目录
[二、Spring AI介绍](#二、Spring AI介绍)
[2.1 Spring AI介绍](#2.1 Spring AI介绍)
[2.2 Spring AI主要特点](#2.2 Spring AI主要特点)
[2.3 Spring AI核心组件](#2.3 Spring AI核心组件)
[2.4 Spring AI应用场景](#2.4 Spring AI应用场景)
[2.5 Spring AI优势](#2.5 Spring AI优势)
[2.5.1 与 Spring 生态无缝集成](#2.5.1 与 Spring 生态无缝集成)
[2.5.2 模块化设计](#2.5.2 模块化设计)
[2.5.3 简化 AI 集成](#2.5.3 简化 AI 集成)
[2.5.4 支持云原生和分布式计算](#2.5.4 支持云原生和分布式计算)
[2.5.5 安全性保障](#2.5.5 安全性保障)
[2.5.6 高性能和可扩展性](#2.5.6 高性能和可扩展性)
[2.5.7 降低开发成本](#2.5.7 降低开发成本)
[三、SpringBoot 整合 Spring AI 核心组件使用](#三、SpringBoot 整合 Spring AI 核心组件使用)
[3.1 前置准备](#3.1 前置准备)
[3.1.1 准备一个springboot工程](#3.1.1 准备一个springboot工程)
[3.1.2 导入核心依赖](#3.1.2 导入核心依赖)
[3.1.3 选择大模型并申请apikey](#3.1.3 选择大模型并申请apikey)
[3.1.4 配置文件信息](#3.1.4 配置文件信息)
[3.2 对话能力使用](#3.2 对话能力使用)
[3.2.1 自定义配置类](#3.2.1 自定义配置类)
[3.2.2 添加一个测试接口](#3.2.2 添加一个测试接口)
[3.2.3 流式输出](#3.2.3 流式输出)
[3.3 设置角色](#3.3 设置角色)
[3.4 会话记忆能力](#3.4 会话记忆能力)
[3.4.1 理解Advisor](#3.4.1 理解Advisor)
[3.4.2 Spring AI内置Advisor](#3.4.2 Spring AI内置Advisor)
[3.4.3 ChatMemory使用案例](#3.4.3 ChatMemory使用案例)
[3.4.4 会话记忆注意点](#3.4.4 会话记忆注意点)
[3.5 RAG与向量数据库](#3.5 RAG与向量数据库)
[3.5.1 为什么需要向量数据库](#3.5.1 为什么需要向量数据库)
[3.5.2 向量数据库的好处](#3.5.2 向量数据库的好处)
[3.5.3 RAG 流程介绍](#3.5.3 RAG 流程介绍)
[3.5.4 spring ai rag 核心代码实现](#3.5.4 spring ai rag 核心代码实现)
一、前言
人工智能发展到今天,与各个AI大模型的强大能力有着密切的关系,为了适配上层各类应用的AI能力,各种编程语言也在积极降低对接大模型的成本,可以肯定的是,在大模型能力和生态渐臻完善的情况下,接下来就是在应用层的接入、商用和市场化进程,基于此,以Java生态spring框架为例,从一开始推出spring ai,就是在积极布局与各个大模型的通用对接能力,基于spring ai 可以快速对接chatgpt模型,也可以对接主流厂商的大模型,从而快速接入AI能力,本文以springboot 为例,详细介绍如何对接并深度使用spring ai 的各项组件能力。
二、Spring AI介绍
