AI系列:智能音箱技术简析
智能音箱工作原理详解:从唤醒到执行的AIPipeline-CSDN博客
挑战真实场景对话------小爱同学背后关键技术深度解析 - 知乎 (zhihu.com)
AI音箱的原理,小爱同学、天猫精灵、siri。_小爱同学原理-CSDN博客
智能音箱执行步骤解析
语音识别的过程概述语音识别(一):介绍和简单实现_语音识别技术的基本实现方法-CSDN博客
语音识别从入门到精通------1-基本原理解释_语音识别入门-CSDN博客
语音识别到语音播放的完整流程涉及多个技术环节,涵盖从声音输入到文本输出,再到语音合成的全过程。以下是详细的分步说明:
声音输入与采集
麦克风拾音:设备麦克风接收声波信号,将模拟声波转换为电信号。
模数转换(ADC):通过采样(如16kHz/44.1kHz)、量化和编码(如16-bit PCM)将模拟信号转为数字信号。
音频预处理
降噪:去除环境噪声(如谱减法、深度学习降噪模型)。
分帧:将连续音频切分为短时帧(通常20-40ms/帧,如25ms帧长+10ms重叠)。
加窗:应用汉明窗/海宁窗减少频谱泄漏。
特征提取:提取梅尔频率倒谱系数(MFCC)、FBANK或时域特征(如Raw Waveform用于端到端模型)。
语音识别(ASR)
声学模型:将音频特征映射为音素或子词单元。
传统方法:GMM-HMM(高斯混合模型+隐马尔可夫模型)。
现代方法:端到端模型(如DeepSpeech、Conformer、Whisper)。
语言模型:基于文本统计(N-gram)或神经网络(BERT、Transformer)修正识别结果(如将"语音识别"纠错为"语音识别")。
解码:结合声学和语言模型,通过束搜索(Beam Search)输出概率最高的文本序列。
自然语言处理(NLP,可选)
意图识别:如智能助手解析"播放周杰伦的歌"为音乐播放指令。
语义理解:实体抽取(如时间、地点)、对话管理。
语音合成(TTS)
文本预处理:
归一化:将"100元"转为"一百元"。
分词与韵律预测:确定停顿、重音(如基于LSTM/Transformer的韵律模型)。
声学模型:
传统方法:拼接合成(单元选择+波形拼接)。
深度学习方法:Tacotron、FastSpeech(生成梅尔谱图)。
声码器:将频谱转为波形(如WaveNet、HiFi-GAN、Diffusion模型)。
后处理:音量均衡、速度调整(如基于PSOLA算法)。
音频输出
数模转换(DAC):将数字音频信号转为模拟信号。
扬声器播放:驱动硬件输出声波。
关键技术与挑战
实时性:端到端模型(如RNN-T)降低延迟。
多语种支持:多语言ASR/TTS模型(如Meta的MMS、Google的USM)。
个性化:语音克隆(如VITS、YourTTS)适配不同音色。
典型应用场景
智能音箱:唤醒词检测(如Alexa)→ASR→NLP→TTS回复。
字幕生成:会议录音→ASR→文本输出。
无障碍工具:语音输入→文本→语音反馈。
整个流程涉及信号处理、深度学习和硬件协同,现代端到端技术(如OpenAI Whisper)正逐步简化传统流水线。
麦克风拾音之后,正常来说就到了语音处理阶段,只不过初步阶段只是预处理,因为要从当前语音信息中抽离出真正的语音信息,而将无效的部分给滤除掉,这一部分涉及到滤波等操作;
拾音和预处理之后,就得到了目标的音频数据,这一步之后,就可以根据需求来进行后续的处理了:
如果只需要存储起来那就直接存到flash中去,结束;
如果需要实时播放出来录到的音频,那就直接播放原始音频数据或者进行编解码后播放即可,结束;
如果需要根据音频的内容来做出更多的回应,那么就需要进行ASR语音识别,将语音转成对应的文本了,注意,这一步将音频信息转换成文本信息了,如果可以根据文本信息的直接判断得到一些简单的回应,比如开灯关灯,那么就直接操作开关灯指令后结束;如果想要更进一步,比如能智能化地聊天,那么,就需要进一步进行NLP处理,得到回应的文本;然后通常还需要进行TTS处理,然后将音频再播放出来,结束;
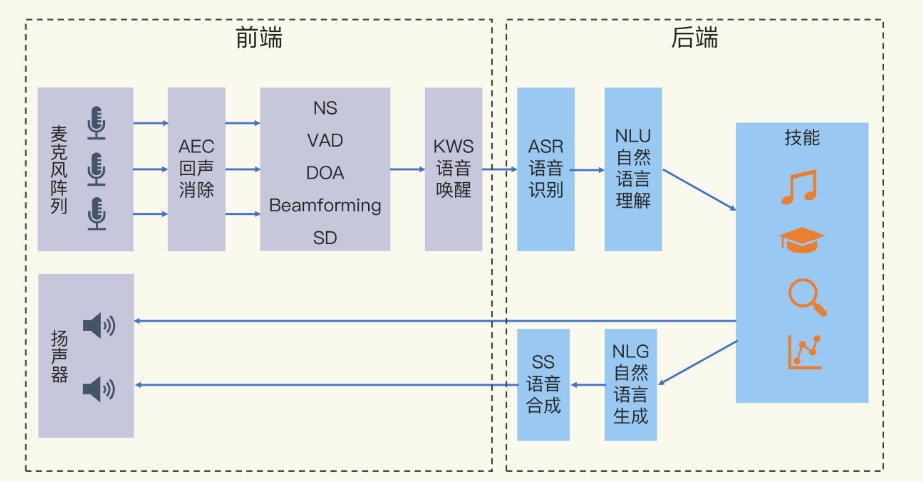
音频信号处理
AEC技术详解(Acoustic Echo Cancellation,声学回声消除)
这里的回声主要是指设备本身发出的声音,又被设备自身采集到了。比如,人声询问小爱同学,小爱同学回答之后,小爱把自己的回答又采集去了,这就形成了回声采集,这是一种需要避免的行为。
实时通信(VoIP/视频会议)
如Zoom、腾讯会议等依赖AEC避免回声。
智能音箱/语音助手
消除设备自身播放声音对语音指令的干扰(如天猫精灵、Alexa)。
车载通话系统
解决车内封闭空间的复杂声学回声。
等等。
VAD技术(Voice Activity Detection,语音活动检测)是一种用于识别音频信号中语音段落的技术。它的核心目标是区分语音段(有声部分)和非语音段(无声或噪声部分),广泛应用于语音通信、音频处理、语音识别等领域。以下是关于VAD技术的详细解析:什么是VAD技术?
