AI创业失败,可私聊经验教训分享...
当前我唯一每个月付费的模型是ChatGPT,但昨天看了Google I/O 后,默默的打开了支付界面,国外做模型基建的大厂真的足够卷!

PS:本来这篇文章是懒得写的,因为基友沈旸已经写得不错了,但他文字有些绕口,所以我这里还是写写:用乐高的方式来创造未来,谷歌I/O 2025的AI魔法时刻
一句话描述Google I/O:
与其他Agent产品一致,从视频宣传来看:新一代模型正在把"写代码造软件"彻底变成了"拼乐高做体验"
接下来,AI会把普通人也拉进创作者的角色,但短时间各位专业同学还不必担心,因为坑一定有点多,长期的话创意比专业更重要了...
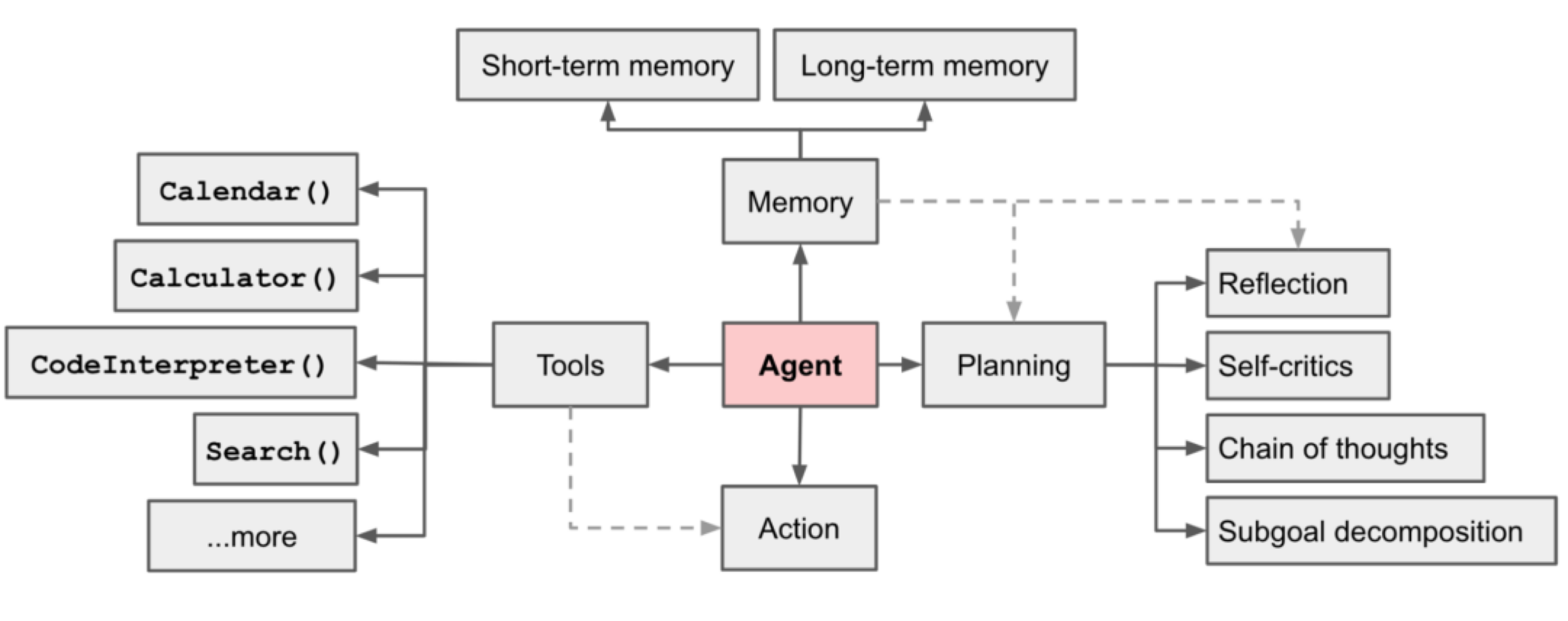
以下是一些会议要点,然后大家不要觉得内容多,跟不上了,事实上他依旧跳不出此图:
Gemini 2.5:更强大的模型
与GPT、LLama4的发布一致,模型开始支持百万token对话窗口了,如图所示:
关注Agent发展的同学一定会清楚:当前主要阻碍Agent的关卡有三:
- 记忆问题;
- 幻觉问题;
- 多模态问题;
事实上,更长的上下文token就是为解决记忆问题而生,但更长的token对模型的基础能力要求更高,因为更长的上下文可能更容易产生幻觉。
所以,这里有几个点大家要关注:
- **多模态 ≠ 多学科:**医疗、法律这类强门槛场景,缺的是结构化行业语料,更大上下文窗口并不能解决这个问题。比如星火 4.0 已经能把 CT 片子、检验单、语音病历一起读,但真正让它在三级医院排 T2 检查,还得有 结构化标注+合规流程 ;