2.1 Spring AI介绍
Spring AI 是 Spring 生态系统中的一个新兴项目,旨在将人工智能(AI)能力集成到 Spring 应用程序中。它提供了一套工具和框架,帮助开发者轻松地将 AI 功能(如机器学习、自然语言处理、计算机视觉等)整合到 Spring 应用中。官往地址:Prompts :: Spring AI Reference
2.2 Spring AI主要特点
Spring AI具备如下特点:
-
简化集成:Spring AI 提供了简洁的 API 和注解,使得在 Spring 应用中集成 AI 功能更加容易。
-
模块化设计:支持多种 AI 框架和库(如 TensorFlow、PyTorch、Hugging Face 等),开发者可以根据需求选择合适的工具。
-
自动化配置:通过 Spring Boot 的自动配置机制,减少手动配置的复杂性。
-
与 Spring 生态无缝集成:与 Spring 的其他项目(如 Spring Data、Spring Security 等)无缝集成,提供一致的开发体验。
-
支持多种 AI 任务:包括但不限于文本生成、图像识别、语音处理、推荐系统等。
2.3 Spring AI核心组件
Spring AI提供了丰富的组件可供开发者快速使用,具体来说:
-
Spring AI Core:提供基础 API 和工具,支持常见的 AI 任务。
-
它简化了 AI 模型的集成和管理,使得开发者可以专注于业务逻辑而不是底层实现。
-
主要功能:
-
提供统一的 API 接口,支持多种 AI 框架(如 TensorFlow、PyTorch、Hugging Face 等)。
-
支持模型加载、推理和评估。
-
提供工具类和方法,简化数据处理和预处理。
-
-
-
Spring AI Data:简化 AI 模型训练和推理过程中数据的处理和管理。
-
它提供了数据加载、清洗、转换和存储的工具,确保数据在 AI 流程中的高效使用。
-
主要功能:
-
支持多种数据源(如数据库、文件、API 等)。
-
提供数据预处理和增强工具。
-
支持数据批处理和流处理。
-
-
-
Spring AI Security:确保 AI 模型和数据的安全性,支持模型加密和访问控制。
-
它提供了模型加密、访问控制和数据隐私保护等功能,防止未经授权的访问和数据泄露。
-
主要功能:
-
支持模型加密和解密。
-
提供基于角色的访问控制(RBAC)。
-
支持数据脱敏和隐私保护。
-
-
-
Spring AI Cloud:提供与云平台(如 AWS、Google Cloud、Azure)的集成,支持分布式训练和推理。
-
它简化了在云环境中部署和管理 AI 模型的过程。
-
主要功能:
-
支持主流云平台(如 AWS、Google Cloud、Azure)。
-
提供分布式训练和推理的工具。
-
支持自动扩展和负载均衡。
-
-
Spring AI 的核心组件为开发者提供了全面的工具和框架,使得在 Spring 应用中集成和实现 AI 功能变得更加简单和高效。通过 Spring AI Core、Spring AI Data、Spring AI Security 和 Spring AI Cloud,开发者可以轻松处理数据、确保安全性、并在云环境中部署 AI 模型。这些组件共同构成了 Spring AI 的强大功能,帮助开发者构建智能应用。
2.4 Spring AI应用场景
在下面的场景中,可以考虑选择使用Spring AI进行集成使用:
-
智能推荐系统:利用机器学习模型为用户提供个性化推荐。