VAD技术通过分析音频信号的特征,判断当前信号是否包含语音内容。它的输出通常是二元的:
语音段(Voice):检测到语音活动。
非语音段(Non-voice):未检测到语音活动(如静音、噪声或背景音)。
VAD技术的应用场景
语音通信:在电话或视频会议中,检测语音活动以触发传输或录音,节省带宽和存储资源。
语音识别:在语音识别系统中,去除无声段,减少处理负担并提高识别效率。
音频处理:在录音或直播中,自动分割语音片段,便于后期编辑。
智能设备:如语音助手(如Siri、Alexa),检测用户是否在说话,触发唤醒或响应。
安全监控:在监控系统中,检测异常声音(如呼喊、警报)并触发报警。
VAD技术的实现方法
(1)基于能量的检测
原理:语音信号的能量通常高于背景噪声。通过计算音频信号的短时能量,与预设阈值比较,判断是否为语音段。
优点:简单易实现,适用于信噪比较高的环境。
缺点:对低能量语音或高噪声环境敏感。
(2)基于零交叉率的检测
原理:语音信号的零交叉率(即信号穿过零点的频率)通常高于噪声。通过统计零交叉率,判断是否为语音段。
优点:对低能量语音有一定鲁棒性。
缺点:对某些噪声(如白噪声)可能误判。
(3)基于频谱特征的检测
原理:语音信号和噪声在频谱上有不同的分布特征。通过分析信号的频谱(如MFCC、频谱平坦度),区分语音和噪声。
优点:对复杂噪声环境有较好的鲁棒性。
缺点:计算复杂度较高。
(4)基于机器学习的检测
原理:利用机器学习模型(如SVM、神经网络)学习语音和噪声的特征,实现更精准的检测。
优点:适应复杂环境,准确率高。
缺点:需要大量训练数据,计算复杂度较高。
(5)混合方法
结合多种特征(如能量、零交叉率、频谱特征),提高检测的准确性和鲁棒性。
VAD用于定位语音段,NS用于提升语音质量。
NS技术 通常指噪声抑制(Noise Suppression)技术在声学领域,NS技术 通常指噪声抑制(Noise Suppression)技术。它是一种通过算法或硬件手段,减少或消除背景噪声,提升语音或音频信号质量的技术。以下是关于声学中NS技术的详细解析:
什么是噪声抑制(NS)技术?
噪声抑制技术是一种信号处理技术,主要用于从音频信号中分离出有用信号(如语音)和背景噪声,并尽可能降低噪声对有用信号的干扰。它广泛应用于语音通信、音频录制、会议系统等领域。
噪声抑制技术的应用场景
语音通信:如电话、视频会议、VoIP(网络语音通话)等,用于提升语音清晰度。
音频录制:在录音棚或嘈杂环境中,减少背景噪声对录音质量的影响。
智能设备:如智能手机、智能音箱等,用于提高语音识别的准确性。
汽车音响:降低车内噪音,提升通话或音乐播放质量。
医疗领域:如听力检测设备,用于过滤环境噪声。
噪声抑制技术的实现方法
(1)基于硬件的噪声抑制
麦克风阵列:通过多个麦克风采集声音信号,利用信号到达时间差或相位差,抑制来自非目标方向的噪声。
主动降噪耳机:通过发射与噪声相位相反的声波,抵消背景噪声。
(2)基于软件的噪声抑制
谱减法:通过分析音频信号的频谱,减去噪声频谱成分。
维纳滤波:基于统计特性,优化滤波器以最小化噪声影响。
自适应滤波:根据实时环境噪声动态调整滤波参数。
深度学习方法:利用神经网络(如RNN、CNN)学习噪声特征,实现更高效的噪声抑制。
噪声抑制技术的关键技术指标
降噪增益:噪声被抑制的程度,通常以分贝(dB)表示。
语音保真度:在抑制噪声的同时,尽可能保留原始语音的自然性。
延迟:处理音频信号时产生的延迟,需控制在可接受范围内。
鲁棒性:在不同噪声环境(如白噪声、风噪、机械噪声)下的适应能力。
噪声抑制技术的挑战
非平稳噪声:如风噪、机械噪声等,其特性随时间变化,难以完全抑制。
语音与噪声的频谱重叠:当噪声频率与语音频率接近时,可能误伤语音信号。
实时性要求:在语音通信等场景中,需保证低延迟处理。
常见的噪声抑制算法和工具
Speex:开源的语音编码和噪声抑制库。
RNNoise:基于神经网络的实时噪声抑制算法。
WebRTC:谷歌的开源项目,包含噪声抑制模块。
MATLAB/Python:通过信号处理工具箱实现自定义噪声抑制算法。
未来发展趋势
人工智能驱动:利用深度学习模型(如卷积神经网络、循环神经网络)实现更精准的噪声抑制。
多模态融合:结合视觉、环境传感器等信息,提升噪声抑制的鲁棒性。
低复杂度算法:在保证性能的同时,降低算法的计算复杂度,适用于嵌入式设备。
如果你有更具体的应用场景或问题,可以进一步探讨!
ANC
主动降噪耳机(ANC)原理及应用介绍 - 知乎 (zhihu.com)
DOA技术(Direction of Arrival,到达方向估计)是一种用于确定声源或信号源在空间中方向的技术。它广泛应用于雷达、声呐、无线通信、语音处理、安防监控等领域。以下是关于DOA技术的详细解析:什么是DOA技术?
