开发目的
解决漏洞扫描器的痛点
第一就是扫描量太大,对一个站点扫描了大量的无用 POC,浪费时间
指纹识别后还需要根据对应的指纹去进行 payload 扫描,非常的麻烦
开发思路
我们的思路分为大体分为指纹+POC+扫描
所以思路大概从这几个方面入手
首先就是 POC,我们得寻找一直在更新的 POC,而且是实时更新的,因为自己写的话有点太费时间了
但是这 POC 的决定是根据我们扫描器来的,因为世面上已经有许多不错的扫描器了,目前打算使用的是 nuclei 扫描器
https://github.com/projectdiscovery/nuclei
Nuclei 是一种现代、高性能的漏洞扫描程序,它利用基于 YAML 的简单模板。它使您能够设计自定义漏洞检测场景,以模拟真实世界的条件,从而实现零误报。
目前也在不断维护更新,当然还有 Xray,Goby 等工具也是不错的选择
然后回到指纹识别技术,这个需要大量的指纹样本,但是世面上的各种工具已经可以做得很好了
指纹识别
这里就的学习一下指纹识别的技术
首先我们需要知道收集指纹目前大概有哪些方法
指纹识别方式
特定文件
比如举一个例子,我们通常是如何判断一个框架是 thinkphp 呢?
我们随便找几个 thinkphp 的网站
特征就是它的图标是非常明显的
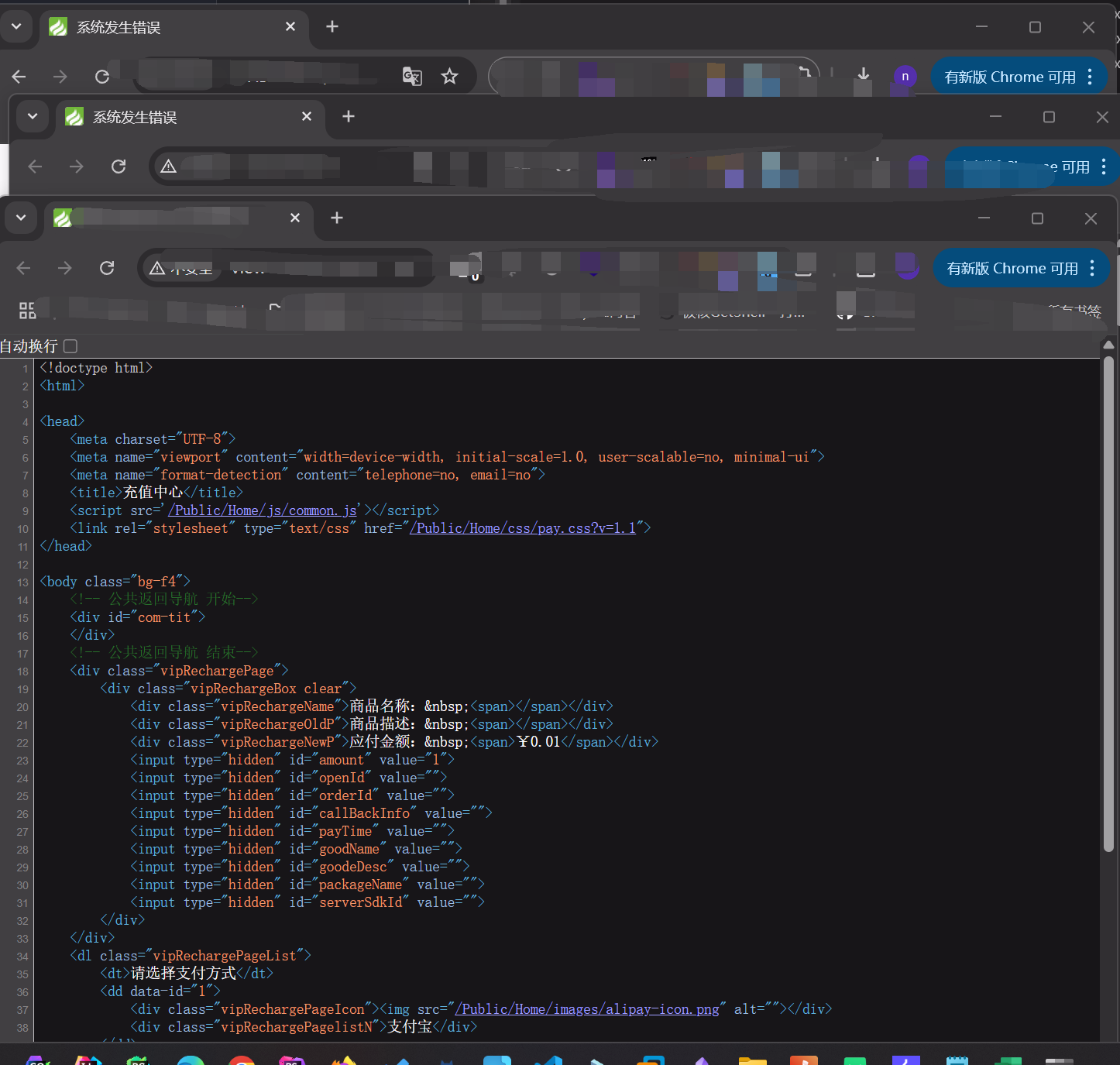
可以看到图标都是一样的,目前 fofa 和 hunter 已经有这种查找的方法了,一般都是把我们的图标换算为我们的 hash 值
这个就是我们的 favicon.ico 图标
一般网站是通过在路径后加入 favicon.ico 比如
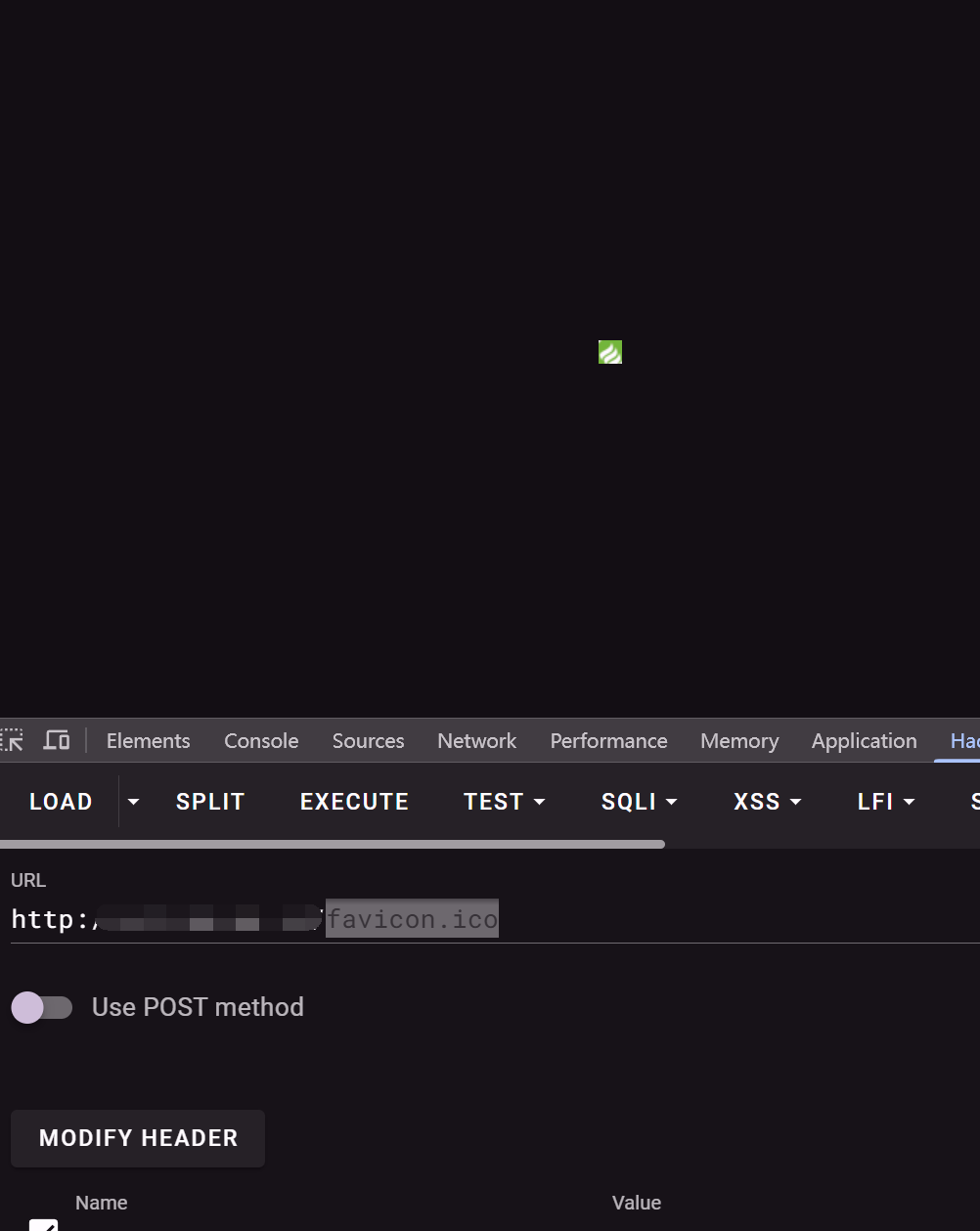
然后就能获取这个图标了,而在 fofa 中可以直接拖动查询了,可以直接算出 hash 值

比如 thinkphp 的
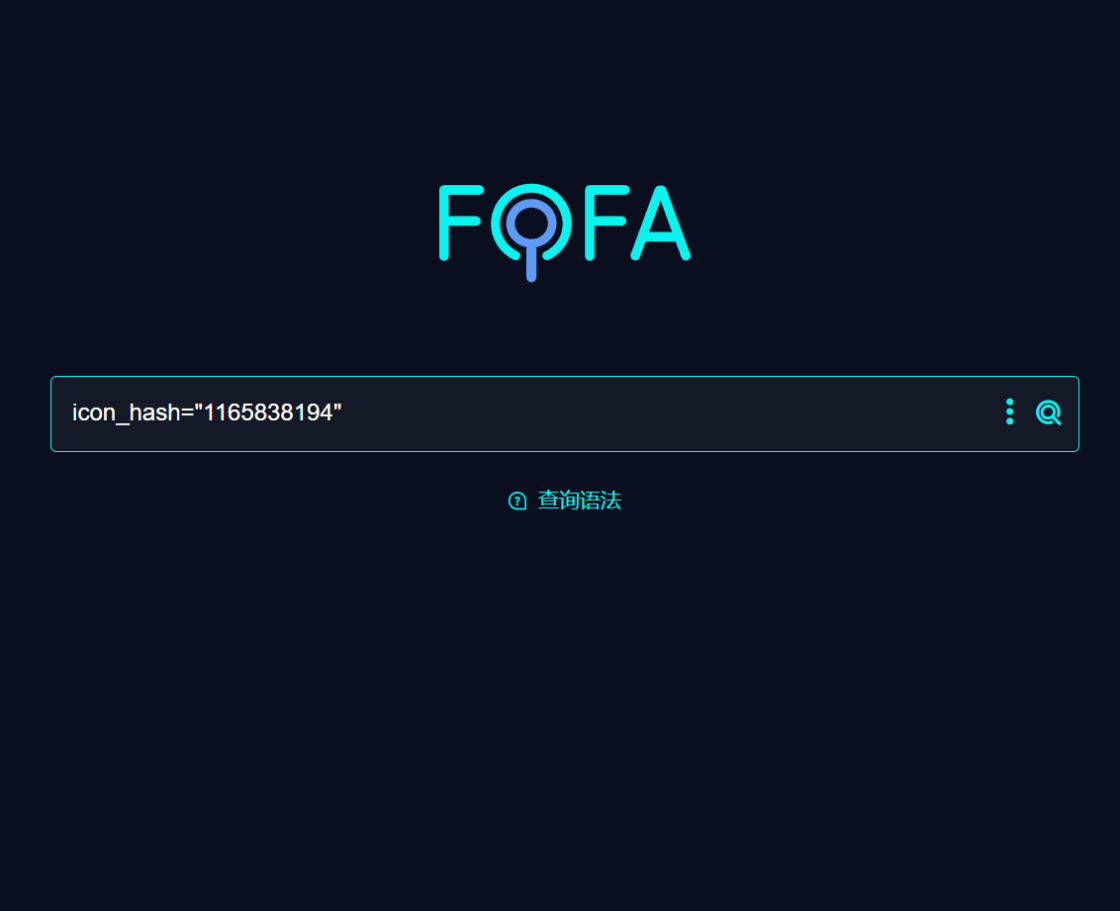
然后再次查询
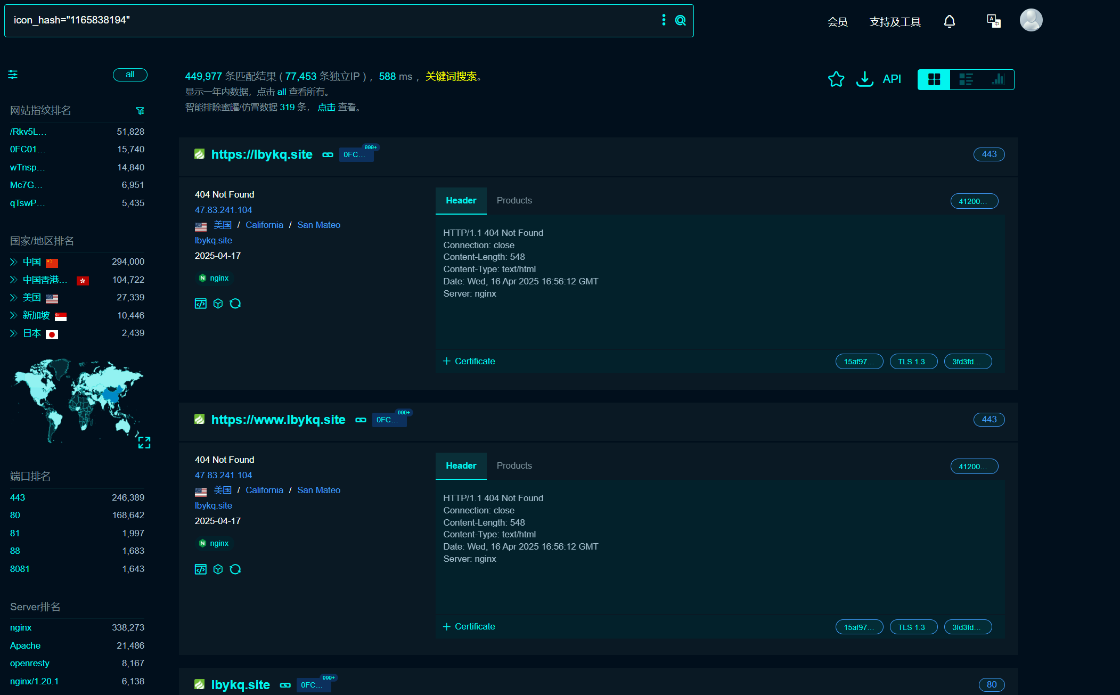
全是 tp 的网站
参考https://github.com/TideSec/TideFinger/blob/master/Web指纹识别技术研究与优化实现.md
当然除了我们的 ico 文件,还有其他很多的文件
帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
一些网站的特定图片文件、js 文件、CSS 等静态文件,如 favicon.ico、css、logo.ico、js 等文件一般不会修改,通过爬虫对这些文件进行抓取并比对 md5 值,如果和规则库中的 Md5 一致则说明是同一 CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的 CMS 会修改这些文件。
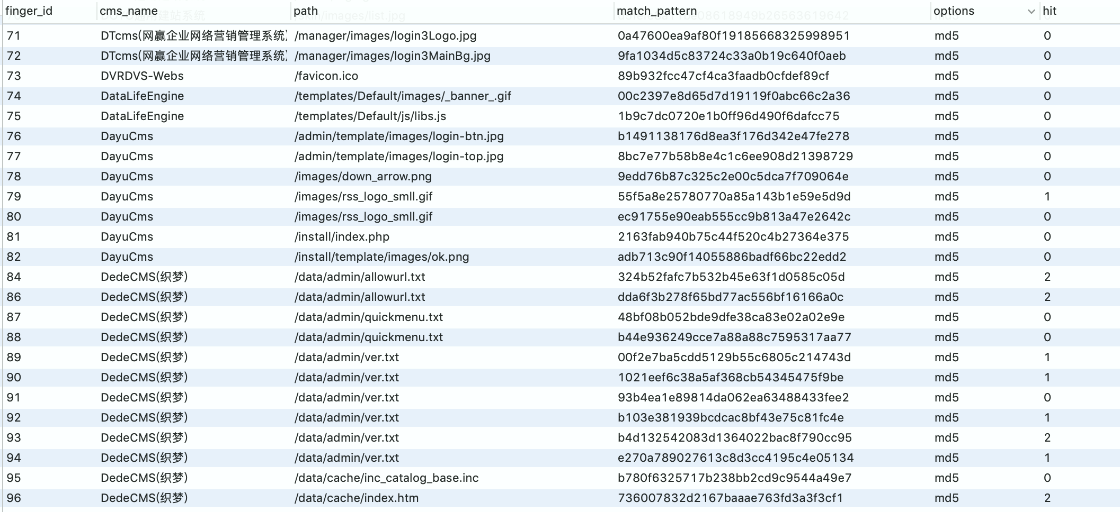
页面关键字
比如 tp 的错误页面大多数都是
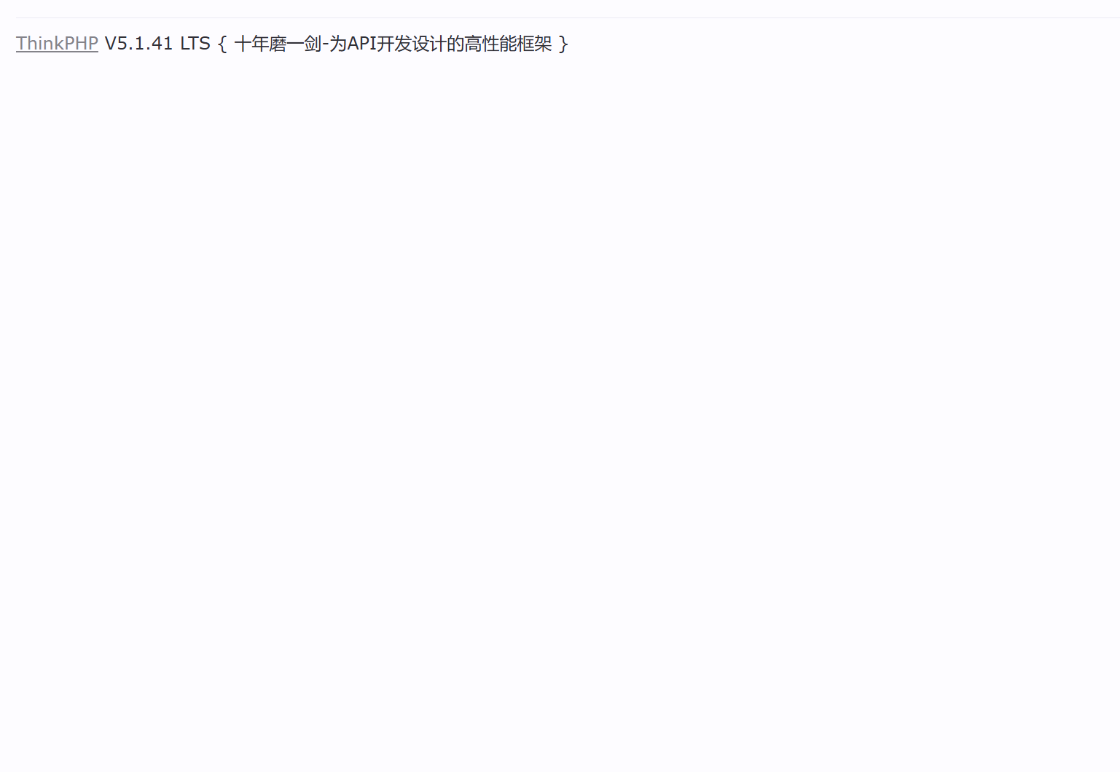
我们 body 就可以包含这个关键字了
或者可以构造错误页面,根据报错信息来判断使用的 CMS 或者中间件信息,比较常见的如 tomcat 和 spring 的报错页面。
根据 response header 一般有以下几种识别方式:
请求头关键字
根据网站 response 返回头信息进行关键字匹配,这个一般是 ningx 这种
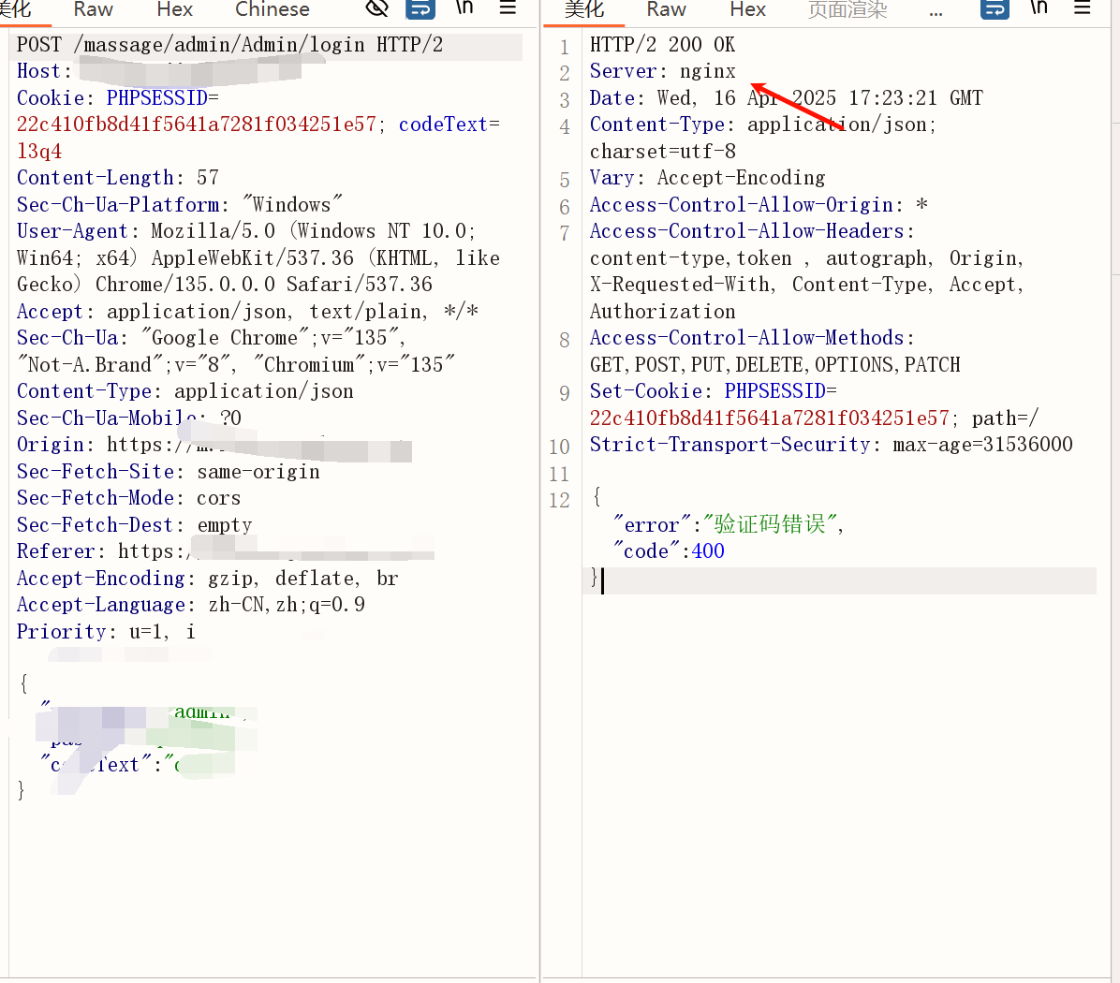
能够识别我们的服务器
URL 路径
根据总结
wordpress 默认存在 wp-includes 和 wp-admin 目录,织梦默认管理后台为 dede 目录,solr 平台可能使用/solr 目录,weblogic 可能使用 wls-wsat 目录等。
大部分还是根据我们的 body
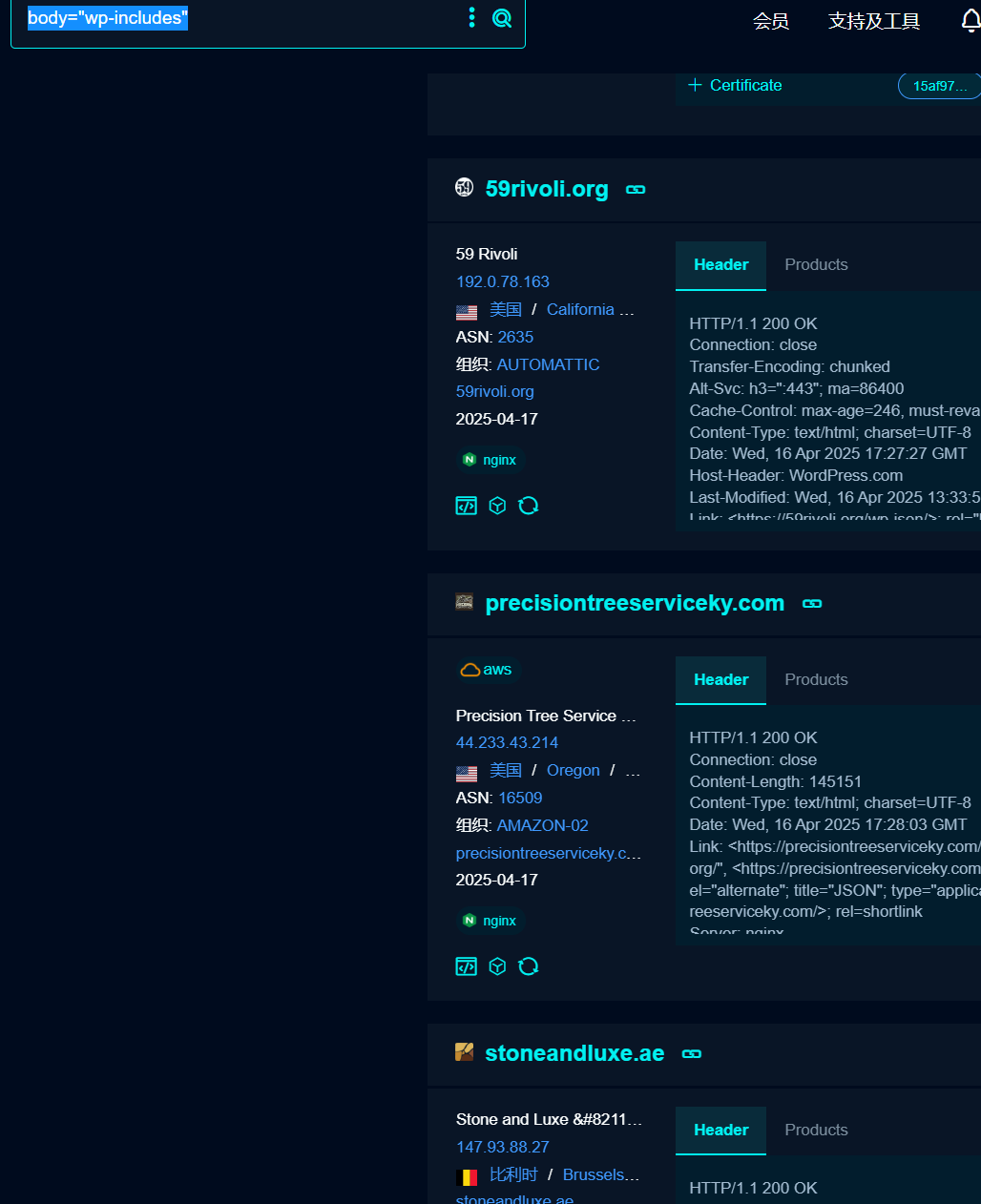
然后点一个进去
