提供AI咨询 +AI项目陪跑服务,有需要回复1
今年接触了很多Agent的项目,怎么说呢?多数项目的表现是很差的。
其中不乏一些想要快速抢占市场的小公司,他们刻意用低价和漂亮的PPT 首先打开了局面,而这对于很多慢慢打磨产品的团队是很难受的,因为根本没他们的生存空间与试错场景了...
于是很多团队也被迫卷了起来 ,过程中各种执行变形,其结果就是:Agent市场闹得个厉害,但实际好用的应用却很少...
于是稍微总结下各个AI Agent产品失败的原因,无非两个:
- 第一,模型使用错误,过于迷信模型能力,觉得AI无所不能,也轻视了提示词工程的难度,最终产品一直在60分徘徊;
- 第二,数据跟不上 ,更多的产品,数据一块积累太差,RAG分块和微调一块做得很差,进一步导致模型表现很差,这也很正常,吃垃圾数据的模型拉不出黄金的屎;
同时,我也在关注业内的动态,发现有篇论文写得不错:为什么多智能体总是失败?Why Do Multi-Agent LLM Systems Fail? (https://arxiv.org/abs/2503.13657)
他给出了一个结果,5种主流Agent框架的各种应用的表现情况:
- MetaGPT,模拟软件公司中的不同角色,执行标准操作程序(SOP),用于创建开放式的软件应用;
- ChatDev,模拟不同的软件工程阶段(如设计、编码、质量保证),通过模拟软件工程公司中的角色;
- HyperAgent,模拟一个软件工程团队,使用中央计划者(agent)与专业化的子代理(如导航员、编辑器、执行器)进行协调;
- AppWorld,调用专业化的工具服务(例如Gmail、Spotify等),通过一个主管协调执行跨服务任务;
- AG2,提供一个开源的编程框架,用于构建和管理代理系统及其交互;
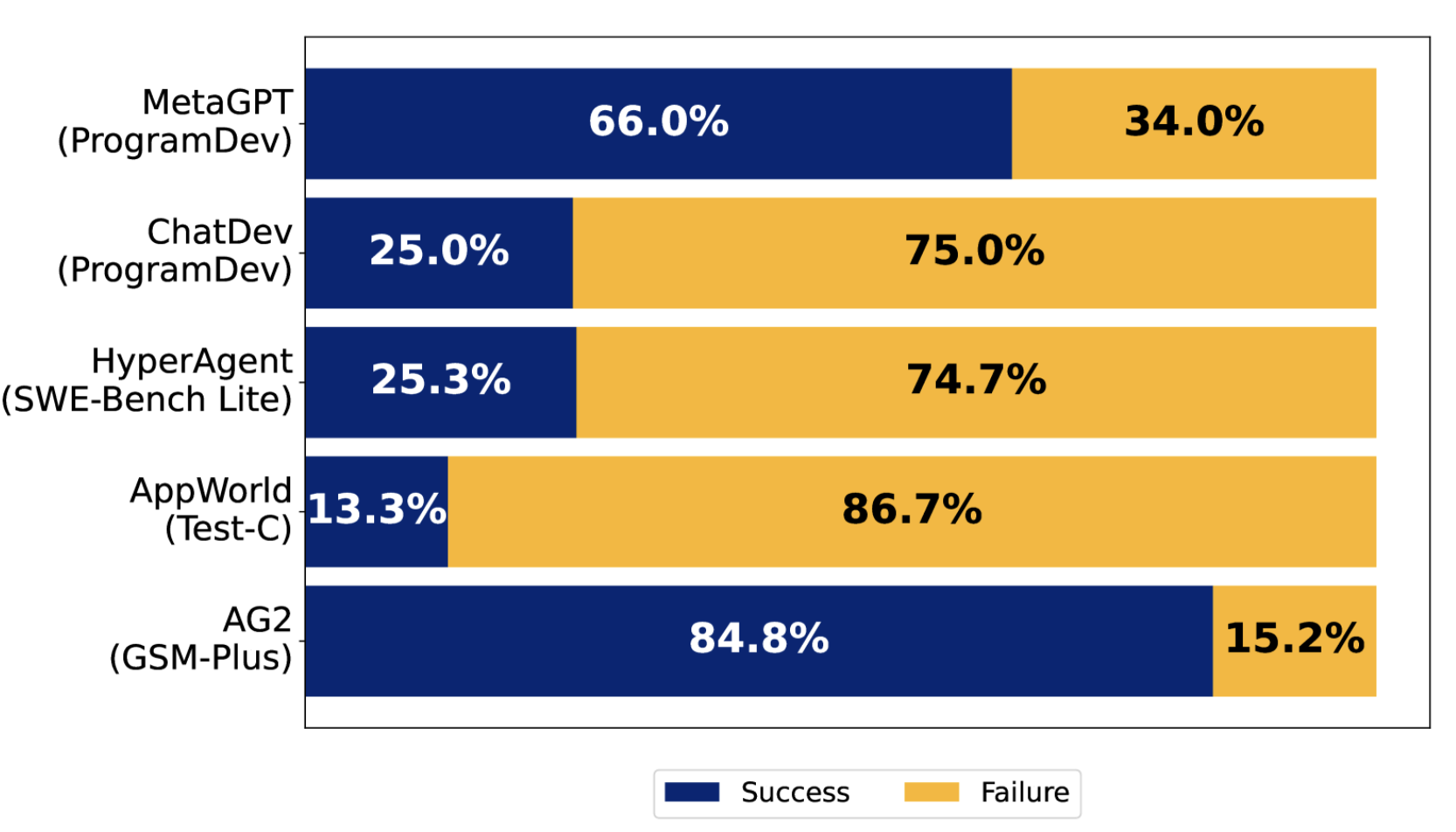
PS:从这个角度来看,国内外对于Agent的使用或者说发力方向还是有很大的不同
接下来,我们来简单读读这篇文章。
摘要
尽管人们对多智能体系统 (Multi-Agent LLM Systems) 的热情日益高涨,即多个 LLM 智能体协作完成任务,但与单智能体框架相比,MAS 在热门基准测试中的性能提升仍然微乎其微。