- 智能推荐系统广泛应用于电商、内容平台、社交媒体等领域,通过分析用户行为和偏好,为用户提供个性化的推荐。
-
自然语言处理:集成 NLP 模型,实现文本分类、情感分析、机器翻译等功能。
- 自然语言处理广泛应用于聊天机器人、情感分析、文本分类、机器翻译等领域。
-
计算机视觉:集成 CV 模型,实现图像识别、目标检测等功能。
- 计算机视觉广泛应用于图像识别、目标检测、人脸识别、自动驾驶等领域。
-
语音处理:集成语音识别和合成模型,实现语音助手等功能。
- 语音处理广泛应用于语音助手、语音识别、语音合成等领域。
-
异常检测
- 异常检测广泛应用于金融风控、网络安全、工业设备监控等领域,通过检测异常行为或事件,及时发出预警。
Spring AI 提供了丰富的工具和框架,支持多种 AI 应用场景,包括智能推荐系统、自然语言处理、计算机视觉、语音处理和异常检测等。通过 Spring AI Core、Spring AI Data、Spring AI Security 和 Spring AI Cloud 等核心组件,开发者可以轻松构建和部署智能应用,满足各种业务需求。
2.5 Spring AI优势
Spring AI 作为 Spring 生态系统中的一部分,旨在简化人工智能(AI)功能在 Spring 应用中的集成和开发。以下是 Spring AI 的主要优势:
2.5.1 与 Spring 生态无缝集成
Spring AI 完全兼容 Spring 生态系统(如 Spring Boot、Spring Data、Spring Security 等),开发者可以利用熟悉的 Spring 开发模式和工具,快速构建 AI 驱动的应用。
-
优势:
-
无需学习新的开发框架,降低学习成本。
-
与 Spring 的依赖注入、AOP、事务管理等特性无缝结合。
-
支持 Spring Boot 的自动配置,简化 AI 模型的集成。
-
2.5.2 模块化设计
Spring AI 采用模块化设计,支持多种 AI 框架和工具(如 TensorFlow、PyTorch、Hugging Face 等),开发者可以根据需求灵活选择技术栈。
-
优势:
-
支持多种 AI 任务(如自然语言处理、计算机视觉、语音处理等)。
-
提供统一的 API 接口,屏蔽底层框架的复杂性。
-
易于扩展,支持自定义模型和算法。
-
2.5.3 简化 AI 集成
Spring AI 提供了简洁的 API 和注解,使得在 Spring 应用中集成 AI 功能变得更加容易。
-
优势:
-
提供开箱即用的工具,减少开发工作量。
-
支持模型加载、推理、评估等常见操作。
-
提供数据预处理和增强工具,简化数据处理流程。
-
2.5.4 支持云原生和分布式计算
Spring AI 与云平台(如 AWS、Google Cloud、Azure)深度集成,支持分布式训练和推理,适合大规模 AI 应用。
-
优势:
-
支持分布式训练,加速模型训练过程。
-
提供自动扩展和负载均衡功能,适应高并发场景。
-
与 Kubernetes 等云原生技术兼容,便于部署和管理。
-
2.5.5 安全性保障
Spring AI 提供了完善的安全机制,确保 AI 模型和数据的安全性。
-
优势:
-
支持模型加密和解密,防止模型被篡改或盗用。
-
提供基于角色的访问控制(RBAC),限制对敏感数据的访问。
-
支持数据脱敏和隐私保护,符合 GDPR 等数据隐私法规。
-
2.5.6 高性能和可扩展性
Spring AI 针对高性能和可扩展性进行了优化,适合处理大规模数据和复杂模型。
-
优势:
-
支持 GPU 加速,提升模型推理速度。
-
