一、 环境准备
激活LLaMaFactory环境,进入LLaMaFactory目录
python
cd LLaMA-Factory
conda activate llamafactory下载模型
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct')二、启动一个 Qwen3-0.6B 模型的网页聊天界面
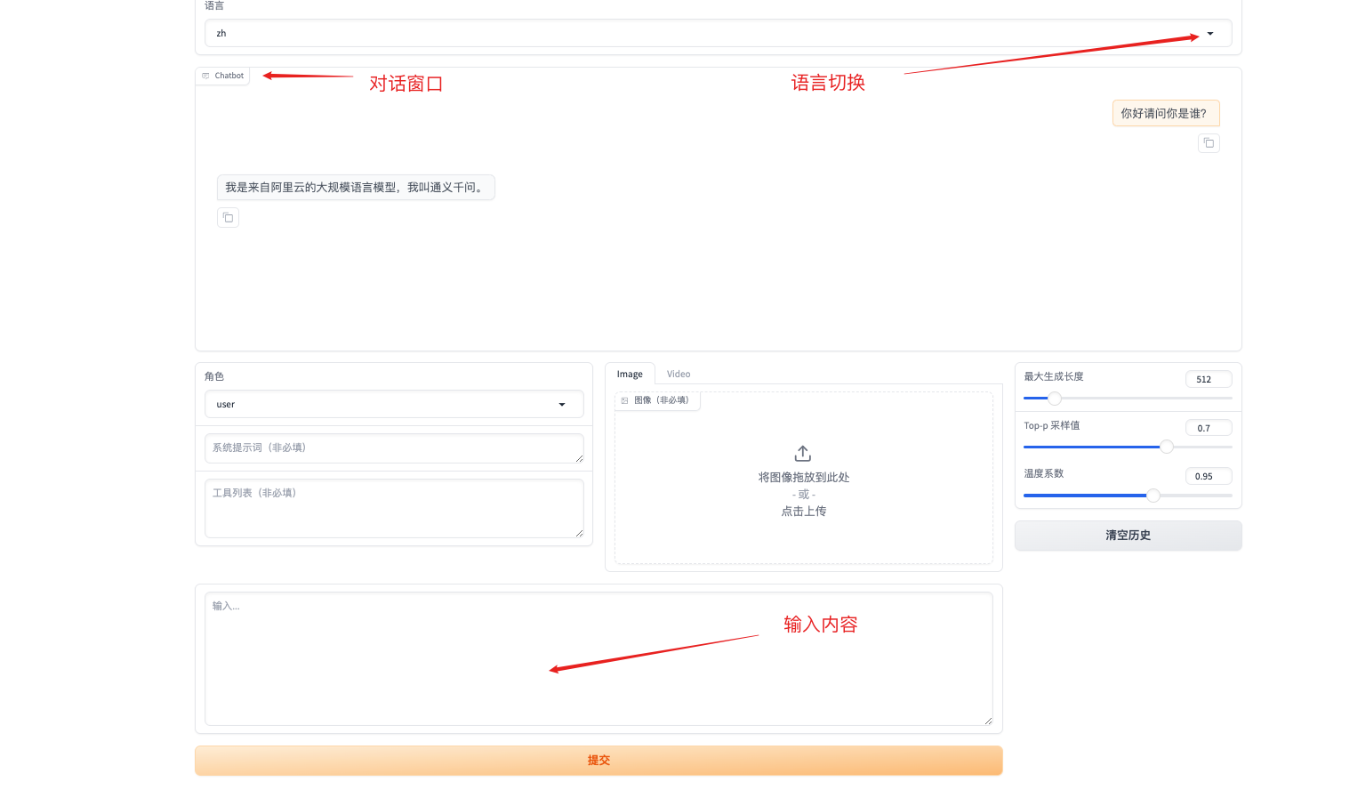
使用 LLaMA-Factory 工具启动一个基于 Qwen3-0.6B 模型的网页聊天界面。
python
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /root/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B \
--template qwen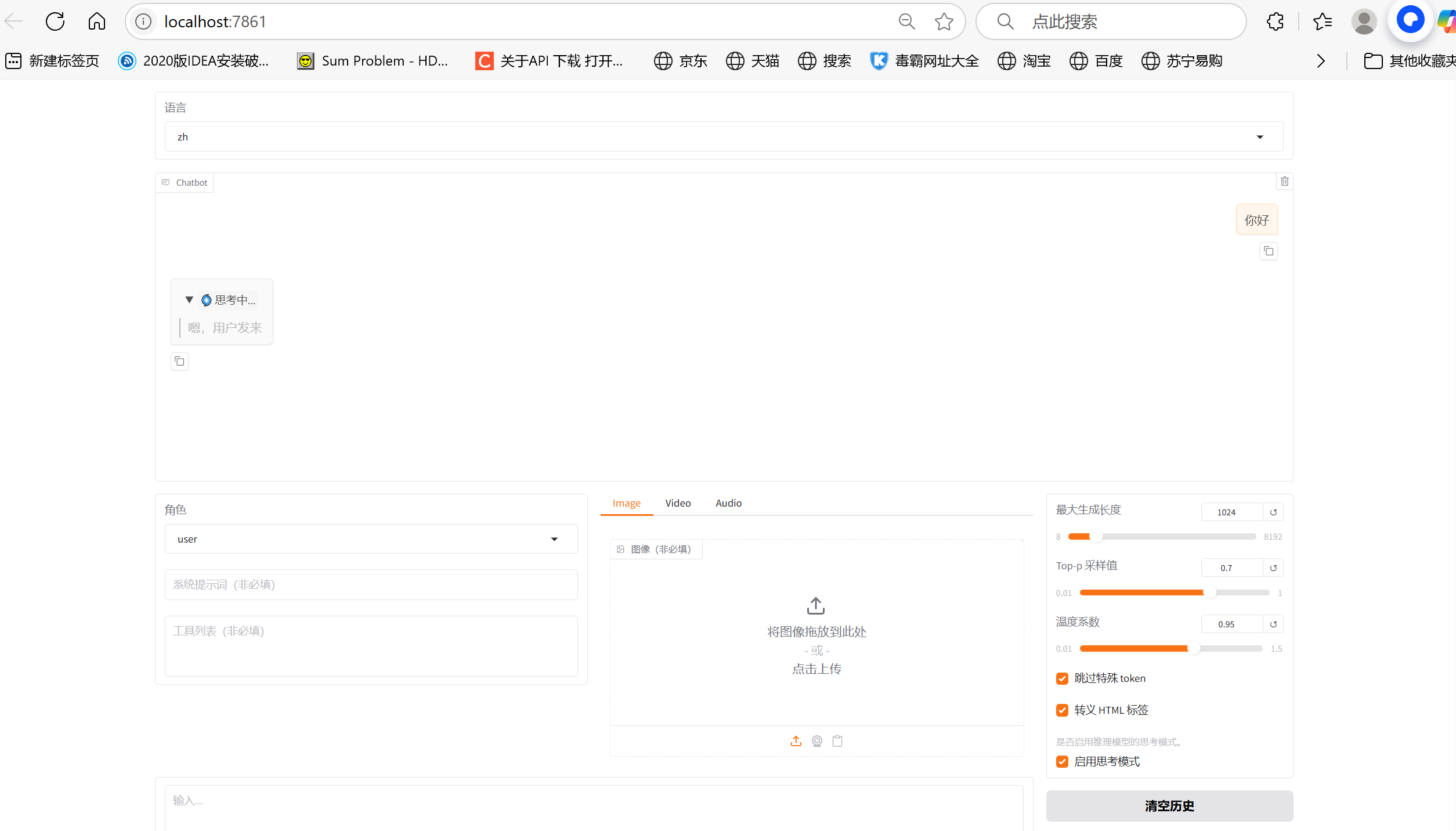
-
CUDA_VISIBLE_DEVICES=0- 指定使用 第0号GPU(单卡运行),屏蔽其他GPU设备。
-
llamafactory-cli webchat- 调用
llamafactory工具的 CLI 接口,启动 网页聊天服务(Web Chat)。
- 调用
-
--model_name_or_path /root/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B-
加载模型路径:
-
从 ModelScope Hub 的本地缓存(
/root/.cache/modelscope)加载 Qwen3-0.6B 模型(60亿参数版本)。 -
若本地无缓存,会先自动下载模型。
-
-
-
--template qwen- 指定使用 Qwen系列专用对话模板,确保模型按Qwen的指令格式处理输入输出(如特殊token和角色标记)。
在LLM(大语言模型)应用中,template(模板) 是控制模型输入输出格式的关键配置,直接影响对话质量和行为。在LLamaFactory中不同模型所使用的模板也会不同。
| Model | Model size | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| DeepSeek 2.5/3 | 236B/671B | deepseek3 |
| DeepSeek R1 (Distill) | 1.5B/7B/8B/14B/32B/70B/671B | deepseekr1 |
| Falcon | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma |
| Gemma 3 | 1B/4B/12B/27B | gemma3/gemma (1B) |
| GLM-4/GLM-4-0414/GLM-Z1 | 9B/32B | glm4/glmz1 |
| GPT-2 | 0.1B/0.4B/0.8B/1.5B | - |
| Granite 3.0-3.3 | 1B/2B/3B/8B | granite3 |
| Hunyuan | 7B | hunyuan |
| Index | 1.9B | index |
| InternLM 2-3 | 7B/8B/20B | intern2 |
| InternVL 2.5-3 | 1B/2B/8B/14B/38B/78B | intern_vl |
