引言
在工作的这些年中,我见证过太多团队在实现排行榜功能时踩过的坑。
今天我想和大家分享 6 种不同的排行榜实现方案,从简单到复杂,从单机到分布式,希望能帮助大家在实际工作中做出更合适的选择。
有些小伙伴在工作中可能会觉得:不就是个排行榜吗?搞个数据库排序不就完了?
但实际情况远比这复杂得多。
当数据量达到百万级、千万级时,简单的数据库查询可能就会成为系统的瓶颈。
接下来,我将为大家详细剖析 6 种不同的实现方案,希望对你会有所帮助。
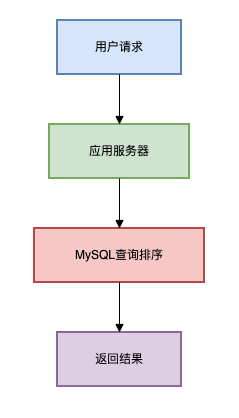
方案一:数据库直接排序
适用场景:数据量小(万级以下),实时性要求不高
这是最简单直接的方案,几乎每个开发者最先想到的方法。
示例代码如下:
java
public List<UserScore> getRankingList() {
String sql = "SELECT user_id, score FROM user_scores ORDER BY score DESC LIMIT 100";
return jdbcTemplate.query(sql, new UserScoreRowMapper());
}优点:
- 实现简单
- 代码维护成本低
- 适合数据量小的场景
缺点:
- 数据量大时性能急剧下降
- 每次查询都需要全表扫描
- 高并发下数据库压力大
架构图如下:
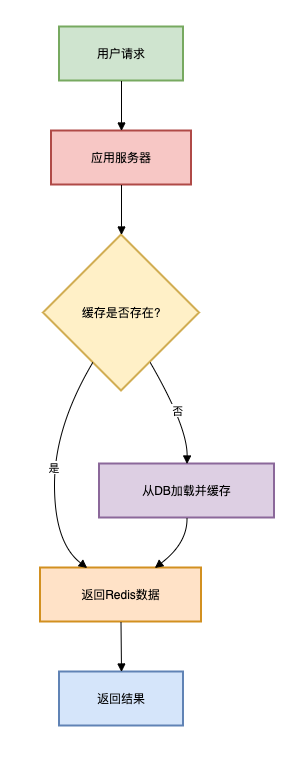
方案二:缓存+定时任务
适用场景:数据量中等(十万级),可以接受分钟级延迟
这个方案在方案一的基础上引入了缓存机制。
示例代码如下:
java
@Scheduled(fixedRate = 60000) // 每分钟执行一次
public void updateRankingCache() {
List<UserScore> rankings = userScoreDao.getTop1000Scores();
redisTemplate.opsForValue().set("ranking_list", rankings);
}
public List<UserScore> getRankingList() {
return (List<UserScore>) redisTemplate.opsForValue().get("ranking_list");
}优点:
- 减轻数据库压力
- 查询速度快(O(1))
- 实现相对简单
缺点:
- 数据有延迟(取决于定时任务频率)
- 内存占用较高
- 排行榜更新不及时
架构图如下:
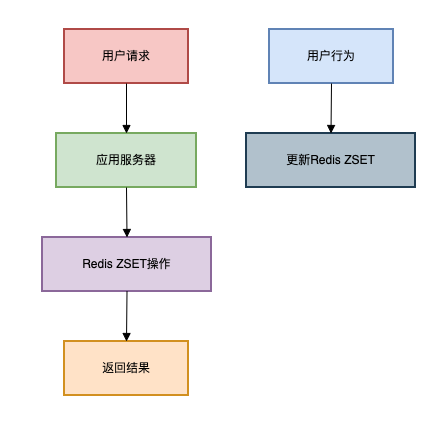
方案三:Redis有序集合
适用场景:数据量大(百万级),需要实时更新
Redis的有序集合(Sorted Set)是实现排行榜的利器。
示例代码如下:
java
public void addUserScore(String userId, double score) {
redisTemplate.opsForZSet().add("ranking", userId, score);
}
public List<String> getTopUsers(int topN) {
return redisTemplate.opsForZSet().reverseRange("ranking", 0, topN - 1);
}
public Long getUserRank(String userId) {
return redisTemplate.opsForZSet().reverseRank("ranking", userId) + 1;
}优点:
- 高性能(O(log(N))时间复杂度)
- 支持实时更新
- 天然支持分页
- 可以获取用户排名
缺点:
- 单机Redis内存有限
- 需要考虑Redis持久化
- 分布式环境下需要额外处理
架构图如下 :
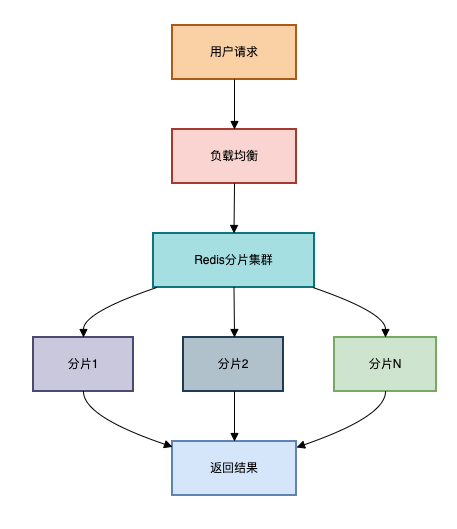
方案四:分片+Redis集群
适用场景:超大规模数据(千万级以上),高并发场景
当单机Redis无法满足需求时,可以采用分片方案。
示例代码如下:
java
//
public void addUserScore(String userId, double score) {
RScoredSortedSet<String> set = redisson.getScoredSortedSet("ranking:" + getShard(userId));
set.add(score, userId);
}
private String getShard(String userId) {
// 简单哈希分片
int shard = Math.abs(userId.hashCode()) % 16;
return "shard_" + shard;
}在这里我们以Redisson客户端为例。
优点:
- 水平扩展能力强
- 可以支持超大规模数据
- 高并发下性能稳定
缺点:
- 架构复杂度高
- 跨分片查询困难
- 需要维护分片策略
架构图如下:
方案五:预计算+分层缓存
适用场景:排行榜更新不频繁,但访问量极大
这种方案结合了预计算和多级缓存。
示例代码如下:
java
@Scheduled(cron = "0 0 * * * ?") // 每小时计算一次
public void precomputeRanking() {
Map<String, Integer> rankings = calculateRankings();