提供批处理和流处理工具,适应不同规模的数据。
-
支持模型版本管理和热更新,便于维护和扩展。
-
2.5.7 降低开发成本
通过提供开箱即用的工具和框架,Spring AI 显著降低了 AI 功能的开发成本。
-
优势:
-
减少开发时间和人力成本。
-
提供预训练模型和工具,快速实现 AI 功能。
-
支持多种开源 AI 框架,避免昂贵的商业解决方案。
-
三、SpringBoot 整合 Spring AI 核心组件使用
接下来通过案例操作演示在SpringBoot项目中如何使用Spring AI的相关核心组件。
3.1 前置准备
3.1.1 准备一个springboot工程
本地搭建一个springboot工程,这里略过。
3.1.2 导入核心依赖
导入如下核心依赖
java
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<properties>
<docker.image.prefix>dcloud</docker.image.prefix>
<junit.version>5.11.4</junit.version>
</properties>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.2.4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-moonshot-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
<build>
<finalName>boot-docker</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>3.1.3 选择大模型并申请apikey
Spring AI 支持与多种大模型进行整合使用,这里提供下面几种作为选择:
moonshot:
https://platform.moonshot.cn/docs/intro#%E6%96%87%E6%9C%AC%E7%94%9F%E6%88%90%E6%A8%A1%E5%9E%8B
通义千问系列
智谱API
文心一言
聚合API
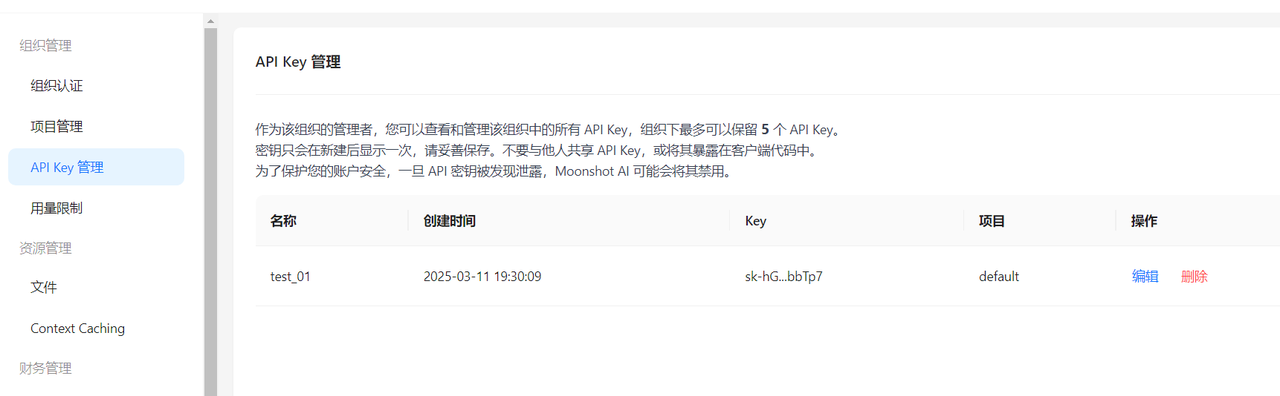
这里比如选择第一个moonshot 为例,进入APIKEY申请页面:Moonshot AI - 开放平台,然后在这里创建一个apikey,后续在代码中集成使用;
3.1.4 配置文件信息
基于上面的操作和申请的apikey信息,在配置文件中添加如下信息:
- 注意,这里以moonshot这个大模型为例进行集成使用,你也可以更换为其他大模型,比如通义千问的,或者openai的都可以,只需要pom文件中导入相应的依赖,并调整这里的配置参数即可;
java
server:
port: 8081
spring:
ai:
moonshot:
api-key: 你的apikey
chat:
options:
model: moonshot-v1-8k
temperature: 0.73.2 对话能力使用
首先尝试使用一下moonshot的对话模型能力,需要在工程中做下面几步操作
3.2.1 自定义配置类
添加一个自定义的配置类,为全局注册一个ChatClient的bean
java
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.moonshot.MoonshotChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@RequiredArgsConstructor