DOA技术通过分析信号在多个接收器(如麦克风阵列、天线阵列)上的相位差、时间差或强度差,推断出信号源的方向。其核心目标是确定信号源相对于接收阵列的方位角(Azimuth)和俯仰角(Elevation)。
DOA技术的应用场景
语音处理:在智能音箱、会议系统中,定位说话人的方向,实现声源分离或波束成形。
雷达与声呐:在军事、航海、航空领域,用于目标定位和跟踪。
无线通信:在基站中,通过DOA估计优化信号传输方向,提高通信质量。
安防监控:通过摄像头或麦克风阵列,定位异常声音或运动的方向。
虚拟现实(VR):在AR/VR设备中,通过DOA技术实现3D音效或用户定位。
例如在智能音箱中,VAD检测语音活动,DOA定位说话人方向,NS抑制噪声,最终实现精准的语音交互。
BeamForming技术(波束成形技术)是一种通过调整信号的相位和幅度,使信号在特定方向上增强或抑制的技术。它广泛应用于雷达、声呐、无线通信、语音处理等领域,旨在提高信号的方向性和抗干扰能力。例如在智能音箱中,VAD检测语音活动,DOA定位说话人方向,BeamForming增强目标声音,NS抑制噪声,最终实现精准的语音交互。
在声学中,SD技术 通常指声学信号解码(Speech Decoding) 或**声学特征提取(Sound Feature Extraction)**技术。它的核心目标是从原始声音信号中提取有用的信息(如语音内容、情感、方向等),并将其转化为可分析或可处理的形式。
KWS
KWS(Keyword Spotting,关键词唤醒)技术是一种用于检测特定关键词或短语的技术,广泛应用于语音助手(如Siri、Alexa、小爱同学)、智能家居、安防监控等领域。它的核心目标是在持续的音频流中实时检测目标关键词,并触发相应的操作(如唤醒设备、执行指令)。
KWS在语音处理的哪个环节?
关键词检测(Keyword Spotting, KWS )在语音处理流程中属于前端触发环节,负责实时监听并判断是否出现预设的唤醒词(如"Hey Siri""小爱同学")。以下是其在语音处理中的具体定位和交互环节:
KWS的核心环节定位
阶段:语音输入与唤醒阶段
位置:
音频采集 → 信号预处理 → KWS → (唤醒后)→ 完整ASR/NLP
作用:
持续监听环境声音,过滤非唤醒词噪声,仅在检测到关键词时激活后续高阶处理模块。
技术层级:
低功耗层:运行在专用DSP芯片或协处理器上,与主CPU/GPU隔离以节省能耗。
预处理层:依赖降采样、简单特征提取(如MFCC的简化版),不涉及复杂语义分析。
与其他模块的协同关系
|---------------|--------------------------------------------|
| 模块 | 与KWS的交互 |
| 麦克风阵列 | KWS接收原始音频流,但仅启用部分麦克风(如双麦中的1个)以降低功耗。 |
| 降噪模块(DENOISE) | 部分设备在KWS前加入轻量级降噪,但多数KWS直接处理原始信号(避免降噪算法延迟)。 |
| 语音活动检测(VAD) | KWS可视为一种特殊的VAD,但专精于特定关键词而非通用语音检测。 |
| 完整ASR | KWS触发后,ASR接管音频流进行全量语音识别。 |工作流程示例
以智能音箱听到"小爱同学,明天天气怎么样?"为例:
KWS阶段:
持续监听环境音,检测到"小爱同学"时触发硬件中断。
向主系统发送唤醒信号,开启全频段麦克风和ASR服务。
ASR阶段:
后续音频"明天天气怎么样?"被完整识别为文本。
NLP阶段:
文本交由语言模型解析意图,调用天气API并生成回复。
关键区别:
KWS仅需判断是否匹配唤醒词 (二分类问题),而ASR需识别任意语音内容(开放词汇识别)。
为什么KWS必须独立前置?
(1)功耗优化
KWS模型体积仅约50-200KB (如TinyML实现的8位量化CNN),而完整ASR模型常达100MB+。
手机待机时,KWS功耗可控制在0.1mW 以下,ASR运行时功耗超500mW。
(2)实时性要求
唤醒词检测需在100-300ms内完成(用户感知无延迟),ASR通常需500ms+。
独立KWS模块可避免加载大型模型的开销。
(3)隐私保护
唤醒前音频仅在本地处理且立即丢弃,避免持续录音引发的隐私风险。
特殊场景下的变体
多阶段KWS:
一级KWS(超低功耗)初步检测 → 二级KWS(更高精度)确认 → 触发ASR。
无唤醒词模式:
通过传感器(如加速度计检测设备拿起)或视觉(摄像头唇动检测)替代KWS。
端到端唤醒:
如Google的《VoiceFilter-Lite》将KWS和ASR融合为单一模型,但需更高算力。
总结
KWS是语音处理流水线的**"守门人"**,负责以最小功耗实现即时唤醒。
唤醒后KWS模块还需要工作吗?
通常,每次对话时都需要唤醒一次;也有连续对话功能支持一次唤醒,连续对话逻辑。
具体实现取决于设备设计和功能需求。以下是详细分析:
唤醒后KWS的典型状态
大多数情况下停止工作
主流程接管 : 唤醒后,系统会切换至**完整语音识别(ASR)和自然语言理解(NLU)**流程,KWS模块进入休眠状态以节省功耗。
原因:
KWS的核心任务是检测唤醒词,任务完成后即可释放资源。
持续运行KWS会导致冗余计算(ASR已包含语音检测功能)。
例外情况:持续监听二次唤醒
某些设备会在唤醒后保持轻量级KWS,用于以下场景:
多轮对话中断:
用户说"小爱同学,打开空调" → 执行后,5秒内检测到"等一下"可中断操作。
新唤醒词触发:
如Alexa的"Alexa, stop"可覆盖前一条指令。
低功耗模式下的长对话:
设备可能用KWS辅助检测对话结束(如静默超时)。
技术实现差异
|-------------|--------------|-----------------------|
| 设备类型 | 唤醒后KWS状态 | 技术原因 |
| 智能手机(如Siri) | 通常关闭 | 依赖ASR的端点检测(VAD)判断语音结束 |
| 智能音箱(如Echo) | 可能保持简化KWS | 需支持远场交互和快速中断 |
| 车载语音系统 | 常开(但复用ASR模块) | 驾驶场景需即时响应新指令 |替代方案:语音活动检测(VAD)
唤醒后,系统一般通过VAD模块(Voice Activity Detection)替代KWS实现类似功能:
作用:
检测用户是否在说话(而非特定关键词)。
确定语音起止点,节省ASR计算资源。
优势:
比KWS更通用(不依赖特定词库)。
可与ASR模型集成(如Transformer的端点预测)。
功耗与性能权衡
关闭KWS:
省电:减少常驻进程,尤其对电池设备(如TWS耳机)关键。
延迟风险:依赖ASR/VAD可能增加误判(如将环境噪声视为语音)。
保留KWS:
快速响应:适合需要即时中断的场景(如智能家居控制)。
功耗代价:需额外分配计算资源。
前沿优化方案
动态切换:
根据场景智能选择KWS/VAD(如会议模式关闭KWS,家居模式开启)。
硬件级融合:
高通Aqstic音频芯片将KWS/VAD/ASR集成到同一低功耗模块。
语义中断检测:
直接通过NLU判断指令终止(如用户说"好了"),减少对KWS依赖。
总结
默认情况:唤醒后KWS模块休眠,由ASR/VAD接管。
特殊需求:如需即时中断或多轮对话,可能保留轻量级KWS。
趋势:随着端侧算力提升,KWS与ASR的界限逐渐模糊(如端到端模型统一处理)。
这一设计平衡了实时性 与能效,确保用户体验与设备续航兼得。
语音助手唤醒前和唤醒后有什么区别?
