bash
conda env list # 看下目前有哪些环境
conda create -n pytorch python=3.8 # 创建一个pytorch虚拟环境
conda activate pytorch # 进入这个环境
conda list # 列出这个虚拟环境中所有的包
conda remove -n pytorch --all # 移出这个环境下所有的文件
conda deactivate # 退出某个环境
conda config --show #展示环境中的配置文件
bash
conda remove --n 虚拟环境名字 --all # 删除虚拟环境:
conda config --add channels 通道地址 # 持久添加通道:
conda config --remove channels 通道地址 # 删除通道:
#查看配置文件中有哪些通道
conda config --get
conda config show一、Pytorch入门
1.pytorch环境
1.1 pytorch环境搭建
1.1.1 安装Anaconda
1.1.2 安装Pytorch
验证pytorch是佛安装成功
1.激活对应的虚拟环境(你安装Pytorch的虚拟环境): conda activate 虚拟环境名
输入conda list,看有没有pytorch或者torch
输入python
输入 import torch
输入 torch.cuda.is_available()
如果显示True,就说明我们这个PyTorch安装成功了
1.1.3 安装Jupyter Notebook
jupyter默认安装在base环境中,无法使用之前安装的pytorch。
bash#1.首先先进入pytorch环境 conda activate pytorch #2.下载Jupyter Notebook conda install nb_conda #3.运行jupyter notebook jupyter notebook
1.1.3 配置PyCharm
1.2 用PyCharm创建project
2.Python学习中的两大法宝函数
在一个package相当于一个工具箱,第一次接触这个工具箱可能不知道这个工具箱里面有什么,但是这里有两个道具会帮助你知道工具箱里面有什么以及工具箱里面的某个模块是如何使用的。
**dir():**提供打开操作,看见里边有什么东西
**help():**像说明书,查看如何使用
举个例子说明一下怎么使用:
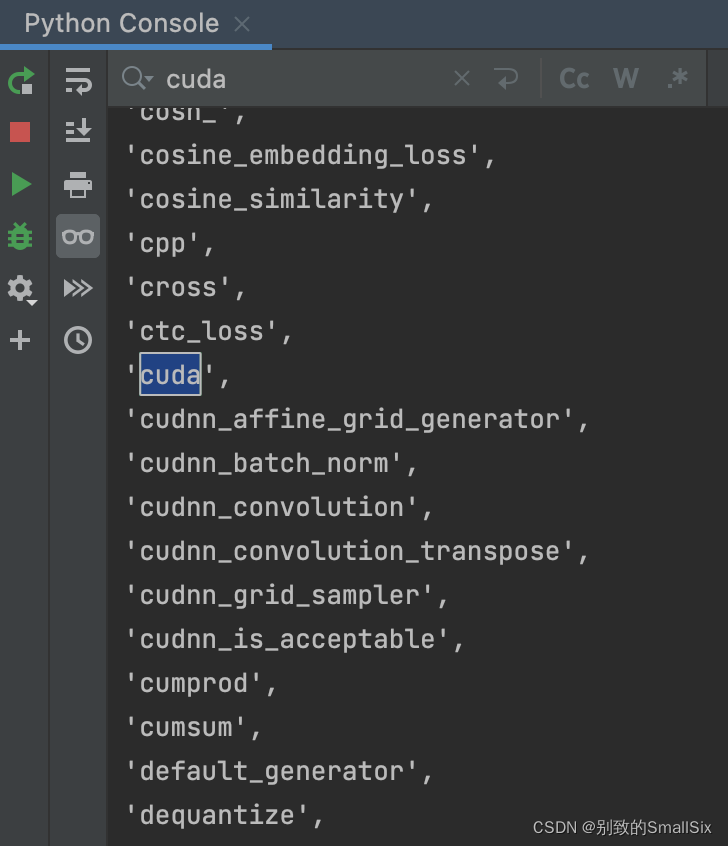
试探索torch这个工具箱所包含的分隔区,采用dir(torch),可以看到包含了大量的分隔区,使用control+F并输入cuda,可以看到torch得确包含了cuda这个分隔区。
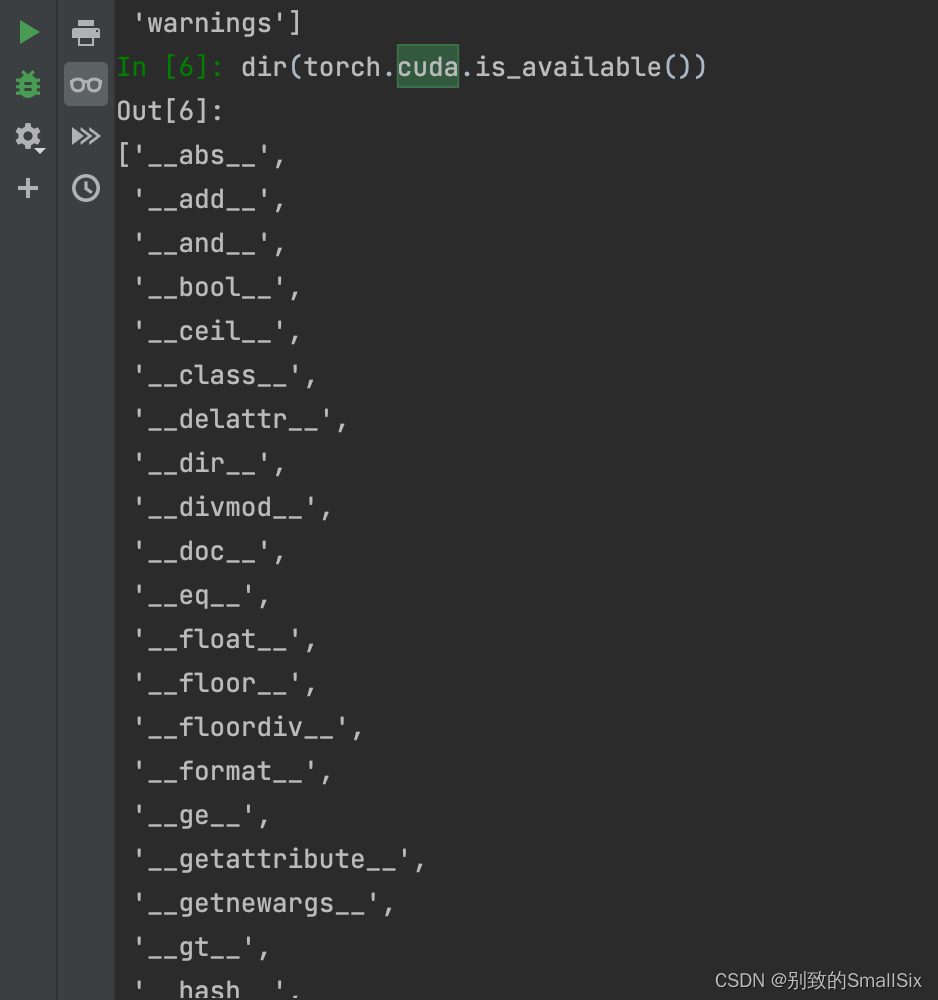
接着使用命令dir(torch.cuda)查看cuda里包含的内容,发现得确有is_available这个分隔区,紧接着查看一下is_available这个分隔区里包含什么。
发现is_available里包含的均为__gt__之类的内容(前后均有下划线:这是一种规范,即该补量不允许篡改),说明is_available就是一个工具了,使用help(torch.cuda.is_available)
注意:help(torch.cuda.is_available)没有()
3.Dataset && Dataloader
3.1 Dataset类与Dataloader类
- 基础概念介绍
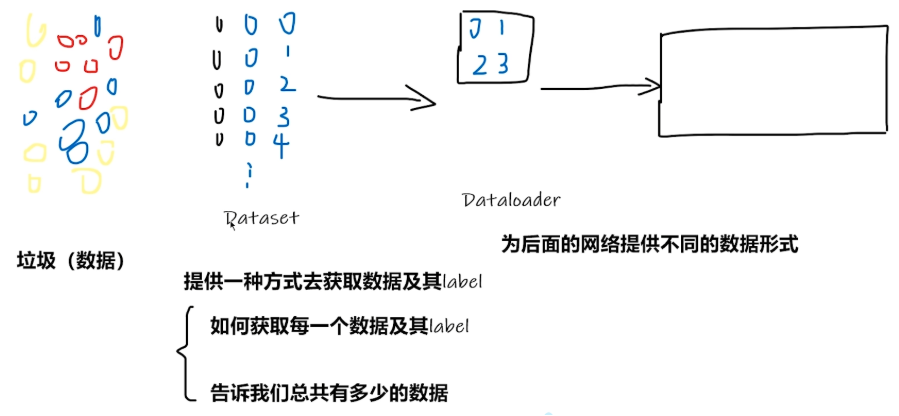
1.Data(数据):需要处理的东西。(可类比为杂乱的垃圾堆)
2.Dataset(数据集):提供一种方式去获取数据及其label,从海量数据中获取目标数据以及它们对应的标签(label),并为每个数据加上索引,可以通过索引直接找到数据(类似于在垃圾堆中找出需要的东西)
**3.Label(标签):**人为对数据分的类,用来告诉电脑哪些数据是正确的,也是模型最终输出的东西,在回归里是一个个类别,预测里是一个个数值。
**4.Dataloader(数据转载器):**将指定的目标数据以及对应的label进行打包,并发送给后面的神经网络,为后面网络提供不同的数据形式。其中有用到的batch_size=n,n=几就打包几个发送给神经网络。
- Dataset类的使用:
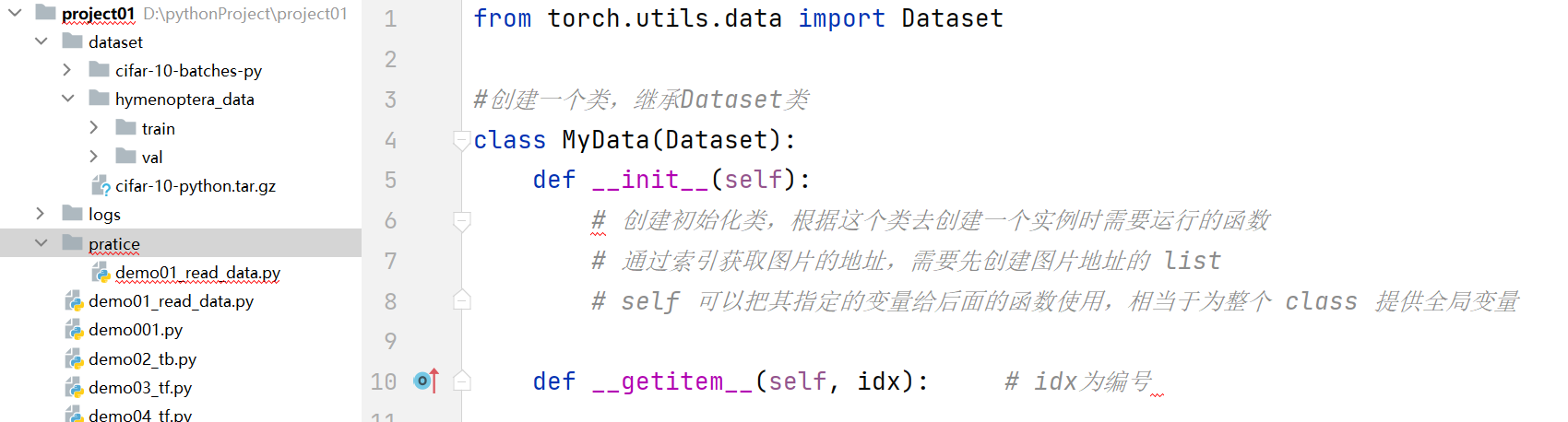
from torch.utils.data import Dataset(引入Dataset类)
Dataset类:所有数据集都要继承这个类,并且重写该类中的__getitem__方法,该方法的作用是每个获取数据及其对应label。用户也可以选择行重写__len__()方法(作用:返回数据的长度)
3.2 Dataset代码实战
想要读取数据集中的文件
第一步:读取图片
根据之前下载的hymenoptera_data数据集来写,首先创建一个python文件,然后创建一个继承Dataset的新类MyData
比如说,我们想要读取数据集中的数据,每张图片是一个数据。
可以使用两种方法来读取图片,例子如下:
python# 法1 from PIL import Image img_path = "xxx" img = Image.open(img_path) img.show() # 法2:利用opencv读取图片,获得numpy型图片数据 import cv2 cv_img=cv2.imread(img_path)若import cv2的时候报错没有opencv包则安装opencv:在 PyCharm的终端里输入
