我毕设做的项目是用C++去实现一个Numpy,因为我是大数据专业,Numpy又是跟数据分析有关的工具,所以我打算自己动手去实现一个小型的Numpy,目前代码规模大概在六千多行左右,并且可以成功移植到OpenEuler RISC-V上面。在这个项目当中,我实现了比较多的数学函数,并且用到了各种高性能有关的技术,如:SIMD,OpenMP,OpenBlas,分别用来做数学运算的加速,向量化循环以及矩阵运算加速,我首先是在x86架构下完成了项目的大部分,后面才移植到了RISC-V上面,目前RISC-V有关的优化只有OpenMP以及OpenBlas,这两者都已经在OpenEuler RISC-V上成功移植并且可以成功运行。至于RVV指令集,目前该操作系统似乎还不太支持,所以如果有时间后面我再另外想办法。
template <typename T>
class ndarray {
private:
std::vector<T> __data;
std::vector<size_t> __shape;
std::vector<size_t> __strides;
size_t __size;
void compute_strides();
size_t calculate_offset(size_t row, size_t col) const noexcept;
...
}项目的数据结构大概如上,__data用于存储实际的数据,不管是一维还是二维的数据,都存在__data里面,至于二维怎么存,可以通过__strides数组结合calculate_offset去映射到一维数组上面;__shape是存储形状的数据结构,如果数组是一维的并且有五个元素,那么__shape就是{5},如果是二乘三的数组,那么__shape就是{2, 3};__size则是存储数组实际元素数量,也就是__data字段的大小。
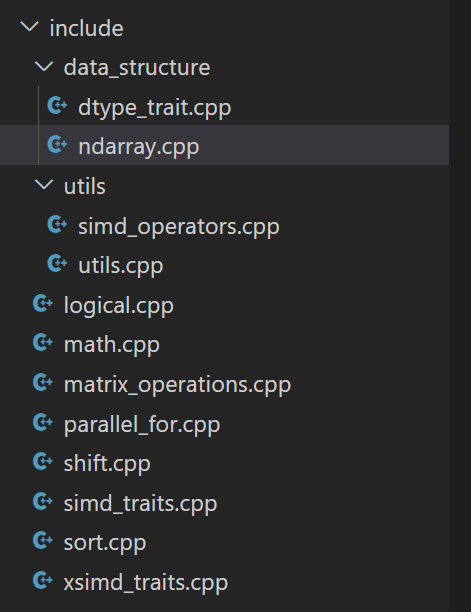
这是项目的结构,logical部分包含了位运算的实现代码,math部分包含了数学函数的实现,shift部分包含了位移的部分,matrix_operations部分包含了矩阵算法的部分,sort是排序部分,parallel_for是向量化for循环的部分。而simd_traits.cpp和xsimd_traits.cpp则负责编译期萃取类型,因为SIMD函数有很多类型,我将它封装成了一个结构体,里面各类型的函数都封装成一个统一接口,这样就能减少很多重复代码。
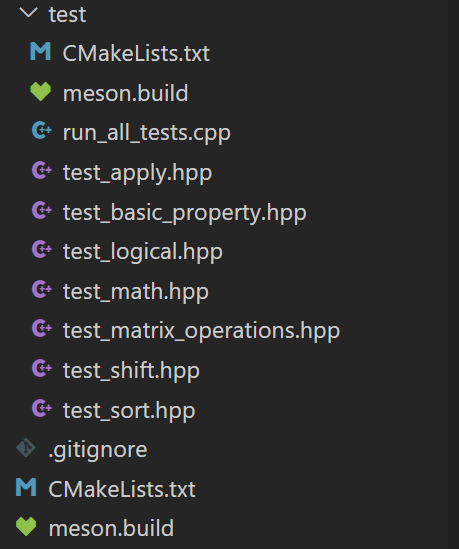
这里则是单元测试部分,我目前使用了GoogleTest对其进行了单元测试,分别对一维数组和二维数组的各种数学函数,并且也有异常相关的测试。该项目提供了CMake和Meson的构建方式,用户可以一键式构建,只需要提前下载gcc、GoogleTest、OpenBlas以及xsimd即可,SIMD指令集以及OpenMP套件一般在GNU工具链里面有。
template <typename T>
std::vector<T> add1(const std::vector<T>& A, const std::vector<T>& B) {
static_assert(std::is_arithmetic_v<T>, "Type must be arithmetic");
static_assert(!std::is_same_v<T, char>);
if (A.size() != B.size()) {
throw std::invalid_argument("Vector dimension mismatch");
}
size_t N = A.size();
std::vector<T> C(N);
if constexpr (std::is_same_v<T, float>) {
cblas_scopy(N, B.data(), 1, C.data(), 1);
cblas_saxpy(N, 1.0, A.data(), 1, C.data(), 1);
} else if constexpr (std::is_same_v<T, double>) {
cblas_dcopy(N, B.data(), 1, C.data(), 1);
cblas_daxpy(N, 1.0, A.data(), 1, C.data(), 1);
} else {
std::vector<float> float_A(N), float_B(N), float_C(N);
for (size_t i = 0; i < N; ++i) {
float_A[i] = static_cast<float>(A[i]);
float_B[i] = static_cast<float>(B[i]);
}
cblas_scopy(N, float_B.data(), 1, float_C.data(), 1);
cblas_saxpy(N, 1.0, float_A.data(), 1, float_C.data(), 1);
for (size_t i = 0; i < N; ++i) {
C[i] = static_cast<T>(float_C[i]);
}
}
return C;
}这里是向量加法部分,因为OpenBlas的函数接口有单精度和双精度类型的,所以我用了编译期条件判断去选择相应的函数实现,对于非浮点数类型,则将其转换为浮点类型再调用Blas的接口(因为Blas实在是快!),但其实这里还有优化的点,后面有时间再想想。
template <typename T>
struct round_simd_traits;
template <>
struct round_simd_traits<float> {
using scalar_type = float;
using simd_type = __m256;
static constexpr size_t step = 8;