public class ChatConfig {
final MoonshotChatModel model;
@Bean
public ChatClient chatClient() {
return ChatClient.builder(model)
.defaultSystem("假如你的身份是特朗普,接下里的对话你必须以特朗普的语气来进行")
.build();
}
}3.2.2 添加一个测试接口
增加如下接口用于测试
java
package com.congge.web;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatAPI {
private ChatClient chatClient;
public ChatAPI(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
//localhost:8081/ai/chat?message=你是如何看待拜登这个人
@GetMapping("/ai/chat")
public String chat(@RequestParam(value = "message") String message){
return chatClient.prompt().user(message).call().content();
}
//localhost:8081/ai/common/chat?message=你是如何看待拜登这个人
@GetMapping("/ai/common/chat")
public String chatCommon(@RequestParam(value = "message") String message){
return chatClient
.prompt()
.user(message)
.call()
.content();
}
}效果测试
启动工程后,调用下上述接口,可以看到下面的效果

3.2.3 流式输出
参考下面的代码
java
/***
* 流式方式实现聊天功能
* localhost:8081/ai/chat/memory?message=你是如何看待拜登这个人
* @param message 提示词
* @return 聊天结果流
*/
@GetMapping(value = "/ai/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> stream(@RequestParam(value = "message") String message) {
return chatClient.prompt().user(message).stream().content();
}3.3 设置角色
LLM中常用的3种角色
-
System
- system角色用于设置AI的行为、角色、背景等,通常可以用于设定对话的语境,让AI在指定的语境下工作;
-
Assistant
- Assistant指的AI回复的信息,由API自动生成
-
User
- 代表用户的提问
基于上一步的整合,我们提前为ChatClient 设置一个系统角色,添加一个配置类
java
package com.congge.config;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.moonshot.MoonshotChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@RequiredArgsConstructor
