**前言:**随着互联网的发展,前端技术也在不断变化,数据的加载方式也不再是单纯的服务端渲染了。现在你可以看到很多网站的数据可能都是通过接口的形式传输的,或者即使不是接口那也是一些 JSON 的数据,然后经过 JavaScript 渲染得出来的。
这时,如果你还用 requests 来爬取内容,那就不管用了。因为requests 爬取下来的只能是服务器端网页的源码,这和浏览器渲染以后的页面内容是不一样的。因为,真正的数据是经过 JavaScript 执行后,渲染出来的,数据来源可能是 Aiax,也可能是页面里的某些 Data,或者是一些 ifame 页面等。不过,大多数情况下极有可能是 Aiax 接口获取的。
所以,很多情况我们需要分析 Aiax请求,分析这些接口的调用方式,通过抓包工具或者浏览器的"开发者工具",找到数据的请求链接,然后再用程序来模拟。但是,抓包分析流的方式,也存在一定的缺点。因为有些接口带着加密参数,比如 token、sign 等等,模拟难度较大;
那有没有一种简单粗暴的方法,这时 Puppeteer、Pyppeteer、Selenium、Splash 等自动化框架出现了。使用这些框架获取HTML源码,这样我们爬取到的源代码就是JavaScript 渲染以后的真正的网页代码,数据自然就好提取了。同时,也就绕过分析 Ajax 和-些 JavaScript 逻辑的过程。这种方式就做到了可见即可爬,难度也不大,同时适合大批量的采集。
Selenium,作为一款知名的Web自动化测试框架,支持大部分主流浏览器,提供了功能丰富的API接口,常常被我们用作爬虫工具来使用。然而selenium的缺点也很明显,比如速度太慢、对版本配置要求严苛,最麻烦是经常要更新对应的驱动
1,selenium
1.1 安装
由于sleenium4.1.0需要python3.7以上方可支持,请注意自己的python版本。
方式1:pip安装
Python3.x安装后就默认就会有pip (pip.exe默认在python的Scripts路径下),打开 cmd,使用pip安装。
pip install selenium
首次安装会有进度条,而且装出来是多个包(依赖于其他第三方库)。如果安装慢(默认连接官网),可以指定国内源。
pip install selenium -i Simple Index
方式2:Pycharm安装
Pycharm-File-Setting-Project:xxxx-Python Interpreter,点击+号
下载浏览器驱动
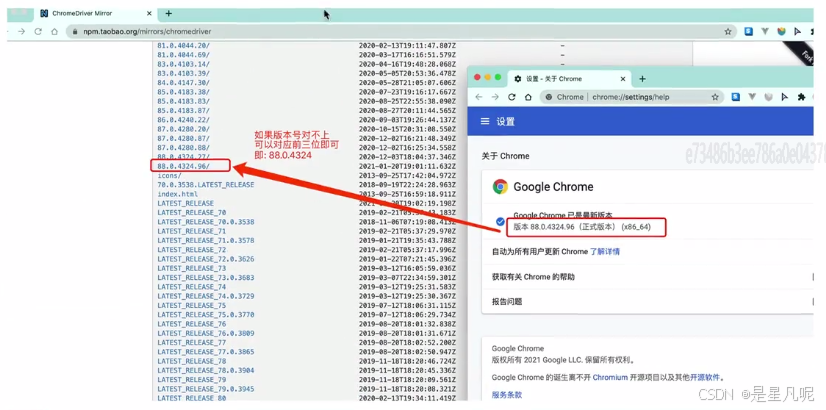
chrome驱动地址:
http://chromedriver.storage.googleapis.com/index.html
安装对应驱动
Microsoft Edge WebDriver | Microsoft Edge Developer
检查浏览器版本,下载对应版本驱动
1.2 quick start
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决rpquests无法直接执行javaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器安装pip包
python
import time
from selenium import webdriver # 按照什么方式查找 By.ID
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #
# edge_driver_path = 'D:\python12'
edge_data = webdriver.Edge()
edge_data.get("https://www.baidu.com")
input_tag = edge_data.find_element(By.ID, 'kw') #百度的搜索输入框ID是kw
input_tag.send_keys('hellokitty')
time.sleep(2)
# 关闭浏览器
edge_data.quit()
1.2.1 元素定位
方式1
python
el = driver.find element by xxx(value)方式2:推荐
python
from selenium.webdriver.common.by import By
driver.find element(By.xxx,value)
driver.find elements(Byxx,value)# 返回列表八种方式:
python
id
nawe
class
tag
link
partial
xpath
Css1.2.2 元素操作(节点交互)
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send _keys()方法,清空文字时用clear()方法,点击按钮时用 click()方法。示例如下:
find_element方法仅仅能够获取元素对象,接下来就可以对元素执行以下操作 从定位到的元素中提取数据的方法
- 从定位到的元素中获取数据
python
el.get_attribute(key)
el.text获取key属性名对应的属性值
获取开闭标签之间的文本内容
- 对定位到的元素的操作
python
el.click() # 对元素执行点击操作
el.submit() # 对元素执行提交操作
el.clear() # 清空可输入元素中的数据
el.send_keys(data) # 向可输入元素输入数据1.2.3 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现
python
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('http://sahitest.com/demo/dragDropMooTools.htm')
dragger = driver.find_element(By.ID,'dragger') # 被拖拽元素
item1 = driver.find_element(By.XPATH,'//div[text()="item_1"]') #目标元素1
item2 = driver.find_element(By.XPATH,'//div[text()="item_2"]')# 目标2
item3 = driver.find_element(By.XPATH,'//div[text()="item_3"]')# 目标3
item4 = driver.find_element(By.XPATH,'//div[text()="item_4"]') #目标4
action = ActionChains(driver)
action.drag_and_drop(dragger,item1).perform() #1.移动dragger到目标1
