往期推荐:
探秘蓝耘元生代:ComfyUI 工作流创建与网络安全的奇妙羁绊-CSDN博客
工作流 x 深度学习:揭秘蓝耘元生代如何用 ComfyUI 玩转 AI 开发-CSDN博客
目录
[一、初识蓝耘元生代平台与 ComfyUI 工作流](#一、初识蓝耘元生代平台与 ComfyUI 工作流)
[2.1 深入理解 Hypervisor](#2.1 深入理解 Hypervisor)
[2.2 存储虚拟化与网络虚拟化](#2.2 存储虚拟化与网络虚拟化)
作为计算机科学与技术专业的学生,每天不是在敲代码,就是在研究各种新技术。最近在接触蓝耘元生代平台时,我意外发现了一个超有意思的事情 ------ 平台上 ComfyUI 工作流的创建,和服务器虚拟化技术之间,竟然有着千丝万缕的联系!这就像找到了两个看似不相关游戏之间的隐藏关卡,打通之后会解锁超多新技能,今天就来和大家唠唠其中的门道!
一、初识蓝耘元生代平台与 ComfyUI 工作流

第一次听到蓝耘元生代平台,还是在实验室学长的嘴里。当时他说在上面用 ComfyUI 搭建工作流特别方便,就跟搭乐高一样,把不同功能的模块拼在一起,就能实现超复杂的 AI 应用。我一听就来了兴趣,马上跑去注册体验。
打开 ComfyUI 的界面,我直接被那可视化的操作惊呆了。一个个节点就像小方块,有的负责数据读取,有的负责模型训练,还有的能输出结果。我试着搭建了一个简单的图像识别工作流,从拖曳数据输入节点开始,连接到图像预处理节点,再连上训练好的分类模型节点,最后接上输出节点。调整好参数后点击运行,原本杂乱的图片数据,经过这几个节点的「加工」,居然真的能准确识别出图片里的物体!这种成就感,就像自己亲手组装好了一台电脑,看着它顺利开机一样。
但在兴奋之余,我也在想,这么多复杂的工作流同时在平台上运行,背后肯定离不开强大的技术支撑。后来深入研究才发现,服务器虚拟化技术在其中扮演了至关重要的角色。
二、服务器虚拟化:让服务器「七十二变」的神奇魔法
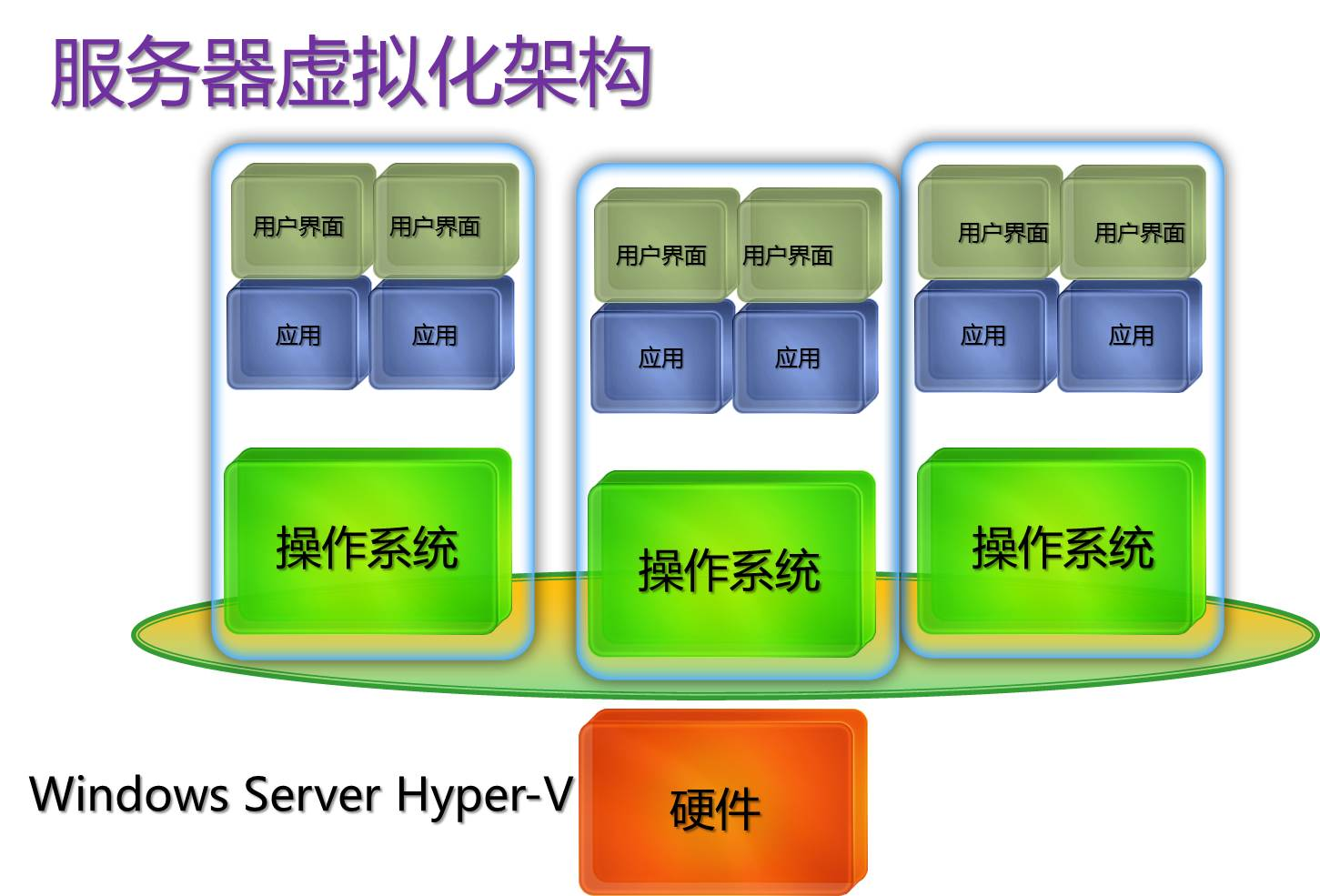
在学习服务器虚拟化之前,我一直以为服务器就像家里的台式电脑,一台机器只能跑一个系统、一套应用。直到上了相关课程,才知道原来服务器也能玩「分身术」!
简单来说,服务器虚拟化就是通过软件技术,把一台物理服务器划分成多个相互隔离的虚拟服务器。每个虚拟服务器都能独立运行自己的操作系统和应用程序,就好像在一台电脑里装了好几个「小电脑」。这就好比一个大房子,原本只能住一户人家,现在通过合理的隔断和改造,能同时住进好几户,而且彼此互不干扰。
实现服务器虚拟化的关键技术有很多,像 Hypervisor(虚拟机监视器)就是其中的核心。它就像一个「大管家」,负责管理和分配物理服务器的资源,比如 CPU、内存、存储和网络带宽等。常见的 Hypervisor 有 VMware ESXi、KVM、Xen 等。以 KVM 为例,它是基于 Linux 内核的虚拟化技术,通过加载kvm.ko内核模块,就能把 Linux 系统变成一个 Hypervisor,从而创建和管理虚拟机。
python
# 检查系统是否支持KVM虚拟化
egrep -o '(vmx|svm)' /proc/cpuinfo
# 安装KVM相关软件包(以Ubuntu为例)
sudo apt update
sudo apt install qemu-kvm libvirt-daemon libvirt-clients bridge-utils virt-manager
# 创建一个基于KVM的虚拟机(示例命令,实际需根据需求调整参数)
virt-install \
--name myvm \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/myvm.qcow2,size=20 \
--os-variant ubuntu20.04 \
--cdrom /path/to/ubuntu-20.04.iso \
--network bridge=virbr0通过这些命令,我们就能在支持 KVM 的系统上创建一个名为
myvm的虚拟机,分配 2GB 内存、2 个 CPU 核心,以及 20GB 的磁盘空间,并通过光盘镜像安装 Ubuntu 20.04 系统。
服务器虚拟化带来的好处可太多了。首先是资源利用率大幅提升,以前一台服务器可能只运行一个应用,大部分资源都闲置浪费了,现在多个虚拟服务器共享物理资源,能让服务器的性能得到充分发挥。其次是灵活性增强,创建和删除虚拟服务器非常方便,就像在电脑上安装和卸载软件一样,能够快速响应业务需求的变化。另外,虚拟化还能提高系统的安全性和可靠性,不同虚拟服务器之间相互隔离,一个虚拟服务器出现问题,不会影响其他服务器的正常运行。