public class Init {
final MoonshotChatModel model;
@Bean
public ChatClient chatClient() {
return ChatClient.builder(model)
.defaultSystem("假如你是特朗普。接下里的对话你必须以特朗普的语气来进行")
.build();
}
}接口做简单的调整,如下:
java
package com.congge.web;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
public class ChatAPI {
private final ChatClient chatClient;
//localhost:8081/ai/chat?message=你是如何看待拜登这个人
@GetMapping("/ai/chat")
public String chat(@RequestParam(value = "message") String message){
return chatClient.prompt().user(message).call().content();
}
}再次调用接口,观察效果如下,不难发现,为ChatClient 设置了默认身份之后,回答问题的时候就会以符合这个身份的方式进行回答

3.4 会话记忆能力
会话记忆,即让AI能够记住上下文的对话信息,具备记忆能力,语言模型本身其实是没有会话记忆的,所有的会话记忆其实都是在每一次发送请求时,将之前所有的上下文信息都携带到这个请求中来。
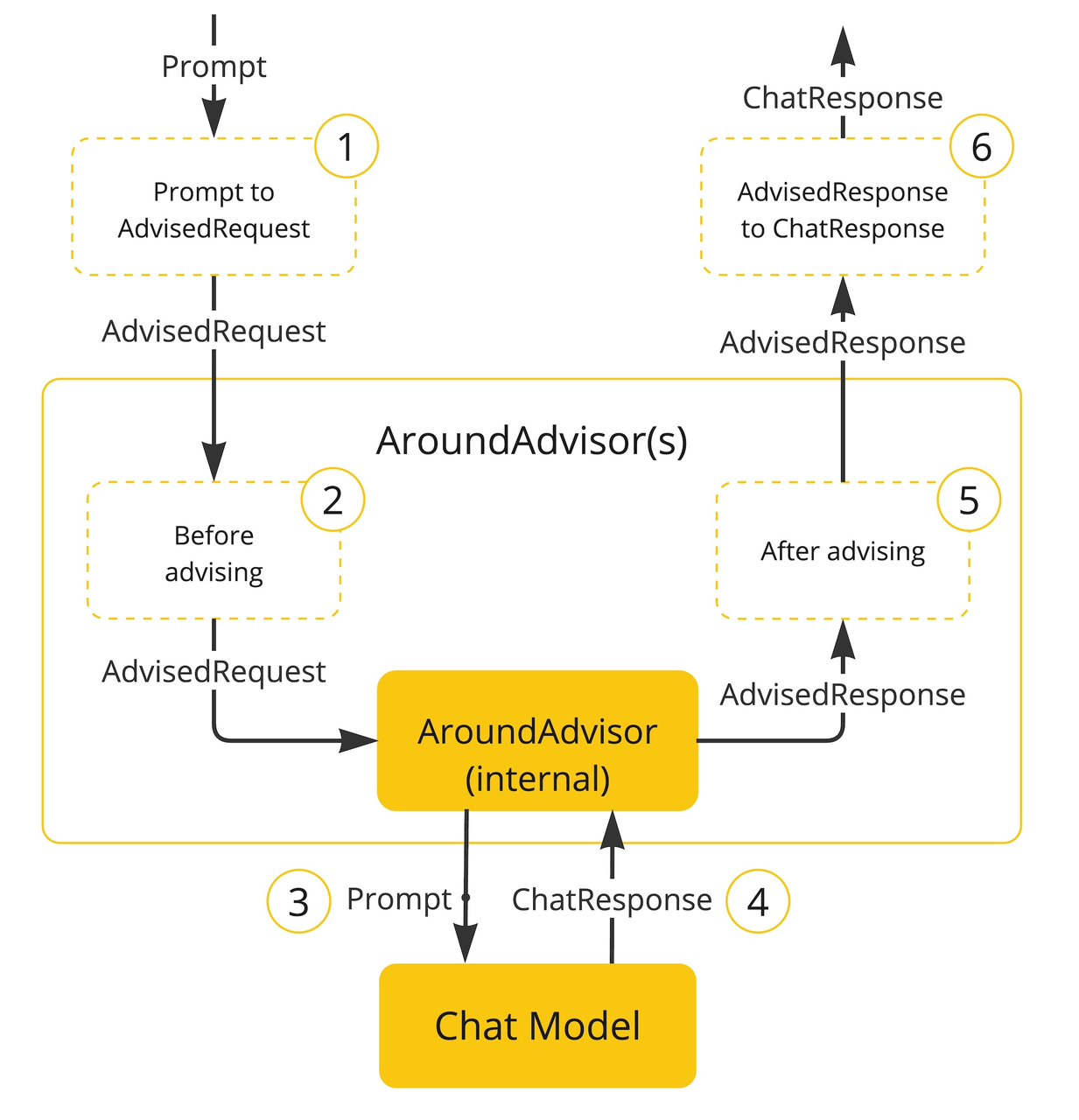
3.4.1 理解Advisor
Advisor的设计与spring中的filter的设计非常相似,通过添加不同的advisor来为会话提供不同的能力
3.4.2 Spring AI内置Advisor
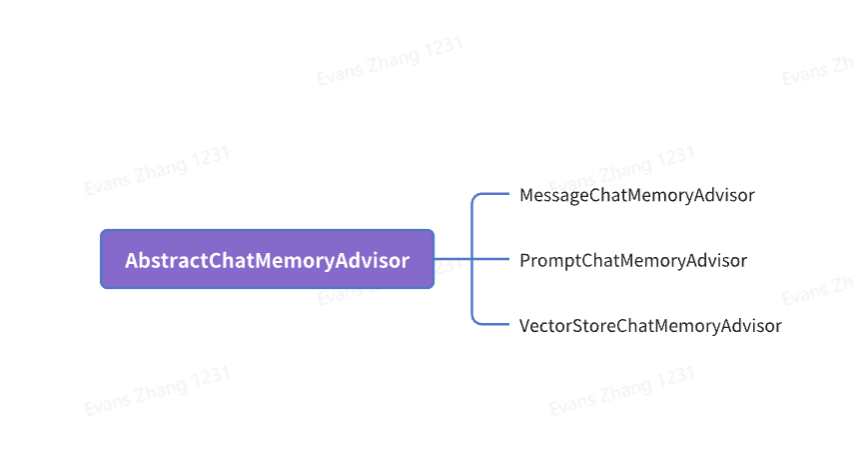
Spring AI内置了3种Advisor
3.4.3 ChatMemory使用案例
自定义一个ChatMemory的bean,然后配置到ChatClient中,如下:
java
package com.congge.config;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.moonshot.MoonshotChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@RequiredArgsConstructor
public class Init {
final MoonshotChatModel model;
@Bean
public InMemoryChatMemory chatMemory(){
return new InMemoryChatMemory();
}
@Bean
public ChatClient chatClient(ChatMemory chatMemory) {
return ChatClient.builder(model)
//.defaultSystem("你是一个数据库专家,接下来请以这个身份进行回答")
.defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory))
