt); // 销毁句柄
return NULL; // 返回NULL
}
// 定义一个函数,用于销毁百度语音识别句柄
esp_err_t baidu_vtt_destroy(baidu_vtt_handle_t vtt)
{
// 检查传入的句柄是否为空,如果为空则返回失败
if (vtt == NULL) {
return ESP_FAIL;
}
// 停止音频管道
audio_pipeline_stop(vtt->pipeline);
// 等待音频管道停止
audio_pipeline_wait_for_stop(vtt->pipeline);
// 终止音频管道
audio_pipeline_terminate(vtt->pipeline);
// 移除音频管道的监听器
audio_pipeline_remove_listener(vtt->pipeline);
// 反初始化音频管道
audio_pipeline_deinit(vtt->pipeline);
// 释放音频缓冲区的内存
free(vtt->buffer);
// 释放句柄本身的内存
free(vtt);
// 返回成功
return ESP_OK;
}
// 函数声明:设置百度语音识别的监听器
// 参数:
// vtt - 百度语音识别句柄
// listener - 音频事件接口句柄
// 返回值:ESP_OK 表示成功,其他错误码表示失败
esp_err_t baidu_vtt_set_listener(baidu_vtt_handle_t vtt, audio_event_iface_handle_t listener)
{
// 检查传入的监听器是否为非空
if (listener) {
// 如果监听器不为空,则将其设置为音频管道的监听器
audio_pipeline_set_listener(vtt->pipeline, listener);
}
// 返回操作成功标志
return ESP_OK;
}
// 函数声明:baidu_vtt_start
// 功能:启动百度语音识别(VTT)服务
// 参数:vtt - 指向百度语音识别句柄的指针
// 返回值:esp_err_t - 表示函数执行结果的错误码
esp_err_t baidu_vtt_start(baidu_vtt_handle_t vtt)
{
// 使用snprintf函数格式化字符串,将百度语音识别的API端点和访问令牌拼接存入vtt->buffer
// vtt->buffer:存储格式化后的字符串
// vtt->buffer_size:buffer的大小
// BAIDU_VTT_ENDPOINT:百度语音识别的API端点格式字符串
// baidu_access_token:百度API访问令牌
snprintf(vtt->buffer, vtt->buffer_size, BAIDU_VTT_ENDPOINT, baidu_access_token);
// 设置HTTP流写入元素的URI为vtt->buffer中的内容
// vtt->http_stream_writer:HTTP流写入元素
// vtt->buffer:包含API端点和访问令牌的字符串
audio_element_set_uri(vtt->http_stream_writer, vtt->buffer);
// 重置音频管道中所有元素的状态
// vtt->pipeline:音频管道
audio_pipeline_reset_items_state(vtt->pipeline);
// 重置音频管道中的环形缓冲区
// vtt->pipeline:音频管道
audio_pipeline_reset_ringbuffer(vtt->pipeline);
// 启动音频管道,开始处理音频数据
// vtt->pipeline:音频管道