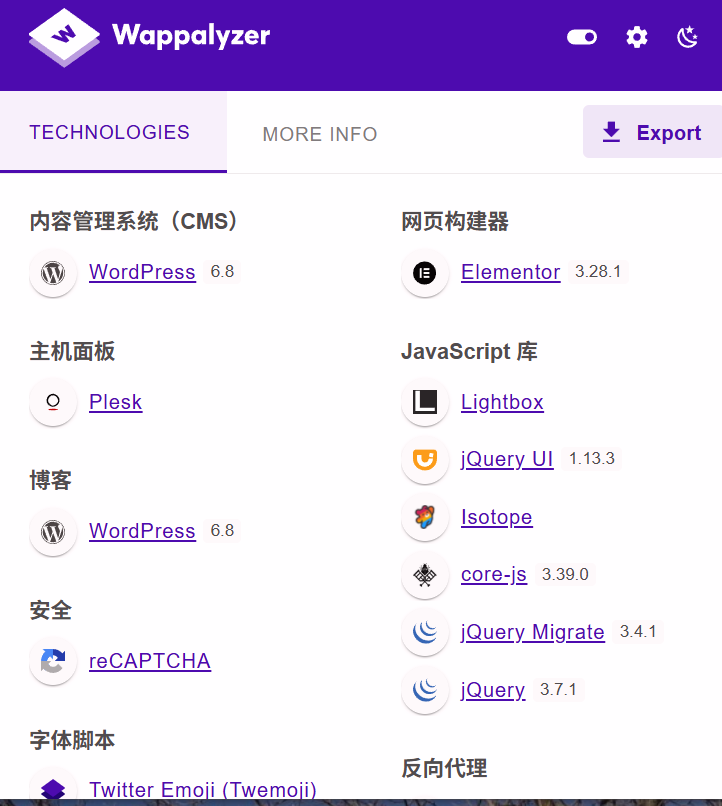
可以看到都是我们的 wordPress 的站点
指纹识别方法
有了我们上面的识别技术,那么我们大概是如何来识别一个指纹的呢
首先使用 python 简单举一个实现
首先就是需要一个配置文件,这个配置文件就需要包含我们的大体指纹和验证方法
php
- name: ThinkPHP
matchers:
- type: header
rule: X-Powered-By
keyword: ThinkPHP
- type: body
keyword: "http://www.thinkphp.cn"
- type: banner
keyword: thinkphp
- type: path
path: /thinkphp/library/think/
keyword: class
- type: favicon_hash
hash: 1165838194然后就是我们的后端处理逻辑了
php
import yaml
import requests
import socket
import base64
import mmh3
def get_http_response(url, path=""):
try:
full_url = url.rstrip("/") + path
return requests.get(full_url, timeout=5)
except:
return None
def get_tcp_banner(ip, port=80):
try:
with socket.create_connection((ip, port), timeout=5) as s:
banner = s.recv(1024).decode(errors="ignore")
return banner
except:
return ""
def get_favicon_hash(url):
try:
res = requests.get(url.rstrip("/") + "/favicon.ico", timeout=5)
favicon = base64.encodebytes(res.content)
return mmh3.hash(favicon.decode('utf-8'))
except:
return None
def load_fingerprints(path="fingerprints.yaml"):
with open(path, "r", encoding="utf-8") as f:
return yaml.safe_load(f)
def match_fingerprint(url, ip=None):
fingerprints = load_fingerprints()
results = []
res = get_http_response(url)
banner = get_tcp_banner(ip or url.replace("http://", "").replace("https://", ""), 80)
favicon_hash = get_favicon_hash(url)
for fp in fingerprints:
matched = False
for matcher in fp["matchers"]:
if matcher["type"] == "header" and res:
if matcher["rule"] in res.headers and matcher["keyword"].lower() in res.headers[matcher["rule"]].lower():
matched = True
elif matcher["type"] == "body" and res:
if matcher["keyword"].lower() in res.text.lower():
matched = True
elif matcher["type"] == "banner":
if matcher["keyword"].lower() in banner.lower():