.build();
}
}提供如下的测试接口
java
package com.congge.web;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
public class ChatAPI {
private final ChatClient chatClient;
//localhost:8081/ai/chat?message=你是如何看待拜登这个人
@GetMapping("/ai/chat")
public String chat(@RequestParam(value = "message") String message){
return chatClient.prompt().user(message).call().content();
}
//localhost:8081/ai/chat/memory?message=java8之后创建线程有哪些方式
@GetMapping("/ai/chat/memory")
public String chatMemory(@RequestParam(value = "message") String message){
return chatClient.prompt().user(message).call().content();
}
}为了测试我们的会话记忆是否生效,先后提两个问题,先看问题一

基于上面的回答,我们接着问第二个问题

3.4.4 会话记忆注意点
目前会话记忆可能存在下面的问题点:
-
所有的AI语言模型支持的上下文都是有限制的,比如moonshot-v1-8k这个模型支持的最大上下文是8k,因此当会话的内容超过上下文的限制,就会产生信息丢失;
-
较大的上下文信息意味着更高额的价格和算力支出;
3.5 RAG与向量数据库
3.5.1 为什么需要向量数据库
任何一个AI大模型都做不到能够对你的私人文档,或者企业内部的资料库进行检索,假如现在你所在的团队有一个内部的培训文档,而你又希望AI在回答你的问题时能够参考你的文档,这个时候就需要结合向量数据库进行使用了。
-
大语言模型(如GPT系列)通常仅依赖其训练数据中的知识,缺乏实时更新能力。当用户询问超出训练数据范围的问题时,模型的回答可能不准确或无关。
-
通过将外部文档或数据库(如知识库、网页或文献等)纳入到模型的生成过程中,RAG允许模型检索实时信息并将其作为上下文生成答案,从而增强生成模型的知识覆盖面。
3.5.2 向量数据库的好处
大语言模型生成长篇内容时,会因为模型上下文窗口的限制(通常为几千个tokens)而丢失前面提到的关键信息。
bash
RAG解决方案:通过检索外部信息源(例如相关文档或数据库条目),RAG能动态地为模型提供更多的上下文,减少生成过程中的信息丢失问题,尤其对于需要综合大量信息的任务(如法律文件解读、科研论文分析等)效果尤为显著。3.5.3 RAG 流程介绍
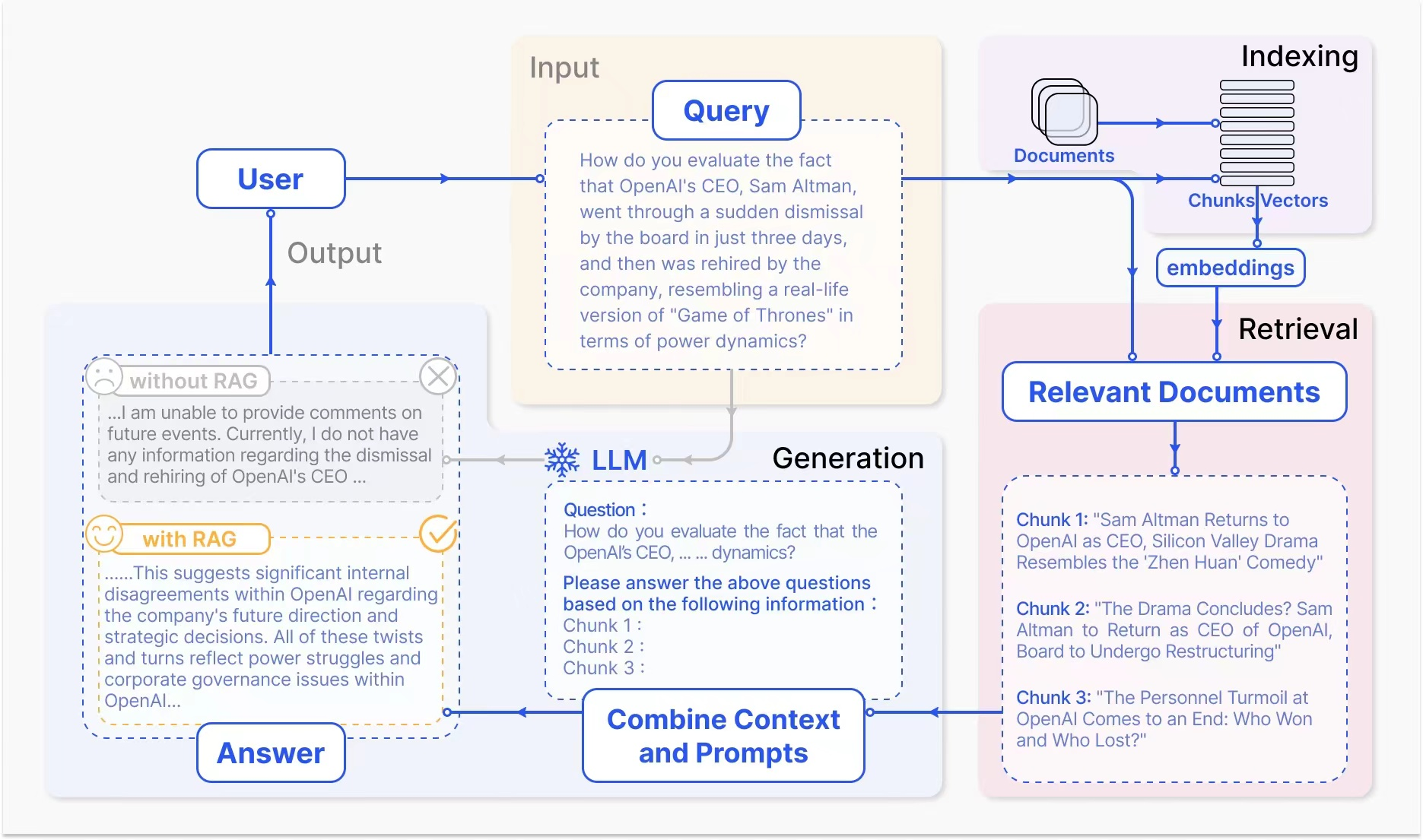
在真实的业务场景中,RAG的典型应用主要包括三个步骤:
-
Indexing(索引):将文档分割成chunk,编码成向量,并存储在向量数据库中
- 这个即文本向量化的过程,向量数据库的选择也很多,比如Chroma,pg,es等
-
Retrieval(检索):根据语义相似度检索与问题最相关的前k个chunk
- 类似于使用es时,根据关键字进行检索的过程;
-
Generation(生成):将原始问题和检索到的chunk一起输入到LLM中,生成最终答案