bashpip install opencv-python

4 TensorBoard
4.1 什么是TensorBoard
TensorBoard 是 TensorFlow 提供的一个可视化工具,就像给你的机器学习模型装了一个"仪表盘"。它的主要作用是帮你更直观地理解和调试模型。
eg:
看训练过程:像看视频回放一样观察模型训练时误差(loss)如何变化、准确率如何提升。
查模型结构:用流程图展示你的神经网络长什么样,每一层如何连接。
找问题:比如发现某些参数异常变大(梯度爆炸),或计算资源使用不平衡。
对比实验:同时显示多次训练结果,方便比较不同参数的效果。
举个生活例子:就像你健身时用智能手表记录心率、卡路里消耗,TensorBoard 就是给AI训练用的"智能手表",把抽象的数字变成图表,让你一眼看懂模型在"锻炼"时的状态。
4.2 如何安装TensorBoard
bash
pip install tensorboard #单独安装 TensorBoard 可以使用如下命令note:
**1.**TensorBoard 包含在 TensorFlow 库中,所以如果我们成功安装了 TensorFlow,我们也可以使用 TensorBoard。
**2.**TensorBoard依赖Tensorflow,所以会自动安装Tensorflow的最新版
bash
# 在python console中输入以下代码,验证是否安装成功,若不提示错误,则代表安装成功
from torch.utils.tensorboard import SummaryWriter 4.3 启动TensorBoard
tensorboard --logdir=路径
eg:tensorboard --logdir=D:\pythonProject\project01\logs
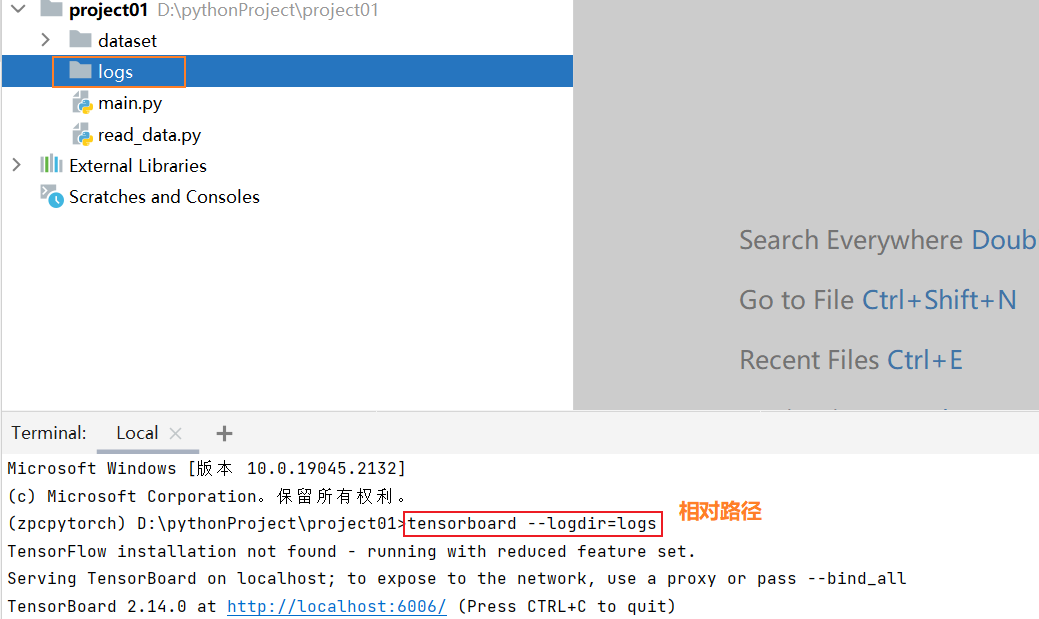
可以用浏览器打开http://localhost:6006/ 查看
4.4 TensorBoard仪表盘
4.4.1 TensorBoard Scalars
4.4.2 TensorBoard Images
4.4.3 TensorBoard Graphs
4.4.4 TensorBoard Distributions and Histograms 分布和直方图
4.5 TensorBoard的使用
5 Transforms(图像变化)
5.1 什么是Transforms
在深度学习和计算机视觉中,Transforms是一组用于数据预处理(Preprocessing)和增强(Augmentation)的操作,通常用于将原始数据(图像、文本)转换为适合模型输入的标准化格式。
在Pytorch中,torchvision.transforms模块提供了丰富的内置变换方法。
(1) 数据预处理
目的:使数据符合模型输入要求(如尺寸、数值范围)。
常见操作:
Resize:调整图像大小。
ToTensor:将图像转为 PyTorch 张量(并自动归一化到[0, 1])。
Normalize:标准化数据(如减去均值、除以标准差)。(2) 数据增强(Data Augmentation)
目的:通过随机变换增加数据多样性,防止模型过拟合。
常见操作:
RandomHorizontalFlip:随机水平翻转图像。
RandomRotation:随机旋转图像。
ColorJitter:调整亮度、对比度、饱和度
特定格式的图片 经过处理 得到结果图片
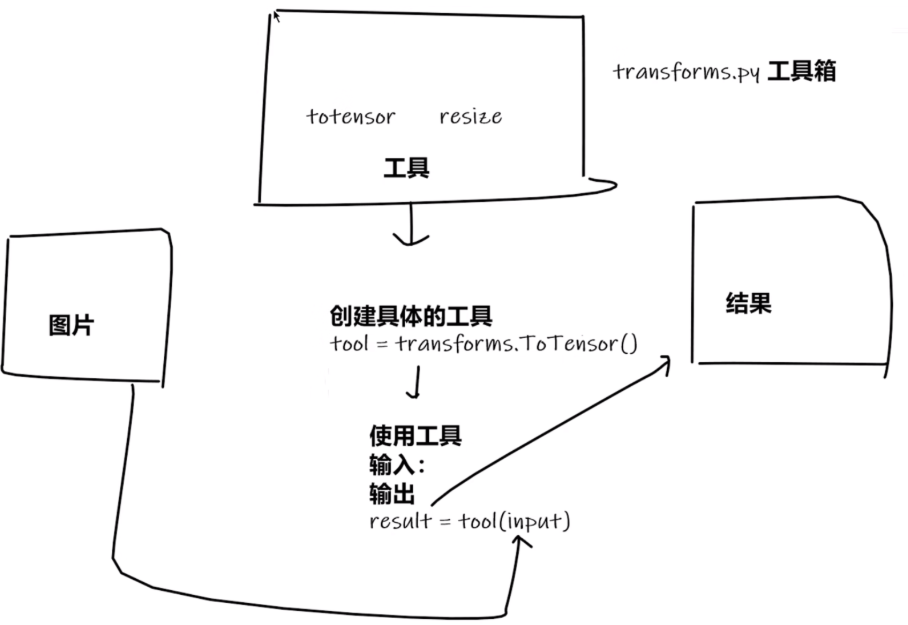
5.2 Transforms的使用(tensor数据)
python的用法,将tensor数据类型,通过transforms.ToTensor来看两个问题。
python
# 如何使用Transforms
tensor_trans = transforms.ToTensor() #类不接受任何参数,要传参数必须实例化这个类(创建的工具)
tensor_img = tensor_trans(img)
python
# 导入必要的库
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 读取图像文件
img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径
img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象
# 创建TensorBoard写入器,用于可视化数据
writer = SummaryWriter("logs") # 指定日志保存目录为"logs"
# 创建图像转换工具链
# transforms.ToTensor()是一个类,需要实例化后才能使用
# 该转换将PIL Image或numpy.ndarray格式的图像转换为PyTorch的Tensor格式
# 同时会自动将像素值从[0, 255]归一化到[0, 1]范围
tensor_trans = transforms.ToTensor()
# 应用转换:将PIL图像转换为Tensor
tensor_img = tensor_trans(img) # 返回形状为(C,H,W)的Tensor,C为通道数,H和W为高和宽
# 使用TensorBoard记录转换后的图像
# add_image()方法要求输入的Tensor形状为(C,H,W)或(B,C,H,W)
# 其中B是批量大小,这里只处理单张图像,因此使用(C,H,W)格式
# "Tensor_img"是图像在TensorBoard中的标签名
writer.add_image("Tensor_img", tensor_img)
