前言
上回作者浅浅尝试了一口本地MCP服务的搭建,并成功运用在AI IDE中,详情在AI assistant本地部署Continue.dev + Ollama + MCP Server。 那么此次好奇这个提供了数据库query工具的MCP服务背后,究竟是用怎样的prompt与LLM交互呢?
动手
Wireshark抓包本地Ollama流量
-
打开Wireshark,选择关注本地
Loopback:lo0
-
过滤Ollama服务端口 Ollama的默认服务端口是11434,可以在Terminal中检查状态:
bash
# Linux/macOS
lsof -i :11434
# Windows
netstat -ano | findstr 11434在Wireshark中过滤http and tcp.port == 11434
-
再次使用AI IDE,发起与AI agent的对话

-
停止抓包,保存capture,分析
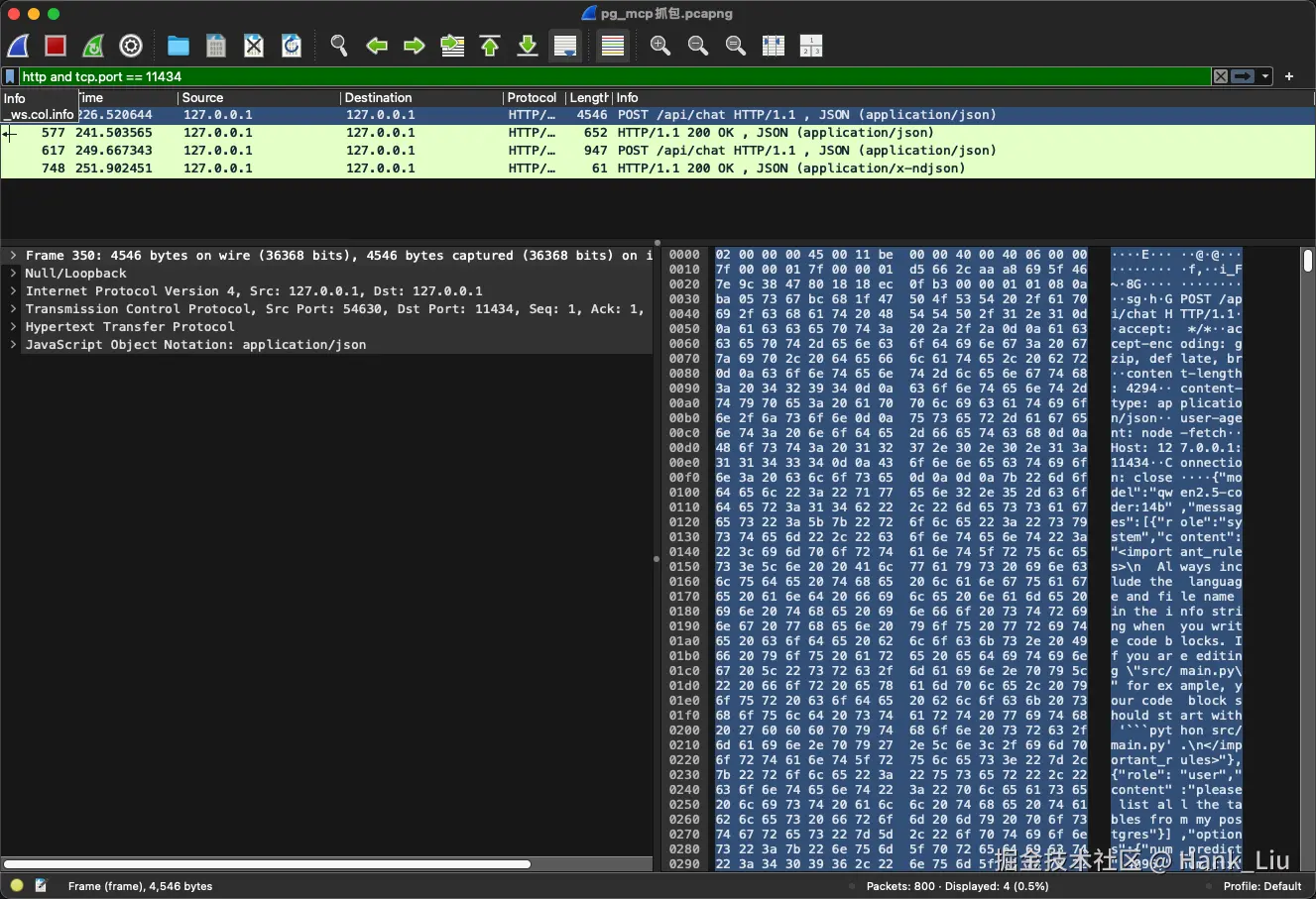
-
重组数据流 a. 右键点击任意一个 HTTP 数据包(如 POST /api/chat)。 b. 选择 Follow > HTTP Stream。



-
分析请求体和返回体 这里我们会看到,Ollama的返回中采用了SSE的流式返回,会有多个json片段。这里可以将这些json片段保存至文件中,再通过
jq快速提取:
bash
cat sse_response.txt | jq -r '.message.content // empty' | tr -d '\n'
总结
分析MCP的tool_call请求体,可以帮助理解MCP背后的运行原理。(但这玩意儿是不是Token消耗的有点多啊?)