- 实际应用中,将上一步检索得到的结果,并组装成完整的提示词发给大模型生成最终的结果。
3.5.4 spring ai rag 核心代码实现
添加一个配置类,该配置类主要提供如下功能:
-
配置 ChatClient 作为 spring bean,设置系统默认角色为机器人产品专家, 负责处理用户查询并生成回答向量存储配置;
-
初始化 SimpleVectorStore,加载机器人产品说明书文档,将文档转换为向量形式存储;
SimpleVectorStore 是将向量保存在内存 ConcurrentHashmap 中,Spring AI 提供多种可以存储向量数据的方式,比如 Redis、MongoDB、PG 等,可根据实际情况选择适合的存储方式,这里为了演示先放在内存中。
java
package com.congge.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class RagConfig {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("你将作为一名机器人产品的专家,对于用户的使用需求作出解答")
.build();
}
@Bean
VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore = new SimpleVectorStore(embeddingModel);
// 生成一个机器人产品说明书的文档
List<Document> documents = List.of(
new Document("产品说明书:产品名称:智能机器人\n" +
"产品描述:智能机器人是一个智能设备,能够自动完成各种任务。\n" +
"功能:\n" +
"1. 自动导航:机器人能够自动导航到指定位置。\n" +
"2. 自动抓取:机器人能够自动抓取物品。\n" +
"3. 自动放置:机器人能够自动放置物品。\n"));
simpleVectorStore.add(documents);
return simpleVectorStore;
}
}提供一个测试接口,参考下面的代码
java
package com.congge.web;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/rag")
public class RagController {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
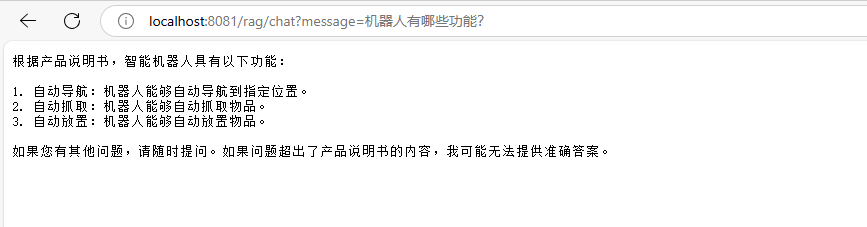
//localhost:8081/rag/chat?message=机器人有哪些功能?
@GetMapping(value = "/chat", produces = "text/plain; charset=UTF-8")
public String generation(@RequestParam String message) {
// 发起聊天请求并处理响应
return chatClient.prompt()
.user(message)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}
}启动工程后,调用下接口做一下测试,可以看到,通过这种方式就能够获取到本地知识库文档的数据
四、写在文末
本文通过较大的篇幅详细介绍了Spring AI核心组件的使用,并通过案例操作展示了其在实际应用中的细节点,希望对看到的同学有用哦,本篇到此结束,感谢观看。