audio_pipeline_run(vtt->pipeline);
// 返回ESP_OK表示函数执行成功
return ESP_OK;
}
// 函数声明:baidu_vtt_stop
// 参数:baidu_vtt_handle_t vtt - 包含音频处理管道和相关资源的结构体指针
// 返回值:char* - 指向响应文本的指针
char *baidu_vtt_stop(baidu_vtt_handle_t vtt)
{
// 调用audio_pipeline_stop函数停止音频处理管道
// vtt->pipeline 是指向音频处理管道的指针
audio_pipeline_stop(vtt->pipeline);
// 调用audio_pipeline_wait_for_stop函数等待音频处理管道完全停止
// 确保所有正在进行的处理都已完成
audio_pipeline_wait_for_stop(vtt->pipeline);
// 返回vtt结构体中的response_text成员
// response_text是一个指向字符数组的指针,存储了处理后的响应文本
return vtt->response_text;
}LLM(large language mode)大语言模型
将VTT输出的文本上传到LLM,LLM回答返回文本数据,将用作TTS的输入
简述:将文本通过http post请求发送到LLM的API接口,并等待接收返回数据,并使用cJSON解析出结果
c
#include <string.h> // 包含标准字符串操作函数库
#include "freertos/FreeRTOS.h" // 包含FreeRTOS操作系统核心头文件
#include "freertos/task.h" // 包含FreeRTOS任务管理相关头文件
#include "esp_log.h" // 包含ESP-IDF日志库头文件
#include "esp_wifi.h" // 包含ESP-IDF WiFi驱动头文件
#include "nvs_flash.h" // 包含ESP-IDF非易失性存储(NVS)头文件
#include "esp_http_client.h" // 包含ESP-IDF HTTP客户端库头文件
#include "sdkconfig.h" // 包含ESP-IDF SDK配置头文件
#include "audio_common.h" // 包含ESP-IDF音频通用库头文件
#include "audio_hal.h" // 包含ESP-IDF音频硬件抽象层(HAL)头文件
#include "minimax_chat.h" // 包含自定义的minimax_chat库头文件
#include "cJSON.h" // 包含cJSON库头文件,用于处理JSON数据
static const char *TAG = "MINIMAX_CHAT";
extern const char * minimax_key;
#define PSOT_DATA "{\
\"model\":\"abab5.5s-chat\",\"tokens_to_generate\": 256,\"temperature\":0.7,\"top_p\":0.7,\"plugins\":[],\"sample_messages\":[],\
\"reply_constraints\":{\"sender_type\":\"BOT\",\"sender_name\":\"小美\"},\
\"bot_setting\":[{\
\"bot_name\":\"小美\",\
\"content\":\"小美,性别女,年龄22岁,在校大学生,性格活泼可爱,说话幽默风趣,擅长撩男生,喜欢美食,爱好旅行,是个话痨。\\n\"}],\