语音助手在唤醒前 和唤醒后的工作模式存在显著差异,主要体现在功耗、数据处理权限、功能范围及隐私保护等方面。以下是详细对比:
工作状态与功耗
|-------|-----------------------|--------------------------|
| 维度 | 唤醒前 | 唤醒后 |
| 麦克风状态 | 仅低功耗监听唤醒词(1-2kHz采样率) | 全频段高精度拾音(16kHz+) |
| 处理器 | 专用低功耗DSP芯片运行 | 主CPU/GPU激活,运行完整ASR/NLP模型 |
| 功耗 | 0.1-1mA(如AirPods唤醒耗电) | 50-500mA(依赖云端交互时更高) |技术实现 : 唤醒前采用硬件级关键词检测(如Apple的Always-On Processor),唤醒后切换至软件栈全功能模式。
数据处理范围
|------|---------------------------|-------------------------|
| 维度 | 唤醒前 | 唤醒后 |
| 音频处理 | 仅分析是否匹配预设唤醒词(如"Hey Siri") | 完整语音识别(ASR)+自然语言理解(NLU) |
| 数据存储 | 不保存原始音频(隐私设计) | 可能缓存录音用于改进服务(用户可关闭) |
| 网络连接 | 本地处理,无需联网 | 通常需连接云端执行复杂NLP/服务调用 |例外 : 部分设备(如HomePod)支持本地唤醒后处理,无需上传云端。
功能权限
|-------|--------|----------------------|
| 维度 | 唤醒前 | 唤醒后 |
| 指令执行 | 仅响应唤醒词 | 可调用API(播放音乐、控制智能家居等) |
| 系统访问 | 无权限 | 获得用户授权权限(如发短信、查日程) |
| 多模态交互 | 无 | 可结合屏幕/摄像头(如显示天气图文) |案例: 华为小艺唤醒后可通过语音直接拨号,唤醒前无法获取通讯录权限。
隐私与安全机制
|-------|-------------------------|-------------------|
| 维度 | 唤醒前 | 唤醒后 |
| 数据加密 | 唤醒词检测结果本地销毁 | 云端传输采用TLS/SSL加密 |
| 用户知情权 | 设备需明确标识唤醒状态(如指示灯) | 部分设备提供录音后人工审核选项 |
| 法律合规 | 符合GDPR/CCPA对"被动监听"的豁免条款 | 需用户同意隐私政策才能使用完整功能 |争议点: 亚马逊Alexa曾因唤醒前意外录音面临诉讼,促使厂商改进误唤醒过滤算法。
技术实现差异
唤醒前
算法:
轻量级二进制分类模型(如SVM、小规模CNN)。
抗噪优化:针对常见环境音(水流声、电视声)降误触发。
硬件:
麦克风阵列中仅1-2个麦克风工作,节省能耗。
唤醒后
算法:
端到端ASR(如Conformer)+ 大语言模型(如GPT-4)。
声纹识别(可选):验证是否为授权用户。
硬件:
多麦克风波束成形 + 传感器协同(如手机陀螺仪确定发声方向)。
用户感知差异
延迟:唤醒前反应时间<100ms,唤醒后完整流程需200-1000ms。
反馈:
唤醒前:无声或轻微震动(避免打扰)。
唤醒后:TTS语音回复+屏幕交互。
未来演进方向
无唤醒词交互:
- 通过注视检测(如AR眼镜)或手势触发。
分级唤醒:
- 敏感指令(如支付)需二次认证。
更严格的隐私保护:
- 联邦学习实现个性化唤醒词不上传云端。
总结
唤醒前是"哨兵模式"(低功耗/有限功能),唤醒后进入"战斗状态"(全功能/高能耗)。这种设计平衡了实时响应 与资源消耗,同时兼顾隐私与用户体验。
ASR
ASR(Automatic Speech Recognition,自动语音识别)技术是一种将人类语音转换为文本或计算机可理解指令的技术。ASR技术通过分析语音信号的特征(如音调、频率、节奏等),将其转化为文字或指令。其核心目标是让计算机"听懂"人类的语言,并准确输出对应的文本或执行相关操作。
ASR一般运行在嵌入式设备端还是后台服务端
ASR(自动语音识别)可以在嵌入式设备端 或后台服务端 运行,具体选择取决于计算资源、实时性、隐私需求等因素。以下是两种方案的对比及适用场景分析:
嵌入式设备端ASR
特点
低延迟:无需网络传输,响应时间通常<500ms(如本地唤醒词检测)。
离线可用:不依赖网络,适合无网环境(工业设备、车载系统)。
隐私保护:音频数据不出设备,符合GDPR等法规要求。
资源限制:需优化模型以适应MCU/DSP(如量化、剪枝)。
典型硬件
低功耗MCU:STM32H7(Cortex-M7)、ESP32(带硬件加速)
专用芯片:Cadence HiFi DSP、Synaptics VS680
边缘计算模块:树莓派(运行Vosk)、Jetson Nano
常用方案
|--------|------------|-------------------------------|
| 技术 | 适用场景 | 示例 |
| 轻量级模型 | 关键词唤醒(KWS) | TensorFlow Lite Micro(20KB模型) |
| 端到端ASR | 简单语音指令识别 | Vosk(50MB离线模型) |
| 硬件加速 | 实时语音转写 | STM32Cube.AI + LSTM |优势场景
智能家居本地控制(如"打开灯光")
车载语音助手(无网络隧道环境)
医疗/工业设备(敏感数据禁止上传)
后台服务端ASR
特点
高精度:可运行大型模型(如Whisper、Conformer),词错误率(WER)更低。
多语言支持:云端模型轻松支持100+语言。
动态更新:模型可随时升级,无需终端OTA。
依赖网络:需稳定带宽(>50kbps),延迟较高(通常1-3秒)。
典型架构
云计算平台:AWS Transcribe、Google Speech-to-Text
自建服务:Kaldi + GPU服务器、NVIDIA Riva
混合方案:本地预处理+云端二次识别(如降噪后上传)
常用方案
|---------|----------|----------------------------|
| 技术 | 适用场景 | 示例 |
| 流式ASR | 实时会议转录 | WebRTC + Google Speech API |
| 大语言模型集成 | 语音对话系统 | Whisper + GPT-4 Turbo |
| 定制化训练 | 垂直领域术语优化 | 基于ESPnet的行业模型 |优势场景
客服电话录音转写(需高准确率)
多语种实时翻译(如Zoom会议)
海量语音数据分析(如用户反馈挖掘)
