前面已经介绍了简单的视觉编码器,这里主要介绍多模态中使用比较多的两种backbone:1、Clip;2、SAM。对于这两个backbone简单介绍基本原理,主要是讨论使用这个backbone。
1、CV中常用Backbone-2:ConvNeXt模型详解
2、CV中常用Backbone(Resnet/Unet/Vit系列/多模态系列等)以及代码
SAM
SAM已经出了两个版本分别是:SAM v1和SAM v2这里对这两种分别进行解释,并且着重了解一下他的数据集是怎么构建的(毕竟很多论文里面都会提到直接用SAM作为一种数据集生成工具)
SAM v1^[1](#SAM v1[1])^
https://arxiv.org/pdf/2304.02643
官方Blog:Introducing Segment Anything: Working toward the first foundation model for image segmentation[[2]](#[2])
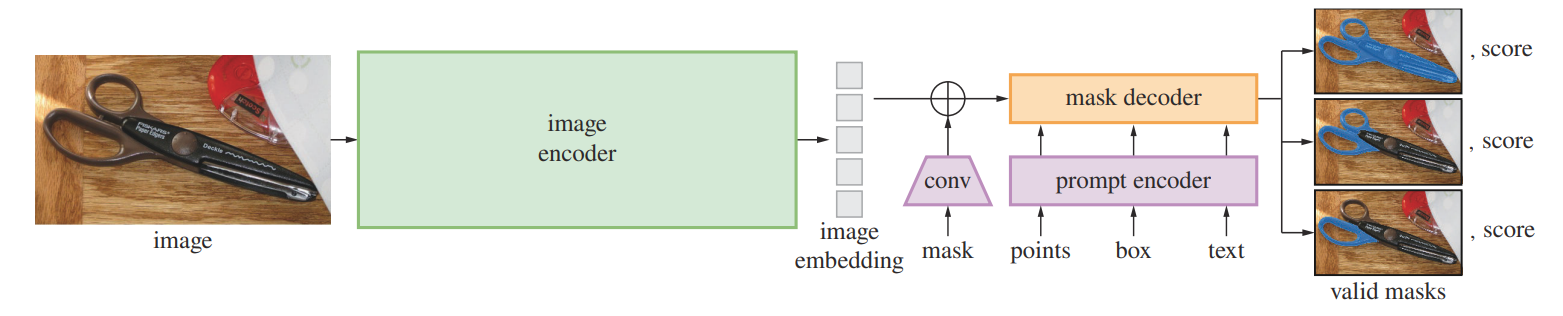
结构上还是比较简单,首先在 Image Encoder :选择的是MAE;Prompt Encoder :从上面结构图很容易知道就3类prompt:1、text用CLIP进行编码;2、points、bbox使用论文[[3]](#[3])(主要是通过傅里叶特征映射方法来提高模型对于高频函数学习能力)中的方法来进行编码处理;3、mask这种内容就直接使用卷积进行编码而后将结果和编码后图像相加;
对于points以及bbox编码原理很简单就是用点或者坐标直接计算他们的傅里叶特征,比如说points的伪代码
python
import numpy as np
# 假设输入点为2D,[x, y]
points = np.array([[0.5, 0.3], [0.2, 0.7]]) # 形状: (N, 2)
m = 256 # 映射维度
sigma = 10.0 # 频率控制参数
# 生成随机矩阵B
B = np.random.normal(0, sigma, size=(m, 2)) # 形状: (m, 2)
# 计算傅里叶特征
Bx = np.dot(points, B.T) # 点积,形状: (N, m)
fourier_features = np.concatenate([np.cos(2 * np.pi * Bx), np.sin(2 * np.pi * Bx)], axis=1) # 形状: (N, 2m)Mask decoder:掩码解码器可以有效的将图嵌入、提示嵌入和输出标记映射到掩码。本模型的解码器基于Transformer的解码器块修改,在解码器后添加了动态掩码预测头。解码器使用了提示自注意力和交叉注意力在提示到图嵌入(prompt-to-image embedding)和vice-versa两个方面进行了修改。完成这两个部分后,对图像进行上采样再使用MLP将输出标记映射到动态线性分类器上,最终得出每个图像位置的蒙板前景概率。