\"messages\":[{\"sender_type\":\"USER\",\"sender_name\":\"靓仔\",\"text\":\"%s\"}]\
}"
#define MAX_CHAT_BUFFER (2048)
char minimax_content[2048]={0};
char *minimax_chat(const char *text)//text文本->post_buffer上传
{
char *response_text = NULL;
char *post_buffer = NULL;
char *data_buf = NULL;
esp_http_client_config_t config = {
.url = "https://api.minimax.chat/v1/text/chatcompletion_pro?GroupId=", // 这里替换成自己的GroupId
.buffer_size_tx = 1024 // 默认是512 minimax_key很长 512不够 这里改成1024
};
esp_http_client_handle_t client = esp_http_client_init(&config);
// 使用asprintf函数将格式化的字符串存储到动态分配的缓冲区post_buffer中
// post_len用于存储生成的字符串的长度(不包括终止的空字符)
// PSOT_DATA是一个格式字符串,类似于printf中的格式字符串
// text是传递给格式字符串的参数,将在生成的字符串中替换相应的格式占位符
int post_len = asprintf(&post_buffer, PSOT_DATA, text);
if (post_buffer == NULL) {
goto exit_translate;
}
// POST
// 设置HTTP客户端的请求方法为POST
esp_http_client_set_method(client, HTTP_METHOD_POST);
// 设置HTTP客户端的请求头,指定内容类型为JSON
esp_http_client_set_header(client, "Content-Type", "application/json");
// 设置HTTP客户端的请求头,添加授权信息,使用minimax_key作为授权密钥
esp_http_client_set_header(client, "Authorization", minimax_key);
// 尝试打开HTTP客户端连接,参数client是HTTP客户端实例,post_len是待发送数据的长度
if (esp_http_client_open(client, post_len) != ESP_OK) {
// 如果连接打开失败,记录错误日志
ESP_LOGE(TAG, "Error opening connection");
// 跳转到exit_translate标签,进行后续的错误处理或清理工作
goto exit_translate;
}
// 向HTTP客户端写入数据,参数client是HTTP客户端实例,post_buffer是待发送的数据缓冲区,post_len是数据长度
int write_len = esp_http_client_write(client, post_buffer, post_len);
// 记录信息日志,显示需要写入的数据长度和实际写入的数据长度
ESP_LOGI(TAG, "Need to write %d, written %d", post_len, write_len);
// 获取HTTP客户端的响应头长度
int data_length = esp_http_client_fetch_headers(client);