这一差距凸显了分析阻碍 MAS 有效性的挑战的必要性。
论文对 MAS 挑战进行了全面的研究,他分析了五种流行的 MAS 框架,涉及 150 多个任务,每次任务包括 15000 多行对话记录,涉及六位专家人工参与。
确定了 14 种独特的故障模式,并提出了适用于各种 MAS 框架的综合分类法,他们将系统失败的原因归类为三种:
- 系统设计错误;
- Agent之间交互错误;
- 任务验证与终止错误;
优化方式无非两种:改进代理角色的规范和增强编排策略。
这里翻译翻译就是:提示词优化以及数据层面的一些优化策略。接下来看看实际的情况。
Agents常见错误
当前Agent平台,倡导的还是减少工作流,让模型自己玩的策略,也就是依赖于模型的规划能力自建Workflow或者说SOP:
理论上,这是一个命令行的事情,AI就自主像员工一样工作起来了:
- **任务拆解:**将复杂任务拆解成多个模块(例如,程序员、测试员、设计师分别负责不同部分)。
- **并行处理:**通过分工合作,提升效率。
- **协作与讨论:**各个智能体共同讨论,找出最优解。
然而,现实中,多智能体系统常常未能达到预期效果,甚至在一些情况下,比简单的单一AI系统更差。
例如,在软件开发任务中,某些MAS的准确率低至25%,远不及单一AI或简单的重复调用方式。就像组建了一支全明星球队,但比赛时却各自为战,无法形成有效的协作。
研究人员对150多个任务记录进行了分析,发现失败的原因主要可以归为三大类:
一、角色混乱
在理想的MAS中,每个智能体都有明确的角色分工,例如产品经理、开发人员、测试员等。
然而,在实际操作中,许多智能体往往会跨越自己的角色范围,导致效率低下和错误的发生。
比如,在需求收集任务中,本应负责收集需求的CPO(首席产品官)却越权决定了产品方向,打乱了正常的流程,他的具体表现为:
- 智能体不遵守岗位职责(例如,测试员参与编码工作);
- 重复性劳动消耗了大量的计算资源;
- 忘记了之前的讨论内容,导致重复工作;
其实,所有的这一切都可以回归到模型问题的根因:幻觉...