matched = True
elif matcher["type"] == "path":
res2 = get_http_response(url, matcher["path"])
if res2 and matcher["keyword"].lower() in res2.text.lower():
matched = True
elif matcher["type"] == "favicon_hash":
if favicon_hash == matcher["hash"]:
matched = True
if matched:
results.append(fp["name"])
return results
# 示例使用
if __name__ == "__main__":
target_url = "http://101.200.50.94:8009/"
result = match_fingerprint(target_url)
print("识别结果:", result)大体逻辑就是这样了
首先就是 yaml 文件为我们的判断依据,对应不同的判断方法我们都有对应的后端处理
一个是对 body 的处理,一个是对 hash 文件的处理
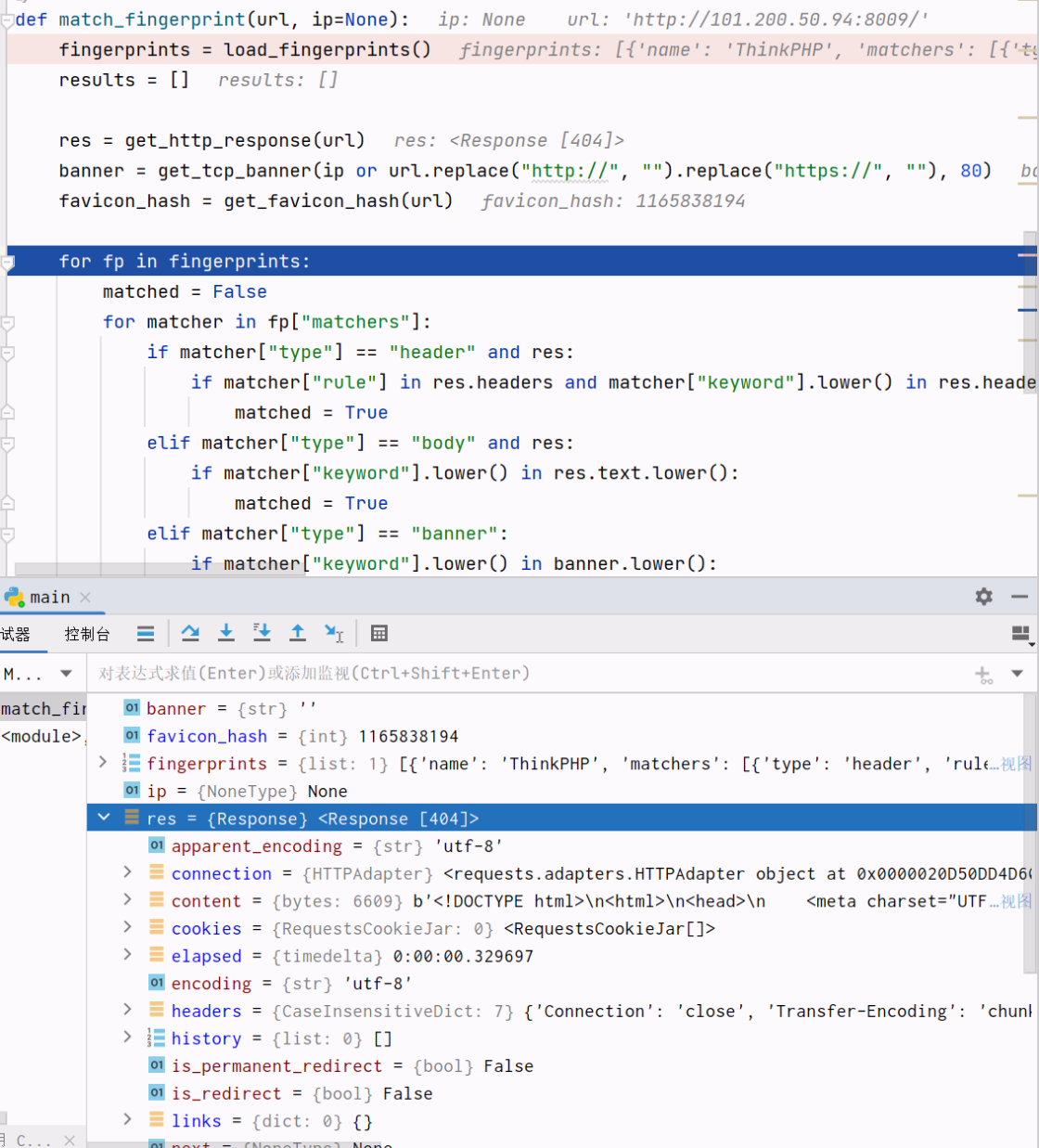
然后再根据规则去匹配
匹配成功输出结果
当然这只是一个简单的逻辑,如果需要实现更高高效快捷第一就是指纹库,第二就是代码运行的速率,提高线程
最终识别代码
首先就是指纹库的获取,这个的话我们就不直接获取了,使用的是 EHole 的指纹库
我们大概看看部分代码
php
{
"fingerprint": [{
"cms": "seeyon",
"method": "keyword",
"location": "body",
"keyword": ["/seeyon/USER-DATA/IMAGES/LOGIN/login.gif"]
}, {
"cms": "seeyon",
"method": "keyword",
"location": "body",
"keyword": ["/seeyon/common/"]
}, {
"cms": "Spring env",
"method": "keyword",
"location": "body",
"keyword": ["servletContextInitParams"]
}, {
"cms": "微三云管理系统",
"method": "keyword",
"location": "body",
"keyword": ["WSY_logo","管理系统 MANAGEMENT SYSTEM"]
}, {
"cms": "Spring env",
"method": "keyword",
"location": "body",
"keyword": ["logback"]
}, {
"cms": "Weblogic",
"method": "keyword",
"location": "body",
"keyword": ["Error 404--Not Found"]
}, {
"cms": "Weblogic",
"method": "keyword",
"location": "body",
"keyword": ["Error 403--"]
}
{
"cms": "Atlassian -- JIRA",
"method": "faviconhash",
"location": "body",
"keyword": ["981867722"]
}, {
"cms": "OpenStack",
"method": "faviconhash",
"location": "body",
"keyword": ["-923088984"]
}, {
"cms": "Aplikasi",
"method": "faviconhash",
"location": "body",
"keyword": ["494866796"]
}, {
"cms": "Ubiquiti Aircube",
"method": "faviconhash",
