项目场景:
利用python爬取某小说网站,主要爬取小说名字,作者,类别,将其保存为三元组形式:(xxx, xxx, xxx)并将其保存至excel表格中。本文从爬取目的到爬取的各步骤都尽量详细的去复现。
(学习爬虫1个月,python两个月,记录自己的学习过程。只要爬成功一次后,之后就会更得心应手。)
本文中不恰当之处还望指正。
复现过程
1.审查相关数据元素标签:
比如我要爬取的内容都在下图红框标签中:
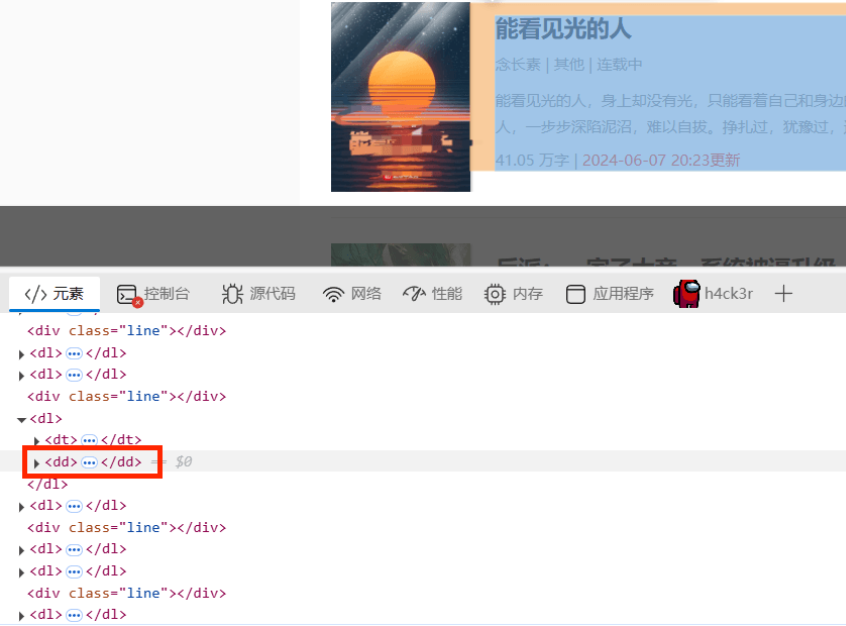
更细分一点呢,我要爬取的是标题,作者和类别,我们发现这三组数据在该页面中都可以找到,就在这个页面中进行爬取吧。接下来寻找数据对应的元素标签。
(打开开发者工具,F12,或在设置里打开也可。找到找个小图标:
点击你想要爬取的内容就可以找到其对应的标签了。)
下面我们来查看一下我们想要爬取的数据的标签吧。
小说名称对应的元素:

作者对应的元素标签:

类别对应的元素标签:

2.下面开始编写代码:
a.导入库:
python3
import requests
from bs4 import BeautifulSoup
import pandas as pdb.这里我就编写一个爬虫类NovelSpider了:
python3
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page这是编写类最基本的内容了,用__init__定义一个类的基本属性。
c.下面我们开始在类中编写一个具体的实现代码了:
python3
def get_novel(self, url: str):
"""获取文章信息的方法"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
novel_list = []
dl_tag = soup.find_all('dl')
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
if title and author and type_:
novel_list.append([title, author, type_])
return novel_list
except Exception as e:
print(f'出现{e}错误!!!')在编写python代码中使用try-except模块几乎是约定俗成的规定:
因为爬虫面临的不确定性很多:比如:网络问题(连接超时、DNS解析失败、SSL错误等),
目标网站变更(HTML结构调整、标签属性变化),反爬机制(IP封禁、验证码、请求频率限制),数据异常(缺失字段、格式不符预期)。
"宁可失败也要明确原因,不要沉默地继续运行错误状态"
try-except块:
python
try:
xxx
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现{e}错误!!!')在编写好最基本的爬虫语句后,着重处理我们想要爬取的特定标签:
我们知道,关于小说的内容都在以下元素中:
html
<dl>
<dt>
<a href="/novel/40814.html" target="_blank">
<img src="/uploads/novel/20240607/16b3a64816abde58e26c2c8313a2dc05.jpg" class="lazyimg" data-original="/uploads/novel/20240607/16b3a64816abde58e26c2c8313a2dc05.jpg" style="display: block;"></a>
</dt>
<dd>
<a href="/novel/40814.html" class="bigpic-book-name" target="_blank">能看见光的人</a>
<p>
<a href="/search/%E5%BF%B5%E9%95%BF%E7%B4%A0.html" target="_blank">念长素</a>
|
<a href="/lists/35.html" target="_blank">其他</a>
| 连载中 </p>
<p class="big-book-info">能看见光的人,身上却没有光,只能看着自己和身边的人,一步步深陷泥沼,难以自拔。挣扎过,犹豫过,逃避过,反抗过,最终抛弃信念,沉默地沉沦在现实的漩涡里。那些有光的人,终究才是世界的中心。也许,怪他不够努力,不够聪明,不够坚定吧...</p>
<p>
<span href="javascript:;" target="_blank">41.05 万字 |</span>
<span class="red">2024-06-07 20:23更新</span>
</p>
</dd>
</dl>我们要遍历网页中的所有dl标签:
python
dl_tag = soup.find_all('dl')*小说名称对应的a标签如下:
<a href="/novel/40814.html" class="bigpic-book-name" target="_blank">能看见光的人</a>
且具有属性:
class="bigpic-book-name"
*小说作者对应的a标签:
<a href="/search/%E5%BF%B5%E9%95%BF%E7%B4%A0.html" target="_blank">念长素</a>
*小说类别对应的a标签:
<a href="/lists/35.html" target="_blank">其他</a>
基于此可编写代码如下:
python3
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
bash
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)1.这行代码的作用是在一个 dl 标签内查找符合特定条件的 a 标签,这个条件是该 a 标签的 href 属性值包含 /search/ 字符串。
2.href=lambda href: href and '/search/' in href:这是一个条件表达式,用于筛选 a 标签。具体来说,它使用了一个匿名函数(lambda 函数)来定义筛选条件。
3.lambda href: href and '/search/' in href 这个匿名函数接受一个参数 href,它代表 a 标签的 href 属性值。
4.href and '/search/' in href 这个条件表达式的含义是:首先检查 href 是否存在(即不为 None),然后检查 '/search/' 是否包含在 href 字符串中。只有当这两个条件都满足时,这个 a 标签才会被选中。
a_type_tag同理。
在循环遍历的每个dl标签中,如果title,author,type都存在的话,就将这三者存储为三元组,并追加到列表中:
python
if title and author and type_:
novel_list.append([title, author, type_])生成的三元组列表如下所示:

d.将三元组列表保存至excel表格中:
python
def save_to_excel(self, data):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print(f"保存成功!!!")e.实现自动翻页:
我们发现:url后面拼接参数?page=xx就可以实现自动翻页,我们需要一个for循环来实现:
python
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print(f"正在保存......")
novel_result = []
for i in range(1, self.page):
base_url = f'{self.url}?page={i}'
novel = self.get_novel(base_url)
novel_result.extend(novel)
self.save_to_excel(novel_result)将拼接好的base_url作为参数传给get_novel()方法就可以爬取每一页了。
f.主程序块
主程序块(if name == 'main ':)是Python脚本的执行入口:
1.脚本自执行:当文件被直接运行时(如 python script.py),块内代码会自动执行
2.模块化隔离:当文件被其他模块导入时,块内代码不会自动运行
在主程序块中传入url和想要翻取的页数:
python
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 3
spider = NovelSpider(url, page)
spider.page_turning()源代码如下:
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
def get_novel(self, url: str):
"""获取文章信息的方法"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
novel_list = []
dl_tag = soup.find_all('dl')
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
if title and author and type_:
novel_list.append([title, author, type_])
return novel_list
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现{e}错误!!!')
def save_to_excel(self, data):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print(f"保存成功!!!")
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print(f"正在保存......")
novel_result = []
for i in range(1, self.page):
base_url = f'{self.url}?page={i}'
novel = self.get_novel(base_url)
novel_result.extend(novel)
self.save_to_excel(novel_result)
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 3 # 想爬多少页可以自己选
spider = NovelSpider(url, page)
spider.page_turning()效果展示:
爬取10页:

优化后的代码:
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_tag_text(tag):
"""辅助函数:获取标签文本,若标签不存在则返回空字符串"""
return tag.text if tag else ""
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
def get_novel(self, url: str) -> list[tuple[str, str, str]]:
try:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
return [
(get_tag_text(dl.find('a', class_="bigpic-book-name")),
get_tag_text(dl.find('a', href=lambda href: href and '/search/' in href)),
get_tag_text(dl.find('a', href=lambda href: href and '/lists/' in href)))
for dl in soup.find_all('dl')
if get_tag_text(dl.find('a', class_="bigpic-book-name"))
and get_tag_text(dl.find('a', href=lambda href: href and '/search/' in href))
and get_tag_text(dl.find('a', href=lambda href: href and '/lists/' in href))
]
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现 {e} 错误!!!')
return []
def save_to_excel(self, data: list[tuple[str, str, str]]):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print("保存成功!!!")
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print("正在保存......")
novel_result = [novel for i in range(1, self.page)
for novel in self.get_novel(f'{self.url}?page={i}')]
self.save_to_excel(novel_result)
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 11
spider = NovelSpider(url, page)
spider.page_turning()优化点说明:
1.辅助函数:定义了 get_tag_text 辅助函数,避免代码中重复出现获取标签文本的逻辑,提高代码复用性。
2.列表推导式: 在 get_novel 方法中,使用列表推导式替代传统的 for 循环,使代码更简洁。 在 page_turning 方法中,同样使用列表推导式来合并各页的小说数据。
3.异常处理细化:在 get_novel 方法中,将 requests 请求异常单独处理,这样能更清晰地定位问题。
4.参数类型提示:为 save_to_excel 方法的参数添加类型提示,增强代码可读性。
5.URL 有效性检查:在 page_turning 方法中添加了对 url 是否有效的检查,避免无效请求。