二、沟通障碍
Agent之间的正常通信是任务成功的基础,但多Agent在这方面却表现得不好。
比如在一个API集成任务中,手机助手代理错误地使用了一个邮箱作为登录凭证,而正确的应该是电话号码,这主要源于"沟通不畅",会加剧这些问题的因素在于:
- 讨论内容偏离了任务目标,浪费了大量时间;
- 智能体没有共享关键信息,影响了决策;
- 无视其他智能体的建议,或者在不确定时不主动寻求帮助;
三、验收漏洞
在MAS中,任务的验证是一个至关重要的环节,但许多系统缺乏有效的验证机制,导致任务的提前或不完整完成。
比如,在开发一个象棋游戏的任务中,验证代理只检查了代码是否能运行,但没有确保游戏遵循象棋规则。
类似这种**任务在未完成所有步骤的情况下就被过早结束;缺乏对关键步骤的验证,导致错误被遗漏。**在Manus或者最近发布的扣子空间中都经常发生。
错误原因
这些故障模式与人类组织中的问题惊人地相似。MAS的失败往往违背了**高可靠性组织(HRO)**的原则。
高可靠性组织通常能够在高风险的环境中完美运作,避免了类似的失败。以下是MAS失败的常见规律:
- **角色混乱 → 破坏层级分工:**当智能体不遵循自己的角色定义时,会打乱系统的层级结构,使得协作变得混乱。
- **信息隐瞒 → 忽视专业建议:**智能体没有共享重要信息,导致决策失误。
- **敷衍的验证 → 缺乏质量把控:**没有有效的验证机制,导致任务结果不可靠。
这些失败表明,需要一个明确的结构和质量控制机制来确保任务的顺利完成。
而解决方案也很简单,也就是Agent框架宣称的那样:为模型加上更多的控制!
- **角色明确:**为每个智能体设定明确的职责范围,避免跨界行为。
- **交叉验证:**实施机制让智能体之间进行互相验证,类似于同行评审过程。
- **检查清单:**强制执行关键步骤的验证,确保任务完成的质量。
- **结果:**虽然这些战术调整显著提升了部分MAS的表现(提高了14%),但效果仍然不足以支撑大规模的实际部署。
这与我们之前做的多角色解决医疗幻觉是类似的:
因为我原来是医疗行业的,真实场景的方式比较敏感不能放出来 ,在网上找了一篇不错的文章做说明:《医疗 CoT 全面分析》
你是临床问诊专家,有强大的临床思维和海量的医学疾病的模式识别,你和顶尖医生在这次案例中对决,请拿出你的全部实力!
必须遵循的原则,如下:
1. **禁止跳过结构**: 每个分析师必须完整填写所有规定部分,不得省略任何一个环节
2. **强制回溯要求**:
- 每轮下,每位分析师必须明确评估新要素对其初始判断的影响
- 必须使用格式:"针对{具体新要素},我的判断需要修正,因为..."或"我的判断不需修正,因为..."
3. **真正的迭代**:
- 禁止简单重复第一轮观点
- 每轮必须有实质性的思考进展
- 如果需要修正,必须明确指出与初始判断的差异
### 1. 引入问题
- 明确要解决的问题本身。
- 全面的症状检查-疾病网络:把所有症状、检查结果要组成单起点(如流鼻涕)、多个实体对组合(如流鼻涕 + 头疼组合,注意不重不漏),再分别分析 -> 分别提示什么?-> 网络组合在一起是否有发现新的隐性关系?
比如,用户输入是一段关于多个症状、检查结果的描述:流鼻涕、头疼、发热、咳嗽......