"location": "body",
"keyword": ["1249285083"]
}简单看了一下逻辑可以发现和我们的指定方法应该差不多,逻辑就是首先根据 method 去选择方法,一个是 keyword 方法,一个是 faviconhash 方法,是一个大的判断,然乎下面就是根据具体的比如 body,title 等去识别了
代码如下
php
import json
import requests
import hashlib
import base64
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
import argparse
# 加载指纹
def load_fingerprints(file='finger.json'):
with open(file, 'r', encoding='utf-8') as f:
data = json.load(f)
if "fingerprint" in data:
return data["fingerprint"]
raise ValueError("指纹文件格式不正确,应包含 'fingerprint' 字段。")
# 获取 HTTP 响应
def get_http_response(url):
try:
headers = {
"User-Agent": "Mozilla/5.0"
}
return requests.get(url, headers=headers, timeout=8, verify=False)
except:
return None
# 计算 favicon hash
def get_favicon_hash(url):
try:
favicon_url = urljoin(url, '/favicon.ico')
res = requests.get(favicon_url, timeout=5, verify=False)
if res.status_code == 200:
m = hashlib.md5()
b64 = base64.b64encode(res.content)
m.update(b64)
return int(m.hexdigest(), 16)
except:
return None
# 匹配单条指纹
def match_one(fpr, res, fav_hash):
method = fpr["method"]
loc = fpr.get("location", "body").lower()
kws = fpr["keyword"]
if method == 'keyword':
text_body = res.text or ""
text_head = "\n".join(f"{k}: {v}" for k, v in res.headers.items())
# 处理 title 和 header 等
if loc == 'header':
spaces = [text_head, text_body]
elif loc == 'title':
soup = BeautifulSoup(text_body, "html.parser")
title = soup.title.string if soup.title and soup.title.string else ""
spaces = [title, text_body]
elif loc == 'body':
spaces = [text_body]
else:
spaces = [text_body]
for space in spaces:
for kw in kws:
if kw.lower() in space.lower():
return True
if method == 'faviconhash' and fav_hash is not None:
for kw in kws:
try:
if fav_hash == int(kw):
return True
except:
continue
return False