# 关闭写入器,释放资源
writer.close()5.3 为什么需要Tensor数据类型
Tensor 是深度学习框架(如 PyTorch、TensorFlow)中的核心数据结构,类似于多维数组,但提供了更强大的功能。
1. 高效计算
- GPU 加速:Tensor 可轻松在 GPU 上运行,大幅提升计算速度
- 优化的底层实现:使用 C++/CUDA 后端,计算效率远高于 Python 原生列表 / 数组
2. 自动微分
- Tensor 支持自动求导(如 PyTorch 的
autograd),是构建神经网络的基础3. 统一的数据格式
- 支持不同类型的数据(图像、文本、音频等)统一表示
- 便于在模型、优化器和其他组件间传递数据
4. 多维操作支持
- 提供丰富的张量操作(矩阵乘法、卷积、转置等)
5. 内存优化
- 支持原地操作(in-place operations)减少内存消耗
6. 与深度学习框架无缝集成
- 所有模型输入 / 输出均要求 Tensor 格式
- 支持批量处理、并行计算等特性
5.4 常见的Transforms
使用python文件中的不同类,有不同的作用

5.4.1 ToTensor(tensor数据)
ToTensor是将图像或其他数据类型转换为 PyTorch 的torch.Tensor类型。在计算机视觉任务里,一般是把 PIL 图像(Python Imaging Library,Python 图像处理标准库)或 NumPy 数组形式的图像数据,转换成torch.Tensor。转换过程中,它会将图像数据的维度顺序调整为
(C, H, W)(通道数、高度、宽度 ),并把像素值的范围从[0, 255](如果是 8 位无符号整型 )归一化到[0.0, 1.0](浮点型 ) ,方便后续的计算和模型处理。
python# 导入必要的库 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") #创建实例 ---> 创建一个SummaryWriter,日志将保存在"logs"目录下 # 读取图像文件 img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径 img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象 # ToTensor的使用 trans_toTensor = transforms.ToTensor() img_tensor=trans_toTensor(img) print('img_tensor.shape ='+ str(img_tensor.shape)) writer.add_image("totensor", img_tensor) writer.close()

5.4.2 Normalize(归一化)
归一化操作是为了让数据分布更加合理,提升模型训练效果。
Normalize会对图像数据进行标准化处理,一般是给定均值(mean)和标准差(std),按照公式(x - mean) / std对图像的每个通道进行计算 。其中x是原始图像数据,经过处理后,数据的均值变为 0,标准差变为 1 。这样能加速模型收敛,避免一些数值计算上的问题。比如对于 RGB 三通道图像,可分别指定三个通道的均值和标准差进行归一化。
数值范围调整
- 把数据的取值范围,比如图像像素值从原本的 0, 255(常见的 8 位图像像素取值范围 ),变换到其他区间,像 0, 1 或者 - 1, 1 等。例如将图像像素值除以 255,就能把范围从 0, 255 映射到 0, 1 。
标准化(Standardization)
- 这是一种常见的归一化方式,基于数据的均值和标准差来变换数据。对于每个特征维度(图像中对应每个通道 ),使用公式 x′=(x−μ)/σ 进行变换,其中 x 是原始数据,μ 是均值,σ 是标准差 。变换后的数据均值为 0,标准差为 1 。在深度学习训练中,标准化能让数据分布更稳定,有助于优化算法更快收敛。
python# 导入必要的库 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") #创建实例 ---> 创建一个SummaryWriter,日志将保存在"logs"目录下 # 读取图像文件 img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径 img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象 # ToTensor的使用 trans_toTensor = transforms.ToTensor() img_tensor=trans_toTensor(img) #Normalize 的使用 print(img_tensor[0][0][0]) trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) img_norm = trans_norm(img_tensor) print(img_norm[0][0][0]) writer.add_image("Normalize", img_norm) writer.close()
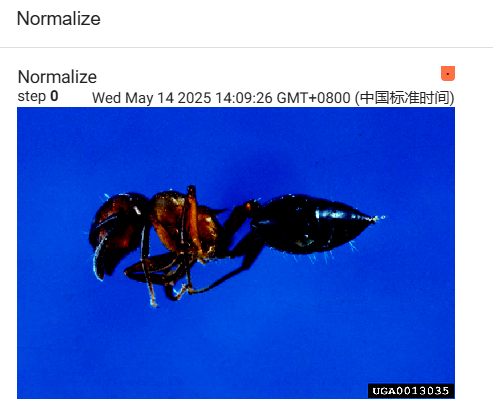
5.4.3 Resize(改变图像尺寸)
Resize的作用是改变图像的尺寸。在深度学习模型训练时,往往要求输入图像具有固定的尺寸规格,Resize可以将图像按照指定的大小进行缩放。比如可以指定缩放后的图像宽度和高度,或者按照一定的比例进行缩放。它通过插值算法(如最邻近插值、双线性插值等 )来计算新尺寸下的像素值,保证图像在尺寸改变后仍能尽量保留原始特征。