2.1 深入理解 Hypervisor
Hypervisor 有两种类型:Type 1(裸金属型)和 Type 2(托管型)。Type 1 直接运行在物理硬件上,性能更高,像 VMware ESXi 就属于这一类;Type 2 运行在操作系统之上,使用起来更方便,比如 VirtualBox。
以下是一个简单的 Python 脚本,使用libvirt库(适用于 KVM)来管理虚拟机,比如列出所有虚拟机:
python
import libvirt
# 连接到libvirt管理守护进程
conn = libvirt.open('qemu:///system')
if conn is None:
print('Failed to open connection to the hypervisor')
exit(1)
# 获取所有活动虚拟机的ID
active_domains = conn.listDomainsID()
print('Active domains:')
for domain_id in active_domains:
domain = conn.lookupByID(domain_id)
print(f' {domain.name()}')
# 获取所有定义的虚拟机(包括非活动的)
defined_domains = conn.listDefinedDomains()
print('Defined domains:')
for domain_name in defined_domains:
print(f' {domain_name}')
conn.close()2.2 存储虚拟化与网络虚拟化
除了计算资源的虚拟化,服务器虚拟化还包括存储虚拟化和网络虚拟化。存储虚拟化可以将多个物理存储设备整合为一个虚拟存储池,方便管理和分配存储空间。而网络虚拟化则可以在物理网络基础上创建多个虚拟网络,实现不同虚拟机之间的隔离和通信。
以下是一个使用ceph进行存储虚拟化的示例配置文件:
python
[global]
fsid = 5a267c12-4b3d-4c5e-6f7g-8h9i0j
mon_initial_members = ceph-mon1, ceph-mon2, ceph-mon3
mon_host = 192.168.1.101,192.168.1.102,192.168.1.103
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 3
[mon]
mon_data = /var/lib/ceph/mon/ceph-$id
[osd]
osd_data = /var/lib/ceph/osd/ceph-$id
osd_journal = /var/lib/ceph/osd/ceph-$id/journal在网络虚拟化方面,
Open vSwitch是一个常用的开源虚拟交换机,以下是创建一个简单的Open vSwitch网桥的命令:
python
# 安装Open vSwitch
sudo apt install openvswitch-switch
# 创建一个网桥
sudo ovs-vsctl add-br br0
# 添加一个物理网卡到网桥
sudo ovs-vsctl add-port br0 eth0三、蓝耘元生代平台工作流与服务器虚拟化的深度绑定
(一)资源动态分配:让工作流「按需索取」
在蓝耘元生代平台上,用户创建的 ComfyUI 工作流千差万别,有的只是简单的数据处理,有的则需要进行大规模的深度学习模型训练,对计算资源的需求差异巨大。这时候,服务器虚拟化的资源动态分配能力就派上用场了。
平台会根据每个工作流的实际需求,通过 Hypervisor 在物理服务器资源池中划分出相应的虚拟资源。比如一个图像生成工作流,在训练阶段可能需要大量的 GPU 资源来加速计算,Hypervisor 就会为它分配更多的 GPU 核心和显存;而在推理阶段,对 GPU 的需求降低,就可以回收部分资源分配给其他需要的工作流。
python
import libvirt
# 连接到libvirt管理守护进程
conn = libvirt.open('qemu:///system')
# 获取指定虚拟机对象
vm = conn.lookupByName('myvm')