redisTemplate.opsForHash().putAll("ranking:hourly", rankings);
// 同步到本地缓存
localCache.putAll(rankings);
}
public Integer getUserRank(String userId) {
// 1. 先查本地缓存
Integer rank = localCache.get(userId);
if (rank != null) return rank;
// 2. 再查Redis
rank = (Integer) redisTemplate.opsForHash().get("ranking:hourly", userId);
if (rank != null) {
localCache.put(userId, rank); // 回填本地缓存
return rank;
}
// 3. 最后查DB
return userScoreDao.getUserRank(userId);
}优点:
- 访问性能极高(本地缓存O(1))
- 减轻Redis压力
- 适合读多写少场景
缺点:
- 数据实时性差
- 预计算资源消耗大
- 实现复杂度高
架构图如下:

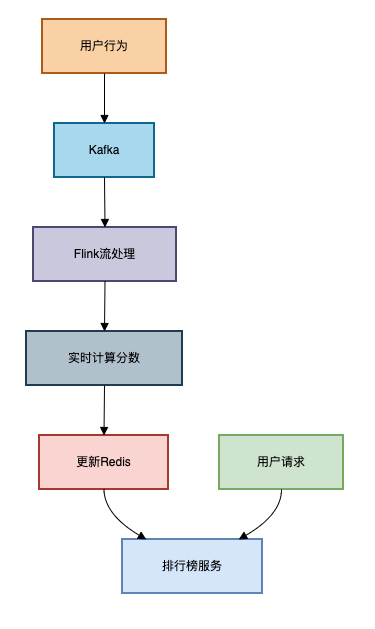
方案六:实时计算+流处理
适用场景:需要实时更新且数据量极大的社交平台
这种方案采用流处理技术实现实时排行榜。
使用Apache Flink示例如下:
java
DataStream<UserAction> actions = env.addSource(new UserActionSource());
DataStream<Tuple2<String, Double>> scores = actions
.keyBy(UserAction::getUserId)
.process(new ProcessFunction<UserAction, Tuple2<String, Double>>() {
private MapState<String, Double> userScores;
public void open(Configuration parameters) {
MapStateDescriptor<String, Double> descriptor =
new MapStateDescriptor<>("userScores", String.class, Double.class);
userScores = getRuntimeContext().getMapState(descriptor);
}
public void processElement(UserAction action, Context ctx, Collector<Tuple2<String, Double>> out) {
double newScore = userScores.getOrDefault(action.getUserId(), 0.0) + calculateScore(action);
userScores.put(action.getUserId(), newScore);
out.collect(new Tuple2<>(action.getUserId(), newScore));
}
});
scores.keyBy(0)
.process(new RankProcessFunction())
.addSink(new RankingSink());优点:
- 真正的实时更新
- 可处理超高并发
- 支持复杂计算逻辑
缺点:
- 架构复杂度高
- 运维成本高
- 需要专业团队维护
架构图如下:
方案对比与选择
| 方案 | 数据量 | 实时性 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 数据库排序 | 小 | 低 | 低 | 个人项目、小规模应用 |
| 缓存+定时任务 | 中 | 中 | 中 | 中小型应用,可接受延迟 |
| Redis有序集合 | 大 | 高 | 中 | 大型应用,需要实时更新 |
| 分片+Redis集群 | 超大 | 高 | 高 | 超大型应用,超高并发 |
| 预计算+分层缓存 | 大 | 中高 | 高 | 读多写少,访问量极大 |
| 实时计算+流处理 | 超大 | 实时 | 极高 | 社交平台,需要实时排名 |
总结
在选择排行榜实现方案时,我们需要综合考虑以下几个因素:
- 数据规模:数据量大小直接决定了我们选择哪种方案
- 实时性要求:是否需要秒级更新,还是分钟级甚至小时级都可以接受
- 并发量:系统的预期访问量是多少
- 开发资源:团队是否有足够的技术能力维护复杂方案
- 业务需求:排行榜的计算逻辑是否复杂
对于大多数中小型应用,方案二(缓存+定时任务)或方案三(Redis有序集合)已经足够。如
果业务增长迅速,可以逐步演进到方案四(分片+Redis集群)。
而对于社交平台等需要实时更新的场景,则需要考虑方案五(预计算+分层缓存)或方案六(实时计算+流处理),但要做好技术储备和架构设计。
最后,无论选择哪种方案,都要做好监控和性能测试。排行榜作为高频访问的功能,其性能直接影响用户体验。
建议在实际环境中进行压测,根据测试结果调整方案。
希望这六种方案的详细解析能帮助大家在工作中做出更合适的选择。
记住,没有最好的方案,只有最适合的方案。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的50万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。