python# 导入必要的库 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") #创建实例 ---> 创建一个SummaryWriter,日志将保存在"logs"目录下 # 读取图像文件 img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径 img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象 # 定义ToTensor转换对象 trans_totensor = transforms.ToTensor() #Resize 的使用 print(img.size) trans_resize = transforms.Resize((512, 512)) # 将图像的尺寸调整为宽度和高度均为 512 像素 # img是PIL数据类型,resize后还是PIL类型 img_resize = trans_resize(img) # img_resize是PIL类型,ToTensor处理后,tensor数据类型 img_resize = trans_totensor(img_resize) writer.add_image("Resize", img_resize) writer.close()

5.4.4 Compose(容器操作化)
Compose本身不是针对图像数据进行具体变换的操作,而是一个容器类。它可以将多个数据预处理操作组合起来,按照顺序依次对数据进行处理。例如,可以先使用Resize调整图像大小,再用ToTensor转换为张量,最后用Normalize进行归一化,把这几个操作放在Compose中,就可以一次性对输入数据按顺序执行这些操作,让数据预处理流程更加简洁、易管理。
python# 导入必要的库 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") #创建实例 ---> 创建一个SummaryWriter,日志将保存在"logs"目录下 # 读取图像文件 img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径 img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象 # 定义ToTensor转换对象 trans_totensor = transforms.ToTensor() # Compose resize --2 trans_resize_2 = transforms.Resize(512) # PIL -> PIL ->tensor trans_compose = transforms.Compose([trans_resize_2, trans_totensor]) img_resize_2 = trans_compose(img) # PIL类型 writer.add_image("Resize--compose", img_resize_2, 1) writer.close()
5.4.5 RandomCrop(随机裁剪)
RandomCrop用于从原始图像中随机裁剪出指定大小的子图像。在数据增强中很常用,通过随机裁剪,能增加训练数据的多样性,让模型学习到图像不同部分的特征,提升模型的泛化能力。比如指定裁剪的子图像的高度和宽度,算法会在原始图像范围内随机确定裁剪区域,然后获取该区域的子图像用于后续训练等操作。
python# 导入必要的库 from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms writer = SummaryWriter("logs") #创建实例 ---> 创建一个SummaryWriter,日志将保存在"logs"目录下 # 读取图像文件 img_path = "dataset/hymenoptera_data/train/ants/0013035.jpg" # 图像文件路径 img = Image.open(img_path) # 使用PIL库打开图像,返回PIL Image对象 # 定义ToTensor转换对象 trans_totensor = transforms.ToTensor() #RandomCrop trans_random = transforms.RandomCrop(512) trans_compose_2 = transforms.Compose([trans_random, trans_totensor]) for i in range(10): img_crop = trans_compose_2(img) writer.add_image("RandomCrop", img_crop, i) writer.close()

6.torchvision
6.1 什么是torchvision
PyTorch 生态中专门用于**计算机视觉(Computer Vision)**的库,提供了常用的数据集、预训练模型、图像处理工具和可视化功能,帮助用户快速构建和训练 CV 模型。
6.2 torchvision的使用
将 数据集 和 transforms 结合在一起
标准数据集的下载、组织 和 查看
数据集(torchvision.datasets.XX)
COCO数据集:目标检测,语义分割
MNIST数据集:手写文字
CIFAR10:物体识别
eg:CIFAR10的使用
- **root:**数据集位置
- **train:**训练集
- **transform:**想进行的变化
- **download:**下载

6.2.1 基本使用
第一步:下载数据集