// 如果获取的长度小于等于0,则使用最大聊天缓冲区长度
if (data_length <= 0) {
data_length = MAX_CHAT_BUFFER;
}
// 分配内存用于存储响应数据,多分配一个字节用于存储字符串结束符'\0'
data_buf = malloc(data_length + 1);
// 如果内存分配失败,跳转到exit_translate标签
if(data_buf == NULL) {
goto exit_translate;
}
// 在数据缓冲区的末尾添加字符串结束符'\0'
data_buf[data_length] = '\0';
// 从HTTP客户端读取数据到数据缓冲区
int rlen = esp_http_client_read(client, data_buf, data_length);
// 在读取的数据末尾添加字符串结束符'\0'
data_buf[rlen] = '\0';
// 打印读取的数据
ESP_LOGI(TAG, "read = %s", data_buf);
// 解析JSON数据
cJSON *root = cJSON_Parse(data_buf);
// 获取JSON对象中的"created"字段的整数值
int created = cJSON_GetObjectItem(root,"created")->valueint;
// 如果"created"字段的值不为0
if(created != 0)
{
// 获取JSON对象中的"reply"字段的字符串值
char *reply = cJSON_GetObjectItem(root,"reply")->valuestring;
// 将"reply"字段的值复制到minimax_content变量
strcpy(minimax_content, reply);
// 将minimax_content的地址赋给response_text
response_text = minimax_content;
// 打印响应文本
ESP_LOGI(TAG, "response_text:%s", response_text);
}
// 删除cJSON对象,释放内存
cJSON_Delete(root);
exit_translate:
// 释放post_buffer指向的内存
free(post_buffer);
// 释放data_buf指向的内存
free(data_buf);
// 清理HTTP客户端资源
esp_http_client_cleanup(client);
// 返回响应文本
return response_text;
}TTS(text to speak)文字转语音
将LLM返回的text文本转化为语音输出到喇叭
c
#include <string.h> // 包含标准字符串处理库
#include "freertos/FreeRTOS.h" // 包含FreeRTOS操作系统核心头文件
#include "freertos/task.h" // 包含FreeRTOS任务管理头文件
#include "esp_log.h" // 包含ESP-IDF日志库头文件
#include "esp_wifi.h" // 包含ESP-IDF WiFi库头文件
#include "nvs_flash.h" // 包含ESP-IDF非易失性存储(NVS)头文件
#include "esp_http_client.h" // 包含ESP-IDF HTTP客户端库头文件
#include "sdkconfig.h" // 包含ESP-IDF SDK配置头文件
#include "audio_element.h" // 包含ESP-IDF音频元素库头文件
#include "audio_pipeline.h" // 包含ESP-IDF音频管道库头文件
