日常问题排查-空闲一段时间再请求就超时
前言
最近买了台mac mini用来写博客,但迟迟没有动笔。虽然积累了非常多的素材,但写一篇《解Bug之路》系列的博客实在是太累人了。同时也很久没有那种让我感到兴奋的问题了。但总归不能让这台新买的mac mini成为摆设,于是就写一些平时遇到的小问题吧。
问题现场
问题是喜闻乐见的调用超时。这个问题的显著特征是:
plain
1.流量小的时候容易出现偶发性访问超时,一般是空闲很长时间后的第一笔请求超时。
2.调大超时时间没有任何效果,平常请求在1s内就能返回。但出现这类超时的时候就算调整到1min超时时间依旧会超时。
3.超时后的重试调用一般都会成功。
4.同一时间其它相同调用不会出现问题。
5.在内网调用不会出现这个问题,在非内网调用不管是专线还是互联网都容易出现这个问题。
6.服务端无法搜索到任何日志,仿佛这个超时请求没有出现过。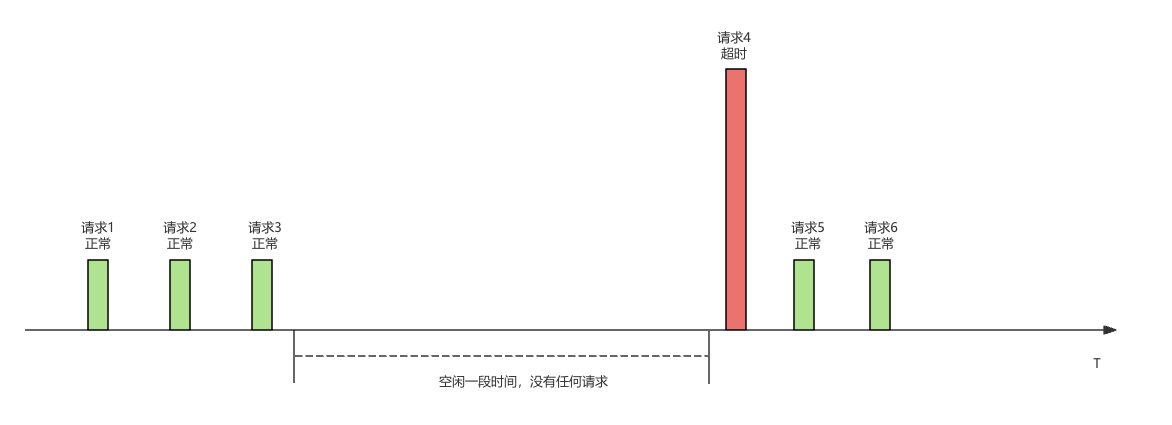
猜想1:服务端关闭了连接
一个非常直观的猜想就是服务端关闭了这个链接,请求直接被拒绝了。但熟悉tcp协议的笔者很快否定了这个猜想,如果连接被关闭了,会有下面图中所示的两种情况:
sequenceDiagram client ->> +server: 请求 server -->> -client: 正常返回 server ->> server: close连接 alt client未收到FIN包 rect rgb(255, 150, 255) client ->> server: tcp packet server -->> client: tcp reset end else client收到FIN包 rect rgb(255, 150, 255) client ->> client: socket has already closed end end
第一种情况,client端没有收到服务端返回的FIN包,那么在请求发送后应该是直接被对端Reset,立刻感知到报错。
第二种情况,client端收到了服务端返回的FIN包,那么在请求发送前会直接报socket has already closed,立刻感知到报错。
根据上面的判断,无论什么情况都是立刻返回,而不是等待很长时间之后超时,和特征2不符,于是可以否定由于服务端关闭连接导致。