python# torchvision 是 PyTorch 中用于计算机视觉任务的扩展库,提供了许多常用的数据集、模型架构和图像变换工具等 。 import torchvision #导入 torchvision库, #使用 torchvision.datasets.CIFAR10 类来加载 CIFAR10 数据集 """ root="./dataset":指定数据集下载和存储的根目录为当前目录下的 dataset 文件夹。 train=True:表示获取训练集数据;train=False 表示获取测试集数据。 download=True:如果指定目录下不存在 CIFAR10 数据集,就自动从网上下载。 """ train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)第二步:输出数据集
python# 获取测试集中的第一个样本,会返回包含图像数据和对应标签的元组,print 语句将其打印出来 print(test_set[0]) #查看测试集中的第一个 print(test_set.classes) img, target = test_set[0] # 将测试集第一个样本解包,把图像数据赋值给 img ,标签赋值给 target 。 print(img) # 打印图像数据,通常是一个表示图像的张量。 print(target) # 打印图像对应的标签(一个整数)。 print(test_set.classes[target]) # 根据标签 target 从类别名称列表 test_set.classes 中获取对应的类别名称并打印。 img.show()
6.2.2 与transforms 联动使用
将 ToTensor 应用到数据集中的每一张图片
第一步: 将数据集中的图片转化为 tensor 类型
pythonimport torchvision # 导入 torchvision 库,该库提供了计算机视觉相关的数据集、模型和图像变换工具等 from torch.utils.tensorboard import SummaryWriter # SummaryWriter 用于将数据记录到 TensorBoard 中,方便可视化训练过程中的各种指标、图像等信息。 """ 使用 torchvision.transforms.Compose 来组合一系列图像变换操作。 这里只包含一个变换 torchvision.transforms.ToTensor(), 其作用是将 PIL 图像或 NumPy 数组形式的图像转换为 PyTorch 的张量(Tensor)形式, 这是后续在 PyTorch 中处理图像数据的常见预处理步骤。 """ dataset_transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ]) """ 使用 torchvision.datasets.CIFAR10 加载 CIFAR10 数据集。 root="./dataset":指定数据集下载和存储的根目录为当前目录下的 dataset 文件夹。 train=True 表示加载训练集,train=False 表示加载测试集。 transform=dataset_transform:对加载的图像应用之前定义好的数据变换,即把图像转换为张量。 download=True:如果指定目录下不存在 CIFAR10 数据集,就自动从网上下载。 """ train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True) print(test_set[0]) # 用于获取测试集中的第一个样本,通常会返回包含图像数据和对应标签的元组第二步:使用TensorBoard显示
pythonwriter = SummaryWriter("logs") # 初始化 SummaryWriter 实例,指定日志文件保存的目录为logs 后续记录的数据会保存在该目录下,用于在 TensorBoard 中展示。 for i in range(10): #循环 10 次 img, target = test_set[i] #每次循环获取测试集中索引为 i 的样本,将图像数据赋值给 img ,标签赋值给 target writer.add_image("test_set", img, i) #将获取到的图像 img 记录到 TensorBoard 中,标签为 "test_set" ,并使用索引 i 作为全局步数(global step),用于在 TensorBoard 中按顺序展示图像。 writer.close()
7. DataLoader的使用
7.1 DataLoader的介绍
DataLoader是 PyTorch 中用于高效加载数据 的工具,主要作用是将数据集(Dataset)包装成可迭代的批次数据,支持多进程加速、随机打乱(shuffle)等操作,是训练深度学习模型的必备组件。
7.2 DataLoader的使用
DataLoader:加载器,将数据加载到神经网络中
从dataset中取数据,取多少数据,怎么取
7.2.1 DataLoader的一些参数
**dataset:**告诉程序,数据集在什么地方,第一张数据、第二张数据在什么地方,数据集有多少数据。
**batch_size:**每次抓牌抓两张。
**shuffle:**打乱
**num_workers:**多进程 or 单进程 加载
note:
出现 错误
BrokenPipError:[Errno32] Broken pipe可以将 num_workers 设置为 0
bashnum_workers = 0**drop_last:**数据集除不尽的时候,要不要舍去余下的图片。

