前言
以<深入理解计算机系统>(以下称"本书")内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定
引入
接续理解计算机系统_并发编程(9)_线程(六):读者-写者问题-CSDN博客,对应本书P708开始内容
线程的进一步思考
前面提到线程的抽象:共享数据,共享函数体,内核自动调度.似乎还不能概括线程的特点,笔者用一个更简洁的观点来看待线程:线程是一个特殊的函数. 并发执行的n个相同函数.据此做一些推导:
1>操作相同数据.通过全局变量和局部静态变量来实现各个线程(函数)之间的数据共享.
2>返回相同类型的数据.在有返回值的前提下,n个线程将自动生成一个n个元素组成的数据集合(生产者-消费者模型).关于这里有一点说明:在理解计算机系统_并发编程(8)_线程(五):生产者-消费者问题_计算机学科中的生产者消费者是什么-CSDN博客
贴中,提到了缓冲区内的数据是有序的,数据结构选用了队列.其实有序无序不是强制的,但考虑到如果是无序的,缓冲区内的数据存在不被访问的风险---一直用不上,所以设置成有序.另外在本贴中,在缓冲区里放置的是文件描述符,也必须设成有序,否则有客户端发来的连接会一直连接不上的后果.
=============================内容分割线↓===================================
单任务线程化
在遇到多核CPU时,将单个任务(函数)线程化---一个函数分解成多个线程,可能会提高效率.
注意:基于笔者的一个设想,有没有效果必须经验证.
假设一个结构里有3个int变量,用单任务的写法
//单任务
/*结构定义*/
struct Demo{
int pa1;
int pa2;
int pa3;
}
/*单任务定义,为简便硬编码*/
void fun(struct Demo* dep){
dep->pa1=1;
dep->pa2=2;
dep->pa3=3;
}
/*主函数调用*/
int main(void){
struct Demo de;
fun(&de);
}以下是多线程写法
//单个任务多线程完成
struct Demo{
int pa1;
int pa2;
int pa3;
}
void *thread(void *vargp);
struct Demo de;
pthread_t tid1,tid2,tid3;
int main(){
Pthread_create(&tid1,NULL,thread,&de); //生成对等线程1
Pthread_create(&tid2,NULL,thread,&de); //生成对等线程2
Pthread_create(&tid3,NULL,thread,&de); //生成对等线程3
Pthread_join(tid1,NULL); //等待对等线程终止
Pthread_join(tid2,NULL); //等待对等线程终止
Pthread_join(tid3,NULL); //等待对等线程终止
exit(0); //终止当前进程中所有线程
}
void *thread(void *vargp){
struct Demo* de=(struct Demo*)vargp;
if(pthread_self(void)=tid1){
de->pa1=1;
return NULL;
};
if(pthread_self(void)=tid2){
de->pa2=2;
return NULL;
};
if(pthread_self(void)=tid3){
de->pa2=3;
return NULL;
};
}多线程的写法显得"生硬 "(未经过验证,可能会有bug),只说思路
两者对比感觉到因为共享的原因,多线程所需的堆区内存会比单任务大
=============================内容分割线↑===================================
信号量
信号量的操作 在理解计算机系统_并发编程(7)_线程(四):信号量和互斥锁-CSDN博客有过说明,信号量的作用 需要做个概括.信号量的作用是"锁 ",一是互斥锁 ,二是资源锁.锁的是线程的个数.
互斥锁 :当信号初始化为1,采用P(v)时,进入线程(函数)的线程个数被限制为1,只有当前线程可以访问共享变量. 资源锁:当信号初始化为n,进入线程(函数)的线程个数被限制为n,可以有n个线程进入,产生n个数据(限制缓冲区的数据个数为n).
一句话概括:++信号量提供锁,控制线程个数++
信号量的延伸使用
++可以作为一个点深入思考信号量的其他用法++,比如读者-写者模式中怎样限制读者的个数.
基于预线程化的并发服务器
本书P708:在图12-14所示的并发服务器中,我们为每一个新客户端创建了一个新线程.这种方法的缺点是我们++为每一个新客户端创建一个新线程,导致不小的代价++.一个基于预线程化的服务器试图通过使用如图12-27所示的生产者-消费者模型来降低这种开销.
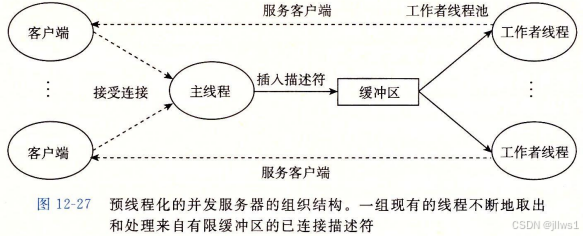
服务器是由一个主线程和一组工作者线程构成的.主线程不断地接受来自客户端的连接请求,并将得到的连接描述符放在一个有限缓冲区中.每一个工作者线程反复地从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符.
**---**解读:一个客户端创建一个线程,导致不小的代价,如果没有亲身体验感觉不出来.既然书上介绍有更好的方法跟着走.
代码思路
首先,不能为了读代码而读.学习别人代码的目的是编程的思路和代码的组织.但同时一定要有自己的思考.所以,在读代码之前,先想想如果是自己来写,应该怎么思考怎么写?
1>从工具入手.摩天大厦不是一步建成的,得先打地基,再造出梁柱和铺楼板,编程要先看一下手里有什么工具,
a.SBUF的程序包---用于生产者-消费者模式,建立一个符合要求的缓冲区,一个数据队列.
b.一个基于线程的并发服务器.他的核心是生成connfd文件描述符,并根据connfd传输数据.
两者结合,构建一个文件描述符队列的缓冲区.文件描述符本身是int类型,和SBUF内的队列数据元素类型一致,可不修改直接用.
2>从数据入手.程序的一切都围绕着数据.这里的"显式"数据是缓冲区,推出的内容和第1条一致.
代码解读
本书P709主程序echoservert-pre.c
第24行:初始化缓冲区
第25,26行:建立NTHREADS个线程,线程函数:第35行~第42行处理文件描述符connfd
第31行,文件描述符添加进缓冲区
第39行,消费者线程取出文件描述符.
本书P710程序echo-cnt.c
第17,18行:初始化线程,每个线程执行到这里需要先初始化
第8行,初始化信号量mutex,作互斥锁.由初始化线程函数(第18行)调用
第22行和第26行:保护共享变量byte_cnt
一个小问题:
echoservert-pre.c的预处理文件中应有#include "echo-cnt.h ",本书省略了echo-cnt.h的内容
小结
线程内容的一点思考和延伸,
"基于预线程化的并发服务器"代码的思路和解读.
不管是写函数,写一个包,或者建立一段程序,思路都是值得反复研究的,多看别人的代码多理解是个不错的切入点.