猜想2:偶发性路由翻动
因为过了非常长的时间才超时,这时候,我们的就可以考虑是在网络层丢包了。那么到底为什么丢包呢?难道是偶发性的路由翻动?这个想法立马被笔者否决了。因为,如果是路由翻动一般会在分钟级别的收敛,而我们观察到在5s超时后的重试都是成功的。而且一旦路由翻动这段时间内所有的请求都应该收到影响,而问题现场其它请求确实正常的。这就和特征3/特征4不符合。
猜想3(真正的原因)
其实这个问题笔者一直遇到,而且解决方案也一直有,但从没有真正的仔细思考过。但最近读《tcpip路由技术》卷二突然灵光一闪,将书中的一些阐述和这个问题莫名的关联想通了其中的关窍。人们由于IPv4地址即将耗尽而不得不开发出NAT技术,而NAT毕竟只是个补丁,其无法完整的融合进TCP导致出现种种因为这个补丁而出现的问题。我们通过NAT设备中的转发表项维护内网的ip:port和外网的ip:port之间的映射,入下图所示:
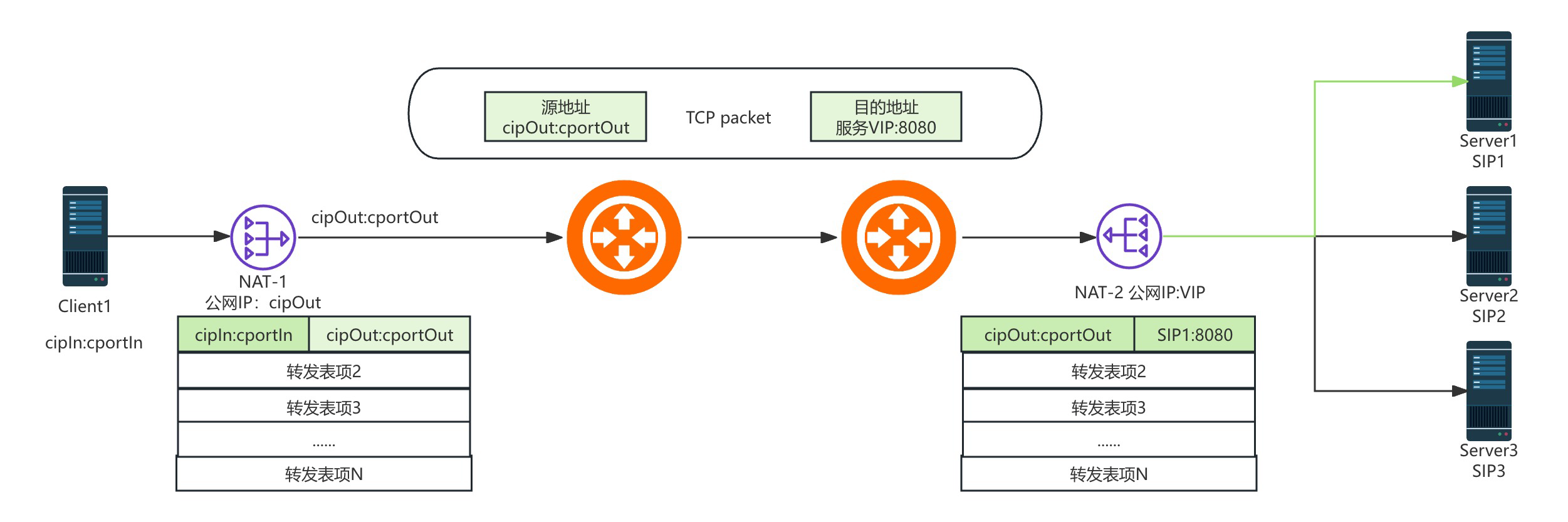
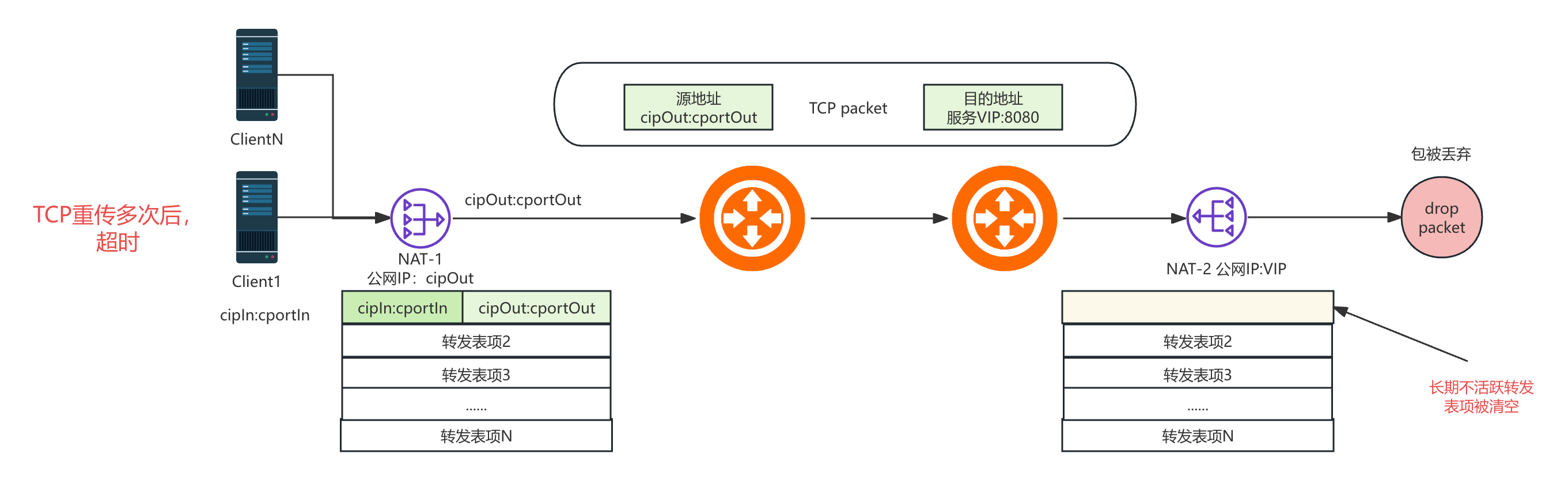
很明显的,由于client和server的数量是非常多的(因为多个服务可能公用一个公网IP),所以转发表是一个非常宝贵的资源,一旦转发表满了,就无法创建新的连接路径了。所以,一些长期没有流量需要有一个定时的清理机制腾出转发表以供新的连接创建。如下图所示,在tcp连接estalbish状态后一定时间内没有任何流量,NAT会直接清空这个转发表项,而client和server端无法感知到这一点,于是client端只好在多次NAT重传后超时。这个和Bug现场的各种特征完全一致。当然无论是NAT-1和NAT-2都有可能清理转发表,只要有一个过期那么这个连接就会出现超时。
使用LVS做NAT的默认超时时间
那么我们看一下我们最常用的使用LVS做NAT的默认超时时间是多少,让我们来番一下LVS源代码:
static const int tcp_timeouts[IP_VS_TCP_S_LAST+1] = {
[IP_VS_TCP_S_NONE] = 2*HZ,
[IP_VS_TCP_S_ESTABLISHED] = 15*60*HZ, // 这边设定了ESTABLISHED状态的超时时间为15min
