哈哈最近感觉自己不像算法倒像是DB,整天围着ES打转,今天查IO,明天查内存,一会优化查询,一会优化吞吐。毕竟RAG离不开知识库,我们的选型是ES,于是这一年都是和ES的各种纠葛。所以顺手把近期获得的一些小tips记下来,万一有人和我踩进了一样的坑,也能早日爬出来。当前使用的ES版本是8.13,和7版本有较大的差异,用7.X的朋友这一章可能有不适配。本章主要覆盖以下
- 多Query向量查询的各种方案:Script,Knn(mesearch)
- KNN查询IOUtil过高问题排查
- 如何使用Filter查询更高效
多Query向量查询的各种方法
大模型的知识库都离不开向量查询,并且当前的RAG往往会对用户query进行多角度的改写和发散,因此会涉及多query同时进行向量查询。如果用ES实现的话,常用的有以下几种形式
- 多向量Pooling Script查询:多个query的向量平均后进行查询,查询效果不好,因为Pooling往往会损失很多信息,虽然把多个向量压缩成了一个向量,查询效率更高压力更小,但是效果差的离谱。但是对使用ES 7.X版本的朋友可能也是一种选择。
python
query_body = {
"size":10
"query": {
"bool": {
"must": [{
"script_score": {
"query": {"match_all": {}},
"script": {
"source": f"cosineSimilarity(params.query_vector, 'vectors')",
"params": {"query_vector": avg_embedding}
}
}
}]
}
}
}- 向量script循环取cosine的最大值或者平均值:使用ES 7且的朋友一般的选项,因为7的版本里部分没有KNN的支持,因此只能使用script线性遍历向量。而不把所有向量召回的内容都取回来进行重排序主要是IO的考虑,返回的条数更少传输压力更小。以下为python的查询示例,embedding_list是多query的向量数组。
python
query_body = {
"query": {
"function_score": {
"script_score": {
"script": {
"source": """
double max_score = -1.0;
if (doc[params.field].size() == 0) return 0; // 空值保护
for (int i=0; i<params.length; i++) {
double similarity = cosineSimilarity(
params.query_vectors[i],
params.field
);
max_score = Math.max(max_score, similarity);
}
return max_score;
""",
"params": {
"length": len(embedding_list),
"query_vectors": embedding_list,
"field": "vectors"
}
}
},
"boost_mode": "replace"
}
}
}
response = es.search(index=index, body=query_body)- 多向量KNN查询:用ES8版本的一般会考虑KNN查询,每个向量单查KNN,对同一个index的多条KNN查询推荐使用msearch组合查询并返回。
python
query_body = {
"query": {
"bool": {
"must": [{
"knn": {
"field": 'vectors',
"query_vector": embedding_item,
"num_candidates": 10
}
}]
}
}
}KNN查询IO打满的问题排查
在使用以上KNN搜索时,我们遇到一个问题,就是一使用KNN查询,IOUitl指标就会打满,进而影响其他所有查询任务,导致线上查询会Hang住,如下图所示。
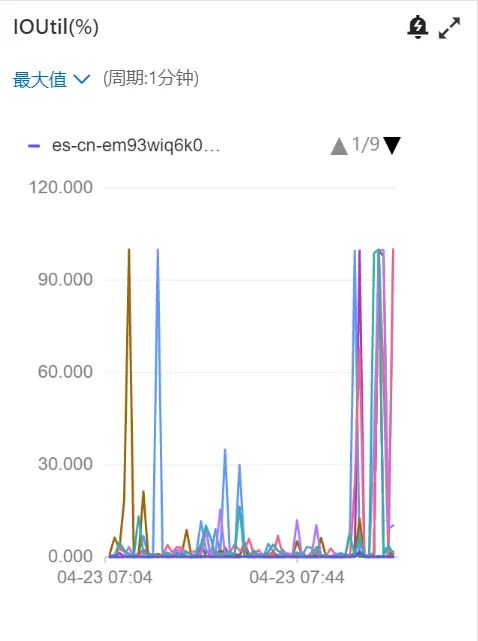
经过阿里ES大佬的帮助,我们定位了问题,核心是HNSW图向量没有加载到内存里,因此在查询时触发了向量加载,因此大量的IO都是在进行向量搬运操作,搬多久IO就打满多久,解决的方案主要分2步
第一步优化图大小,原始我们的图使用Float32存储的,ES8.15提供了int4,int8存储,8.17好像还提供压缩比例更高的存储方式,因此我们reindex了索引修改成了INT8存储。但是发现优化后IO指标并未下降。
于是就有了第二步预加载,大佬给出的解释是HNSW算法存在大量的随机读,除了HNSW图,还会读取原始或量化后的向量数据,这些数据也需要加载到内存中进行查询(从磁盘加载)。而解决这个问题的办法就是预加载。以int8_hnsw为例,预加载的方式如下,需要先关闭索引,完成预加载,再开启索引。因此必须在非业务使用期进行操作,百万级的索引大小大概几分钟就能完成以下操作,不过我们在预加载时有时会引起集群的不稳定,因此建议在业务低峰期操作。
txt
# 关闭索引
POST your_index/_close
# 调整preload参数
PUT your_index/_settings
{
"index.store.preload": ["vex", "veq"]
}
# 开启索引
POST your_index/_open只不过以上预加载存在一个问题,就是预加载的内容会持续存在缓存中,也算是用空间换时间的方案,如果有太多索引需要做预加载,应该会存在竞争关系,不过在我们的配置下还未出现这个问题,所以大家在预加载时需要关注下内存等指标变化
Filter的三种不同使用方式
依旧围绕向量搜索,在使用向量时在我们的场景中一般会有时间Filter,根据不同的时效性分层和时效性抽取结果选取不同的查询时间段,和整个index大小相比,时效性filter往往能大幅缩减查询的索引范围,但是使用filter的方式不同,对查询效率有较大影响。
- pre filter:过滤条件在knn的filter语句中
JSON
{"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}
]
}
}- post filter:过滤条件在bool的filter语句中
JSON
{
"bool": {
"must": [{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}],
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}]
}
}- 过滤条件在must语句中
JSON
{
"bool": {
"must": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
},
{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}]
}
}以上三种查询方式的对比如下
| Filter方式 | 查询效率 |
|---|---|
| Pre Filter | 查询效率最高,前置过滤会缩减knn查询范围提高查询效率 |
| Post Filter | 查询效率较低,在非KNN的其他查询场景这是查询效率最高的写法。但在KNN场景中会比只用KNN更慢,因为是在KNN搜索结果拿到后进行后置过滤,同时会导致最终返回的数量可能少于查询数量 |
| 过滤条件在must语句中 | 查询效率最低,在filter语句中ES会直接忽略不满足条件的文档,而在must语句中所有文档都会参与评分。并且Filter语句ES会缓存过滤条件使得后续查询更快而must不会进行缓存 |