| Kimi-VL | 16B | kimi_vl |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3-3.3 | 1B/3B/8B/70B | llama3 |
| Llama 4 | 109B/402B | llama4 |
| Llama 3.2 Vision | 11B/90B | mllama |
| LLaVA-1.5 | 7B/13B | llava |
| LLaVA-NeXT | 7B/8B/13B/34B/72B/110B | llava_next |
| LLaVA-NeXT-Video | 7B/34B | llava_next_video |
| MiMo | 7B | mimo |
| MiniCPM | 1B/2B/4B | cpm/cpm3 |
| MiniCPM-o-2.6/MiniCPM-V-2.6 | 8B | minicpm_o/minicpm_v |
| Ministral/Mistral-Nemo | 8B/12B | ministral |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| Mistral Small | 24B | mistral_small |
| OLMo | 1B/7B | - |
| PaliGemma/PaliGemma2 | 3B/10B/28B | paligemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3/Phi-3.5 | 4B/14B | phi |
| Phi-3-small | 7B | phi_small |
| Phi-4 | 14B | phi4 |
| Pixtral | 12B | pixtral |
| Qwen (1-2.5) (Code/Math/MoE/QwQ) | 0.5B/1.5B/3B/7B/14B/32B/72B/110B | qwen |
| Qwen3 (MoE) | 0.6B/1.7B/4B/8B/14B/32B/235B | qwen3 |
| Qwen2-Audio | 7B | qwen2_audio |
| Qwen2.5-Omni | 3B/7B | qwen2_omni |
| Qwen2-VL/Qwen2.5-VL/QVQ | 2B/3B/7B/32B/72B | qwen2_vl |
| Seed Coder | 8B | seed_coder |
| Skywork o1 | 8B | skywork_o1 |
| StarCoder 2 | 3B/7B/15B | - |
| TeleChat2 | 3B/7B/35B/115B | telechat2 |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 (Code) | 1.5B/6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
三、 llama_factory常用命令
| 动作参数枚举 | 参数说明 |
|---|---|
| llamafactory-cli version | 显示版本信息version |