关键决策因素
|-------|---------------|--------------------------|
| 因素 | 嵌入式端 | 服务端 |
| 延迟 | <500ms | 1-5s(含网络传输) |
| 隐私要求 | 数据完全本地处理 | 需加密传输 |
| 模型大小 | <100MB(需量化) | 无限制(如Whisper-large 10GB) |
| 多语言支持 | 通常单一语言 | 支持上百种语言 |
| 硬件成本 | 低(1−1−10 MCU) | 高(云服务费用$0.01/分钟起) |
| 网络依赖 | 无需网络 | 必须联网 |混合方案(边缘+云端)
工作流程
设备端:
运行轻量级KWS检测唤醒词
本地预处理(降噪、VAD)
服务端:
仅上传有效语音片段
高精度ASR+语义理解
典型案例
苹果Siri:本地检测"Hey Siri"后,云端处理复杂查询。
特斯拉车载系统:基础指令本地执行,导航请求发往云端。
趋势与前沿
端侧大模型:
如高通AI Stack支持在手机端运行70亿参数模型。
联邦学习:
云端训练模型,分布式更新终端模型(保护隐私)。
硬件加速:
NPU专用于ASR(如华为昇腾310的语音处理单元)。
总结建议
选择嵌入式端ASR:
需求低延迟、强隐私、无网环境。
典型场景:智能家居控制、工业设备指令。
选择服务端ASR:
需求高准确率、多语言、复杂NLP交互。
典型场景:客服系统、会议转录。
混合方案:
平衡体验与成本,如消费级智能音箱。
NLP
NLP(Natural Language Processing,自然语言处理) 是人工智能的一个重要分支,涉及计算机对人类语言的理解、生成和交互。在NLP领域,NLU(Natural Language Understanding,自然语言理解) 和 NLG(Natural Language Generation,自然语言生成) 是两个核心子任务,分别负责语言的理解和生成。
为什么NLP不直接处理音频数据,而是要事先通过ASR将音频数据转成文本
NLP(自然语言处理)不直接处理原始音频数据,而是先通过语音识别(ASR)将音频转为文本,这一设计是出于技术效率、计算成本、任务分工和实际应用需求的综合考量。以下是具体原因分析:
模态差异:音频与文本的本质区别
音频数据:
高维度连续信号:1秒16kHz采样率的音频包含16,000个数据点(时间序列)。
信息密度低:大量冗余信息(如静音段、语气词)对语义贡献有限。
文本数据:
离散符号序列:直接表达语义的最小单元(词/字)。
结构化特征:语法、词序等更适配NLP模型处理。
类比: 就像人类不会直接分析声波图谱来理解语言,而是先通过听觉系统转化为抽象的语言符号。
技术分工优化效率
语音识别(ASR)的专精化:
ASR模型(如Whisper、Conformer)专门优化声学特征到文本的映射,解决口音、噪声等问题。
NLP模型(如BERT、GPT)专注文本语义理解,两者分工可达到更高准确率。
计算资源分配:
联合训练端到端音频到语义的模型(如SpeechT5)需要极大算力,而拆分后ASR和NLP可独立优化。
实验数据: 联合模型的错误率通常比ASR+NLP流水线高20-30%(尤其在复杂指令场景)。
文本的通用性与可扩展性
跨模态统一接口:
文本可作为语音、图像(OCR)、触控等多模态输入的中间表示。例如:
语音指令 → 文本 → NLP → 控制智能家居
图片中的文字 → 文本 → NLP → 问答
生态兼容性:
现有NLP工具链(分词器、预训练模型、知识图谱)均基于文本构建,直接复用成本低。
实际应用场景需求
可解释性与调试:
文本日志便于追踪错误(如ASR误识别"打开空调"为"打开空气")。
隐私与合规:
音频含生物特征(声纹),转为文本后可脱敏处理。
存储与传输:
文本数据体积比音频小1000倍以上(1分钟语音≈10KB文本 vs. 1MB音频)。
例外:端到端语音NLP的探索
尽管主流方案仍依赖ASR+NLP流水线,但以下场景尝试直接处理音频:
Speech-to-Intent(如智能家居简单指令):
跳过文本阶段,直接用音频分类(如"开灯"→
action:turn_on)。情感/语调分析:
结合音频的韵律特征(如停顿、音高)判断情绪,此时需保留原始信号。
多模态模型(如OpenAI Whisper+GPT):
虽内部有ASR阶段,但对用户呈现为"音频输入→语义输出"的黑箱。
未来趋势
软硬件协同优化:
端侧芯片(如NPU)可能推动端到端语音NLP的实用化。
跨模态统一模型:
类似Flamingo(音频+文本+视觉)的架构可能模糊传统边界。
但短期内,ASR→NLP的分阶段处理仍是性价比最高的方案,尤其在复杂语义理解场景。
TTS
SS(Speech Synthesis,语音合成) 是**TTS(Text-to-Speech,文本转语音)**的另一种表述,指通过技术手段生成人类语音的过程。它与TTS是同一概念,只是名称不同。
小结
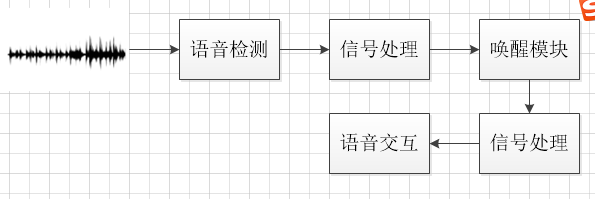
简单的说,音箱工作的时,麦克风阵列始终处于拾音状态(对声音进行采样,量化)。进过基本的信号处理(静音检测、降噪等),唤醒模块会判断是否出现唤醒词,是的话就进行更复杂的语音信号处理,开始真正的语音交互流程。
1.前端信号的处理
1.1语音检测(VAD voice activity detection)
准确的检测音频信号的语音段起始位置,从而分离出语音段和非语音段
1.2降噪
现实环境中存在噪声,通过降低噪声的干扰,降低语音识别难度。
常用的有LMS和维纳滤波。
1.3声学回声消除(AEC)
麦克风收集声音的时候,去除自身播放的声音。否则在播放音乐的时候,人的声音可能被掩盖。
1.4去混响处理
避免声音的反射对音箱的干扰。
1.5声源定位
确定人的位置。
1.6波束形成
降噪去混响的作用
2唤醒
经过语音检测后的信息,只能音箱会在检测到唤醒词之后才开始复杂的信号处理(声源定位等)和后续的交互。
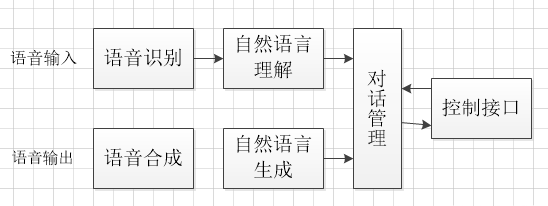
3语音交互
语音输入-语音识别-自然语言的理解-对话管理控制借口-对话管理-自然语言生出-语音合成-语音输出。
3.1语音识别(ASR)
将语音信号转化成文本。
3.2自然语言理解(NLU)
要结合特定的使用场景和现有技术。
领域分类:根据识别命令所属领域,领域是封闭的集合。
意图分类:在相应的领域,识别用户的意图。
实体抽取:确定意图的参数。比如歌手名字和歌曲名称。
3.3对话管理:
对一些追加性的问题的优化。比如明天上海天气怎么样?北京呢?