- 记得住不代表拎得清: 百万 token 上下文只是把"全部信息"摊在桌面,缺少可靠检索与质量分级,一样会"记错重点",在这个角度来说 Attention is all you need;
- **治理成本上升:**模型新增 Deep Think 模式,但企业要启用 Deep Think 前,先把"推理路径留痕"写进合规手册,否则输出再复杂也无法审计;
Project Mariner + Agent Mode
我们之前聊过computer use,并且给了一个结论:体验并不好,还有很多小BUG。
他是由Anthropic(Claude母公司)在2024年10月推出。
目标是让AI像人类一样操作电脑:看屏幕、动光标、点按钮、打字,再这个基础上再扩展功能,比如帮订机票、填表格、查天气。
技术实现为:通过截屏+虚拟键盘鼠标模拟人类操作,类似于"教会实习生用电脑"。
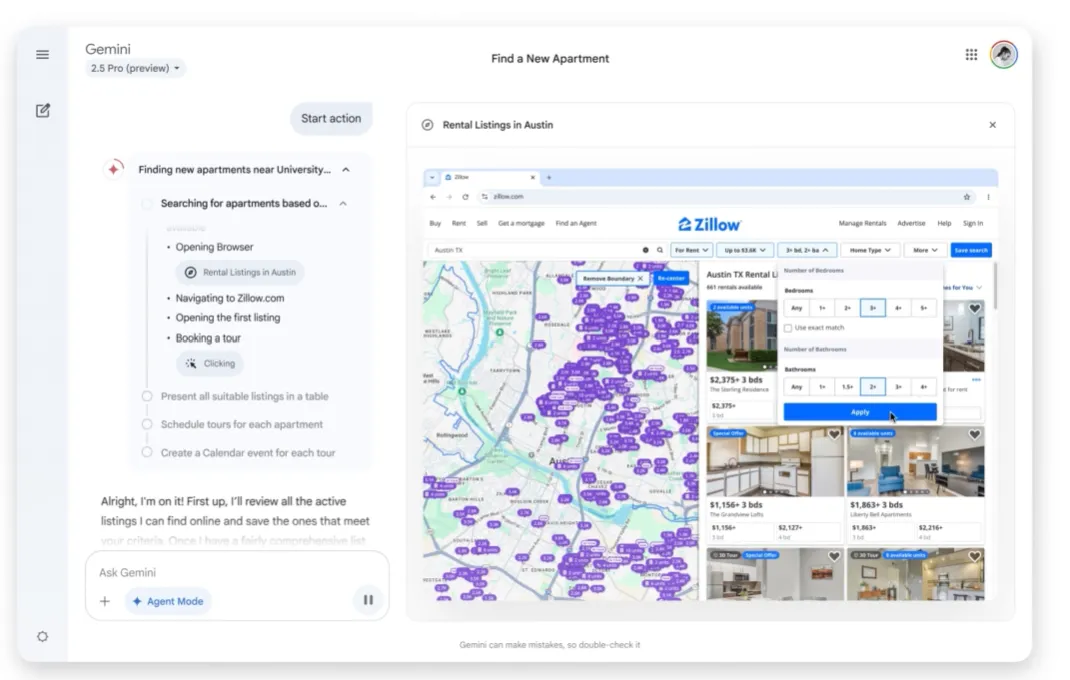
Project Mariner就屌了,他是 Google 在 2025 I/O 大会上公布的浏览器级 AI 代理原型。
**它运行在一组云端虚拟机里,像"数字人"一样用鼠标、键盘和登录态操作真实网页,并通过自然语言与用户沟通。**最新版本的三个关键卖点:
- 网页操作学习能力:用户示范一次完整流程(例如订火车票),Mariner 记录 DOM 结构、表单字段、验证码插桩位置→自动归纳成"任务脚本",此后遇到类似界面即可复用;
- **并行多任务:**一次可在 10 个沙箱浏览器里同时跑不同流程(查房源+填报表+比价);
- **Gemini 深度接入:**即将通过 Agent Mode 出现在 Gemini App/Search 侧边栏;API 已开放给 Automation Anywhere、UiPath 等 RPA 厂商做二次封装;
