🌟 2025:生物AI的"DeepSeek时刻"
当整个中文互联网为国产大语言模型DeepSeek欢呼时,生命科学界正悄然掀起一场静默革命------由Arc Institute领衔,斯坦福、UC Berkeley、哥大、UCSF携手英伟达等顶尖AI企业,共同推出百亿参数级生物语义理解引擎Evo2!这个能直接"读懂"核苷酸语言的神奇模型,正在重新定义我们对基因密码的认知方式🧬
🌟模型亮点速览:
-
🧬 直接解析核苷酸序列的"生物语言"
-
🚀 支持8192长度(base模型)1 百万(完整模型)超长基因片段处理
-
🌍 跨物种基因理解能力升级
-
🔓 完全开源!支持NVIDIA NIM云端部署和本地运行
(👉小贴士:想了解Evo1到Evo2的架构革命?快在评论区催更技术解析专题!)
🔍本期实战目标:
🛠️ 从零开始的保姆级教程
🚀用Embedding+DNN实现BRCA1突变效应预测
📊性能飞跃:相较于仅用score函数差值预测的0.7 AUROC(Fair级),Embedding+DNN方案直冲0.9 AUROC(Good级)📈
✨ 小贴士:
我从零开始,租用新的Auto-dl服务器,搭建环境,重跑code,以保证每个新手小白都能有成功感地一次性运行成功,不产生任何报错。已准备好开箱即用的Auto-dl镜像,评论区@zylAK(我的博客园昵称)即刻获取🚀 如果觉得帖子不错欢迎转发zylAK的帖子给小伙伴们,你们的支持是我更新的动力。如果还想了解Evo2更多的应用,例如如何设计新的核酸序列、如何获得可解释的大语言模型理解等,都可以在评论区催更。
废话不多说,以Auto-dl云服务器为例,直接上代码:
一、前期准备:
1.1 云服务器配置:
1.2 开启Auto-dl的学术加速并从github上下载Evo2项目文件,激活:
命令行是:
1 source /etc/network_turbo #开启学术加速
2 git clone https://github.com/ArcInstitute/evo2.git #下载Evo2项目文件
3 cd evo2 #进入项目路径4 git clone https://github.com/Zymrael/vortex.git #手动安装vortex依赖5 python setup.py install #项目激活1.3 从hugging face镜像站hf-mirror上下载对应Evo2模型,并存储在本地,以供后续调用。目前4090机器的配置可以运行1b和7b的模型(完整和base版均可),40b模型可能需要内存更高的机器且需要多卡GPU部署,这一期暂不讨论。三种参数量的模型效果相差不那么明显。
命令行是:
1 cd /root/autodl-tmp/evo2/evo2_models #在项目文件夹中单独创建一个evo2_model文件夹用于保存下载的模型,这样就不用每次调用时重新下载了
2
3 #设置huggingface-cli下载的镜像网址
4 export HF_ENDPOINT=https://hf-mirror.com
5
6 #下载evo2_1b_base模型为例
7 huggingface-cli download --resume-download arcinstitute/evo2_1b_base --local-dir /root/autodl-tmp/evo2/evo2_models正确的下载运行时会有如下的输出(进度条逐渐增加)

二、模型加载与Embeddings提取
2.1 导入项目需要用到的所有packages
1 from Bio import SeqIO
2 import gzip
3 import matplotlib.pyplot as plt
4 import numpy as np
5 import pandas as pd
6 import os
7 import seaborn as sns
8 from sklearn.metrics import roc_auc_score
9 import numpy as np
10 import torch
11 import torch.nn as nn
12 from torch.utils.data import DataLoader, TensorDataset
13 from sklearn.model_selection import train_test_split
14 from sklearn.metrics import roc_auc_score
15 from torch.optim.lr_scheduler import ReduceLROnPlateau
16 from pathlib import Path
17 from tqdm.notebook import tqdm
18 import transformer_engine.pytorch as te
19 from transformer_engine.common import recipe可能会出现报错:

但完全不影响后续代码运行。如果后期flash-attn包升级造成冲突,可以指定安装2.7.4版本。
2.2 加载模型
os.chdir('/root/autodl-tmp/evo2/evo2')
model_path = "/root/autodl-tmp/evo2/evo2_models/evo2_1b_base/evo2_1b_base.pt"
from evo2.models import Evo2
model = Evo2(model_name='evo2_1b_base',local_path=model_path)2.3 加载并解析输入数据------BRCA1数据,包括序列数据,突变位点,突变效应分类。详细说明请见Evo2项目案例介绍:https://github.com/ArcInstitute/evo2/tree/main/notebooks/brca1
