目录
[Text Enocder](#Text Enocder)
[Image Encoder](#Image Encoder)
[LLava 1.5](#LLava 1.5)
[LLava 1.6](#LLava 1.6)
CLIP
CLIP是OpenAI 在 2021 年发布的,最初用于匹配图像和文本的预训练神经网络模型,这个任务在多模态领域比较常见,可以用于文本图像检索。CLIP的思想是使用大量图片文本对来进行预训练,以学习图像和文本之间的对齐关系。CLIP有两个模态,一个是文本模态,另一个是视觉模态,包括两个主要部分:Text Encoder 和 Image Encoder。
CLIP训练
CLIP的训练阶段基于对比学习 的,如给定64个图片文本对,那么对应的就是64条文本和64张图片,在对比学习中,图片文本对本身就是正样本,而该文本与其他的63张图片构成了负样本,相对应的这张图片与另外63条文本构成了负样本。基于余弦相似度,在对比学习的这个过程中,我们可以知道配对的图片文本其余弦相似度最高(如图1(1)矩阵的主对角线),而当前样本的文本与另外的63张图片余弦相似度应较小。通过这种对比学习方式,来让相似的图片文本尽可能拉近,不相似的图片文本尽可能拉远。
CLIP图像分类
CLIP在下游任务图像分类中的应用中也表现出色。
- 首先对于给定的图像分类任务(例如,将图像分为"猫"、"狗"、"鸟"等),首先将所有可能的类别名称转换为文本描述。例如,对于类别"猫",可以构造提示(prompt)如"a photo of a cat"、"a picture of a cat"等。通常会使用一个模板,如"a photo of a {object}"。
- 将这些文本描述通过文本编码器来获得每个类别的文本嵌入。
- 对于一张待分类的图像,则通过图像编码器来获得图像的嵌入表示。
- 计算图像嵌入与所有类别文本嵌入之间的余弦相似度。
- 选择相似度最高的类别来作为图像的预测类别。
收益于在大量图片文本对上的对比学习,CLIP在零样本的情况下,也能很好的实现图像的分类。将所有类别以一个相同prompt进行表示,并通过编码所有类别文本的表示,通过计算待测图片与所有类别文本之间的余弦相似度,来选择相似度最高的类别文本,所预测的类别就是该类别文字中的类别。
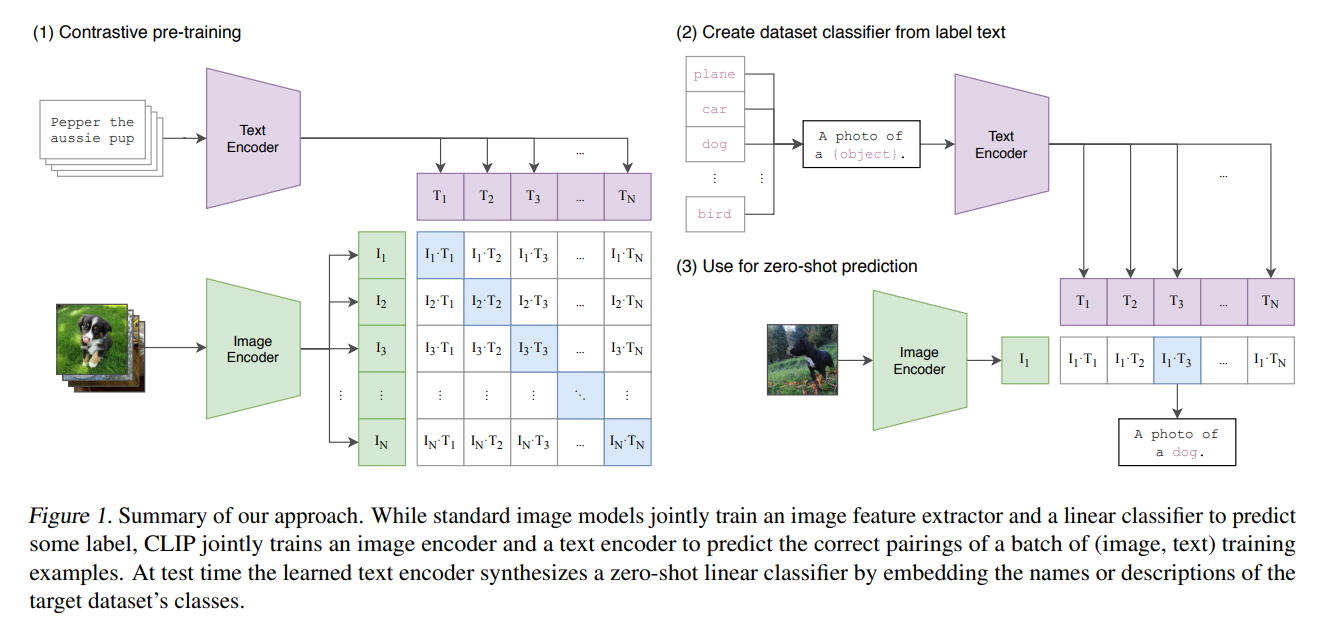
图1 CLIP方法
CLIP框架
CLIP的框架主要是两大部分,分别是Text Encder 和 Image Encoder。
Text Enocder
Text Encoder本质上与BERT差不多。
Image Encoder
Processor
首先是图像处理,借鉴了Transformer在NLP领域的成功,ViT将图像进行分割来作为一系列的tokens进行处理。CLIP中ViT模块Embedding包含以下几个关键部分:
- 图像分块。由于Transformer处理的是序列数据,为了让Transformer能够处理图像,ViT首先需要将输入的二维图像分割成一系列固定大小的、不重叠的小块(patches)。在这个过程中,首先需要对输入的图片分辨率进行修改,统一分辨率,如CLIP-VIT--base-Patch32中,ViT模块的图片分辨率都被统一压缩为224*224,每一个图像块的分辨率为32*32,因此一张224*224的图片将被切分49块(224/32 * 224/32)。每个图像块都是32*32*3的张量,3表示通道数,表示图片由红绿蓝三种通道所形成。
Embedding
- 展平与线性投影。每个带有通道信息的图像块被转换成一个1D的向量,并将其投影到一个统一的嵌入空间中,来使其维度与Transformer的隐藏维度相匹配。对于每个带有通道数32*32*3的图像块,其被展平后维度是32*32*3=3072。随后,这个3072维的展品向量被一个可学习的线性投影层映射到D维的嵌入空间,Clip-ViT-base-patch32中D维是768维。
- 位置编码。在经过上述操作后,图像的表示为49,768,但这49个图像块没有进行位置编码,如果没有位置编码的话,不能很好地还原整张图像的关系。位置编码的优先级为从左都右,从上到下。因此进行位置编码后,我们可以确定对应位置的图像块在原图像的具体位置。与文本类似,ViT在这部分也添加了一个可学习的CLS token,用于最终图像表示。因此一张图片可以最终表示为50,768, 随后这个embedding后的向量再被归一化后,就被输入到Transformer中进行Encoding了。
后续Encoding的部分与文本的Transformer基本类似,就不再过多介绍了。
LLava系列
LLava
LLava贡献
- 提出一个数据重组方式,使用 ChatGPT/GPT-4 将图像 - 文本对转换为适当的指令格式。
- 大型多模态模型,基于CLIP的ViT模块和文本解码器LLaMa,开发了一个大型多模态大模型------LLava,并在生成的视觉 - 语言指令数据上进行端到端微调。实证研究验证了将生成的数据用于 LMM 进行 instruction-tuning 的有效性,并为构建遵循视觉 agent 的通用指令提供了较为实用的技巧。
LLava模型结构
视觉编码器CLIP-ViT-large-patch14 + LLM Vicuna。
两个模型通过一个简单的映射矩阵进行连接,这个矩阵负责将视觉和语言特征对齐或转换,以便在一个统一的空间内对它们进行操作。
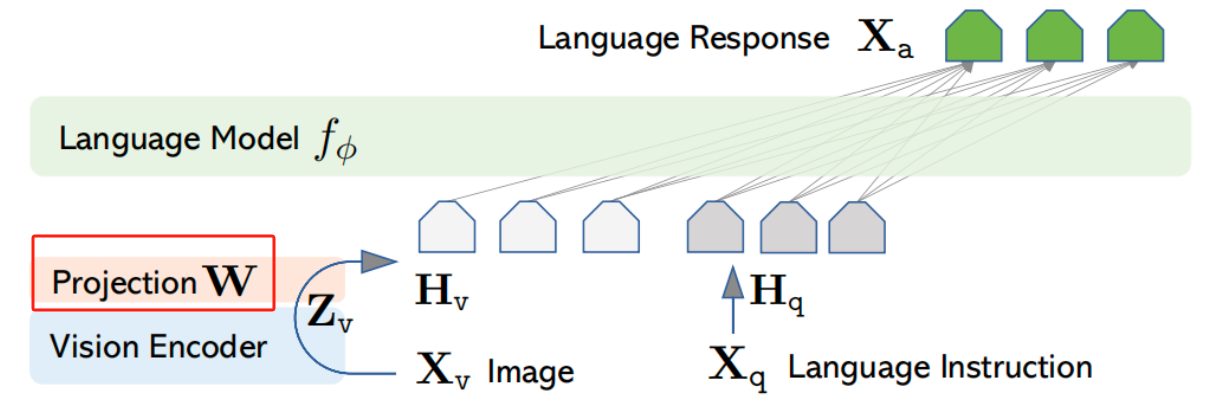
对于输入图像Xv,经过视觉编码器后得到Zv,需要注意的是Zv不是CLIP-ViT最终的输出,论文是将ViT模块Transformer最后一层之前和之后的视觉特征都考虑上了,这可能因为不同层的网格特征可能包含不同层次的信息,前一层特征可能更聚焦于局部细节,而后一层特征可能侧重于更全局、抽象的图像属性 ,综合考虑这些特征,有助于模型更好地理解图像内容。随后再通过可训练的投影矩阵进行映射,将Zv映射为Hv,来保持视觉模态维度与文本模态维度保持一致,从而实现多模态维度的对齐。