# 识别单个 URL 指纹
def match_fingerprint(url, fps=None):
fps = fps or load_fingerprints()
res = get_http_response(url)
fav_hash = get_favicon_hash(url)
matched = []
for fpr in fps:
if 'cms' not in fpr or 'method' not in fpr or 'keyword' not in fpr:
continue
if match_one(fpr, res, fav_hash):
matched.append(fpr['cms'])
print(f"[✓] {url} 指纹识别结果:{list(set(matched))}")
return {url: list(set(matched))}
# 多线程执行
def run_multithread(urls, threads):
fps = load_fingerprints()
results = []
with ThreadPoolExecutor(max_workers=threads) as executor:
future_to_url = {executor.submit(match_fingerprint, url, fps): url for url in urls}
for future in as_completed(future_to_url):
results.append(future.result())
return results
# 主程序入口
def main():
parser = argparse.ArgumentParser(description="指纹识别脚本 - 支持多线程")
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument("-u", "--url", help="单个目标 URL")
group.add_argument("-f", "--file", help="包含多个 URL 的文件")
parser.add_argument("-t", "--threads", type=int, default=10, help="线程数(默认10)")
args = parser.parse_args()
if args.url:
match_fingerprint(args.url)
elif args.file:
with open(args.file, 'r', encoding='utf-8') as f:
urls = [line.strip() for line in f if line.strip()]
results = run_multithread(urls, args.threads)
if __name__ == '__main__':
main()加入了支持多线程和支持多目标的思路
结合漏洞扫描
我们光目标识别后,还需要实现精准化打击,正好 Nuclei 引擎支持根据 tag 去寻找我们的目标,完美了
实现思路就是首先寻找我们的 tag,然后在漏洞库里面查询,把有 tag 的和没有 tag 的分别分开放好,然后根据有 tag 的去精准化识别运行,完成最后的精准化 POC 攻击
初步的代码如下
php
import json
import os
import threading
import time
import base64
import hashlib
import requests
import argparse
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
from queue import Queue
requests.packages.urllib3.disable_warnings()
# ---------- 指纹识别部分 ----------
def load_fingerprints(file='finger.json'):