1 os.chdir('/root/autodl-tmp/evo2')
brca1_df = pd.read_excel( 2 os.path.join('notebooks', 'brca1', '41586_2018_461_MOESM3_ESM.xlsx'),
3 header=2,
4 )
5 brca1_df = brca1_df[[
6 'chromosome', 'position (hg19)', 'reference', 'alt', 'function.score.mean', 'func.class',
7 ]]
8
9 # 对列名重命名
10 brca1_df.rename(columns={
11 'chromosome': 'chrom',
12 'position (hg19)': 'pos',
13 'reference': 'ref',
14 'alt': 'alt',
15 'function.score.mean': 'score',
16 'func.class': 'class',
17 }, inplace=True)
18
19 # 将突变效应命名为二分类标签
20 brca1_df['class'] = brca1_df['class'].replace(['FUNC', 'INT'], 'FUNC/INT')
21
22 WINDOW_SIZE = 8192
23
24 # 读取17号染色体参考基因组序列
25 with gzip.open(os.path.join('notebooks', 'brca1', 'GRCh37.p13_chr17.fna.gz'), "rt") as handle:
26 for record in SeqIO.parse(handle, "fasta"):
27 seq_chr17 = str(record.seq)
28 break
29
30 def parse_sequences(pos, ref, alt):
31 """
32 解析参考序列(未突变序列)和突变序列
33 """
34 p = pos - 1 # Convert to 0-indexed position
35 full_seq = seq_chr17
36
37 ref_seq_start = max(0, p - WINDOW_SIZE//2)
38 ref_seq_end = min(len(full_seq), p + WINDOW_SIZE//2)
39 ref_seq = seq_chr17[ref_seq_start:ref_seq_end]
40 snv_pos_in_ref = min(WINDOW_SIZE//2, p)
41 var_seq = ref_seq[:snv_pos_in_ref] + alt + ref_seq[snv_pos_in_ref+1:]
42
43 # 数据合理性检查
44 assert len(var_seq) == len(ref_seq)
45 assert ref_seq[snv_pos_in_ref] == ref
46 assert var_seq[snv_pos_in_ref] == alt
47
48 return ref_seq, var_seq
49
50 # 给参考序列一个索引值
51 ref_seqs = []
52 ref_seq_to_index = {}
53
54 # 解析序列并存储索引值
55 ref_seq_indexes = []
56 var_seqs = []
57
58 for _, row in brca1_df.iterrows():
59 ref_seq, var_seq = parse_sequences(row['pos'], row['ref'], row['alt'])
60
61 # 给当前循环到的参考序列获取/创建索引
62 if ref_seq not in ref_seq_to_index:
63 ref_seq_to_index[ref_seq] = len(ref_seqs)
64 ref_seqs.append(ref_seq)
65
66 ref_seq_indexes.append(ref_seq_to_index[ref_seq])
67 var_seqs.append(var_seq)
68
69 ref_seq_indexes = np.array(ref_seq_indexes)2.4 以BCRA1序列为输入,提取全部全部层的Embedding并保存下来
1 # ========== 配置参数 ==========
2 device = next(model.model.parameters()).device
3 candidate_layers = [f"blocks.{i}.pre_norm" for i in range(25)]
4 batch_size = 8 # 根据GPU显存调整
5 save_dir = "extract_embeddings"
6 os.makedirs(save_dir, exist_ok=True)
7
8 # ========== 批量嵌入提取 ==========
9 def process_sequences(seq_list, layer_name, desc, prefix="ref"):
10 """批量处理序列嵌入并确保文件保存"""
11 # 生成标准化文件名
12 sanitized_layer = layer_name.replace('.', '_')
13 memmap_path = os.path.join(save_dir, f"{prefix}_{sanitized_layer}.npy")
14
15 # 创建内存映射文件并立即保存头信息