#include "audio_event_iface.h" // 包含ESP-IDF音频事件接口库头文件
#include "audio_common.h" // 包含ESP-IDF音频通用库头文件
#include "audio_hal.h" // 包含ESP-IDF音频硬件抽象层库头文件
#include "http_stream.h" // 包含ESP-IDF HTTP流库头文件
#include "i2s_stream.h" // 包含ESP-IDF I2S流库头文件
#include "mp3_decoder.h" // 包含ESP-IDF MP3解码器库头文件
#include "baidu_tts.h" // 包含百度语音合成(TTS)库头文件
static const char *TAG = "BAIDU_TTS";
extern char *baidu_access_token;
#define BAIDU_TTS_ENDPOINT "http://tsn.baidu.com/text2audio" //接口API
#define BAIDU_TTS_TASK_STACK (8*1024)
typedef struct baidu_tts {
audio_pipeline_handle_t pipeline;
audio_element_handle_t i2s_writer;
audio_element_handle_t http_stream_reader;
audio_element_handle_t mp3_decoder;
int buffer_size;
char *buffer;
char *text;
int sample_rate;
} baidu_tts_t;
// 定义一个静态函数,用于处理HTTP流事件
static esp_err_t _http_stream_reader_event_handle(http_stream_event_msg_t *msg)
{
// 从消息中获取HTTP客户端句柄
esp_http_client_handle_t http = (esp_http_client_handle_t)msg->http_client;
// 从消息中获取用户数据,转换为baidu_tts_t类型
baidu_tts_t *tts = (baidu_tts_t *)msg->user_data;
// 检查事件ID是否为HTTP_STREAM_PRE_REQUEST
if (msg->event_id == HTTP_STREAM_PRE_REQUEST) {
// Post text data
ESP_LOGI(TAG, "[ + ] HTTP client HTTP_STREAM_PRE_REQUEST, lenght=%d", msg->buffer_len);
// 使用snprintf函数将TTS请求的参数格式化并存储到tts->buffer中
// 参数包括语言、设备ID、内容类型、音量、发音人、百度访问令牌和待合成的文本
// snprintf返回值是写入的字符数,不包括终止的null字符
int payload_len = snprintf(tts->buffer, tts->buffer_size, "lan=zh&cuid=ESP32&ctp=1&vol=15&per=4&tok=%s&tex=%s", baidu_access_token, tts->text);
// 使用esp_http_client_set_post_field函数设置HTTP客户端的POST请求体
// 参数包括HTTP客户端句柄、请求体内容和请求体长度
esp_http_client_set_post_field(http, tts->buffer, payload_len);