总结
LLaVa的模型结构非常简单,就是一个CLIP - ViT + LLaMA,为了与文本维度进行对齐,设计一个可学习的投影矩阵来对齐视觉模态和文本模态的维度。
LLava两阶段训练
阶段一:特征对齐预训练。由于从CLIP提取的特征与word embedding不在同一个语义表达空间,因此,需要通过预训练,将image token embedding对齐到text word embedding的语义表达空间。这个阶段冻结Vision Encoder和LLM模型的权重参数,**只训练插值层Projection W的权重。**即提升视觉模态维度投影到文本模态维度上的表现。
阶段二:端到端训练。这个阶段,依然冻结Vision Encoder的权重,**训练过程中同时更新插值层Projection W和LLM语言模型的权重,**训练考虑Multimodal Chatbot和Science QA两种典型的任务。
LLava 1.5
LLava1.5和LLava在模型架构上基本一样,在文本模型和维度对齐方面做了修改,图像编码器也相应地进行了略微的调整。具体地
- LLM模型,LLM从Vicuna升级为Vicuna v1.5 13B, 模型的参数量更大,效果得到了提升。
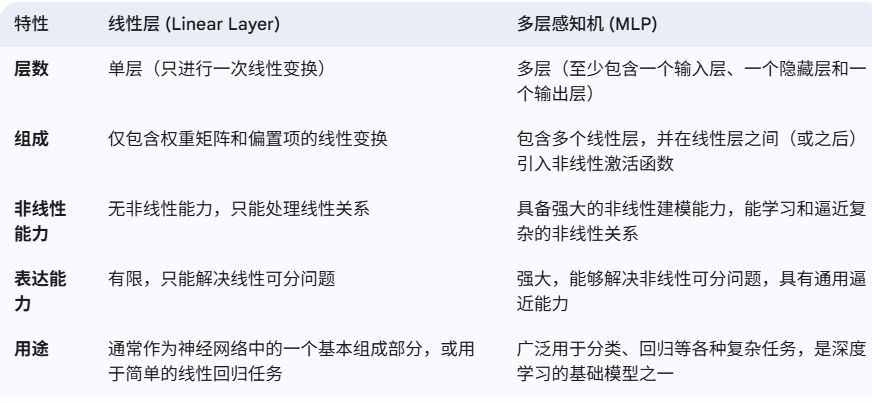
- Connector:原来是通过投影矩阵即线性层来将视觉模态维度映射到文本模态维度,但在LLava中采用MLP去进行映射。MLP和线性层的区别在于MLP是多层线性层的叠加,且在线性层之间/之后引入非线性激活函数。
- Vision Encoder:使用CLIP - VIT - Large336px,输入图像分辨率从224 * 224 增大为 336 *336,对图像的细节理解能力更强。(减少了分辨率降低所带来的细节程度忽略)
- 数据的质量也得到了提高
LLava 1.6
LLava1.6参数量达到34B,参数量为1.5版本相比得到了巨大的提升,在各项指标上提升也十分明显。在推理,OCR和世界知识的能力得到了增强。具体的改变有:
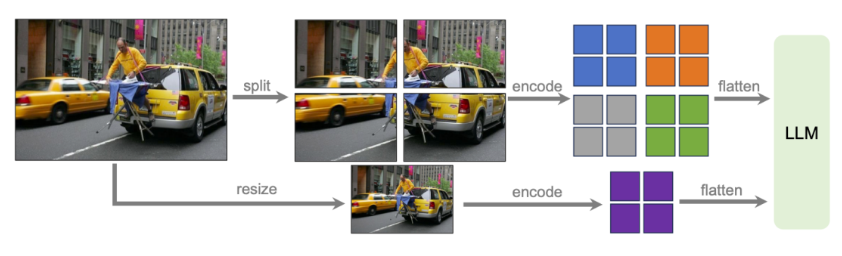
- Vision Encoder:支持更大的分辨率,包括672x672, 336x1344, 1344x336 几种分辨率的输入,并且支持通过图片裁切,编码,合并来实现。图片的细节可以得到充分展示,降低了压缩图片分辨率所带来的影响。
- 参数量大升级,由LLaVA 1.5的13B参数,增加到最多34B参数。
- OCR能力提升:更好的推理和OCR能力:通过修改指令数据集实现
- 更好的视觉对话:在一些场景下,拥有更好的世界知识