with open(file, 'r', encoding='utf-8') as f:
data = json.load(f)
return data["fingerprint"]
def get_http_response(url):
try:
headers = {"User-Agent": "Mozilla/5.0"}
return requests.get(url, headers=headers, timeout=8, verify=False)
except:
return None
def get_favicon_hash(url):
try:
favicon_url = urljoin(url, '/favicon.ico')
res = requests.get(favicon_url, timeout=5, verify=False)
if res.status_code == 200:
m = hashlib.md5()
b64 = base64.b64encode(res.content)
m.update(b64)
return int(m.hexdigest(), 16)
except:
return None
def match_one(fpr, res, fav_hash):
method = fpr["method"]
loc = fpr.get("location", "body").lower()
kws = fpr["keyword"]
if method == 'keyword':
text_body = res.text or ""
text_head = "\n".join(f"{k}: {v}" for k, v in res.headers.items())
if loc == 'header':
spaces = [text_head]
elif loc == 'title':
soup = BeautifulSoup(text_body, "html.parser")
title = soup.title.string if soup.title and soup.title.string else ""
spaces = [title]
else:
spaces = [text_body]
for space in spaces:
for kw in kws:
if kw.lower() in space.lower():
return True
elif method == 'faviconhash' and fav_hash is not None:
for kw in kws:
try:
if fav_hash == int(kw):
return True
except:
continue
return False
def match_fingerprint(url, fps):
res = get_http_response(url)
fav_hash = get_favicon_hash(url)
matched = []
for fpr in fps:
if 'cms' not in fpr or 'method' not in fpr or 'keyword' not in fpr:
continue
if match_one(fpr, res, fav_hash):
matched.append(fpr['cms'])
print(f"[✓] {url} 指纹识别结果:{list(set(matched))}")
return {"url": url, "cms": list(set(matched))[0] if matched else ""}
def run_fingerprint_scan(urls, threads, output='res.json'):
fps = load_fingerprints()
results = []
with ThreadPoolExecutor(max_workers=threads) as executor:
future_to_url = {executor.submit(match_fingerprint, url, fps): url for url in urls}
for future in as_completed(future_to_url):
results.append(future.result())
with open(output, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# ---------- Nuclei 扫描部分 ----------
class AutoNuclei:
def __init__(self, res_file='res.json', tag_file='C:\\Users\\86135\\nuclei-templates\\TEMPLATES-STATS.json', thread_count=5):
self.res_file = res_file
self.tag_file = tag_file
self.havetag_file = 'havetag.txt'
self.notag_file = 'notag.txt'
self.result_dir = 'result'
self.thread_count = thread_count
self.cms_targets = {} # {cms: [url1, url2]}
self.nuclei_tags = set()
self.tagged_targets = {} # {tag: [url1, url2]}
self.untagged_targets = []
self.task_queue = Queue()
self.load_res_json()
self.load_tags()
self.classify_targets()
self.save_targets()
self.start_scan_threads()
def load_res_json(self):
with open(self.res_file, 'r', encoding='utf-8') as f:
data = json.load(f)
for entry in data:
cms = entry.get("cms", "").lower()
url = entry.get("url")
if cms and url:
self.cms_targets.setdefault(cms, []).append(url)
def load_tags(self):
with open(self.tag_file, 'r', encoding='utf-8') as f:
tags_data = json.load(f)
for item in tags_data.get("tags", []):
if item["name"]:
self.nuclei_tags.add(item["name"].lower())
def classify_targets(self):
for cms, urls in self.cms_targets.items():
if cms in self.nuclei_tags:
self.tagged_targets.setdefault(cms, []).extend(urls)
else:
self.untagged_targets.extend(urls)
def save_targets(self):
with open(self.havetag_file, 'w', encoding='utf-8') as f:
for tag, urls in self.tagged_targets.items():
for url in urls:
f.write(f"{tag}||{url}\n")
with open(self.notag_file, 'w', encoding='utf-8') as f:
for url in self.untagged_targets:
f.write(url + '\n')
if not os.path.exists(self.result_dir):