16 emb_mmap = np.lib.format.open_memmap(
17 memmap_path,
18 dtype=np.float32,
19 mode='w+',
20 shape=(len(seq_list), 1920)
21 )
22
23 try:
24 # 分批处理
25 for i in tqdm(range(0, len(seq_list), batch_size), desc=desc, leave=False):
26 batch_seqs = seq_list[i:i+batch_size]
27
28 # Tokenize并填充
29 batch_tokens = []
30 for seq in batch_seqs:
31 tokens = model.tokenizer.tokenize(seq)
32 batch_tokens.append(torch.tensor(tokens, dtype=torch.long))
33
34 max_len = max(len(t) for t in batch_tokens)
35 padded_tokens = torch.stack([
36 torch.nn.functional.pad(t, (0, max_len - len(t))) for t in batch_tokens
37 ]).to(device)
38
39 # 前向传播
40 with torch.no_grad():
41 _, emb_dict = model.forward(
42 padded_tokens,
43 return_embeddings=True,
44 layer_names=[layer_name]
45 )
46
47 # 写入内存映射文件
48 batch_emb = emb_dict[layer_name].float().mean(dim=1).cpu().numpy()
49 emb_mmap[i:i+len(batch_emb)] = batch_emb
50
51 # 立即刷新写入磁盘
52 emb_mmap.flush()
53
54 finally:
55 # 确保文件关闭
56 del emb_mmap
57
58 return memmap_path
59
60 # ========== 主流程 ==========
61 # 预先生成全局索引文件 (只需保存一次)
62 np.save(os.path.join(save_dir, "ref_idx.npy"), ref_seq_indexes)
63
64 for layer_name in tqdm(candidate_layers, desc="🔍 Processing Layers"):
65 # 处理参考序列 (生成 ref_blocks_0_pre_norm.npy)
66 _ = process_sequences(
67 ref_seqs,
68 layer_name,
69 f"🧬 Ref {layer_name}",
70 prefix="ref"
71 )
72
73 # 处理变异序列 (生成 var_blocks_0_pre_norm.npy)
74 _ = process_sequences(
75 var_seqs,
76 layer_name,
77 f"🧬 Var {layer_name}",
78 prefix="var"
79 )正确运行后有如下输出显示:

三、基于保存的Embeddings开发下游的突变效应预测器:
3.1 Embedding数据加载函数的定义
1 # ========== 新增配置参数 ==========
2 embed_dir = Path("extract_embeddings")
3 layers_to_train = [f"blocks.{i}.pre_norm" for i in range(25)] # 需要训练的层列表,全部的25层
4 results_dir = Path("training_results")
5 results_dir.mkdir(exist_ok=True)
6
7 # ========== 数据加载函数 ==========
8 def load_layer_data(layer_name):
9 """加载指定层的嵌入数据和标签"""
10 sanitized = layer_name.replace('.', '_')
11
12 # 加载嵌入数据(内存映射模式)
13 ref_emb = np.load(embed_dir/f"ref_{sanitized}.npy", mmap_mode='r')
14 var_emb = np.load(embed_dir/f"var_{sanitized}.npy", mmap_mode='r')
15 ref_idx = np.load(embed_dir/"ref_idx.npy")
16
17 # 拼接特征
18 X = np.concatenate([ref_emb[ref_idx], var_emb], axis=1)
19
20 # 获取标签(从原始数据框)
21 y = brca1_df['class'].map({'FUNC/INT':0, 'LOF':1}).values
22
23 return X, y3.2 Embeddings数据正确性检验。主要是验证数据是否存在,以及是否符合Evo2_1b_base模型中间层的维度(1920维)
1 # 示例,检查第24层文件是否存在
2 assert os.path.exists("extract_embeddings/ref_blocks_24_pre_norm.npy")
3 assert os.path.exists("extract_embeddings/var_blocks_24_pre_norm.npy")