[IP_VS_TCP_S_SYN_SENT] = 2*60*HZ,
[IP_VS_TCP_S_SYN_RECV] = 1*60*HZ,
[IP_VS_TCP_S_FIN_WAIT] = 2*60*HZ,
[IP_VS_TCP_S_TIME_WAIT] = 2*60*HZ,
[IP_VS_TCP_S_CLOSE] = 10*HZ,
[IP_VS_TCP_S_CLOSE_WAIT] = 60*HZ,
[IP_VS_TCP_S_LAST_ACK] = 30*HZ,
[IP_VS_TCP_S_LISTEN] = 2*60*HZ,
[IP_VS_TCP_S_SYNACK] = 120*HZ,
[IP_VS_TCP_S_LAST] = 2*HZ,
};
struct ip_vs_conn *ip_vs_conn_new(......)
{
......
timer_setup(&cp->timer, ip_vs_conn_expire, 0); // 在初始化连接的时候设置超时函数ip_vs_conn_expire
......
}
static void ip_vs_conn_expire(struct timer_list *t){
......
if (likely(ip_vs_conn_unlink(cp))) { // 在这里清理转发表
......
}
......
}
static inline void set_tcp_state(......)
{
......
// 通过状态在tcp_timeout表中找到相应的超时时间并设置进timeout
cp->timeout = pd->timeout_table[cp->state = new_state];
......
}从上面代码中我们可以看到,LVS通过设置的timeout_table来设置转发表项超时时间,而不同的tcp状态会有不同的超时时间,而默认的established的超时时间是15 * 60 * HZ也就是15min。也就是说,在默认不设置的情况下,15min中之后这个连接就会GG。
解决方案