比如,你在找房,告诉它预算、位置偏好,它可以自动登录 Zillow 等网站,调整筛选器、比对选项,甚至调用 MCP 协议帮你预约看房:
这个东西大家并不陌生,国内其实也有一些对标品,最显眼的是Manus,其他还有:
钉钉新出的知识库自动化用 RPA + 规则引擎让文档自动归档、流转、审批;脚本级定制还能连 ERP、CRM 做端到端闭环;
另一方面,飞书智能伙伴自动生成会议纪要、分配待办,并能调用 JIRA、GitLab API 把 action 写进工单。
当这类产品都有一些问题:
- 网页改变,代理就会跟着翻车;
- 对于员工来说,真正的痛点不是"能不能录动作",而是谁来兜底异常?国内很多团队最后还是要给每条流程绑上人工二次审核;
换句话说,自动化类工具最怕出错,我之前为某个公司做了一块AI工具,最终导致裁员70%客服,但某次程序出问题,公司根本找不到那么多备用客服,导致了巨大损失,最终的结果是,他们又招了一批回来...
Canvas:对话就能搭出一个应用
这个东西约等于产品经理的低保真原型机,只要说一句"我要做英语测验网站",页面 + 题库 + 样式全自动!
这一切,无需写代码、也无需切 IDE。Canvas 就像一个"语言编程的乐高桌",你说想拼一个"城堡",它立刻递给你窗户、砖块、塔楼,一拼就成:
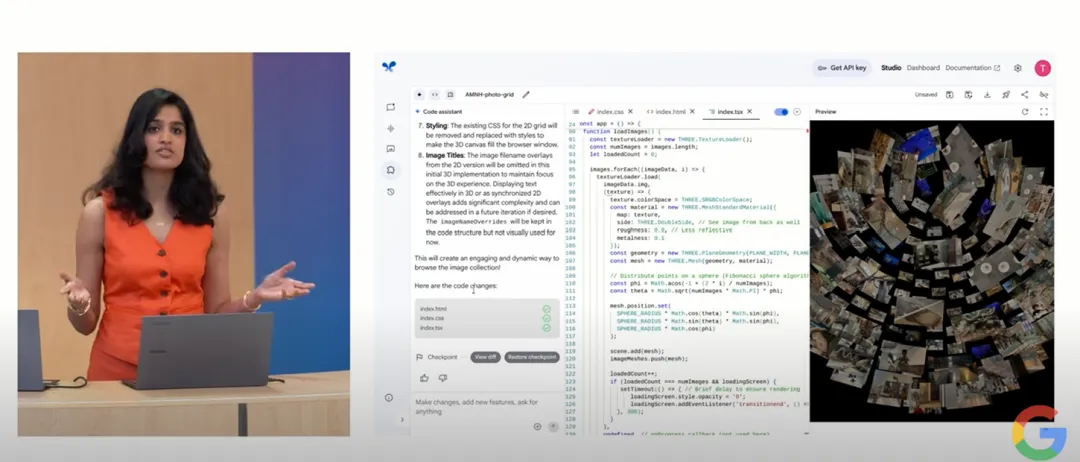
但这里不能看视频表现很友好,他很可能只适合 0→1 快速验证。
验证成功后, 1→10 之后接口、权限、性能,全是你要补的坑,这一步才是跟业务死磕的开始。
Flow + Veo 3 + Imagen 4
这是标准的视听"三件套",导演只剩审美!