| # 单卡训练(Qwen1.5-4B模型) CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --model_name_or_path Qwen/Qwen1.5-4B \ --dataset alpaca_en \ --template qwen \ --output_dir ./output # 多卡训练(使用2张GPU) CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train \ --model_name_or_path meta-llama/Llama3-8B \ --dataset alpaca_en,code_alpaca \ --template llama3 \ --bf16 true \ --deepspeed configs/ds_config.json | 命令行版本训练tran |
| # 加载本地微调后的模型 llamafactory-cli chat \ --model_name_or_path ./output/checkpoint-1000 \ --template qwen \ --quantization_bit 4 # 4位量化减少显存占用 | 命令行版本推理chat |
| # 合并LoRA适配器到基座模型 llamafactory-cli export \ --model_name_or_path Qwen/Qwen1.5-4B \ --adapter_name_or_path ./lora_output \ --template qwen \ --export_dir ./merged_model # 导出为GGUF格式(用于llama.cpp) llamafactory-cli export \ --model_name_or_path ./merged_model \ --quantization_bit 4 \ --export_gguf true | 模型合并和导出export |
| # 启动REST API服务(默认端口8000) CUDA_VISIBLE_DEVICES=0 llamafactory-cli api \ --model_name_or_path Qwen/Qwen1.5-4B \ --template qwen \ --port 8080 # 自定义端口 | 启动API server,供接口调用api |
| # 在MMLU数据集上评测 llamafactory-cli eval \ --model_name_or_path ./output/checkpoint-1000 \ --eval_dataset mmlu \ --template qwen \ --batch_size 8 | 使用mmlu等标准数据集做评测eval |
| # 启动Web聊天界面(自动打开浏览器) CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path THUDM/chatglm3-6b \ --template chatglm3 \ --quantization_bit 4 | 前端版本纯推理的chat页面webchat |
| # 启动集成训练/评测/聊天的可视化界面 llamafactory-cli webui \ --model_name_or_path Qwen/Qwen1.5-7B \ --template qwen | 启动LlamaBoard前端页面,包含可视化训练,预测,chat,模型合并多个子页面webui |