// 使用esp_http_client_set_method函数设置HTTP客户端的请求方法为POST
esp_http_client_set_method(http, HTTP_METHOD_POST);
// 使用esp_http_client_set_header函数设置HTTP客户端的请求头
// 第一个参数是HTTP客户端句柄,第二个参数是请求头的名称,第三个参数是请求头的值
// 设置Content-Type为application/x-www-form-urlencoded,表示请求体是URL编码的表单数据
esp_http_client_set_header(http, "Content-Type", "application/x-www-form-urlencoded");
// 设置Accept为*/*,表示客户端接受任何类型的响应数据
esp_http_client_set_header(http, "Accept", "*/*");
return ESP_OK;
}
return ESP_OK;
}
baidu_tts_handle_t baidu_tts_init(baidu_tts_config_t *config)
{
// 管道设置
audio_pipeline_cfg_t pipeline_cfg = DEFAULT_AUDIO_PIPELINE_CONFIG();
// 分配内存用于baidu_tts_t结构体
baidu_tts_t *tts = calloc(1, sizeof(baidu_tts_t));
// 检查内存分配是否成功,如果失败则返回NULL
AUDIO_MEM_CHECK(TAG, tts, return NULL);
// 初始化音频管道
tts->pipeline = audio_pipeline_init(&pipeline_cfg);
// 设置缓冲区大小
tts->buffer_size = config->buffer_size;
// 如果配置的缓冲区大小小于等于0,则使用默认的缓冲区大小
if (tts->buffer_size <= 0) {
tts->buffer_size = DEFAULT_TTS_BUFFER_SIZE;
}
// 分配缓冲区内存
tts->buffer = malloc(tts->buffer_size);
// 检查内存分配是否成功,如果失败则跳转到exit_tts_init进行清理
AUDIO_MEM_CHECK(TAG, tts->buffer, goto exit_tts_init);
// 设置采样率
tts->sample_rate = config->playback_sample_rate;
// I2S流设置
i2s_stream_cfg_t i2s_cfg = I2S_STREAM_CFG_DEFAULT_WITH_PARA(0, 16000, 16, AUDIO_STREAM_WRITER);
// 设置I2S流为单声道模式
i2s_cfg.std_cfg.slot_cfg.slot_mode = I2S_SLOT_MODE_MONO;
// 设置I2S流为左声道
i2s_cfg.std_cfg.slot_cfg.slot_mask = I2S_STD_SLOT_LEFT;
// 初始化I2S流
tts->i2s_writer = i2s_stream_init(&i2s_cfg);
// http流设置
http_stream_cfg_t http_cfg = {
.type = AUDIO_STREAM_READER, // 设置流类型为读取
.event_handle = _http_stream_reader_event_handle, // 设置事件处理函数
.user_data = tts, // 设置用户数据为tts结构体