好了,了解完原理之后,我们就可以有解决方案了。第一种方案,就是使用短连接。也就是每次请求的时候新建一个连接,NAT本身对tcp的FIN包做了处理,一旦发生四次挥手会自动清理表项。用完即回收,即减少了NAT设备转发表的压力也不会产生过一段时间超时的问题。但这个方案有个缺陷,也是短连接的固有缺陷。由于复用不了连接,短时候有海量的请求过来产生大量的短连接,由于TCP 2MSL机制的存在,client即有可能出现端口耗尽。而端口耗尽后会导致Kernel在搜索可用端口号的时候性能急剧劣化(每次搜索端口从数次循环急剧劣化到每次搜多端口都要数万次循环),这会导致client端的机器CPU利用率急剧上升,一直陷在搜索端口号的循环里面导致整体不可用! 如下图所示:
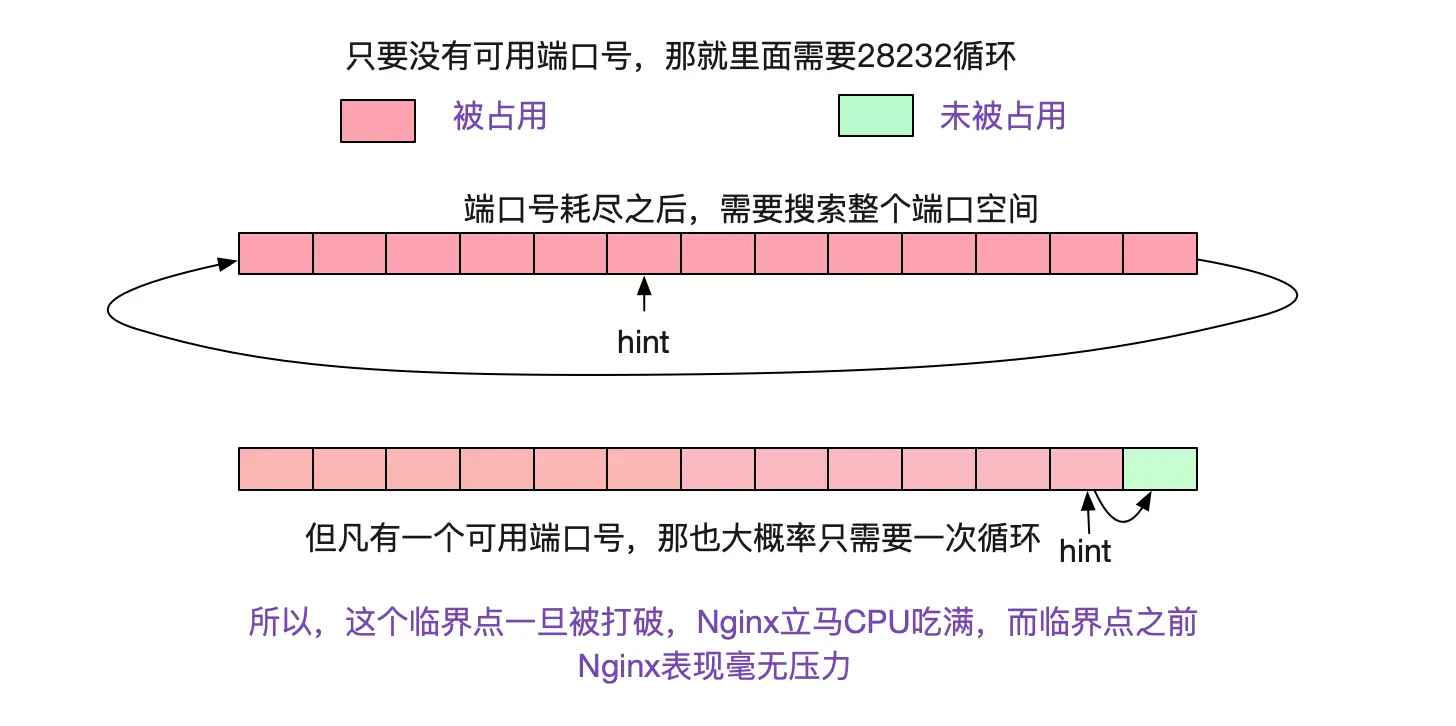
具体分析可以见笔者的另一篇博客: https://my.oschina.net/alchemystar/blog/4436558
为了解决第一种的方案的问题,我们可以依旧复用连接,只不过这个复用时间特别短,例如6s之内复用,超过6s的连接就直接丢弃。这样既能在大量请求涌过来的时候扛住,又能解决长时间不用的超时问题。HttpClient其实提供这个机制,如下所示:
HttpClients.custom().evictIdleConnections(6, TimeUnit.SECONDS)第三种方案,我们可以轮询每一个connection发送心跳包,但这个实现起来比较麻烦,远没有上面的HttpClient内置方案省心。
还有一个需要提到的是Http的Keep-alive,连接的保持时间是在Server端设置的。而这个Keep-alive timeout可能 > NAT的清理时间。对于Client端来说很难约束Server端的配置。所以笔者还是建议采用第二种方案。
总结
NAT虽然大幅度延长了IPV4地址耗尽的时间,但由于只是打了补丁,它的固有缺陷会导致很多问题。不过我们会根据遇到问题的原因给出各种解决的方案,从而让系统稳定的运行。如果具备相应的基础知识,这个问题非常容易解决。但如果没有对整个通信过程有一个大致的理解,会无从着手,所以系统化的学习非常重要。
题外话
解Bug/日常问题排查 系列写了很多了,呈现的一个个复杂的技术点。笔者这几年一直在搞稳定性建设,由点入面,在稳定性方面有了一定的沉淀。所以笔者准备开新坑《高可用之路》系列,敬请期待。