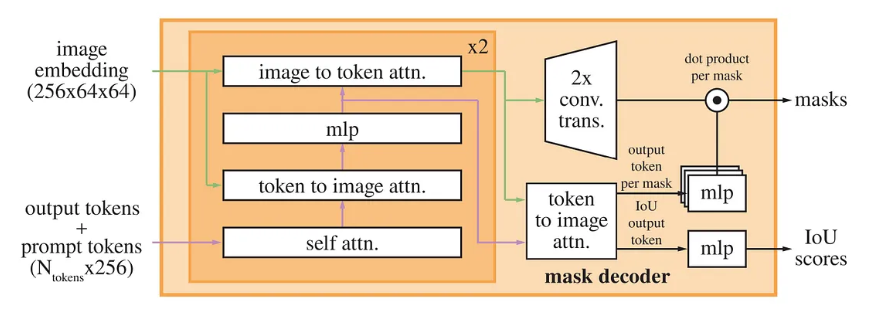
Resolving ambiguity :对于一个不确定的提示,模型会给出多个有效掩码,经过修改SAM可以由单个提示预测输出多个掩码(一般是3个--整体、部分、子部分)。训练时,仅掩码进行反向传播。为了对掩码进行排名,模型会预测每个掩码的置信分数(使用IOU度量),所谓的整体、部分、子部分,比如说:

SAM v2^[4](#SAM v2[4])^
SAM v2更像是SAM v1在视频邻域的泛化,整个模型结构如下所示:
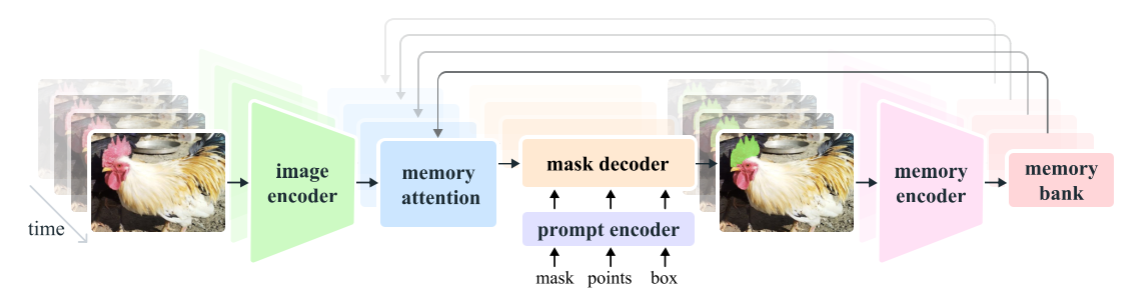
主要值得关注的是其中的 Memory Attention :将当前帧的特征与过去帧的特征和预测以及任何新的提示联系起来。通过堆叠了 L 个transformer模块,第一个模块将当前帧的图像编码作为输入。每个区块执行self-attention,然后cross-attention(提示/未提示)帧和对象的记忆,这些记忆存储在一个记忆库中,接着是一个 MLP。在self-attention和cross-attention中使用了vanilla注意力操作,从而受益于高效注意力内核的最新发展。
memory encoder 通过使用卷积模块对输出掩码进行下采样,并将其与图像编码器的无条件帧嵌入相加,生成记忆,然后使用轻量级卷积层来融合信息。
memory bank 通过维护最多N个最近帧的FIFO记忆队列来保留视频中目标对象的过去预测信息,并将提示信息存储在最多M个提示帧的FIFO队列中 。例如,在VOS任务中,初始掩码是唯一的提示,内存库始终保留第一帧的记忆以及最多N个最近(非提示)帧的记忆。两组记忆都以空间特征图的形式存储。
除空间存储器外,还根据每个帧的掩码解码器输出标记,将对象指针列表作为轻量级向量存储起来,用于存储要分割对象的高级语义信息。
我们将时间位置信息嵌入到N个最近帧的memory中,允许模型表示短期物体运动,但不包含到提示帧的记忆中,因为提示帧的训练信号更稀疏,并且更难以推广到推理设置中,提示帧可能来自与训练期间看到的时间范围非常不同的时间范围。
Clip[[5]](#Clip[5])
Clip模型结构(论文里面提到的)也比较简单,其核心机制为:核心机制是通过对比学习和嵌入空间对齐,将图像和文本映射到一个共享的语义空间中
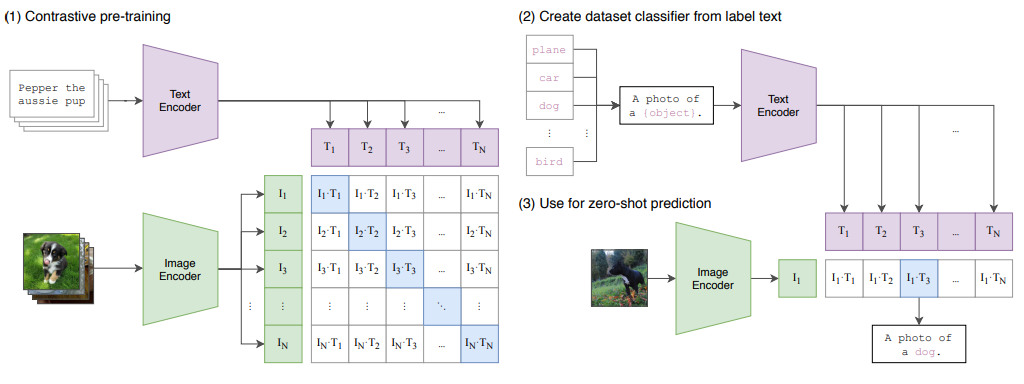
预训练过程 :直接将文本和图像都进行编码,而后将编码后的内容通过计算他的相似度(比如:cosine similarities)来确保模型最后能够对齐文本和图像之间的特征。
使用过程:对于给定的图像直接通过Clip的图像编码,而后将文本进行编码(文本编码中会有一个 label dataset通过从label dataset中抽取出标签和自己文本进行组合得到n条微博呢)再去计算最后的结果。
代码操作
所有代码见:sam-clip.ipynb