.task_stack = BAIDU_TTS_TASK_STACK, // 设置任务堆栈大小
};
// 初始化HTTP流
tts->http_stream_reader = http_stream_init(&http_cfg);
// MP3流设置
mp3_decoder_cfg_t mp3_cfg = DEFAULT_MP3_DECODER_CONFIG();
// 初始化MP3解码器
tts->mp3_decoder = mp3_decoder_init(&mp3_cfg);
// 将HTTP流注册到音频管道
audio_pipeline_register(tts->pipeline, tts->http_stream_reader, "tts_http");
// 将MP3解码器注册到音频管道
audio_pipeline_register(tts->pipeline, tts->mp3_decoder, "tts_mp3");
// 将I2S流注册到音频管道
audio_pipeline_register(tts->pipeline, tts->i2s_writer, "tts_i2s");
// 设置管道中各组件的连接顺序
const char *link_tag[3] = {"tts_http", "tts_mp3", "tts_i2s"};
audio_pipeline_link(tts->pipeline, &link_tag[0], 3);
// I2S流采样率 位数等设置
i2s_stream_set_clk(tts->i2s_writer, config->playback_sample_rate, 16, 1);
return tts;
exit_tts_init:
baidu_tts_destroy(tts);
return NULL;
}
// 定义一个函数,用于销毁百度语音合成(TTS)的句柄
esp_err_t baidu_tts_destroy(baidu_tts_handle_t tts)
{
if (tts == NULL) {
return ESP_FAIL;
}
audio_pipeline_stop(tts->pipeline);
audio_pipeline_wait_for_stop(tts->pipeline);
audio_pipeline_terminate(tts->pipeline);
audio_pipeline_remove_listener(tts->pipeline);
audio_pipeline_deinit(tts->pipeline);
free(tts->buffer);
free(tts);
return ESP_OK;
}
// 函数声明:设置百度语音合成(TTS)的事件监听器
// 参数:
// - tts: 百度语音合成句柄,包含语音合成的相关配置和状态
// - listener: 音频事件接口句柄,用于监听和处理音频事件
// 返回值:esp_err_t 类型,表示函数执行结果,ESP_OK 表示成功
esp_err_t baidu_tts_set_listener(baidu_tts_handle_t tts, audio_event_iface_handle_t listener)
{
// 检查传入的监听器是否为非空
if (listener) {
audio_pipeline_set_listener(tts->pipeline, listener);
}
return ESP_OK;
}
// 函数声明:检查百度语音合成事件是否完成
// 参数:tts - 百度语音合成句柄,msg - 音频事件消息指针
// 返回值:布尔值,表示事件是否完成
bool baidu_tts_check_event_finish(baidu_tts_handle_t tts, audio_event_iface_msg_t *msg)