3.4自然语音的生成(NLG)
采用预先设计的文本模块生成文本输出。
即将为您播放的歌曲是谁的什么歌。
3.5语音合成
TTS使机器能够像人一样朗读给定的文本。
语音数据预处理和ASR和NLP和TTS技术有什么区别吗?
语音数据预处理、ASR(自动语音识别)、NLP(自然语言处理)和TTS(文本转语音)是语音技术链中的不同环节,各自承担独特任务但又紧密关联。以下是它们的核心区别与联系:
语音数据预处理
定位 :所有语音技术的前置基础环节
目标:将原始音频转化为适合后续处理的干净、结构化数据
核心任务:
降噪:去除环境噪声(如谱减法、深度学习降噪模型)
分帧加窗:将连续音频切分为20-40ms的帧(汉明窗减少频谱泄漏)
特征提取:计算MFCC(梅尔频率倒谱系数)、FBANK等声学特征
VAD(语音活动检测):定位有效语音段,剔除静音
输出 :标准化音频特征矩阵(如
[时间帧×特征维度])特点:
不涉及语义理解,纯信号处理
为ASR/TTS提供高质量输入
(1) ASR:声学信号 → 文本
核心挑战:
口音、噪声、语速差异下的鲁棒性。
实时性要求(如流式识别)。
关键技术:
声学模型:分析音频特征(如MFCC、FBANK)到音素/字符的映射(常用模型:Conformer、Whisper)。
语言模型:修正识别错误(如N-gram或Transformer-based模型)。
输出示例:
音频"打开空调" → 文本"打开空调"。
(2) NLP:文本 → 语义理解
核心挑战:
歧义消除(如"苹果"指水果还是公司)、多轮对话管理。
关键技术:
意图识别:分类用户意图(如播放音乐、查询天气)。
实体抽取:提取关键信息(如时间、地点)。
上下文建模:基于对话历史生成响应(如BERT、GPT)。
输出示例:
文本"明天上海天气?" → 结构化意图
{action:query_weather, location:上海, date:明天}。(3) TTS:文本 → 自然语音
核心挑战:
合成语音的自然度、情感表达(如高兴/愤怒)。
关键技术:
文本分析:分词、韵律预测(如停顿、重音)。
声学模型:生成频谱特征(如Tacotron、FastSpeech)。
声码器:将频谱转为波形(如WaveNet、HiFi-GAN)。
输出示例:
文本"已为您关闭空调" → 语音音频。
四者协同工作流程示例
用户指令 :"小爱同学,明天北京气温多少度?"
预处理:
麦克风音频→降噪→分帧→提取MFCC特征
ASR:
MFCC特征→文本"明天北京气温多少度"
NLP:
解析为
{intent:query_weather, location:北京, date:明天}TTS:
生成语音回复"明天北京最高气温25度,多云转晴"
关键区别总结
|------|---------------|-----------|-----------|------------|
| 维度 | 预处理 | ASR | NLP | TTS |
| 输入 | 原始音频 | 预处理后的特征 | ASR输出的文本 | NLP生成的文本 |
| 输出 | 声学特征矩阵 | 文本 | 结构化意图 | 语音波形 |
| 核心技术 | 信号处理(FFT/DSP) | 声学模型+语言模型 | 意图识别+实体抽取 | 韵律建模+声码器 |
| 评估指标 | SNR(信噪比) | WER(词错误率) | 意图准确率 | MOS(自然度评分) |总结
预处理是地基,决定上游天花板;
ASR是翻译官,连接声学与文本;
NLP是大脑,解析用户意图;
TTS是播音员,将结果转化为语音。 四者像工厂流水线,任何环节的缺陷都会影响最终体验,但通过联合优化(如ASR与NLP联合训练)可提升整体性能。
补充
小米的小爱同学AI是开源的吗?