4
5 # 验证嵌入维度
6 ref_emb = np.load("extract_embeddings/ref_blocks_24_pre_norm.npy", mmap_mode='r')
7 var_emb = np.load("extract_embeddings/var_blocks_24_pre_norm.npy", mmap_mode='r')
8 print(f"参考序列嵌入维度: {ref_emb.shape}") # 应为 (N_ref, 1920)
9 print(f"变异序列嵌入维度: {var_emb.shape}") # 应为 (N_ref, 1920)
10
11 for layer_name in layers_to_train:
12 print(layer_name)
13 X, y = load_layer_data(layer_name)
14 print(X.shape)3.3 (重要)定义分离器DNN的结构(仿照原文中的DNN结构)
1 # ========== 模型架构 ==========
2 class BRCA1Classifier(nn.Module):
3 def __init__(self, input_dim):
4 super().__init__()
5 self.net = nn.Sequential(
6 nn.Linear(input_dim, 512),
7 nn.ReLU(),
8 nn.BatchNorm1d(512),
9 nn.Dropout(0.3),
10
11 nn.Linear(512, 128),
12 nn.ReLU(),
13 nn.BatchNorm1d(128),
14 nn.Dropout(0.3),
15
16 nn.Linear(128, 32),
17 nn.ReLU(),
18 nn.BatchNorm1d(32),
19
20 nn.Linear(32, 1),
21 nn.Sigmoid()
22 )
23
24 def forward(self, x):
25 return self.net(x)3.4 (重要)训练流程定义
1 # ========== 训练流程 ==========
2 def train_for_layer(layer_name):
3 """单层训练流程"""
4 print(f"\n=== 开始训练层 {layer_name} ===")
5
6 # 加载数据
7 X, y = load_layer_data(layer_name)
8
9 # 数据划分
10 X_temp, X_test, y_temp, y_test = train_test_split(
11 X, y, test_size=0.2, random_state=42, stratify=y
12 )
13 X_train, X_val, y_train, y_val = train_test_split(
14 X_temp, y_temp, test_size=0.25, random_state=42, stratify=y_temp
15 )
16
17 # 转换为PyTorch Dataset
18 train_dataset = TensorDataset(torch.FloatTensor(X_train), torch.FloatTensor(y_train).unsqueeze(1))
19 val_dataset = TensorDataset(torch.FloatTensor(X_val), torch.FloatTensor(y_val).unsqueeze(1))
20 test_dataset = TensorDataset(torch.FloatTensor(X_test), torch.FloatTensor(y_test).unsqueeze(1))
21
22 # ========== 训练配置 ==========
23 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
24 model = BRCA1Classifier(X.shape[1]).to(device)
25
26 # 优化器和损失函数
27 optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
28 criterion = nn.BCELoss()
29
30 # 学习率调度器
31 scheduler = ReduceLROnPlateau(
32 optimizer,
33 mode='max',
34 factor=0.5,
35 patience=20,
36 min_lr=1e-6
37 )
38
39 # 数据加载器
40 train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
41 val_loader = DataLoader(val_dataset, batch_size=128)
42 test_loader = DataLoader(test_dataset, batch_size=128)
43
44 # ========== 训练循环 ==========
45 best_auc = 0
46 patience_counter = 0
47 max_patience = 100
48
49 for epoch in range(500):
50 # 训练阶段
51 model.train()
52 train_loss = 0
53 for inputs, labels in train_loader:
54 inputs, labels = inputs.to(device), labels.to(device)
55