static simd_type load(const scalar_type *ptr) noexcept {
return _mm256_loadu_ps(ptr);
}
static void store(scalar_type *ptr, simd_type val) noexcept {
_mm256_storeu_ps(ptr, val);
}
static simd_type op(simd_type a) noexcept {
return _mm256_round_ps(a, _MM_FROUND_TO_NEAREST_INT);
}
};
template <>
struct round_simd_traits<double> {
using scalar_type = double;
using simd_type = __m256d;
static constexpr size_t step = 4;
static simd_type load(const scalar_type *ptr) noexcept {
return _mm256_loadu_pd(ptr);
}
static void store(scalar_type *ptr, simd_type val) noexcept {
_mm256_storeu_pd(ptr, val);
}
static simd_type op(simd_type a) noexcept {
return _mm256_round_pd(a, _MM_FROUND_TO_NEAREST_INT);
}
};这里是SIMD萃取的过程,这样子外部调用的时候就可以直接统一用OP去调用,省去了函数重载的过程。
template <typename T>
std::vector<T> acos1_simd(const std::vector<T>& A) {
if (A.size() < 32)
return apply_unary_op_plain(A, [](const T& a) {
return std::acos(a);
});
#ifdef __riscv
return apply_unary_op_plain(A, [](const T& a) {
return std::acos(a);
});
#endif
#ifdef __AVX2__
return apply_unary_op_simd<T, acos_simd_traits<T>>(A, [](const T& a) {
return std::acos(a);
});
#endif
}这里是math函数部分,对于数据规模较小的,直接调用朴素循环,对于RISC-V架构,目前我的做法也是直接调用朴素循环(还可以优化),如果是支持AVX2的环境,则可以调用SIMD版本的函数。
if(CMAKE_SYSTEM_PROCESSOR MATCHES "x86_64|AMD64|i386|i686")
add_definitions(-mavx2 -fopenmp -O3)
elseif(CMAKE_SYSTEM_PROCESSOR MATCHES "riscv64")
add_definitions(-fopenmp -march=rv64gcv -O3)
endif()像CMake部分,经过我的测试,在O3优化的情况下性能最高,所以我开了O3优化。还有一点区别就是RISC-V需要开V扩展,而x86开-mavx2用来支持AVX2指令集。
name: CI
on:
push:
branches:
- main
pull_request:
branches:
- main
workflow_dispatch:
jobs:
build-and-test:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest]
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Install system dependencies
run: |
if [[ "${{ matrix.os }}" == "ubuntu-latest" ]]; then
sudo apt-get update
sudo apt-get install -y cmake build-essential libopenblas-dev libxsimd-dev libboost-all-dev
elif [[ "${{ matrix.os }}" == "fedora-latest" ]]; then
sudo dnf update -y
sudo dnf install -y cmake make gcc-c++ openblas-devel xsimd-devel boost-devel
fi
- name: Download and install Google Test
run: |
git clone https://github.com/google/googletest.git
cd googletest
mkdir build
cd build
cmake ..
make
sudo make install
- name: Create build directory
run: mkdir -p build
- name: Configure CMake
working-directory: build
run: cmake ..
- name: Build project
working-directory: build
run: make -j$(nproc)
- name: Run tests
working-directory: build/test
run: ./run_all_tests另外项目当中还提供了Ubuntu最新版的CI/CD,也就是Ubuntu 24.04,项目已开源,有时间我会多多commit,欢迎关注~