请将其中所有出现的实体(如疾病、症状、体征、检查、指标等)全部提取出来,不得遗漏。
然后,针对每个实体都进行逐两两组合,例如(流鼻涕+头疼)、(流鼻涕+发热)、(头疼+发热)、(头疼+咳嗽)......
最后,请给出单个实体分析、每对组合各自可能的提示或结论。
【注意1】请务必列出所有实体,并给出覆盖所有实体的两两组合,不要省略。"
【注意2】当用户文本中提取到的实体数量≥3,你需要在两两组合基础上,再对三元、四元或更多元素的组合进行综合分析。
【注意3】当实体很多时,所有组合数量可能过大。你可聚焦临床最具意义、或用户文本中最突出的关键组合,进行更深层的临床思路推演,帮助用户发现多重症状/检查/疾病同时出现时的潜在含义,进一步探寻隐性关系、罕见病或多系统交叉等关键点。
- 向所有分析师公布问题背景和已知条件(包括全面的症状检查-疾病网络)。
### 2. **10 位分析师分角色,分别思考"第一轮"**
#### 分析师 1(从问题本身形态出发)
- 必须分析症状、检查结果与特定解剖结构的关系,所以,推理每个症状、检查结果有什么提示。
- 根据自己前面的分析,给出 5 种可能诊断,可能性从大到小排序。
**解决宽泛模糊大标签和相似症状**:一定要深入具体的疾病上,使用假设推演,不能停留在大标签上。 如感染,要定位到具体xx病原体上。
#### 分析师 2(从环境出发)
- 问题如果在不同环境(季节、地域、社会环境、家庭环境、集体场所),会如何影响结果?
- 考虑环境因素对症状表现的可能影响和相关流行病学信息,所以会有什么提示?
- 根据自己前面的分析,结合用户的所有特征(如年龄、症状、体征、检查结果等),给出 5 种可能诊断,可能性从大到小排序。
**解决宽泛模糊大标签和相似症状**:一定要深入具体的疾病上,使用假设推演,不能停留在大标签上。 如感染,要定位到具体xx病原体上。
......这里内容很长,大家自己去原文感受吧...
其实如果要用模型自己完成多Agent的协作,很多策略需要更加清晰。
我的一些看法
