看到有人需要将扫描pdf文档转markdown,想起之前写的一个小工具。
这个脚本是为了将pdf转成markdown,只需要申请一个智谱的api key,并填到config里,使用的模型是4v flash,免费的,所以可以放心使用。
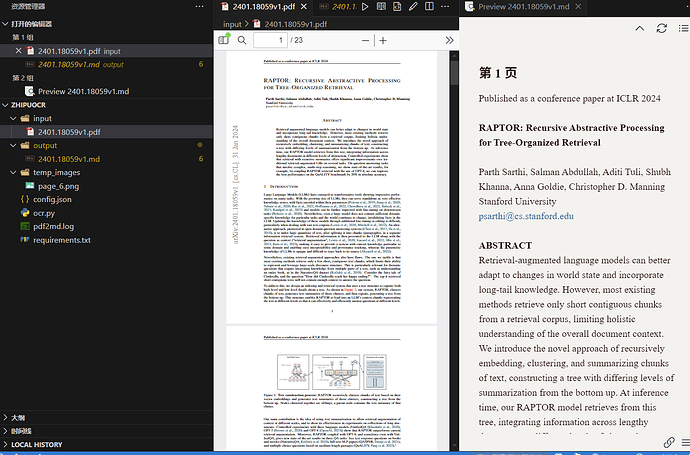
效果如下图:
脚本里的提示词可以根据个人需要进行修改。以下是原始代码:
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
PDF转Markdown自动化系统
功能:监控input/目录下的PDF文件,转换为Markdown格式
作者:您的专属程序员
日期:2025-04-03
版本:2.0.0
"""
import base64
import logging
import time
import json
import os
import fitz # PyMuPDF
from pathlib import Path
from typing import Optional, Dict, Any, List, Generator
from zhipuai import ZhipuAI
from zhipuai.core._errors import ZhipuAIError
# 配置日志系统
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('pdf2md.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class GLM4VTester:
"""GLM-4V 模型测试工具类"""
def __init__(self, api_key: str, model_name: str = "glm-4v-flash"):
self.client = ZhipuAI(api_key=api_key)
self.model_name = model_name
self.total_tokens = 0
self.total_requests = 0
self.total_time = 0.0
def analyze_image(self, image_path: str, prompt: str = "你是一个OCR助手,请把图中内容按原有格式输出出来,如果有公式则输出为LaTeX") -> Dict[str, Any]:
"""
分析图片内容
:param image_path: 图片路径
:param prompt: 提示词
:return: API响应结果
"""
start_time = time.time()
# 读取图片并转为base64
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
# 调用API
response = self.client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}
]}
]
)
# 更新统计信息
elapsed_time = time.time() - start_time
self.total_requests += 1
self.total_time += elapsed_time
if hasattr(response, 'usage') and response.usage:
self.total_tokens += response.usage.total_tokens
logger.info(f"API请求完成,耗时: {elapsed_time:.2f}秒")
return {"response": response, "time": elapsed_time}
def generate_markdown_report(self, image_path: str, result: Dict[str, Any], output_path: str) -> str:
"""
生成Markdown格式的分析报告
:param image_path: 原始图片路径
:param result: API响应结果
:param output_path: 输出文件路径
:return: 生成的Markdown内容
"""
response = result["response"]
elapsed_time = result["time"]
# 提取文本内容
content = response.choices[0].message.content
# 生成Markdown
markdown = f"""# 图像分析报告
## 原始图像
})
## 分析结果
{content}
## 统计信息
- 处理时间: {elapsed_time:.2f}秒
- 总请求数: {self.total_requests}
- 总Token数: {self.total_tokens}
- 平均响应时间: {self.total_time/self.total_requests:.2f}秒
"""
# 保存到文件
with open(output_path, 'w', encoding='utf-8') as f:
f.write(markdown)
return markdown
class ProcessingConfig:
"""PDF处理配置类"""
def __init__(self, config_dict: Dict[str, Any]):
self.api_key = config_dict.get("api_key", "")
self.input_dir = config_dict.get("input_dir", "input")
self.output_dir = config_dict.get("output_dir", "output")
self.model = config_dict.get("model", "glm-4v-flash")
self.dpi = config_dict.get("dpi", 600)
self.api_interval = config_dict.get("api_interval", 3.0)
self.max_retries = config_dict.get("max_retries", 3)
self.retry_backoff = config_dict.get("retry_backoff", 0.5)
self.prompt = config_dict.get("prompt", "你是一个OCR助手,请把图中内容按原有格式输出出来,不要翻译,如果有公式则输出为LaTeX,图片忽略不管")
class PDFProcessor:
"""PDF处理核心类"""
def __init__(self, config: ProcessingConfig, ocr_engine: GLM4VTester):
"""
初始化PDF处理器
:param config: 处理配置
:param ocr_engine: OCR引擎实例
"""
self.config = config
self.ocr_engine = ocr_engine
self.temp_dir = "temp_images"
os.makedirs(self.temp_dir, exist_ok=True)
def _convert_page_to_image(self, page, page_num: int) -> str:
"""
将PDF页面转换为图片
:param page: PyMuPDF页面对象
:param page_num: 页码
:return: 图片文件路径
"""
pix = page.get_pixmap(dpi=self.config.dpi)
img_path = os.path.join(self.temp_dir, f"page_{page_num}.png")
pix.save(img_path)
return img_path
def _safe_api_call(self, image_path: str) -> str:
"""
安全的API调用方法,包含重试机制
:param image_path: 图片路径
:return: OCR结果文本
"""
retries = 0
while retries <= self.config.max_retries:
try:
time.sleep(self.config.api_interval + (retries * self.config.retry_backoff))
result = self.ocr_engine.analyze_image(image_path, self.config.prompt)
return result["response"].choices[0].message.content
except ZhipuAIError as e:
logger.warning(f"API调用失败(重试 {retries}/{self.config.max_retries}): {e}")
retries += 1
raise Exception(f"API调用失败,超过最大重试次数 {self.config.max_retries}")
def _format_page(self, content: str, page_num: int) -> str:
"""
格式化单页内容为Markdown
:param content: OCR原始内容
:param page_num: 页码