7.2.2 DataLoader的使用方式
python
import torchvision.datasets # 用于加载常见数据集(如 CIFAR-10)
from torch.utils.data import DataLoader # 将数据集包装为可迭代的批次(batch),支持并行加载和打乱数据。
from torch.utils.tensorboard import SummaryWriter # 将数据写入 TensorBoard 日志,用于可视化。
# 1.准备的测试数据集
"""
CIFAR10:加载 CIFAR-10 数据集(10 类彩色图像,每类 6000 张,共 60,000 张)。
"./dataset":数据存储路径(若不存在则自动下载)。
train=False:加载测试集(10,000 张图像)。
transform=ToTensor():将图像从 PIL 格式转为 Tensor(形状为[3, 32, 32],即[通道数, 高度, 宽度])。
"""
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
# 2.建立Loader
"""
batch_size=64:每次迭代返回 64 张图像和标签。
shuffle=True:每个 epoch(遍历数据集一次)前打乱数据顺序。
num_workers=0:不使用多进程加载数据(主进程处理)。
drop_last=True:若最后一批不足 64 张,丢弃该批次。
"""
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 3.测试数据集中第一张 图片 及 target
img, target = test_data[0] # test_data[0]:返回第 1 张图像(Tensor)和对应的标签(整数)
print(img.shape)
print(target)
# 4.查看batch_size 、drop_last的效果
"""
外层循环(epoch):遍历数据集 2 次。
内层循环(data):每次从test_loader获取一个批次(64 张图像和标签)。
add_images:
标签:"Epoch:{epoch}"(如"Epoch:0")。
数据:imgs(形状为[64, 3, 32, 32],即[批次大小, 通道数, 高度, 宽度])。
步骤:step(记录当前批次的索引,用于 TensorBoard 中的时间轴)。
"""
writer = SummaryWriter("logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()
# 取出 test_Loader 中的每一个返回
# print(targets)
# print(imgs.shape)8 神经网络的基本骨架--nn.moudule的使用
PyTorch的官方文档
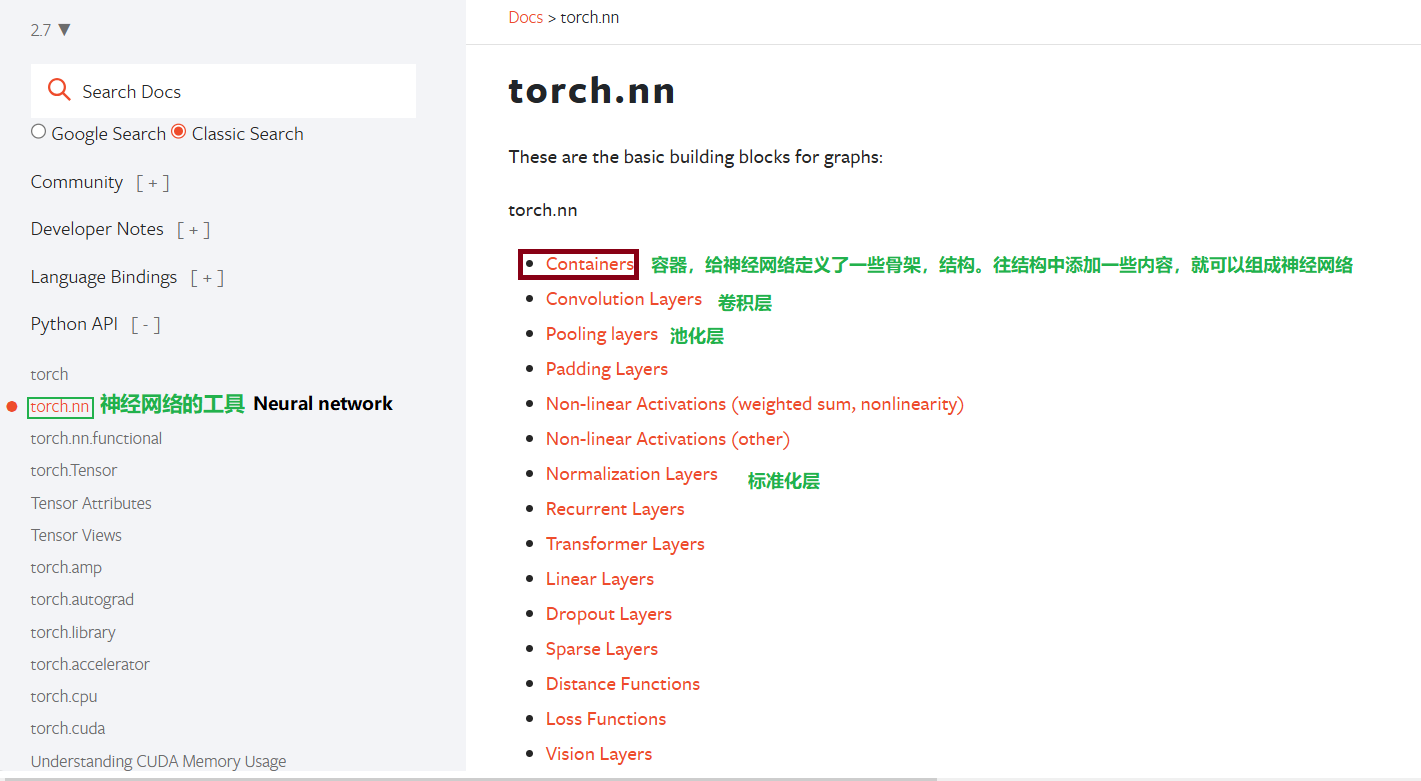
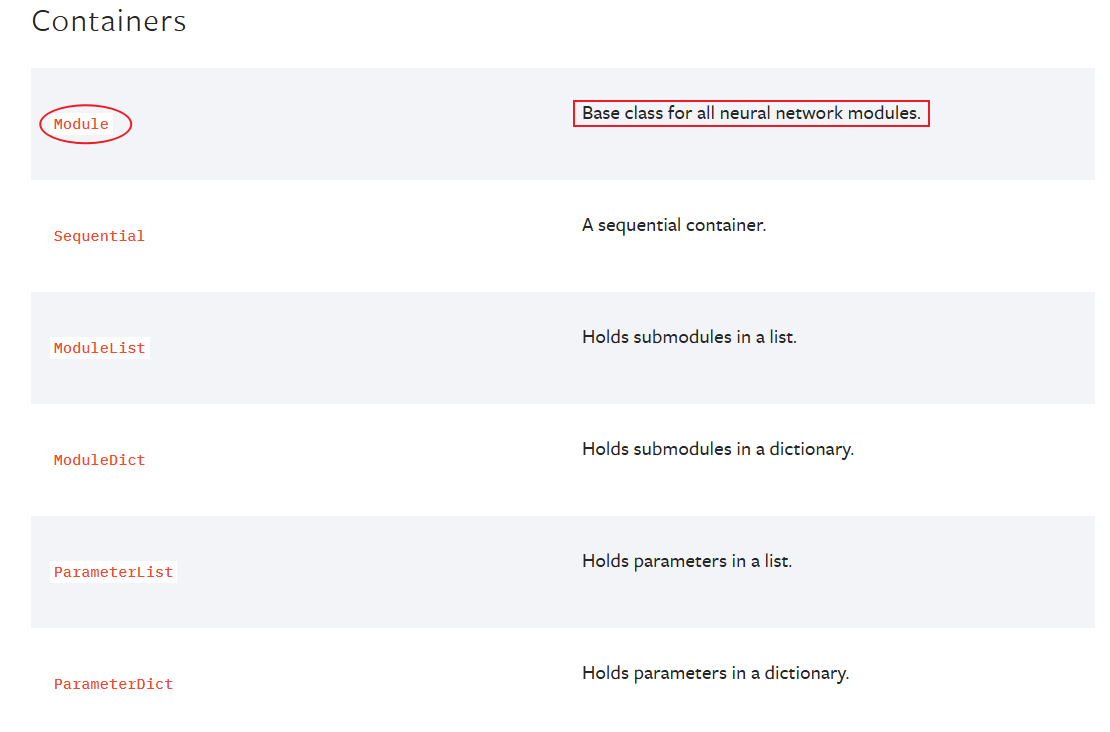
Module是Contains中最常用的模块,Contains是用来构建神经案例架构的。
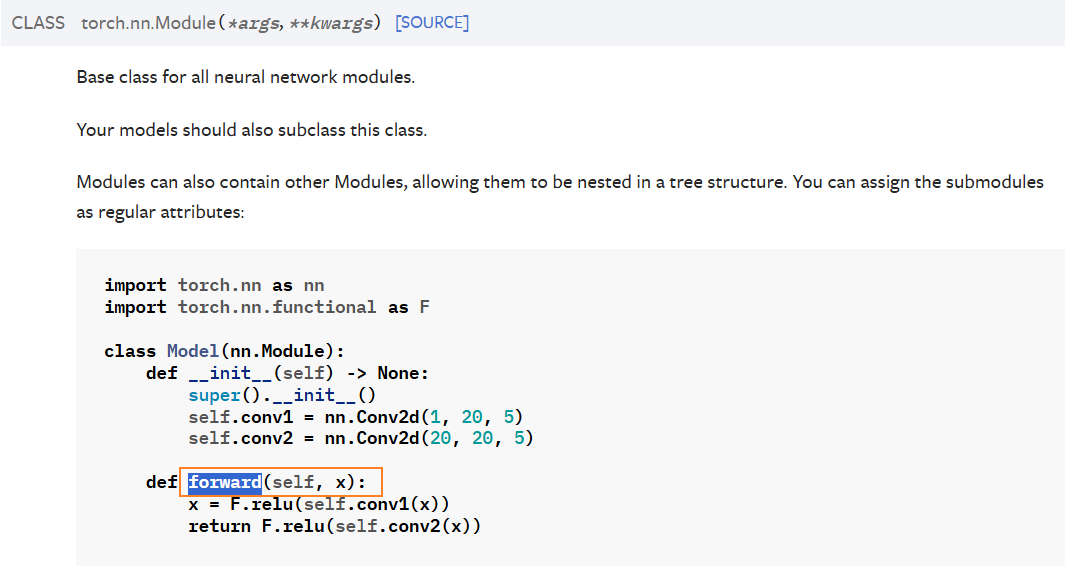
python# 官方文档的代码 import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 20, 5) self.conv2 = nn.Conv2d(20, 20, 5) def forward(self, x): x = F.relu(self.conv1(x)) return F.relu(self.conv2(x))步骤:使用神经网络的基本骨架---nn.Module,主要可以分为三步:
1.创建一个类继承nn.Module
2.继承nn.Module的初始化加上自己的初始化
3.重写forword
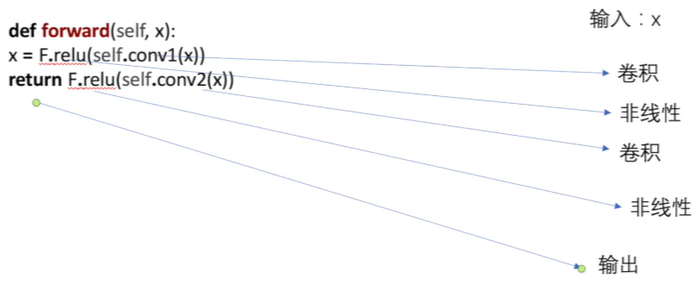
二、卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种在计算机视觉领域取得了巨大成功的深度学习模型。它们的设计灵感来自于生物学中的视觉系统,旨在模拟人类视觉处理的方式。在过去的几年中,CNN已经在图像识别、目标检测、图像生成和许多其他领域取得了显著的进展,成为了计算机视觉和深度学习研究的重要组成部分。
1. 图像原理
先看看图像的原理:
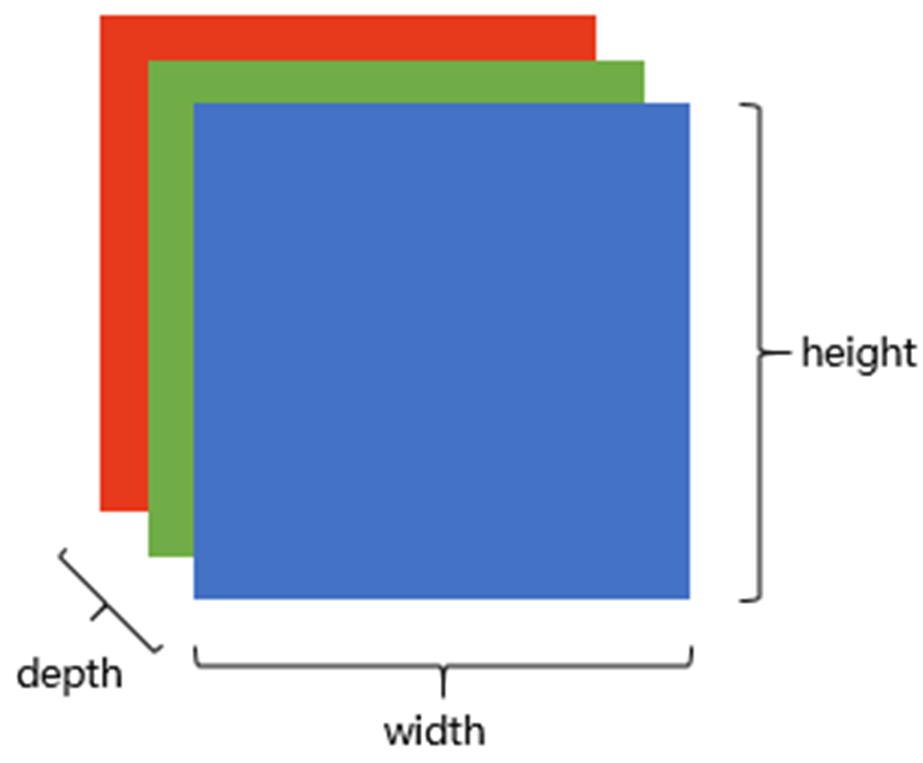
图像在计算机中是一堆按顺序排列的数字,数值为0到255。0表示最暗,255表示最亮。 如下图:
上图是只有黑白颜色的灰度图,而更普遍的图片表达方式是RGB颜色模型,即红、绿、蓝三原色的色光以不同的比例相加,以产生多种多样的色光。RGB颜色模型中,单个矩阵就扩展成了有序排列的三个矩阵,也可以用三维张量去理解。
其中的每一个矩阵又叫这个图片的一个channel(通道),宽、高、深来描述。

2. 为什么学习卷积神经网络
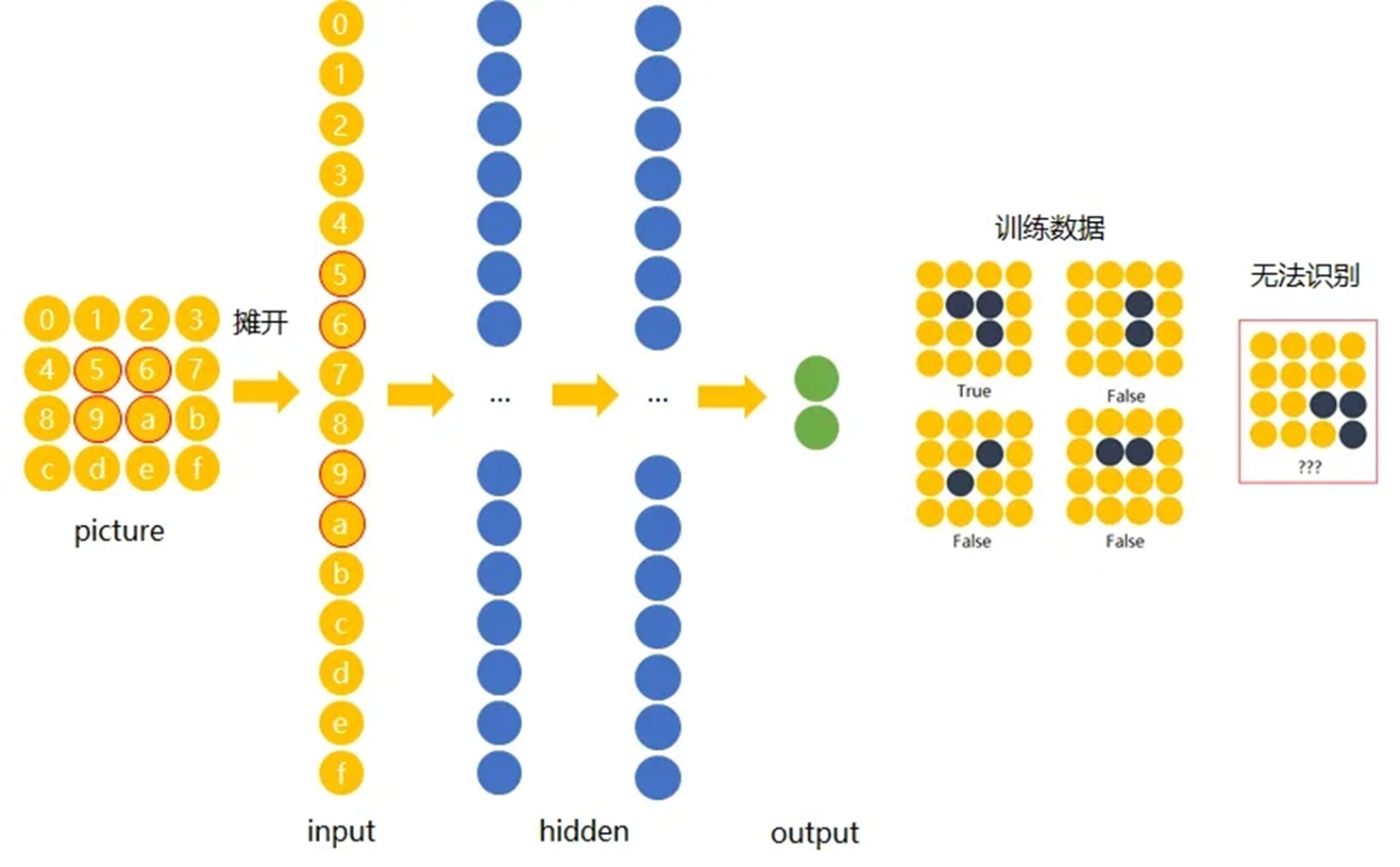
在传统神经网络中,我们要识别下图红色框中的图像时,我们很可能识别不出来,因为这六张图的
位置都不通,计算机无法分辨出他们其实是一种形状或物体。
传统神经网络原理如下图:
我们希望一个物体不管在画面左侧还是右侧,都会被识别为同一物体,这一特点就是不变性。为了实现平移不变性,卷积神经网络(CNN)等深度学习模型在卷积层中使用了卷积操作,这个操作可以捕捉到图像中的局部特征而不受其位置的影响。


3.卷积---基础知识
3.1 什么是卷积?