# 动态调整虚拟机的CPU核心数(示例:从2核调整为4核)
new_vcpus = 4
vm.setVcpusFlags(new_vcpus, 0)
# 动态调整虚拟机的内存大小(示例:从2GB调整为4GB,单位为KiB)
new_memory = 4 * 1024 * 1024
vm.setMemory(new_memory)
conn.close()这段 Python 代码利用
libvirt库,连接到虚拟化管理服务,实现了对指定虚拟机(这里以myvm为例)的 CPU 核心数和内存大小的动态调整。在蓝耘元生代平台中,类似的操作可以根据工作流的实时资源需求自动进行,确保资源得到最合理的利用。
(二)隔离与安全:给工作流穿上「防护甲」
前面提到服务器虚拟化能实现虚拟服务器之间的隔离,这对于蓝耘元生代平台上的工作流安全至关重要。每个 ComfyUI 工作流在运行时,都可以被看作是在一个独立的虚拟环境中,它们之间的数据和操作相互隔离,不会出现数据泄露或相互干扰的情况。
想象一下,如果没有这种隔离机制,多个用户的工作流在同一环境下运行,一个恶意用户就有可能通过某些手段获取到其他用户的数据,或者干扰其他工作流的正常运行。而虚拟化技术通过创建独立的虚拟服务器,为每个工作流打造了专属的「安全小屋」。
此外,不同的工作流可能对操作系统和软件环境的要求不同。比如有的工作流依赖 Python 3.8 环境,有的则需要 Python 3.10。通过服务器虚拟化,平台可以为每个工作流创建定制化的虚拟环境,安装相应的操作系统和软件版本,确保工作流能够稳定运行,就像给每个工作流配上了最适合的「装备」。
为了进一步加强安全防护,还可以使用防火墙规则来限制虚拟机之间以及虚拟机与外部网络的通信。以下是一个使用iptables设置简单防火墙规则的示例:
python
# 清空现有规则
sudo iptables -F
# 允许本地回环接口通信
sudo iptables -A INPUT -i lo -j ACCEPT
# 允许已建立和相关的连接
sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
# 允许SSH连接(端口22)
sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT
# 允许HTTP和HTTPS连接(端口80和443)
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 443 -j ACCEPT
# 默认拒绝所有其他输入流量
sudo iptables -A INPUT -j DROP
# 允许所有输出流量
sudo iptables -P OUTPUT ACCEPT(三)快速部署与迁移:工作流的「闪电搬家」
在蓝耘元生代平台上创建工作流时,我们经常会遇到需要快速部署和迁移的情况。比如,一个新的工作流项目需要紧急上线,传统方式下可能要花费大量时间在服务器配置和环境搭建上。但借助服务器虚拟化技术,这一切都变得非常简单。
平台可以提前创建好多个标准化的虚拟服务器模板,这些模板中已经预装了常见的操作系统和开发环境。当用户创建工作流时,只需选择合适的模板,就能在短时间内快速生成一个可用的虚拟环境,大大缩短了部署时间。
python
# 使用virt-clone命令克隆一个已有的虚拟机模板(假设模板名为templatevm)
virt-clone \
--original templatevm \
--name newvm \
--file /var/lib/libvirt/images/newvm.qcow2上面的命令通过
virt-clone工具,基于已有的虚拟机模板templatevm快速克隆出一个新的虚拟机newvm,新虚拟机继承了模板的所有配置和环境,稍作调整就能投入使用。
另外,当物理服务器出现故障,或者需要对服务器进行维护升级时,工作流的迁移就显得尤为重要。利用服务器虚拟化的实时迁移技术,正在运行的工作流可以在不中断服务的情况下,从一台物理服务器迁移到另一台,整个过程对用户几乎无感知,就像给工作流来了一次「闪电搬家」。
以下是一个使用virsh命令进行虚拟机实时迁移的示例:
python
# 假设目标主机为 target_host,虚拟机名为 myvm
virsh migrate --live --persistent --undefinesource myvm qemu+ssh://target_host/system四、实战:在蓝耘元生代平台利用服务器虚拟化优化工作流