os.makedirs(self.result_dir)
def scan_worker(self):
while not self.task_queue.empty():
try:
tag, url = self.task_queue.get(timeout=1)
target_file = f"temp_{int(time.time() * 1000)}.txt"
with open(target_file, 'w', encoding='utf-8') as f:
f.write(url)
output_file = os.path.join(self.result_dir, f"{tag}_{int(time.time())}.txt")
cmd = f"F:\\gj\\Vulnerability_Scanning\\nuclei\\nuclei.exe -l {target_file} -tags {tag} -o {output_file} -stats"
print(f"[+] 扫描任务启动: {url} -> {tag}")
os.system(cmd)
os.remove(target_file)
except Exception as e:
print(f"[!] 线程错误: {e}")
def start_scan_threads(self):
for tag, urls in self.tagged_targets.items():
for url in urls:
self.task_queue.put((tag, url))
threads = []
for _ in range(self.thread_count):
t = threading.Thread(target=self.scan_worker)
t.start()
threads.append(t)
for t in threads:
t.join()
print("[✓] 所有扫描任务完成!")
# ---------- 主程序入口 ----------
def main():
parser = argparse.ArgumentParser(description="指纹识别 + Nuclei自动化工具")
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument("-u", "--url", help="目标 URL")
group.add_argument("-f", "--file", help="URL列表文件")
parser.add_argument("--fp-threads", type=int, default=10, help="指纹识别线程数")
parser.add_argument("--scan-threads", type=int, default=5, help="Nuclei 扫描线程数")
args = parser.parse_args()
urls = []
if args.url:
urls = [args.url]
elif args.file:
with open(args.file, 'r', encoding='utf-8') as f:
urls = [line.strip() for line in f if line.strip()]
print("[*] 正在执行指纹识别...")
run_fingerprint_scan(urls, threads=args.fp_threads, output='res.json')
print("[*] 指纹识别完成,开始 Nuclei 扫描...")
AutoNuclei(
res_file='res.json',
tag_file=os.path.join(os.environ['USERPROFILE'], 'nuclei-templates', 'TEMPLATES-STATS.json'),
thread_count=args.scan_threads
)
if __name__ == '__main__':
main()