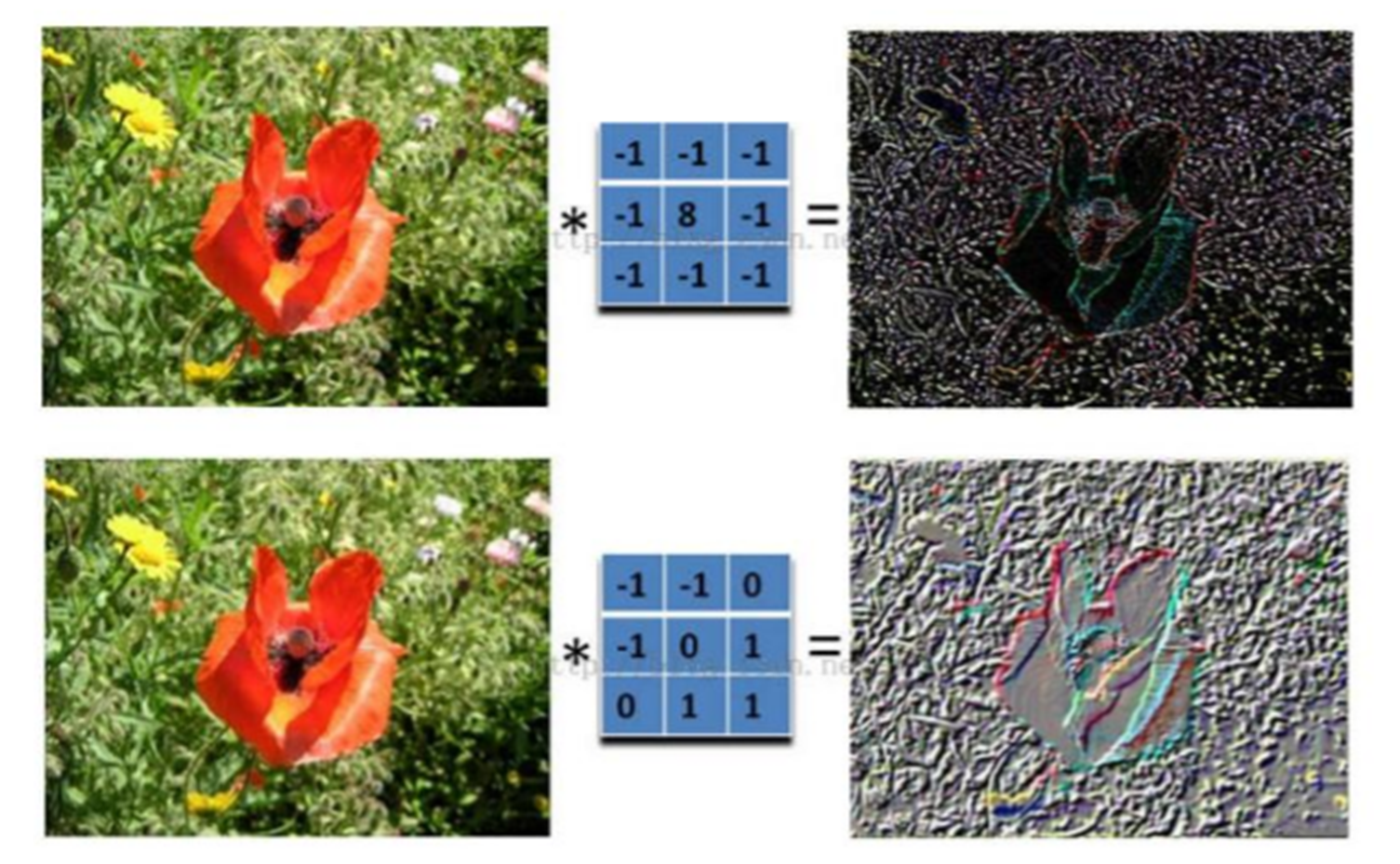
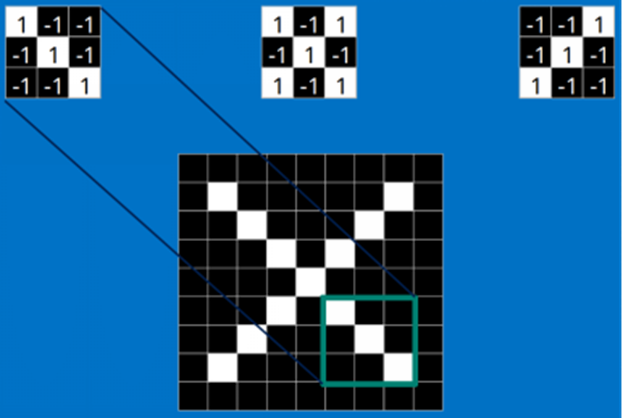
在卷积神经网络中,卷积操作是指将一个可移动的小窗口 (称为数据窗口,如下图绿色矩形)与图像进行逐元素相乘然后相加的操作。这个小窗口其实是一组固定的权重 ,它可以被看作是一个特定的滤波器 (filter)或卷积核。这个操作的名称"卷积",源自于这种元素级相乘和求和的过程。这一操作是卷积神经网络名字的来源。

3.2 卷积的计算过程
下图这个绿色小窗就是数据窗口。简而言之,卷积操作就是用一个可移动的小窗口来提取图像中的特征,这个小窗口包含了一组特定的权重,通过与图像的不同位置进行卷积操作,网络能够学习并捕捉到不同特征的信息。文字解释可能太难懂,下面直接上动图:
这张图中蓝色的框 就是指一个数据窗口,红色框 为卷积核(滤波器),最后得到的绿色方形 就是卷积的结果**(数据窗口中的数据与卷积核逐个元素相乘再求和)**
一张图了解卷积计算过程:
3.3 卷积需要注意哪些问题
1.步长stride:每次滑动的位置步长
可以是单个数,或元组(sH,sW)---控制横向和纵向步进
2.卷积核的个数:决定输出的depth厚度。同时代表卷积核的个数
3.填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
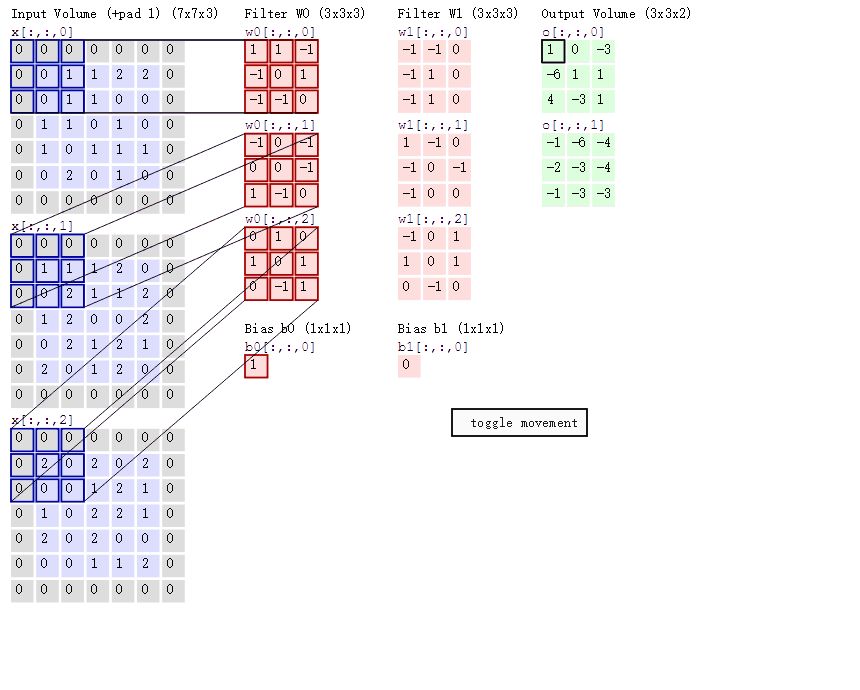
以上图为例,那么:
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2
- 两个神经元,即depth=2,意味着有两个滤波器
- zero-padding=1
Q:为什么要进行数据填充:
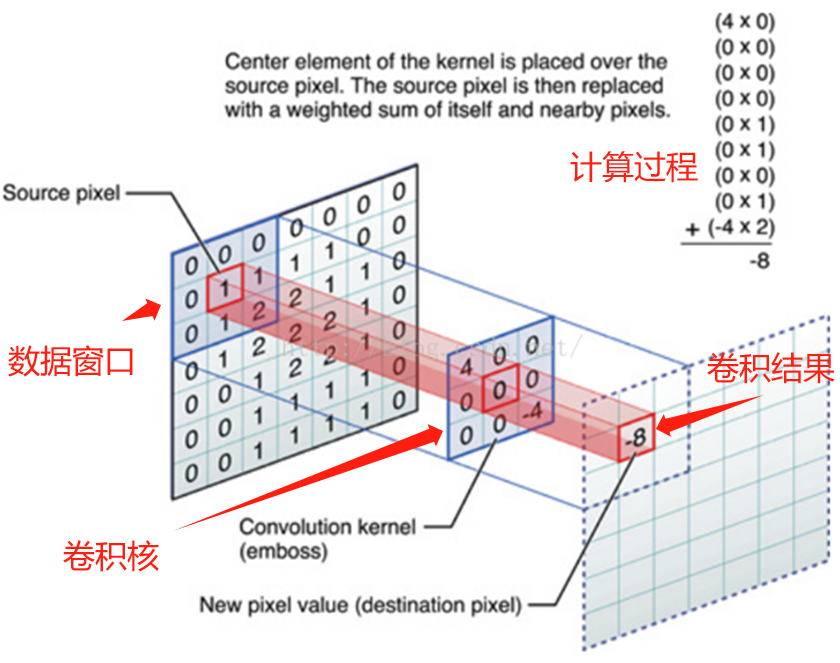
假设有一个大小为4x4的输入图像:
python[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]现在,我们要应用一个 3x3 的卷积核进行卷积操作,步幅(stride)为 1,且要使用填充(padding)为 1。如果不使用填充,卷积核的中心将无法对齐到输入图像的边缘,导致输出特征图尺寸变小。 假设我们使用步幅(stride)为 1 进行卷积,那么在不使用填充的情况下,输出特征图的尺寸将是 2x2。
---> 所以我们要在它的周围填充一圈0,填充为 1 意味着在输入图像的周围添加一圈零值。添加填充后的图像:
python[ [0, 0, 0, 0, 0, 0], [0, 1, 2, 3, 4, 0], [0, 5, 6, 7, 8, 0], [0, 9, 10, 11, 12, 0], [0, 13, 14, 15, 16, 0], [0, 0, 0, 0, 0, 0] ]现在,我们将 3x3 的卷积核应用于这个填充后的输入图像,计算卷积结果,得到大小不变的特征图。
数据填充的主要目的是确保卷积核能够覆盖输入图像的边缘区域,同时保持输出特征图的大小。这对于在CNN中保留空间信息和有效处理图像边缘信息非常重要。
3.4 卷积神经网络的模型是什么样的
上面红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。
4.卷积神经网络的模型
4.1 输入层
输入层接收原始图像数据。图像通常由三个颜色通道(红、绿、蓝)组成,形成一个二维矩阵,表示像素的强度值。
4.2 卷积和激活(卷积层)
卷积层将输入图像与卷积核进行卷积操作。然后,通过应用激活函数(如ReLU)来引入非线性。这一步使网络能够学习复杂的特征。
nn.Conv2d
参数:
CLASS
pythontorch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)in_channels (int) -- Number of channels in the input image 输入图像通道数
out_channels (int) -- Number of channels produced by the convolution 输出图像通道数
kernel_size (int or tuple)-- Size of the convolving kernel 卷积核大小
stride (int or tuple, optional) -- Stride of the convolution. Default: 1 步长
padding (int, tuple or str, optional)-- Padding added to all four sides of the input. Default: 0
padding_mode (string, optional) -- 'zeros', 'reflect', 'replicate' or 'circular'. Default: 'zeros' padding填充已什么样的方式填充
dilation (int or tuple, optional)-- Spacing between kernel elements. Default: 1
groups (int, optional) -- Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) -- If True, adds a learnable bias to the output. Default: True 偏置
公式
N是batch_size,Cin输入通道数,Hin 输入的高,Win 输入的宽
代码举例
pythonimport torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 下载数据集 dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset, batch_size=64) # 搭建简单的神经网络 class Lh(nn.Module): def __init__(self) -> None: super().__init__() # 定义卷积层 self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1(x) return x lh = Lh() # 实例化 writer = SummaryWriter("logs") step = 0 for data in dataloader: imgs, targets = data output = lh(imgs) print(imgs.shape) print(output.shape) # torch.Size([64, 3, 32, 32]) 输入大小 batch_size=64 in_channel=3,32*32 writer.add_images("input", imgs, step) # torch.Size([64, 6, 30, 30]) 输出大小 # 将形状变为[xxx,3,30,30] output = torch.reshape(output, (-1, 3, 30, 30)) writer.add_images("output", output, step) step = step + 1 writer.close()