登录与注册 :打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
(一)项目需求:搭建一个高并发的文本分类工作流
最近参加一个课程设计项目,需要在蓝耘元生代平台上搭建一个文本分类工作流,用来处理大量用户上传的文本数据。预计在高峰时段,会有上千个用户同时上传文本,对服务器的性能和稳定性要求极高。
(二)基于服务器虚拟化的方案设计
- 资源规划:根据预期的并发量和数据处理需求,通过平台的管理界面,申请多个虚拟服务器。为每个虚拟服务器分配 2 个 CPU 核心、4GB 内存和 50GB 的磁盘空间,同时为部分服务器分配 GPU 资源,用于加速文本分类模型的训练和推理。
- 环境配置:选择适合的虚拟服务器模板,该模板中已经预装了 Python 3.9、TensorFlow 2.8 等开发环境。在每个虚拟服务器中,安装项目所需的文本处理库,如 NLTK、spaCy 等,并配置好数据库连接。
- 负载均衡:利用虚拟化环境中的负载均衡技术,将用户的文本上传请求均匀分配到各个虚拟服务器上。这样可以避免单个服务器负载过高,提高整个工作流的处理能力和响应速度。
(三)代码实现与优化
1.文本分类模型训练代码
python
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from tensorflow.keras.models import Model
# 假设已经预处理好的文本数据和标签
text_data = tf.keras.preprocessing.sequence.pad_sequences(text_data, maxlen=100)
labels = tf.keras.utils.to_categorical(labels, num_classes=num_classes)
input_layer = Input(shape=(100,))
x = Embedding(input_dim=vocab_size, output_dim=128)(input_layer)
x = LSTM(128)(x)
output_layer = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(text_data, labels, epochs=10, batch_size=32)2.负载均衡配置代码(以 Nginx 为例)
python
# Nginx配置文件
upstream text_classification_servers {
server vm1.example.com;
server vm2.example.com;
server vm3.example.com;
least_conn; # 采用最少连接数算法进行负载均衡
}
server {
listen 80;
server_name text-classification.example.com;
location / {
proxy_pass http://text_classification_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}3.数据预处理代码
python
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import re
nltk.download('stopwords')
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
# 转换为小写
text = text.lower()
# 去除特殊字符和数字
text = re.sub(r'[^a-zA-Z]', ' ', text)
# 分词
words = text.split()
# 去除停用词
words = [w for w in words if w not in stop_words]
# 词形还原
words = [lemmatizer.lemmatize(w) for w in words]
# 重新组合成文本
preprocessed_text = ' '.join(words)
return preprocessed_text
# 示例使用
text = "This is an example sentence for text preprocessing!"