小米的小爱同学AI并不是完全开源的。小爱同学是小米公司自主研发的人工智能助手,其核心技术(如语音识别、自然语言处理、语音合成等)属于小米的知识产权,并未对外公开源代码。
不过,小米在一些技术领域(如智能家居、物联网)提供了部分开源工具和SDK,供开发者使用。以下是相关情况的详细说明:
小爱同学的核心AI技术
语音识别(ASR):小爱同学的语音识别技术基于小米自研的模型,结合第三方技术(如百度、科大讯飞等),但具体实现细节和模型并未开源。
自然语言处理(NLP):小爱同学的语义理解和对话管理能力是小米的核心技术,未对外开源。
语音合成(TTS):小爱同学的语音合成技术也是小米自研的,未开源。
小米的开源资源
尽管小爱同学的核心AI技术未开源,但小米在以下领域提供了开源资源:
MACE(Mobile AI Compute Engine):
小米开源的移动端AI推理框架,支持将深度学习模型部署到移动设备上。
GitHub地址:MACE
MiAI:
小米的人工智能平台,提供了一些AI开发工具和SDK,但核心算法未开源。
IoT平台:
小米的智能家居平台(如MIoT)提供了开源的SDK和开发文档,方便开发者接入小米生态。
小爱同学的开发工具
小米为开发者提供了一些小爱同学相关的开发工具和API,但核心AI技术仍然封闭:
小爱开放平台:
小米为开发者提供了小爱同学的技能开发平台,允许开发者创建自定义技能(如控制智能家居、查询天气等)。
官网:小爱开放平台
小爱同学SDK:
小米提供了一些小爱同学的SDK,供开发者在应用中集成语音交互功能,但核心AI模型未开源。
为什么小爱同学不开源?
商业竞争:AI技术是小米的核心竞争力之一,开源可能会削弱其技术优势。
知识产权保护:小爱同学的语音识别、NLP等技术涉及大量专利和知识产权,开源可能引发侵权风险。
安全性考虑:AI技术涉及用户隐私和数据安全,开源可能增加安全风险。
如何获取类似小爱同学的功能?
如果希望开发类似的语音助手功能,可以使用以下开源或第三方技术:
语音识别(ASR):
Kaldi:开源的语音识别工具包。
DeepSpeech:Mozilla开源的端到端语音识别引擎。
自然语言处理(NLP):
Rasa:开源的对话管理和NLP框架。
Transformers:Hugging Face提供的预训练语言模型库。
语音合成(TTS):
Tacotron 2:Google开源的端到端语音合成模型。
WaveNet:DeepMind开源的高质量语音合成模型。
总结
小爱同学的核心AI技术(如语音识别、NLP、TTS)并未开源,但小米提供了部分开发工具和SDK,方便开发者接入其生态系统。如果需要类似的功能,可以使用开源的AI技术(如Kaldi、Rasa、Tacotron等)进行开发。
嵌入式智能语音助手方案推荐总结在嵌入式设备上实现智能语音助手,需要综合考虑硬件性能、语音识别精度、功耗和成本 。以下是针对不同场景的推荐方案,涵盖本地唤醒词识别、语音交互、云端语义理解等关键功能。
硬件平台选型
(1) 低功耗MCU方案(关键词唤醒+简单指令)
适用场景:智能家居控制、工业设备语音指令
推荐芯片:
STM32H743(Cortex-M7,带硬件浮点,适合轻量级语音处理)
ESP32-S3(双核Xtensa LX7,支持Wi-Fi/BLE,内置神经网络加速)
Nordic nRF5340(低功耗蓝牙+语音前端处理)
麦克风:数字麦克风(如INMP441,PDM接口)
方案特点:
本地运行唤醒词检测(如"Hey Siri"),通过串口/UART输出指令。
支持离线语音识别(10~20个固定命令词)。
功耗低(<10mA),适合电池供电设备。
推荐算法
唤醒词引擎:
Picovoice Porcupine(支持自定义唤醒词,免费开源)
Edge Impulse(可视化训练关键词模型)
语音识别:
TensorFlow Lite Micro(轻量级ASR模型)
Vosk(小型嵌入式语音识别库)
(2) 中端MPU方案(本地语音识别+云端交互)
适用场景:智能音箱、车载语音助手
推荐芯片:
瑞芯微RK3308(Cortex-A35,内置音频DSP,支持8麦克风阵列)
全志R329(双核A53 + 玄铁DSP,专为语音优化)
NXP i.MX RT1170(Cortex-M7 + Cortex-M4,高性能低功耗)
麦克风:数字麦克风阵列(如Knowles SPH0645)
方案特点:
本地处理唤醒词和简单指令(如"播放音乐")。
复杂请求(如"今天天气如何")通过Wi-Fi/4G上传云端(如阿里云/Google STT)。
支持回声消除(AEC)、降噪(ANS)算法。
推荐算法
本地语音识别:
Coqui STT(开源语音识别,支持嵌入式Linux)
Snowboy(热词检测+轻量级ASR)
云端交互:
阿里云智能语音交互(中文优化,高准确率)
Google Assistant SDK(多语言支持)
(3) 高性能AI芯片方案(全功能语音助手)
适用场景:高端智能音箱、带屏交互设备
推荐芯片:
晶晨A311D(4核A73 + NPU 5TOPS,支持8K视频+语音处理)
瑞芯微RK3588(8核A76 + NPU 6TOPS,支持多模态交互)
高通QCS8250(AI加速,支持远场语音+摄像头融合)
麦克风:6~8麦克风环形阵列(如楼氏SiSonic)
方案特点:
本地运行完整语音识别(如Vosk大模型)。
支持自然语言理解(NLU)和多媒体控制(播放/暂停)。
可扩展视觉交互(如人脸识别、手势控制)。
推荐算法
全链路语音方案:
Rhino(本地语义理解)
Mycroft(开源语音助手,支持嵌入式Linux)
软件架构设计
(1) 本地+云端混合架构
(2) 关键模块实现
音频前端处理(必选)
降噪(ANS):使用RNNoise或SpeexDSP。
回声消除(AEC):适用实时交互场景(如通话)。
语音活动检测(VAD):减少无效音频上传(如WebRTC VAD)。
唤醒词检测(必选)
开源:Porcupine、Snowboy。
自训练:Edge Impulse + TensorFlow Lite。
语音识别(ASR)
离线:Vosk、Coqui STT。
在线:阿里云/Google STT。
语义理解(NLU)
本地:Rhino、Rasa。
云端:Dialogflow、阿里云NLP。
语音合成(TTS)
离线:eSpeak、Flite(英文)/Edge-TTS(中文)。
在线:Google TTS、Azure Speech。
开发工具与资源
硬件开发板:
瑞芯微RK3308开发板(8麦克风阵列支持)
ESP32-S3-Korvo(语音识别参考设计)
数据集:
Google Speech Commands(关键词训练)
AISHELL-1(中文语音数据集)
调试工具:
Audacity:分析麦克风采集的音频质量。
Wireshark:监控云端API通信。
方案选型对比
|-------------------|---------------|-------------|-----------|
| 方案 | 优势 | 缺点 | 适用场景 |
| STM32 + Porcupine | 超低功耗,成本<10美元 | 仅支持简单指令 | 智能开关、工业控制 |
| RK3308 + Vosk | 本地识别,支持100+词条 | 需外接Wi-Fi模块 | 智能音箱、车载设备 |
| RK3588 + 阿里云 | 全功能语音助手,高准确率 | 成本高(>50美元) | 高端带屏设备 |注意事项
麦克风布局:线性阵列适合定向拾音,环形阵列支持360°收音。
功耗优化:唤醒词检测时CPU休眠,仅DSP工作(如RK3308的"低功耗监听模式")。
多语言支持:Vosk/Coqui STT支持中文,Picovoice需定制模型。
总结
低成本控制类设备 :选STM32 + 关键词唤醒(如智能灯控)。
智能音箱/车载中端设备 :选RK3308/R329 + 本地ASR + 云端NLU。
高端交互设备 :选RK3588/A311D + 全链路语音方案。
根据需求选择硬件和算法组合后,可通过优化降噪算法和模型量化进一步提升体验。
嵌入式里有什么音频处理的现成库吗?