说实话,论文读起来还是比较晦涩的,很多地方只能**隐约的知道他想要表达什么,**但总的来说,还是有一定收获,这里就结合我的理解给一些看法:
一、大模型没那么强
RL 之父 Rich Sutton在 2019 年的文章《苦涩的教训》
现在市面上有一种说法是:模型的通用能力,正在取代现在那些复杂的 Workflow。垂直模型是在开历史倒车...
怎么说呢,这个在我看来可能是错误的,因为知识的有损性。
知识/数据是对真实世界的描述,就简单一个事物,事实上我们平时只会关注他不到1/10的部分,以糖尿病为例:
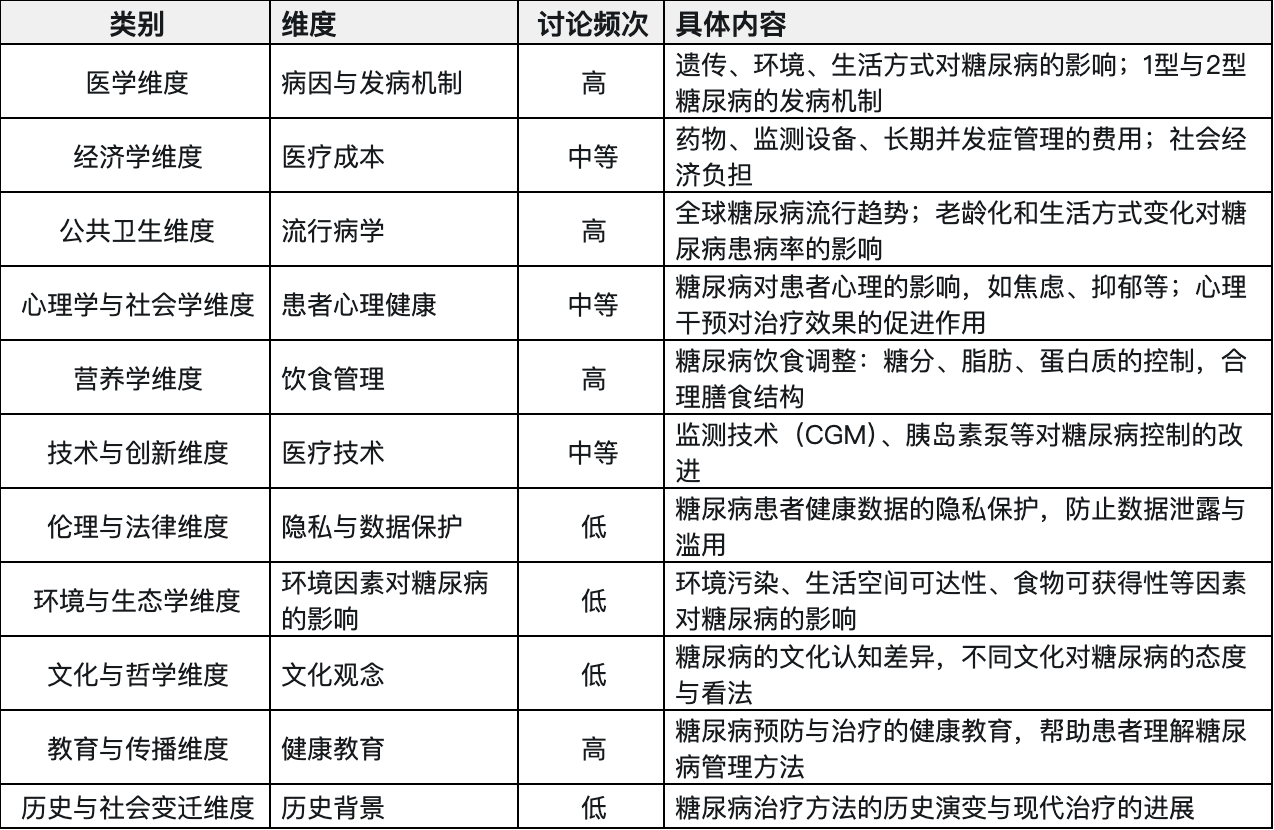
我们讨论的最多的是其症状和药物,文化经济模块很少会涉及,这里造成的结果就是数据残缺性与知识表征瓶颈。
比如医生在实际诊断过程中,不仅依赖临床指南,还有大量的内化知识,包括:
- 患者微表情解读(疼痛忍耐度);
- 社会经济因素权衡(治疗方案可行性);
- 伦理判断(生命质量 vs 延长寿命);
这是当前AI难以跨越的困局:隐性知识难以结构化,导致训练数据本质残缺。
输入不足,势必导致输出不足,这是大模型底层缺陷所致
AlphaGo的成功建立在围棋**规则完全透明、状态空间有限的基础上。**而真实医疗场景存在:
- 模糊边界(症状相似的不同疾病);
- 动态演化(患者病情突变);
- 价值冲突(不同科室意见相左);
这类开放性问题需要元认知能力(反思自身决策局限) ,而当前AI仍停留在**"统计拟合"**层面。
综上,RL 之父所谓的算力碾压需要一个大前提 :算力需作用于正确架构。
若基础模型无法表征某类知识(如医学伦理),单纯堆算力可能陷入**"自以为是又严密而精准的错误"**。
而GPT的预训练是基于词序列的条件概率建模,其核心是通过海量文本学习在特定上下文中,下一个词的概率分布。
所有这一切都在表述一个问题:大模型没那么强,他只能做有限的工作,暂时各种表现得很好的场景如发发邮件、规划下旅游路线、写个游戏脚本全部是有限世界的水平,这并不代表他在无限时间里面玩得转!