4.3 池化层
池化层通过减小特征图的大小来减少计算复杂性。它通过选择池化窗口内的最大值或平均值来实现。这有助于提取最重要的特征。
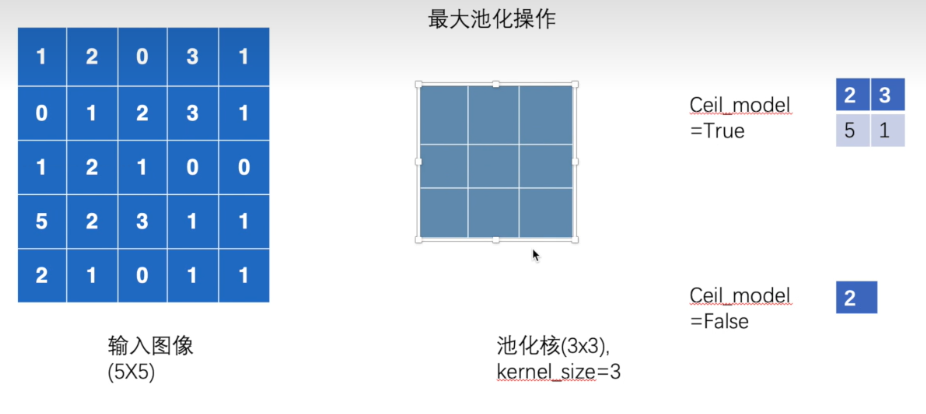
torch.nn.MaxPool2d
pythontorch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数
**kernel_size:**池化窗口的大小,可以是整数或元组。
**stride:**步幅,默认为与 kernel_size 相同,决定窗口移动的距离。
**padding:**每个边缘的填充大小,默认为0。
**dilation:**控制池化窗口元素之间的间隔,默认是1。
**return_indices:**如果为 True,返回最大值的索引(默认值为 True)。
**ceil_mode:**如果为 False ,则当kernel 超过二维 tensor 时,不保留值(默认值为 False)。
代码举例
pythonimport torch import torchvision from torch import nn from torch.nn import MaxPool2d # 这是一个 5×5 的二维张量,作为 MaxPool2d 层的输入 input = torch.tensor([[1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,0], [5,2,3,1,1], [2,1,0,1,1]],dtype=float) """ MaxPool2d 层期望的输入格式是四维张量,形状为(batch_size, channels, height, width)。这里: batch_size=1(一次处理 1 个样本) channels=1(单通道,如灰度图像) height=5和width=5(输入矩阵的尺寸) """ # maxpool 的 input 需要是四维 input = torch.reshape(input,(1,1,5,5)) """ Mary类继承自nn.Module,是 PyTorch 中定义神经网络的标准方式。 __init__方法初始化网络层:创建了一个 MaxPool2d 层,参数说明: kernel_size=3:使用 3×3 的池化窗口 ceil_mode=True:当池化窗口超出输入边界时,使用 ceil 函数计算输出尺寸(保留边缘信息) forward方法定义了数据的前向传播路径,将输入 x 通过 maxpool1 层处理后返回。 """ class Mary(nn.Module): def __init__(self): super(Mary,self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) def forward(self,x): x = self.maxpool1(x) return x #实例化 Yorelee = Mary() output = Yorelee(input) print(output)示例代码
pythonimport torch import torchvision from torch import nn from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter """ 创建 CIFAR-10 测试数据集(训练集参数设为False),并将图像转换为 Tensor 格式。 使用 DataLoader 批量加载数据,每批 64 张图像。 """ dataset = torchvision.datasets.CIFAR10("dataset",False,torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset,64) """ 定义名为Mary的神经网络,仅包含一个 MaxPool2d 层。 池化窗口大小为 3×3,ceil_mode=True确保边缘信息被保留(超出边界时使用 ceil 函数计算输出尺寸)。 """ class Mary(nn.Module): def __init__(self): super(Mary,self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) def forward(self,x): x = self.maxpool1(x) return x Yorelee = Mary() writer = SummaryWriter("logs") """ 遍历每个数据批次,获取图像 (img) 和标签 (target)。 使用add_images方法向 TensorBoard 添加原始图像和经过最大池化后的图像。 step作为全局步数计数器,确保每个批次的图像在 TensorBoard 中正确显示。 """ step = 0 for data in dataloader: img,target = data writer.add_images("input",img,step) output = Yorelee(img) writer.add_images("output",output,step) step += 1 writer.close()

4.4 多层堆叠
CNN通常由多个卷积和池化层的堆叠组成,以逐渐提取更高级别的特征。深层次的特征可以表示更复杂的模式。
4.5 全连接和输出
最后,全连接层将提取的特征映射转化为网络的最终输出。这可以是一个分类标签、回归值或其他任务的结果。
5. 图片经过卷积后的样子
与人眼观看事物原理相似,卷积神经网络可以看到事物的轮廓