在嵌入式系统中进行音频处理,可以选择多种现成的轻量级库,这些库针对资源受限环境(如MCU、DSP)进行了优化。以下是分类整理的嵌入式音频处理库及其适用场景:
通用音频处理库
(1) ARM CMSIS-DSP
适用平台:所有ARM Cortex-M/R/A系列MCU
核心功能:
FFT/IFFT(支持定点/浮点)
滤波器(FIR/IIR)、卷积、相关运算
音频特征提取(如MFCC)
优势:
ARM官方优化,无动态内存分配
提供汇编级加速(如Cortex-M4的SIMD指令)
代码示例(计算FFT):
#include "arm_math.h" arm_rfft_fast_instance_f32 fft_handle; arm_rfft_fast_init_f32(&fft_handle, 512); // 512点FFT arm_rfft_fast_f32(&fft_handle, input, output, 0); // 计算FFT(2) KissFFT
特点:
纯C实现,代码精简(<2KB Flash)
支持定点/浮点运算
适用场景:资源极度受限的MCU(如M0内核)
语音编解码库
(1) Opus(嵌入式版本)
特点:
支持8-48kHz采样率,码率6-510kbps
低复杂度模式(适合MCU)
配置裁剪:
./configure --enable-fixed-point --disable-float-api
(2) Codec2
特点:
超低码率(2400bps)语音编码
适合窄带通信(如LoRa语音传输)
语音增强库
(1) SpeexDSP
功能:
回声消除(AEC)
噪声抑制(DENOISE)
支持定点运算(适合无FPU的MCU)
示例代码(降噪):
SpeexPreprocessState *st = speex_preprocess_state_init(FRAME_SIZE, 16000); speex_preprocess_ctl(st, SPEEX_PREPROCESS_SET_NOISE_SUPPRESS, -20); // 降噪强度 speex_preprocess_run(st, audio_frame); // 处理一帧音频(2) RNNoise(嵌入式移植版)
特点:
基于深度学习的实时降噪
需~20MHz主频(Cortex-M4F实测)
资源占用:
Flash: ~50KB
RAM: ~10KB
硬件厂商专用库
|-----|----------------------|--------------------|-----------------|
| 厂商 | 库名称 | 特色功能 | 典型平台 |
| ST | STM32 Audio BSP | 硬件加速FFT,AEC算法 | STM32F4/H7 |
| ESP | ESP-ADF | 多麦克风波束成形,WiFi音频传输 | ESP32/ESP32-S3 |
| NXP | MCUXpresso SDK Audio | 低功耗语音唤醒(VAD) | LPC55S06 |
| TI | TI DSPLib | 优化语音编解码(G.711/GSM) | C5000/C6000 DSP |开源轻量级项目
(1) TinyALSA
特点:
针对嵌入式Linux的音频驱动框架
支持PCM设备控制(如采样率、声道配置)
适用场景:树莓派、Allwinner芯片等Linux嵌入式设备
(2) LiquidDSP
功能:
自适应滤波(LMS/RLS)
音频压缩与解调
深度学习推理框架(音频相关)
(1) TensorFlow Lite Micro
应用场景:
关键词唤醒(KWS)
语音命令识别
模型示例:
MicroSpeech(仅需~20KB RAM)
(2) STM32Cube.AI
流程:
训练模型(如基于Mel频谱的CNN)
通过STM32CubeMX转换为C代码
部署到STM32(支持8-bit量化)
选型建议
按需求快速匹配
|--------------|-----------------------|----------------|
| 需求 | 推荐库 | 资源消耗 |
| 基础FFT/滤波 | CMSIS-DSP / KissFFT | <5KB RAM |
| 实时降噪 | SpeexDSP / RNNoise | 10-50KB RAM |
| 低码率语音传输 | Opus / Codec2 | 20-100KB Flash |
| 硬件加速(如STM32) | STM32 Audio BSP | 依赖芯片外设 |
| 深度学习关键词检测 | TensorFlow Lite Micro | 50-200KB Flash |开发注意事项
内存优化:
使用静态内存分配(避免动态
malloc)启用芯片的硬件加速(如STM32的CRC计算加速滤波)
实时性保障:
采用DMA传输音频数据(减少CPU中断开销)
使用RTOS任务优先级调度(如FreeRTOS)
调试工具:
Audacity:分析处理前后的音频波形
SEGGER Ozone:实时监控DSP运算耗时
示例项目框架(STM32 + CMSIS-DSP)
// 在STM32CubeIDE中配置 void ProcessAudio(int16_t *input, int16_t *output, uint16_t len) { float32_t fft_in[256], fft_out[256]; // 转换为浮点 arm_q15_to_float(input, fft_in, len); // 计算FFT arm_rfft_fast_instance_f32 fft; arm_rfft_fast_init_f32(&fft, 256); arm_rfft_fast_f32(&fft, fft_in, fft_out, 0); // 应用滤波器(示例:低通滤波) // ...此处添加滤波代码... // 转换回整型 arm_float_to_q15(fft_out, output, len); }扩展方向
多麦克风处理 : 结合波束成形算法(如GCC-PHAT)实现声源定位。
边缘AI : 使用SensML (CEVA)或Cadence HiFi DSP部署神经网络音频处理。
嵌入式音频处理的核心是平衡性能与资源,建议优先选择芯片厂商提供的优化库(如ST/ESP/NXP的SDK),再通过开源库补充特定功能。