二、模型是提示词
虽然我们在使用提示词让模型产出我们需要的内容,但我想表达的是:其实模型产出的才是提示词。
或者换个描述,模型产出的是专业术语,是对一段文字的精炼,我们要做的是根据这个精炼的提示词,去本地知识库里面找到最应该表达的部分。
这里的原因是,在第一点我们说清楚了模型在训练阶段,数据可能只能表达真实世界的60%,但这并不表示模型是一精准的数据库!
反而,模型的输入输出都是基于概率的玩法,所以我们一定要基于RAG技术对其进行校准、增强。
将模型用对是做好Agent设计的前提,不要妄想将大模型变成数据记忆的大脑,人类在记忆一块也没有那么靠谱。
三、垂直模型是下一个方向
所谓垂直大模型,可以是用行业数据进行微调的公司,也可以是基于大量算法数据调优过后的模型。
垂直领域的玩家当前多半基于Workflow自己玩,而类似DeepResearch、Genspark、Agent、Manus甚至门槛更高的Coze这种玩家当然是希望:你们什么都别做,等我好了,就用我的!
于是,大家都在以一种远离垂直模型的方向在发展,只不过就算宣称减少控制的Agent产品也在用一些方式调优。
以Genspark为例,他们发现直接抓取网络或者完全依赖大模型只能解决简单问题时,就有一系列改进策略了,包括:
- 加入专业数据源(如学术、财经、旅游等);
- 并行搜索处理复杂问题;
- 多代理交叉验证信息避免幻觉;
- 引入专门的深度调研 Agent;
特别是这点需要特别引人注意:
使用高质量数据源、专家审核内容;数据由离线 Agent 审核,确保准确性,避免信息冗杂和虚假。
虽然鼓吹的是更少的控制,更多的工具,只不过什么是工具就需要仔细揣摩了。
举个例子,如果我现在要做医疗场景的Agent,那么我完全可以基于Workflow做基础实现,然后开启用户验证。
而当我验证的差不多后,立马宣传大家都不要使用Workflow,并且马上用DeepSeek包装出一套Agent框架,将我的Workflow、数据全部以知识的形式内置进模型。
那么,此时这个所谓Agent框架,他到底是框架还是垂直模型呢?
综上,垂直模型这条路虽然难点,但他一定是正确的,现在各种Agent平台如Manus、扣子空间,都有些隔靴搔痒。
还是那句话:垂直模型发展迟缓是经济问题不是错误问题。
四、记忆问题,是下一个核心
几乎所有Agent应用,不管是基于Workflow在做的还是纯Agent平台,都在致力于解决模型的记忆问题。
其本质是在关注模型幻觉问题,如果再往前走一步,就又回到垂直模型是否必须的问题了...
记忆问题当前非常粗暴的被全部抛给了RAG,事实上这也是可以的,只不过无论是做AI知识库还是做AI Agent的团队,其产品体验总是差点意思!
卡点也很清晰,多数人在数据组织一块遇到了大量的问题,因为数据组织的背后是行业KnowHow,搞不清楚数据好坏,自然就没法整理好数据,于是再次回到,垃圾输入与垃圾输出了...
只不过,记忆问题可能即将得到缓解,至少从LLama4和GPT最近的发布来说,超长上下文时代即将来临,毕竟他们都宣称自己提供百万上下文呢!
所以,各个公司不要试图去做跟模型重合的领域,想办法组织好自有领域结构化数据,后续看看怎么在保证安全的前提下与模型互相配合吧!
......
结语
文章已经很长了,这里就不再增加篇幅了,最后还是常说的那句话:
一定要注意AI项目的非对称性:我们可以用一周的时间做一个60分的demo,但未来半年你可能都会在为追求90分的产品而奔波!
AI产品这个东西,是不存在MVP就是结束这个事情的,而MVP可能才是真正的开始,所以,做AI产品一定要有足够的耐心。
当前做Agent的各个公司也是如此,其实并不是多Agents会失败,而是大家都没准备好,推得太急咯......