preprocessed_text = preprocess_text(text)
print(preprocessed_text)(四)测试与效果
在完成工作流的搭建和配置后,进行了压力测试。模拟了 1000 个用户同时上传文本,结果显示,通过服务器虚拟化技术的资源分配和负载均衡,每个虚拟服务器的负载都保持在合理范围内,工作流能够稳定、高效地处理请求,文本分类的准确率也达到了预期目标。这让我深刻体会到服务器虚拟化对提升工作流性能的巨大作用。
五、蓝耘元生代品牌建设与服务器虚拟化的双向赋能
(一)服务器虚拟化助力品牌竞争力提升
对于蓝耘元生代平台来说,服务器虚拟化技术是提升品牌竞争力的关键。稳定、高效的虚拟化环境能够为用户提供优质的工作流创建和运行体验,吸引更多用户使用平台。
当用户在平台上创建的工作流能够快速部署、稳定运行,并且资源得到合理分配时,他们会对平台产生更高的信任度和满意度。这种良好的口碑会在用户群体中传播开来,吸引更多计算机专业的学生、科研人员和企业开发者加入,从而扩大平台的用户规模,提升品牌知名度。
此外,服务器虚拟化带来的高安全性和可靠性,能够保障用户数据和工作成果的安全,这对于品牌形象的树立至关重要。在当今数据安全备受关注的时代,一个能够提供强大安全保障的平台,无疑更具竞争力。
(二)品牌建设推动服务器虚拟化技术创新
随着蓝耘元生代平台品牌建设的不断推进,用户数量和业务需求也在持续增长。这对服务器虚拟化技术提出了更高的要求,促使平台不断投入资源进行技术创新和优化。
为了满足用户对更复杂工作流的需求,平台可能会探索更先进的虚拟化技术,如容器化技术(Docker、Kubernetes)与传统服务器虚拟化的融合,进一步提高资源利用率和部署效率。以下是一个使用 Docker 创建一个简单 Python Flask 应用容器的示例:
python
# 创建一个简单的Flask应用文件 app.py
cat << EOF > app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
EOF
# 创建Dockerfile
cat << EOF > Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
EOF
# 创建requirements.txt文件
echo "flask" > requirements.txt
# 构建Docker镜像
docker build -t my-flask-app .
# 运行Docker容器
docker run -p 5000:5000 my-flask-app同时,为了提供更好的用户体验,平台会不断优化虚拟化环境的管理和监控功能,实现更智能的资源调度和故障预警。可以使用
Prometheus和Grafana来搭建一个监控系统,以下是一个简单的Prometheus配置文件示例:
python
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'vm_monitoring'
static_configs:
- targets: ['vm1.example.com:9100', 'vm2.example.com:9100']品牌建设还能吸引更多优秀的技术人才和合作伙伴,共同参与服务器虚拟化技术的研发和应用,推动整个领域的技术进步。这种双向赋能的关系,让蓝耘元生代平台和服务器虚拟化技术相互促进,共同发展。
六、结语
通过这段时间对蓝耘元生代平台工作流和服务器虚拟化的研究与实践,我收获了满满的知识和经验。原本以为这两个技术毫无关联,深入了解后才发现它们就像一对默契的搭档,相互协作,共同为用户提供强大而高效的服务。
对于我们计算机专业的学生来说,掌握这些技术不仅是课程学习的要求,更是未来职业发展的必备技能。希望我的分享能让大家对蓝耘元生代平台、ComfyUI 工作流和服务器虚拟化有更深入的认识。如果你在学习过程中也有类似的发现和体会,欢迎在评论区留言交流,咱们一起在计算机技术的海洋里探索更多的奥秘!