其实今年在图像与视频侧AI在各种开挂,前些日子设计领域的Agent产品Loveart表现得非常不错:

而后Google马上展开会心一击,谷歌发布了三款创作者向的 AI 工具:
- Flow 脚本→分镜→配乐→配音一条龙;
- Veo 3 让 AI 视频摆脱"无声时代",支持原生音轨与物理细节;
- Imagen 4 图生图,2K 分辨率保持 Logo 与文字清晰;
这三者组合,就像是给创作者配齐了导演、摄影、视觉总监:

于是基友最近一直在鼓吹创业失败的我:

但其实这里也有几个要思考的点:
- **内容监管新考题:**Deepfake、版权爬虫全升级,企业如果想用来做广告,先把 Model Card + 审核流水准备齐;
- **创作者岗位重塑:**从"剪辑工"变"艺术总监",但审美差依旧一刀见血,AI 只能给你 70 分底稿,封神还靠人;
- **数据飞轮机会:**品牌若能把自有素材、视觉规范拿来做训练,反而能打造独家风格壁垒,垂直板块的应用可能是机会;
Project Astra:视觉突破
若前所述,长token解决的是记忆问题,那么听觉视觉问题当然要处理,所以Astra应运而生。
视频中是一位谷歌员工戴着眼镜,在展厅走来走去,让 AI 一路陪聊。
她拿着咖啡问:"我刚才在哪里买的这杯?"
AI 分析了杯子上的模糊图案,告诉她店名,还顺便推荐了类似口味的咖啡店。
她走到一面画着涂鸦的墙前问:"这是谁的作品?"
AI 实时识别图案,说出艺术家,还讲了背后的小故事。
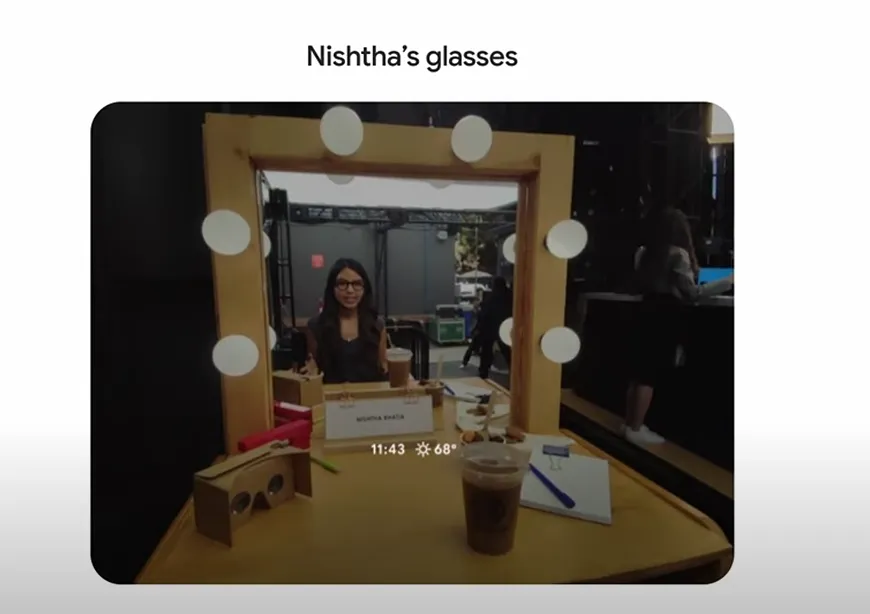
这种实时视觉 + 语音 + 100 万 token 记忆,像贴身纪录片导演。
其实这种眼镜之前就见过了,只不过这次穿上了AI的外衣,但这款产品要走向市场,依旧绕不过几个问题:
- **隐私与法规:**持续摄录+长期存储,GDPR/SOX/医疗 HIPAA......哪一条都够你写几百页合规文档;
- **硬件掣肘:**AR 眼镜要塞进 Gemini Nano,功耗、发热、散热还没看到终极方案,之前硬件的问题,现在也还在;
- **场景 ROI:**最后,各个公司不要跟风。维修、仓储、远程护理是刚需,娱乐打卡纯属"炫技 demo",企业别走错优先级;
搜索再进化
搜索也被彻底"拼乐高化"。一句复杂问题,Gemini 搜索自动拆分并聚合答案,还能上传视频请它诊断故障。
比如你可以问:"我家附近有什么适合初学者、提供折扣课的瑜伽班?距离不超过3公里,还要晚上开课。"
Gemini 搜索会:
- 找出你的位置
- 分析课程类型
- 识别营业时间和新手优惠
- 给出地图、链接和推荐理由
而且你可以点"更简洁"或"更详细",就像调节回答风格一样自然。
事实上我们之前就说过,浏览器正常逐渐AI知识库化,进一步正在Agent化,Google I/O 展示来说,他们确实也在这么做。
但要走向深入应用,我不知道其现在边界在哪,我之前是做AI + 医疗领域的,就随便说个问题对学术、医疗这类需要可追溯证据的环节,模糊引用没法做责任链。
另一方面,传统浏览器领域会收到绝对的冲击,比如SEO来说,内容站若只提供"干货片段",流量入口被截胡,用什么换广告营收?