{
// 检查消息来源类型是否为音频元素类型// 检查消息来源是否为tts句柄中的i2s_writer // 检查消息命令是否为报告状态 // 检查消息数据状态是否为停止或完成
if (msg->source_type == AUDIO_ELEMENT_TYPE_ELEMENT && msg->source == (void *) tts->i2s_writer
&& msg->cmd == AEL_MSG_CMD_REPORT_STATUS
&& (((int)msg->data == AEL_STATUS_STATE_STOPPED) || ((int)msg->data == AEL_STATUS_STATE_FINISHED))) {
return true;
}
// 如果以上条件有任何一个不满足,返回false,表示事件未完成
return false;
}
// 函数声明:baidu_tts_start
// 参数:tts - 指向百度TTS句柄的指针,text - 要转换为语音的文本
// 返回值:esp_err_t - 表示函数执行结果的错误码
esp_err_t baidu_tts_start(baidu_tts_handle_t tts, const char *text)
{
// 释放tts句柄中之前分配的文本内存
free(tts->text);
// 将输入的文本复制到tts句柄中,并分配相应的内存
tts->text = strdup(text);
// 检查内存分配是否成功
if (tts->text == NULL) {
ESP_LOGE(TAG, "Error no mem");
return ESP_ERR_NO_MEM;
}
// 将百度TTS的API端点格式化到tts句柄的缓冲区中
snprintf(tts->buffer, tts->buffer_size, BAIDU_TTS_ENDPOINT);
// 重置音频管道中所有元素的状态
audio_pipeline_reset_items_state(tts->pipeline);
// 重置音频管道中的环形缓冲区
audio_pipeline_reset_ringbuffer(tts->pipeline);
// 设置HTTP流读取元素的URI为tts句柄的缓冲区内容
audio_element_set_uri(tts->http_stream_reader, tts->buffer);
// 运行音频管道,开始处理音频流
audio_pipeline_run(tts->pipeline);
return ESP_OK;
}
// 定义一个函数 baidu_tts_stop,用于停止百度语音合成(TTS)
esp_err_t baidu_tts_stop(baidu_tts_handle_t tts)
{
audio_pipeline_stop(tts->pipeline);
audio_pipeline_wait_for_stop(tts->pipeline);
ESP_LOGD(TAG, "TTS Stopped");
return ESP_OK;
}各API的获取:
VTT and TTS
在百度智能云平台开通语音合成 和语音识别 服务,并绑定到应用中
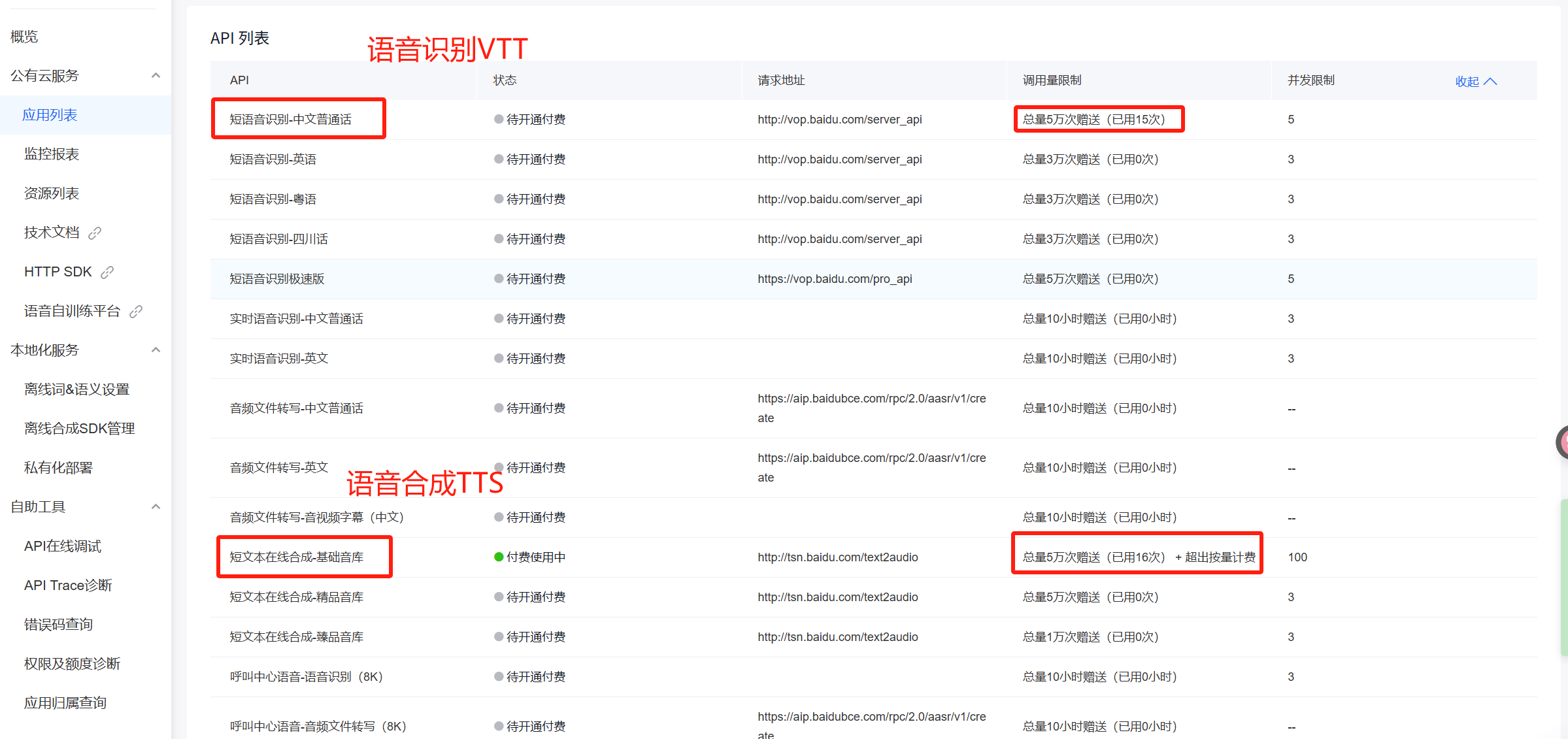
复制key
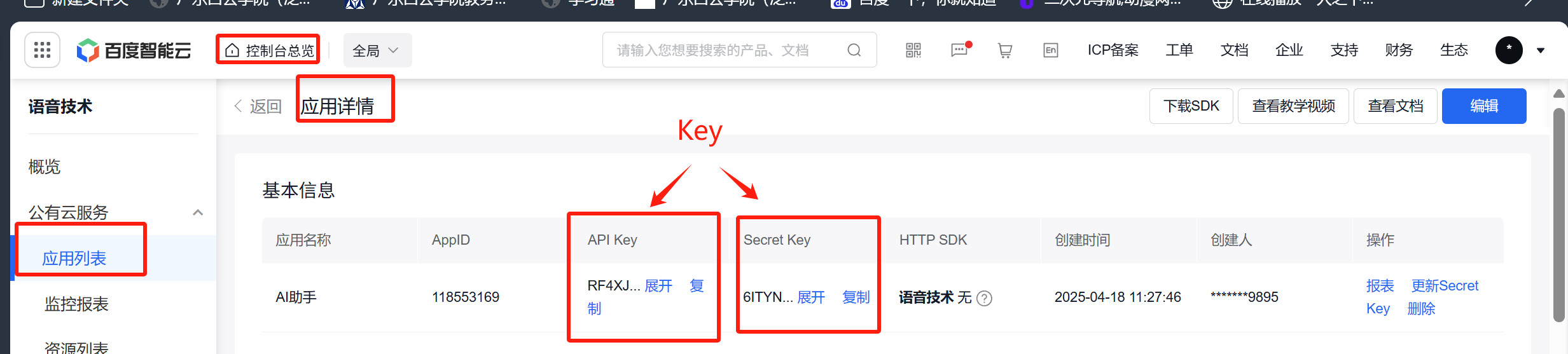
填入main中宏定义

LLM
主要获取groupID,接口密钥
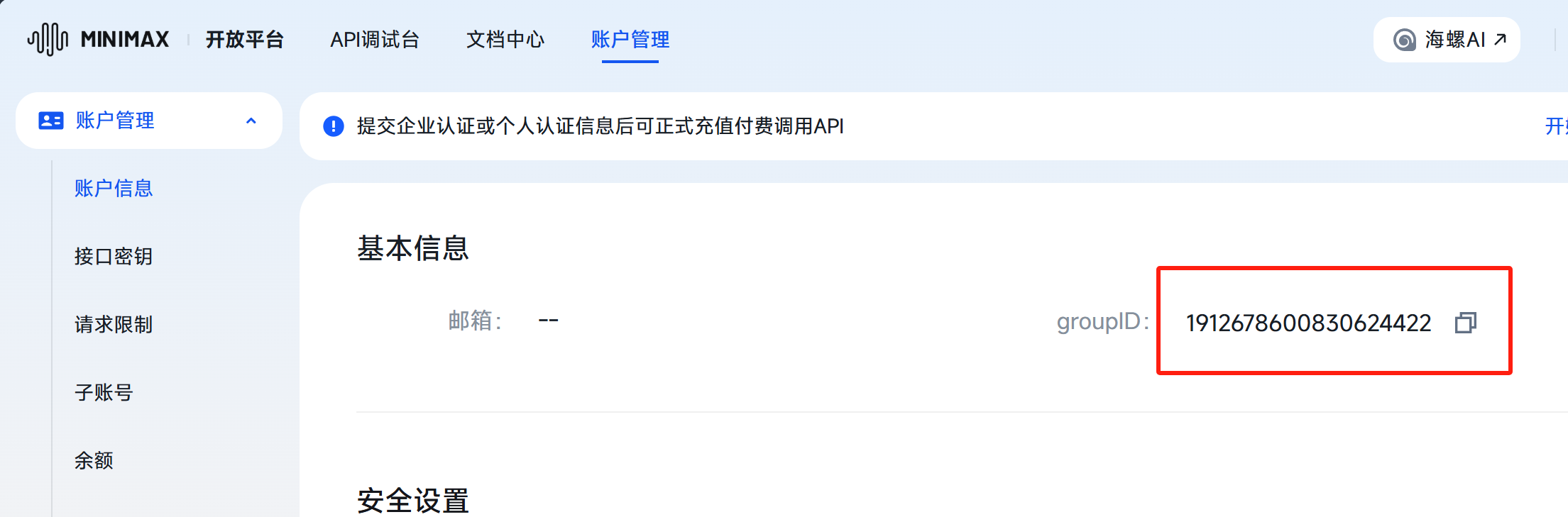
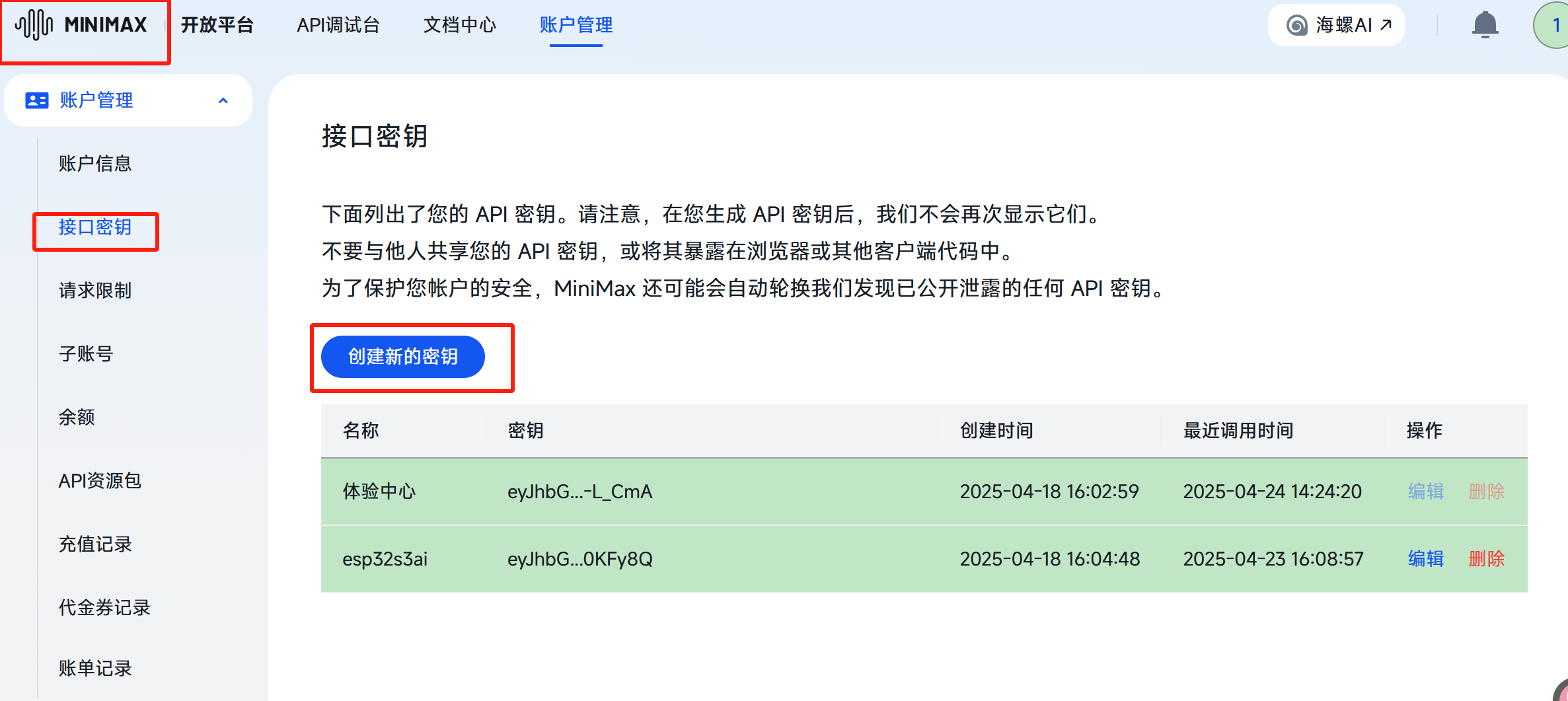
填入main中宏定义