sleep(2)
action.click_and_hold(dragger).release(item2).perform() #2.效果与上句相同,也能起到移动效果
sleep(2)
action.click_and_hold(dragger).move_to_element(item3).release().perform() #3,效果与上两句相同,也能起到移动的效果
sleep(2)
action.click_and_hold(dragger).move_by_offset(800,0).release().perform()
sleep(2)
driver.quit()1.2.4 执行JS
selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了
当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的。这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。滚动条是无法直接用定位工具来定位的。selenium里面也没有直接的方法去控制滚动条,这时候只能借助Js代码了,还好selenium提供了一个操作js的方法:execute_script(),可以直接执行js的脚本。代码如下:
python
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(3)1.2.5 页面等待
为什么需要等待
如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,这个时候就可以设置一个等待时间,强制等待指定时间,等待结束之后进行元素定位,如果还是无法定位到则报错
页面等待的三种方法
- 强制等待
也叫线程等待,通过线程休眠的方式完成的等待,如等待5秒: Thread sleep(5000),一般情况下不太使用强制等待,主要应用的场景在于不同系统交互的地方。
import time time.sleep(n)
阻塞等待设定的秒数之后再继续往下执行
- 显式等待
也称为智能等待,针对指定元素定位指定等待时间,在指定时间范围内进行元素查找,找到元素则直接返回,如果在超时还没有找到元素,则抛出异常,显示等待是 selenium 当中比较灵活的一种等待方式,他的实现原理其实是通过 while 循环不停的尝试需要进行的操作。
python
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 每隔 0.5s 检查一次(默认就是 0.5s),最多等待 10 秒,否则报错。如果定位到元素则直接结束等待,如果在10秒结束之后仍未定位到元素则报错
chrome = webdriver.Edge()
# 发起请求
chrome.get('https://www.jd.com')
# 查找响应页面中的某个标签元素
img_s = chrome.find_elements(By.CLASS_NAME, "focus-item-img")
wait = WebDriverWait(chrome,10,0.5)
wait.until(EC.presence_of_element_located((By.ID, 'J goodsList')))- 隐式等待
隐式等待设置之后代码中的所有元素定位都会做隐式等待通过implicity_wait完成的延时等待,注意这种是针对全局设置的等待,如设置超时时间为10秒,使用了implicitly_wait后,如果第一次没有找到元素,会在10秒之内不断循环去找元素,如果超过10秒还没有找到,则抛出异常,隐式等待比较智能它可以通过全局配置,但是只能用于元素定位
python
driver.implicitly_wait(10) #在指定的n秒内每隔一段时间尝试定位元素,如果n秒结束还未被定位出来则报错注意:
Selenium显示等待和隐式等待的区别
1、selenium的显示等待原理:显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception
(简而言之,就是直到元素出现才去操作,如果超时则报异常)
2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。
注意:
在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
1.2.6 selenium的其他操作
- 无头浏览器
我们已经基本了解了selenium的基本使用了,但是呢,不知各位有没有发现,每次打开浏览器的时间都比较长,这就比较耗时了.我们写的是爬虫程序.目的是数据,并不是想看网页.那能不能让浏览器在后台跑呢?答案是可以的
python
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") #设置窗口大小
web = Chrome(options=opt)- selenium处理cookie
python
# 通过driver.get_cookies()能够获取所有的cookie
dictCookies=driver.get_cookies() #添加cookie
driver.add_cookie(dictCookies) #删除-条cookie
driver.delete_cookie("CookieName") #删除所有的cookie
driver.delete_all_cookies()- 页面前进和后退
python
driver.forward() #前进
driver.back() #后退学
driver.refresh() #刷新
driver.close() #关闭当前窗口1.2.7 滑动验证案例
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式査找
from selenium.webdriver.support import expected conditions as EC
from selenium.webdriver.support.wait import webDriverWait #等待页面加载某些元素
import cv2
from urllib import request
from selenium.webdriver.comon.action chains import Actionchains2 ,pyppeteer
