Transformer架构
embedding 层的参数量 = 词汇表数量 * 嵌入维度
为什么要使用transformer算法架构
传统的RNN、CNN等算法架构存在的问题:
- 扩展能力差
- 泛化能力弱
Transformer的优势
- 自注意力机制:计算和使用序列中任意文本之间的依赖关系
- 位置编码:能够对序列中的token进行并行计算
Transformer自注意力机制的计算
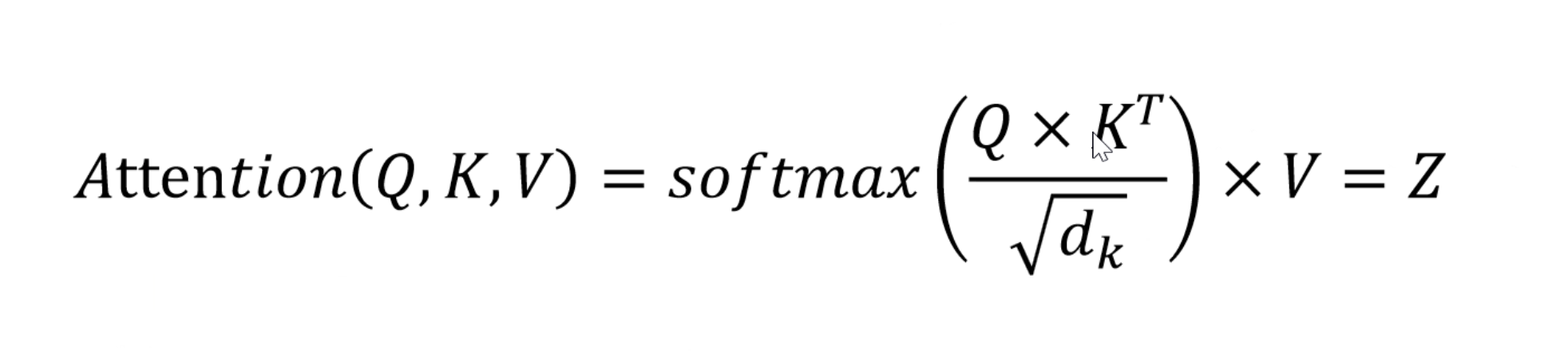
对于给定的序列x1、x2、x3,需要计算他们之间的对应关系,例如求x1和整个文本中x1、x2、x3之间的相关性。
模型通过训练,已经提前得到一个(多注意力头的话会有多个)Wq、Wk、Wv矩阵,这样很容易求得各个输入token的q向量、k向量、v向量。
| q向量 | k向量 | v向量 | |
|---|---|---|---|
| x1 | q1 = x1 * Wq | k1 = x1 * Wq | v1 = x1 * Wv |
| x2 | q2 = x2* Wq | k2 = x2* Wk | v2 = x2* Wv |
| x3 | q3 = x3 * Wq | k3 = x3 * Wk | v3 = x3 * Wv |
得到各个输入token x的q、k、v向量后,带入公式计算各个token直接的相关性。我们可以用一个二维表格进行表示。
| x1 | x2 | x3 | |
|---|---|---|---|
| x1 | Attention(q1, k1, v1) | Attention(q2, k1, v1) | Attention(q3, k1, v1) |
| x2 | Attention(q1, k2, v2) | Attention(q2 k2, v2) | Attention(q3, k2, v2) |
| x3 | Attention(q1, k3, v3) | Attention(q2, k3, v3) | Attention(q3, k3, v3) |
得到的各个token间的关联性得分为,如下的结果,表示x1、x2、x3分别只和自己相近,和其它token均没有相关性。
| x1 | x2 | x3 | |
|---|---|---|---|
| x1 | 0.90 | 0.03 | 0.08 |
| x2 | 0.02 | 0.96 | 0.01 |
| x3 | 0.08 | 0.01 | 0.91 |