56 optimizer.zero_grad()
57 outputs = model(inputs)
58 loss = criterion(outputs, labels)
59
60 # 梯度裁剪
61 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
62
63 loss.backward()
64 optimizer.step()
65 train_loss += loss.item() * inputs.size(0)
66
67 # 验证阶段
68 model.eval()
69 val_loss = 0
70 y_true, y_pred = [], []
71 with torch.no_grad():
72 for inputs, labels in val_loader:
73 inputs, labels = inputs.to(device), labels.to(device)
74 outputs = model(inputs)
75 val_loss += criterion(outputs, labels).item() * inputs.size(0)
76 y_true.extend(labels.cpu().numpy())
77 y_pred.extend(outputs.cpu().numpy())
78
79 # 计算指标
80 train_loss /= len(train_loader.dataset)
81 val_loss /= len(val_loader.dataset)
82 val_auc = roc_auc_score(y_true, y_pred)
83
84 # 学习率调整
85 scheduler.step(val_auc)
86
87 # 早停机制
88 if val_auc > best_auc:
89 best_auc = val_auc
90 patience_counter = 0
91 torch.save(model.state_dict(), 'best_model.pth')
92 else:
93 patience_counter += 1
94 if patience_counter >= max_patience:
95 print(f"早停触发于第{epoch}轮")
96 break
97
98 # 打印进度
99 print(f"Epoch {epoch+1}: "
100 f"Train Loss: {train_loss:.4f} | "
101 f"Val Loss: {val_loss:.4f} | "
102 f"Val AUROC: {val_auc:.4f}")
103
104 # ========== 最终评估 ==========
105 model.load_state_dict(torch.load('best_model.pth'))
106 model.eval()
107 y_test_true, y_test_pred = [], []
108 with torch.no_grad():
109 for inputs, labels in test_loader:
110 inputs, labels = inputs.to(device), labels.to(device)
111 outputs = model(inputs)
112 y_test_true.extend(labels.cpu().numpy())
113 y_test_pred.extend(outputs.cpu().numpy())
114
115 test_auc = roc_auc_score(y_test_true, y_test_pred)
116 print(f"\n最终测试集AUROC: {test_auc:.4f}")
117
118 # 保存结果
119 sanitized = layer_name.replace('.', '_')
120 torch.save(model.state_dict(), results_dir/f"best_model_{sanitized}.pth")
121 np.save(results_dir/f"test_pred_{sanitized}.npy", y_test_pred)
122
123 return test_auc3.5 执行训练流程
1 # ========== 主执行流程 ==========
2 if __name__ == "__main__":
3 results = {}
4 for layer in tqdm(layers_to_train, desc="Training Layers"):
5 try:
6 auc = train_for_layer(layer)
7 results[layer] = auc
8 except Exception as e:
9 print(f"训练层 {layer} 时出错: {str(e)}")
10 results[layer] = None
11
12 # 保存最终结果
13 with open(results_dir/"summary.txt", "w") as f:
14 for layer, auc in results.items():
15 f.write(f"{layer}: {auc:.4f}\n")运行成功后会有类似如下输出:
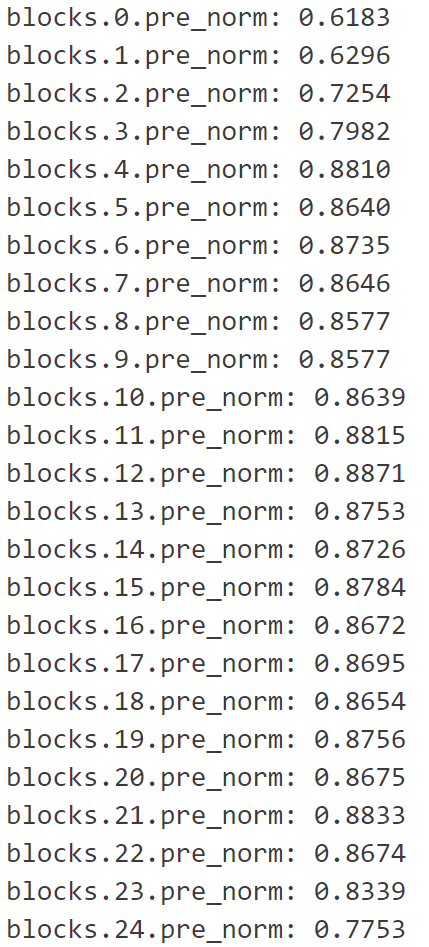
最后,我们可以通过检查summary.txt获取训练最优的训练结果是利用哪一层Embedding。我训练的结果显示第12层embedding训练得到的DNN预测器效果最好,小伙伴伴们也可以自己尝试不同的模型下,不同的DNN结构,哪一层能获得最好的预测效果。