由于Selenium流行已久,现在稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易就可以判断出是真人访问还是webdriver。虽然也可以通过中间代理的方式进行js注入屏蔽webdriver检测,但是webdriver对浏览器的模拟操作(输入、点击等等)都会留下webdriver的标记,同样会被识别出来,要绕过这种检测,只有重新编译webdriver,麻烦自不必说,难度不是一般大。由于Selenium具有这些严重的缺点。pyppeteer成为了爬虫界的又一新星。相比于selenium具有异步加载、速度快、具备有界面/无界面模式、伪装性更强不易被识别为机器人,同时可以伪装手机平板等终端;虽然支持的浏览器比较单一,但在安装配置的便利性和运行效率方面都要远胜selenium。
- pyppeteer的安装
pyppeteer无疑为防爬墙撕开了一道大口子,针对selenium的淘宝、美团、文书网等网站,目前可通过该库使用selenium的思路继续突破,毫不费劲。
介绍Pyppeteer之前先说一下Puppeteer,Puppeteer是谷歌出品的一款基于Node.js开发的一款工具,主要是用来操纵Chrome浏览器的 APl,通过Javascript代码来操纵Chrome浏览器,完成数据爬取、Web程序自动测试等任务。
pyppeteer是非官方 Python 版本的 Puppeteer 库,浏览器自动化库,由日本工程师开发
Puppeteer是 Google 基于 Node.js 开发的工具,调用 Chrome 的 API,通过 JavaScript代码来操纵 Chrome 完成一些操作,用于网络爬虫、Web 程序自动测试等。
pyppeteer 使用了 Python 异步协程库asyncio,可整合 Scrapy 进行分布式爬虫。
puppet 木偶,puppeteer 操纵木偶的人。
pip3 install pyppeteer
使用之前需要运行下这个代码
python
import pyppeteer.chromium_downloader
print('默认版本是:{}'.format(pyppeteer.__chromium_revision__))
print('可执行文件默认路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64')))
print('win64平台下载链接为:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))
查看电脑中间的可执行文件的默认的路径,如果没有需要建立相对应的文件夹,下面为下载路径
下载完成之后需要将对应的解压缩之后的文件夹放到上面的文件夹的目录下面
commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/
- pyppeteer滑动验证案例
python
from pyppeteer import launch
import random
import asyncio
import cv2
from urllib import request
async def get_track():
big = cv2.imread("bigimg.jpg",0)
small = cv2.imread("smallimg.jpg",0)
# print("cv2:",small)
res = cv2.matchTemplate(big, small, cv2.TM_CCOEFF_NORMED)
value = cv2.minMaxLoc(res)[2][0]
print(value)
#需要通过渲染比计算出实际的距离
return value * 342 / 360
async def main():
browser = await launch({
"headless": False,
"args":["--window-size=1920,1080"],
})
#打开新的标签页
page = await browser.newPage()
# 设置界面大小一致
await page.setViewport({"width":1920, "height":1080})
#访问主页
await page.goto("https://passport.jd.com/new/login.aspx")
await page.type("#loginname","18438371807",{
"c":random.randint(30,60)
})
await page.type("#nloginpwd", "abc10000610", {
"delay":random.randint(30, 60)
})
await page.waitFor(2000)
await page.click("div.login-btn")
await page.waitFor(2000)
# page.Jeval(selector,pageFunction) # 定位元素,并调用js函数去执行
big_img = await page.Jeval(".JDJRV-bigimg > img","el=>el.src")
small_img = await page.Jeval(".JDJRV-smallimg > img", "el=>el.src")
# 下载图片
request.urlretrieve(big_img, 'bigimg.jpg')
request.urlretrieve(small_img, 'smallimg.jpg')
# 得到滑动的距离
distance = int(await get_track())
print("distance:", distance)
# Pyppeteer 三种解析方式
# Page.querySelector() # 选择器
# Page.querySelectorAll()
# Page.xpath() #xpath 表达式# 简写方式为:
# Page.J(), Page.j](), and Page.Jx()
el = await page.J("div.JDJRV-slide-btn")
#获取元素的边界框
box = await el.boundingBox()
await page.hover("div.JDJRV-slide-btn")
await page.mouse.down()
# steps 是指分成几步来完威 steps越大,滑动速度越慢
await page.mouse.move(box["x"] + distance + random.uniform(30,33), box["y"], {"steps":100})
await page.waitFor(2000)
await page.mouse.move(box["x"] + distance + 29, box["y"], {"steps": 100})
await page.mouse.up()
await page.waitFor(2000)
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())