最终问题会来到企业端,他们不会想贡献自己的数据被白嫖!
Gemini 无处不在
行业已经逐渐走向成熟,抬腕记笔记、车内自然语音回短信、XR 导航......整合体验一致性史无前例。
在 Android 16 和 Wear OS 6 中,Gemini 将以系统服务的方式存在,协助你完成一切操作。
只不过,非要杠一句的话,当前Android碎片化还是挺严重的,OEM 要不要跟?跟了之后系统权限、隐私弹窗谁负责?
我在导航时候跳出一个游戏窗口,想想就很刺激!
另一方面,开发者负担可能会变重,统一 API 表面简单,实际要维护多端 Feature Flag,别高估 Google 对低端机的兼容投入。
写代码像拼模板
对程序员来说,谷歌也没忘记他们的"拼乐高愿望"。官方的亮点是:1M token IDE 上下文、自动 "PR+单测" 生成、设计稿一键落地。
从 Cursor 到微软的 Copilot,再到如今的 Code Assist、Jules、Stitch、Firebase Studio 套装,大厂从来没有放弃干死程序员的梦想...
总之,程序员们自求多福吧,我现在才意识到封闭 = 安全,闭塞才能长久啊...
Gemini 世界模型
Gemini 2.5 被定位为"世界模型"雏形:能模拟物理、推演场景、规划行动。
与Manus不同的是,其实 Google 已经铺垫多年,他表现得极为厚重:
- 在《星际争霸》《围棋》中训练智能体,习得复杂决策策略;
- 打造 Genie 2,只需一张图,就能生成完整的 3D 可交互虚拟世界;
- 推出 Gemini Robotics,让机器人学会"如何抓住一件物品、执行指令并根据实时环境动态调整";
- 以及最新发布的 Veo,具备对"物理世界直觉"的深刻理解,能精准掌握运动、惯性等背后的规律;
这些能力的交汇,正慢慢把 Gemini 变成一个有感知、有推理、有记忆、有行动力的超级智能体。
一个令人震撼的方向是:借助 Gemini,我们可以轻松地将现实中的物理世界,转化为通过代码和网页仿真的数字世界。例如拍下下面的一张树木的照片,Gemini可以帮你生成游戏模型或者3D模型中的树的结构。

只不过,世界模型是最吃数据闭环的存在,如果没有实时反馈,它只是更大的 GAN 罢了。
其次,企业最怕"模型判定 A > B 的原因"说不清。世界模型越复杂,越需要传统规则引擎 + 审计日志兜底。
这可不是通用大模型能搞定的事情,总之理想很好,只不过Manus的技术成本也不高,那些所谓的技术沉淀,现在看来有点亏啊...
结语
Google 这波秀肌肉,确实把"软件=乐高"这条路铺得更亮、更滑。但别忘了:拼得快不等于拼得稳,拼得炫不等于拼得赚。
对个人,AI 让创意门槛史无前例地下探:可要是审美、故事、逻辑没跟上,生成再多 4K 视频也只是高清无聊。
对创业者,0→1 的原型速度是爽点,1→10 的迭代成本是痛点;先算 ROI,再谈"颠覆"。
对企业,长记忆、世界模型听着性感,合规、可解释、责任链 才是"刚需满级怪"。
总结下来:让技术为价值买单,而不是让价值去追技术的热闹。
把每一块乐高都当作"可替换零件",选最能提升核心指标的那块先落地------剩下的,等它们从炫技变刚需,再入手也不迟。