:return: 格式化后的Markdown
"""
return f"## 第 {page_num} 页\n\n{content}\n\n---\n"
def process_pdf(self, pdf_path: str) -> Generator[str, None, None]:
"""
处理单个PDF文件
:param pdf_path: PDF文件路径
:return: 生成Markdown内容
"""
logger.info(f"开始处理PDF文件: {pdf_path}")
with fitz.open(pdf_path) as doc:
for page_num, page in enumerate(doc, start=1):
try:
# 转换为图片
img_path = self._convert_page_to_image(page, page_num)
# OCR识别
content = self._safe_api_call(img_path)
# 格式化输出
yield self._format_page(content, page_num)
# 清理临时图片
os.remove(img_path)
except Exception as e:
logger.error(f"处理第{page_num}页时出错: {e}")
yield f"## 第 {page_num} 页\n\n[处理错误: {str(e)}]\n\n"
logger.info(f"完成PDF处理: {pdf_path}")
def process_single_image(config: ProcessingConfig, image_path: str, output_path: str):
"""处理单张图片模式"""
try:
tester = GLM4VTester(api_key=config.api_key, model_name=config.model)
logger.info(f"开始分析文件: {image_path}")
result = tester.analyze_image(image_path, config.prompt)
markdown = tester.generate_markdown_report(image_path, result, output_path)
print(f"\n分析完成! 结果已保存到: {output_path}\n")
return True
except Exception as e:
logger.error(f"文件处理失败: {e}")
return False
def process_pdf_file(config: ProcessingConfig, pdf_path: str, output_path: str):
"""处理PDF文件模式"""
try:
tester = GLM4VTester(api_key=config.api_key, model_name=config.model)
processor = PDFProcessor(config, tester)
with open(output_path, 'w', encoding='utf-8') as f:
for page_content in processor.process_pdf(pdf_path):
f.write(page_content)
logger.info(f"PDF转换完成! 结果已保存到: {output_path}")
return True
except Exception as e:
logger.error(f"PDF处理失败: {e}")
return False
def batch_process_pdfs(config: ProcessingConfig):
"""批量处理input/目录下的PDF文件"""
tester = GLM4VTester(api_key=config.api_key, model_name=config.model)
processor = PDFProcessor(config, tester)
input_dir = config.input_dir
output_dir = config.output_dir
os.makedirs(input_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
processed_files = set()
if os.path.exists("processed.log"):
with open("processed.log", "r") as f:
processed_files = set(f.read().splitlines())
while True:
try:
for filename in os.listdir(input_dir):
if filename.lower().endswith('.pdf') and filename not in processed_files:
pdf_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, f"{os.path.splitext(filename)[0]}.md")
logger.info(f"开始处理: {filename}")
with open(output_path, 'w', encoding='utf-8') as f:
for page_content in processor.process_pdf(pdf_path):
f.write(page_content)
# 记录已处理文件
with open("processed.log", "a") as f:
f.write(f"{filename}\n")
processed_files.add(filename)
logger.info(f"处理完成: {filename} -> {output_path}")
time.sleep(10) # 每10秒检查一次新文件
except KeyboardInterrupt:
logger.info("收到中断信号,停止处理")
break
except Exception as e:
logger.error(f"批量处理出错: {e}")
time.sleep(30) # 出错后等待30秒再重试
def load_config():
"""加载配置文件"""
config_path = "config.json"
default_config = {
"api_key": "",
"input_dir": "input",
"output_dir": "output",
"model": "glm-4v-flash",
"dpi": 600,
"api_interval": 3.0,
"max_retries": 3,
"retry_backoff": 0.5,
"prompt": "你是一个OCR助手,请把图中内容按原有格式输出出来,如果有公式则输出为LaTeX,图片请用《》描述"
}
try:
with open(config_path, 'r') as f:
config = json.load(f)
# 合并配置,优先使用配置文件中的值
return {**default_config, **config}
except FileNotFoundError:
logger.warning(f"配置文件 {config_path} 未找到,使用默认配置")
# 创建默认配置文件
with open(config_path, 'w') as f:
json.dump(default_config, f, indent=2)
return default_config
except json.JSONDecodeError as e:
logger.error(f"配置文件格式错误: {e}")
return default_config
def main():
"""主函数"""
config_dict = load_config()
config = ProcessingConfig(config_dict)
# 检查API密钥是否设置
if not config.api_key:
logger.error("API密钥未设置,请在config.json中设置api_key")
exit(1)
# 确保目录存在
os.makedirs(config.input_dir, exist_ok=True)
os.makedirs(config.output_dir, exist_ok=True)
# 直接启动批处理模式
logger.info(f"启动批处理模式,监控目录: {config.input_dir}")
batch_process_pdfs(config)
if __name__ == '__main__':
main()自己修改一下config里面的智谱api key:
json
{
"api_key": "智谱的api_key",
"input_dir": "input",
"output_dir": "output",
"model": "glm-4v-flash",
"dpi": 600,
"api_interval": 3.0,
"max_retries": 3,
"retry_backoff": 0.5
}缺点是由于是ocr,所以无法提取图片,有需要图片的用minerU或者marker,我试了marker,效果还可以的。